词素位置概率信息在中文双字词识别中的作用:词汇语境多样性的调节 *
2024-01-31梁菲菲冯琳琳王昶浩
梁菲菲 冯琳琳 刘 瑛 王昶浩 王 洁
(1 教育部人文社会科学重点研究基地天津师范大学心理与行为研究院,天津 300387) (2 天津师范大学心理学部,天津 300387) (3 学生心理发展与学习天津市高校社会科学实验室,天津 300387)
1 引言
在多数拼音文字书写系统中(如英语、德语等),词间空格作为一种天然的视觉词切分线索,促进词汇识别和引导眼跳定位(Clifton et al.,2016;Perea & Acha,2009)。相比之下,中文阅读没有明显的视觉词切分线索标记词的开始和结束,其词切分过程显得相对复杂且重要(白学军 等,2019; 梁菲菲 等,2019; Li & Pollatsek,2020)。中文读者如何以及利用何种线索进行词切分,是揭示中文阅读眼动控制的关键。
词素位置概率是指汉字出现在词内特定位置的概率信息(梁菲菲 等,2022; Liang et al.,2023)。例如,在“抽”字构成的26 个双字词中(如“抽象”“抽空”“抽打”等),“抽”字均用在词首,其位置线索完全指向词首,位于词内特定位置的汉字提供了一定的词切分信息。前期系列研究均已证明词素位置概率信息作用于中文阅读的词切分(曹海波 等,2023; Liang et al.,2017; Liang et al.,2015;Liang et al.,2023)。词素位置概率信息作为一种亚词汇水平的统计学词切分线索,其作用受词频的调节(曹海波 等,2023)。研究者采用词汇判断任务,通过两项实验考察高频词和低频词识别中首、尾词素位置概率的作用方式。结果发现,高频词识别中首、尾词素位置概率信息均不起作用;低频词识别中,首词素而不是尾词素的位置概率信息起作用。表明中文词汇识别中词频自上而下调节了词素位置概率信息的加工方式。
在语言习得领域,词频是多数语义表征模型构建的基础,反映心理学的重复原则(principle of repetition),其逻辑是,相比于低频词,高频词获得更多、更强的记忆痕迹,更容易提取(Rosa et al.,2017)。研究者对基于单纯重复原则的词频在词汇组织中的作用提出了质疑。他们发现,相比于词频,词汇的语境多样性(contextual diversity)更能代表读者词汇组织的信息来源。语境多样性是指词汇出现在语料库不同文本中的数量,反映了可能需要原则(principle of likely need),其假设是,相比于出现在单一语境中的词汇,出现在不同语境中的词汇在之后的未知语境中更有可能被需要,从而更广泛地得到运用(Adelman et al.,2006; Jones et al.,2017)。
