基于时序感知DAG的多模态对话情绪识别模型
2024-02-18沈旭东黄贤英邹世豪
沈旭东 黄贤英 邹世豪
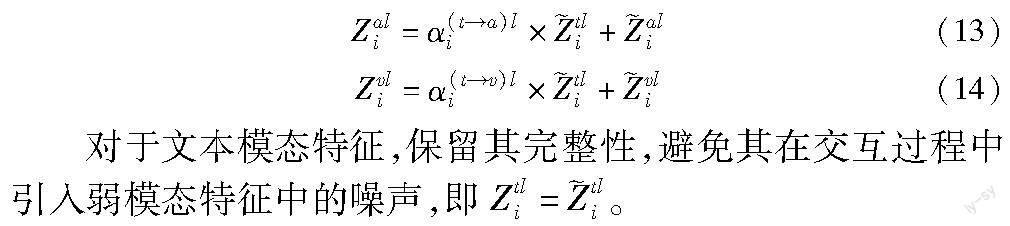

摘 要:针对现有对话情绪识别方法中对时序信息、话语者信息、多模态信息利用不充分的问题,提出了一个时序信息感知的多模态有向无环图模型(MTDAG)。其中所设计的时序感知单元能按照时间顺序优化话语权重设置,并收集历史情绪线索,实现基于近因效应下对时序信息和历史信息更有效的利用;设计的上下文和话语者信息融合模块,通过提取上下文语境和话语者自语境的深度联合信息实现对话语者信息的充分利用;通过设置DAG(directed acyclic graph)子图捕获多模态信息并约束交互方向的方式,在减少噪声引入的基础上充分利用多模态信息。在两个基准数据集IEMOCAP和MELD的大量实验表明该模型具有较好的情绪识别效果。
关键词:对话情绪识别; 有向无环图; 近因效应; 特征提取; 多模态交互
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-008-0051-08
doi:10.19734/j.issn.1001-3695.2023.04.0183
Multi-modal temporal-aware DAG for emotion recognition in conversation
Abstract:Aiming at the issue of insufficient utilization of temporal information, speaker information, and multi-modal information in existing conversational emotion recognition methods, this paper proposed a multi-modal temporal-aware DAG model (MTDAG). The designed temporal-aware unit optimized the discourse weight setting in chronological order and collected historical emotional cues to achieve more effective utilization of temporal and historical information based on recency effect. The context and speaker information fusion module achieved the full utilization of discourse information by extracting the deep joint information of contextual context and speaker self-context. By setting the DAG subgraphs to capture multi-modal information and constrain the interaction direction, the model achieved full utilization of multi-modal information while reducing the introduction of noise. Extensive experiments conducted on two benchmark datasets, IEMOCAP and MELD, demonstrate that the model exhibits excellent performance in emotion recognition.
Key words:emotion recognition in conversation(ERC); directed acyclic graph; recency effect; feature extraction; multi-modal interaction
0 引言
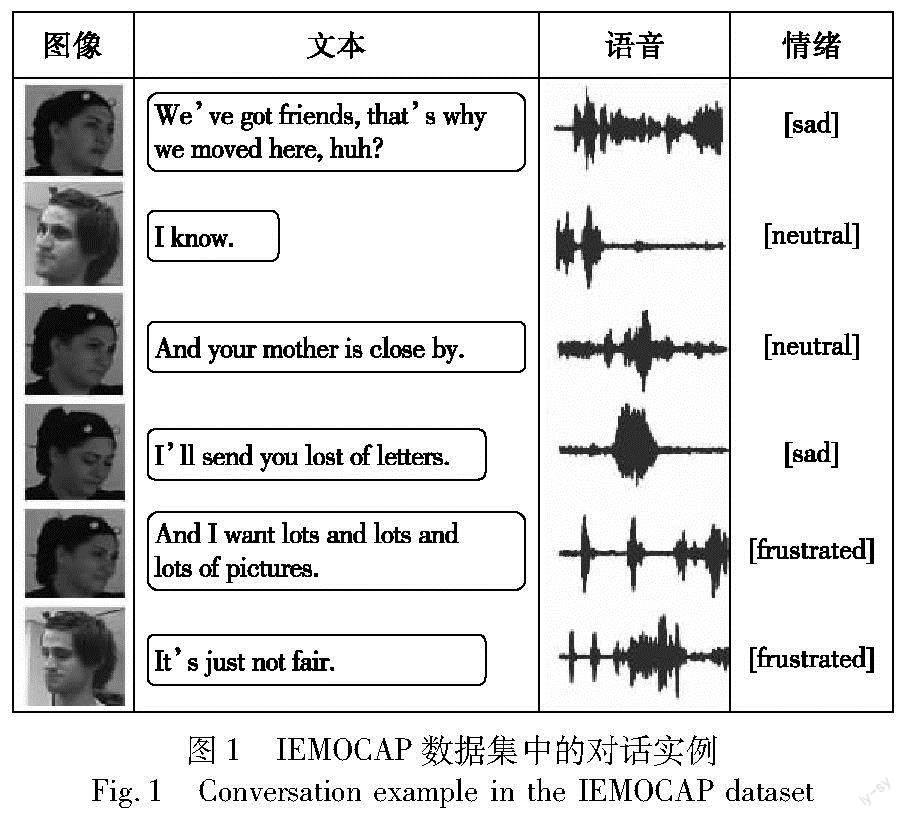
对话情绪识别(ERC)的主要目标是正确识别每个话语者在对话过程中的话语所表达的情绪。在对话过程中,存在着文本、语音和图像三种模态的信息,多模态ERC就是基于这三种模态的信息,通过模型对话语进行情绪识别,对话实例如图1所示。由于话语者情绪倾向的研究在消费购物、社交媒体中的意见挖掘[1]和人机对话交互等领域有着巨大的应用价值,所以该任务越来越受到研究者的关注。由于ERC中可用的信息只有三种模态的信息以及话语者和话语的对应关系,所以研究者們不得不从上下文时序关系、话语者自身特点、模态交互融合等方面获得更有用的信息。尽管现有研究使用了多种方法挖掘这些信息,如以时间序列的形式建模对话[2~4]、对话语者单独建模[5,6]、构建模态融合图[6,7]等,但依旧存在一些问题:a)利用时序信息时没有考虑到对话中的近因效应(新近获得的信息比原来获得的信息影响更大);b)话语者细粒度信息的挖掘还不够充分;c)多模态信息的利用还不充分。
