一种基于HDFS的分布式文件系统MPIFS
2024-01-31陈卓航陈雅琴郭志勇
陈卓航,陈雅琴,郭志勇
(西南民族大学 计算机科学与工程学院,成都 610225)
随着计算机信息技术的发展,对数据处理的需求不断增大,使得高性能计算类型不再是单一的计算密集型计算, 数据密集型计算已成为高性能计算中不可或缺的一部分。MPI[1-2]适用于计算密集型计算,在如今的高性能计算中仍占主导地位,但是不太适合现在具有数据密集型特征的计算。
印度国立大学提出的将HDFS和Matlab分布式计算节点进行整合[3],集群中的每一个节点既作为HDFS的存储节点也作为Matlab分布式计算的计算结点。这种架构资源利用率更高,测试结果表明存储效率比普通文件系统高。
文中详细阐述基于HDFS的MPIFS分布式文件系统的设计思路以及实现,将MPI和HDFS结合提出一种分布式文件系统架构。该文件系统整合Hadoop和MPI各自的优点,同时支持数据密集型与计算密集型计算。
1 传统工具分析
1.1 MPI
MPI是1994年发布的一个基于Pipe管道通讯的通讯协议,适用于计算密集型并行计算,成为并行计算的主要实现方法。它是一个跨语言的通讯协议,用于编写并行计算程序,常用于编写并行代码指令,同时支持点对点、面对面、广播等多种协议连接形式[4]。
MPI计算特点是数据向计算迁移[5],需要计算的数据通过网络传输到计算节点,当MPI遇到数据密集型计算就会出现大文件传输,给MPI集群网络造成较大压力。这样会导致整个MPI工作时长增加,有效工作(计算)时间占比下降。MPI大多用于计算密集型科学计算,涉及较多的是计算和消息传递,几乎不涉及本地文件的访问和处理。
MPI不提供数据访问方法,MPI程序的数据访问部分代码只能使用编程语言提供的方法。在分布式环境下程序实现文件访问,各个节点需要打开各自的本地文件,程序的编写非常繁琐,编写这部分代码没有任何意义反而增加工作量。为此,提出一个专用于文件访问的中间件层,使用者只需调用就能实现数据访问,可以降低程序编写难度,提高工作效率,使MPI胜任数据密集型计算。
MPI并不会将可执行文件分发到集群的各节点,MPI程序只会让各个节点去启动自己路径下的可执行程序。MPI程序能够在集群中正确运行需要前期准备,建立集群共享文件夹,把可执行文件放到共享文件夹,每个节点都可以访问并执行,也可将可执行文件分别复制到各节点本地。
集群共享文件夹的主要实现方式是NFS(Network File System)[6]网络共享文件夹[7],在数据特别庞大的情况下会给系统造成存储压力以及读取文件时产生网络传输压力两类问题,这些情况都会影响系统的性能以及工作效率,而且MPI没有原生的文件系统,部署MPI集群不仅需要在每个节点安装MPI编译环境,还需要为集群创建共享文件夹。如果集群中没有共享文件夹,每个节点只能访问自己本地的文件。这种情况下要使MPI正确运行,计算时需要将不同数据分别发送到各节点本地,这也会增加时间和工作复杂度。而DFS(Distributed File System)[8]分布式文件系统能够符合MPI并行计算的文件需求。
1.2 HDFS
HDFS[9-11]是Hadoop的分布式文件系统,它是一个广泛使用的大数据系统,由Apache软件基金会在2006年开发完成第一个版本。系统实现了文件的分布式存储,支持并行批处理计算与数据密集型分布式计算。
HDFS提供文件存储、读取、分块、寻址功能。HDFS可以将大文件切块,将文件切割成小文件块并分布式存储在集群的各节点上。文件块非常适合数据的备份和磁盘资源的利用,还可以实现相同文件不同文件块之间的并行计算。以往对非分布式单独大文件只能单进程对其操作,文件切块后分布式存储对文件的操作实现并行化,这样的模式大大缩短了文件读写的时间。
HDFS将大文件分块并分布式存储在集群各节点,该特性可以与MPI分布式执行的特性有机结合。
2 MPIFS系统
基于以上对MPI和HDFS的研究与分析,提出一种新的文件系统架构MPIFS,使用中间件层将两个成熟的系统结合起来。MPIFS基于HDFS,利用HDFS成熟的分布式文件系统作为MPI的底层文件系统。利用两者分布式的共性,使被发送到节点上的MPI进程根据HDFS提供的文件存储信息去寻址。各个节点上的进程找到对应存储在节点本地的数据,所有节点进程之间并行处理自己本地的数据,处理完成后通过MPI通讯函数将结果发送到主节点汇总。该架构将MPI以往的数据向计算迁移的计算特征转变为计算向数据迁移,MPI可依赖MPIFS执行数据密集型计算,解决传统MPI没有文件系统、读取数据时需要网络传输、无法在大数据环境下有效工作的问题。计算和存储节点合二为一,其主节点、从节点在同一台物理机上,实现本地计算的同时也节省了搭建该系统所需的硬件资源。