基于重复原则的词频和基于可能需要原则的语境多样性,对词汇识别做出不同预测:如果词频更重要,那么不断重复更有利于词汇识别,且每一次重复对于词汇表征的构建同等重要;反之,如果语境多样性更为重要,那么单纯重复词汇本身所产生的学习效果有限,只有伴随语境的改变,才能逐步构建完整的词汇表征(Jones et al.,2017)。研究者就词频和语境多样性在语料库(Adelman et al.,2006; Johns et al.,2012)、词汇识别(Huang et al.,2021; Perea et al.,2013; Soares et al.,2015)以及句子阅读(Chen et al.,2017; Pagán et al.,2020;Plummer et al.,2014)中的预测作用展开大量研究。结果发现,在控制词频后,低语境多样性词汇的反应时间显著长于高语境多样性词汇;而在控制语境多样性后,词频对词汇识别速度的影响消失。由此可知,在控制词频后,语境多样性仍能解释很多变异;而在控制语境多样性后,词频的预测作用消失。根据词汇遗留假说(lexical legacy hypothesis)(Nation,2017),阅读提供诸多不同的语境、情节和经验。随着读者阅读经验的累积,这些不同的语境、情节和经验汇聚成个体关于词汇的数据库。仅仅只是一味地重复呈现某个词,或在同样的语义中重复某个词均无法刷新词典历史,而伴随语境的变化才会不断更新词汇表征,从而增强学习效果(贺斐,2021; Nation,2017)。由此推断,语境多样性这一指标可能更好地反映心理学的词汇组织原则,在词汇识别中起到更强的预测作用。
本研究通过两项实验同时操纵首、尾词素的位置概率信息,回答词汇语境多样性对词素位置概率信息加工的调节方式。基于读者对高语境多样性词汇表征的建立更为完善,倾向于整词通达的加工方式,而低语境多样性词汇表征建立相对不完善,需要借助自上而下的整词通达和自下而上的词素通达(Coltheart et al.,2001),本研究预期:如果词汇语境多样性调节词汇通达方式,词素位置概率信息在高语境多样性词汇识别中不起作用,在低语境多样性词汇中发挥作用;如果语境多样性条件不能调节词汇通达方式,词素位置概率效应将在高语境和低语境条件下保持一致。
2 实验1:高语境多样性词汇识别中首、尾词素位置概率信息的作用
2.1 被试
天津师范大学60 名在校生参加实验,平均年龄为20.20±1.66 岁。所有被试母语均为汉语,视力或矫正视力正常,均不知晓实验目的。
2.2 实验设计
采用2(首词素位置概率:高、低)×2(尾词素位置概率:高、低)的被试内实验设计。因变量为词汇判断正确率和反应时。
2.3 实验材料
