基于非文本模态强化和门控融合方法的多模态情感分析
2024-02-18魏金龙邵新慧
魏金龙 邵新慧
摘 要:针对各模态之间信息密度存在差距和融合过程中可能会丢失部分情感信息等问题,提出一种基于非文本模态强化和门控融合方法的多模态情感分析模型。该模型通过设计一个音频-视觉强化模块来实现音频和视觉模态的信息增强,从而减小与文本模态的信息差距。之后,通过跨模态注意力和门控融合方法,使得模型充分学习到多模态情感信息和原始情感信息,从而增强模型的表达能力。在对齐和非对齐的CMU-MOSEI数据集上的实验结果表明,所提模型是有效的,相比现有的一些模型取得了更好的性能。
关键词:多模态情感分析; 多模态融合; 模态强化; 门控机制
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-006-0039-06
doi:10.19734/j.issn.1001-3695.2023.04.0213
Multimodal sentiment analysis based on non-text modality reinforcement and gating fusion method
Abstract:To address the problems of information density gaps between modalities and the possibility of losing some sentiment information in the fusion process, this paper proposed a multimodal sentiment analysis model based on non-text modality reinforcement and gating fusion method. The model reduced the gap with text modality by designing an audio-visual reinforcement module to achieve information enhancement of audio and visual modalities. Then, the cross-modal attention and gating fusion method allowed the model to fully learn the multimodal sentiment information and the original sentiment information to enhance the representation of the model. Experimental results on the aligned and unaligned CMU-MOSEI datasets show that the proposed model is effective and achieves better performances than some existing models.
Key words:multimodal sentiment analysis; multimodal fusion; modality reinforcement; gating mechanism
0 引言
情感分析一直是自然语言处理领域的重要研究方向之一,在舆情监控、产品推荐、金融风控等领域有着广泛应用[1]。近年来,随着多媒体技术的发展和短视频的兴起,包含了文本、音频和视觉信息的多模态情感分析受到了越来越广泛的关注,相比于单模态情感分析,多模态情感分析可以融合来自不同模态的信息,从而作出更加准确的情感判断。而多模态情感分析的关键任务之一是如何设计高效的融合网络,使得模型可以充分学习到不同模态的情感信息,从而进行准确的情感预测。早期的多模态融合策略主要包括早期融合[2]和晚期融合[3]。早期融合的主要做法是将来自不同模态的特征进行拼接,送入情感分类器中进行情感预测。而晚期融合主要利用每个单模态特征进行情感预测,通过对单模态预测结果采取加权平均或者投票机制得到最终的预测结果。虽然上述两种策略均可以完成多模态情感分析任务,但是不能充分挖掘各模态的内部信息和模态间的交互作用。随着Transformer模型的出现[4],文献[5,6]基于Transformer的注意力机制实现多模态融合,使得多模态情感表达更加充分。但是,上述方法通常将各个模态看作同等重要,忽视了不同模态之间的信息密度存在差异,而部分研究表明[7,8],在多模态情感分析中,文本模态的重要性通常最高,而音频、视觉模态的重要性较低。因此,在多模态情感分析中要充分关注不同模态之间的信息差异,从而提高融合效率。
