一种基于改进YOLOv5s的高速公路广告实时检测算法
2024-01-26赵丁莹刘正才雷宇斌朱建伟王书涵
赵丁莹,刘正才,雷宇斌,朱建伟,王书涵,
(1.湘潭大学 土木工程学院,湖南 湘潭 411105;2.湖南科技大学 地理空间信息技术国家地方联合工程实验室,湖南 湘潭 411201;3.湖南省第一测绘院,湖南 长沙 410114)
0 引言
高速公路广告牌基数庞大,随着我国高速公路现代化建设的不断推进,高速公路广告牌的数量将持续增长.作为高速公路的重要运营模块之一,现阶段对于高速公路广告牌的管理依旧采用人工巡检的方式,该方式存在作业危险系数高、效率低下以及信息管理不便等问题[1-2].研发新型的高速公路广告牌智能巡检技术已成为亟须解决的一大问题.目标检测作为几乎涵盖各类AI项目的第一步,对整个项目最终的结果具有重要意义.现阶段目标检测算法直接应用于高速公路广告牌目标检测,面临以下几个主要问题:(1)高速公路广告牌影像数据集匮乏;(2)移动小型设备提供的算力有限,模型需尽量轻巧;(3)在高速行驶条件下进行实时检测,目标尺度变化剧烈,同时容易造成广告牌密集区域数据的运动模糊,降低检测精度.
传统的数字图像处理技术难以满足实时检测的需求.近年来,深度学习对目标高纬度信息强大的挖掘能力被广泛应用于各类目标检测任务中.李晗等[3]提出了一种以固态硬盘(SSD)进行迁移学习的户外广告牌检测方法,虽可行度高,但易出现漏检.卜江等[4]采用模糊决策树探测视频流关键帧,抽帧后基于图像颜色特征和局部尺度不变特征变化的特性与模板商标进行匹配来实现对广告牌目标的检测,该方法较好地结合了传统方法与机器学习的优势,但模板匹配的方法需要大量的样本建立数据库.党倩[5]基于无人机平台,以YOLOv5算法结合级联分类器的方法实时检测高速公路广告设施,但在高速巡检状态下检测精度欠佳.刘罗成等[6]融合YOLOv3目标检测算法和语义分割算法识别城市道路旁的违规广告牌,该方法虽实时检测性能较好,但检测速度较慢.尽管现有目标检测方法在精度和实时检测能力上远远超越了传统方法,但在面对小型移动式嵌入检测平台处于高速运动状态且仅能提供有限算力等苛刻条件时,算法性能有待进一步的提升.
当下主流的目标检测算法按照深度学习模型的网络架构阶段数的差异分为两类:双阶段模型(two-stage)和单阶段模型(one-stage).其中,双阶段检测法虽然检测精度较高,但是模型体积大、计算速度慢且算力要求高,难以满足实时检测的需求,其代表性算法有Faster-RCNN[7]等;而单阶段检测法将目标检测当作回归问题来解决,可以一步得出待识别物体类型及所处图像的位置坐标值,检测速度和模型体积更适用于实时检测任务,其代表算法为YOLO[8-11]系列,还有SSD[12]、EfficientNet[13]、RetinaNet[14]等.YOLOv1于2016年首次被Redmon等[8]提出,随后该团队更新了YOLOv2和YOLOv3,2020年,YOLOv4、YOLOv5 又相继被提出.本文聚焦于解决高速公路广告牌目标检测所面临的主要问题,提出一种改进的YOLOv5s标检测算法,为高速公路广告牌智能巡检平台视觉系统提供技术支撑.
1 YOLOv5介绍与改进
YOLOv5作为最具代表性的一阶段检测算法,其网络架构可以灵活地进行网络深度、宽度调整以及网络组件配置,非常适合于算力有限设备的基础部署模型.
1.1 YOLOv5算法介绍
YOLOv5网络架构分为输入端、骨干网络(Backbone)、颈部网络(Neck)、预测层(Head)4部分,其中YOLOv5s的简化网络架构如图1所示.
