Privacy Protection Technology of Educational Data Mining Based on Visual Federated Learning
2024-01-29MENGFanHAITaoZHANGRuihuaSHENGXiaoliZHENGMaoxingZhangHuiqin
MENG Fan,HAI Tao,ZHANG Ruihua,SHENG Xiaoli,ZHENG Maoxing,5,Zhang Huiqin
(1.Professional and Technical Personnel Continuing Education Base Office,Baoji Education College,Baoji Shaanxi 721004,China;2.School of Computer and Information,Qiannan Normal University for Nationalities,Duyun Guizhou 558000,China;3.Faculty of Education,Languages,Psychology & Music,SEGi University & Colleges,Petaling Jaya,Selangor 47810,Malaysia;4.School of Marxism Studies,Nanchang Institute of Science and Technology,Nanchang Jiangxi 330044,China;5.School of Computer Sciences,Baoji University of Arts and Sciences,Baoji Shaanxi 721007,China;6.Faculty of Education,Universiti Teknologi MARA,Shah Alam,Selangor,40450,Malaysia)
Abstract: Artificial intelligence(AI)has become increasingly important in the field of education.However,with the rise of big data and intelligence technology,ensuring privacy protection has become a crucial issue that needs immediate attention.To address this issue,the concept of federated learning in AI is introduced,which involves decentralized training of machine learning models on data that is distributed across multiple devices or organizations without exchanging the raw data.The system model and training process of federated learning,as well as its privacy protection technologies are analyzed,and the potential applications of the model in various educational data mining algorithms are explored.Federated visualization is an extension of the federated learning architecture in the domain of visualization,with a focus on establishing mutually beneficial and win-win federated cooperation techniques for visual data analysis from multiple data sources while ensuring data privacy.The framework executes encryption training for certain activities and situations without integrating data,generating a visual model that reflects the features of all data.By removing industry data barriers and sharing data and expertise,federated visualization can effectively address privacy protection issues that may arise in educational data mining.It is found that federated learning is a promising approach for protecting data privacy in principle and can be easily integrated into existing educational applications.Moreover,the use of a federated visualization framework can maximize model accuracy while protecting privacy.Federated learning provides a new pathway for the informatization and intelligent growth of education.
Key words: federated learning;educational data mining;privacy protection;visual features;data visualization
In the era of artificial intelligence,the gathering and utilization of educational data are critical to the sustained growth of intelligent education.However,there are concerns regarding the privacy and dignity of learners,which may be compromised during the in-depth mining of educational data[1].Therefore,preserving student privacy while maximizing the use of educational data has been a subject of intense research.Various approaches have been proposed,including rebuilding the institutional ethics of data governance and enhancing the data governance capacity of educational decisionmakers,as well as leveraging information security technologies and blockchain technology for protecting educational data privacy[2].
Despite these safeguards,privacy leakage remains an issue during the collection and transfer of educational data throughout the data mining process.The conflict between the requirements of learners for educational privacy protection and the desire for educational data sharing in the intelligent era has become a critical paradox that impacts the function of artificial intelligence technology in education.To address these challenges,federated learning has emerged as a promising method for protecting data privacy in various sectors,including smart medical care and smart city development.
Federated learning enables machine learning processes to be carried out locally by each participant under the coordination of a central server,without requiring the central collection of raw data[3].This approach essentially resolves the privacy protection issue in data mining,as there is no subsequent data transfer or public sharing.However,there has been little research on the potential applications of federated learning in the education field.
Data silos,inter-industry rivalry,administrative processes,data privacy,and security have resulted in difficulties for data integration in various industries.Data visualization plays a critical role in transportation,finance,security,and other sectors[4].However,errors in analysis findings may lead to significant losses,and visual analysis based on one-sided data may provide wildly inaccurate results.Federated learning provides a solution to eliminate data silos while preserving data security,and this approach may enable the integration of data dispersed across multiple institutions while maintaining data privacy[5].
This study aims to provide a platform that integrates federated learning visualization and education,and federated visualization.By leveraging federated learning,the visualized feature data can be computed using a model that has been cooperatively enhanced by multiple institutions,rather than simply querying the database.This approach may enable the utilization of a huge quantity of high-dimensional,high-quality data,which is often necessary for a model to work properly,and may help overcome the issues of limited data and low quality in many disciplines.Overall,federated learning has the potential to revolutionize data privacy and security while enabling the effective utilization of educational data in the intelligent era.
1 Federated Learning visualization
1.1 System model and training process of Federated Learning model
DefineNparticipantsP={p1,…,pN},each with a private dataset {D1,…,DN}.The traditional machine learning method unifies the dataset of each participant into a data lakeD=D1∪…∪DN,and then trains the model M-SUM.In the federated learning method,each participantpilocally trains the model {M1,…,MN} and its parameters {w1,…,wN} under the coordination of the central server,and uses the parameters of the model M_NwNis sent back to the central server,which is integrated into the global model M-FL by the central server.
