面向复杂数据审计需求的数据血缘构建方法
2024-02-18潘晓华金泳高扬华朱心洲沈诗婧
潘晓华 金泳 高扬华 朱心洲 沈诗婧

摘 要:针对复杂数据审计需求,现有方法是通过查询分析数据库中每条执行语句信息,数据审计效率低下;目前也有一些手段是使用数据血缘工具进行快速查找,但是这种方式需要侵入系统获取源码,容易造成数据泄露或者被恶意窜改。针对这些问题,提出一种面向复杂数据审计需求的数据血缘构建方法,融合日志预处理、数据关系解析、数据对齐等关键技术,通过解析系统运行日志信息以非侵入的方式实现数据血缘图谱的构建,并面向烟草物流出入库环节形成数据审计工具。以烟草物流中13 796个批次货物在流转过程中所对应的155 728条事务日志为测试数据集,从完整性、构建成本、数据审计效率三个方面进行对比实验。结果表明,提出的方法能够在10 s内完成查询任务,占用内存为1.23 MB/百条,明显少于现有方法。相比现有方法,提出的方法可在数据级粒度上进行完整准确的数据血缘构建,且使用基于该方法所构建的数据血缘进行数据审计能够大幅度提升卷烟物流过程中的数据审计效率。
关键词:数据血缘; 非侵入式; 数据审计; 卷烟物流; 自动化作业
中图分类号:TP311.13 文献标志码:A 文章编号:1001-3695(2024)01-012-0076-07
doi:10.19734/j.issn.1001-3695.2023.05.0214
Data lineage construction method for complex data audit requirements
Abstract:For complex data audit requirements, existing methods rely on querying and analyzing the information of each execution statement in the database, resulting in low efficiency of data audit. At present, there are also some methods that use data lineage tools for quick search, but these methods require intrusion into the system to obtain source code, which can easily cause data leakage or malicious tampering. In response to these issues, this paper proposed a data lineage construction method for complex data audit requirements, integrating key technologies such as log preprocessing, data relationship analysis, and data alignment. By analyzing the systems running log information, it constructed the data lineage graph in a non-invasive manner, and formed a data audit tool for the tobacco logistics inbound and outbound. This paper took 155 728 transaction logs corresponding to 13 796 batches of goods in the tobacco logistics as the test dataset and conducted comparative experiments from three aspects, such as completeness, construction cost, and data audit efficiency. The experimental results show that the proposed method can complete the query task within 10 s, occupying a memory of 1.23 MB/hundred items, which is obviously less than the existing methods. Compared with the existing methods, the proposed method can construct a complete and accurate data lineage at the data level granularity, and using the data lineage constructed by this proposed method can greatly improve the efficiency of data auditing in the cigarette logistics.