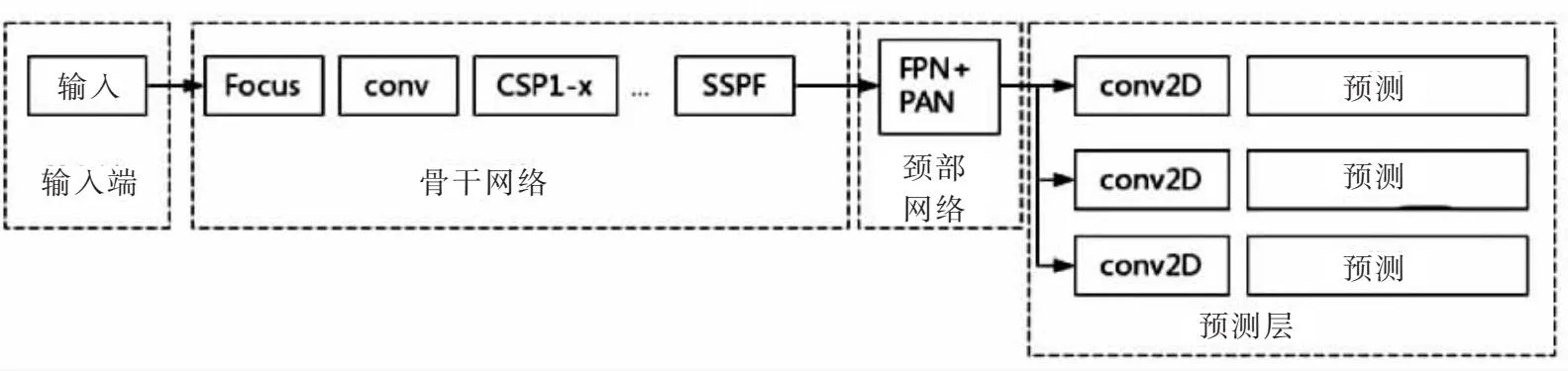
图1 未改进YOLOv5s的网络架构Fig.1 does not improve the network architecture of YOLOv5s
输入端主要包含数据增强、自适应锚框计算等功能.骨干网络包含Foucs、CSP1-x/C3、SPP/SPPF 等组件;其中CSP1-x/C3模块一共封装了向量卷积运算[15]、归一化处理[16]、线性整流函数[17]和池化[18]4个功能;SPPF对特征图进行多次最大池化,尽可能多地提取高层级的语义特征,同时保证特征图尺寸和通道数不变;但骨干网络中的CSP1-x结构包含的参数量较大,使模型应用受限.颈部网络(Neck)负责完成多尺度特征融合,Neck部分的组件有CBS、Upsample、Concat和不带残差神经网络的CSP2-1;YOLOv5采用FPN[18](Feature Pyramid Network)+PA-Net[19]双向耦合的特征融合策略,Neck层的特征融合金字塔中包含两个PA-Net结构,此外YOLOv5将Neck的普通卷积升级为CSP2-1结构;虽然相比YOLOv4版本具有更强的特征融合能力,但在应对尺寸变化剧烈的检测任务时依旧存在可提升的空间.预测层主要完成锚框的非极大值抑制以及训练损失函数计算[20],表达公式如式(1)所示,通过改变每个损失函数权值(λ)可以调整对三者(分类损失Lclsj、定位损失Lobjj、置信度损失LCIoUj)的关注度.
(1)
式中:λ1、λ2、λ3为损失函数权值;Lclsj为分类损失;Lobjj为定位损失;LCIoUj为置信度损失.
1.2 YOLOv5改进
针对现有算法难以满足高速公路广告牌高精度实时检测任务需求的问题,本文基于YOLOv5s进行改进,主要改进为:将骨干网络中的CSP1-x模块替换为性能更优、参数量更少的PP-LCNet网络,在特征提取能力基本不变的同时实现模型的轻量化;将颈部网络中的双向金字塔特征融合网络中的PA-Net网络改为ASFF自适应特征融合网络,进一步提高轻量化模型的特征融合能力,改进后的YOLOv5s网络架构如图2所示.