对于问题a)来说,基于心理学[8,9]的研究,由于近因效应的存在,对话开始时的话语有效信息较少,对于每个话语的情绪识别,更具有价值的是其临近的话语信息,所以需要对话语进行权重约束以限制先前话语中的冗余信息过多流向当前。历史话语为当前话语的情绪识别提供了重要的情绪线索,但这些情绪线索的重要性同样会根据时序而有所差别,因此可以采用基于近因效应的方法提取历史话语中的情绪线索,从而更有效地利用时序信息。
针对问题b),研究[6,7]表明,话语者信息中含有大量情绪线索,对话语者信息进行更细粒度的利用可以提高情绪识别的效果。通过分析数据注意到,同一个话语者的情绪具有一定的惯性,也就是说,话语者倾向于保持自己的情绪状态,但当被其他话语者所影响时,其情绪才可能会产生变化,例如,一个对话开始时处于愉快状态的话语者可能会在接下来的对话中保持愉快,而一个开始时愤怒的话语者可能会继续表达愤怒。这种情绪惯性在话语者自语境中体现,并且会受上下文语境中的情绪线索影响,因此可以分别提取话语者自语境和上下文语境中的情绪线索并加以融合,从而实现更细致的话语者信息挖掘利用。
对于问题c),则需要考虑在ERC中多模态特征的特点。Zou等人[10]认为不同模态具有不同的表征能力,在三种模态的信息中,文本模态的表征能力最强,其他两个模态的表征能力则较弱,此外用强表征能力的模态去增强弱表征能力的模态可以弥补语义鸿沟,从而有效缓解模态融合时发生表征衰减的问题。Shen等人[11]使用有向无环图(directed acyclic graph,DAG)的结构去建模对话上下文,这使得模型较好地利用了对话的特点,既能获取对话中的时序信息,又能同时收集当前话语附近的信息,在当时取得了最好的实验效果,这种优点使得DAG同样可以用来建模多模态信息。因此,可以在用DAG捕获多模态信息的基础上对模态交互的方向进行约束以充分利用多模态信息。
针对上述问题,提出了一个时序信息感知的多模态DAG模型(multi-modal temporal-aware DAG,MTDAG),其包括如下的改进:设计的时序感知单元通过时间顺序优化权重设置,并收集历史情感线索,实现基于近因效应下对时序信息和历史信息更有效的利用;设计的上下文和话语者信息融合模块,提取了上下文语境的情绪线索和话语者自语境的情绪惯性线索,并将两部分线索深度融合以增强文本特征,实现了对话语者细粒度信息更充分地挖掘利用;通过设置DAG子图的方式将多模态信息引入模型,同时在模态交互过程中对信息的流向进行约束,以减少交互产生的噪声,从而充分利用多模态信息。
总的来说,本文的贡献如下:
a)提出了一种基于近因效应,以时间为监督信号的话语特征优化方法和历史情绪线索收集方法,以充分利用对话时序信息。
b)注意到话语者的情绪惯性,并在文本模态中提出多粒度特征融合的上下文和话语者信息融合模块,通过提取上下文语境级别和话语者自语境级别的深层次联合信息来利用这种情绪惯性,以充分利用话语者信息。
c)在多模态ERC任务中使用DAG对三种模态的信息建模进行情绪识别,并在其中设置模态交互约束条件以减少交互产生的噪声,实现多模态特征更有效的利用。
d)提出模型在IEMOCAP和MELD两个数据集上都取得了优于其他模型的效果,证明了其优越性和有效性。
1 相关工作
1.1 基于文本的ERC
近几年来,ERC受到了许多关注。DialogueRNN[4]使用多个RNN对对话进行动态建模。DialogueGCN[12]构建了同时考虑说话者和对话顺序信息的图,使用图网络进行话语者的self-和inter-之间依赖关系的建模。COSMIC[13]在DialogueRNN的基础上,通过从ATOMIC引入外部的常识信息来提高模型的表现。 DialogueCRN[14]通过构建推理模块模拟人类推理的过程,从而判断情绪标签。HCL-ERC[15]首次将课程学习引入对话情绪识别领域,通过设置两个级别的课程来划分数据,进而在上述提及的部分模型基础上,性能都得到了提升。文献[16]将对话主题信息和行为信息融入对话文本并通过图神经网络建模对话上下文。HSGCF[17]利用层次结构来提取情感判别特征,并使用五个图卷积层分层连接来建立一个特征提取器。但上述基于文本的方法并未充分使用其他模态可供利用的信息,导致效果不够理想。
1.2 基于多模态的ERC
之前的大多研究工作仅将文本信息建模进行情绪判别,但音频和视频信息也能对情绪判别提供帮助。Poria等人[2]用基于LSTM的模型将提取到的三个模态的特征进行融合。ICON[3]和CMN[18]利用GRU和记忆网络进行情绪判别。Chen等人[19]提出了一种在单词层面进行多模态融合的方法。Sahay等人[20]提出用关系张量网络体系結构融合模态信息来预测情绪。Zaheh等人[21]提出记忆融合网络来融合多视图的信息。MMGCN[6]按模态内和模态间对话语的多模态信息构建图。MM-DFN[7]在此基础上设计了一种动态融合模块来融合多模态上下文信息。文献[22]构建了多模态特征学习和融合的图卷积网络,并以说话人在完整对话中的平均特征为一致性约束,使模型学习到更合理的话语特征。DIMMN[23]在注意力网络中设计了多视图层,使模型能够在动态的模态互动过程中挖掘不同群体之间的跨模态动态依赖关系。上述研究工作表明,使用多模态数据特征比使用单模态数据特征具有更好的性能和鲁棒性,这种优势在情绪识别任务中更为明显。
