切入场景下基于碰撞风险聚类的改进车速预测方法
2024-02-05周世亚姜文龙史立峰
马 彬,周世亚,姜文龙,史立峰,赵 宇
(1.北京信息科技大学 机电学院, 北京 100192;2.新能源汽车北京实验室, 北京 100192;3.北京电动车辆协同创新中心, 北京 100192;4.中国人民公安大学 交通管理学院, 北京 100038;5.中国公路车辆机械有限公司, 北京 100010;6.天津中德应用技术大学 汽车与轨道交通学院, 天津 300350)
0 引言
随着智能汽车的发展,自动驾驶汽车的行驶安全成为一个重要的关注点。其中,统计结果显示,换道、超车等切入场景发生交通事故的比例为4%~10%。因此,提高换道、超车等自动驾驶汽车的行驶安全具有重要意义[1]。当前基于自车的车速预测并结合碰撞风险指标已经能够提高换道、超车的安全性[2],但在目标车辆切入过程中无法针对周车行为做出及时决策[3],限制了自动驾驶安全性的提升。研究结果显示,考虑车车耦合碰撞风险预测的车速预测可以进一步提高自动驾驶车辆的行驶安全性,解决切入场景下车辆行驶的不确定性问题。
当前,碰撞风险预测的研究方法主要分为基于速度的预测和基于轨迹的预测。在基于轨迹的碰撞风险预测方面,Wang等[4]基于LSTM进行周围车辆的轨迹预测,并将风险评估指数作为车辆风险评估的基本指标,实现了对碰撞风险的实时估计。Wang等[5]采用通用迭代的方式进行轨迹预测,通过加速度计算下一时刻速度,生成速度轨迹。然而,上述轨迹预测方法在预测时域内基于恒速假设,计算出的TTC在实际驾驶场景中由于车车耦合具有短期非线性特征存而存在较大误差。基于速度的预测可以提高碰撞预测的准确性。而危险工况下的车速预测主要包括道路运行时切入切出等快变工况和交叉口内的车速预测。宋传杰等[6]通过对事故数据的多元线性回归提取特征要素,并采用马尔科夫链和循环神经网络实现了道路运行时平稳工况和快变工况下前车车速预测。马莹莹等[7]建立了基于神经网络的无信号控制交叉路口内车速预测模型,拟合了车辆通过交叉路口的速度与其影响因素之间的复杂关系,提高了交叉路口内的车速预测精度。史立峰等[8]提出了一种基于参数自适应调整的在线径向基函数神经网络的车速预测方法,实现了车速的高精度预测。然而,线性回归无法捕捉到复杂数据的非线性模式,神经网络则过度依赖数据质量。