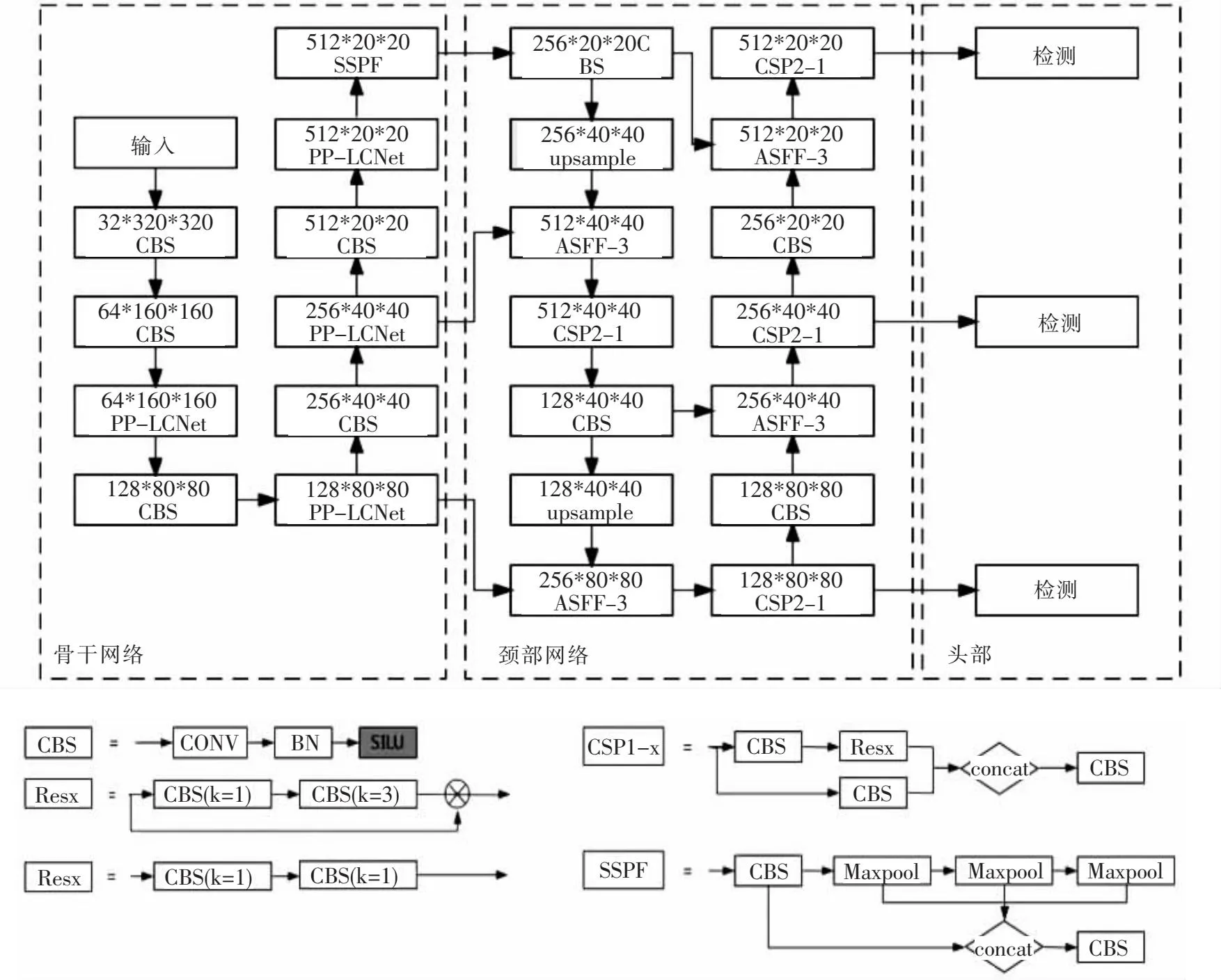
图2 改进后的YOLOv5s网络架构Fig.2 Improved YOLOv5s network architecture
1.2.1 骨干网络的改进
YOLOv5骨干网络中采用CSP1-x结构使其获得了强大的深层特征提取能力,但大量的网络参数和浮点数导致该算法在小型移动设备实时检测应用中效果欠佳.为了兼容模型强大的特征提取能力与轻量化的体积,本文引入百度团队提出的PP-LCNet网络[21]对骨干网络中的CSP-x模块进行替换.PP-LCNet在检测精度和模型体积上的优势超越现有的轻量级网络.PP-LCNet网络架构如图3所示,Stem部分使用标准的3×3卷积,基本模块为深度可分离卷积(DepthSepConv);DW表示深度方向卷积,从Stem层开始,中间包含了13层DW;PW表示方向卷积;GAP表示全局平均池化;此外还包含虚线框内的SE注意力模块.
