Python在数学建模中的应用初探
2024-01-29王海龙刘飘飘王易平
王海龙 刘飘飘 王易平
(1邯郸职业技术学院,河北 邯郸 056005;2吉利学院,成都 641423)
作为开源免费语言,Python语言简洁易读、扩展性强,在科学计算、数据处理等方面功能强大,可以帮助我们解决各类数学问题,在数学建模中具有广泛的应用,逐渐成为数学建模中的常用编程语言。Python提供了数学建模所需的丰富的工具和库,比如NumPy、SciPy、Matplotlib、Pandas、Pulp 等,下面通过一些实际问题来探讨它们在数学建模中的具体应用。
一、Python在解决线性规划问题中的应用
线性规划主要是利用数学方法使资源的运用最优化,是数学建模问题中的常见类型。首先看一个典型题目:有一项工作需译成英、日、德、俄四种文字,现有甲、乙、丙、丁四人,他们翻译成不同语种的所需时间见表1,问如何安排人员最省时间?
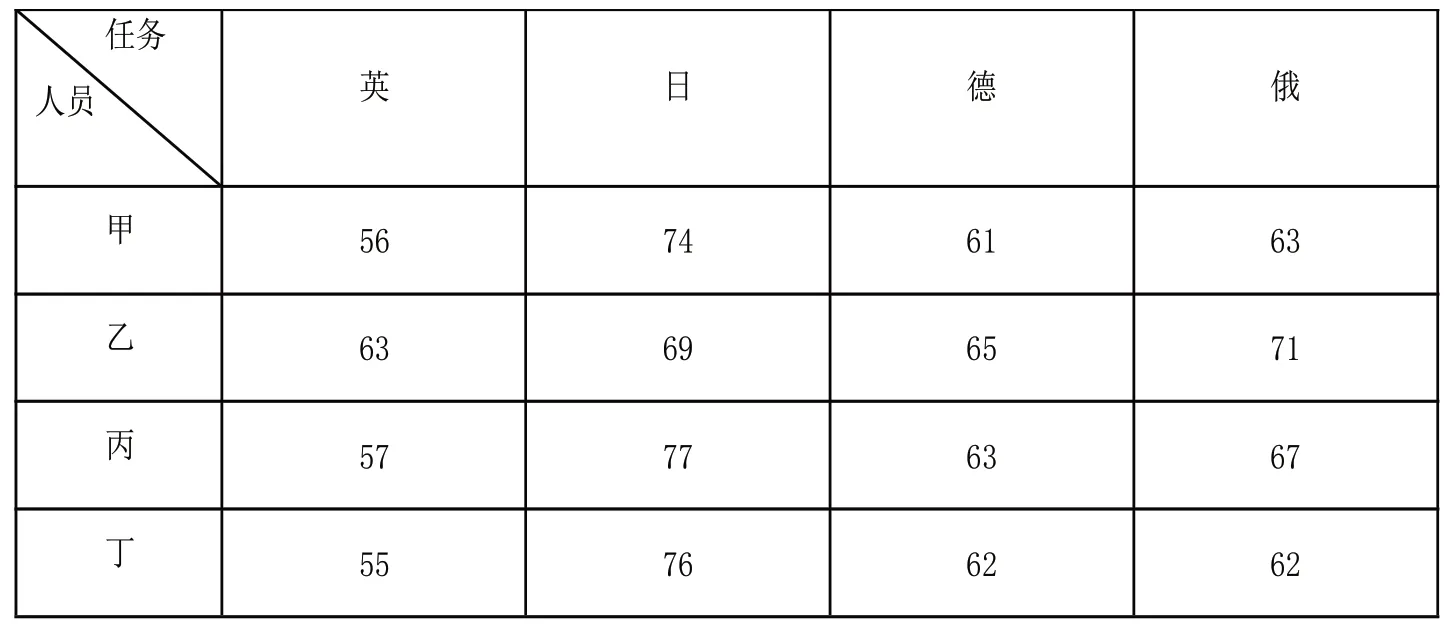
表1 四人翻译不同语种的所需时间(单位:h)
由于每个人仅参与一项翻译工作,每个语种翻译工作仅有1人完成,因此约束条件为:
这个问题可以运用Python语言的Pulp模块来求解。Pulp模块不是Python的默认安装模块,需要使用pip安装。具体解题步骤如下:
1.定义问题为LP,求最小值(LpMinimize):
2.定义变量x,参数cat="Binary"定义变量类型为0-1型:
3.定义目标函数,格式为“问题名+=目标函数式”:
4.添加约束条件,格式为“问题名+=约束条件表达式”:
5.求解,solve()为求解函数:
6.输出,LP.objective是目标函数值的最优解,LP.variables为每个变量的最优解:
在以上解题中,使用了Python 语言的pulp 模块,输出时还使用了pandas 和numpy 模块,因此需要在程序中先使用import来导入这三个模块。