The accuracies of the models M-FL and M-SUM are defined as V-FL and V-SUM,respectively,these two values should be very similar.Definingδas a non-negative real number,if |V-FL-V-SUM |<δ,the federated learning algorithm is considered to have aδ-accuracy loss[6].
The system model of federated learning,as depicted in Figure 1,involves a central server and data owners or participants.Typically,the central server is hosted on a private cloud server or leased public cloud server belonging to the firm,organization,or researcher initiating the federated learning job.The data owners may vary depending on the job,but for instance,when an educational institution is training a model using students’ educational data,the data owner is the student’s own database holding the educational data on devices such as mobile phones,PCs,and tablets.In cases where educational institutions collaborate for model training using their own stored data,each institution’s server serves as the data owner.
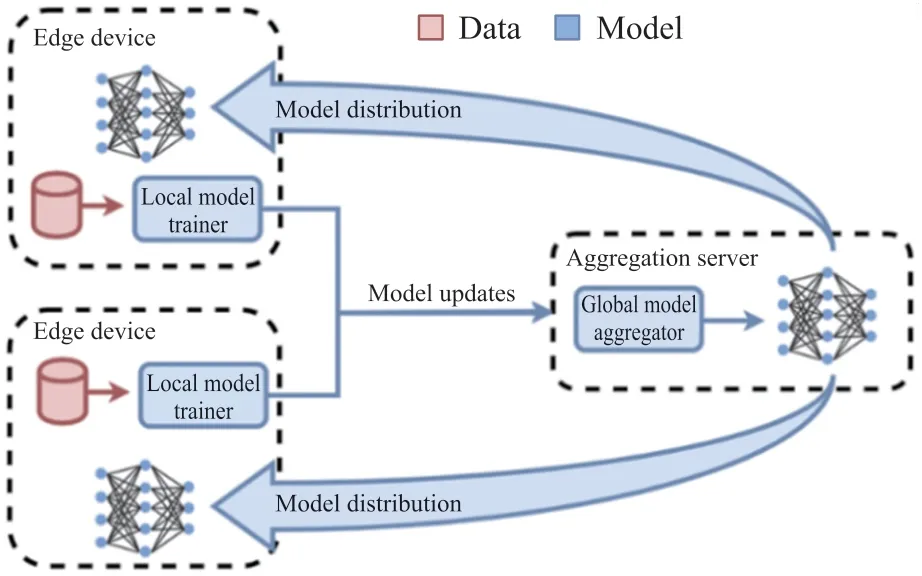
Fig.1 Common system model for federated learning
It is essential for the training components associated with federated learning to be installed locally by the data owner using the initiator’ s given software.Participants in the federated learning process must collect data locally over a period of time,and if insufficient data is collected,they cannot participate.Data owners must interact with the central server using an Ethernet or cellular network.The most commonly used algorithm for the federated learning model is the federated averaging algorithm.
The training procedure for federated learning involves three main steps:task initialization,local model training and update,and global model aggregation,update,and iteration.During the task initialization step,the central server chooses the encryption mechanism and specifies the training objectives,tasks,and data needs.The central server also selects the hyperparameters of the global model and training procedure and sends the initialized global model parameters to the participants.
During the local model training and update step,participants receive the global model parameters and use their local data to train their local model.The local model’s encrypted parameters are then sent back to the central server.The global model aggregation,update,and iteration step involves the central server taking the model parameters provided by each participant,taking their average,updating the global model,and sending it back to the participants’ local.The second and third training phases are repeated in this manner,and the global model is iterated until the loss function converges,minimizing the global model’s accuracy loss as much as possible.
1.2 Privacy-preserving framework
In the realm of privacy-preserving data mining,there are two widely used privacy models:the syntactic anonymity model and the differential privacy model,each of which approaches privacy concerns from a different perspective.The k-anonymity model,which is a representative of the syntactic anonymity model,aims to prevent re-identification by linking quasi-identifiers that exist in both public and private databases.It does this by makingkrecords identical to each other,thereby preventing identity leakage and making it impossible for attackers to identify a specific individual[1].To assess the risk of attribute disclosure in privacy-preserving data mining,researchers have also developed the l-diversity model[2]and the t-tightness model[3].Differential privacy models are commonly used to anonymize query replies[4]by introducing random noise from a deterministic distribution.
To strike a balance between privacy and usefulness in anonymous visualization representations,researchers in the field of privacy-preserving data visualization have adapted and expanded models from the data mining community.For example,when using parallel coordinates to describe multidimensional data,researchers have explored options for using syntactic anonymization approaches such as k-anonymity and l-diversification[5].Reference [ 6] focuses on event sequence data and provides a graphical interface for data owners to assess possible privacy concerns and fine-tune outcomes based on algorithmic suggestions and their own discretion.References[7-9] focus on the anonymization of multi-attribute table data and the privacy protection of graph data.They design privacy protection schemes that allow users to customize both privacy protection and practicality,but it requires users to complete some complex tasks.Reference[8] utilizes the unpredictability of screen space to repel attackers,while references[9] and [10] safeguard privacy by introducing ambiguity into the display chart.
