结合坐标注意力与生成式对抗网络的图像超分辨率重建*
2024-01-24彭晏飞李泳欣刘蓝兮
彭晏飞,孟 欣,李泳欣,刘蓝兮
(辽宁工程技术大学电子与信息工程学院,辽宁 葫芦岛 125100)
1 引言
图像超分辨率SR(Super-Resolution)重建技术旨在将给定的低分辨率LR(Low-Resolution)图像经过一系列过程恢复出其对应的高分辨率HR(High-Resolution)图像,是一种底层的计算机视觉任务,被广泛应用于卫星遥感[1]、人脸识别[2]和医学成像[3]等领域。早期,图像SR重建分为基于插值[4]的方法、基于重建[5]的方法和基于学习[6]的方法,主要依赖约束项的构造以及图像之间配准的精确度实现重建效果,因此难以恢复出HR图像原本的细节信息。随着深度学习的迅速发展,传统SR重建方法中的瓶颈问题迎刃而解。目前,基于卷积神经网络CNN(Convolutional Neural Network)的方法已经成为主流。Dong等人[7]最先将CNN应用于图像SR重建问题中,提出了具有里程碑式意义的SRCNN(Super-Resolution Convolutional Neural Network),仅使用3个卷积层就实现了从LR图像到HR图像的重建过程。受这一开创性工作的启发,Kim等人[8]提出了具有深层网络的VDSR(Super_Resolution using Very Deep convolutional network),首次将残差学习[9]应用于图像SR重建问题中,实验结果表明该网络取得了更好的重建效果。同年,Kim等人[10]在VDSR的基础上进行改进,提出了DRCN(Deeply Recursive Convolutional Network),该网络使用16个递归层,通过递归监督和跳跃连接的方法提高了模型的性能。由于将经过插值的LR图像作为输入增加了计算复杂度,因此Shi等人[11]提出了ESPCN(Efficient Sub-Pixel Convolutional Neural network),直接将LR图像作为输入,采用亚像素卷积层代替反卷积层实现上采样过程,大大缩短了模型的运行时间。近年来,注意力机制被广泛应用于图像SR重建模型中,Zhang等人[12]将通道注意力集成到残差块中,提出了RCAN(Residual Channel Attention Network),注重特征通道之间的相互依赖性,提高了网络的表达能力。通道注意力机制只是在通道层面选择感兴趣的特征,忽略了空间中的位置信息,而位置信息是视觉任务中捕获目标结构的关键,因此造成了位置特征利用不充分的问题。
上述方法都是采用最小化均方误差MSE(Mean Square Error)的优化思想,虽然在峰值信噪比PSNR(Peak Signal-to-Noise Ratio)上取得了较优的结果,但是生成的图像往往过于平滑和模糊。Goodfellow等人[13]提出的生成式对抗网络GAN(Generative Adversarial Network),将SR重建技术推向了一个新的高度,有效缓解了重建图像的平滑和模糊问题。Ledig等人[14]提出了SRGAN(Super-Resolution Generative Adversarial Network),首次将GAN应用于SR任务,通过生成器和判别器的相互迭代训练实现图像的重建。随后,Wang等人[15]对SRGAN进行改进,提出了ESRGAN(Enhanced Super-Resolution Generative Adversarial Network),将残差块中的批量归一化BN(Batch Normalization)层去掉,使用残差中嵌入残差的结构构建生成器,使得重建图像具有丰富的纹理细节。Li等人[16]提出了用于高质量图像SR重建的Beby-GAN,采用区域感知的对抗学习策略,使重建图像具有更丰富和更合理的纹理。