此外,目前的多模态情感分析往往只关注于融合特征,而忽视了原始的情感信息表示,在多模态的融合过程中可能会丢失部分原始情感特征,使得模型的表达不够充分。部分研究表明[9],结合不同层次的特征进行情感分析可以有效提高模型的性能。因此,如何充分学习多模态情感表示和原始情感特征也是多模态情感分析面临的关键问题之一。
针对上述問题,本文提出了一个基于非文本模态强化和门控融合方法的多模态情感分析模型(multimodal sentiment ana-lysis based on non-text modality reinforcement and gating fusion method,NMRGF),主要贡献如下:
a)提出一个音频-视觉强化模块,通过对音频和视觉两个低级模态进行强化,减少冗余信息的出现,从而减小两者与文本模态的差距,提高融合效率。
b)提出一种门控融合方法,使得模型能够充分学习多模态情感特征和原始情感特征,增强模型的表达能力。
c)在对齐和非对齐下的CMU-MOSEI数据集上进行了充分实验,结果表明该模型相比于一些现有模型达到了最佳性能。
1 相关工作
多模态情感分析的重点任务是融合来自不同模态的信息,目前主要的融合方法包括基于张量融合[10,11]、基于图融合[12]、基于翻译策略的融合[13,14]、基于注意力的方法[15~18]等,上述方法在多模态情感分析任务中都取得了较好的效果。其中,基于注意力的方法通常表现更好。
近年来多模态情感分析更多关注于和其他领域前沿方法的结合。Rahman 等人[19]充分发挥预训练模型的优势,将非文本模态的信息融入到BERT模型的微调阶段,使得文本模态可以学习到其他两个模态的信息。Yu等人[20]通过自监督的方式生成单模态情感强度标签,随后使用多任务学习联合训练多模态和单模态情感分析任务。Sun等人[21]基于特征混合的思想,提出一种基于多个MLP单元组成的多模态特征处理方法,可以对多模态数据在不同轴上进行展开,并且降低了计算成本。Han等人[22]将互信息的概念引入多模态情感分析中,提出了一种分层次最大化互信息学习框架,有效减少了各个模态中的冗余信息,提高预测准确率。Hazarika 等人[23]将模态向量投影至两个不同的空间中,同时进行模态不变和模态特定的表示学习。Wu等人[24]则利用图神经网络和胶囊网络实现多模态融合,大大提高了计算效率。文献[25]通过深度典型相关分析方法学习不同模态之间的相关性,从而完成情感预测。
受到上述研究的启发,本文在完成各个模态的特征提取之后,首先利用Self-Transformer模块增强单模态特征的表达;之后设计一个音频-视觉强化模块完成两种低级模态特征的强化,减小和文本模态的信息差距;最后利用跨模态注意力完成多模态融合过程,并通过门控融合机制使得模型充分学习多模态情感信息和原始情感信息,增强模型的表达能力和泛化能力。
2 多模态情感分析模型
2.1 模型概述
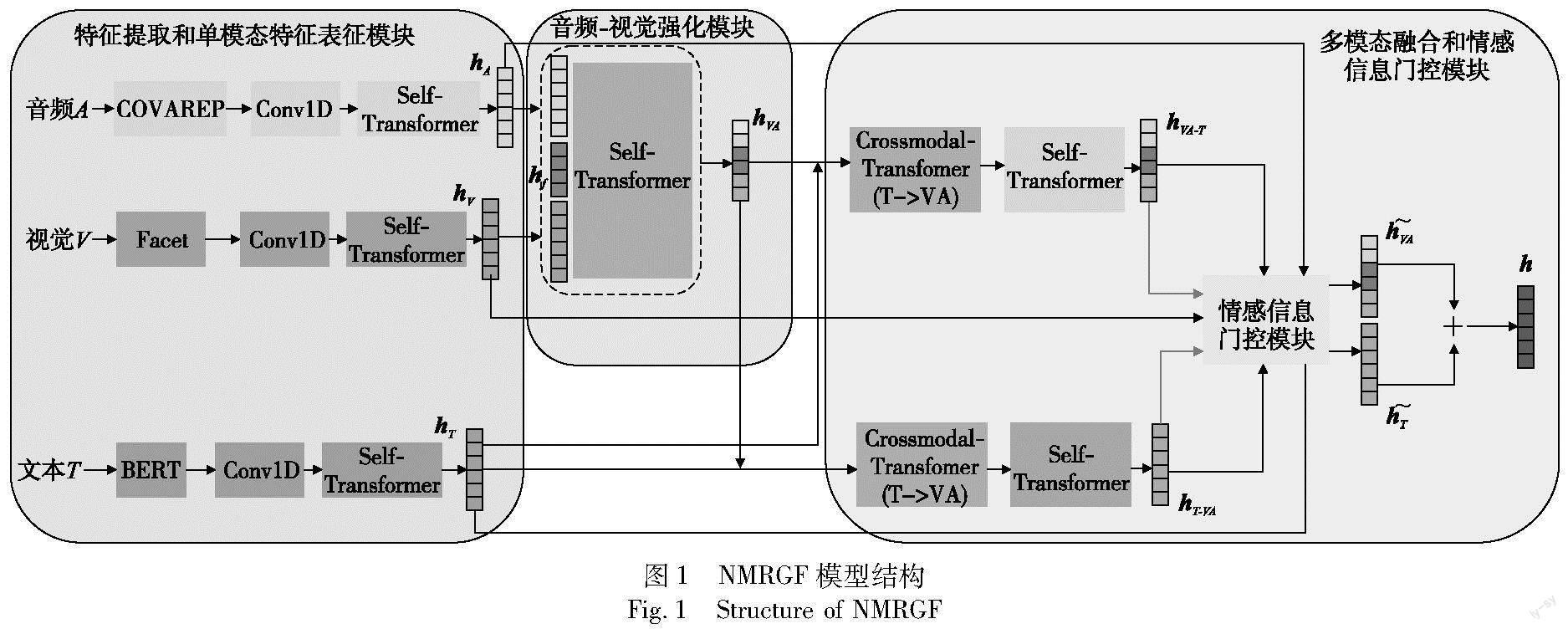
本文提出的基于非文本模态强化和门控融合方法的多模态情感分析网络NMRGF如图1所示。该模型主要由特征提取和单模态特征表征模块、音频-视觉强化模块、多模态融合和情感信息门控模块三部分组成。特征提取和单模态特征表征模块对单模态特征进行提取并通过Self-Transformer增强其表达。音频-视觉强化模块实现音频和视觉这两个低级模态的强化,多模态融合和情感信息门控模块使模型通过跨模态注意力操作完成多模态融合,并充分学习多模态情感信息和原始情感信息。
2.2 特征提取和单模态特征表征模块
2.2.1 特征提取和一维卷积