1.3 有向无环图
DAG因为独特的拓扑结构所带来的优异特性,经常被用于处理动态规划、导航中寻求最短路径、数据压缩等多种场景。大量基于DAG的深度学习模型此前也被相继提出,例如:Tree-LSTM[24]、DAG-RNN[25]、D-VAE[26]和DAGNN[27]。DAG-ERC[11]受到DAGNN的启发,将DAG模型用于对话情绪识别任务中,取得了较好的成果。然而,这些方法没有考虑到不同的话语按时间顺序对当前话语的情感识别有不同的贡献。
2 问题定义
给定一段对话U={u1,u2,…,uN},其中N表示对话中语句的数量。每个话语分别包含三个模态的信息,可以表示如下:
ui={uti,uai,uvi}(1)
其中:uti、uai、uvi分别表示第i个话语的文本模态信息、语音模态信息、图像模态信息。有话语者S={s1,s2,…,sM},其中M为话语者的数量,并且M≥2。在该任务中,话语ui由话语者sφ(ui)说出,其中φ表示话语者和话语之间的映射关系。另外有情绪标签Y={y1,y2,…,yk},其中k为情绪标签的数量。对话情绪识别的目标就是基于以上可用信息,正确预测每个话语的情绪标签。
3 MTDAG模型
提出的模型MTDAG被建模如下:首先将对话原始数据输入三个模态编码器以获得特征向量,对于文本特征将其输入上下文和话语者信息融合模块,获得具有上下文和话语者联合信息的增强文本特征,其他两个模态的特征通过双向LSTM进行特征提取,然后用三个模态的特征分别构建DAG子图进行交互,最后将得到的结果进行融合来预测情绪标签。模型的框架如图2所示。它包含模态编码层、特征提取层、带有时序感知单元的DAG交互层和情绪分类层四个关键部分,其中FC表示全连接层,CSFM表示所提出的上下文和话语者信息融合模块。值得注意的是,在DAG子图中设置了时序感知单元用于优化特征并收集历史情绪线索。
3.1 模态编码层
3.1.1 文本模态编码
为了获得更好的文本模态特征表示,使用大规模预训练语言模型RoBERTa-Large[28]来进行话语文本信息uti的编码提取。该模型的架构与BERT-Large[29]相同,RoBERTa在BERT的基础上,通过动态掩码修改预训练任务,在更多数据上使用更大的批次,对模型进行更长时间的训练等方面进行优化,从而实现了更强大的表征能力。除此以外,使用ERC数据集对预训练模型进行微调,以此获得更好的文本表征效果。最后获得每个话语都为1 024维的句子向量eti。
3.1.2 语音模态编码
根据Hazarika等人[3]的配置,使用OpenSmile[30]进行语音特征提取。使用IS13比较配置文件,该文件为每个话语视频提取了总共6 373个特征,通过使用全连接层将IEMOCAP的维度降低到1 582,MELD数据集的维度降到300。通过上述操作将语音信息uai转换为了特征向量eai。
3.1.3 图像模态编码
图像面部特征是通过使用DenseNet[31]在面部表情识别Plus(FER+)[32]语料库上预先训练提取得到的,通过DenseNet捕获话语者表情的变化,这对ERC来说是非常重要的信息。最终将图像信息uvi转换为342维的特征表示evi。
3.2 特征提取层
3.2.1 上下文和话语者信息融合模块
其中:Uλ指话语者sλ的所有话语集合;hpλ,j是话语者sλ的第j个话语者级别LSTM的隐藏层状态。
hti=attention(pti,cti,cti)(4)
3.2.2 语音和图像特征处理
对于语音和图像模态,采用上下文语境级别的LSTM进行线索的提取,计算如下:
3.3 带有时序感知单元的DAG交互层
根据Shen等人[11]的工作,建立了一个DAG网络,其中对于每个模态分别建立子图,用于捕获多模态信息,可以描述为Gδ=(Vδ,Eδ,Rδ),δ∈{t,a,v} 。在子图中,把对话中的语句所对应的特征作为节点。边(i,j,rij)∈Eδ表示句子ui到uj的某种关系rij。规定句子之间存在两种关系rij=(0,1)∈Rδ:值为0时说明两个句子是由不同的话语者说的,在模型图中为单向实线;1则为同一个人,体现为单向虚线。在所建立的DAG网络中,信息流动是单向的,即先前的话语信息可以传递到未来,但是未来的话语不能反向传递回从前,这也符合现实话语情境中过去说过的话不会受未来所影响这一实际情况。如果同一话语者在对话中所说相邻前后两个话语为ufront和urear,就定义其间的所有话语为后一个话语urear的局部信息,其间的所有节点称为urear的局部信息节点Adjδrear。除此以外,为了实现对话语时序信息和历史情绪线索利用得更有效,在三个子图中分别设置了时序感知单元。
