基于相似图投影学习的多视图聚类
2024-02-18赵伟豪林浩申曹传杰杨晓君
赵伟豪 林浩申 曹传杰 杨晓君

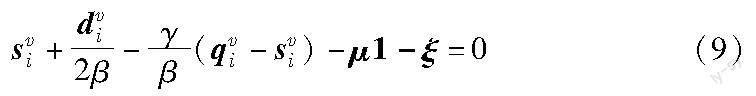

摘 要:随着数据来源方式的多样化发展,多视图聚类成为研究热点。大多数算法过于专注利用图结构寻求一致表示,却忽视了如何学习图结构本身;此外,一些方法通常基于固定视图进行算法优化。为了解决这些问题,提出了一种基于相似图投影学习的多视图聚类算法(multi-view clustering based on similarity graph projection learning,MCSGP),通过利用投影图有效地融合了全局结构信息和局部潜在信息到一个共识图中,而不仅是追求每个视图与共识图的一致性。通过在共识图矩阵的图拉普拉斯矩阵上施加秩约束,该算法能够自然地将数据点划分到所需数量的簇中。在两个人工数据集和七个真实数据集的实验中,MCSGP算法在人工数据集上的聚类效果表现出色,同时在涉及21个指标的真实数据集中,有17个指标达到了最优水平,从而充分证明了该算法的优越性能。
关键词:多视图聚类; 投影学习; 相似图; 图融合
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-016-0102-06
doi:10.19734/j.issn.1001-3695.2023.05.0195
Multi-view clustering based on similarity graph projection learning
Abstract:With the diversified development of data sources, multi-view clustering has become a research hotspot. Most algorithms focus too much on using graph structure to seek consistent representation, but ignore how to learn the graph structure itself. In addition, some methods are usually optimized based on fixed views. In order to solve these problems, this paper proposed a multi-view clustering algorithm based on similarity graph projection learning(MCSGP), which effectively fused the global structure information and local potential information into a consensus graph by using the projection graph, rather than only pursuing the consistency of each view with the consensus graph. By imposing a rank constraint on the graph Laplacian matrix of the consensus graph matrix, this algorithm could naturally divide the data points into the required number of clusters. In the experiments on two artificial datasets and seven real datasets, the MCSGP algorithm shows excellent clustering effect on artificial data sets. At the same time, in the real datasets involving 21 indicators, 17 indicators reach the optimal level, which fully proves the superior performance of the proposed algorithm.
Key words:multi-view clustering; projection learning; similarity graph; graph fusion
0 引言
隨着现代信息技术的发展,信息获取途径不断增多,人们从社交媒体、移动应用程序到各种传统媒体中收集数据的形式也变得越来越多样化,例如一个图片存在HOG特征、LBP特征和Haar特征等多种类型的图像特征。在人们的日常生活中,由于信息不足,若仅基于一个图像特征对图像进行聚类会导致聚类性能降低。由于可以从数据的不同视图中获得不同的信息,多视图聚类所获得的信息量远大于单视图聚类。在多视图聚类中,如何提取有用的信息并综合不同视图的信息进行聚类,已成为一个挑战。