In the context of federated learning,providing participants with privacy protection is a crucial aspect.Participants exchange only model parameters,not actual data,effectively resolving the issue of data leakage.However,several studies have shown that certain basic information about participants,such as gender,employment status,and geographic location,can still be gleaned from the model parameters supplied by participants[11].
To address this issue,this study proposes a novel framework that is distinct from standard visualization.The framework ensures that an attacker cannot access the original data and that the data owner can configure the privacy protection system without significant interaction.By starting at the data level,this framework provides a comprehensive solution to privacy protection in federated learning[7].Therefore,to prevent malicious players or servers from providing countermeasure parameters,federated learning may employ a range of privacy protection mechanisms to offer comprehensive protection for participants’ personal privacy while pushing critical information.In federated learning,there are three kinds of privacy protection solutions:①Differential privacy-based solutions.This method primarily targets malicious users.The basic concept is to utilize a random method for differential privacy protection,such as the Gaussian mechanism,to introduce noise to the parameters before transferring them from the participants to the central server.The parameters of the shared global model cannot be used to infer information about other participants.Simultaneously,the participants continually compute the likelihood of malevolent participants exploiting the shared parameters to reverse the information,and when a predetermined threshold is reached,they halt the model training process[7].②Solutions for collaborative training.Participants do not upload the entire set of parameters generated by their local training to the central server,nor do they update the entire global model to the local,but rather upload and download selectively,based on the scenario.Even if users do not submit the whole parameter set,the final trained global model is still as accurate as the global model with the full parameter set,according to studies.For instance,the global model for the MNIST dataset obtained 99.14% accuracy when participants consented to contribute 10% of parameters and 98.71% accuracy when participants provided just 1% of parameters[8].③Encryption-based solutions.Before transferring the participants’ training parameters to the server,this approach encrypts them using homomorphic encryption.Encryption is a widespread and effective way of protecting privacy that may be used with other methods.Some studies have proposed a hybrid solution based on encryption and differential privacy,employing an additive homomorphic encryption mechanism and adding noise that purposefully interferes with the original parameters to protect the privacy of the participants prior to sending the parameters to the server[9].
1.3 AI and visualization
The primary objective of visual analysis[12]has always been to combine visualization with conventional machine learning approaches to create a human-in-theloop analysis process.The “black box” aspect of AI models encourages the development of AI interpretability visualization tools[13]to disclose the inner workings of AI models.References [14- 15] offer a thorough summary of the current studies.The tree boosting method[16],the convolutional neural network(CNN)[17-18],the recurrent neural network(RNN)[19],the generative adversarial network(GAN)[20],the deep reinforcement learning network(DQN)[21],and the deep generative models[22]are just a few of the visualization techniques that have been proposed by researchers to explain the different types of AI models from different perspectives.These works use visualization technologies to explain and improve AI models,i.e.,to address AI-related issues(VIS for AI).In contrast,the federated visualization framework suggested in this research uses an AI model(a federated learning model)to tackle the privacy protection issue in visualization,i.e.,AI technology is used to solve the visualization problem(AI for VIS).
Numerous domain specialists regard AI for VIS as a highly promising path in the area of visualization.In recent years,several great research works have been published in the domains of visual exploration[23-24],graph drawing[25-27],visual chart suggestion,automated production[28-30],etc.They employ AI models to handle different challenges in graphics.
2 Applications of Federated Learning in Education
2.1 Privacy Issues in Educational Data Mining
Common machine learning techniques employed in the area of educational big data mining may be primarily split into two groups:supervised learning and unsupervised learning,based on the various kinds of data.Supervised learning is the application of labeled data.Unsupervised learning refers to a model mining its inherent connections and structure from unlabeled input[10]as shown in Table 1.Different algorithms have their own benefits and limitations,and educational researchers adopt algorithms based on the kind of data gathered and the learning objectives at hand.Nonetheless,all types of algorithms need the assistance of relevant educational data,and there may be privacy leakage issues.

Table 1 Different algorithms have their own advantages and disadvantages
When researchers require a method to classify distinct data,they often use classification techniques from supervised learning,such as support vector machines and deep neural networks.Support vector machines offer the advantages of minimal structural risk and low generalization error rates,making them an ideal choice for evaluating the quality of teaching and learning in the field of education[12].To train models for the assessment of teaching quality,researchers often utilize expert and student rating data,which includes information on instructors’ teaching attitudes,materials,and procedures.Similarly,to evaluate the learning process,data from student self-assessment and instructor evaluation are gathered,including information such as attendance rate,attitude toward learning,and assignment correctness.However,it is imperative to maintain the privacy of this sensitive data to prevent any damage to instructors or students.