基于SUBTLEX-CH 语料库(Cai & Brysbaert,2010),以logCD=0.85 作为语境多样性高、低分界点,高语境多样性条件的logCD 范围为0.90~3.12,平均值为1.73;低语境多样性条件的logCD范围为0~0.845,平均值为0.49。将词素位置概率高于0.7 定义为高概率条件,低于0.3 定义为低概率条件。操纵首、尾词素位置概率高低,形成4 种条件,每种条件包括40 个双字词:(1) 首高尾高(简称“HH”);(2)首高尾低(简称“HL”);(3)首低尾高(简称“L H”);(4) 首低尾低(简称“LL”)。四种条件下目标词的语境多样性、词频、首词素笔画数、首词素字频、尾词素笔画数、尾词素字频差异均不显著,Fs<1.71,ps>0.05。见表1。
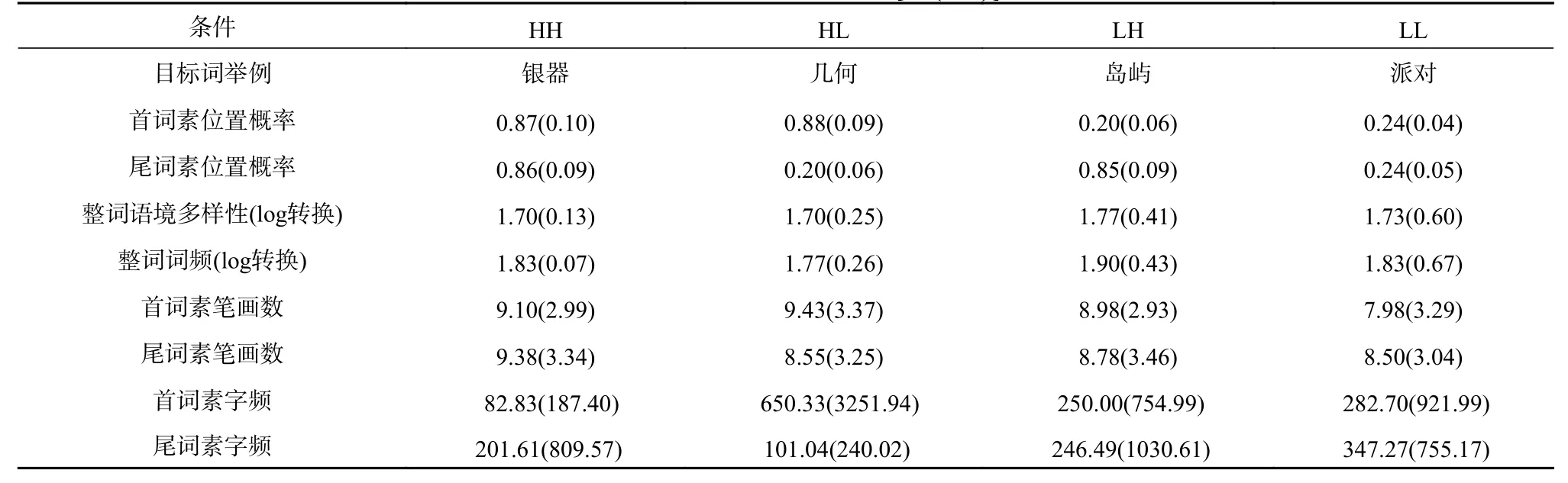
表1 实验1 真词词汇特征[M(SD)]
选取相同数量双字假词(160 个)作为填充词,构成词汇判断“否”反应。将真字两两组合构成假词,形成与真词对应的四个条件:HH、HL、LH、LL,每个条件包括40 个目标词。四个实验条件下假词的首词素笔画数、首词素字频、尾词素笔画数、尾词素字频差异均不显著,Fs<1.94,ps>0.05,见表2。

表2 实验1 假词词汇特征[M(SD)]
2.4 实验仪器
实验采用14 英寸笔记本电脑,分辨率为2880×1800 像素,刷新率为60 Hz,实验材料为35 号等宽字体。
2.5 实验程序
使用E-Prime 3.0 编程。被试单独施测。首先呈现500 ms 的注视点“+”,注视点消失后呈现目标词,要求被试又快又准地进行真假词汇判断,真词按“F”键,假词按“J”键。两个相邻试次的时间间隔为1000 ms。实验材料随机呈现。正式实验前有8 个练习试次。
2.6 结果
删除反应时超过3000 ms 以及3 个标准差之外的试次,删除数据比例为6.7%。反应时分析只针对正确反应试次。四种词素位置概率实验条件下的平均正确率和反应时见表3。基于R(R Development Core Team,2016)语言环境下的广义线性混合模型(generalized mixed-effects models,GLMMs)和lme4 数据包(Bates et al.,2023)对正确率数据进行分析,采用线性混合模型(liner mixed model,LMM)对反应时数据进行分析,并进行log转换。将首、尾词素位置概率作为固定因素,被试、项目作为随机效应纳入模型。模型分析汇总结果见表4。
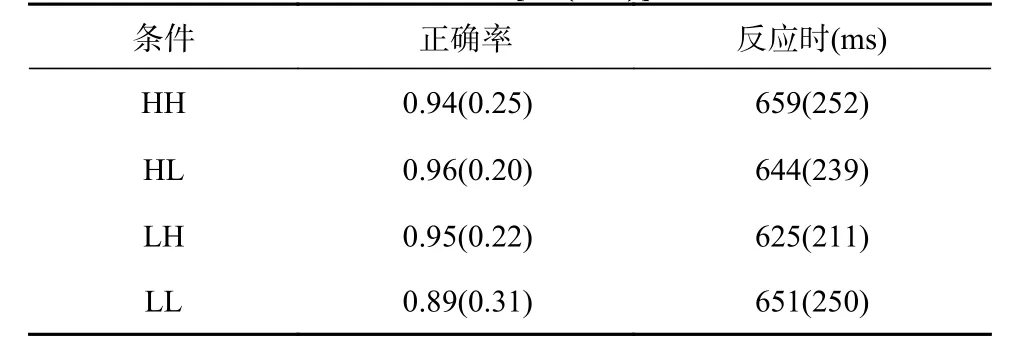
表3 实验1 不同词素位置概率实验条件下的平均正确率和反应时[M(SD)]

表4 实验1 不同词素位置概率实验条件下正确率和反应时的模型分析汇总结果