多视图聚类算法是一种处理多源异构数据的有效方法,在这个过程中,研究人员采用不同的思路和技术去融合有用的信息来提高整体的聚类性能。现有多视图算法大致可分为多视图协同训练算法、多视图共正则化算法、多视图多核聚类算法、基于子空间多视图聚类算法、基于图的多视图聚类算法等。
在考虑多视图一致性问题下,协同训练算法被广泛研究和应用,这类算法旨在最大限度地实现所有观点(视图)达成一致,达到最广泛的共识。此外,研究人员也研究了协同训练算法的多个扩展版本,如co-EM[1]、联合正则化[2]、联合聚类[3]等。多核学习最初是为了扩大核函数搜索空间,以提高模型的泛化能力。传统的核学习算法通常使用固定的核函数,如线性核、多项式核和高斯核等。基于多核学习的多视图聚类旨在优化组合一组预定义的核,以提高聚类性能。在这类算法中,一个核心问题就是如何选择合适的核函数,并将这些核函数进行最优的组合以完成聚类任务。在单视图场景下基于最大间隔聚类[4],Zhao等人[5]提出了一种多核聚类算法,可以同时找到最大间隔超平面、最佳聚类和最优核。De Sa等人[6]基于最小化不一致性算法构建了自定义核组合方法。Yu等人[7]将经典的K-means聚类扩展到Hilbert空间,其中多视图数据矩阵被表示为核矩阵,然后自动组合用于数据融合。低秩张量约束多视图子空间聚类是由Zhang等人[8]提出的一种基于子空间的多视图聚类算法,该算法借助潜在空间的理论,假设存在一个多视图数据可以共同表示的潜在表示,将多个视图的数据映射到潜在表示下,利用潜在表示的联系和互补性进行聚类。其中,子空间聚类算法常用的方法包括子空间学习[9~11]和非负矩阵分解。子空间学习通常假设每个视图的数据分布在一个低维子空间中,而非负矩阵分解则假设数据可以表示为非负基向量的线性组合。Xu等人[12]提出了一种新的带有平滑权重的自定步长算法,该算法继承了logistic函数的优点,并提供了概率权重,以缓解局部极小值问题。虽然这些多视图算法[13~17]在不同的数据集下取得了较好的结果,但依然存在下面几个问题:a)目前多视图谱聚类算法中大部分采用预先构造一个共识图的方法,这种方法首先利用其他单视图算法获取每个不同视图的相似图,然后固定这些相似图执行聚类融合任务,未能很好地利用不同视图的信息互补性以更新相似图;b)以往许多研究都集中在共识图与不同视图相似图之间的差异,并采用加权策略来调整视图权重,然而这种差异本身就是存在的,若过度关注于同视图相似图和共识图的本身差异,则会忽略两者之间的关联性;c)不同视图形成相似图的概率本身并没有精确地描述数据之间的关系,而是表征了一种可能的关系,这种关系更多地反映了整体数据的部分信息映射到相似图中的结果。不同视图提供的信息是由整体数据的总信息与某种关系共同作用的结果,但是这种关系并未得到充分的展现。
为了解决上述问题,本文提出一种基于相似图投影学习的多视图聚类(multi-view clustering based on similarity graph projection learning,MCSGP)。a)该算法将投影学习和多视图谱聚类融合为一个框架,并联合优化投影矩阵、局部相似学习和多视图谱聚类,通过这种方式有助于获得可靠性高的相似度图,并最终提高聚类性能;b)该算法采用了互相促进的方法来学习每个视图的图和共识图,而非使用固定的相似图,从而进一步提高了聚类的性能,具体而言,该方法通过投影图将不同视图上的信息融合在共识图中,而不再是专注地利用图结构寻求一致表示,运用投影图去学习图结构本身,借助投影图减少了视图之间的互补性信息,不会产生共识图丢失重要信息的影响,因此该算法能够保证每次更新后视图的互补性信息不会大量减少,并将视图信息也融合到共识图中,以促进学习到的共识图更好地分为不同的聚类簇;c)为了求解联合优化问题,设计了一种有效的交替迭代方法。实验结果表明,MCSGP算法在人工数据集和真实数据集中均表现出了较好的性能,证明了其优越性。
1 相关工作
1.1 符号定义
1.2 自适应邻居聚类
谱聚类是一种基于图论和矩阵分析的无监督学习算法,在处理非凸、非线性的数据中获得的聚类效果较好。谱聚类的构造方式可以通过调整相似度矩阵或拉普拉斯矩阵来适应不同的数据类型和聚类需求。在谱聚类中,构造邻接矩阵时,对于每个边的权重需要用高斯核函数来构造。Nie等人[18]提出在自适应近邻学习中,通过对每个数据点分配基于局部连通性的自适应和最优邻居来学习数据相似度矩阵S,并用实验验证相似度矩阵稀疏会对噪声具有鲁棒性,极大地提高了聚类效果。目标函数为
s.t.i, sTi1=1,0≤si≤1,F∈RApn×c,FTF=I(1)