Deep neural networks with multiple layers are widely used in education for tasks such as image identification,voice recognition,and text recognition[13].These networks are also used to recommend learning resources by gathering historical learning data and personal information provided by learners on online platforms.Moreover,deep neural networks are used to analyze students’ concentration and comprehension in class,encouraging teachers to improve the quality of classroom instruction and assist students in enhancing their learning efficiency.However,this analysis requires multi-view classroom footage that contains vast amounts of image and audio data,posing a potential privacy threat to the participants[14].
The regression method is a standard machine learning prediction model that uses a straightforward structure and theory.Linear regression is used when data points oscillate around the main axis to construct the model[15].For instance,researchers have constructed a model for predicting students’ marks in computer science courses based on their mathematics grades using multiple linear regression.However,the arithmetic performance data of children represents a privacy issue that must be handled with utmost care[16].
Unsupervised learning clustering algorithms,such as K-means clustering and DBSCAN,are used to cluster similar data into one category when researchers are unsure of the number of categories.Education extensively uses clustering algorithms for predicting student success,analyzing student behavior,and evaluating teacher quality[17].For instance,researchers employ the K-means clustering technique to analyze the link between college students’ course assessments and their results on the associated tests to predict students’test scores based on student ratings.However,pre-collected student rating data and academic performance data pose a significant privacy concern that needs to be addressed appropriately.
2.2 Visualization Model
The objective of this study is to address the issue of data isolation in visualization analysis by proposing a federated visualization framework using the federated learning approach.The proposed framework aims to obtain a visualization model that represents the characteristics of the entire dataset while maintaining the privacy of each data owner through encrypted training within their local region.
Information visualization heavily relies on visual mapping,which involves converting data into visual elements.The mapping results should be clear,easy to understand,and easy to remember.The three components of visualization include the visualization space,markup,and visual channel.Data is composed of attributes and values,where attributes represent labels and values correspond to visual channels.Mark refers to the mapping of data attributes to visual elements,such as points,lines,surfaces,volumes,etc.Visual channels map the value of a data attribute to the visual representation parameters of the mark.A visual layer maps the value of a data attribute to the visual presentation parameters of mark.Common visual channels include location,size,shape,orientation,color,etc.By combining the marker and the visual channel,data information can be fully expressed visually.
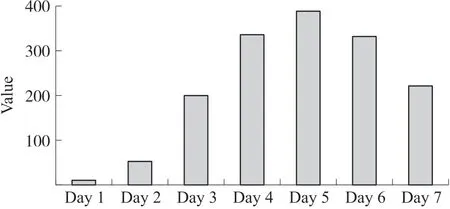
Fig.2 Example of a visual feature set
Assuming thatVis a visual graph,it may be represented asV=VF1,VF2,…,VFn,where VFI=vfI1,vfI2,…,vf in is a visual feature set consisting of numerous visual features.For instance,the histogram contains just one set of visual characteristics,and the purpose of each visual characteristic is to represent the column height(as shown in Figure 2).
2.3 Framework Architecture
As an example,the federated visualization framework is introduced using a scenario in which there are three data owners(i.e.,enterprises A,B,and C),and each data owner has the same user characteristics but different users(i.e.,horizontal federated learning).The detail settings of the framework can be expanded to accommodate more complex data distributions.These firms do data analysis only on their own data.Suppose these three firms want to examine the properties of the aggregate data’s distribution collectively.Due to data privacy and security concerns,the three organizations cannot direct merge data,but they may construct a visualization model using the federated visualization framework so that each company can view comparable data.Figure 3 depicts the structure and operational mechanism of federation visualization.
In order to ensure the confidentiality of data during the training process,it is crucial to use a third-party collaborator server for encrypted training.To illustrate this,let us consider the example of using a heat map for the training process,which can be divided into the following four parts:
①Data preprocessing:Each company organizes its local geographic data into annbymgrid based on latitude and longitude,and counts the data points in each grid.