以上网络均使用了经典的VGG(Visual Geometry Group)式判别器,其输出是对图像整体结构进行真假判断,没有对局部纹理进行细致的判断,因此重建图像的纹理细节不够逼真。Yan等人[17]提出了FASRGAN,使用了类U-Net(U-shape Network)判别器,并将判别器的其中一个输出作为细粒度注意力反馈给生成器,提升了重建图像的纹理逼真程度。由于U-Net判别器对复杂的训练输出具有更强的鉴别能力,Wang等人[18]将其应用于盲SR任务中,重建出了清晰且真实的图像。但是,GAN模型仍然面临着因不易收敛和梯度消失而导致的训练不稳定问题。
针对SR重建的现有问题,本文提出了结合坐标注意力和生成式对抗网络的图像超分辨率重建模型。将坐标注意力CA(Coordinate Attention)[19]嵌入到残差块中作为构建生成器的基本单元,可以将通道注意力分解为2个一维特征编码过程,分别沿通道和空间产生注意力特征图,增强模型对特征信息的利用率。引入高级视觉任务中的随机失活层(Dropout)正则化,调节其加入网络的方式,并应用于SR重建任务中,防止过拟合并提高模型的泛化能力。将GAN模型中经典的VGG式判别器改为U-Net式判别器,对局部纹理产生精确的梯度反馈,以生成清晰且逼真的SR图像。并在相匹配的分辨率之间加入跳跃连接,弥补连续下采样和上采样造成的细节损失。最后在判别器中加入谱归一化SN(Spectral Normalization)操作,以稳定GAN的训练。通过以上方法充分挖掘特征信息,使重建图像的局部纹理细节更加逼真,进一步提升图像的视觉效果。
2 工作基础
2.1 坐标注意力机制
通道注意力广泛应用于SR重建任务中,对重要通道即高频特征赋予更大的权重,对图像质量提升幅度较小的通道赋予低权重,从而提升模型的性能。但是,通道注意力忽略了对生成空间选择性注意映射很重要的位置信息,使得特征图中局部空间层面上的信息没有被合理利用。而CA机制将位置信息嵌入到通道注意力中,可以捕获方向感知、位置感知和跨通道的信息。
CA机制的实现包括2个部分。第1部分是坐标信息的嵌入,对输入X(设其高度为H,宽度为W,通道数为C)使用池化核的2个空间范围(H,1)和(1,W)分别沿水平和垂直方向对每个通道进行编码,池化后的特征图的高度为h(0≤h≤H),宽度为w(0≤w≤W),因此,第c(0≤c≤C)个通道在高度为h时的输出可表示为式(1),同样地,第c个通道在宽度为w时的输出可表示为式(2):
(1)
(2)
其中,xc(h,i) 表示输入特征图中通道为c,坐标为(h,i)的分量;xc(j,w)表示输入特征图中通道为c,坐标为(j,w)的分量。
以上编码过程分别沿着2个空间方向聚合特征,得到一对方向感知特征图。第2部分是坐标注意力的生成,将聚合的特征映射进行级联,并将其送入共享的1×1卷积变换函数F1(·)中,得到编码水平和垂直2个方向空间信息的中间特征f:
f=δ(F1([zh,zw]))
(3)
其中,zh表示沿X轴方向平均池化后的输出,zw表示沿Y轴方向平均池化后的输出,δ(·)表示h-swish激活函数。
接着沿空间维度将f分成2个单独的张量fh和fw,再利用2个1×1卷积Fh(·)和Fw(·)分别将其通道数转换成与输入X相同的通道数,经过Sigmoid函数激活之后分别得到特征图在高度和宽度方向的注意力权重gh和gw。该过程可以表示如式(4)和式(5)所示:
gh=σ(Fh(fh))
(4)
gw=σ(Fw(fw))
(5)