Key words:data lineage; non-invasive; data audit; cigarette logistics; automated job
0 引言
伴隨着大数据、智能制造等技术的发展,卷烟企业的物流过程逐步从传统人工作业方式进入到自动化设备作业方式[1, 2],自动化方式通过在运输、入库、出库、分拣等物流环节读写周转箱或笼车上的RFID(radio frequency identification)标签实现了实时向信息系统更新各作业的数据,建立了卷烟物流过程中各阶段之间的联系。自动化的方式极大地提高了卷烟物流过程中的效率,降低了成本。在卷烟物流自动化作业的过程中会产生大量的数据,涉及出入库扫码系统、在途信息系统、分拣打码系统、仓储系统等多个物流信息系统,数据组成较为复杂,存在大量数据之间的交叉关联关系,并且由于早期数据定义标准不同,数据呈现出多源、异构的特点[3]。在卷烟物流自动化作业的过程中存在着大量数据审计需求,如在入库时审计某一批次的货物完整的历史流转信息,或查看系统中某异常数据的上下链路等。伴随着海量数据的增长,对卷烟物流数据进行审计分析变得越来越耗时,极大地影响了物流过程中的生产效率,造成卷烟货物入库堆积等问题;由于数据被不同系统所使用[3,4]、数据之间存在的复杂关系等原因,现有通过SQL查询[5,6]、数据整合[7,8]等方法来处理审计需求的方法往往不具有普适性,需要开发人员对数据底层及数据关系有广泛的了解,所以迫切需要一种新方法来提高卷烟物流过程中数据审计的效率。
数据血缘技术为上述问题提供了一种可行性方案,数据血缘(又称数据世系)是一种描述数据从产生并随时间演化的过程中数据之间关系的方法[9]。数据血缘技术在金融数据监管[10,11]、物联网设备数据防窜改[12]等场景已得到广泛应用。通过构建卷烟物流过程中的数据血缘可记录物流过程中数据的全链路流转过程,可针对数据向下做影响分析或向上做溯源分析,并基于此满足各类卷烟物流过程中的数据审计[13]需求,提高审计人员对卷烟物流流转过程中的数据管控能力。
构建卷烟物流过程中的数据血缘并非易事,在现有研究中,数据血缘构建方法主要分為两类[14]:a)侵入式的方法,如Bates等人[15]提出的Linux provenance modules、Alkhaldi等人[16]提出的Wasef(write-ahead store engine,schema-agnostic indexing engine,extensible transaction management,flexible query processing)等方法,侵入式方法需要从系统的内核层截获系统调用信息,并从中获取、解析相关的数据血缘信息,此类方法可以准确、完整地进行数据血缘的构建,但在系统层面往往具有较高的安全敏感性,且受到操作系统内核限制;b)非侵入式的方法,如Chacko等人[17]提出的一种基于MongoDB数据库操作日志进行数据血缘构建的方法、马张迪[18]提出的通过解析Spark中数据执行逻辑计划以构建Spark平台中数据血缘的方法等,非侵入式方法无须在操作系统层级上进行数据血缘的构建,可与现有数据存储系统兼容使用,无须对现有数据存储逻辑进行较大的改动,但受限于可获取信息局限在数据原本的结构信息,现有非侵入式方法只能在表级粒度、字段级粒度上进行数据血缘的构建,无法在更精确的数据级粒度上进行数据血缘的构建。
使用现有侵入式的数据血缘构建方法无法在单条数据的粒度上进行数据血缘构建及分析,不适用于卷烟物流数据审计场景及需求,且通过侵入至操作系统层面进行数据血缘构建不适用于分布式系统,同时会影响卷烟物流信息系统的安全。为此,本文提出一种面向复杂数据审计需求的数据血缘构建方法,包括数据收集、数据关系解析、数据对齐、血缘存储,该方法可从卷烟物流信息系统数据库的运行日志中提取事务信息,无须侵入至操作系统层面进行相关操作,不影响原系统使用;同时,借助该方法所构建的数据血缘可将卷烟物流过程中复杂的数据审计查询问题转换为图搜索问题,有效地提高卷烟物流过程中的数据审计效率。与已有非侵入式数据血缘构建方法相比,本文方法可以在更精确的数据粒度上进行准确、完整的数据血缘构建。本文主要贡献如下:a)提出一种面向复杂数据审计需求的非侵入式数据血缘构建方法,通过解析系统日志信息构建完整数据血缘图谱;b)提出了一种基于SQL表达式词法分析和抽象语法树构建的数据关系解析方法,将数据血缘的粒度提升至单条数据;c)提出了一种基于信息熵的数据对齐方法,实现了不同事务中解析出的数据间的关联,提升了数据血缘结果的准确性和全面性。本文方法主体结构如图1所示。