此外,数据来源多依赖于昂贵的车载及路侧传感器设备,全场景的数据提取目前需要人为实现,限制了神经网络等机器学习的进一步使用。因此,低成本、高精度车速预测方法是目前的发展方向。其中,差分自回归移动平均(ARIMA)模型在时间序列预测方面具有显著优势[9]。Cadenas等[10]利用ARIMA模型进行了风速预测,Guo等[11]基于ARIMA模型完成了车辆循环工况的道路坡度和车速预测,Fan等[12]结合ARIMA和LSTM实现油井产量的预测,郭兴等[9]使用变阶ARIMA模型提高了车速的预测精度。
然而,当前车速预测忽略了车车耦合等典型非线性场景对自车速度变化的影响。在目标车辆的切入场景中,考虑周围车辆的行驶状态能够有效避免碰撞发生。研究结果表明,基于支持向量机(SVM)、隐Markov模型(HMM)等机器学习算法能够有效识别和捕捉车车耦合等场景的典型非线性特性。崔格格等[13]通过构建动静态要素属性与要素之间隐含交互关系的图特征,建立了基于SVM的驾驶员个性化危险场景识别模型,提高了模型识别的准确率。张海伦等[14]基于双层HMM模型,完成了高速场景下相邻前车换道行为的识别,并考虑相邻前车与周围环境车辆的交互作用来预测驾驶人的换道意图,且模型仿真计算时间满足系统实时性的需求。
然而,上述研究虽然基于机器学习算法实现了对车车耦合风险的在线识别,但均缺少危险工况下对自车速度的改进。因此,本文中提出了一种结合SVM和ARIMA模型的改进车速预测方法,旨在降低车辆的碰撞风险,提高车速的预测精度并改进车辆在切入场景下的车速的预测效果。以碰撞时间(TTC)作为评价指标,对改进前后的风险进行评估。最后,利用自然驾驶数据在Matlab环境下进行多工况的仿真,验证了文中所提方法能够有效提高自车的速度预测精度,并降低前车切入场景下的碰撞风险。
1 车速预测方法及数据准备
为提高自动驾驶汽车切入工况的安全性,开展了基于车车耦合风险聚类的切入场景自车速度高精度预测方法的研究。首先,依据实验所得自然驾驶数据进行车辆切入切出片段提取,使用K-means方法,在确定特征向量的基础上进行车车耦合碰撞风险聚类分析。其次,基于支持向量机SVM模型,对切入切出工况车车交互状态进行在线识别,对切入危险工况进行实时预测;提出基于ARIMA的车速预测方法,并结合在线识别结果进行车速在线优化。所提出的基于碰撞风险聚类的改进车速预测方法,框架如图1所示。
