基于光纤陀螺的温度补偿模型改进、压缩和FPGA 实现
2024-02-16杨雷静王竣可
杨雷静,王竣可,苏 杭
(1.北京邮电大学 电子工程学院,北京 100876;2.湖北三江航天红峰控制有限公司,孝感 432100)
1913 年,法国科学家G.Sagnac 提出了Sagnac 效应,即沿闭合光路相向传播的两光波之间的相位差正比于闭合光路法向的输入角速度[1]。基于此原理,并结合光纤通信器件技术与工艺基础的发展,1976 年,美国Utah 大学Victor Vali 和Richard W.Shorthill 在实验室成功演示了第一个光纤陀螺仪(Fiber-Optic Gyroscope,FOG),标志着FOG 的诞生[2]。其应用范围非常广泛,主要包括惯导系统、汽车和船舶导航、无人机和机器人、防震和平稳系统、航空航天工业、石油和天然气勘探等多个领域[3]。FOG 中核心光电子器件受温度的影响性能指标会发生变化,主要受温度影响的是光纤环,根据Shupe 理论,温度环境变化会直接导致FOG 产生相位误差,从而导致FOG 的零偏误差增大[4]。
由温度变化引起的FOG 零偏误差是非线性的,即随着温变速度的变化,漂移量不是恒定的,常常受到一段时间内大范围温度变化的影响,需要进行复杂的补偿和校准。针对FOG 受温度变化影响带来的零偏误差,研究人员建立了多种模型进行温度误差补偿。总体而言,分为传统温度补偿模型和神经网络温度补偿模型,传统的温度补偿模型有多项式算法、支持向量机等[5],相较而言,神经网络对于复杂非线性关系具有良好的逼近能力,模型补偿精度高,近年来,运用神经网络模型对FOG 进行温度补偿成为探索趋势。有学者采用反向传播(Back Propagation,BP)神经网络以及各种改进BP 神经网络模型来补偿FOG 温度误差[6]。但FOG 的输出常常不是受到某一时刻的温度影响,在一段时间范围内温度的变化都会影响FOG 的输出,而BP 神经网络简单的全连接(Fully Connected,FC)结构只能依据单一时刻温度影响来补偿对应的温度误差,导致补偿精度有限;有学者提出采用循环神经网络(Recurrent Neural Network,RNN)来补偿FOG温度误差,凭借RNN 的记忆性特点,可以有效改进BP 神经网络模型的不足[7],但是RNN 只能记忆上一时刻的输入值,对于全局的拟合效果不佳;有学者提出采用长短期记忆神经网络模型(Long Short-Term Memory,LSTM)对FOG 进行温度补偿[8],LSTM 模型可以解决RNN 存在的长距离依赖以及梯度消失和梯度爆炸的问题,而对于LSTM 中的超参数选择,常常通过试凑法决定,不具有客观性,导致最终建模效果不佳。针对该问题,本文通过将粒子群算法(Particle Swarm Optimization,PSO)的惯性权重,个体学习因子,社会学习因子由固定值改变为分段非线性(Piecewise Nonlinear,PN)的动态值,对LSTM 模型超参数进行寻优,建立了PN-PSO-LSTM 模型。实验结果表明,与BP 神经网络模型、传统PSO-LSTM 模型相比,本文提出的PN-PSO-LSTM 模型补偿精度更高。