最后在原始特征图上通过乘法加权计算,最终得到在宽度和高度方向上带有注意力权重的特征图。由于本文设计的残差块去除了BN层,因此也将CA中的BN层去掉,修改后的CA机制结构如图1所示,图中r表示通道的缩减因子。首先对输入特征图分别沿X轴和Y轴方向进行平均池化;然后将2个方向的特征图拼接在一起,并输入卷积模块进行降维(Concat+Conv2d);再经过非线性层(Nonlinear)编码2个方向的空间信息;接着进行分离(Split),通过卷积(Con2d)调整2个方向特征向量的通道数;最后与原输入加权计算(Re-weight),得到注意力权重。将CA嵌入到每个残差块中,使得模型可以捕获输入特征图沿一个空间方向的长程依赖关系,更加精准地识别图像中感兴趣的部分。

Figure 1 Structure of coordinate attention图1 坐标注意力结构
2.2 Dropout正则化
在高级计算机视觉任务中,Dropout可以有效降低模型过拟合的风险,但在SR重建这种底层视觉任务中会造成输出图像的部分像素缺失。不过,Kong等人[20]通过研究证明了只要将Dropout加入网络的方式进行调整,便可以应用于SR重建任务中,并且有益于提升模型的性能。Dropout的影响主要取决于其在网络中的位置、维度和概率。(1)Dropout在网络中的位置。Hinton等人[21]将Dropout应用于分类任务输出之前的完全连接层,类似地,在回归任务中可以应用于输出前的卷积层,因此本文将其应用于生成器网络输出前的卷积层。(2)Dropout的维度。在卷积层中可以应用在元素或通道2个维度上,Dropout元素维度是指在所有的特征图上随机丢弃元素,这会造成生成图像的像素缺失问题。Dropout通道维度是指随机丢弃一个通道,使得PSNR值不再依赖于特定的通道,可提高通道的表达能力。因此,本文选择在通道维度应用Dropout。(3)Dropout的概率决定了元素或通道被丢弃的概率。在分类网络中可以选择高达50%的失活概率,由于SR网络抵抗信息干扰的鲁棒性要差于分类网络的,所以过高的概率可能会丢失部分像素,降低SR网络的性能。Kong等人[20]还指出,当Dropout的概率为10%,20%和30%时,更有利于SR网络性能的提升,本文通过实验最终选择使用20%的Dropout概率。
2.3 U-Net式判别器
GAN面临的挑战之一是判别器难以生成同时具有全局形状和局部纹理的真实图像。SR重建中常用的VGG式判别器如图2所示,其中,ISR表示生成器重建出的图像,IHR表示真实的高分辨率图像。该判别器的输出是基于图像全局形状的二分类结果,通过一个单一的数值来区分真假图像,因此只是以粗略的方式向生成器提供反馈。而U-Net模型是一个编码-解码的结构。Schönfeld等人[22]提出了U-Net GAN,其中编码器对图像整体结构进行判断,解码器对图像进行像素级决策,同时输出图像的全局和局部判定,如图3所示。这一结构的判别器具有更强的鉴别能力,使得设计欺骗判别器的生成器任务更具挑战性,从而提高生成图像的质量。受该文献启发,本文使用U-Net式判别器,不再是对图像的全局样式进行二分类判断,而是输出一幅特征图,即对每个像素进行分类,每个像素均输出一个真实数值,可以向生成器提供一种细粒度的反馈,以此来更新生成器。这样,判别器可以对局部纹理产生精确的梯度反馈,更好地保留局部细节,使生成的SR图像尽可能地接近HR图像。

Figure 2 Structure of VGG discriminator图2 VGG式判别器结构图

Figure 3 Structure of U-Net GAN图3 U-Net GAN结构
2.4 谱归一化