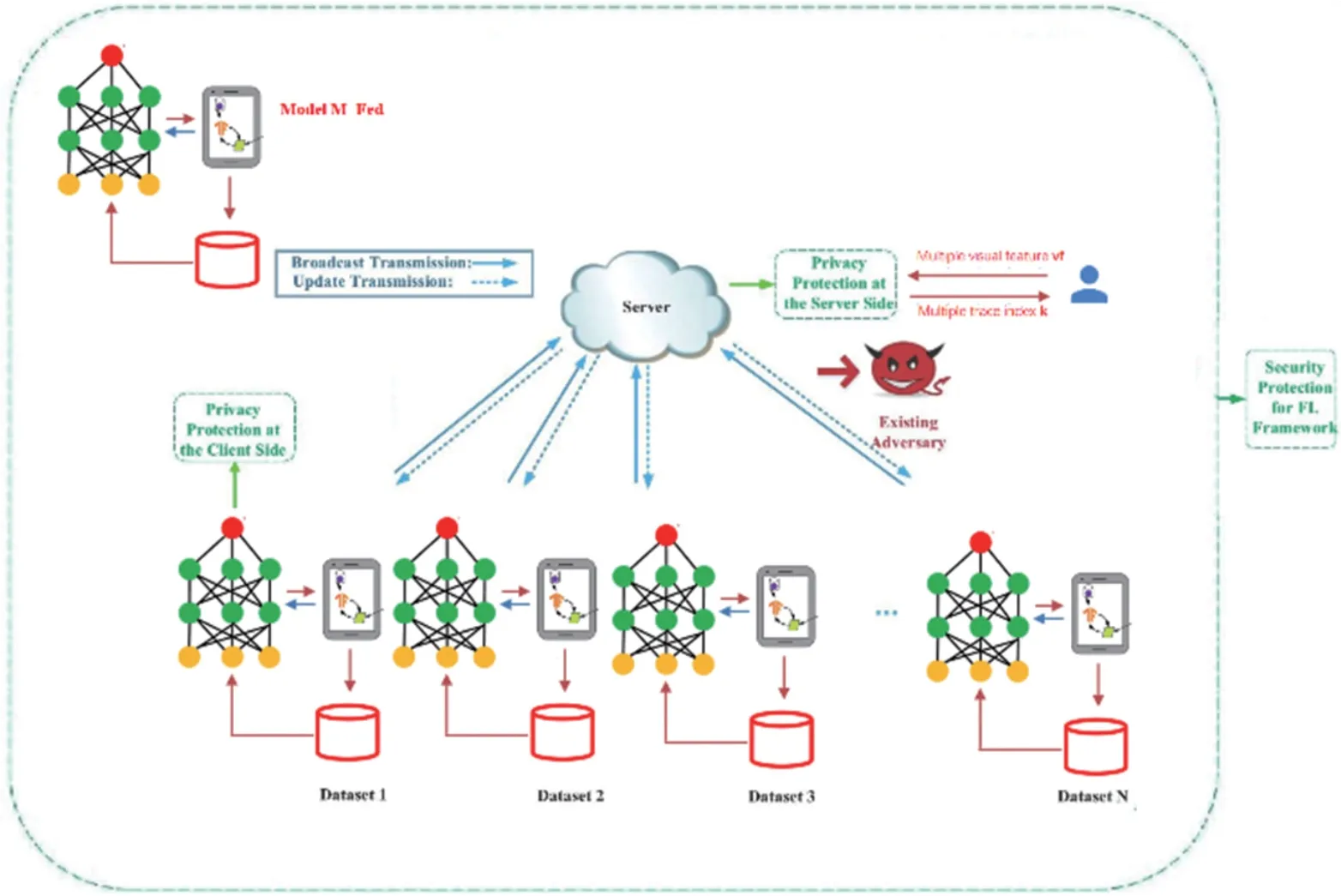
Fig.3 Framework and operating mechanism of federation visualization
②Initial model distribution:The server initializes a model called M-Fed and distributes parameters to each organization based on federated learning.As shown in the heat map,the input to the M-Fed model is a collection of grid indices corresponding to latitude and longitude,and the output is the grid’s data point statistics.
③Cryptographic model training:Each organization receives the parameters from the server,calculates the gradient value based on its local data,encrypts the gradient value,and sends it to the server.The server then weights and averages the gradient values provided by each organization,updates the parameters,and sends them back.
④Visual chart illustration:After several iterations,the model’s accuracy improves progressively.Each organization locally uses the search indexkof each grid as the input to the M-Fed model,obtains the matching grid’s data point statistics,vfk,and displays thenbymgrid data as a heat map.
During the training process,each organization does not transmit its local data,thereby protecting data privacy.Moreover,since each enterprise can see the complete data picture,collaboration between companies is facilitated,leading to more informed judgments.
In summary,using a third-party collaborator server for encrypted training and adopting the federated learning approach can effectively protect the privacy of data,while also enabling collaboration and informed decision-making.
3 Experiments
This research leverages millions of Haikou taxi order records(including latitude and longitude information)to conduct a small experiment to validate the usefulness of the federated visualization system described above.
3.1 Data Preprocessing
In order to simulate multiple enterprises,this paper randomly divides a data set into three non-IID data sets,and performs the following processing on the data.
Divide Haikou into a 360×180 grid with(x,y)
{x∈[1,360],y∈[1,180]}.
Count the data in each grid to get the data(x,y,count){x∈[1,360],y∈[1,180]}.
3.2 Technology Implementation
The three databases are encrypted and educated using the federated average technique,and the integrated data is fitted to guarantee the data privacy of all parties.
Regarding the setup of the federated averaging process,utilize the Python SocketIO open-source database for server-to-database connections.Each round of training includes all databases,and each database trains for one round.