在FOG 诸多应用场景中,对实时性需求非常高,因为它直接影响系统的响应速度、稳定性和准确性,比如在航空航天、船舶和车辆导航系统中,需要实时获取和处理陀螺仪提供的角速度和方向信息,以确保航行的准确性和安全性。采用神经网络模型来提高补偿精度时,其巨大的参数量和模型深度导致无法在计算资源有限的硬件设备进行推理,如何满足FOG 实时性的需求是非常重要的研究课题。本文在综合考虑FOG 实际应用场景、模型参数数量以及模型输出精度后,为上述得到的优化模型提出了一套合适的压缩方案来解决神经网络对硬件资源消耗大的问题,包括知识蒸馏、参数剪枝、非线性函数线性化、定点数量化等方法。
神经网络的计算是高度并行的,而FPGA 具有可实现大规模并行计算的能力。FPGA 中的可编程逻辑单元和内部存储器可以同时执行多个计算任务,从而在神经网络的推理过程中实现高效的并行计算。此外,FPGA 还具有低延迟、低功耗、灵活性等特征,综上所述,本文采用Verilog 语言实现压缩模型,并在搭载Xilinx 某型芯片的FPGA 开发板上测试成功。压缩后模型相较于压缩前模型大小减小94.1%,补偿速度也比PC 端提升98.47%。
1 温度误差机理
在光纤环中,存在两束干涉光,分别按顺时针(Clock Wise,CW)和逆时针(Counter Clock Wise,CCW)方向传播。当环境温度发生变化时,光纤的折射率也发生变化,导致两束光在经过距离端点处z的一段光纤基元dz时产生相位延迟,其计算公式如下:
式(1)(2)中,ϕcw(t)为顺时针光沿光纤环传输产生的相移;ϕccw(t)为逆时针光沿光纤环传输产生的相移;L为光纤环长度;n为光纤折射率,β0为光在真空中的传输系数,其值为2π/λ,λ为光波长,c为光在光纤环中传播的速度,T为光纤内温度,ΔT为光纤环z点处的温度变化量。式(1)与式(2)相减并化简得到光纤环温度变化产生的Shupe 误差为:
式(3)表明,环境温度引起的相位误差 Δϕ(t)与温度、温度变化率等有关。由IEEEStd952-1997 标准提供的单轴FOG 温度误差模型如下[9]:
式(4)中,E为温度误差,DT为漂移速率温度敏感系数,ΔT为温度变化,DdT为温度斜坡漂移速率敏感系数,dT/dt为温度变化率,为时变温度梯度漂移率敏感系数,为温度梯度。FOG 内部温度场分布的复杂性导致温度梯度的测量变得困难。因此,建立FOG 温度误差、温度以及温度变化率之间的关系,补偿FOG 的输出,提高FOG 的输出精度。
2 温度补偿模型改进
2.1 LSTM 算法
LSTM 是Hochreiter 等提出的RNN 的变体,其具有记忆长短期信息的能力。该模型引入门结构,将系统认为重要时刻的数据信息一直保留传递,而不像RNN 只保留上一时刻的数据信息,这对FOG 温度变化带来的误差有更好的补偿效果。相较于RNN,LSTM克服了机器学习中梯度消失和梯度爆炸的问题[10]。LSTM 单元的状态是由长期记忆单元和各个门控结构组成,其单元结构如图1 所示。