给定一个视频片段X,分别利用不同的工具提取其文本模态T、音频模态A和视觉模态V的原始特征,三个模态的初始特征可以表示为Im∈RApTm×dm,其中Tm代表序列长度,dm代表特征维度,m∈{T,A,V}。对于文本模态,使用BERT预训练模型进行特征提取[26],将BERT模型最后一层的输出作为文本模态的表示IT。对于音频模态,使用COVAREP[27]提取音频特征IA,对于视觉模态,使用Facet工具[28]提取视觉模态特征IV。
将得到的原始特征输入到一维卷积层,一方面可以捕捉各模态内部的局部特征,另一方面统一各模态的特征维度方便后续计算,计算公式如下:
Xm=Conv1D(IM,kernel) M∈{A,V,T}(1)
2.2.2 Self-Transformer模块
得到各模态初始特征Xm后,通过Self-Transformer 模块进一步增强模态特征的表示,该模块主要利用了原始Transformer模型的编码器部分,该部分主要由多头注意力(MHA)、层归一化(LN)以及带有残差连接的前馈神经网络(FFN)组成,该模块通过多头注意力机制可以学习到序列全文的信息,从而增强建模能力。Self-Transformer中第l层的表达如下所示。
yl=MHA(LN(Xl-1m))+ LN(Xl-1m)(2)
Xlm=FFN(LN(yl))+ LN(yl)(3)
其中:Xlm代表第l层的输出;多头注意力MHA通过多头处理,分別捕捉不同子空间的特征,最后再拼接起来作为最终的表示,其计算公式如下。
其中:Q、K、V是同一个模态的特征通过线性变换得到的;m是注意力的头数;WQi、WKi、WVi、WO代表训练参数;concat代表拼接操作。原始特征Xm通过多层Self-Transformer模块的堆叠,使得三个模态特征不断增强自身信息的表达,得到各模态的原始情感特征hT、hV、hA。
2.3 音频-视觉强化模块
由于文本模态常常在多模态情感分析工作中占据主导地位,音频和视觉模态的信息对于多模态情感分析的贡献相对较低,即这两种模态与文本模态的信息密度差异较大。受到文献[29]的启发,本文设计了一个音频-视觉强化模块来实现音频和视觉模态的强化,从而减小与文本模态之间的信息差距,使得后续的多模态融合过程更加高效。具体而言,本文提出一个聚合块来实现音频和视觉特征的强化,该聚合块的序列长度为B(BTm),特征维度为d,利用该聚合块和Self-Transformer模块不断增强音频和视觉两种模态特征的信息。首先将该聚合块和音频特征拼接,经过多层的Self-Transformer模块,使得该聚合块学习到音频模态的信息;之后将已经学习到音频信息的聚合块和视觉特征拼接,再经过多层的Self-Transformer模块,使得该聚合块学习到视觉模态的特征,利用该聚合块实现音频和视觉模态特征的强化,使得模型充分学习来自这两个模态的特征,从而减小与文本模态的信息差距。将该模块最后一层的输出作为强化后的音频-视觉模态表示hVA,该表示融合了音频和视觉模态的情感信息。其计算公式如下:
2.4 多模态融合和情感信息门控模块
2.4.1 多模态融合模块
将增强后的音频-视觉模态特征hVA,同文本特征hT进行多模态融合,利用文献[5]提出的Crossmodal-Transformer模块进行融合,该模块借鉴了Transformer模型编码器的主要思想,通过源模态的特征不断增强目标模态的特征,使得目标模态可以学习到源模态的信息,从而实现多模态的融合,具体过程如图2所示。该模块的核心是跨模態注意力的计算,给定目标模态特征hT,源模态特征hVA,跨模态注意力的(crossmodal attention,CM)计算方式如式(9)所示。
其中:向量Q由目标模态提供;向量K和V由源模态提供。通过这种跨模态注意力的计算,使得文本模态可以学习到来自音频和视觉模态的信息。同样,音频和视觉模态特征也可以通过这种方式学习到来自文本模态的信息,通过这种方式实现多模态融合过程。经过多层的Cross-Transformer堆叠之后,对得到的两个融合向量再经过多层的Self-Transformer不断增强跨模态特征表示,最终得到多模态情感信息表示hT-VA和hVA-T。
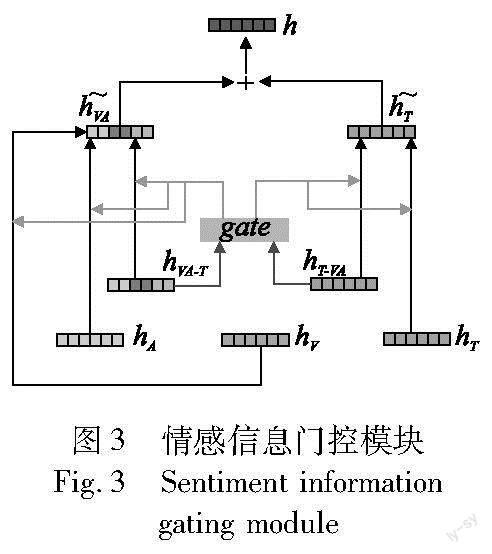