1 数据血缘构建
如图2所示,本文提出的数据血缘构建方法主要包括日志预处理、数据关系解析、数据对齐、血缘存储四个阶段。该方法基于以下两个目标进行设计:a)不影响现有卷烟物流信息系统的正常使用;b)在数据层面上进行数据血缘的构建。
1.1 日志预处理
卷烟物流信息系统数据库运行日志中记录着卷烟物流自动化作业过程中涉及数据的所有事务,其中事务包括时间和所执行的SQL表达式。通过日志预处理整理日志格式,可以从日志中提取、过滤蕴涵数据关系的事务。如算法1的伪代码所示,日志预处理的流程如下:a)定义一个关键词列表(如INSERT、UPDATE、DELETE);b)结合关键词列表,通过正则表达式对原始日志L进行过滤;c)以(时间,SQL表达式)的格式提取出包含数据流转关系的事务,将其加入事务集合J。
对于记录格式为“时间-SQL表达式”的日志,可使用正则表达式r进行提取、过滤,r如式(1)所示。
r=(?P〈time〉\d{4}-\d{2}-\d{2}\d{2}:\d{2}:\d{2}).
*?(?P〈sql〉(INSERT\UPDATE\DELETE). +?;)(1)
算法1 日志预处理方法
输入:卷烟物流信息系统数据库运行日志L,正则表达式r。
输出:事务集合J。
for each line in L do // 逐行遍历原始日志L
匹配每行日志line中的SQL表达式;
sql_exp←match(r,line);
if sql_exp is not null then
add sql_exp to J;
end
end
1.2 数据关系解析
卷烟物流自动化作业过程中的数据关系主要体现在插入某些查询结果到相应的数据表中,或根据某些查询结果进行数据的更新,该过程通过执行经过复杂组合的INSERT(或UPDATE)与SELECT的表达式实现,如图3所示的SQL表达式。因此在完成日志预处理后,需要对日志中的每条事务进行数据关系解析。当某一批次卷烟将要从一个仓库运输到另一仓库时,会首先下发一个运输作业(job),随后由运输方根据作业进行承运,上述表达式描述了当运输方承运时,作业数据、承运数据到运输过程数据的数据流转关系。其中,ProductCSN为卷烟批次号,Origin为发运地,destination为目的地,VehicleID为车牌号,DriverID为驾驶员ID。如图4所示,使用关系解析提取SQL表达式中所蕴涵的数据关系的主要流程为:a)将输入的SQL表达式转换为关键字(token)流;b)根据语法规则,遍历关键字集合将其转换为抽象语法树结构(abstract syntax tree,AST);c)遍历抽象语法树识别出定义的数据节点,提取数据节点之间的依赖关系。
在图4中,对于事务集合中的任一SQL表达式Q,首先对其按照字符进行切分,使得Q′={c1,c2,c3,…,ci},其中c为SQL表达式中的组成字符。根据SQL表达式的词法规则构造一个确定的有穷自动机(deterministic finite automata,DFA)[19]D来计算关键字集合:
M=D(S,Q′,δ,c0)(2)
其中:S为根据SQL表达式的词法规则定义的有穷状态集;δ为DFA中的状态转换函数,可根据当前状态和新输入的字符返回新的状态。通过D依次讀入字符列表Q′,并根据转移函数δ进行状态转移,当D达到了一个接收状态,则认为识别出了一个关键字。通过上述方法可将Q′转换为关键字集合M,其中M={(T1,C1),(T2,C2),…,(Tj,Cj)},C为SQL表达式中的关键字,T为关键字的类型。SQL表达式词法分析的伪代码如算法2所示。
算法2 SQL表达式词法分析方法
输入:SQL表达式Q的字符集合Q′,初始状态q0,有穷状态集合S。
输出:SQL表达式Q的关键字集合M。
initialization:M←{},current_token←"",current_state←q0;
for each char in Q′ do // 逐行遍历Q′中的每个字符
if current_state in S then
add (current_state, current_token) to M;
current_token←"";
current_state←q0;
end
current_token=current_token+char;
current_state=δ (current_state, char);
end
获取到关键字集合M后,根据M进行抽象语法树的构建,将从抽象语法树中获取SQL表达式中蕴涵的数据关系。如算法3所示,构建抽象语法树的主要流程如下:a)获取SQL的上下文无关文法规则和对应的语法分析表,并初始化一个语法分析栈;b)依次读取M中的关键字;c)在进行语法分析时,根据语法分析栈栈顶元素和当前读取到的关键字进行移进-规约操作[20];d)重复步骤c)直至读取完关键字集合M中的所有元素。