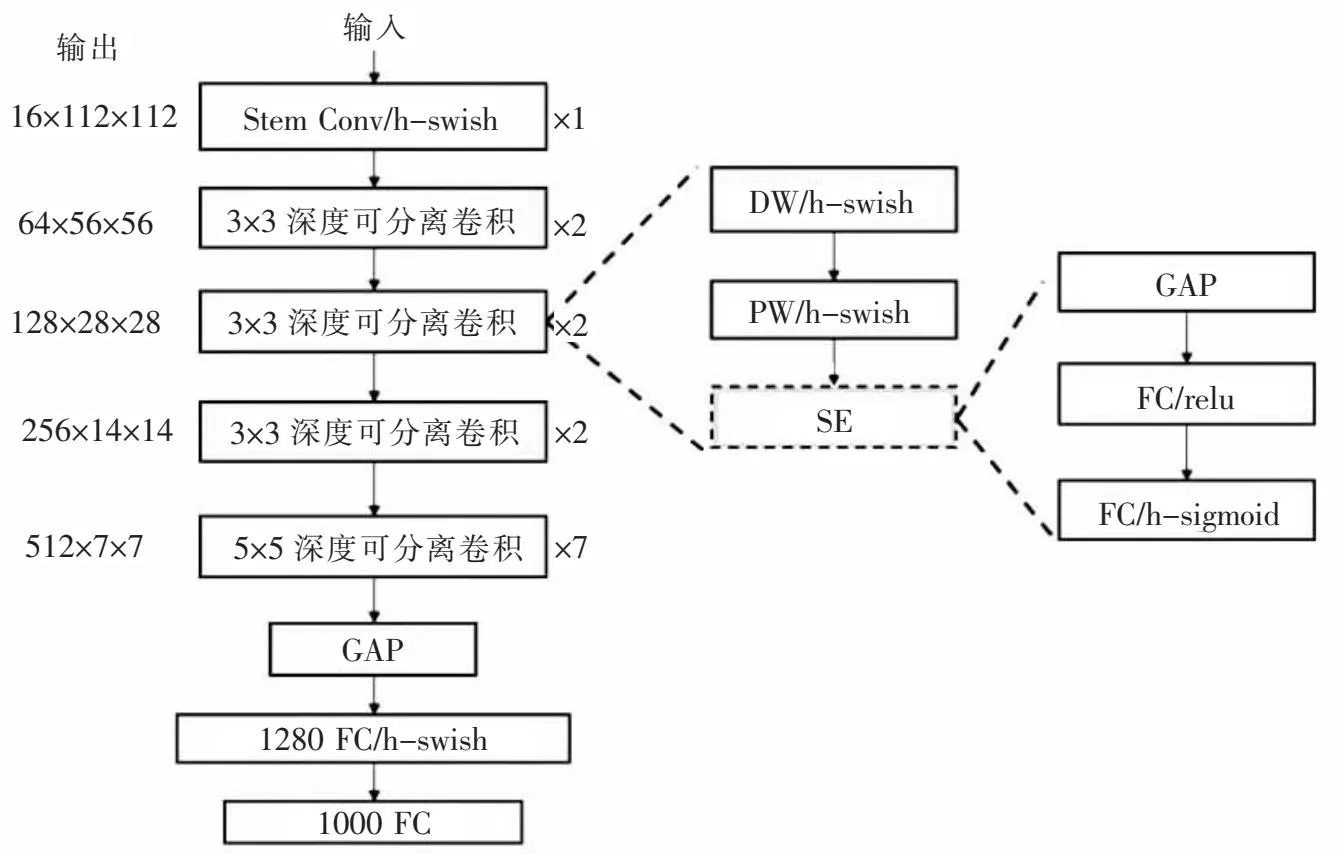
图3 PP-LCNet网络架构Fig.3 PP-LCNet network architecture
PP-LCNet较同级网络能保证在推理时间不变的情况下挖掘到更多的深度语义特征,PP-LCNet中深度可分离卷积选择了性能更好的H-Swish激活函数,避免了大量的指数运算;同时采用了更大的卷积核,在网络的末端进行了5×5卷积内核替换操作;此外,在最后的全局平均池化层与全连接层之间插入一个1 280维大小1×1的卷积核,解决网络输出尺寸较小的问题;最后,为了注意力机制能更好地捕捉显著特征,调整了SE模块至更合适的安装位置,文献[22]经过大量实验验证指出,当SE模块位于网络末端时,能产生最佳的精度与速度的平衡.PP-CLNet较CSP1-x参数量减少了36%,但该网络的特征提取依旧具有鲁棒性.