2.4.2 情感信息门控模块
为了避免在多模态融合过程中丢失部分原始情感信息,在得到hT-VA和hVA-T两个融合表示之后,本文利用这两个融合了三种模态信息的特征表示生成一个情感信息门控单元gate,该单元将控制多模态情感信息和原始情感信息在最终的情感表示中的比重,具体过程如下:
2.5 情感预测
练样本的数量,yi代表该样本的真实标签。
3 实验设计与结果分析
3.1 数据集
实验数据集选择CMU-MOSEI数据集[12],这是目前最大的多模态情感分析数据集,该数据集包括22 856个带有情感注释的视频片段,每个片段标注的情感值在[-3,3],数值越小代表负面情绪越明显,数值越大则表示正面情绪越明显。根据各个模态是否对齐,即各模态的序列长度是否相同,可以分为对齐数据和非对齐数据。该数据集的训练集、验证集和测试集的数量分别是16 326、1 871和4 659。
3.2 实验设置及评价指标
通过特征提取之后,文本模态的特征维度是768,音频模态的特征维度是74,视觉模态的特征维度是35。
本文模型搭建和训练在Python 3.8和深度学习框架PyTroch 1.10下进行,训练环境是Ubuntu 20.04,GPU为显存24 GB的RTX3090。初始学习率设置为2E-3,BERT学习率设置为5E-5,优化器使用AdamW并设置学习率衰减策略,训练批次大小为32,迭代次数为10。
模型涉及的主要超参数设计如下:三种模态下一维卷积的卷积核大小为1,公共维度d为60,Self-Transformer和Cross-Transformer模块的层数为5,多头注意力的头数为5。
本文选取的评价指标包括平均绝对误差(MAE)、皮尔森相关系数(Corr)、二分类准确率(Acc-2)、F1值和七分类准确率(Acc-7)五个指标以全面衡量模型的性能。其中,除平均绝对误差MAE外,其他的指标数值越高越好。
3.3 对比实验
本文分别在对齐数据下和非对齐数据下进行实验,并与不同的基准模型进行比较。对齐数据下选取的基准模型有:
a)MFN[30]。利用LSTM网络对三个模态进行建模,并设计一个DMAN模块实现不同模态之间的交互作用从而完成多模态融合。
b)Graph-MFN[12]。在MFN模型的基础上,设计一种动态融合图方法实现不同模态之间的交互作用。
c)ICCN[25]。采用深度典型相关分析的方法探索三种模态之间的相关性,从而完成多模态融合。
d)MISA[23]。将不同模态的特征向量投影至两个不同的空间中,同时进行模态不变和模态特定的表示学习。
e)MAG-BERT[19]。把非文本模态的特征融合到BERT微调阶段,使得词向量表示可以学习其他模态的信息。
f)BIMHA[31]。设计一种新的多头注意力方式去捕捉两两模态之间的潜在联系以完成多模态融合。
非对齐数据下选取的基准模型:
a)TFN[10]。采用张量外积的方式对单模态、双模态和三模态信息进行建模,并将最终的融合向量用于情感分析。
b)LMF[11]。在TFN的基础上,采用张量低秩分解的方法降低模型的复杂度和计算成本。
c)MulT[5]。利用跨模态注意力实现两两模态的交互作用,从而完成多模态融合。
d)GraphCAGE[24]。利用图神经网络和胶囊网络更好地捕捉不同模型之间的交互作用,从而完成多模态融合过程。
e)Self-MM[20]。采用自监督的方式生成单模态情感标签,随后使用多任务学习联合训练多模态和单模态情感分析任务。
f)MMIM[22]。首次将互信息引入多模态情感分析,提出一种分层次最大化互信息学习框架,有效减少了各个模态中的冗余信息。
g)NHFNET[29]。通过增强音频和视觉模态的信息来降低跨模态注意力的计算复杂度,提高多模态融合效率。
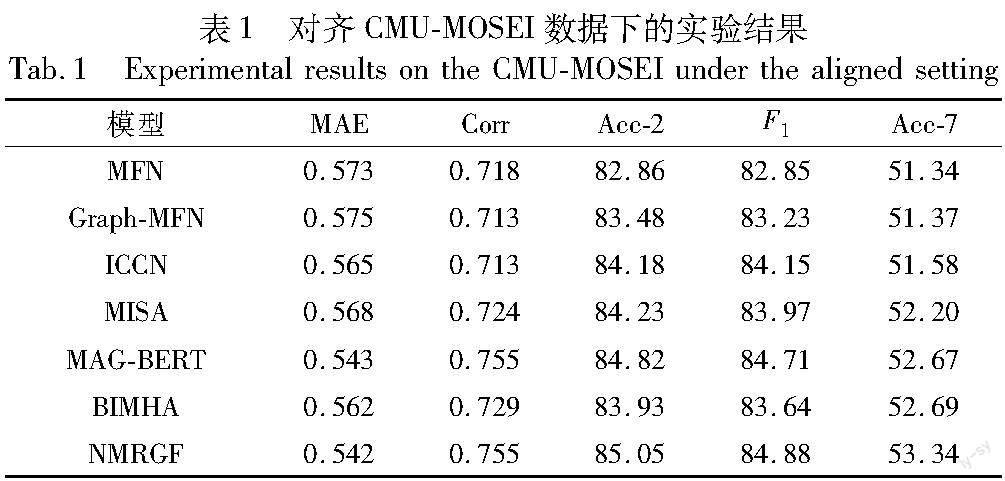
在不同数据集下的实验结果如表1、2所示。实验结果表明,无论是在对齐数据下还是非对齐数据下,本文NMRGF模型在各项指标上都表现出了最佳性能。进一步,同MFN、TFN、LMF、ICCN、GraphCAGE等非基于注意力方法进行多模态融合的模型相比,模型的各项指标都有显著提高,其中二分类准确率约提升3%,充分说明注意力融合策略相较于其他的融合方式可以更加准确地捕捉到不同模态之间的交互作用。相比于MulT、NHFNET、MISA、BIMHA等模型,NMRGF也表现出了明显优势,说明加入原始情感信息并使模型充分学习到多模态情感表示和原始情感表示可以提高预测准确率。