算法3 SQL表达式抽象语法树生成方法。
输入:关键字集合M,语法分析表action。
输出:SQL表达式Q的抽象语法树T。
initialization:stack←[ 0 ],tree_stack←empty stack;
while true do
state←stack 顶部元素;
symbol=M[i][0];
action=action[state][symbol];
if action. type is "shift" then // 移进操作
shift (symbol, action. value, stack);
push Node(M [i] ) from tree_stack;
else if action.type is "reduce" then // 规约操作
rnode=reduce(action. value, tree_stack, stack);
push rnode from tree_stack;
else if action.type is "accept" then
T=tree_stack[0]
break while
end
end
其中,shift()为移进操作,用于将下一输入符号加入到语法分析栈中;reduce()为规约操作,用于将栈中符合某个文法规则的一段内容替换为该文法规则的左部。在规约操作过程中:若替换的文法规则左部是终结符号,则直接返回该符号对应的节点;若替换的文法规则左部是非终结符号,则将该符号作为一个父节点,将文法规则右部的符号作为其子节点,依次加入到语法树中,随后返回该符号对应的节点。
在获取到SQL表达式Q的抽象语法树T后,删除抽象语法树的符号节点(如括号节点、句号节点等),将符号节点的子节点与其父节点直接相连。SQL表达式Q中涉及的数据节点分布在抽象语法树T的叶子节点上,子节点所对应的父节点蕴涵具体的语义关系。自上而下递归地遍历抽象语法树T,根据节点信息及位置获取SQL表达式中数据之间的关系。为更好地表示数据关系,使用图的方式进行关系的表示,首先将图中数据节点定义为node:〈ID,name,type,data〉。一个数据节点由四部分组成,其中,ID为数据节点的标识符;name为数据节点的名称;type为数据节点的类型,分为具体数据、读出数据、操作;data为数据节点所拥有的属性数据。使用三元组的方式描述数据节点之间的关系,三元组的第一个元素是头节点,第二个元素是尾节点,第三个元素是关系名称,三元组定义为R:〈Node1,Node2,Relation〉。
结合上述定义,当遍历到父节点类型为“INSERT”的树,新创建一个数据节点,并将数据节点的name初始化为树中“INTO”的子节点对应的表名,将数据节点的type初始化为“具体数据”,建立新数据节点与“VALUES”中所有子节点之间的关系,如图5所示。将“VALUES”中所有子节点的实际值以数据字典的形式初始化为数据节点的data,返回新创建的数据节点。
当遍历到父节点类型为“SELECT”的树中,获取“WHERE”所对应子节点描述的过滤规则,根据数据节点的属性进行搜索,匹配受影响的数据节点,建立“SELECT”所对应的读出数据与“FROM”所对应的具体数据之间的关系及具体数据之间的连接关系,如图6所示。返回读出数据节点列表。
当遍历到父节点类型为“UPDATE”或“DELETE”的抽象语法树时,通过“WHERE”所对应子节点描述的过滤规则,根据数据节点的属性进行搜索,匹配到影响的数据节点,对受影响的数据进行添加、修改或删除。
1.3 数据对齐
通过上述数据关系解析方法,可为卷烟物流自动化作业过程中涉及的每一条数据生成一个数据节点,并从所执行的SQL表达式中解析数据节点之间的关系。在完成对事务集合J中所有SQL表达式的解析后,对于分散在不同事务中的相同数据节点,通过数据对齐可将它们进行合并,从而将不同事务中解析出的数据关系进行关联,获得更全面和准确的数据血缘结果。数据对齐面向的对象的type为“具体数据”的数据节点,如算法4所示的伪代码,数据对齐的主要流程为:a)根据名称name对数据节点进行分类,对于其中的任一类别B,B类数据节点所构成的数据集合为set(B);b)基于信息熵算法[21],依次计算其set(B)中的每一项属性元素对区分数据的影响程度;c)选择影响程度最大的一个或若干个的属性作为B类数据节点关键属性;d)在此类数据中,根据关键属性的值进行数据节点的对齐,将关键属性值相同的数据节点进行关联、合并。其中,信息熵的计算方法如下所示:
其中:n是数据集合set(B)中属性的总个数;pi为set(B)中与属性i相同的数据所占所有数据的比例。结合上述所计算的信息熵,可以计算属性i对set(B)的影响程度,具体公式如下:
其中:Vbi为set(B)中属性i的取值集合,set(B)v为set(B)中属性i取值为v的子集。通过遍历所有属性并计算影响,可以确定哪些属性是关键属性,从而对B类数据节点中关键属性相同的值进行对齐、合并。
算法4 数据对齐
输入:对齐前的数据节点集合Z。
输出:对齐后的数据节点集合Z。
initialization: attdict←{}; // 初始化存储各类别的字典
选择Z中type为“具体数据”的节点,记为Z(type="具体数据");
根据节点的name,对Z(type="具体数据")进行分组,记为GR;
for each G in GR do // 确定关键属性
计算G中每一项属性的影响程度,获取影响程度最大的属性i;
attdict[G]=i; // 记录G的关键属性为i
end
for each G in GR do // 根据关键属性进行数据对齐
datadict={ }; // 初始化存储相同数据节点的字典
I=attdict [G]; // 获取关键属性
for each node in set(G) do // 遍历G中的每一个节点
if node [i] in datadict then
node_a=datadict[node[i]];
merge node and node_a;
else
datadict [node [i] ]=node;
end
end
end
1.4 血缘存储
在完成数据血缘的构建后,数据血缘将以有向图的形式存储在图数据库中。在图数据库中对卷烟物流自动化作业过程中数据节点与数据节点的关系进行描述,可直接使用图查询的方法快速定位到相关数据,也可以将其作为数据源服务于其他的应用系统中。以图数据库Neo4j为例,其支持多平台部署、支持事务的原子性、隔离性、一致性和持久性[22],并且有一套可视化系统,可以方便地对图数据进行查看分析,Neo4j在多个重要场景上已得到广泛应用。利用Neo4j图数据库存储并对数据血缘关系进行可视化展示,对批次号为“N20081811”的卷烟,在进入“WM071”仓库的过程时查询到的数据血缘,总体的数据流转关系如图7所示,其中,不同颜色的数据节点表示不同名称的数据,如浅蓝色节点表示操作数据、褐色节点表示具体数据中的人员数据、橘色节点为卷烟货物数据(参见电子版),数据节点之间所连接的边代表数据节点之间的关系。各个数据节点也蕴涵着相关的属性信息,选择这一批次卷烟节点,可查看该数据节点中的属性数据,如图8所示。
2 审计工具实现
本文使用Neo4j图数据库提供的一种名为Cypher[23]的查询语言[24]进行数据审计,能够在不编写图形结构的遍历代码的情况下实现高效准确的图查询。将所构建的数据血缘关系存储进Neo4j后,可根据查询条件使用Cypher定位到具体的数据节点,并查询到该节点的全链路数据关系,实现对数据进行聚合、计算、分组、连接、排序等操作。使用Cypher可满足大部分卷烟物流过程中的数据审计需求,对于部分Cypher无法描述的需求,也可基于Cypher返回的三元组图结构编写相关图算法实现。将数据审计问题转换为图搜索问题,使得处理数据审计需求的方法具有普适性,能够提高数据审计工作的效率。
同时,基于Cypher实现了一个面向审计人员的审计工具,通过捕获日志内容自动进行数据对齐,实现血缘的及时更新。数据审计人员可通过搜索关键属性定位到具体数据节点,并通过审计工具对数据的上游数据进行溯源或对下游数據进行追踪,通过工具对数据的流转、来源进行清晰的分析,极大提高数据审计效率及对数据的管控能力,审计工具添加数据源、对数据进行审计的快照如图9、10所示。审计工具基于RESTFul风格[25]的API设计,前后端之间通过接口进行交互,可基于接口将能力嵌入至现有卷烟物流信息化系统中,实现部分环节的自动化审计或扩展更多的自定义功能。
3 实验结果与分析
为了证明本文方法的先进性和科学性,将本文方法与现有主流方案进行对比分析。在数据血缘构建方法上,选取近年来不同类型的先进方法进行对比实验,并在所构建数据血缘图谱的完整准确性、构建过程中的时间/空间成本这两个维度上进行对比分析。在面向复杂数据审计查询效率上,将本文提出的基于数据血缘的图查询方法与现有主流的SQL查询方法、基于SQL索引查询方法进行对比实验,评估本文方法的可行性和有效性。
3.1 实验环境及数据
3.1.1 实验环境
本文基于Python实现所提出的面向卷烟物流数据审计需求的数据血缘构建方法,基于Cypher实现卷烟物流过程中的相关数据审计功能,本次实验评估使用Python 3.8、Neo4j、MySQL 8.0、Spark 3.2等软件完成。实验运行环境为:一台搭载Windows 10系统,拥有AMD锐龙7-4800H处理器(8核心16线程,最高4.2 GHz)的服务器,并分配48 GB RAM(DDR4)。
3.1.2 实验数据