正确率分析。首、尾词素位置概率的主效应均不显著(|z|s<1.05),二者的交互作用显著(|z|=2.63)。简单效应分析发现,当首词素位置概率较高时,尾词素位置概率的高、低无显著差异(t=1.02);而当首词素位置概率较低时,尾词素位置高概率条件下的正确率显著高于尾词素位置低概率条件(|t|=2.42)。
反应时分析。首、尾词素位置概率的主效应均不显著(|t|s<0.73),二者的交互作用显著(t=1.99),当首词素位置概率信息较高时,尾词素概率高、低之间的差异不显著(|t|=1.03);当首词素位置概率较低时,尾词素概率高、低之间的差异也不显著(t=1.79)。
上述结果表明,在正确率分析中,尾词素位置概率作用受首词素位置概率高低的制约,当首词素位置概率较高时,尾词素的位置概率信息不起作用;当首词素位置概率较低时,尾词素的位置概率信息开始起作用。而首词素位置概率信息对尾词素位置概率信息的调节作用并没有表现在反应时分析中。
3 实验2:低语境多样性词汇识别中首、尾词素位置概率信息的作用
3.1 被试
同实验1。
3.2 实验设计
同实验1。
3.3 实验材料
基于SUBTLEX-CH 语料库(Cai & Brysbaert,2010),将词素位置概率高于0.7 定义为高概率条件,低于0.3 定义为低概率条件。操纵首、尾词素位置概率高低,形成4 种条件:HH、HL、LH、LL,每种条件下35 个双字词。四种条件下双字词的语境多样性、词频、首词素笔画数、首词素字频、尾词素笔画数、尾词素字频差异均不显著,Fs<1.99,ps>0.05。见表5。
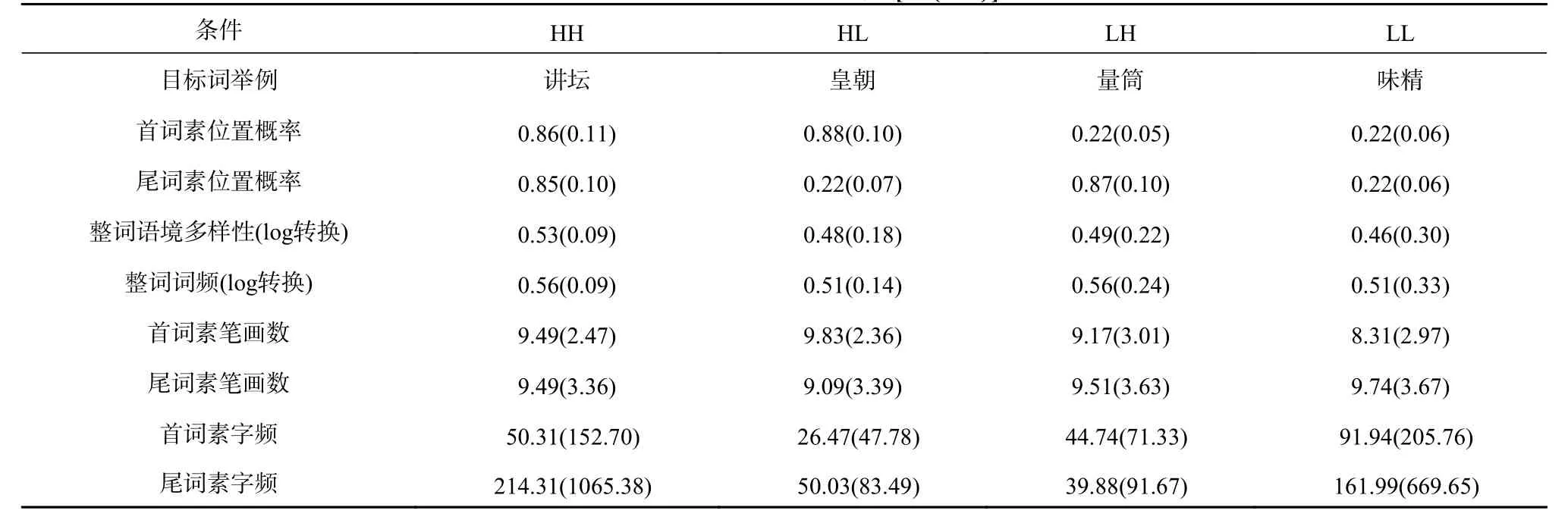
表5 实验2 真词词汇特征 [M(SD)]
为平衡词汇判断是否项目数,在材料中加入同等数量填充词构成“否”反应。将两个真字组合为假词构成填充词。四种条件下各35 个假词,同样控制四种条件下填充词的首词素笔画数、首词素字频、尾词素笔画数、尾词素字频差异均不显著,Fs<1.70,ps>0.05。见表6。
表6 实验2 假词词汇特征[M(SD)]
3.4 实验仪器和实验程序
同实验1。
3.5 结果
删除数据标准和数据分析方法同实验1,删除比例为16.8%。四种实验条件下的平均正确率和反应时见表7,模型分析汇总结果见表8。

表7 实验2 不同词素位置概率实验条件下的平均正确率和反应时[M(SD)]
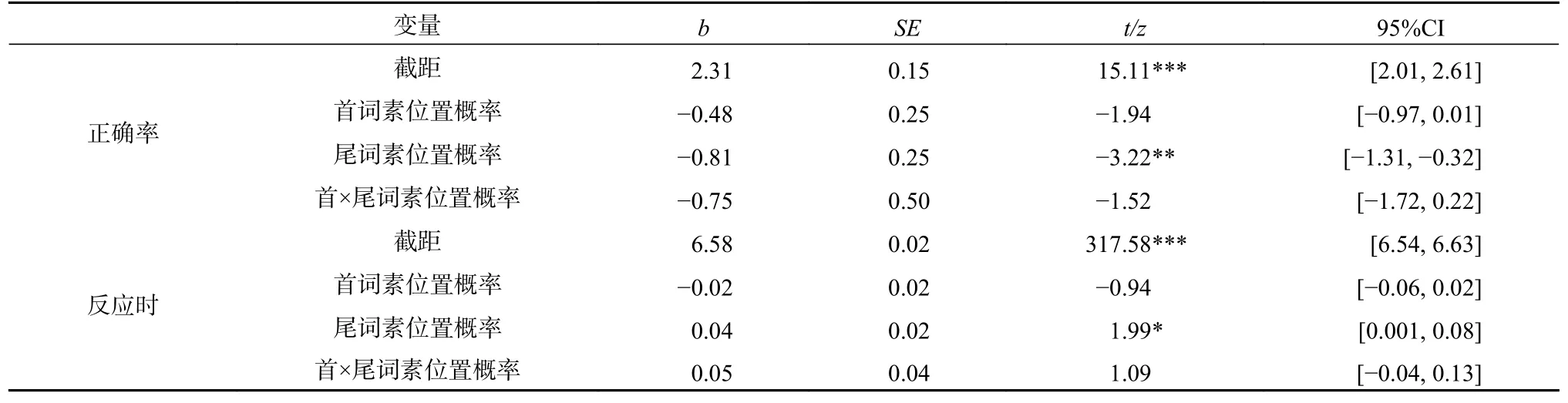
表8 实验2 不同词素位置概率实验条件下正确率和反应时的模型分析汇总结果
正确率分析。首词素位置概率的主效应边缘显著(|z|=1.94),尾词素位置概率的主效应显著(|z|=3.22),二者的交互作用不显著(|z|=1.52),表明在低语境多样性条件下,首、尾词素位置概率在词汇识别中均起作用。