与MAG-BERT、MMIM、Self-MM等先进模型相比,本文模型在各项指标上也略优于它们,其中七分类准确率提升约1.2%,进一步说明将先进的注意力融合策略和情感信息门控融合机制相结合,可以使得模型学习到更加完整的情感表示,从而丰富模型的情感表达能力,进而作出更加精准的情感判断。
3.4 消融实验
为了进一步验证本文模块的合理性,在非对齐下的CMU-MOSEI数据集上设计如下七组消融实驗,实验结果如表3所示。
NMRGF表示原模型;A表示去掉情感信息门控模块,直接将多模态融合特征和原始情感特征相加得到最终的表示向量用于情感预测;B表示去掉文本模态的情感信息门控模块,保留音频和视觉模态的情感信息门控模块;C表示去掉音频和视觉模态的情感信息门控模块,保留文本模态的情感信息门控模块;D表示去掉情感信息门控模块和原始情感信息特征,将多模态融合之后的两个情感表示相加作为最终的情感特征用于情感预测;E表示保留情感信息门控模块,原始情感信息特征替换为经过一维卷积之后的三个模态的特征;F表示保留情感信息门控模块,不使用音频-视觉强化模块,仅使用文本和音频模态完成多模态情感分析;G表示保留情感信息门控模块,不使用音频-视觉强化模块,仅使用文本和视觉模态完成多模态情感分析。由表3可知,本文设计的七组消融实验结果相比原模型在各个指标上都有不同程度的下降,说明本文所设计的不同模块可以有效提高多模态情感分析的准确率。具体而言,当去掉情感信息门控模块之后,直接使用多模态特征和原始的情感特征相加作为最终的输出表示,模型的各项指标都有所下降,由于模型不能有选择地学习多模态情感信息和原始情感信息,导致部分冗余信息的产生,降低了模型的性能。而如果去掉原始情感信息表示和情感信息门控模块,只使用多模态融合之后的特征作为最终表示,模型的整体表现也有所下降,说明加入原始情感信息增强模型的情感表达能力是非常有必要的。针对不同的模态,分别去掉对应的情感信息门控模块进行情感预测,可以看到模型的表现进一步变差,其中只去掉文本模态的门控机制后模型效果下降得最少,本文认为一方面是因为人们情感的表达一般主要依赖于文本模态,另一方面是由于BERT预训练模型的天然优势,使得文本模态本身含有丰富的情感信息,门控机制在文本模态中发挥的作用相对较弱。此外,本文将原始情感信息特征替换为经过一维卷积之后三个模态的特征表示,而不是经过Self-Transformer增强后的模态特征,可以看到模型性能也有所下降,说明通过堆叠多层的Self-Transformer之后,三个模态的原始情感特征得到了增强,更能代表原始的情感信息。最后,当去掉音频-视觉强化模块后,只使用文本和音频或者文本和视觉模态完成多模态情感分析时,模型的预测能力有所下降,说明通过增强两个低级模态的语义信息可以减小和文本模态的信息差距,从而提高融合效率,帮助模型作出更准确的判断。
3.5 音频-视觉强化模块的对比实验
为了进一步验证音频-视觉强化模块在多模态情感分析中的预测效果,针对该模块设计如下四组对比实验:
T表示只有文本模态进行多模态情感分析,即只将原始的文本情感表示hT传入情感分类器中进行情感预测;A表示只有音频模态进行多模态情感分析,即只将原始的音频情感表示hA传入情感分类器中进行情感预测;V表示只有视觉模态进行多模态情感分析,即只将原始的视觉情感表示hV传入情感分类器中进行情感预测;A+V表示只将通过音频-视觉强化模块增强后的音频-视觉表示hVA传入情感分类器中进行情感预测。
实验结果如图4所示。由图4不难发现,在仅使用单模态信息进行情感预测时,文本模态表现出了绝对优势,进一步验证了文本模态是多模态情感分析的主导模态,其自身蕴涵丰富的情感信息。而单独使用音频或者视觉模态进行情感分析时,相比于单独使用文本模态时,F1值下降了接近20%,说明这两个模态中存在较多的冗余信息,情感表达能力较弱,相比而言视觉模态的预测表现略好于音频模态,但两者都与文本模态的预测表现存在较大的差距,所以直接使用这两个模态的原始特征进行融合可能会导致多模态融合效率降低,由此说明对这两个低级模态进行强化是非常有必要的。而只使用本文提出的音频-视觉强化模块增强后的特征进行情感分析时,相比于只使用音频或视觉特征,该特征的预测表现在多个指标上都有明显提升,说明通过音频-视觉强化模块的作用,可以有效减少这两个低级模态中存在的冗余信息,增强两个模态的情感表示,从而达到非文本模态强化,减小与文本模态的信息差距、提高多模态融合效率的目的。