本文中采用的自然驾驶数据由实车测试所得。车载自然驾驶数据采集系统如图2所示。
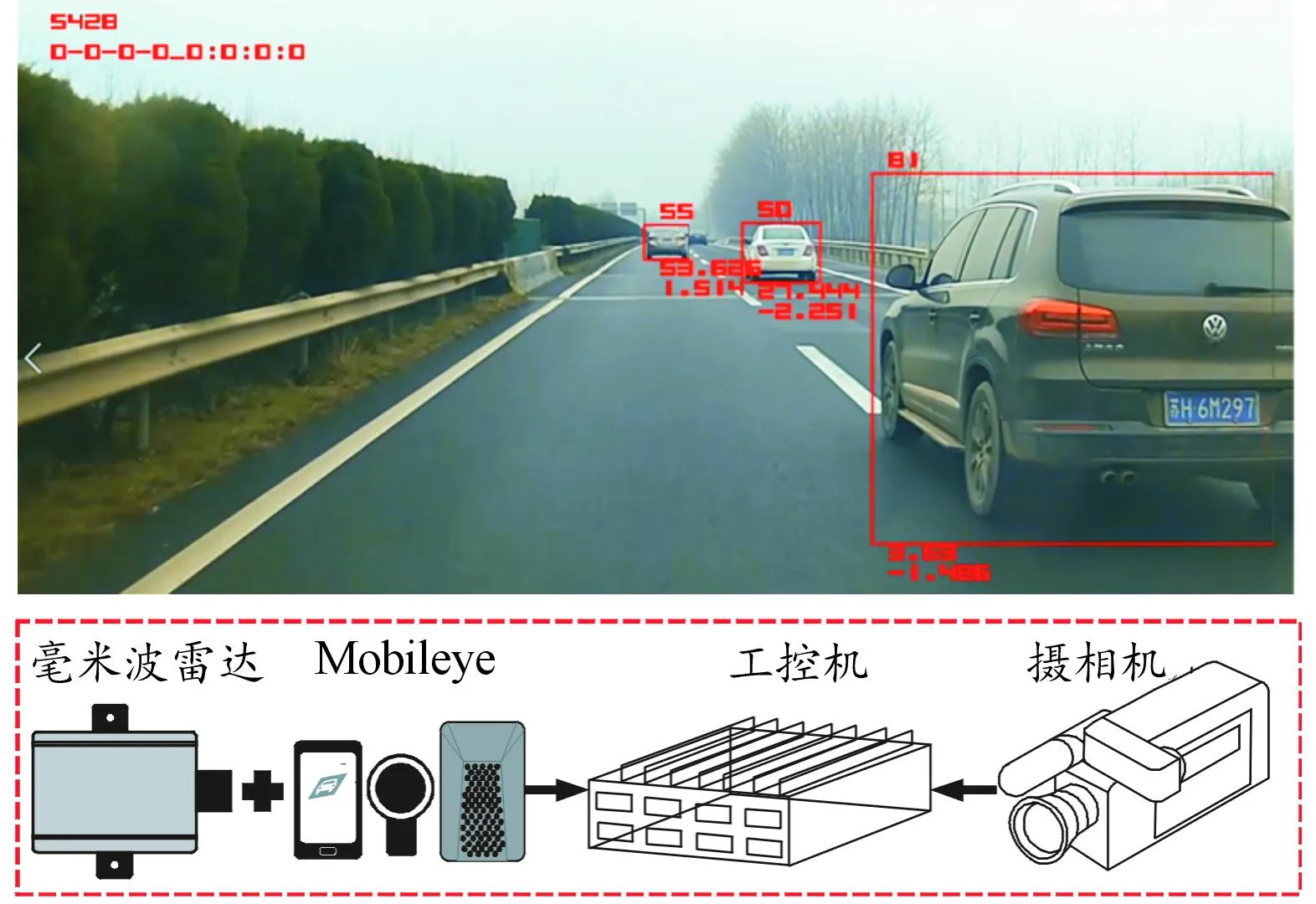
图2 自然驾驶数据采集系统示意图
实车采集设备包括Mobileye、毫米波雷达、摄像机和车载GPS。其中,CAN总线采样频率为25 Hz,用来获取车辆的位置、纵向速度、纵向加速度、横向加速度、转向角和制动情况;毫米波雷达、摄像头等用来获取自车与周围车辆之间的相对纵向位置、相对横向位置、相对纵向速度、相对横向速度等信息。
为保证数据分析结果,对采集的数据噪声进行去噪处理。常用的数据去噪方法主要有均值滤波、卡尔曼滤波和Savitzky-Golay(SG)滤波[15]等。SG滤波可以在平滑数据的同时保留数据的趋势和形状,因此选用SG滤波器对所采集到的自然驾驶数据进行处理,SG滤波器的表达式为:
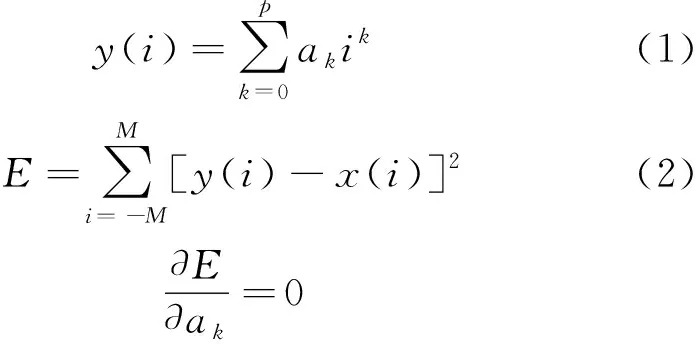
(3)
式中:M为在原始数据x(i)附件选取的采样点个数;p为多项式y(i)的阶数;E为数据拟合误差;i=-M,…,0,…,M,p≤2M+1,k=0,1,2,…,p。
采集的自然驾驶数据中原始速度和加速度信息在经过SG滤波后的数据结果如图3所示。由结果可知,经过滤波之后的数据变得更加平滑的同时也保留了数据的趋势和形状。后文选用滤波后的数据进行车车耦合风险分析和车速预测。
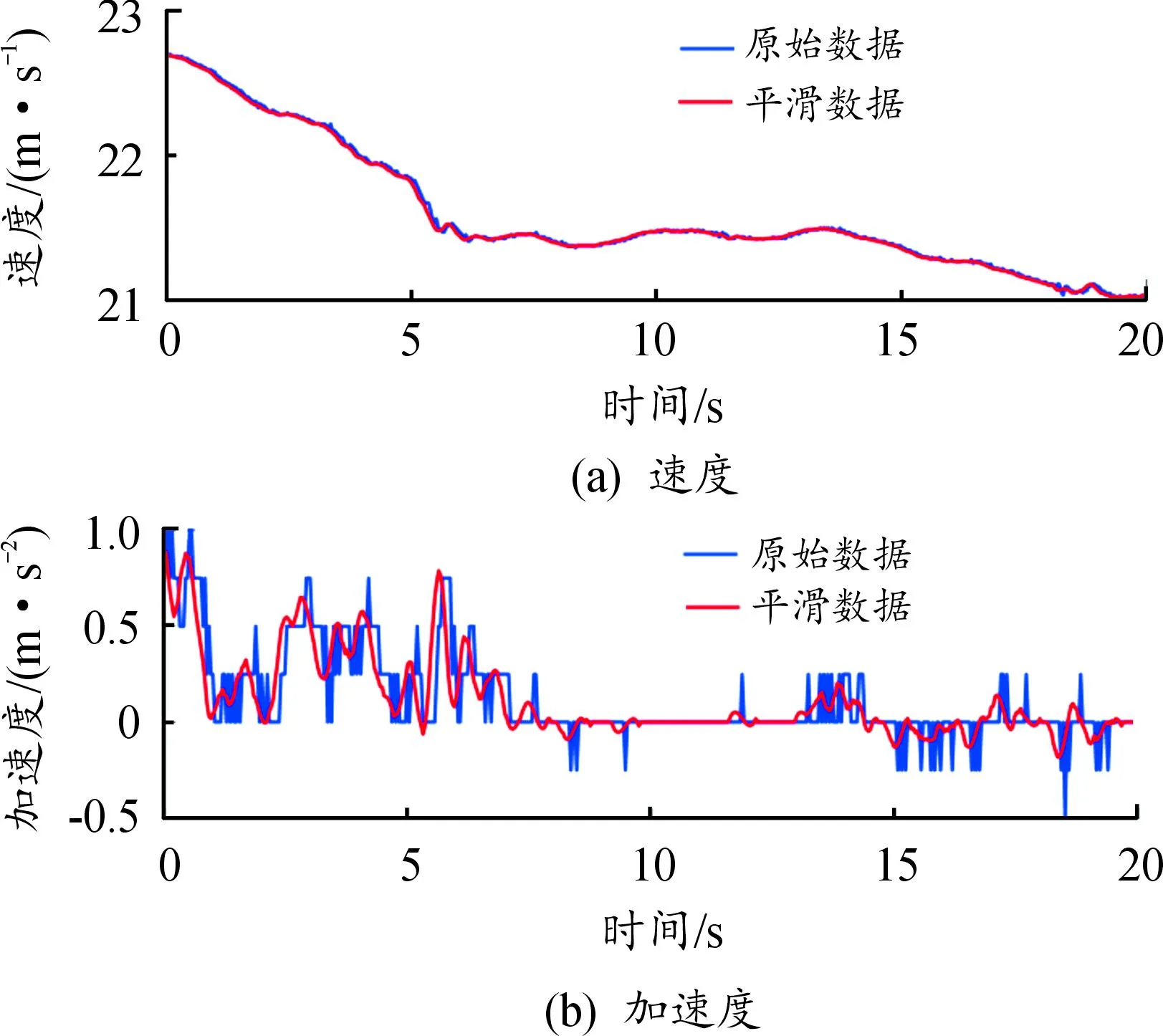
图3 车速和加速度SG滤波结果
2 基于SVM的车车耦合场景识别
2.1 切入切出场景提取
为研究切入场景下碰撞风险等级与加速度之间的关系,进行了不同速度及路况下切入切出场景的实车数据采集。其中,切入标准场景如图4所示。
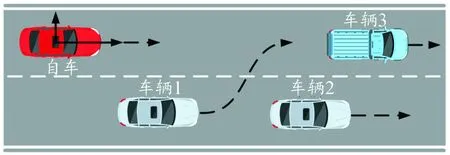
图4 标准场景下车辆切入示意图