In terms of neural network configuration,the input is the latitude and longitude index(x,y),while the output is the grid’s count result.Use five fully connected layers with a width of 96,a linear rectified function(rectified linear unit,ReLU)as the activation function for each layer,an Adadelta optimizer,and a batch size of 32.
3.3 Experimental results
As seen in Figure 4,the relative inaccuracy of the model output varies as the number of iterations rises.Early in the training process,relative error falls fast.After a certain number of training instances,the relative error fluctuates slowly and must be raised.Multiple rounds are required to get more precise findings.After 20,000 iterations,the relative error decreased to 4.9%,and the resulting solution was shown in Figure 4.
The produced heat map is comparable to the result of merging the three datasets direct.By improving the training procedure further,the outcomes will approach those of direct data integration.

Fig.4 Relative error versus iteration number(after smoothing)
4 Application cases of federated learning in educational data mining
Traditional machine learning approaches typically require researchers to gather and centrally handle large amounts of educational data samples,which can lead to privacy violations and data leaks during data collection,transfer,storage,and usage.Federated learning provides a solution to these challenges by enabling the machine learning process to be conducted locally by participants,eliminating the need for data collection and transfer.This approach ensures that communication with the central server is restricted to encrypted settings,thereby protecting the privacy of participants.
Federated learning is suitable for training almost all machine learning models used in education,and it can increase the precision of these models while addressing data privacy concerns.To illustrate the technique and process of using federated learning,this study uses three examples of teaching quality assessment based on support vector machines,learning resource suggestion based on deep neural networks,and student performance analysis based on the K-means clustering algorithm.
By using federated learning,educational institutions can securely train machine learning models without compromising the privacy of their students and teachers.The approach eliminates the need for centralized data collection,ensuring that sensitive information remains on local devices.Through this decentralized process,the privacy of participants is maintained while enabling collaboration and improved data analysis.
4.1 Application of Federated Learning in Support Vector Machines
Training a teaching quality assessment model using support vector machines(SVM)involves identifying the hyperplane with the largest geometric margin that effectively separates the categories in the teaching evaluation data.However,conventional SVM approaches require collecting data for centralized processing,which can lead to data breaches and privacy violations.In contrast,federated learning SVM algorithms allow the machine learning process to be performed locally by the participants,eliminating the need for data transfer or collection.
The process involves the central server initializing the teaching quality evaluation and classification task,determining the necessary data,selecting participants based on their data,and distributing starting parameters.Each participant then performs local SVM operations,calculates the gradient,updates local parameters,and transmits results back to the central server.The server averages the local parameters and transmits the computation results back to participants until the loss function converges.The central server delivers the teaching quality assessment model for testing and verification.Using federated learning,the SVM method exhibits similar performance to the conventional SVM technique in terms of model convergence speed and accuracy.Studies comparing the two techniques using the MNIST dataset show that the centralized classical SVM method model achieved convergence in around 14 seconds with an accuracy of 87.7% using the same processing resources.The federated learning SVM method achieved convergence in approximately 15 seconds,with a model accuracy of 87.7%.The use of federated learning in SVM training not only improves efficiency and precision but also secures participants’ privacy[18].This method can be applied to other machine learning models in education,such as learning resource suggestion based on deep neural networks and student performance analysis based on the Kmeans clustering algorithm,further enhancing data privacy and precision.
4.2 Application of Federated Learning in Deep Neural Network Algorithms
The deep neural network-based learning resource recommendation algorithm involves the extraction of learner and learning resource features,scoring them,and then recommending resources to the learner based on the score[14].To prevent data leaks,the feature extraction process of the deep neural network may use federated learning,which distributes the computation process to local participants.Figure 5(b)illustrates the federated learning process for retrieving learner features in a deep neural network.Initially,the central server defines the network’s topology and fundamental parameters.Participants adjust the network settings based on the local learning scenario data,which they then report to the central server.The participants in the federated learning deep neural network procedure for obtaining learning resource characteristics may include educational institutions or organizations.