3.6 案例分析
为了更加直观地说明本文模型在实际样本中的预测效果以及该模型的先进性,本文从CMU-MOSEI数据集中选择部分样本和不同模型的预测值进行对比,如表4所示。其中:“文本”一列表示该片段文本模态的信息;“音频”一列代表该片段的音频模态信息;“视觉”一列代表该片段的视觉模态信息;“真实值”一列代表该片段的真实情感值;“NMRGF”一列代表
本文模型的预测结果;“Self-MM” 一列代表使用Self-MM模型进行预测的结果;“MMIM”一列代表使用MMIM模型进行预测的结果。具体而言,在案例1中,文本模态没有传达明显的情感信息,音频和视觉模态也没有提供较多的情感特征,因此模型作出了中性情感的判断,与真实值差距极小。在案例2中,说话者的文本内容表达出了明显的正面情感,音频和视觉模态也蕴涵着积极的情感信息,尽管Self-MM和MMIM这两个模型也作出了正确的情感倾向判断,但是NMRGF模型通过非文本模态信息的增强,给出的预测值更加接近真实值,预测效果明显更好。而对于案例3,文本模态和音频模态并没有非常明显的情感倾向,但是视觉模态包含了明显的负面情感信息(皱眉),NMRGF通过音频-视觉强化模块学习到了该情感信息并作出了较为准确的判断,而Self-MM模型的预测值和真实值差距较大,MMIM模型则作出了完全相反的判断。通过上述案例分析,进一步说明了本文模型在实际样本中的预测效果,相比于一些现有模型,该模型可以更加准确地完成多模态情感分析任务。
4 結束语
针对多模态情感分析中模态之间信息存在差异以及部分情感特征丢失的问题,本文提出了一种基于非文本模态强化和情感信息门控融合方法的多模态情感分析模型(NMRGF)。该模型在完成特征提取和单模态特征表征之后,首先通过音频-视觉强化模块完成对两个低级模态的强化,从而减小与文本模态之间的信息差距,提高融合效率。在多模态融合阶段,通过Cross-Transformer结构和情感信息门控模块,使得模型可以充分完成多模态融合并利用不同层次的情感特征,从而增强模型的预测能力。为了验证该模型的性能,本文在对齐和非对齐的CMU-MOSEI数据集上进行了大量实验,实验结果表明,该模型的整体性能优于一些现有模型。此外,通过消融实验,进一步说明了本文所设计模块的合理性和有效性,案例分析则直观地给出了模型在实际样本中的预测效果。但是,本文方法计算开销较大,模型的训练效率较低,而且在实际视频数据中的预测效果还需要进一步地探索。接下来的主要研究工作应关注于简化多模态融合的过程并提高模型的鲁棒性。
参考文献:
[1]Chaturvedi I, Cambria E, Welsch R E, et al. Distinguishing between facts and opinions for sentiment analysis: survey and challenges[J].Information Fusion,2018,44:65-77.
[2]Poria S, Cambria E, Hazarika D, et al. Multi-level multiple attentions for contextual multimodal sentiment analysis[C]//Proc of IEEE International Conference on Data Mining.Piscataway,NY:IEEE Press,2017:1033-1038.
[3]Nojavanasghari B, Gopinath D, Koushik J, et al. Deep multimodal fusion for persuasiveness prediction[C]//Proc of the 18th ACM International Conference on Multimodal Interaction.New York:ACM Press,2016:284-288.