1.2.2 颈部网络的改进
高速巡检时要求检测模型能够在目标尺度变化剧烈的条件下进行高效的特征融合.YOLOv5现有的PA-Net特征融合方法只是简单地对FPN输出的不同特征层统一尺寸后再相加,这种融合方式不能有效地对抗不同尺度目标的不同层级特征之间冲突的不一致性导致的梯度传播干扰.ASFF算法[23]能学习自适应融合不同层级的特征,在空间上过滤冲突信息以抑制梯度反向传播时的不一致性.其适配最优融合的操作过程是差分的,所以非常方便在网络中进行部署,且不干预主干模型,实现简单.本文将特征融合层中的PA-Net替换为ASFF组成新的特征融合网络,在计算体积基本不变的情况下能更好地融合高层的语义特征和底层的细粒度特征.ASFF结构如图4所示:
图4中的第一层、第二层、第三层分别为FPN特征金字塔输出的特征图,虚线框内则演示了ASFF-3的特征融合过程.融合的ASFF-3为不同层级输出与可学习权重系数α3、β3、γ3的乘积的和,计算表达式如下:
(2)
(3)
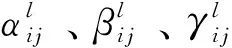
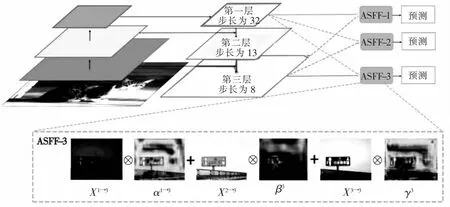
图4 ASFF网络结构Fig.4 ASFF network structure
在高速公路广告牌目标检测任务中,虽然只有广告牌一个目标类别,但在高速运动状态下进行目标检测任务,目标尺度变化剧烈,瞬时图像中往往存在多个不同尺度的目标,如图5所示,图中从左到右广告牌目标尺度依次增大,按该顺序定义图中3个目标分别为小目标、中目标和大目标,分别对这3个目标做可视化分析.
在图6所示的第一层、第二层、第三层中,左边为小目标的可视化特征图,中间为中目标的可视化特征图,右边为大目标的可视化特征图.

图5 高速公路广告牌多目标样例 图6 特征图可视化Fig.5 Example of a highway billboard with multiple targets Fig.6 Feature map visualization
在第一层中,相对尺度最大的大目标响应剧烈,很容易就被检测到,这说明深层网络更注重语义信息,对于尺度相对较大的检测目标,检测头需要配置更大的感受野,更加顾及基于底层特征的相互逻辑关系所构建的高级的语义特征,如由广告牌边缘、颜色、纹理等所构成的“广告牌目标”这个高层的语义特征;第二层检测到相对尺度较小的中目标和小目标;而相对尺度最小的小目标在第三层响应剧烈,大目标在该层则未被检测到,这说明浅层网络更加注重细节信息,对于尺度较小的目标则需要底层的细粒度特征来判别,诸如广告牌中的边缘特征、局部的颜色特征、轮廓特征、空间关系特征等.ASFF实现了每一层的权重参数与特征求积再相加的特征融合方式,只保留该层的有效信息,该方式能更好地融合不同层的特征信息,相较于原有模型简单统一特征图尺寸后就相加的特征融合方式能有效地提升模型的训练效率.
2 实验与分析
2.1 数据集构建
高速公路广告牌智能巡检技术还处于研发阶段,已开源的数据集匮乏,针对该问题,本文自主制作了一份高速公路广告牌影像数据集.数据来源于湖南省长株潭城市群长潭西高速路段,长度约24 km,其地理坐标为28°3′36″N~28°9′30″N,112°52′12″E~112°52′48″E.沿线两侧高炮广告牌共128个,车载相机型号为DSC-RX1RM2,像素为4 020万,焦距为35 mm.沿线采集图像数据,剔除拍摄不清晰、角度不合理、图内目标丢失等数据;其次为了防止在模型训练过程中发生过拟合或欠拟合的情况,引入百度和361图库中符合要求的高速公路高炮广告牌图片,使数据集所体现的样本特点更具普适性.最终得到总计2 200张高速公路广告牌影像,按照1~2 200对图片进行随机编号排序,方便对数据集进行分割.本文对训练集、验证集、测试集的划分对应比例为8∶2∶1.数据标注基于Labellmg软件的YOLO格式人工标注完成,总计标注真实目标框9 774个,目标框对应的标签文件包含其中心点横纵坐标、长宽以及一个总类别标签,存储格式为txt格式,数据集标签信息统计如图7所示.