系统分为五层,如图1所示。系统各层级之间使用统一标准的接口,隐藏各层的实现细节,降低各层之间的耦合性,使系统开发和维护简单方便,用户使用起来更简洁高效。
用户层:系统使用者的所有操作都在这一层级,用户可以在这一层完成自己的高性能计算任务。用户看到的文件也和普通单节点文件系统一样,是以根目录为起点的文件系统。在该系统中通过中间件层对文件进行操作,与在单节点文件系统的操作一样,使用者并不需要去了解文件分布式存储之后的具体分块和存储情况。使用上和常规MPI高性能并行计算方法相同,都是通过集群主节点控制整个集群。集群中的从节点通过HDFS层从主节点上获取到本地文件块的信息,对文件块进行用户自定义计算后,从节点将结果通过MPI通讯机制发送给主节点。主节点将接收到从节点发送的信息并进行汇总和统计分析工作,完成Map-Reduce[12-15]的归约Reduce部分。
中间件层:中间件层对用户层隐藏HDFS层的分布式文件存储细节,并将虚拟文件系统目录映射到上层,用户能感知到的是一个以根目录为起点的普通文件系统。用户使用中间件层提供的文件操作方法对文件进行进一步地自定义操作,在文件的读写操作上,只需要在方法中填入虚拟文件路径,中间件层向HDFS发出请求获取虚拟文件路径下对应的真实文件分块文件名及所在节点。主节点根据文件块的分布情况分发任务,使得每个节点都只对本地文件进行操作,实现本地计算,完成MapReduce的任务分发Map部分。存储节点和计算节点合并在同一台物理机上,不仅能实现本地计算还能节约硬件资源,同时降低因为文件跨节点读取造成的网络传输压力。中间件层向用户层返回的只是文件描述符,用户层通过文件描述符能做到关于文件的所有操作,更具有灵活性,不限制于某一种或某一类工作。实现方式上根据HDFS安装时配置的文件存储路径和中间件层获取的文件名快速定位文件,使用底层操作系统文件读写函数打开文件进行读取。
HDFS层:HDFS存储主要负责文件的分块存储,将分块后得到的文件块分布式存储在集群的节点上。利用成熟的分布式文件系统HDFS作为文件系统,HDFS的分布式存储特征又能和MPI的分布式计算特征相结合。HDFS存储层对上层隐藏了文件分块和文件存储的实现细节,只提供命令接口给中间件层。文件切分、切分大小标准、切分的文件块存储在哪个节点上、文件块实际路径的记录都由HDFS层负责并对上层隐藏。这些特征使得对底层文件系统不用太多的关注,系统构建更加简单稳定。HDFS也采用分布式系统经典的主从节点架构,主节点负责整个集群信息的保存维护、文件的分块及存储和存储文件作业的调度。
操作系统层:集群中主节点存储分块以及控制信息,从节点上文件分割之后的数据块存储都依托于操作系统。所有文件块都通过操作系统的文件系统进行存储,操作系统提供最基础的文件查找、寻址、打开、读写等功能。所有的上层功能都通过操作系统提供的基础功能优化组合而来。HDFS系统架设在操作系统上,需要的环境如Java由操作系统提供。HDFS并没有直接架设在物理层,操作系统作为中间层可以实现硬件无关性。鉴于Linux对MPI和HDFS良好的支持性,实验使用的操作系统选用Linux较为成熟的发行版本Ubuntu。
物理层:集群的硬件设备,真实物理机。将MPIFS的主节点同时作为MPI的主节点与HDFS的master节点,MPIFS集群的从节点作为MPI的从节点与HDFS的slave节点。MPI与HDFS管理节点部署在一起,MPI计算节点与HDFS存储节点部署在一起,计算结点与存储节点合二为一,既节省硬件资源也在硬件架构上支持本地计算,使计算变得更高效。
以词频统计工作为例,系统的工作流程如图2所示。词频统计程序启动,MPIFS主节点执行Map任务分配工作给从节点。主节点等待结果返回统计,执行Reduce任务。MPIFS从节点以文件系统中存储的文件路径为参数调用MYMPI_Openfile函数,函数调用HDFS获得整个文件所有分块的存储情况。获取虚拟文件对应的真实存储在集群中属于虚拟文件的文件块信息,信息包括一共有多少个文件块、文件块的名字以及存储节点的IP地址。每个节点的MPI进程都会得到一张完整的文件块对应的IP地址表,通过获取自己的IP地址与表中的数据比对,得到自己本地磁盘存储的文件块名。HDFS分布式文件系统在每一个节点上存储文件块的位置都是相对固定的,存储文件位置可在部署HDFS之前自定义。从节点通过操作系统层查找到文件块的绝对路径,调用操作系统层提供的打开文件函数,打开文件获取文件描述符,MYMPI_Openfile函数返回文件描述符。词频统计程序得到文件描述符对文件进行词频统计工作,统计工作完成后关闭文件向主节点发送统计结果,从节点程序结束,完成本地计算。主节点等待所有的从节点完成,通过MPI消息传递机制对各节点的计算结果进行汇总并统计输出,得到整个集群的计算结果。