其中:拉普拉斯矩阵LS=D-(S+ST)/2;度矩阵D是一个对角矩阵,其对角线第i个元素dii=(sij+sji)/2;F∈RApn×c是谱嵌入矩阵,由LS矩阵的c个最小特征值对应的特征向量组成,c是聚类的类别数。上述自适应近邻学习(CAN)的单视图聚类算法可直接使用在多视图聚类中,故目标函数为
其中:svij是第v个视图中相似度矩阵Sv里的第i行、第j列的元素。过去的研究[18]表明,通过样本间的局部相似性可以更准确地刻画样本之间的关系。
1.3 相似图学习
在多视图聚类的图形学习中,MVGL[19]提出了构建共识图的思路,首先对每个视图运用CAN算法,得到每个视图的相似图Sv,然后从多个视图的相似图中学习得到一个统一的共识图A,最后对共识图进行一个拉普拉斯秩约束。在基于图的多视图聚类中,对MVGL进行了改进。GMC[20]模型首先在每个视图的原始样本空间Xv分别学习到自身视图的相似度诱导图Sv,为了融合不同视图的相似图,GMC引入了一个共识的相似度图U,并使每个Sv尽可能地与U达到一致,主要是将视图的一致性信息融合进去。其中wv使每个视图都是自动加权的,并且相似图矩阵和统一图矩阵是联合学习的,以便它们能够以相互加强的方式相互帮助。考虑到每个视图的贡献可能是不同的,GMC的目标函数为
其中:U是学习得来的共识相似度矩阵。这里忽略每个视图的相似度图可能本身差异性就较大,而使用的约束是wv‖U-Sv‖2F,该约束项侧重于增强视图之间的共性,以尽可能使每个视图的自身相似图一致,但是没有充分利用视图之间的差异性。在更新过程中,视图的相似图由于趋于一致而损失了自身视图的信息量,这可能会影响下一次更新共识图矩阵的准确性。为了更好地利用视图间的互补性信息,在每次更新过程中需要保持视图的互补性信息不减少。
2 MCSGP聚类算法
2.1 MCSGP模型
为了将每个视图的相似图学习到一起,MCSGP算法也将引入一个共识的相似度图U,并且假设每个视图的相似度图Sv是由共识相似度图投影得到的,本文模型使用核范数来度量误差,所构建的约束为
其中:Pv是投影矩阵。每个视图样本之间的关系主要是通过将整个共识图样本之间的关系投影到视图空间中获得的,这样可以避免每个视图的相似图逐渐趋于一致的问题,并且减少了在更新过程中损失视图间互补性信息的风险。此外,这种方法还可以获得每个视图中的信息,并将其融合到共识图中。为更好地将共识相似度图合理地划分为c个聚类簇,在GMC算法启发下,本文也引入rank(LU)=n-c约束项,其中LU=DU-(U+UT)/2。矩阵的秩约束直接求解并不能有效地得到目标函数的解。令υi(LU)为LU的第i个最小的特征值。由于LU
其中:β、γ、λ是目标函数的超参数,用于平衡每个约束项之间的权重。在整体的目标函数中,本文通过投影关系将多视图数据的共识相似图与每个视图的相似图融合在一起。此外,多视图相似度图和共识图之间的相互学习可以改善不同视图与共识图的映射关系,并且能够生成更符合实际映射关系的投影图。接下来,采用一种交替迭代优化方法(alternating direction method of multipliers,ADMM)来求解式(5),即目标函数。
2.2 优化求解
本文提出的多視图聚类模型的目标函数是高度耦合的,难以一次性求解每个变量。为了解决这个问题,本文将目标函数分解为四个子问题,并采用交替迭代优化方法对每个变量进行优化求解。通过这种方式可以有效地降低问题的复杂度,提高求解效率,并且保证每个变量的优化问题都能得到充分的考虑和处理。
1)固定Pv、U、F,更新Sv 当其余参数固定时,目标函数最后一项变为常量,目标函数等价于
注意到式(6)中不同的i对应的svi之间是相互独立的,因此可以对每个svi分别求解该问题。
定义dvij=‖xvi-xvj‖22和Qv=PvU,将qvi∈RApn×1定义为向量,属于Qv中的第i列。式(6)可以写成向量的形式:
由式(7)根据现有的约束项构建拉格朗日函数:
其中:μ为拉格朗日系数标量;ξ为拉格朗日系数向量。由上式对svi求导并令求导为零,即得到
根据Karush-Kuhn-Tucker(KKT)条件求解得到
根据文献[21]中的解法,限制svi有k个非零元素,则
又因约束条件1Tsvi=1,则
由式(11)(12)综合可得
为了约束svi有k个非零元素的最优解,可得
根据式(11)(12)(14),联立可得Sv最终的更新公式为
2)固定Sv、U、F,更新Pv 当其余参数固定时,目标式(3)只有第三项依然是变量,目标函数等价于
对于任意矩阵,‖M‖2F=Tr(MMT)都成立。可将式(16)推导为
通过简单替换,模型变为
其中:A=UUT,B=USv。为了求解式(18),本文引入文献[22]中的定理来解决此模型。可以将式(18)中的Stiefel流形上的二次问题进一步松弛为
其中:W=(Pv)T,通过式(20)对W求导为0,且由文献[22]可得到
定理1 用UΣVT表示M∈RApm×n的奇异值分解,则Z=UVT是式(19)的解。