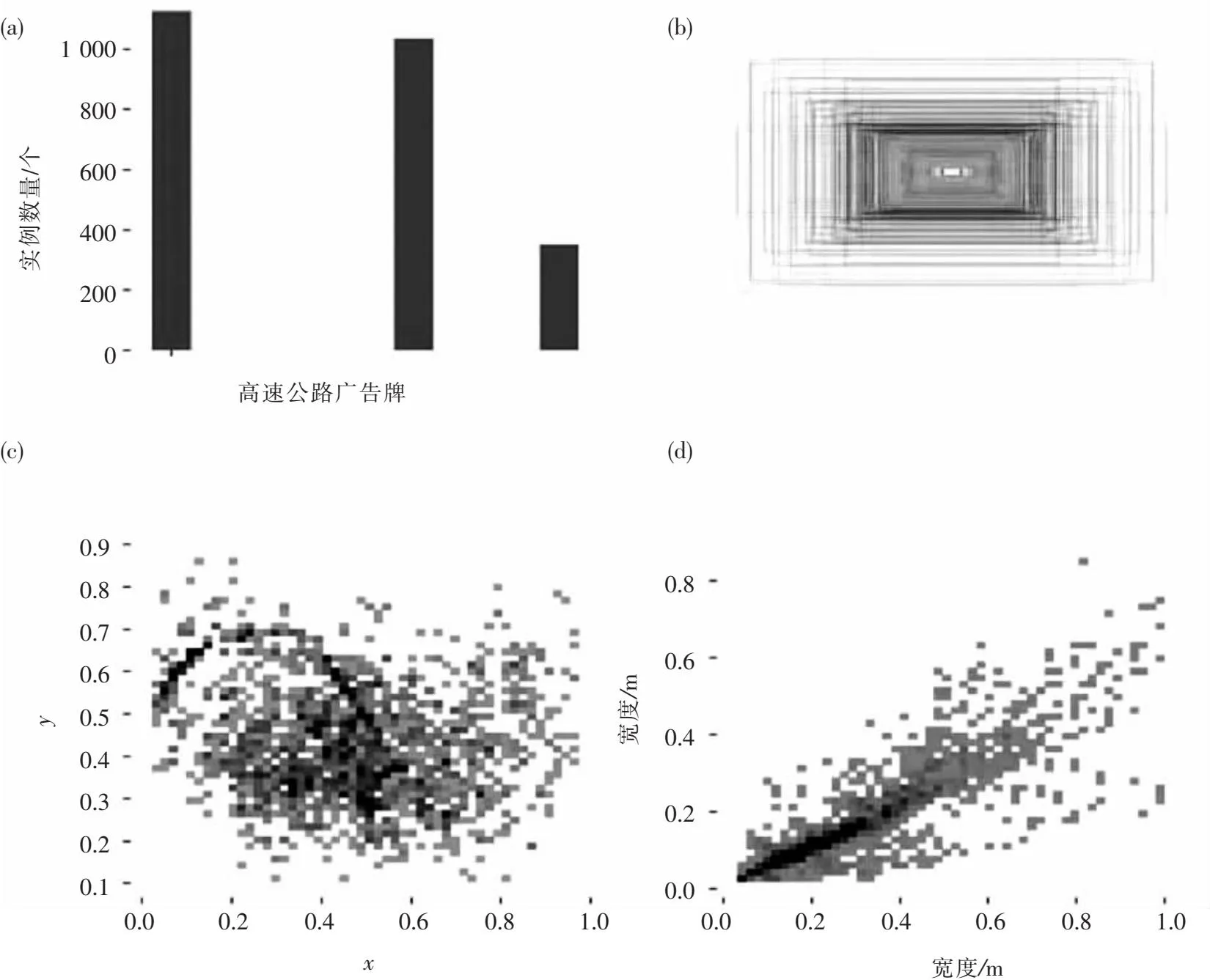
图7 (a)数据实体;(b)标注框可视化;(c)标注框中心点坐标分布;(d)标签尺寸分布Fig.7 (a)Data entity;(b)Dimension box visualization;(c)Coordinate distribution of the center point of the dimension box;(d)Label size distribution
2.2 评价指标
本文采用的评价指标有:精确率(Precision)、平均精度(AP)、召回率(Recall)、帧率(FPS).计算方式为:预测值为正样本记为P;预测值为负样本记为N;预测可能发生的情况以混淆矩阵的形式表示,如表1所示.

表1 混淆矩阵
则精确率、召回率、平均精度指标按如下公式(4)计算.
(4)
式中,APc为第c个类别的精确率.
2.3 模型训练
模型训练基于自建数据集,使用随机梯度下降法(SGD)[23]进行梯度更新,训练次数设置为 200 轮,训练批的大小为16,训练参数设置如表2所示.

表2 训练参数设置
在本文实验数据上的收敛效果如图8所示.