NumPy 支持大量的维度数组与矩阵运算,Pandas 的函数和方法可以快速处理数据,这两个模块都可以在数学建模中发挥重要作用。上面题目如果数据量增加,可以通过pandas的read_excel函数来读取,并可将计算结果再输出到excel表格中。
二、Python在数据处理和分析中的应用
数学建模就是要用数学的办法来优化和解决实际问题,题目通常源于生产生活,原始数据样本采集自各个领域,一般数据量较大,且数据可能存在缺失、异常等情况,因此数据的处理和分析对数学建模非常重要。Python拥有的强大数据处理和分析能力,在数据读取与预处理、数据分析、数据可视化等方面都可以发挥重要作用。
2021 年全国大学生数学建模竞赛E 题:中药材的鉴别,题目附件1 给出的数据量为425(药材的编号)×3348(光谱的波数),如何分析和处理这上百万的数据是解决问题的基础。读取数据:由于Python读取csv文件速度较快,可以先将所给数据另存为csv格式,再使用pandas的read_csv函数导入。数据处理:导入的数据结构为DataFrame,可以使用众多函数处理数据,使用columns、index、values函数输出列索引、行索引、值,使用describe函数查看数据的统计性信息,还可以通过loc、iloc函数获取行或列的数据,Concat函数可用于拼接数据等等。绘制图像:Matplotlib库的pyplot函数可方便地绘制图像。使用Python将附件1给出的数据绘制图像如图1所示:

图1 各波段下药材吸光度图