arg max Tr(ZTM)
s.t. ZTZ=I(22)
其中:UTU=VTV=Ir;Σ∈RApr×r为非奇异对角矩阵,其对角线上的元素为矩阵B的奇异值λi;r=rank(M)。
根据定理1,式(18)的最优解为
Pv=WT=(UVT)T(23)
其中:U和V是M的左、右奇异向量矩阵。
3)固定Sv、F、Pv,更新U 当其他参数固定时,目标式(5)可推导为
由于Pv是投影矩阵,且符合(Pv)TPv=I,而且投影矩阵是固定的,可继续优化公式得
由于‖AB‖F≤‖A‖F‖B‖F和‖Pv‖F=‖(Pv)T‖F,式(26)的第二部分一起优化,将矩阵转换成矩阵各个元素即
其中:dfij=‖fi-fj‖22,Ev=PvSv,evij是矩阵Ev中第i行、第j列的元素。因式(27)的变量为U,‖Pv‖2F是一个固定量,可当做常数。注意到问题对不同的i是独立的,因此对每个ui分别求解式(27),可优化为
进一步将dfi表示为向量,对应第j个元素为dfij,将evi表示为向量,对应第j个元素为evij。将问题等价于求解如下问题:
4)固定Sv、Pv、U,更新F 优化问题即为解决以下问题:
则最优解F由拉普拉斯矩阵LU最小c个特征值对应的c个特征向量组成。算法1总结了MCSGP的所有操作流程。
5)初始化 在实际实验过程中,本文初始化相似图(SIG)矩阵,每个视图的SIG矩阵是独立的,这里以Sv为例。
其中:bvij=‖xvi-xvj‖22和k是近邻个数。设投影矩阵Pv初始化为单位矩阵,共识相似图矩阵U为
算法1 MCSGP
输入:具有m个视图的多视图数据集{Xv}mv=1,聚类数c,初始化参数β、γ、λ。
输出:Sv、Pv、U,F。
初始化:通过式(31)(32)(30)来初始化Sv、U、F以及初始化Pv为单位矩阵;
重复执行:
通过式(15)来优化Sv;
通过式(23)来优化Pv;
通过式(29)来优化U;
通过式(30)来优化F;
直到目标函数收敛
2.3 复杂度分析
本节分析MCSGP算法的计算成本,该算法主要由相似图构造、投影图构造、共识相似图构造和谱聚类四部分组成。对应的复杂度分别为O(mnk),O(m3n3),O(cn),O(cn2)。其中m代表视图数,n代表样本数,c代表聚类,由于n>>m并且n>>c,本文算法的复杂度主要计算投影图的构造过程。
3 实验结果与分析
3.1 人工数据集实验
本文使用了两个被广泛应用的人工数据集,分别是:a)TwoMoon数据集,由两个视图组成,每个视图包含两个月球形簇,添加0.12%的高斯随机噪声,每个类别包含100个样本点;b)ThreeRing数据集,由三个视图组成,每个视图都由三个同圆心但不同半径的圆组成,并且添加了随机高斯噪声,每个类分别包含30、90和180个样本点。
图1和2显示了TwoMoon和ThreeRing中两个视图的聚类过程。图2(b)展示了两个视图最原始的相似矩阵构造图,两个类之间的数据点是有连接的部分,说明类群之间的相连不易分离;图2(c)展示了两个视图通过目标函数迭代学习到的相似矩阵构造图,可以发现,其与图2(b)部分数据点之间的边被削弱,部分边被对应地加强;图2(d)展示了三个圆形聚类得到了很好的分离,这是因为MCSGP算法通过投影图,充分利用了不同视图相似矩阵的差异性信息,并在共识图中融合它們。在人工数据集上的实验结果表明,本文算法能够很好地融合不同视图的信息互补性,利用投影图可以最大程度地保留每个视图的信息,同时在共识图中融合这些信息,从而实现视图间的信息交互。
3.2 真实数据集实验
本节旨在对七个真实的多视图数据集进行评估,以验证本文算法的有效性。表1介绍了这些数据集的相关信息。
a)BBC数据集,它是一个包含685篇文章的合成文本数据集,这些文章来自BBC新闻网站。每个文档分为四个部分,对五个主题标签中的一个进行人工标注。
b)100Leaves数据集,它是一个包含16种不同植物叶片的数据集,每种都有100个样本。对于每个样本,给出了形状描述符、细比例边界和纹理直方图。
c)ORL数据集,它是一个包含400张不同人脸的图像数据集,是由英国剑桥的Olivetti研究实验室在1992—1994年期间创建的。该数据集包括40个不同人的图像,每个人有10张图像,此外,该数据集还包括4个视图。
d)MSRC_v1数据集,它是一个包含210张图像和7个类的数据集,数据来自剑桥微软研究院,是带有粗粒度标记的图像。
e)3sources数据集,它是包含169条新闻组成的多视图文本语料库。该数据集由三个在线新闻服务的文章组成,包括英国广播公司、路透社和《卫报》的三个视图,每个视图有169个新闻,共分为6个类别。
f)WebKB数据集,它是包含四所大学的计算机科学系收集的网页数据,共4个类别以及203个网页样本。每个网页通过页面的内容、超链接的锚文本以及标题中的文本进行描述。