基于GAN的SR重建模型增强了生成图像的真实感,但是GAN也面临着训练不稳定的问题。这是由于当判别器非常准确时,生成数据和真实数据分布很难有所重叠,导致生成模型的损失函数几乎没有梯度,即二者难以同时达到收敛,造成了GAN训练不稳定的结果。Arjovsky等人[23]提出了WGAN(Wasserstein Generative Adversarial Network),用Wasserstein距离代替JS(Jensen-Shannon)散度,平衡了生成器和判别器的训练程度,有效提高了GAN训练的稳定性。WGAN虽然性能优越,但是留下了难以解决的1-Lipschitz问题。针对这一问题,Miyato等人[24]提出了SNGAN(Spectral Normalization for Generative Adversarial Network),对判别器中的参数进行归一化处理,将每层的参数矩阵除以自身的最大奇异值,最大限度地保存了判别器权值矩阵的信息,使得映射函数满足了Lipschitz约束。SN使判别器满足Lipschitz连续性,限制了函数变化的剧烈程度,同时可以防止训练过程中出现模式坍塌现象,从而使模型更稳定。因此,本文引入SN操作,在判别器的卷积层中使用SN层代替传统的BN层,增强GAN在训练过程中的稳定性。
3 本文模型

Figure 4 Structure of the proposed model图4 本文模型结构
本文模型以生成式对抗网络为框架,结构如图4所示。生成器(其输入为低分辨率图像ILR)是以残差块为基本单元构建的,同时在残差块中加入CA机制,充分聚合通道和空间2个方向的特征。并且在上采样操作后引入了Dropout,以增强模型的泛化能力。判别器以U-Net结构进行构造,增强对局部纹理的判断能力。同时在判别器中加入谱归一化,以稳定GAN的训练。在损失函数方面,利用VGG19网络激活前的多层特征加权求和计算感知损失,使用Charbonnier损失函数[25]作为内容损失,并加入GAN特有的对抗损失,三者共同构成生成损失,使得重建图像具有精确的纹理细节。
3.1 生成器
由于BN层容易引起伪影,并且增加了计算复杂度,所以本文在残差块的设计中未使用BN层。本文提出的坐标注意力残差块如图5所示,具体来说,该模块包含了3个卷积层和1个注意力层,卷积核的大小均为3×3,通道数分别为128,256和64,在第3个卷积层后设计CA,确保网络提取更精细的特征信息。

Figure 5 Structure of coordinate attention residual block图5 坐标注意力残差块结构
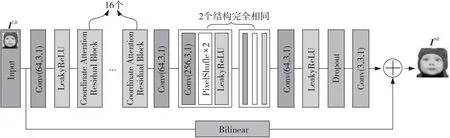
Figure 6 Structure of generator图6 生成器结构
生成器的网络结构如图6所示。首先使用一个卷积层提取输入图像的边缘特征,然后将其输入到坐标注意力残差模块中,同时关注通道信息和位置信息,更全面地提取特征。生成器的上采样模块,由2个亚像素卷积层构成,完成图像像素的扩充。在最后一个卷积层前加入Dropout正则化,并将经过双线性插值法处理的输入图像与最后一个卷积层的输出相加,得到最终的输出。生成器的激活函数均使用LeakyReLU函数。该激活函数通过引入小的斜率避免神经元的“死亡”,同时解决了梯度方向的锯齿问题,使得模型能够更快地收敛。
3.2 判别器
U-Net式判别器是一个下采样-上采样的结构,如图7所示。其中,n表示通道数,k×k表示卷积核的尺寸,s表示步长。首先,第1个卷积层采用64个3×3的卷积核对输入图像进行特征提取,然后下采样部分(Downsampling)分别使用128,256和512个步长为2,尺寸为4×4的卷积核,实现通道数量的增加以及特征图空间的减小,从而提高网络的表达能力。判别器的上采样部分使用双线性插值法进行渐进式上采样,逐渐扩展特征图的空间大小。为弥补连续下采样和上采样造成的细节损失,下采样部分的各层级特征图与经过上采样获得的特征图通过跳跃连接的方式进行特征融合,并在卷积层后加入SN层,稳定训练过程。网络的末端包括3个卷积层,最后一个卷积层的通道数为1,以得到一幅与输入图像大小相同的灰度图,图中每个像素均输出一个真实数值,以对局部纹理产生精确的梯度反馈。特征图中颜色较亮部分意味着输入图像的相应像素更接近于HR图像的,对应于像素的鉴别置信度为真,而较暗部分的鉴别置信度为假。