将车辆的切入或切出过程划分为准备和稳定2个阶段[16],以横向距离和纵向距离作为切入或切出数据长度的划分指标。例如,目标车辆切入前与自车不在同一车道,所以,此时两车间的横向距离满足2.0 m≤|Y|≤3.5 m[5],在切入完成后,目标车辆与自车的横向距离间距满足|Y|≤1.2 m[17]。同时,考虑到拥堵、停车、等红灯以及距离较远的车辆对自车的影响,所以纵向距离满足5 m≤X≤120 m,以此来消除对结果造成干扰的切入切出行为。根据挑选原则,从采集到的自然驾驶视频数据中筛选出包含车辆切入和切出场景的数据片段,共得到50个案例。其中切入场景占比为70%,切出场景占比为30%。
2.2 基于K-means的车辆切入风险聚类
2.2.1K-means聚类方法基本原理
K-means聚类算法是一种经典的无监督机器学习算法[18],具有良好的可扩展性。K-means聚类算法使用距离作为相似性的评价指标,从给定的n个样本点x1、x2、…、xn中随机选取k个点作为初始聚类中心c1、c2、…、ck,应用迭代思想,不断移动聚类中心直到聚类误差函数收敛或达到最大迭代次数为止[19],计算公式如下:
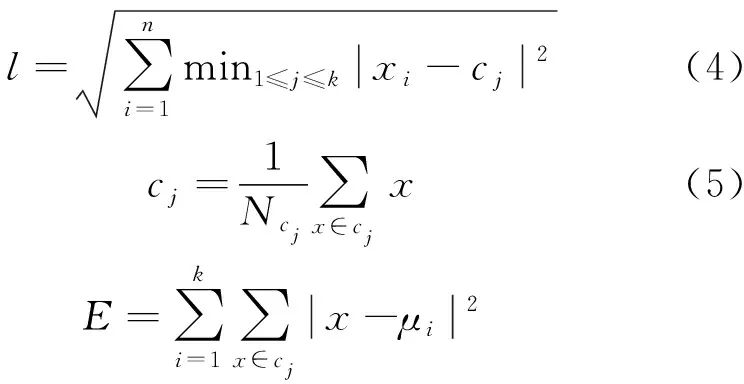
(6)
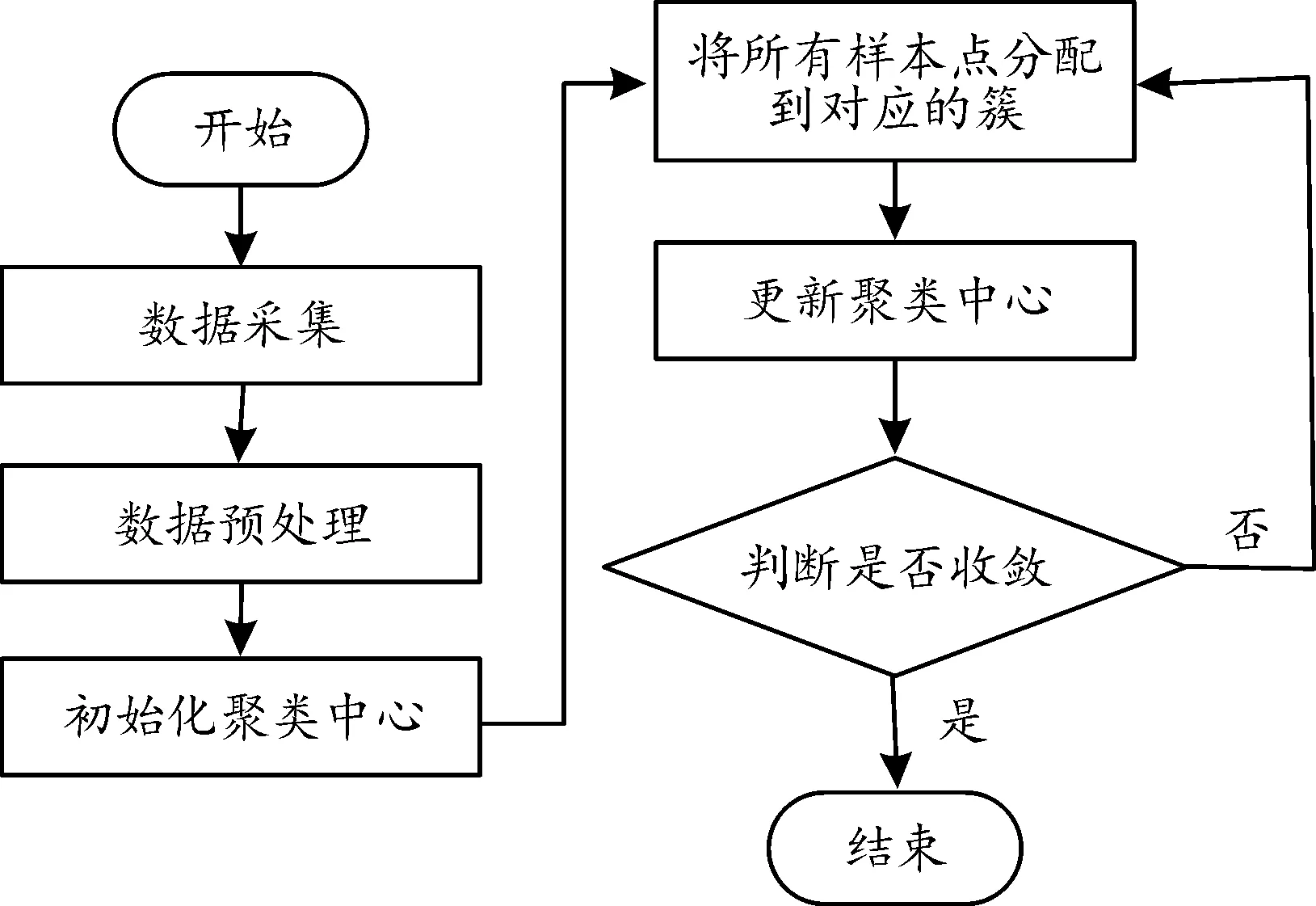
图5 基于K-means的车辆切入风险聚类流程
2.2.2 特征参数的选择
特征参数的选取对实现精确风险聚类具有重要影响。特征参数的选择越多,所包含的车辆信息也就越丰富,但过多的特征参数会增加计算负担进而影响计算效率和车辆的响应速度[18]。因此,根据车车耦合的关系,选取了平均加速度、平均纵向距离、碰撞时间(TTC)和车头时距(THW)作为特征参数,来表达不同场景下目标车辆的切入特征。
1) 平均加速度为目标车辆切入过程中速度变化的平均值。该参数有效揭示了目标车辆在不同切入场景下的速度变化的大小。
2) 平均纵向距离在切入场景中自车与目标车辆间的平均纵向距离会受到车速、车辆类型等多因素的影响,能有效表达不同切入场景下的距离特征。
3) TTC是用于评估车辆间距离和速度差的量化指标。在不同的切入场景中,TTC可用来评估目标车辆切入过程的安全性。其计算公式如下

(7)
式中:D为前车和自车的相对纵向距离,m;Vr和Vf分别为自车和前车的速度,m/s。
4) THW(time to hazard warning)是指发现潜在危险到系统发出警告的时间,在切入场景中用来表征对不同切入场景的危险认知程度。