g)HW2sources数据集,它是一个包含2 000个手写数字的图片数据集,来自UCI存储库,其中每个样本都是手写数字之一(0~9)。数据来源于HW数据集里的两个视图。
用于比较的11种多视图聚类算法分别是SC_best、基于联合非负矩阵分解的多视图聚类(multi-view clustering via joint nonnegative matrix factorization,MultiNMF)[24]、谱聚类的亲和聚合(affinity aggregation for spectral clustering,AASC)[25]、自適应加权过程进行多视图聚类(multiview clustering via adaptively weighted procrustes,AWP)[26]、共正则化多视图光谱聚类(co-regularized multi-view spectral clustering,CoReg)[27]、多视图共识图聚类 (multiview consensus graph clustering,MCGC)[28]、多视图聚类的图形学习(graph learning for multiview clustering,MVGL)[19] 、基于低秩和稀疏分解的鲁棒多视角谱聚类(robust multi-view spectral clustering via low-rank and sparse decomposition,RMSC)[29]、基于图的多视图聚类(graph-based multi-view clustering,GMC)[20]、基于深度非负矩阵分解的多层流形学习多视图聚类(multi-layer manifold learning for deep non-negative matrix factorization-based multi-view clustering,ODD-NMF)[30]、基于集成的快速多视图聚类(fast multi-view clustering via ensembles: towards scalability,superiority,and simplicity)[31]。其中SC_best是在真实数据集中每个视图实验过程中进行谱聚类,取单个视图中最好的聚类效果。为了减少部分对比算法初始化带来的随机性,将每种对比算法重复执行10次,并取其平均聚类效果值,本文算法和对比算法在真实数据集的聚类性能结果如表2~4所示。
3.3 聚类实验结果
在本次实验中,对样本数据进行归一化处理,并采用三种常用的评价指标,即准确度(accuracy,ACC)、归一化互信息(normalized mutual information,NMI)、纯度(purity,PUR)。对于这三个指标,数值显示越高,证明聚类性能越好。如表2~4所示,在这次实验过程中,对相同数据集的实验性能,不同算法聚类性能最优算法用黑体加粗,次优算法加下画线。具体来看,在ORL、MSRC_v1、WebKB、BBC和HW2sources数据集上,显示了本文算法优于其他对比算法,三个指标都占优。在BBC、100Leaves和3sources数据集上显示本文算法在部分指标上占优,尤其是3sources和WebKB数据集,准确度远远领先于次优算法,分别提高了6.51%和6.77%。在WebKB数据集中,MCSGP算法在互信息量指标下的聚类效果也显著优于其他算法,该算法能够学习到样本间的局部相似性以及视图间的互补性,将每个视图的互补性信息映射到共识相似矩阵中,从而获得一个更优的聚类效果。
3.4 参数敏感性分析
在本文实验过程中,有三个超参数需要手动调整,分别是视图正则化参数β、视图投影权重系数γ、谱聚类权重参数λ。为了直观地说明参数对聚类性能的影响,本文在BBC数据集上进行了基于ACC和NMI的参数分析实验。三个参数在[50:10:100]遍历。实验结果如图3所示。实验固定一个参数,测试另外两个参数的敏感性,从图3可以看出,三个参数对算法准确度和互信息量影响不大,表明本文方法的性能对参数不敏感。在其他数据集上的实验也得出类似结论,说明本文算法稳定可靠,但仍需根据具体情况调整参数,以达到最佳性能。
3.5 收敛性分析
本节主要负责验证目标函数能否达到收敛。图4展示了迭代目标函数与迭代次数的关系,本文算法的目标函数在七个数据集中,在前15次迭代就已达到条件,收敛速度较快,侧面说明了本文算法的高效性。
4 结束语
本文提出一种基于相似图投影学习的多视图聚类(MSCGP)算法。首先该算法充分考虑了局部相似性,能够自适应地学习样本间的相似图构造;充分借助自适应学习的投影图,将共识图和不同视图的相似图更好地融合,在统一的优化框架下联合学习自适应图、学习投影图和共识图;最后,通过直接动态融合得到最佳共识图矩阵和谱嵌入矩阵,以及最后的聚类结构。通过实验,在涉及到7个真实数据集的评估中,本文算法在11个对比算法中共涉及的21个聚类指标中表现出优异的结果。具体而言,本文算法在这些指标中有17个聚类指标排名最高,并且还有2个聚类指标排名次高,本文算法展现出了比对比算法更为稳定的整体聚类效果。经过对人工数据集和真实数据集的实验,MCSGP算法证明了其有效性和出色的性能表现,但是本文算法的计算复杂度较高,导致运算时间较长。未来的研究将致力于在不大幅度降低算法精确度的前提下,进一步提升算法的运算效率。