2022 年全国大学生数学建模竞赛E 题:小批量物料的生产安排,题目需首先计算各种物料需求出现的频次、需求数量、平均价格等。可以使用Pandas 的分组函数groupby 和聚合函数agg 很快求出:首先使用pandas的read_csv 函数读取附件的csv文件,将数据存储为DataFrame 对象;然后使用groupby 函数对数据按“物料编码”列分组,并使用聚合函数agg 对“物料编码”列计数,对“需求量”列求和,对“销售单价”列求平均值;最后使用pandas的to_csv()函数将结果导出。导出数据表如图2所示(部分截图):
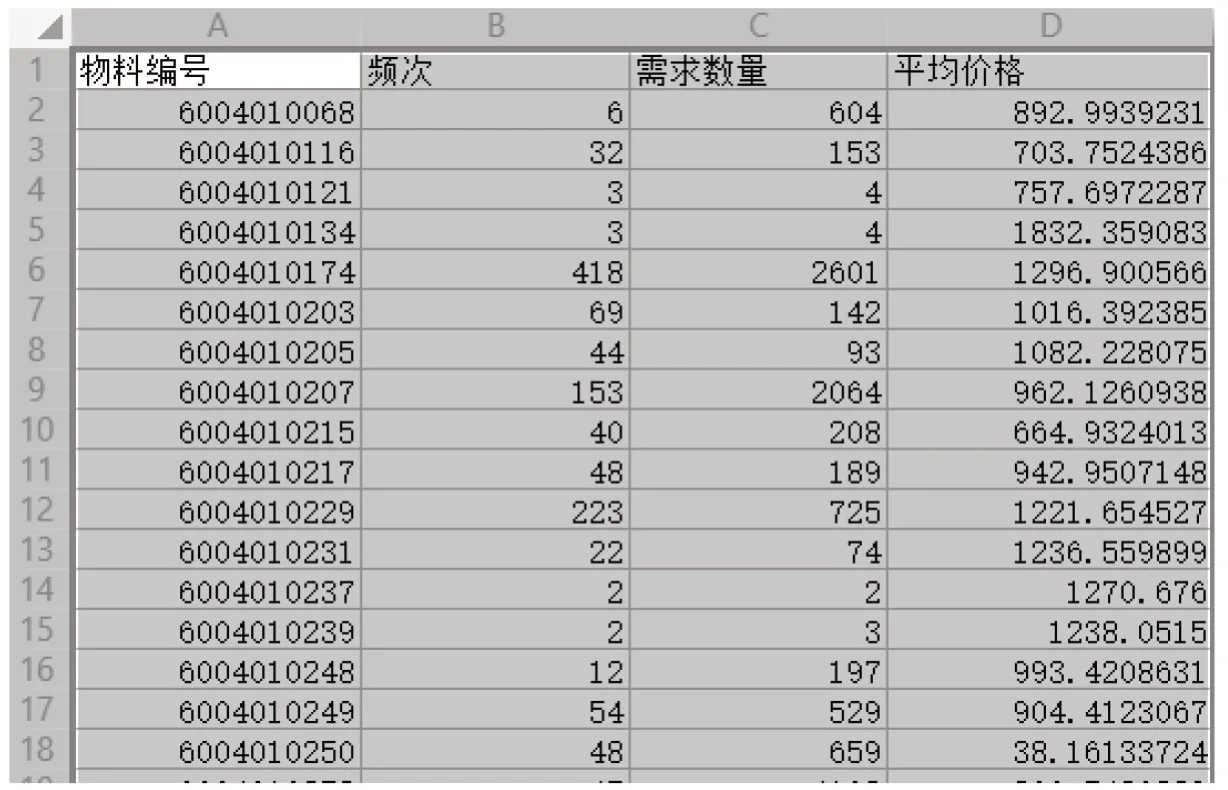
图2 物料的频次、需求数量、平均价格表
三、Python在采集网络信息中的应用
数学建模有些题目需要参赛者自己采集网络数据。2015 年全国大学生数学建模竞赛B 题:“互联网+”时代的出租车资源配置,就要求参赛者自己搜集相关数据,需要查找典型城市的出租车情况(数量、分布等)以及运营情况(高峰期、空载率等),从而得出出租车资源的供求关系。2019年全国大学生数学建模竞赛C题:机场的出租车问题,就需要参赛者自己收集国内某一机场数据(如机场航班架次等)及其所在城市出租车的相关数据(如出租车数量等),从而研究机场乘客数量与出租车流量的关系。
Python语言功能强大,可以方便地获取大量网络数据。Python的requests库可爬取网页数据,Beautiful-Soup库可解析网页,正则表达式re 库可检索网页,获得需要的信息。比如在当当网搜索数学建模类图书,检索得到100个页面,每个页面有50本图书的信息,利用Python编写爬虫程序,可以很快爬取这些图书的名称和价格等信息,并导出到excel表格中进行查看处理。导出数据表如图3所示(部分截图):
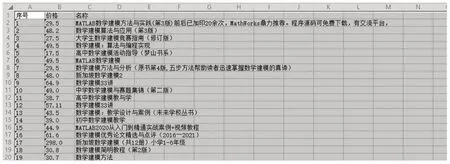
图3 爬取的当当网数学建模类图书表
除此之外还可以通过开源大数据平台来获取数据,比如利用Python的财经数据接口包TuShare来采集股票等金融数据,然后进行数据分析和可视化等操作。