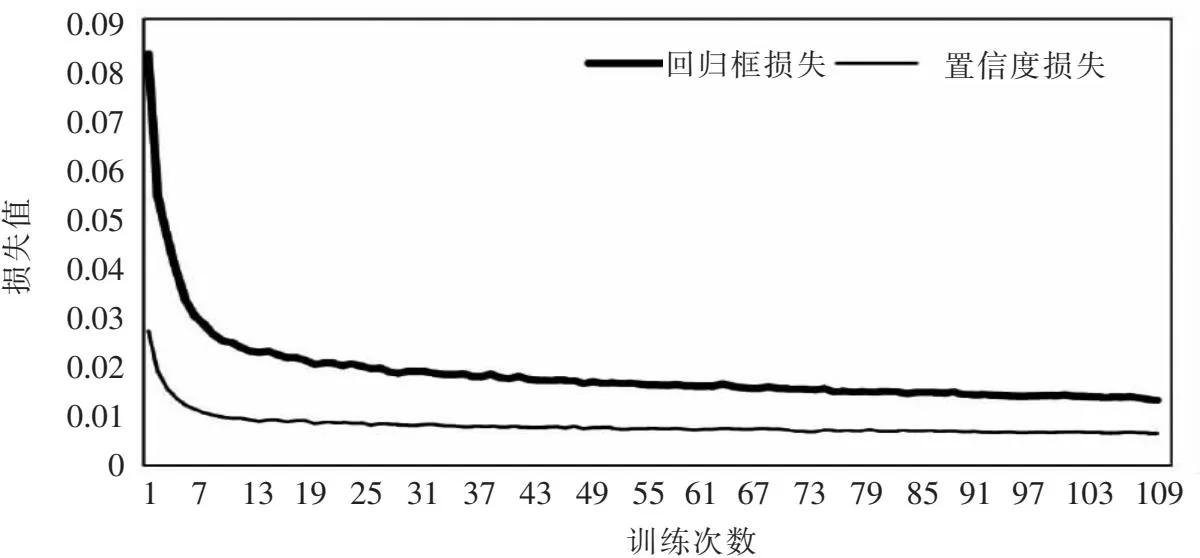
图8 改进YOLOv5s的损失函数Fig.8 Improved loss function of YOLOv5s
由于本文仅针对高速公路广告牌一个类别标签进行训练,故类别损失为0,图中仅展示回归框损失与置信度损失.本文模型的检测效果主要评价因子变化如图9所示.
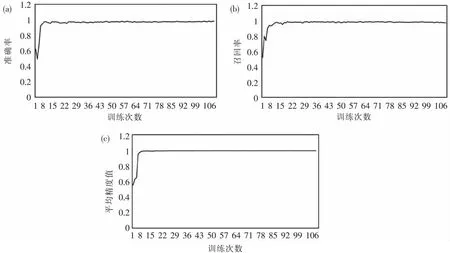
图9 改进YOLOv5s的评价因子变化:(a)精确率变化图;(b)召回率变化图;(c)平均精度变化图Fig.9 Improvement of YOLOv5s evaluation factor changes:(a)Accuracy variation chart;(b)Recall rate change chart;(c)Average accuracy variation chart
可见,本文提出的改进YOLOv5s算法在自建集上的性能非常好,收敛速度快,只训练了30轮左右时两类损失函数就已经趋于稳定;检测精度高,仅训练10轮左右mAP就已经达到98.5%.最终的实验结果表明,本文算法在自建集测试中AP达到99.2%,Recall达到97.2% ,FPS达到77帧,并且权重大小仅10.8 MB,完全满足高速公路智能巡检目标检测任务的需求.为了模拟该模型的实时检测效果,本文基于车载相机录制了长潭西高速路段模拟巡检视频,并在仅配置CPU的计算机上模拟实时目标检测任务,结果表明本文算法在高速出入口广告牌密集路段、广告牌背景地物复杂路段以及高速行驶等条件下依旧具有鲁棒性,部分检测效果如图10所示.

图10 改进的YOLOv5s算法检测效果Fig.10 Improved detection effect of YOLOv5s algorithm
2.4 对比实验与分析
为了更好地体现本文算法在高速公路广告牌目标检测任务中的优势,开展了与Faster-RCNN、SSD、YOLOv4、YOLOv5m以及未改进的YOLOv5s的对比实验.所有模型训练均基于本文自建集在相同训练条件下开展.各模型在权重大小、平均精度、召回率以及推理时间对比结果如表3所示.由表3可知,从权重大小来看,YOLOv5s算法较二阶段检测算法Faster-RCNN、一阶段检测算法SSD和同系列的YOLOv4、YOLOv5m是最轻量的算法,权重大小仅为14.7 MB,但文本改进的YOLOv5s算法在此基础上体积再次缩小了26.5%,仅有10.8 MB,非常适用于安装在小型移动检测设备上.从平均精度、召回率与推理时间来看,本文算法虽然比二阶段检测算法AP降低了0.6%、Recall降低了1%,但检测速度大大超越了Faster-RCNN;与一阶段算法相比,较除本文算法外性能最优的YOLOv5s在AP上提高了2.5%、Recall提高了1.9%,推理时间减少了12 ms.综合来看,本文提出的改进YOLOv5s算法在自建集上的性能表现最佳.可见,本文算法较好地解决了高速公路广告牌实时目标检测任务所面临的问题,具有较高的应用价值.