参考文献:
[1]Nigam K, Ghani R. Analyzing the effectiveness and applicability of co-training[C]//Proc of the 9th International Conference on Information and Knowledge Management.New York:ACM Press,2000:86-93.
[2]Cai Xiao, Nie Feiping, Huang Heng, et al. Heterogeneous image feature integration via multi-modal spectral clustering[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Washington DC:IEEE Computer Society,2011:1977-1984.
[3]Assent I, Domeniconi C, Gullo F, et al. MultiClust 2013: multiple clusterings, multiview data, and multisource knowledgedriven clustering[J].ACM SIGKDD Explorations Newsletter,2016,18(1):35-38.
[4]Xu Linli, Neufeld J, Larson B, et al. Maximum margin clustering[C]//Proc of the 17th International Conference on Neural Information Processing Systems.Cambridge,MA:MIT Press,2004:1537-1544.
[5]Zhao Bin, Kwok J T, Zhang Changshui. Multiple kernel clustering[C]//Proc of SIAM International Conference on Data Mining.[S.l.]:Society for Industrial and Applied Mathematics,2009:638-649.
[6]De Sa V R, Gallagher P W, Lewis J M, et al. Multi-view kernel construction[J].Machine Learning,2010,79(1-2):47-71.
[7]Yu Shi, Tranchevent L, Liu Xinhai, et al. Optimized data fusion for kernel K-means clustering[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2011,34(5):1031-1039.
[8]Zhang Changqing, Fu Huazhu, Liu Si, et al. Low-rank tensor constrained multiview subspace clustering[C]//Proc of IEEE International Conference on Computer Vision.Washington DC:IEEE Compu-ter Society,2015:1582-1590.
[9]張华伟,陆新东,朱小明,等.基于t-SVD的结构保持多视图子空间聚类[J].计算机科学,2022,49(S2):525-530.(Zhang Huawei, Lu Xindong, Zhu Xiaoming, et al. Structure preserved multi-view subspace clustering based on t-SVD[J].Computer Science,2022,49(S2):525-530.)
[10]Liu Xiaolan, Pan Gan, Xie Mengying. Multi-view subspace clustering with adaptive locally consistent graph regularization[J].Neural Computing and Applications,2021,33(11):15397-15412.