3.3.1 DAG层
在DAG的每一层,从第一个话语到最后一个话语根据时序计算话语的隐藏状态。本文使用{hti}Ni=1、{hai}Ni=1、{hvi}Ni=1来初始化各子图第(0)层的节点。对于话语ui在第(l)层的节点特征,需要经过DAG层中同模态特征的聚合以及跨模态交互层中不同模态特征的交互后得到。
针对话语ui在第(l)层的節点特征hδli,先计算其在上一层的隐藏向量hδ(l-1)i和局部信息节点hδlj,j∈Adjδi的关系分数βδlij,然后根据关系分数聚合这些信息得到Xδli。
获取到聚合信息之后,使用能控制信息流向的GRU细胞来获得该节点在当前层的融合特征:
其中:GRUδlh和GRUδlX中输入的特征相同,输入的位置相反。
3.3.2 多模态交互
引入多模态信息可以增加模型识别情绪所需要的重要线索,但是由于不同模态语义鸿沟的存在,需要在引入信息的同时进行多模态交互以减少噪声。根据Zou等人[10]的研究,相比语音和图像模态,文本模态具有更强的特征表示能力,由此设置了模态交互约束条件,保证模态交互只存在于强表征能力模态(文本)与弱表征能力模态(语音、图像)之间,避免弱模态之间低效交互产生过多噪声。
对语音和图像子图中每个话语节点的特征,使用同一层文本子图中的特征进行交互增强。首先计算图像特征和语音特征与文本特征各自的相关分数,计算公式如下:
其中:Wil(·)为可训练参数;f(·)代表Leaky_ReLU函数;α(t→a)li和α(t→v)li分别代表第l层DAG子图中第i个文本节点特征与语音节点特征和图像节点特征的相关分数。
此时获得了三种模态的语义交互相关性,然后利用该相关分数计算交互后的语音和图像增强特征:
3.3.3 时序感知单元
上述的各模态特征表示仍旧是基于每个话语的权重是相等的,但事实上每个话语随时序应有不同的重要性。由此设计了时序感知单元,该模块主要有两个作用:a)以时间信息作为监督信号来进行差异化的话语权重设置;b)根据时序为每个话语提供历史情绪线索。如图4所示,其中∑R代表式(12)中提出的聚合函数,∑G代表门控机制。
具体来说,先为模态特征赋予初始权重ωi:
ωi=ω+(1-ω)×i/N(15)
δli=ωi×Zδli(16)
其中:权重衰减系数ω为设置的超参数;i为该话语在当前对话中的位置;N为当前对话中话语的个数。
为了收集时序历史情绪线索,设计了如下的聚合函数:
其中:μ为近因效应影响因子;i为话语的位置。μ小于1时体现出首因效应,这不符合进行对话时的直觉,因此μ通常大于1。当该话语为对话中的第一句时,其不存在历史信息,因此将该值置为0。
在结合这两部分信息时,使用了参数可学习的门控机制:
ε=σ(Wgate[Mδli‖Qδli])(19)
hδli=ε×Mδli+(1-ε)×Qδli(20)
其中:Wgate为可训练参数矩阵,σ为sigmoid函数。
3.4 情绪分类层
在情绪分类阶段先将单个模态各DAG层的特征表示进行拼接:
Hi=Hti‖Hai‖Hvi‖hti‖hai‖hvi(22)
然后将Hi输入全连接层进行情绪标签的预测:
使用标准交叉熵和L2正则化作为训练过程中的损失函数:
其中:N是对话的个数;c(i)是对话i中的话语数量;Pi,j是对话i中话语j的预测情绪标签的概率分布;yi,j是对话i中话语j的预测类别标签;η是L2正则化权重;θ是所有可训练参数的集合。使用随机梯度下降的Adam[33]优化器来训练网络模型。
4 实验设置
4.1 实施细节
超参数设置如下:在IEMOCAP中,权重衰减系数ω为0.7,近因效应影响因子μ设置为1.5,在MELD中ω设为0.85,μ为1.4。学习率为5E-4,L2正则化参数设置为5E-5,batch size设置为64,dropout设置为0.3,隐藏状态维度dh设置为300维,DAG层数n为3。每个训练和测试过程都在单个RTX 3090 GPU上完成。每个数据集都训练30个epoch,单个epoch平均耗时约10 s。实验结果数据都是基于测试集上5次随机运行的平均分数。所有的超参数都是通过基于测试性能的网格搜索来确定的。
4.2 数据集
在IEMOCAP[34]和MELD[35]两个基准数据集上对所提模型的有效性进行了评估。这两个数据集都是包含文本、语音、图像的多模态ERC数据集。对于数据集的划分是根据Hu等人[6]的配置所确定的。表1显示了两个数据集的数据划分情况。
IEMOCAP:每段对话都是来自两位演员根据剧本所作出的表演。IEMOCAP中一共有7 433个话语和151个对话。对话中的每个话语都带有六个类别的情绪标签,分别是happy、sad、neutral、angry、excited和frustrated。
MELD:包含从电视剧Friends中收集的多方对话视频数据,其中一共包括13 708个话语和1 433个对话。与IEMOCAP中只有两个话语者不同,MELD在一次对话中有三个或三个以上的话语者,对话中的每个话语都带有七个类别的情绪标签,分别是neutral、surprise、fear、sadness、joy、disgust和angry。