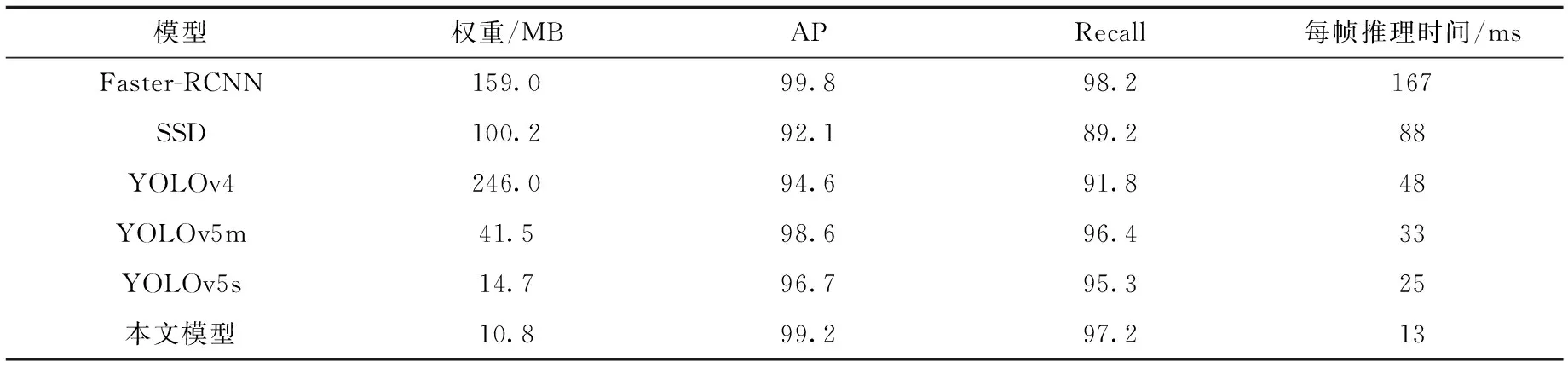
表3 对比实验结果
2.5 消融实验与分析
开展消融实验以验证本文在YOLOv5s算法网络中改进的两个模块对算法整体性能的优化效果.实验结果如表4所示,PL-YOLOv5s表示仅替换骨干网络中的CSP1-x结构后的模型,AF-YOLOv5s表示骨干网络不变,颈部网络中PA-Net替换为ASFF后的模型.由表4可知,Neck不变,将骨干网络中的CSP1-x模块替换为PP-LCNe模块后,参数量大大降低,推演时间较改进前降低了14 ms,但同时平均精度仅损失0.9%;骨干网络不变,将颈部网络的PA-Net特征融合层替换为ASFF自适应特征融合后,模型的平均精度较未改进前提高了2.7%,但同时推演时间仅增加3 ms;最后的实验结果表明,将两个模块同时改进以后耦合效果良好,改进后的模型较原YOLOv5s平均精度提高了2.5%,推演时间减少了12 ms,在检测平均精度和速度上同时得到了提升.

表4 消融实验结果
3 结论
高速公路广告牌智能巡检平台的研发迫在眉睫.本文自主制作了一份可靠的高速公路广告牌影像数据集,同时提出了一种基于YOLOv5s改进的轻量化高精度的高速公路广告牌实时目标检测算法.基于自建数据集的实验结果表明,本文算法平均精度、召回率、权重大小、每帧推演时间分别达到99.2%、97.2%、10.8 MB、13 ms;较未改进的YOLOv5s平均精度、召回率分别提高了2.5%、1.9%;权重大小、每帧推演时间减少了26.5%、12 ms.该方法有效地解决了移动小型设备难以提供足够算力和高速巡检条件下目标检测精度较低的问题,为研发高速公路广告牌智能巡检平台提供了有力的技术支持.下一步将开发嵌入本文模型的移动巡检前端并开展基于车载遥感的广告牌影像信息提取工作.