图2 LSTM 整体模型图Fig.2 LSTM over all model diagram
首先,定义长期记忆单元的值,记作c。在每个时间步骤t,LSTM 单元会接收到一个输入值xt和前一个时间步骤的状态值ht-1。然后,它会计算输入门it、遗忘门ft、数据输入gt和输出门ot的值,这些值由式(5)-(8)计算得出:
其中,Wi、Wf、Wg和Wo是权重矩阵,bi、bf、bg和bo是偏置向量,σ是sigmoid 函数。接下来LSTM单元会更新长期记忆单元ct的值,使用式(9)计算得出:
其中,⊙表示对应相乘,ct-1表示上一时刻的长期记忆单元值。最后LSTM 单元会根据输出门ot和长期记忆单元ct的值,计算当前时刻的输出值ht:
这样LSTM 模型可以自适应地选择何时读取或遗忘过去的信息,以及何时输出当前的信息。对于FOG温度补偿模型,由于温度是连续的数据,LSTM 模型可以保留整段温度参数中对系统影响最大的数据,来更好地补偿修正FOG 零偏输出。本文以温度和温度变化率作为输入,温度补偿值作为输出,一层LSTM 层,一层FC 层进行建模。
LSTM 模型在训练时需要人为调整的超参数有学习率,神经元个数,通过试凑法往往导致训练结果陷入局部最优解,本文采用改进PSO 算法来优化LSTM温度补偿模型。
2.2 PSO 算法
PSO 算法的基本原理是通过模拟生物群体中个体间的信息交流和协作来搜索最优解。算法中的“粒子”是搜索空间中的一个候选解,每个粒子都有一个位置和速度向量,表示它当前的搜索状态和搜索方向。每个粒子根据自身经验和群体经验来更新自己的速度和位置,以期望更好地搜索到全局最优解[11]。
基本流程为:
(1)随机生成一定数量的粒子,粒子的位置向量中包含了LSTM 模型中待优化的超参数,并随机给定它们的初始位置和速度。
(2)分别使用每个粒子中的LSTM 超参数进行训练,根据训练结果与真实零偏输出计算均方误差(Mean Square Error,MSE)得到每个粒子的适应度。
(3)对于每个粒子,将其适应度与其历史最优位置的适应度相比,若更好就替代其位置成为历史最优位置。再从所有粒子的历史最优位置中,选择全局最优位置。
(4)根据式(11)(12),更新每个粒子的速度和位置,其中ω、c1、c2分别为惯性权重、个体学习因子和社会学习因子,r1、r2为[0,1]范围内均匀分布的随机数:
其中,vk表示第k次粒子的速度,xk表示其位置,表示其个体历史最优位置表示全局最优位置。
(5)判断是否满足停止条件(如达到最大迭代次数或目标函数值小于某个阈值),如果满足,则算法结束;否则,回到第(2)步。
2.3 PN-PSO-LSTM 算法
在标准的PSO 里,惯性权重ω,个体学习因子c1,社会学习因子c2分别都是固定的一个经验值,这无法保证系统在寻优过程中既满足大范围搜寻的同时又尽可能稳定地收敛,因此带来了局限性。惯性权重控制PSO 算法中探索和开发之间的平衡。更高的惯性权重意味着粒子将更频繁地移动到新的邻域,增加探索。另一方面,较小的惯性权重可以使粒子保持在相同的邻域附近,并在其中寻找最优解。针对ω,文献[12]提出采用线性变换ω代替固定值,但是其搜寻能力和收敛稳定性有限,本文采用式(13),即分段非线性ω代替标准PSO 算法里的ω:
式(13)中,ωmax、ωmin为惯性权重的最大值和最小值;Tmax为最大迭代次数;k为当前迭代次数。如图3 所示,对比传统线性变换ω,采用式(13)时,ω在寻优初始阶段从ωmax更加缓慢地减小,可以在初始阶段保持一个较大的值,使系统尽可能探索更多的领域;在寻优结束阶段,ω减小到ωmin的变化率也更加平缓,使粒子在结束阶段时能尽可能在自身附近寻优,系统更加稳定。
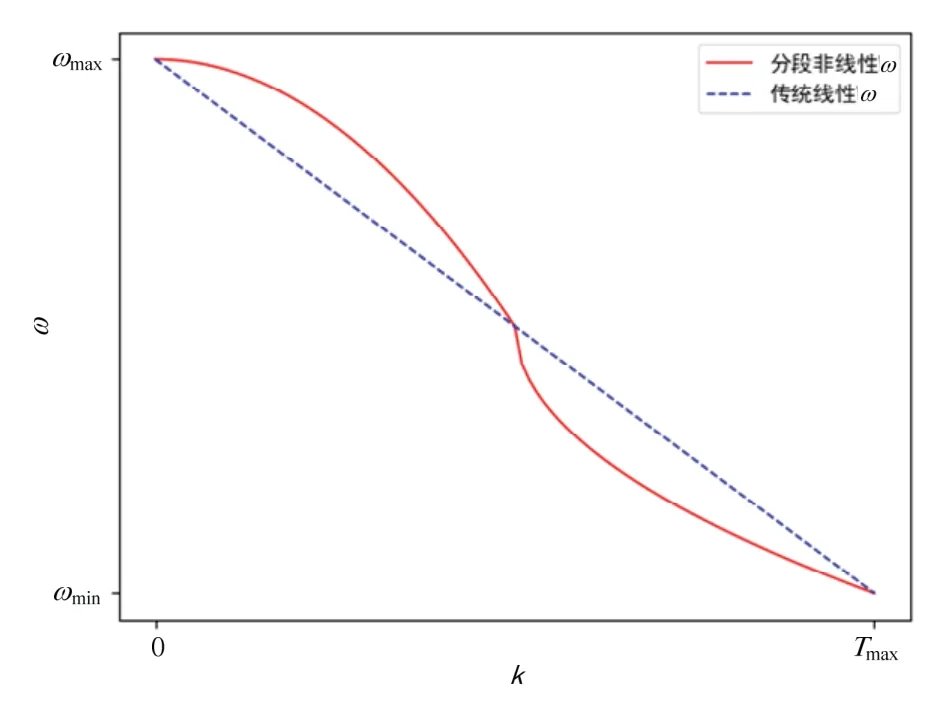
图3 ω 随迭代次数k 变化图Fig.3 Graph of ω changing with number of iterations k