4.3 对照方法
a)BC-LSTM[2]:其通过双向LSTM网络对上下文语义信息进行编码,但是没有考虑话语者信息。
b)ICON[3]:利用两个GRU来建模话语者信息,使用额外全局的GRU跟踪整个对话中情绪状态的变化,利用多层记忆网络对全局情绪状态进行建模,但是ICON仍不能适应多个话语者的情景。
c)DialogueRNN[4]:其通过三种不同的GRU(全局GRU、话语者GRU和情绪GRU)对对话中的话语者和顺序信息进行建模,但是DialogueRNN在多模态领域并没有多大的改进。
d)DialogueGCN[12]:其将GCN应用于ERC,生成的特征可以集成丰富的信息。RGCN和GCN都是非谱域GCN模型,用于对图进行编码。
e)DialogueCRN[14]:其引入认知阶段,从感知阶段检索的上下文中提取和整合情绪线索。
f)MMGCN[6]:使用GCN来获取上下文信息,可以有效地弥补DialogueGCN中不能利用多模态依赖关系的缺点,还有效地利用话语者的信息进行对话情绪识别,但其存在较多冗余信息。
g)DAG-ERC[11]:利用DAG的结构进行建模,将话语都看成节点,依时序向后建图,但没有设置差异化的话语权重。
h)MM-DFN[7]:通过设计了新的基于图的动态融合模块来融合多模态上下文信息,以此充分理解多模态对话上下文来识别话语中的情绪。
i)HSGCF[17]:使用五个图卷积层分层连接,以此建立了一个情感特征提取器。
j)DIMMN[23]:在注意力网络中设计了多视图层,在动态的模态互动过程中挖掘不同群体之间的跨模态动态依赖关系。
5 结果与分析
5.1 与其他对照方法的比较
所提模型在IEMOCAP和MELD数据集上与其他基线模型进行了比较,实验结果如表2和图5所示。在带有“*”的基线结果使用开源代码重新运行。为了公平对比,使用本实验中处理的数据,在所有能够被重构的基线模型上进行实验,用于后面对比文本特征的效果,在表中如“+RoBERTa”所示。空缺处是因为该基线未开源,或是并未使用某评估指标。其他带有结果的基线从文献[7]中复制而来。由于发表于2023年的两篇工作未能开源,所以选择了MM-DFN来进行更细致的实验结果对比。
分析表2可以发现:
a)本文MTDAG在weighted accuracy和F1-score评分方面均优于所有的基线模型,证明了提出模型在多模态ERC上的有效性。
b)MTDAG在weighted accuracy和F1-score上均优于MM-DFN,这表明本文模型对对话中话语者信息的提取,比使用话语者信息的最先进基线模型有着更好的效果。
c)在单独情绪类别的比较中,MTDAG在IEMOCAP和MELD数据集都获得了所有类别的最佳性能,如圖5所示。在MELD中的情绪类别中,除了样本数量最多的neutral类别外,其余的情绪类别中都取得远比MM-DFN更好的效果。特别说明:MM-DFN报告了每个类别的F1得分,除了MELD上的两个情绪类别(即fear和disgust),由于训练样本的数量较少,其结果没有统计学意义,所以被合并到近似的情绪类别中。
5.2 消融实验
为了研究MTDAG中不同模块和模态选择的影响,对两个数据集进行了消融实验,考虑了以下设置。
a)w/o TaU:移除所使用的时序感知单元。
b)w/o CSFM:移除上下文和话语者信息融合模块。
c)A&V with MLP:针对语音和图像模态使用多层感知机(multi-layer perceptron,MLP)建模而非设置DAG子图的方式。
d)w/o interaction:移除模态间的交互过程。
e)T:只使用文本模态进行对话中的情绪预测。
f)A:只使用语音模态进行对话中的情绪预测。
g)V:只使用图像模态进行对话中的情绪预测。
表3显示了消融实验的结果,通过其中的数据可以得到:
a)移除时序感知单元会在两个数据集上降低较多的F1分数,并且在IEMOCAP中更明显,证明了对DAG进行时序权重约束和情绪线索收集的合理性。虽然对话开始阶段的话语中有效信息较少,但其中仍然包含有一定的情绪线索,所以需要以合适的方法利用这些信息,而提出模型较好地解决了这一问题。而该模块在IEMOCAP数据集中影响更大的原因在于 IEMOCAP数据集中对话更长,虽然较长的对话长度会包含更多的信息,但是同样会产生较多的冗余信息,通过降低先前话语的权重并合理收集历史情绪线索可以帮助模型专注于附近的信息,从而获得更好的表现。
b)移除上下文和话语者信息融合模块同样会在两个数据集上降低精度,但在两个数据集中表现不同,同样证明了对于话语者细粒度的信息挖掘策略是有效的,合理利用话语者信息可以提高情绪识别的精度。因为从心理学的角度来看,话语者倾向于保持当前的情绪状态,所以话语者自语境中必然蕴涵着导致情绪变化的线索,将这部分线索与上下文语境级别的情绪线索进行融合,将更好地实现情绪识别。而造成该模块在两个数据集中的效果有差异的原因在于MELD数据集中对话长度短,且话语者人数多,情绪的连续性并不明显,导致话语者自语境的信息较少,性能较IEMOCAP差一些。