反应时分析。首词素位置概率的主效应不显著(|t|=0.94),尾词素位置概率的主效应显著(t=1.99),二者的交互作用不显著(t=1.09)。表明在低语境多样性条件下,尾词素位置概率对词汇识别的时间产生影响。
上述结果表明,在低语境多样性词汇识别中,首、尾词素位置概率信息均起到一定作用。相比之下,尾词素位置概率信息的影响更为广泛(同时表现在正确率和反应时上),首词素位置概率信息的作用仅表现在正确率方面。
4 假词分析结果
由于实验1 和实验2 被试相同,且填充词的构词规则和标准相同,将两个实验的填充词合并分析。数据分析方法同实验1,删除数据占总数据的8.4%。四种实验条件下的平均正确率和反应时见表9,模型分析汇总结果见表10。
正确率和反应时分析的结果趋势完全一致。首、尾词素位置概率的主效应以及二者交互作用均显著(|z|s>2.96),简单效应分析表明,当首词素位置概率较高时,尾词素位置概率高、低条件下的正确率和反应时均无显著差异(|t|s<0.78);当首词素位置概率较低时,尾词素位置高概率词汇识别正确率显著低于、反应时显著长于尾词素位置概率较低时(|t/z|s>3.88)。该结果表明,当读者判断一个词为假词时,会同时运用首、尾词素的位置概率信息进行判断,且尾词素位置概率信息的作用受首词素位置概率高低的调节。当首词素位置概率较高时,尾词素的位置概率不起作用;当首词素位置概率较低时,读者会运用尾词素位置概率信息进行判断。
5 讨论
本研究通过两个平行实验,同时操纵首、尾词素的位置概率高低,考察了中文词汇识别中词汇的语境多样性如何调节首、尾词素位置概率信息的加工。主要发现如下:在高语境多样性词汇识别中,当首词素用在词首的概率较高时,尾词素的位置概率信息不影响词汇识别,但是当首词素用在词首的概率较低时,尾词素的位置概率高低影响词汇判断的正确率;在低语境多样性词汇识别中,首、尾词素的位置概率信息均作用于词汇识别;在假词识别中,首、尾词素的位置概率信息均作用于假词识别,且首词素位置概率的高低限制尾词素位置概率信息的加工。研究结果与本研究假设相符,表明词汇语境多样性调节了首、尾词素位置概率信息在词汇识别中的作用方式。本研究结果对于理解中文词汇识别和词切分的认知机制有以下启示。
相比于词频,词汇的语境多样性在衡量心理语言学的重复原则时,纳入了语境多样性因素,因此在词汇识别中具有更强的解释力(Chen et al.,2017; Pagán et al.,2020; Plummer et al.,2014)。比较本研究和曹海波等人(2023)的研究结果,发现词汇语境多样性对首、尾词素位置概率信息加工的调节作用与词频对其的调节作用并不完全一致,在高、低语境多样性条件下均能激活首、尾词素位置概率信息,而在高、低词频条件下,仅在低频词识别中激活了首词素位置概率信息,因而前者的调节作用在一定程度上大于后者。