图4 PN-PSO-LSTM 算法流程图Fig.4 PN-PSO-LSTM algorithm flowchart
当增大c1时,会增强粒子的个体认知能力,但是收敛速度缓慢;当增大c2时,会增强粒子的社会认知能力,收敛速度迅速,但是极易使算法早熟。为了保证PSO 算法的搜索能力和协调粒子的个体认知及社会认知能力,采用与构建ω相同的方法,将c1、c2的取值与粒子当前的迭代次数联系起来。其函数表达式为:
式中,c1max、c1min、c2max和c2min为c1、c2的最大值和最小值;Tmax为最大迭代次数;k为当前迭代次数。
2.4 实验对比
在本实验中,将课题组某型FOG 置于温箱的水平转台上,FOG 敏感轴指向天顶,并将温度设定为-20℃,温箱变温速率配置为4℃/min,随后逐渐升温至60℃,每隔一秒采集温度数据和FOG 输出数据。先在相同的条件下进行两次实验,得到两组数据。其中一组数据用作训练集,另一组数据用作测试集,再在不同温变速率下分别进行一组升温实验和降温实验,得到二组数据作为验证集,来验证温度补偿模型在不同温度条件下的适应性。然后将得到的数据进行100 s 滑动平均,再经过归一化得到实验所需FOG 误差和温度数据,最后分别进行 BP 神经网络,PSO-LSTM,PN-PSO-LSTM 建模进行补偿,得到实验结果如下。
图5、图6、图7 分别为采用BP 神经网络模型,传统PSO-LSTM 模型以及PN-PSO-LSTM 网络模型的训练结果,以及各模型对应的补偿结果。表1 显示了各模型的补偿MSE、零偏稳定性和角度随机游走,对比可得,PN-PSO-LSTM 网络模型补偿结果的均方误差相较于BP 网络模型降低74.4%,相较于PSO-LSTM模型降低53.5%;零偏稳定性相较于BP 模型降低48.8%,相较于PSO-LSTM 模型降低31.6%;角度随机游走相较于BP 模型降低49.6%,相较于PSO-LSTM模型降低30.4%,补偿效果均有较大的提高。图8、图9 为改变温度条件后,分别采用三种模型对FOG 零偏输出进行补偿的结果图,表2 为在升温条件下验证集上各模型的补偿MSE、零偏稳定性和角度随机游走,对比可得PN-PSO-LSTM 网络模型补偿结果的均方误差相较于BP 网络模型降低72.5%,相较于PSO-LSTM 模型降低59.4%;零偏稳定性相较于BP模型降低33.3%,相较于PSO-LSTM 模型降低29.1%;角度随机游走相较于BP 模型降低55.8%,相较于PSO-LSTM 模型降低41.0%;表3 为在降温条件下验证集上各模型的补偿MSE、零偏稳定性和角度随机游走,对比可得PN-PSO-LSTM 网络模型补偿结果的均方误差相较于BP 网络模型降低65.0%,相较于PSO-LSTM 模型降低57.0%;零偏稳定性相较于BP模型降低30.5%,相较于PSO-LSTM 模型降低28.6%;角度随机游走相较于BP 模型降低40.2%,相较于PSO-LSTM 模型降低35.7%。