[11]洪振宁,苏雅茹.非凸张量多视图子空间聚类[J].福州大学学报:自然科学版,2022,50(6):737-741.(Hong Zhenning, Su Yaru. Non convex tensor multi-view subspace clustering[J].Journal of Fuzhou University:Natural Science Edition,2022,50(6):737-741.)
[12]Xu Chang, Tao Dacheng, Xu Chao. Multi-view self-paced learning for clustering[C]//Proc of the 24th International Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2015:3974-3980.
[13]宋菲.基于聚类结构和局部相似性的多视图隐空间聚类[J].计算机应用研究,2023,40(9):2650-2656.(Song Fei. Multi-view latent subspace clustering with cluster structure and local similarity[J].Application Research of Computers,2023,40(9):2650-2656.)
[14]Hussain S F, Mushtaq M, Halim Z. Multi-view document clustering via ensemble method[J].Journal of Intelligent Information Systems,2014,43(1):81-99.
[15]Serra A, Greco D, Tagliaferri R. Impact of different metrics on multi-view clustering[C]//Proc of International Joint Conference on Neural Networks.Piscataway,NJ:IEEE Press,2015:1-8.
[16]Xue Zhe, Li Guorong, Wang Shuhui, et al. GOMES:a group-aware multi-view fusion approach towards real-world image clustering[C]//Proc of IEEE International Conference on Multimedia and Expo.Piscataway,NJ:IEEE Press,2015:1-6.
[17]Hou Chenping, Nie Feiping, Tao Hong, et al. Multi-view unsupervised feature selection with adaptive similarity and view weight[J].IEEE Trans on Knowledge and Data Engineering,2017,29(9):1998-2011.
[18]Nie Feiping, Wang Xiaoqian, Huang Heng. Clustering and projected clustering with adaptive neighbors[C]//Proc of the 20th ACM SIGKDD international Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2014:977-986.
[19]Zhan Kun, Zhang Chanqing, Guan Junpeng, et al. Graph learning for multiview clustering[J].IEEE Trans on Cybernetics,2017,48(10):2887-2895.
[20]Wang Hao, Yang Yan, Liu Bing. GMC:graph-based multi-view clustering[J].IEEE Trans on Knowledge and Data Engineering,2019,32(6):1116-1129.
[21]Nie Feiping, Cai Guohao, Li Xuelong. Multi-view clustering and semi-supervised classification with adaptive neighbours[C]//Proc of the 31st AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2017:2408-2414.
[22]Nie Feiping, Zhang Rui, Li Xuelong. A generalized power iteration method for solving quadratic problem on the Stiefel manifold[J].Science China Information Sciences,2017,60(5):article No.112101.
[23]Fiori S. Formulation and integration of learning differential equations on the Stiefel manifold[J].IEEE Trans on Neural Networks,2005,16(6):1697-1701.
[24]Liu Jialu, Wang Chi, Gao Jing, et al. Multi-view clustering via joint nonnegative matrix factorization[C]//Proc of SIAM International Conference on Data Mining.[S.l.]:Society for Industrial and Applied Mathematics,2013:252-260.
[25]Huang H C, Chuang Y Y, Chen Chusong. Affinity aggregation for spectral clustering[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Washington DC:IEEE Computer Society,2012:773-780.
[26]Nie Feiping, Tian Lai, Li Xuelong. Multiview clustering via adaptively weighted Procrustes[C]//Proc of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.New York:ACM Press,2018:2022-2030.
[27]Kumar A, Rai P, Daume H. Co-regularized multi-view spectral clustering[C]//Proc of the 24th International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2011:1413-1421.
[28]Zhan Kun, Nie Feiping, Wang Jing, et al. Multiview consensus graph clustering[J].IEEE Trans on Image Processing,2019,28(3):1261-1270.
[29]Luong K, Nayak R, Balasubramaniam T, et al. Multi-layer manifold learning for deep non-negative matrix factorization-based multi-view clustering[J].Pattern Recognition,2022,131(11):108815.
[30]Xia Rongkai, Pan Yan, Du Lei, et al. Robust multi-view spectral clustering via low-rank and sparse decomposition[C]//Proc of the 28th AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2014:2149-2155.
[31]Huang Dong, Wang Changdong, Lai Jianhuang. Fast multi-view clustering via ensembles:towards scalability, superiority, and simplicity[J].IEEE Trans on Knowledge and Data Engineering,2023,35(11):11388-11402.