这在一定程度上表明,虽然词汇的语境多样性和词频具有中等相关(Hoffman et al.,2013),但是二者在心理语言学中的含义并不相同。目前主流的中文字词识别模型(如汉字识别模型)(Taft & Zhu,1997)以及阅读眼动控制模型(中文阅读眼动控制模型)(Li &Pollatsek,2020)均将词频纳入模型,作为解释词汇加工与识别的重要变量。结合本研究结果以及前期关于词汇语境多样性的研究发现,后续研究者可以尝试将词汇语境多样性纳入上述模型,以提升该模型的检验力。
词汇语境多样性如何调节首、尾词素位置概率信息的加工?依据多字词的混合通达模型(Caramazza et al.,1988)以及词汇遗留假说(Nation,2017)的观点,本研究推测:当一个词处在多样化语境中,其词汇表征质量更高,更倾向于整词通达模式,此时位于字水平的词素位置概率信息激活程度较小,因此表现出高语境多样性词汇加工中,仅当首词素的实际位置与其常用位置不相符,造成认知加工困难时,读者才会利用尾词素的位置概率信息帮助完成词汇判断;当一个词所出现的语境较为单一时,词汇表征质量相对较低,此时更倾向于词素通达模式,因此,首、尾词素的位置概率信息均在字加工层面被激活,前馈到词水平加工层级,帮助进行词汇识别;当判断一个词为假词,作出“否”的判断时,由于事先没有假词的词汇表征,没有自上而下来自词水平信息的反馈,读者不得不同时依据首、尾词素的位置概率信息作出判断。例如,当首词素不经常用在词首,尾词素不经常用在词尾时,读者将更快地作出“否”判断。需要说明的是,为了实现最大限度的操纵,本研究基于语料库,将词汇语境多样性分为高、低两个水平。但从本质上讲,词汇的语境多样性是一个连续变量,二分变量无法从连续性的视角描述词汇语境多样性对词素位置概率加工调节作用的变化。后续研究有必要结合全面的语料库分析以及局部的实验设计,从连续性视角揭示该问题。
本研究还发现,首词素位置概率信息的加工在一定程度上限制尾词素位置概率信息的加工,结果支持中文双字词识别中首词素具有加工优势的观点(Ma & Li,2015; Tsang & Zou,2022)。这可能与中文自身的文字特征以及阅读方向有关:由于中文阅读的视觉词汇加工从左至右进行,读者对首词素的加工先于尾词素,使得首词素在词汇识别中起关键作用。这符合基于拼音文字阅读提出的自我组织词汇习得与识别模型(SOLAR)(Davis,2001)和顺序编码模型(SERIOL)(Whitney,2001)的基本主张,即字母的兴奋性激活程度从词汇左侧向右侧逐步递减。后续研究有必要在中文词汇识别模型中纳入首、尾词素加工的不同地位,以增强模型的解释力。
6 结论
本研究条件下得出如下结论:在高语境多样性词汇识别中,仅当首词素与常用位置不相符时,读者才会利用尾词素的位置概率信息完成词汇识别;在低语境多样性词汇识别中,首、尾词素的位置概率信息均起作用。