表1 各算法效果对比Tab.1 Comparison of the effectiveness of various algorithms
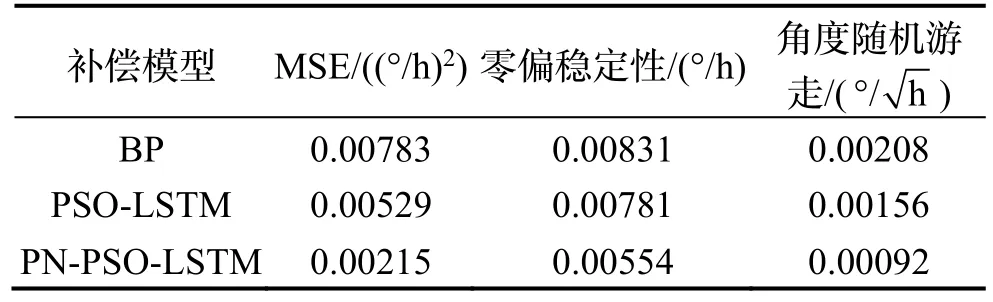
表2 验证集各算法效果对比(升温)Tab.2 Comparison of the effectiveness of various algorithms in the validation set with temperature rising

表3 验证集各算法效果对比(降温)Tab.3 Comparison of the effectiveness of various algorithms in the validation set with temperature decreasing
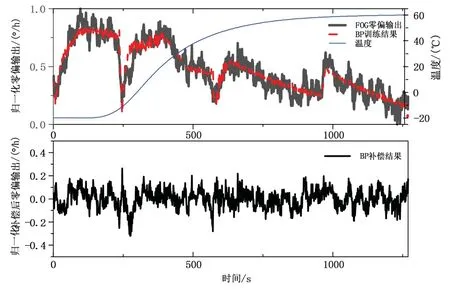
图5 BP 神经网络补偿结果图Fig.5 BP neural network compensation result diagram
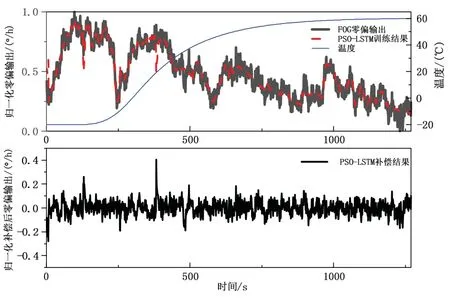
图6 PSO-LSTM 补偿结果图Fig.6 PSO-LSTM compensation result diagram

图7 PN-PSO-LSTM 补偿结果图Fig.7 PN-PSO-LSTM compensation result diagram

图8 升温条件下各模型补偿效果图Fig.8 Compensation effect diagram of each model under heating conditions

图9 降温条件下各模型补偿效果图Fig.9 Compensation effect diagram of each model under cooling conditions
3 模型压缩
深度学习模型通常具有巨大的参数数量,需要大量的存储空间。对于移动设备、边缘设备和云平台等资源受限的环境,压缩模型可以减少存储需求,降低模型部署和传输的成本,对于实时应用场景至关重要。深度学习模型压缩是在保持模型性能的前提下减小模型的存储空间和计算成本的过程,可以为深度学习模型提供更广泛的应用场景[13]。
基于上一节训练好的模型,本文设计并实现了一套适用于FOG 应用场景的压缩方案。压缩方案包括:(1)知识蒸馏;(2)模型剪枝;(3)非线性函数线性化;(4)定点数量化。流程图如图10 所示。

图10 压缩流程图Fig.10 Compression flowchart
3.1 知识蒸馏
知识蒸馏是模型压缩的一种常用方法,最早是由Hinton 在2015 年首次提出并应用在分类任务上面。知识蒸馏中的大模型称为教师模型,小模型称为学生模型。来自教师型输出的监督信息称为知识,而学生模型学习迁移来自教师模型的监督信息的过程称为蒸馏。不同于一般的模型压缩,由于实时性的需求,FOG输出数据是单独连续的,所以模型补偿数据也需要单独连续,即神经网络模型在进行推理时不能像训练那样将多组数据进行打包输入。又因为LSTM 模型具有记忆特征,对于温度补偿误差来说,其训练与推理对输入数据的打包数量需要统一。这就导致了对实时性有要求的小模型在每次训练时需要单组数据进行输入,训练速度大大降低。对于上一节训练好的高精度模型,采用知识蒸馏的压缩方法训练得到小模型,这不仅解决了大模型训练时由于单组数据输入带来的训练速度缓慢问题,也比直接训练得到的小模型精度更高。经过知识蒸馏,神经元个数减少50%。
3.2 模型剪枝
模型剪枝是一种通过减少模型中不必要或冗余的参数和连接来压缩模型的技术,它的目标是在保持模型性能的同时减小模型的存储空间和计算成本。top-k剪枝方法是一种简单有效且具有高灵活性的剪枝方法[15]。本文采用top-k 剪枝方法,剪枝原理如图11 所示:基于式(5)-(8),一个输入维数为ni,输出维数为no的LSTM 层,有ht-1∈Rno×1,Wh∈Rno×no,先将Wh进行分组,每组c个元素,在c个元素中只保留绝对值最大的k个,其余赋0 值。在本文中,针对输入为2输出为16 的LSTM 层,在大量实验测试后,选取c=4,k=2 进行剪枝,最终Wh参数量减半,即Wh∈R8×16。同理,针对16 输入,1 输出的全连接层的权重也用相同剪枝方法,对于Wh与Wfc,参数量减少50%。至此,整体模型参数减少84%。