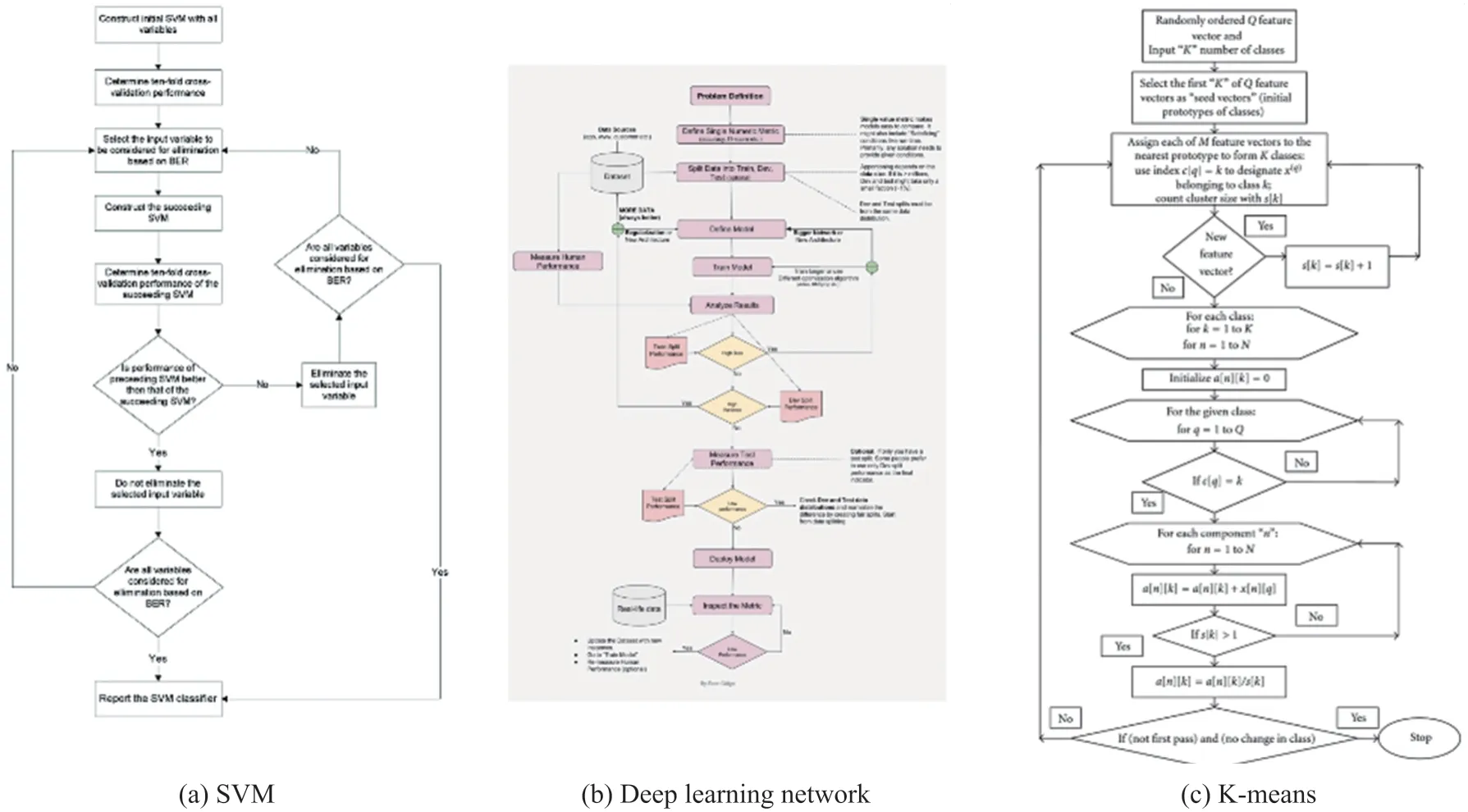
Fig.5 Flowchart of the application of federated learning in support vector machines,deep neural networks,and K-means clustering algorithms
By utilizing federated learning in deep neural network-based learning resource recommendation,the privacy of participants is protected while maintaining the accuracy and efficiency of the model.Additionally,this approach facilitates the sharing of knowledge across organizations and institutions,improving the overall quality of education.Research studies comparing the performance of federated learning-based deep neural network models with centralized deep neural network models show that the federated learning-based approach achieves comparable accuracy while improving privacy[19].Furthermore,the use of federated learning in deep neural network-based models may enable the creation of personalized learning experiences tailored to individual learners’ needs while ensuring the protection of their personal data.
In summary,the federated learning-based deep neural network approach for learning resource recommendation has several advantages,including privacy protection,knowledge sharing,and personalization.With the increasing use of educational technology and data,protecting the privacy of participants has become more critical than ever.Therefore,the use of federated learning in educational data mining,particularly in deep neural network-based models,is a promising solution to this challenge.
Several researchers have conducted performance evaluations of both centralized and federated deep neural network learning techniques using the fashion-MNIST dataset.According to the studies,the centralized deep neural network algorithm took 26.4 seconds to train the model and achieved an accuracy of 87%.On the other hand,the federated deep neural network algorithm utilized a large number of participants with a total computing power greater than that of a single server.Despite the time-consuming communication process,the algorithm was still able to train the model in less than a second.Specifically,the model was trained in 16.75 seconds with an accuracy of 85.15%[19].It is clear that the federated learning technique significantly enhances the performance of the deep neural network algorithm.Although there is a slight decrease in precision,the overall results are satisfactory.
4.3 Application of Federated Learning in K-Means Clustering Algorithm
The K-means clustering technique is commonly used to analyze student performance by partitioning student performance data intoKgroups and assigning each group a cluster center.The objective is to minimize the sum of squares of the distances between each data point and its cluster center.In federated learning,the central server determines the number of clustersK,and each participant selects its local clustering center based on locally stored score data.The selected clustering center,together with the gradient,is then uploaded to the central server.The central server aggregates the cluster centers and transmits them back to the participants for local optimization,repeating the process until the loss function converges.