c)为了探究设置DAG子图捕获多模态特征的合理性,针对语音和图像模态使用MLP建模进行情绪预测,结果表明通过DAG子图的方式建模多模态特征的效果优于仅使用MLP,证明DAG子图捕获多模态特征的建模方式降低了数据中的噪声,更充分地利用了多模态信息,以此缓解话语长度较短场景中情绪线索不足的问题。
d)移除模态间的交互过程会降低模型效果,证明所设计的交互操作能够有效增强多模态交互效果,提高模型表现。这也同样表明经过改进的DAG结构能够有效建模多模态信息,实现多模态场景下的情绪识别。
e)多模态数据的输入性能要优于单模态数据的输入。分析发现在给文本特征加入另外两种模态信息时,效果比单一文本模态时更好,这点在IEMOCAP上表现更为明显,因为语音和图像在一定程度上会对文本起到一定的辅助作用,尤其是在文本的情绪表达不明显的话语中。此外文本模态的性能表现远比另外两种模态的效果好。
f)仅保留文本特征时,实验得到的评价指标要比表2中仅基于文本的对照方法更高,证明了所提模型表现同样要优于仅基于文本的对照模型,同时保证了与基于文本的方法进行对比的公平性。
5.3 文本特征编码的影响
表2记录了使用不同文本特征编码器获取到的文本特征的实验结果。在所有能够被重构的基线模型上使用本实验中处理的数据进行实验,用于对比文本特征的效果。观察表2可以发现,在两个数据集上,无论是基线模型还是MTDAG,使用RoBERTa嵌入的性能都优于使用TextCNN嵌入的性能。这表明高质量的深度语境化词汇表示可以进一步提高模型的有效性。因此选择RoBERTa作为文本嵌入获得的性能增益是可取的,也是必要的。而在全部使用RoBERTa嵌入的基线模型比较中,MTDAG的表现依然要优于它们,证明了提出模型的有效性。
5.4 参数敏感性实验
对于权重衰减系数ω和近因效应影响因子μ在两个数据集上的选取,是通过基于测试性能的网格搜索来确定的,结果如图6所示。
从图6可以看出:
a)适合两个数据集的ω并不相同。数据集中对话长度以及单个话语的长度可以解释这一现象:在IEMOCAP中,对话长度和话语长度都普遍较长,说明先前的历史信息较多,冗余信息也同样较多,因此先前信息的重要程度较低,表现为ω取值相对较小;然而在MELD中对话的长度和话语长度都相对较短,先前话语仍旧会对末尾话语产生着较大影响,因此先前话语的重要性比较高,表现为ω取值相对较大。
b)适合两个数据集的μ也并不相同。原因同样是对话和话语的长度,MELD数据集的情绪预测需要更多的历史信息,表现为μ取值相对较小,从先前收集到的情绪线索更多;IEMOCAP则更依靠附近的话语信息,无须太多历史情绪线索,表现为μ取值较大,近因效应更明显。
5.5 误差分析
通过对两个数据集进行详细研究以便对实验结果进行误差分析。通过对图7的分析发现:
a)IEMOCAP中相似情绪之间的转换比例很高,推测模型在相似的情绪类别之间出现了混淆。比如happy和excited,有较多的happy类都被模型预测为了excited。分析了数据集以后发现部分原因是训练样本分布不均衡,happy类在整个IEMOCAP中所占的比例最低,导致模型从全局最优的角度降低了少数类样本的训练优先级。
b)结合图5可以看到MELD數据集中sadness、disgust、fear类情绪样本的预测F1分数较差,在分析了整个数据集的样本分布后发现该数据集的样本标签不均衡问题更加严重,sadness、disgust、fear为样本数量最少的三类情绪,并且F1分数和样本数量均逐个递减。由此发现这同样是样本标签不均衡问题所导致的。
此外,从表3可以看到,图像和语音模态特征在模型中表现较差。对于语音来说,对话中人的语音语调只能反映话语者的情绪强度,与其情绪种类没有必然联系,比如开心和生气时的声音都会较其他的情绪语调更高。因此当某些情绪具有相似的频率和幅度时,仅通过语音数据很难正确区分当前话语者的情绪。对于图像特征,可以通过面部特征来判断话语者的情绪,但当话语者故意掩饰自己的面部表情,图像特征就很难进行正确的情绪判断。因此,仍旧需要更好的图像和语音模态特征提取方法或更适合的特征处理方式。
5.6 实例分析
为了更加直观地表现MTDAG模型的准确性和有效性,选取了MELD数据集中的一段对话进行实例分析。所选对话包含11个话语,参与者为话语者A和B。此处选择了MM-DFN和DAG-ERC模型作为MTDAG的实例对比模型,因为MM-DFN是使用了话语者信息的最先进模型,而DAG-ERC是第一个运用DAG建模对话的模型。对比实验的结果如图8所示。
从图8可以看出,与MM-DFN和DAG-ERC相比,MTDAG在进行情绪预测时更加准确,分析原因如下: DAG-ERC在话语轮次1、2和6中,由于没有利用数据集中的语音和图像信息,所以出现了短文本情况下的情绪线索不足问题,同时关于对话时序信息利用不充分的问题导致了它在话语轮次5中接收到对话早期话语中过多的冗余信息,导致情绪预测错误; MM-DFN在话语轮次6中的表现说明了虽然有语音和图像信息提供参考,但其无向图的对话建模方式弱化了对话的时序特点,过多关注了先前的话语信息而一定程度上忽略了关键的临近话语信息,同样会造成预测错误,而对于话语轮次11,由于MM-DFN没有细粒度地挖掘话语者自语境的情绪线索,忽视了话语者自身的情绪惯性,最终预测错误。提出的MTDAG模型首先挖掘了两个级别的情绪线索并加以融合,其次强化并利用了对话的時序特点,同时以合适的方式建模了多模态信息,因此在整个情绪预测过程中都表现出了良好的准确性和有效性。