图11 Top-k 剪枝示意图Fig.11 Top k pruning diagram
3.3 非线性函数线性化
由于LSTM 模型中的非线性激活函数tanh 函数和sigmoid 函数需要复杂的指数运算,这些运算在FPGA上具有较高的计算复杂度,而分段线性函数仅需要简单的比较和乘法操作,计算复杂度较低,能够更有效地在硬件上实现。将非线性激活函数改为分段线性函数可以更好地适应硬件资源的分配和利用,提高FPGA 的效率。本文采用式(16)代替tanh 函数,用式(17)代替sigmoid 函数。
3.2 定点数量化
在基于PyTorch 框架下训练得到的LSTM 模型,其参数为32 位浮点数,浮点数计算需要更多的计算资源。相比之下,定点数计算可以使用更简单和高效的算术运算,减少了计算复杂度,提高了计算效率,本文采用线性量化将输入数据及各参数进行量化[16]。线性量化的原理由式(18)(19)给出:
其中W为原数据,m为整数位比特数,f为小数位比特数,因为是有符号数,最终Qm,f所占比特数为m+f+1。本文在综合考虑FPGA 内存占比和模型精度后,对参数采取12 比特量化,其中8 比特小数位,3 比特整数位,1 比特符号位。量化比特数与误差如表4所示。
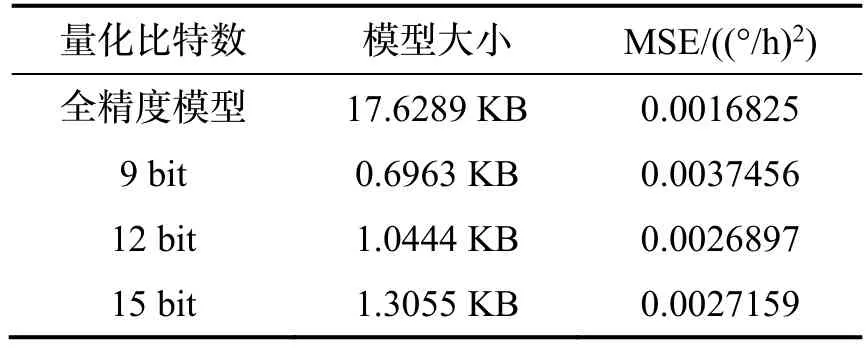
表4 量化对比Tab.4 Quantitative comparison
最终完成模型压缩后实验结果如图12 和表5 所示,在模型压缩后,其补偿误差仍然比BP 神经网络模型低59.4%,比传统PSO-LSTM 神经网络模型低26.1%。对比全精度PN-PSO-LSTM 模型,误差增加58.8%,模型大小减小94.1%。
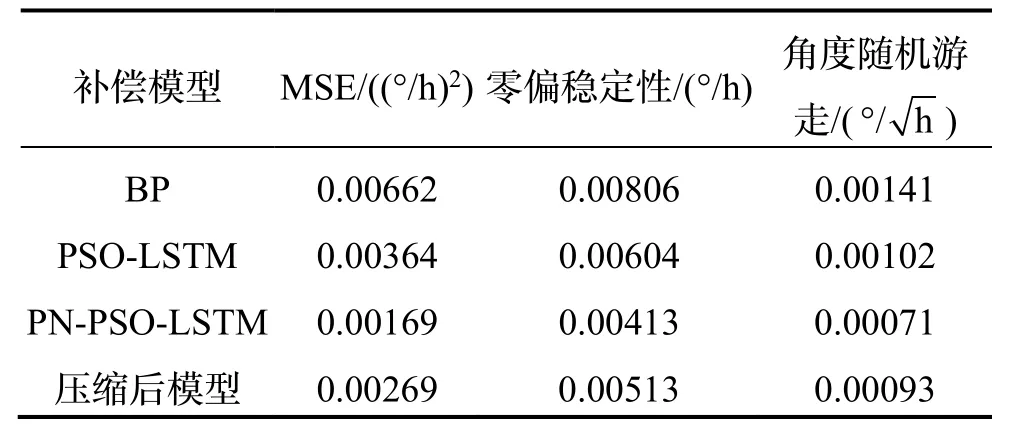
表5 压缩后效果对比Tab.5 Comparison of compressed effects