[4]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J].Advances in Neural Information Processing Systems, 2017,30:5998-6008.
[5]Tsai Y H H, Bai Shaojie, Liang P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]//Proc of the 57th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:ACL,2019:6558-6569.
[6]Sahay S, Okur E, Kumar S H, et al. Low rank fusion based transformers for multimodal sequences[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:ACL,2020:29-34.
[7]Wang Yansen, Shen Ying, Liu Zhun, et al. Words can shift:dynamically adjusting word representations using nonverbal behaviors[C]//Proc of the 33rd AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI,Press,2019:7216-7223.
[8]Chen Minping, Li Xia. SWAFN: sentimental words aware fusion network for multimodal sentiment analysis[C]//Proc of the 28th International Conference on Computational Linguistics.New York:International Committee on Computational Linguistics,2020:1067-1077.
[9]Rao Tianrong, Li Xiaoxu, Xu Min. Learning multi-level deep representations for image emotion classification[J].Neural Processing Letters,2020,51(3):2043-2061.
[10]Zadeh A, Chen Minghai, Poria S, et al. Tensor fusion network for multimodal sentiment analysis[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:ACL,2017:1103-1114.
[11]Liu Zhun, Shen Ying, Lakshminarasimhan V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[C]//Proc of the 56th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:ACL,2018:2247-2256.
[12]Zadeh A B, Liang P P, Poria S, et al. Multimodal language analysis in the wild:CMU-MOSEI dataset and interpretable dynamic fusion graph[C]//Proc of the 56th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:ACL,2018:2236-2246.