Figure 7 Structure of U-Net discriminator图7 U-Net式判别器结构
3.3 损失函数
损失函数的选取对模型的训练影响很大,选择合适的损失函数可以使模型正确且快速地收敛。本文采用多种损失函数相结合的策略,在预训练和训练时分别使用不同的损失函数,使模型朝着正确的方向收敛,以获得具有丰富纹理的重建图像。
3.3.1 内容损失
传统的图像SR重建方法大多是基于L2损失函数计算损失,虽然获得了较高的PSNR值,但重建图像过于平滑,缺乏纹理细节。而L1损失函数能加快模型的收敛速度,使重建的图像具有相对清晰的边缘。所以,本文模型在预训练时,采用L1损失函数和L2损失函数相结合的策略,在保证获取较高PSNR值的同时减轻平滑现象。L1损失函数和L2损失函数定义分别如式(6)和式(7)所示:
(6)
(7)
其中,G(ILR)表示生成器重建的图像,IHR表示真实的HR图像。
在训练过程中使用Charbonnier损失函数作为内容损失,可以规避异常点,有效抑制伪影现象,具有更好的鲁棒性。Charbonnier损失函数定义如式(8)所示:
LC=∑(ρ(IHR-G(ILR)))
(8)
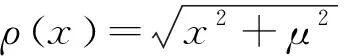
3.3.2 感知损失
本文使用预训练的VGG网络提取特征,使用ReLU激活层之前的特征作为计算感知损失的依据。提取VGG19网络conv1-2、conv2-2、conv3-4、conv4-4和conv5-4层特征进行计算,使得重建图像具有更多的细节信息。对浅层特征赋予低权重,深层特征赋予高权重,加权求和作为最终的感知损失。感知损失定义如式(9)所示:
(9)
3.3.3 对抗损失
本文在损失函数的计算中加入了GAN特有的对抗损失,基于U-Net GAN的思想,判别器的损失定义为所有像素的平均决策,像素级别的损失计算可以使重构图像的纹理细节更加精确。判别器损失函数定义如式(10)所示:
(10)
其中,[D(IHR)]i,j和[D(G(ILR))]i,j表示判别器在像素(i,j)处的决策。
相应地,生成器的优化目标如式(11)所示:
(11)
3.3.4 预训练损失与训练损失
本文的预训练损失和训练损失是根据上述损失函数构建的。
预训练部分只针对生成器进行训练,其损失定义如式(12)所示:
Lpre=L1+L2
(12)
训练部分包括生成器和判别器2个部分,判别器的损失函数计算如式(10)所示,生成器的总损失定义如式(13)所示:
L=γ1LC+Lpercep+γ2LG
(13)
其中,γ1=0.01,γ2=0.005,LC、Lpercep和LG分别表示上文提到的Charbonnier损失、感知损失和生成器损失。
4 实验与结果分析
4.1 实验设置
本文实验在NVIDIA®GeForce®RTX 2080 GPU,内存为43 GB的主机上进行,使用Windows 10操作系统,以PyTorch作为深度学习框架,编程语言为 Python。实验使用DIV2K(DIVerse 2K resolution image dataset)[26]中800幅HR图像和对应的经过双三次插值处理的LR图像作为训练数据集,该数据集中图像纹理丰富,适合作为训练数据集。测试集为2个广泛使用的标准数据集Set5和Set14。实验使用PSNR和结构相似性SSIM(Structure SIMilarity)作为评价指标。PSNR用于衡量2幅图像间的差异,其值越大,表示2幅图像越接近。SSIM用于衡量2幅图像相似性,可以较好地反映人眼的主观感受,其值越大,表示2幅图像越相似。