图12 压缩后模型补偿结果图Fig.12 Diagram of model compensation results after compression
4 FPGA 实现
基于Xilinx 公司某芯片,采用Verilog 语言实现压缩后的模型,整体系统框图如图13 所示,主要包括LSTM 模块和FC 模块[17]。其核心是采用使能信号控制的思想,完成式(5)~式(10)的运算。为保证中间运算过程数据精度的同时尽可能减少资源占比,通过大量实验测试,将输入数据位数设置为23 bit,最终运算结果位数保留为45 bit。

图13 系统整体框图Fig.13 Overall system block diagram
LSTM 模块设计框图如图14 所示。(1)首先将存有剪枝后非零权重的位置信息的数据以二进制格式存入Vivado ROM IP 核中,同时将上一时刻输出ht-1一起输入路复用器中,通过对比非零权重位置信息的数据,选择性输出与非零权重位置对应的ht-1值,而其余ht-1值将不会被输入计算。

图14 LSTM 设计框图Fig.14 LSTM design block diagram
(2)再将权重数据Wi、Wf、Wg和Wo,偏置数据bi、bf、bg和bo也存入ROM IP 核中,结合输入xt一起传入矩阵向量乘法器中,xt先与Wi、Wf、Wg和Wo进行矩阵乘法运算,再与对应偏置相加得到计算结果。然后经过激活函数的运算,原本非线性激活函数经过第3 节线性化之后,只需要进行简单移位运算和加减法运算即可,最后经过激活函数运算可得it、ft、gt、ot四个门控值,即完成了式(5)~式(8)的运算过程。
(3)将输出it、ft、gt输入C 运算单元,同时将上一时刻ct-1从移位寄存器中输入C 运算单元,ft和ct-1完成对应相乘运算,it和gt完成对应相乘运算,然后再将两结果相加,可计算得到ct,即完成了式(9)的运算过程。
(4)将ct输入移位寄存器保存,以便与下一时刻的各数据计算,同时将ct、ot输入H 运算单元,在H运算单元中,ct先经过激活函数tanh,计算过程与第(2)步中激活函数运算一样,计算结果再与ot对应相乘,得到ht。
(5)将H 运算单元运算结果ht输入移位寄存器,以便与下一时刻各数据进行计算。
(6)移位寄存器输出ht给FC 模块,同时回到(1),进行循环计算。
FC 层结构和LSTM 模块相似,直接将FC 层权重、偏置、非零权重位置信息以及LSTM 层ht输入矩阵向量乘法器,最终输出即为整体模型输出结果。Vivado2018.3 仿真结果如图15 所示,由于FPGA 运算过程中对数据位有截断,所以推理结果与PC 端有些许误差,推理结果对比如图16 所示,误差对比如表6所示。可见推理结果与PC 端推理结果相比误差可忽略不计。