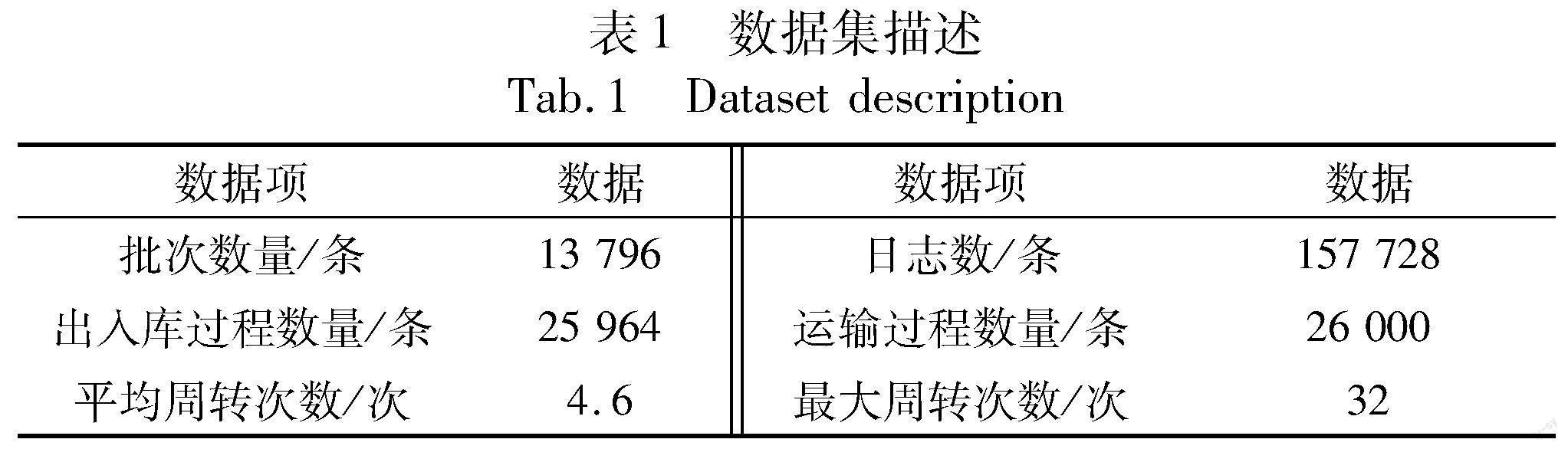
采用某省卷烟物流信息系统中的实际运行数据进行实验分析,选取已有完整记录的从2019年9月—2022年6月共13 796个卷烟批次货物出仓、运输、出入库过程中涉及的数据进行分析,各数据项详情如表1所示。
3.2 数据血缘完整准确性实验
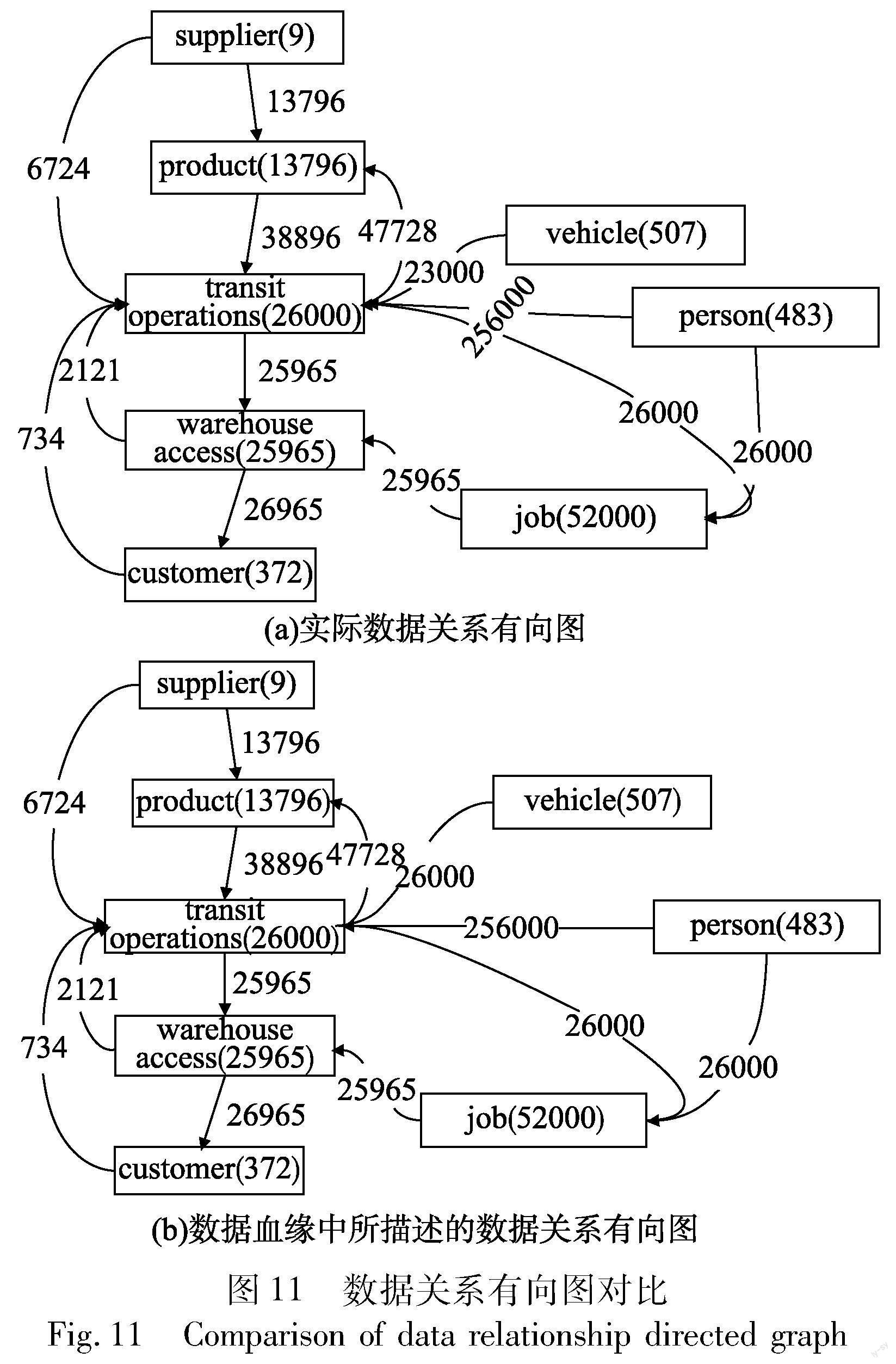
为验证所构建数据血缘的完整准确性,将上述13 796个批次的卷烟货物在物流流转过程中的数据关系转换为有向图,与这13 796个批次所对应的数据血缘图进行比较,分别比较两个有向图中的节点集和边集是否相等。
图11展示了数据血缘完整准确性实验的实验结果,其中,矩形代表数据节点,矩形之間的连接代表数据节点之间的关系,分别比较两个有向图的实体集和边集合的相似情况,所构建的数据血缘图与实际体现数据关系的有向图在节点集、边集上均相等。表明本文提出的数据血缘构建方法可以完整、准确地从数据事务日志中挖掘数据关系,基于数据关系在数据粒度上完成数据血缘的构建,完整、准确地呈现单条数据的全链路数据血缘。
3.3 数据血缘构建方法对比实验
为探究使用本文方法在构建数据血缘的时间及空间成本,根据上述13 796个批次货物在流转过程中所对应的155 728条事务日志,使用本文方法进行数据血缘的构建,判断挖掘事务日志、提取数据关系并分析数据血缘构建所需的时间及内存。
选取近年来的先进方法作为基线方法,与本文的数据血缘构建方法进行对比:
a)SQLFlow。SQLFlow(https://sqlflow.gudusoft.com)是现有数据血缘提取的一款主流工具,通过上传SQL脚本,自动分析SQL里的数据对象,包括database、schema、table、view、column等,进而分析这些数据对象之间的依赖关系。
b)ParseDriver[26]。通过ParseDriver 实现 SQL 解析,并通过深度优先搜索算法获取SQL解析结果中的数据关系以构建数据血缘。
c)SAC[27]。一种在Spark中解析Spark SQL数据血缘的方法,采用Spark SQL监听器来监视Spark SQL DDL或Spark DML的状态,并基于此使用Spark SQL解析器进行数据血缘的构建。
为提高实验结果的准确性,分别以每百条数据事务为单位及以批次货物物流流转过程中所涉及数据事务为单位,按顺序记录每次结果所消耗的时间、内存相关信息,最终取平均值。实验结果如表2所示。
本文方法的时间复杂度为O(n2),主要在数据对齐阶段较为耗时,空间复杂度为O(m),主要在数据关系解析阶段需要维护有穷状态集、语法分析表、语法分析栈。如表2所示的实验结果可以看出,因为本文方法避免了对事务日志解析时多余的解析部分,提高了解析效率,相比SQLFlow、ParseDriver、SAC等方法在时间、空间上具有明显优势,能够在较小的空间成本上高效率地实现卷烟物流过程中各数据全链路数据血缘的构建,更能符合在复杂数据审计需求的数据审计场景下对时间、空间代价的要求。
为进一步验证本文的数据对齐方法在对齐前后不同数据事务的数据节点时的准确性,引入对齐精确率作为评价指标,使用三元组集合表示数据血缘图谱中的关系,实验结果如图12所示。对齐精确率(precision)为对齐正确的关系占所有需要对齐关系的比例。
从图12可以看出,本文方法可准确有效地确认关键数据,并根据关键数据进行数据血缘的对齐,解决了其他方法无法关联对齐距离远的数据事务的问题。相比SAC,本文方法无须侵入至系统内部,并支持离线、分布式运行。结合完整准确性实验、时间空间成本分析、对齐准确性的实验结果,进一步证明了本文方法的可行性与先进性。
3.4 审计效率对比实验
为进一步探究基于本文所构建的数据血缘进行数据审计的方法相比现有进行数据审计的方法在效率上的提升规模,针对上述13 796个批次货物在物流流转过程中所产生的数据,在实际使用场景中选择两个有代表性的数据审计任务进行实验:a)查询某一批次卷烟货物的全链路物流流转过程所涉及的所有数据;b)查询某个入库过程中入库的所有卷烟货物的来源信息。
对于任务a)b),使用现有基于SQL查询的方法需考虑多个表的连接、嵌套及组合关系,如对某一批次的货物,若想查询其在物流过程中所涉及的所有数据,首先需在供应商表中查询该批次货物的来源信息,并在装车、运输过程表中按顺序查询该批次货物经历的所有装车、运输过程,并根据运输过程在出入库过程表中查询对应的出入库过程,分别在对应人员、交通工具、作业等表中查询所涉及的相关作业和人员信息。同样地,如要查询某个入库过程入库的所有卷烟货物的来源信息,需先在运输表中查询此次入库过程中对应的运输过程,根据运输过程查询上一次所在的仓库,并根据货物批次号逐级查询对应的运输过程和出入库过程,直至获得所有货物的来源信息。