图2 工作流程
3 实 验
3.1 实验设置与条件
文中设计了两个类型的实验:
1)使用固定数量的节点,将数据量递增的文件都分布式存储在系统中,每个节点上存储的数据量也因而递增。用词频统计的方法进行测试,得出不同数据量的处理时间。根据集群中文件数据量增加时处理时间的变化,得出集群中各节点的并行关系。每一组实验使用固定数量的节点进行数据量依次倍增的词频统计实验,集群中单个节点上存储的数据量以及依次递增情况相同。各组实验之间集群的节点数量不同,依此分析集群节点数量不同时集群的并行关系。
2)使用不同数量的节点,把相同数据量的文件分布式存储在系统中,每个节点上存储的数据量会因为节点的数量而改变。用词频统计的方法进行测试,得出不同节点数量的处理时间。根据结果分析集群中节点增加时处理时间的变化,以及集群中各节点之间的并行关系。每一组实验使用的节点数量依次递增,进行数据量不变的词频统计实验,集群中节点数量依次递增情况相同。各组实验之间集群数据量依次倍增,依此分析系统中存储不同数据量时集群的并行关系。
将MPIFS分布式文件系统部署在同一局域网下的6台计算机上。在HDFS分布式文件系统中,包括一个主节点5个从节点。单个计算机软硬件设备如表1所示。

表1 实验设备软硬件
3.2 实验结果
集群中每一个节点上存储切分后的数据块数据量,由8 MiB以每次数据量两倍的数量级倍增到256 MiB,每个节点的计算时间和该节点存储数据量的关系如图3所示。
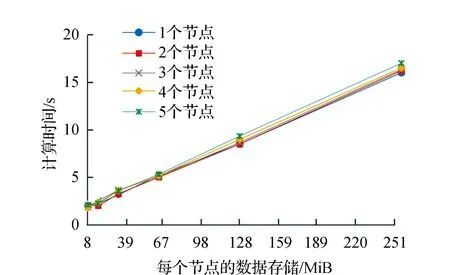
图3 节点计算时间与节点存储的数据量关系
图3分别将节点数设置为1、2、3、4、5,并对比不同数据量的节点计算时间。经分析数据结果可得图3中节点存储的数据量与计算时间呈一次线性正相关,说明词频计算时间的增长是因为数据量增大而导致运算量增大,最终导致计算时间延长。
图4记录了集群总的数据存储量与不同个数的节点上存储数据量大小的关系,分别设置节点数为1、2、3、4、5。

图4 集群存储总数据量与节点存储数据量关系
由图3和图4可知,计算时间并不由集群的总数据量决定,而是由分布式存储在集群每个节点上的数据量大小决定。
总数据量增长的同时增加集群的节点数,使得单个节点上的数据量不变,计算时间不变。当集群只有一个存储和计算节点,节点的计算方式只能是本地计算,图3中多个节点和单个节点计算时间一致,说明文件在系统中没有进行传输,如果存在文件在节点之间的传输,会出现多个节点和单个节点计算时间不一致。由此可得出集群的所有节点都是本地运算。
集群总存储数据量由40 MiB以每次数据量两倍的数量级倍增到1 280 MiB,计算时间与节点数量关系如图5所示。

图5 计算时间与节点数量关系
图5记录了存储在MPIFS的文件由集群中的计算和存储节点读取计算,计算和存储节点数量与词频统计时间之间的关系。在存储文件数据量不变的情况下,集群中计算和存储节点数量从1增加到5,由图5可看出,读取时间和集群计算和存储节点数成非线性负相关,随着集群计算和存储节点数量的增加计算时间减小。经过数学分析,整个集群存储文件时,节点数量与计算时间呈一元幂指函数负相关。
不同数据量的运算呈现的数据量和运算时间的关系都相同,运算时间并不会随运算量大小而改变,说明系统节点之间是并行关系,运算关系不受文件大小的影响。
当集群中存储待分析文件数据量不变时,随着集群节点数的增加,计算工作量分发到每个节点会减少,从而整个集群的工作时间减小。在节点数量成倍增加时,整个集群的工作时间成倍减小,可得出每个节点的工作量成倍减少。由此得出集群的计算节点之间没有互相依赖的并行关系。
4 结束语
文中提出一种MPIFS分布式文件系统,通过实验得出,当数据量m不变,集群计算时间t随集群计算节点数量n减小而增加,m增大n数量增大t不变,m增大n数量不变t增大,经过数学分析,t与m/n成一次线性正相关关系,因此,证明计算时间不是由集群的总数据量决定,而是由单个节点上的数据量决定,集群计算节点之间是并行关系。
文中成功验证了MPIFS能将MPI与HDFS结合,完成文件的分块和寻址,为MPI底层提供文件系统。MPIFS文件系统与MPI结合,使MPI不仅能支持传统的数据向计算迁移计算,同时也能支持计算向数据迁移计算,完成大数据计算任务。