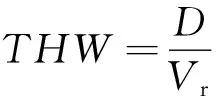
(8)
2.2.3 车辆切入风险的K-means聚类分析
根据上述所选择的特征参数,采用K-means聚类算法,对所提取的切入切出场景数据进行风险聚类。聚类结果分为前车加速切出,前车匀速切出,前车加速切入,自车减速避让,自车紧急避让5类。最终的聚类结果如图6所示,得到聚类结果与加速度之间的关系,如图7所示。
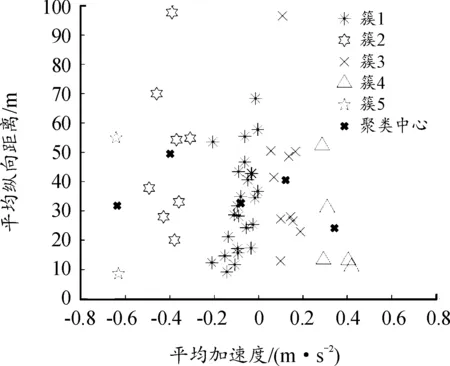
图6 基于K-means算法的聚类结果

图7 K-means的聚类结果与加速度之间的关系
聚类结果与自车加速度范围如表1所示。通过对切入场景下车车耦合关系的风险聚类分析,建立了碰撞风险等级与加速度的关系模型,为预测车速的改进提供了理论依据。

表1 聚类结果与加速度范围
2.3 基于SVM的风险场景识别
支持向量机SVM是一种常见的机器学习算法[20],常用于分类和回归问题。SVM的基本思想是在特征空间中找到一个超平面(或多个超平面)作为决策曲面,将不同类别的样本分隔开来,并使得离超平面最近的样本点到超平面的距离最大化,其分类原理如图8所示。

图8 基于SVM的分类模型
SVM最早用于解决线型可分的二分类问题,假设SVM的训练样本为:
{(xi,yi),i=1,2,…,l},x∈Rn
(9)
式中:yi∈{-1,1}由2类构成:xi为特征输入,若xi属于第一类,记yi=1;若xi属于第二类,记yi=-1。找到图8所示的分类超平面wx+b=0,将集合内的数据正确分类,则该集合需要满足:
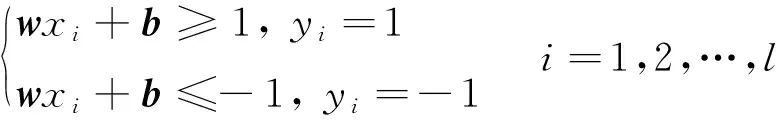
(10)
式中:距离超平面最近的几个样本称之为支持向量,b为偏置,确定了超平面和坐标原点之间的距离;w=(w1,w2,…,wd),为可调权重向量,它决定了超平面的方向;则任意一点xi到超平面的距离为:

(11)
则超平面之间的最大间隔为:

(12)

(14)
式中,ai为Lagrange系数。
在多数情况下,数据并不是线性的,这时候无法找到图8所示的超平面。此时,需要将特征输入映射到高维空间中,并构造高维空间中的最优超平面,引入适当的核函数k(xi,yj)将低维空间中的非线性问题转换成高维空间的线型问题,此时最优超平面的目标函数变为:
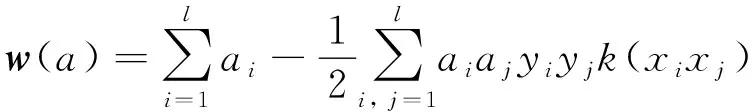
(15)
构建基于SVM方法的车车耦合场景在线识别模型,以所选取的特征参数和基于K-means的聚类结果作为SVM算法的输入和输出,识别当前场景下目标车辆切入过程中的风险状况。为验证SVM风险识别准确性,在提取的切入切出场景中随机产生训练集和测试集,其识别结果如图9所示,识别准确率为97.611%,验证了基于SVM的车辆切入风险识别模型的有效性和可靠性。
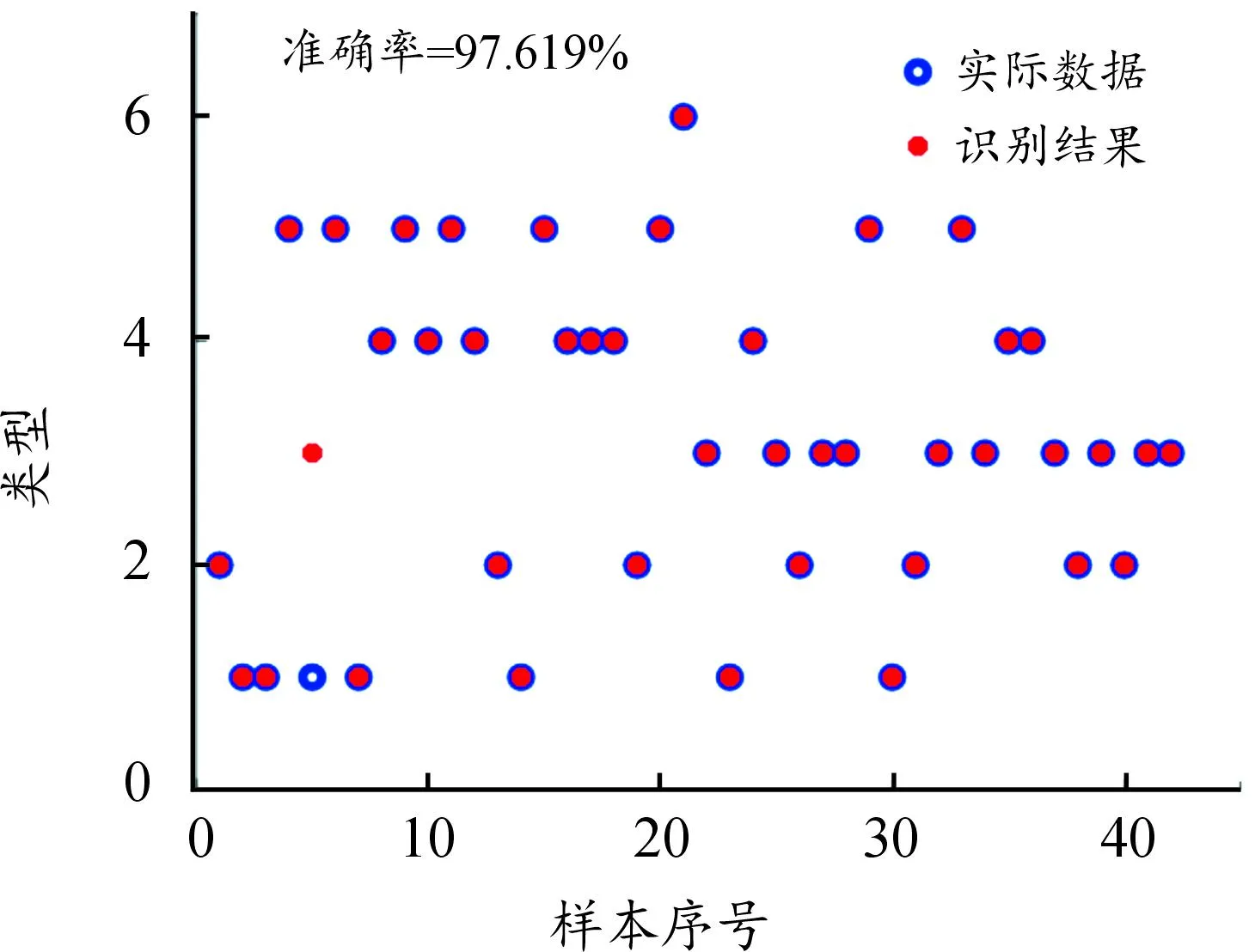
图9 基于SVM算法的车辆切入风险识别结果
3 基于ARIMA模型的改进车速预测方法
3.1 ARIMA模型车速预测方法
ARIMA模型是一种用于时间序列预测和分析的统计模型,因其具有灵活、简易与精度高的特点得到广泛应用。ARIMA模型首先进行白噪声检验,将非平稳的时间序列经过差分处理得到平稳的时间序列。在建立模型时,ARIMA仅考虑因变量的当前值和滞后值,以及随机误差项的当前值和滞后值,并进行回归运算来建立模型,其数学表达式为:
yt=c+φ1yt-1+φ2yt-2+…+φpyp-1+
εt+θ1εt-1+…+θqεt-q,t∈Z
(16)
式中:p表示自回归(AR)的模型阶数;q表示移动平均(MA)的模型阶数;εt-1,εt-2…,εt-q是误差项;c是常数;φ1,φ2,…,φp表示AR模型的系数;θ1,θ2,…,θq表示MA模型的系数。
本文中以自车的历史速度序列作为ARIMA预测的输入,并采用滑动时间窗口将时间序列数据分割为多个子序列,以捕捉目标车辆切入过程中,自车速度变化的关键信息,从而提高自车速度的预测精度。
ARIMA模型速度预测的输入数据为自车的历史速度序列X,输出为预测的速度序列Y。
X=[V1,…,Vt-1,Vt]
(17)
Y=[Vt_1,…,Vt_pre-1,Vt_pre]
(18)
式中:Vt_1,…,Vt_pre-1,Vt_pre为预测时域内自车的速度;Vt为t时刻车辆的速度。
在传统ARIMA模型速度预测的基础上,基于碰撞风险的改进车速预测方法的步骤为:
1) 根据SVM算法对当前切入场景下车车耦合风险的在线识别结果,以及风险等级与加速度的匹配关系,得到预测时域内自车加速度