表6 FPGA 输出结果对比Tab.6 Comparison of FPGA output
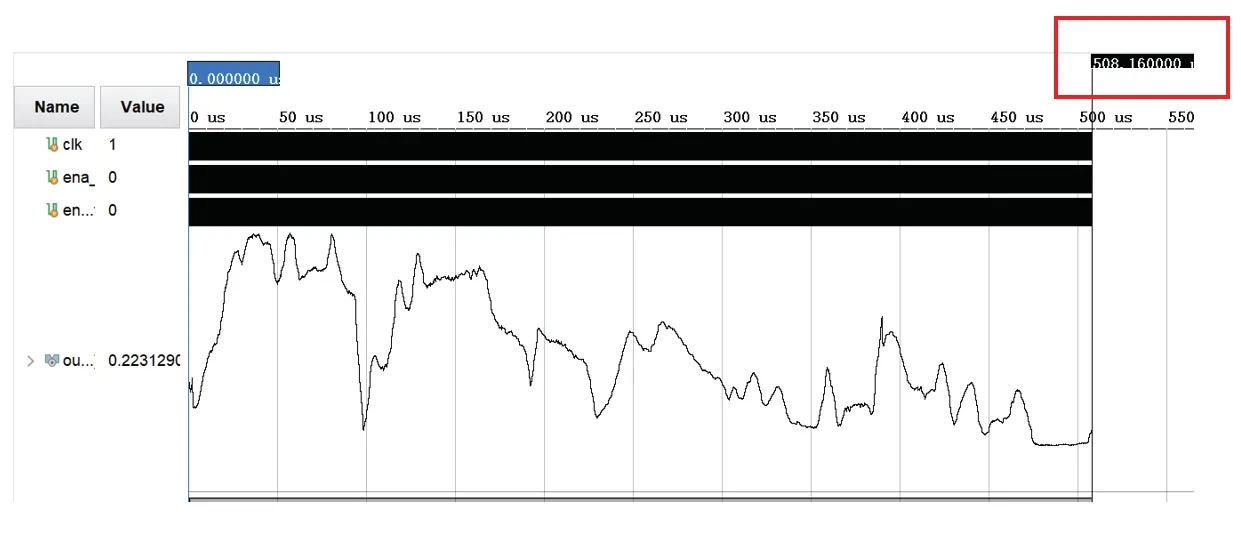
图15 Vivado 仿真结果Fig.15 Vivado simulation results
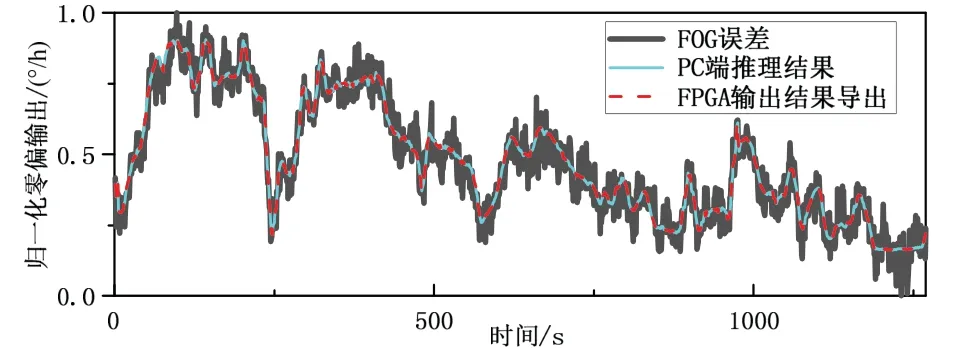
图16 FPGA 输出结果与PC 对比图Fig.16 Comparison between FPGA output results and PC
在速度方面,PC 端i7-13700CPU 推理速度为33.2 ms,而在FPGA 中,本文对时钟的配置为50 MHz,图17 为时序报告表,其中WNS 表示最差负时序裕量,意味着在实际需求的时钟周期内有额外的2.114 ns 来满足时序要求,所以实际运行周期是满足配置的时钟周期的,完整推理时间为0.508 ms,速度对比PC 端i7-13700CPU 提升98.47%。资源占比如表7 所示,可见充分合理利用了该FPGA 开发板的资源。

表7 资源占比Tab.7 Resource proportion

图17 时序报告Fig.17 Timing report
5 结论
本文通过分析 FOG 温度误差特性,提出PN-PSO-LSTM 温度补偿模型,对比传统BP 神经网络模型陀螺输出零偏均方误差降低74.4%,相较于PSO-LSTM 模型均方误差降低53.5%。在此基础上,针对FOG 温度补偿实时性的需求,设计了一套模型压缩方案,在模型大小减小94.1%的同时,误差仍然比传统全精度模型更低。最后,对比PC 端i7-13700CPU,压缩模型部署在FPGA 上后推理速度提升98.47%。综上,本文实现了PN-PSO-LSTM 全精度温度补偿模型及相应的压缩小模型,并完成了压缩小模型的FPGA部署。针对不同的硬件资源和工程需要,可将全精度模型应用于硬件资源充裕且精度要求苛刻的场景,压缩小模型应用于硬件资源受限且精度标准相对宽松的场景。