6 结束语
本文在基于不同话语按照时序对当前话语的情感识别有不同的贡献基础上,提出了一个多模态的时序信息感知的DAG网络,其使用DAG对三种模态的信息建模进行情绪识别,并在其中设置模态交互约束条件以减少交互产生的噪声,实现多模态特征更有效的交互利用,通过使用多粒度特征融合来提取上下文和话语者的深度联合信息,并按时序优化权重设置,收集历史情感线索来提高模型性能。通过在两个基准数据集上的大量实验验证了本文模型的有效性和优越性。
然而,MTDAG仍有一些不足之处,必须在未来加以改进。例如,所使用的上下文和话语者信息融合模块在多人对话中无法很好地提取情感线索。因此,后续的工作将设法通过提取每个说话者的对应特征来改进该方法,以适应多人对话场景。此外,目前只对文本模态采用先进的特征提取器,而对语音和图像模态,还未得到很好的特征表示,因此,下一步需要提取出更有效的其他模态的特征信息。在分析数据集时发现了样本标签不均衡问题,该问题造成了较大的影响但尚未解决,因此也值得进行更深入的研究。
参考文献:
[1]Chatterjee A, Narahari K N, Joshi M, et al. SemEval-2019 task 3: EmoContext contextual emotion detection in text[C]//Proc of the 13th International Workshop on Semantic Evaluation.2019:39-48.
[2]Poria S, Cambria E, Hazarika D, et al. Context-dependent sentiment analysis in user-generated videos[C]//Proc of the 55th Annual Mee-ting of the Association for Computational Linguistics.2017:873-883.
[3]Hazarika D, Poria S, Mihalcea R, et al. Icon: interactive conversational memory network for multimodal emotion detection[C]//Proc of Conference on Empirical Methods in Natural Language Processing.2018:2594-2604.
[4]Majumder N, Poria S, Hazarika D, et al. DialogueRNN: an attentive RNN for emotion detection in conversations[C]//Proc of AAAI Conference on Artificial Intelligence.2019:6818-6825.
[5]Li Jiwei, Galley M, Brockett C, et al. A persona-based neural conversation model[C]//Proc of the 54th Annual Meeting of the Association for Computational Linguistics.2016:994-1003.
[6]Hu Jingwen, Liu Yuchen, Zhao Jinming, et al. MMGCN:multimodal fusion via deep graph convolution network for emotion recognition in conversation[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Confe-rence on Natural Language Processing.2021:5666-5675.
[7]Hu Dou, Hou Xiaolong, Wei Lingwei, et al. MM-DFN:multimodal dynamic fusion network for emotion recognition in conversations[C]//Proc of International Conference on Acoustics,Speech and Signal Processing.2022:7037-7041.
[8]Kahneman D, Tversky A. Subjective probability:a judgment of representativeness[J].Cognitive Psychology,1972,3(3):430-454.