[13]Pham H, Liang P P, Manzini T, et al. Found in translation: learning robust joint representations by cyclic translations between modalities[C]//Proc of the 33rd AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2019:6892-6899.
[14]Tang Jiajia, Li Kang, Jin Xuanyu, et al. CTFN: hierarchical lear-ning for multimodal sentiment analysis using coupled-translation fusion network[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:ACL,2021:5301-5311.
[15]Chauhan D S, Akhtar M S, Ekbal A, et al. Context-aware interactive attention for multimodal sentiment and emotion analysis[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Proces-sing.Stroudsburg,PA:ACL,2019:5647-5657.
[16]Han Wei, Chen Hui, Gelbukh A, et al. Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis[C]//Proc of the 29th ACM International Conference on Multimodal Interaction.New York:ACM Press,2021:6-15.
[17]包廣斌,李港乐,王国雄.面向多模态情感分析的双模态交互注意力[J].计算机科学与探索,2022,16(4):909-916.(Bao Guangbin, Li Gangle, Wang Guoxiong. Bimodal interactive attention for multimodal sentiment analysis[J].Journal of Frontiers of Compu-ter Science and Technology,2022,16(4):909-916.)
[18]宋云峰,任鸽,杨勇,等.基于注意力的多层次混合融合的多任务多模态情感分析[J].计算机应用研究,2022,39(3):716-720.(Song Yunfeng, Ren Ge, Yang Yong, et al. Multimodal sentiment analysis based on hybrid feature fusion of multi-level attention mechanism and multitask learning[J].Application Research of Compu-ters,2022,39(3):716-720.)
[19]Rahman W, Hasan M K, Lee S, et al. Integrating multimodal information in large pretrained transformers[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:ACL,2020:2359-2369.
[20]Yu Wenmeng, Xu Hua, Yuan Ziqi, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis[C]//Proc of the 35th AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2021:10790-10797.
[21]Sun Hao, Wang Hongyi, Liu Jiaqing, et al. CubeMLP: an MLP-based model for multimodal sentiment analysis and depression estimation[C]//Proc of the 30th ACM International Conference on Multimedia.New York:ACM Press,2022:3722-3729.
[22]Han Wei, Chen Hui, Poria S. Improving multimodal fusion with hie-rarchical mutual information maximization for multimodal sentiment analysis[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:ACL,2021:9180-9192.
[23]Hazarika D, Zimmermann R, Poria S. MISA: modality-invariant and specific representations for multimodal sentiment analysis[C]//Proc of the 28th ACM International Conference on Multimedia.New York:ACM Press,2020:1122-1131.
[24]Wu Jianfeng, Mai Sijie, Hu Haifeng. Graph capsule aggregation for unaligned multimodal sequences[C]//Proc of the 23rd ACM International Conference on Multimodal Interaction.New York:ACM Press,2021:521-529.
[25]Sun Zhongkai, Sarma P, Sethares W, et al. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis[C]//Proc of the 34th AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2020: 8992-8999.
[26]Devlin J, Chang Mingwei, Lee K, et al. BERT:pre-training of deep bidirectional transformers for language understanding[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:ACL,2019:4171-4186.
[27]Degottex G, Kane J, Drugman T, et al. COVAREP:a collaborative voice analysis repository for speech technologies[C]//Proc of the 39th International Conference on Acoustics,Speech and Signal Processing.New York:IEEE Press,2014:960-964.
[28]Baltruaitis T, Robinson P, Morency L P. OpenFace: an open source facial behavior analysis toolkit[C]//Proc of IEEE Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE Press,2016:1-10.
[29]Fu Ziwang, Liu Feng, Xu Qing, et al. NHFNET:a non-homogeneous fusion network for multimodal sentiment analysis[C]//Proc of IEEE International Conference on Multimedia and Expo.Piscataway,NJ:IEEE Press,2022:1-6.
[30]Zadeh A, Liang P P, Poria S, et al. Memory fusion network for multi-view sequential learning[C]//Proc of the 32nd AAAI Confe-rence on Artificial Intelligence.Palo Alto,CA:AAAI Press,2018:5634-5641.
[31]Wu Ting, Peng Junjie, Zhang Wenqiang, et al. Video sentiment analysis with bimodal information-augmentedmulti-head attention[J].Knowledge-Based Systems,2021,235(10):article ID 107676.