使用基于数据血缘进行数据审计可直接将数据审计转换成图搜索问题,对某一批次的货物,若想查询其在物流过程中所涉及的所有数据,首先通过搜索定位到该货物对应的数据节点,再通过前向图搜索获得该数据节点的全链路数据关系,根据全链路数据关系的顺序及数据节点的类型获得物流流转过程所涉及的全部数据。若要查询某个入库过程中入库的所有卷烟货物的来源信息,也可通过定位到相关入库过程的数据节点并通过反向图搜索筛选反向链路中与相应货物有关的数据。
针对任务a)b),分别使用基于SQL查询的方法、基于SQL查询(索引)的方法、基于数据血缘查询的方法来实现,实验时取平均所需时间作为实验结果,结果如图13所示。其中在建立索引时,根据任务中涉及表的主键分别建立索引。
根据图13的实验结果可以发现,基于SQL查询进行数据审计的耗时较长、效率较低,主要原因是关系型数据库中往往存在基于外键约束的两个表或多个表互相连接、引用的情况,在通过外键进行数据搜索、匹配工作时,往往需要消耗较多的时间在各表中查询数据,无法及时响应相应的需求,随着数据量的增大,在各表中进行连接、搜索的耗时也会急剧增加。而且卷烟物流过程中的数据追溯、审计需求往往存在多变性、广泛性的特点,无法面面俱到地提前建立相关索引,影响了整体的物流审计效率。本文提出的基于数据血缘进行数据审计的方法拥有较高的效率,相比现有基于SQL查询进行数据审计的方法,可以在保证准确性的前提下以更短的时间获得结果。且现有基于SQL查询的数据审计方法需要审计人员对数据的底层存储及数据之间的关系有广泛的了解,有较高的技术要求,不具有普适性。基于数据血缘的数据审计方法将不同的数据审计问题转换为图查询问题,审计人员能够通过Neo4j提供的Cypher進行图查询,从而快速、高效地获得相应结果,提高审计效率。
4 结束语
为提高卷烟物流过程中数据审计的效率,本文提出了一种面向复杂数据审计需求的数据血缘构建方法,包括数据预处理、数据关系解析、数据对齐、血缘存储,并基于数据血缘实现了数据审计工具。采用真实数据,从所构建数据血缘的完整准确性、所需的时间和空间成本以及在数据审计时的效率提升规模对本文方法进行了验证。实验结果表明,本文方法可在不影响原有物流信息系统使用的情况下,完整、准确地进行卷烟物流过程中数据血缘的构建,且相比现有基于SQL查询进行数据审计的方法,基于数据血缘进行数据审计可极大地提升数据审计的效率,加强审计人员对卷烟物流过程中的数据管控能力。未来将进一步挖掘更多场景下的数据关系,实现多源数据血缘的融合,以提高企业对数据的管控能力。同时,可将本文方法应用在更多特定领域的数据血缘的构建,如智能制造过程中等。
参考文献:
[1]孟博,庞磊.烟草商业企业卷烟物流设备管理初探[J].中国烟草学报,2018,24(4):86-90.(Meng Bo, Pang Lei. Preliminary study on management of cigarette logistics equipment in tobacco commercial enterprise[J].Acta Tabacaria Sinica,2018,24(4):86-90.)
[2]周军,赵长友,刘战强,等.烟丝原料立体仓库堆垛机出入库作业优化研究[J].计算机集成制造系统,2009,15(4):772-776.(Zhou Jun, Zhao Changyou, Liu Zhanqiang, et al. Operation optimization of storage and retrieval for stackers in AS/RS of raw tobacco material[J].Computer Integrated Manufacturing Systems,2009,15(4):772-776.)
[3]陈寅.贵阳烟草物流中心跨区域物流信息系统的构建研究[D].贵阳:贵州大学,2020.(Chen Yin. Research on the construction of cross-regional logistics information system of Guiyang Tobacco Logistics Center[D].Guiyang:Guizhou University,2020.)
[4]李奇颖,赵阳,阿孜古丽·吾拉木,等.卷烟制造工业互联网平台建设与应用[J].计算机集成制造系统,2020,26(12):3427-3434.(Li Qiying, Zhao Yang, Aziguli Wulamu, et al. Construction and application of industrial Internet platform in cigarette manufactu-ring[J].Computer Integrated Manufacturing Systems,2020,26(12):3427-3434.)