[9]Tversky A, Kahneman D. Belief in the law of small numbers[J].Psychological Bulletin,1971,76(2):105.
[10]Zou Shihao, Huang Xianying, Shen Xudong, et al. Improving multimodal fusion with main modal transformer for emotion recognition in conversation[J].Knowledge-Based Systems,2022,258:109978.
[11]Shen Weizhou, Wu Siyue, Yang Yunyi, et al. Directed acyclic graph network for conversational emotion recognition[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Proces-sing.2021:1551-1560.
[12]Ghosal D, Majumder N, Poria S, et al. DialogueGCN:a graph convolutional neural network for emotion recognition in conversation[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing.2019:154-164.
[13]Ghosal D, Majumder N, Gelbukh A, et al. COSMIC:commonsense knowledge for emotion identification in conversations[C]//Findings of the Association for Computational Linguistics:EMNLP.2020:2470-2481.
[14]Hu Dou, Wei Lingwei, Huai Xiaoyong. DialogueCRN:contextual reasoning networks for emotion recognition in conversations[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing.2021:7042-7052.
[15]Yang Ling, Shen Yi, Mao Yue, et al. Hybrid curriculum learning for emotion recognition in conversation[C]//Proc of AAAI Conference on Artificial Intelligence.2022:11595-11603.
[16]王雨,袁玉波,過弋,等.情感增强的对话文本情绪识别模型[J].计算机应用,2023,43(3):706-712.(Wang Yu, Yuan Yubo, Guo Yi, et al. Sentiment boosting model for emotion recognition in conversation text[J].Journal of Computer Applications,2023,43(3):706-712.)
[17]Wang Binqiang, Dong Gang, Zhao Yaqian, et al. Hierarchically stacked graph convolution for emotion recognition in conversation[J].Knowledge-Based Systems,2023,263(C):110285.
[18]Hazarika D, Poria S, Zadeh A, et al. Conversational memory network for emotion recognition in dyadic dialogue videos[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.2018:2122.
[19]Chen Minhai, Wang Sen, Liang P P, et al. Multimodal sentiment analysis with word-level fusion and reinforcement learning[C]//Proc of the 19th ACM International Conference on Multimodal Interaction.2017:163-171.
[20]Sahay S, Kumar S H, Xia Rui, et al. Multimodal relational tensor network for sentiment and emotion classification[C]//Proc of Grand Challenge and Workshop on Human Multimodal Language.2018:20-27.
[21]Zadeh A, Liang P P, Mazumder N, et al. Memory fusion network for multi-view sequential learning[C]//Proc of AAAI Conference on Artificial Intelligence.2018.
[22]譚晓聪,郭军军,线岩团,等.基于一致性图卷积模型的多模态对话情绪识别[J].计算机应用研究,2023,40(10):3100-3106.(Tan Xiaocong, Guo Junjun, Xian Yantuan, et al. Consistency based graph convolution network for multimodal emotion recognition in conversation[J].Application Research of Computers,2023,40(10):3100-3106.)
[23]Wen Jintao, Jiang Dazhi, Tu Geng, et al. Dynamic interactive multiview memory network for emotion recognition in conversation[J].Information Fusion,2023,91:123-133.
[24]Tai Kaisheng, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[C]//Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing.2015:1556-1566.
[25]Shuai Bing, Zuo Zhen, Wang Bing, et al. Scene segmentation with DAG-recurrent neural networks[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2017,40(6):1480-1493.
[26]Zhang Muhan, Jiang Shali, Cui Zhicheng, et al. D-VAE:a variatio-nal autoencoder for directed acyclic graphs[C]//Advances in Neural Information Processing Systems.2019.
[27]Thost V, Chen Jie. Directed acyclic graph neural networks[C]//Proc of International Conference on Learning Representations.2021.
[28]Liu Yinhan, Ott M, Goyal N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL].(2019-06-26).https://arxiv.org/abs/1907.1 1692.
[29]Kenton J D M W C, Toutanova L K. BERT: pre-training of deep bidirectional transformers for language understanding[C]//Proc of NAACL-HLT.2019:4171-4186.
[30]Eyben F, Wllmer M, Schuller B. Opensmile: the Munich versatile and fast open-source audio feature extractor[C]//Proc of the 18th ACM International Conference on Multimedia.2010:1459-1462.
[31]Huang Gao, Liu Zhuang, Van Der Maaten L, et al. Densely connec-ted convolutional networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.2017:4700-4708.
[32]Barsoum E, Zhang Cha, Ferrer C C, et al. Training deep networks for facial expression recognition with crowd-sourced label distribution[C]//Proc of the 18th ACM International Conference on Multimodal Interaction.2016:279-283.
[33]Kingma D P, Ba J. Adam: a method for stochastic optimization[EB/OL].(2017-01-30).https://arxiv.org/abs/1412.6980.
[34]Busso C, Bulut M, Lee C C, et al. IEMOCAP: interactive emotional dyadic motion capture database[J].Language Resources and Evaluation,2008,42:335-359.
[35]Poria S, Hazarika D, Majumder N, et al. MELD:a multimodal multi-party dataset for emotion recognition in conversations[C]//Proc of the 57th Annual Meeting of the Association for Computational Linguistics.2019:527-536.