a=[a1,…,aprf]
(19)
2) 根据加速度的匹配关系,进行预测时域内的速度改进,具体改进规则为
Yipv=[Vtf1+a1,…,Vtfpre+apre]
(20)
3.2 ARIMA模型车速预测方法性能分析
为验证ARIMA模型车速预测效果,采用传统LSTM及RBF预测方法进行对比分析。由于车辆驾驶行为具有一定的内在规律,如图10所示,对所选取的切入切出场景的速度和加速的进行分析,当车速低于20 km/时,车辆的加速度多处于-0.4~0.4 m/s2。
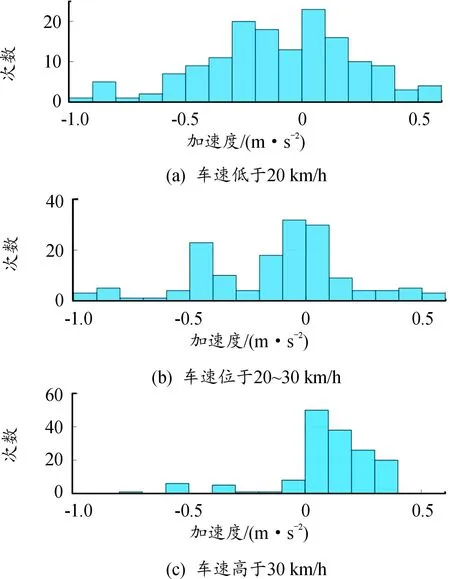
图10 切入切出场景下不同速度区间的加速度分布
当车速在20~30 km/h时,车辆的加速度多分布在-0.2~0.2 m/s2。而当车速高于30 km/h时车辆的加速度多集中在-0.1~0.4 m/s2。这也正是使用LSTM等神经网络预测模型所需学习和模拟的特性[21]。因此,本文中选用不同场景下的自然驾驶数据作为训练集,对LSTM神经网络模型进行离线训练,以保证使用样本的合理性。同时,利用自车过去10 s内的历史数据,以0.4 s为时间间隔作为LSTM的测试集以及RBF模型和ARIMA模型的输入,预测未来2 s内的车速。此外,本文中采用均方根误差(RMSE)作为速度预测精度的评价指标。其预测结果及RMSE的对比结果如图11—图13所示。

图11 高速区间的车速预测结果及RMSE曲线
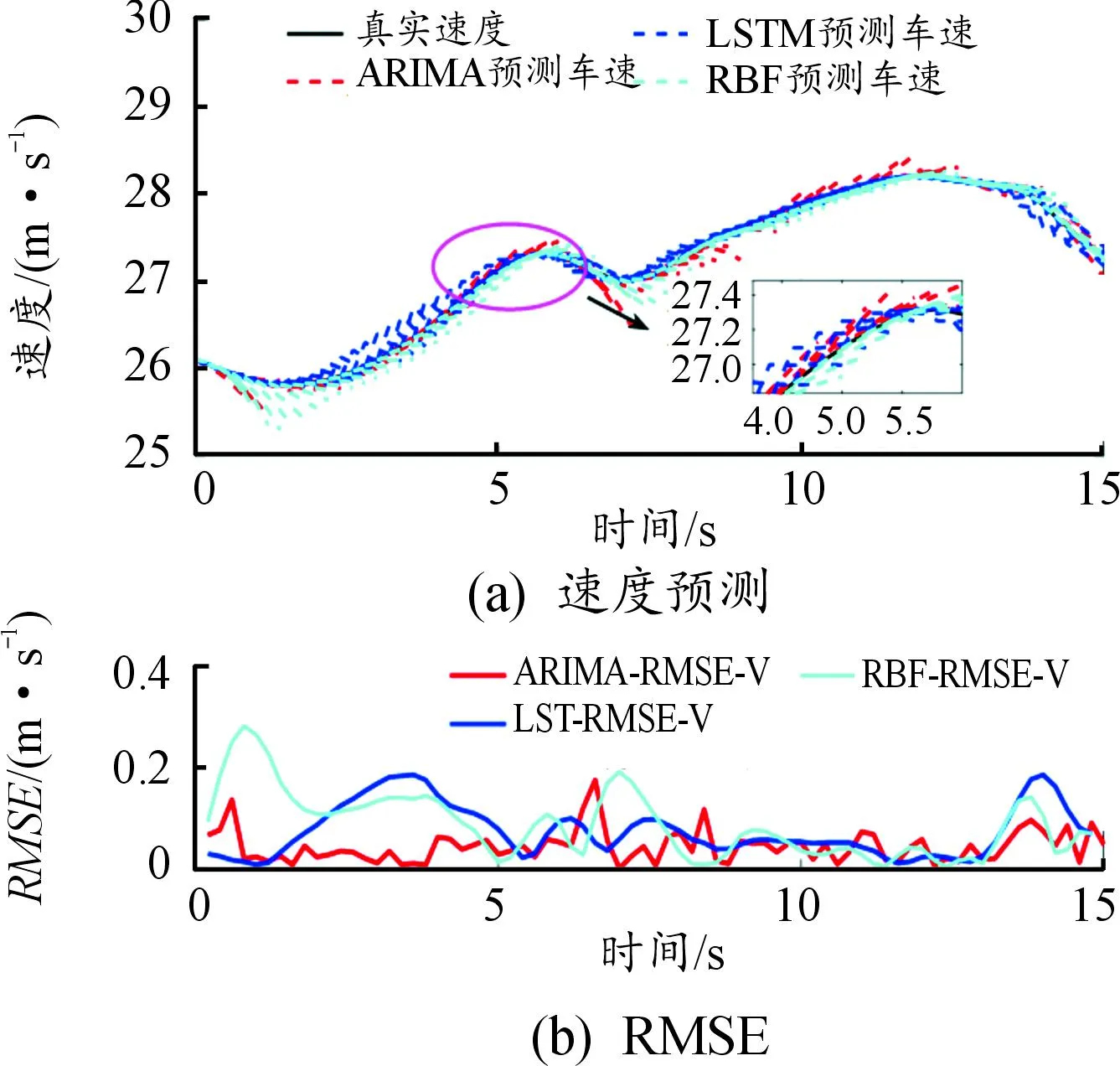
图12 中速区间的车速预测结果及RMSE曲线
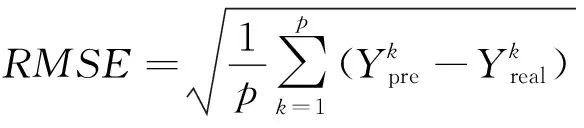
(21)

由预测结果的RMSE对比可知,尽管ARIMA、LSTM及RBF预测结果的RMSE都在1 m/s以内,但ARIMA的预测结果比LSTM和RBF误差更小,精度更高。此外,LSTM需要不同场景下的自然驾驶数据进行离线训练,而 ARIMA仅需要自车过去10 s内的历史数据即可实现更高精度的车速预测效果。因此,ARIMA模型在处理小样本高精度的车速在线预测问题时具有更大的优势。
3.3 基于碰撞风险聚类的改进车速预测