[5]方新丽.数据库中的SQL查询语句在计算机审计中的应用[J].中国科技信息,2008(14):113-114.(Fang Xinli. Application of SQL query statements in database in computer auditing[J].China Science and Technology Information,2008(14):113-114.)
[6]马承希.SQL之异曲同工审计查询技巧[J].理财:审计版,2020(4):22-23.(Ma Chengxi. SQLs similar audit query techniques[J].Financial Management,2020(4):22-23.)
[7]胡杰.浅析ERP与OA系统合同和审计业务的数据整合[J].当代石油石化,2012,20(12):26-32.(Hu Jie. A simple analysis of the data integration for ERP and OA system contract and auditing business[J].Petroleum & Petrochemical Today,2012,20(12):26-32.)
[8]卢利娟,余从容,梁东贵,等.基于并行随机森林的审计大数据疑点预测[J].计算机与数字工程,2019,47(1):174-179.(Lu Lijuan, Yu Congrong, Liang Donggui, et al. Auditing doubts prediction based on parallel random forest algorithm under audit big data[J].Computer & Digital Engineering,2019,47(1):174-179.)
[9]高明,金澈清,王晓玲,等.数据世系管理技术研究综述[J].计算机学报,2010,33(3):373-389.(Gao Ming, Jin Cheqing, Wang Xiaoling, et al. Survey on management of data provenance[J].Chinese Journal of Computers,2010,33(3):373-389.)
[10]Gao Yuanzhao, Chen Xinyuan, Du Xuehui. A big data provenance model for data security supervision based on PROV-DM model[J].IEEE Access,2020,8:38742-38752.
[11]张旭.大数据技术在金融统计分析中的应用初探[J].当代经济,2021(7):26-29.(Zhang Xu. Application of big data technology in financial statistical analysis[J].Contemporary Economics,2021(7):26-29.)
[12]Porkodi S, Kesavaraha D. Secure data provenance in Internet of Things using hybrid attribute based crypt technique[J].Wireless Personal Communications,2021,118(4):2821-2842.
[13]Loeb S E, Shamoo A E. Data audit: its place in auditing[J].Accountability in Research,1989,1(1):23-32.
[14]Ikeda R, Widom J. Data lineage:a survey[EB/OL].(2019-01-10).http://adrem.uantwerpen.be/sites/default/files/lin_final.pdf.
[15]Bates A, Tian D, Butler K R B, et al. Trustworthy whole-system provenance for the Linux kernel[C]//Proc of the 24th USENIX Security Symposium.Berkeley,CA:USENIX Association,2015:319-334.
[16]Alkhaldi A,Gupta I, Raghavan V, et al. Leveraging metadata in NoSQL storage systems[C]//Proc of the 8th IEEE International Confe-rence on Cloud Computing.Washington DC:IEEE Computer Society,2015:57-64.
[17]Chacko A M, Fairooz M, Kumar S D M. Provenance-aware NoSQL databases[C]//Proc of the 4th International Symposium on Security in Computing and Communication.Singapore:Springer,2016:152-160.
[18]馬张迪.基于Spark的元数据管理系统的设计与实现[D].成都:电子科技大学,2022.(Ma Zhangdi. Design and implementation of a Spark-based metadata management system[D].Chengdu:University of Electronic Science & Technology of China,2022.)
[19]Hopcroft J E, Motwani R, Ullman J D. Introduction to automata theory, languages, and computation, 2nd edition[J].ACM SIGACT News,2001,32(1):60-65.
[20]Knuth D E. On the translation of languages from left to right[J].Information and Control,1965,8(6):607-639.
[21]Peng Hanchuan, Long Fuhui, Ding C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2005,27(8):1226-1238.
[22]李雪.一种基于Neo4j图数据库的模糊查询研究与实现[J].计算机技术与发展,2018,28(11):16-21.(Li Xue. Research and implementation of a fuzzy query based on Neo4j graph database[J].Computer Technology and Development,2018,28(11):16-21.)
[23]Francis N, Green A, Guagliardo P, et al. Cypher: an evolving query language for property graphs[C]//Proc of International Conference on Management of Data.New York:ACM Press,2018:1433-1445.
[24]Neo4j, Inc. Neo4j Cypher manual[EB/OL].(2022-01-24)[2023-02-14].https://neo4j.com/docs/cypher-manual/current/introduction/.
[25]Rodriguez A. RESTFul Web services: the basics[EB/OL].(2018-11-06).https://cs.calvin.edu/courses/cs/262/kvlinden/references/rodriguez-restfulWS.pdf.
[26]滕召嘉.基于血緣关系的元数据管理系统的设计与实现[D].北京:北京交通大学,2022.(Teng Zhaojia. Design and implementation of a metadata management system based on lineage[D].Beijing:Beijing Jiaotong University,2022.)
[27]Tang Mingjie, Shao Saisai, Yang Weiqing, et al. SAC:a system for big data lineage tracking[C]//Proc of the 35th IEEE International Conference on Data Engineering.Piscataway,NJ:IEEE Press,2019:1964-1967.