We conducted a comparative analysis of the performance of the centralized K-means clustering method versus the federated learning K-means clustering algorithm using datasets from UCI.The results showed that the centralized method had an accuracy rate of approximately 98%,while the federated learning approach had an accuracy rate of about 95%[21].However,the federated learning approach offers the advantage of preserving the privacy of the participants while improving the accuracy of the model.Furthermore,in practical applications,federated learning approaches may result in higher-quality models due to the availability of more data.Participants in federated learning can be either individual students with substantial past performance data or institutions with large amounts of student performance data,depending on the specific learning task at hand.
4.4 The impact of federated learning on stakeholders
The integration of intelligence and technology in education is a complex undertaking that involves a wide range of stakeholders,including students,educators,software developers,researchers,and others.The adoption of federated learning in the development of intelligent education systems represents a mutually beneficial approach that maximizes stakeholder engagement and meets the diverse requirements of each party involved.By addressing privacy concerns in machine learning,federated learning facilitates the collection and integration of data from multiple sources to train high-quality models,thereby enhancing the effectiveness and efficiency of the educational process.
To encourage participation and data sharing among stakeholders,federated learning implements several incentive mechanisms that reward high-quality data contributors[22].For example,some researchers propose a service pricing scheme where model owners determine the required dataset size based on their task needs,and participants price their data units based on availability.This pricing mechanism encourages participants with extensive data to contribute to model training,thereby ensuring the availability of high-quality datasets for intelligent education development.Additionally,some researchers implement a reputation system that measures the quality and dependability of federated learning members based on their reputation scores.This rating system helps to ensure the security and maintenance of reputation scores by adding them to the reputation blockchain.When initiating a federated learning activity,the central server selects participants based on their reputation scores.
Through the use of federated learning,diverse stakeholders in education can benefit from the development of intelligent education systems.For instance,students can leverage artificial intelligence technology to enhance their learning experience without compromising their privacy[23].High-quality models produced through federated learning can provide students with more personalized learning assistance,thereby increasing learning effectiveness and efficiency.Teachers can also utilize federated learning to enhance their professional knowledge and teaching skills,leveraging educational experience and knowledge to improve their teaching models and evaluation methods.Educational institutions can maintain ownership and access rights to their data,while ensuring the privacy of their pupils,reducing the likelihood of collaboration with third parties and minimizing data abuse and leakage.Participation in federated learning is open to institutions of all sizes,and the creation of useful datasets allows each institution to benefit from a more complete and accurate global model.Educational technology researchers and developers can access actual data through federated learning,reducing the need to collect data and speeding up research and development efforts.Manufacturers of educational software and hardware can also utilize federated learning to gather data without compromising privacy,optimize product designs,and increase revenue.
In conclusion,the use of federated learning in the development of intelligent education systems represents a promising approach to addressing privacy concerns while maximizing stakeholder participation and the integration of diverse datasets.By employing incentivization mechanisms and reputation systems,federated learning facilitates the creation of high-quality datasets and the training of accurate and effective models,benefitting all stakeholders involved in the educational process.
5 Conclusion
The need for educational data in developing educational artificial intelligence technologies has become increasingly crucial in the era of big data.The research area faces significant challenges concerning the limited dissemination of data and the need for improved data privacy regulation by relevant authorities.However,the emergence of federated learning has introduced fresh ideas to the artificial intelligence domain,enabling it to overcome data silos and further its progress.To tackle data silos in the visualization industry,this study proposes a federated visualization framework based on the concept of federated learning.The key concept of this framework is to use visualization as a model and train it while encrypting the data and ensuring that it remains with the data owner.The federated learning approach will help overcome privacy protection challenges in educational data mining by integrating fragmented educational data and distributing the model learning process to each participant’ s local decentralized computer.The federated visualization framework offers an effective solution to data barriers and allows data owners to collaborate on data analysis.However,the federated visualization research is still in its early stages,and several challenges need to be addressed.In terms of privacy,the proposed federated visualization method effectively prevents the leakage of private data.In terms of accuracy,when the feature data to be fitted is less than 1 000,the accuracy rate can be over-fitted after thousands of iterations.Since over thousands of training iterations,the model complexity keeps increasing to perfectly fit the limited training data.But after reaching sufficient capacity,adding more complexity leads to overfitting where minute details get modeled losing the general pattern in the data.Therefore,having less than 1 000 feature data points can lead to overfitting in terms of accuracy metrics.The validation accuracy is a better indicator in such cases than the ever-improving training accuracy.However,more feature data requires more iterations to achieve the desired level of accuracy.Furthermore,the proposed method only considers tabular data and can draw common visual charts,such as bar charts,pie charts,and h-charts.The application of federated learning to the area of visualization has substantial practical implications and holds great promise for the future.