选取目标车辆匀速切入、目标车辆减速切入、目标车辆加速切入3种不同场景对本文中算法进行验证,以说明改进速度预测方法的准确性。改进的速度预测结果如图14—图16所示。

图14 目标车辆减速切入场景速度预测结果曲线
目标车辆减速切入场景的预测车速改进结果如图14所示。此场景下,SVM在线识别结果为自车处于紧急避让状态,因此对预测时域内的速度进行减速处理。由图14(a)可知,经过改进之后车辆预测速度低于原始车速,降低了车辆切入风险。经过改进,切入过程TTC平均值的提高说明改进后的预测速度能够有效降低车辆的碰撞风险。
目标车辆加速切入场景的预测车速改进结果如图15所示。此场景下,SVM在线风险识别结果为前车加速切入,且目标车辆与自车之间的TTC为负值,没有碰撞风险。同时,改进前后的预测车速近似相等,这表明所提出的方法在无碰撞风险的情况下,不对速度预测作出改进,维持原速度进行后期控制符合实际驾驶情况。

图15 目标车辆加速切入场景速度预测结果曲线
目标车辆匀速切入场景的预测车速改进结果如图16所示。此场景下,SVM在线风险识别结果为自车处于减速避让状态。因此,根据风险识别结果对预测时域内的速度进行减速处理。由图16(a)可知,经过改进之后车辆的预测车速明显降低,切入全过程中TTC值均有所提升,表明改进后的速度预测序列能够根据车车耦合关系进行实时改进,降低切入过程车辆碰撞风险。此外,TTC的提高表明所提出方法在目标车辆匀速切入场景中同样适用。
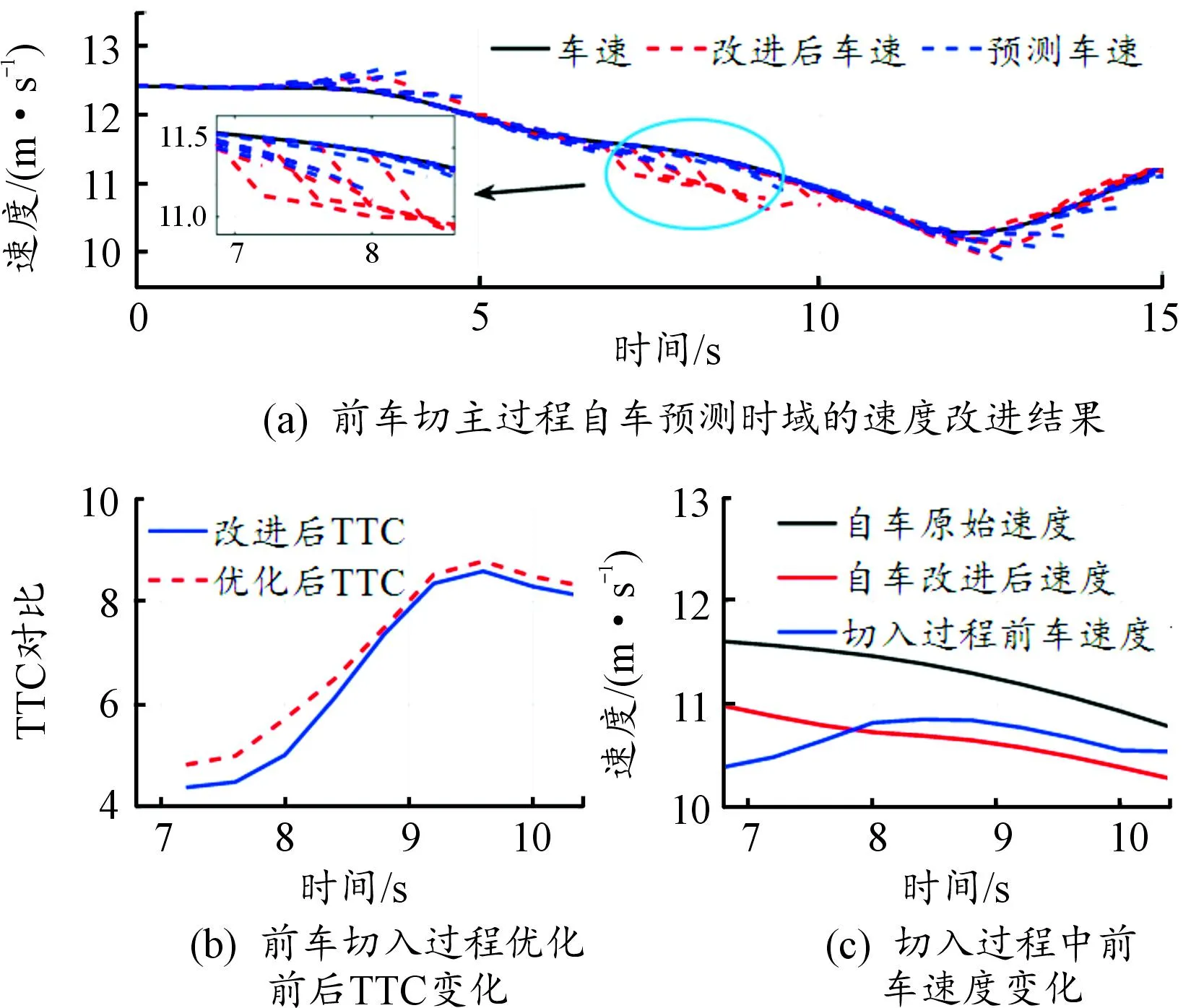
图16 目标车辆匀速切入场景速度预测结果曲线


表2 切入过程改进车速预测结果
4 结论
1) 针对目标车辆的切入场景,对自车速度的预测方法进行研究,提出了一种基于碰撞风险聚类的改进车速预测方法,有效提高了车辆切入场景下自动驾驶车辆的安全性。
2) 利用ARIMA模型样本需求少、预测精度高的特点,实现了自车速度的高精度预测;结合K-means和SVM算法对目标车辆的切入过程进行风险聚类和识别,得到不同风险场景下的速度改进规则以及当前切入场景的风险类型,改进ARIMA的车速预测效果,从而降低了车辆切入过程中的碰撞风险。
3) 基于Matlab环境进行仿真验证,结果表明:在不同的切入场景下的车速预测结果与改进前相比,车辆的碰撞风险降低10%~20%。研究结果对提高自动驾驶安全性具有一定的参考价值。