训练过程中每个批次处理16个大小为128×128的图像块,训练分为2个阶段:首先使用式(12)定义的损失函数训练一个面向PSNR的模型,预训练共迭代2.5×105次,初始学习率为2×10-4,每5×104次学习率衰减为原先的一半;然后将经过预训练的模型作为初始生成器,根据式(13)定义的损失函数来训练生成器,生成器的初始学习率为10-4,判别器采用和生成器不同的学习率,初始值设为4×10-4,共迭代3×105次,每5×104次学习率减半。训练时生成器损失函数的参数设置为γ1=0.01,γ2=0.005。实验过程均使用Adam优化器,设置参数为β1=0.9,β2=0.99,ε=10-7。
4.2 坐标注意力残差块的影响
生成器是基于坐标注意力残差块实现的,为了验证其作用,本节在预训练模型中进行实验,比较PSNR值的变化。由表1可以看出,坐标注意力残差块数量由8增至16时,PSNR值在Set5测试集和Set14测试集上分别提高了0.13 dB和0.12 dB;由16增至24时,PSNR值在Set5测试集上没有增加,在Set14测试集上提升了0.02 dB,但此时参数量过于庞大。因此,本文最终使用16个坐标注意力残差块来构建生成器,在保证获得较高PSNR值的同时网络参数量不会过于庞大。
4.3 Dropout正则化的影响
为了验证Dropout可以提高SR网络的性能,本节在预训练模型中,分别对不使用Dropout和使用较小Dropout丢弃概率的情况进行实验,所得结果如表2所示。在Set5测试集上,PSNR值随Dropout丢弃概率的增加而增加。在Set14测试集上,当Dropout丢弃概率为10%和20%时,PSNR值均比未使用Dropout结构的模型提高了0.01 dB;当丢弃概率增加为30%时,PSNR值较未使用Dropout结构的模型降低了0.02 dB。可以看出,Dropout的引入并不会破坏网络,并且有益于模型性能的提升,因此可以在生成器中加入了Dropout正则化。此外,在3种Dropout丢弃概率中,使用20%丢弃概率取得的平均PSNR值高于使用10%和30%丢弃概率的,因此本文最终选用了20%的Dropout概率。
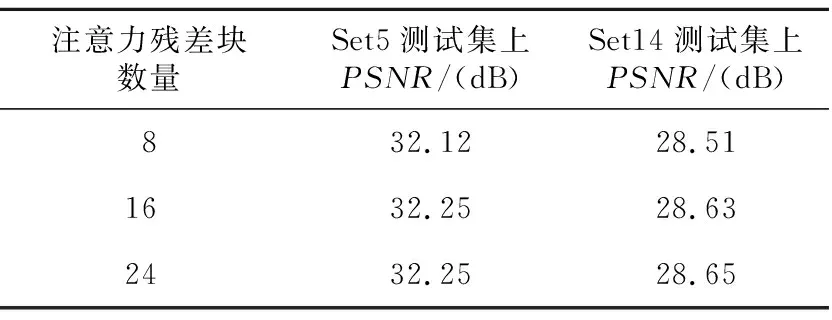
Table 1 Variation of PSNR with the number of coordinate attention residual blocks表1 PSNR值随坐标注意力残差块数量的变化情况

Table 2 Variation of PSNR with Dropout probability表2 PSNR值随Dropout概率的变化情况
4.4 U-Net判别器的影响
本文将SR重建模型中常用的VGG式判别器改为U-Net结构的判别器。为了验证其有效性,本节在保证生成器结构相同的情况下,计算平均PSNR值,所得结果如表3所示。可以看出,在Set5和Set14测试集上,U-Net式判别器较VGG式判别器得到的PSNR值分别提高了0.33 dB和0.46 dB。

Table 3 Variation of PSNR with discriminator structure表3 PSNR值随判别器结构的变化情况 dB
本文选取了Set14测试集中的“lenna”图像进行对比,并放大局部细节,如图8所示。可以看出,U-Net式判别器使得重建图像的局部形状更接近真实HR图像的,线条走势与HR图像的基本相同,细节部分恢复得更加清晰,在主观视觉上验证了U-Net式判别器的有效性。

Figure 8 Reconstruction images comparison of image “lenna” in Set14 test set图8 Set14测试集中图像“lenna”重建对比图
4.5 实验对比
模型训练完成后,本节在数据集Set5和Set14上将本文模型分别与经典的SR重建模型(Bicubic、SRCNN和ESPCN)、基于GAN的模型(SRGAN和ESRGAN)以及使用类U-Net式判别器的 FASRGAN模型进行实验比较。平均PSNR和SSIM值分别如表4和表5所示,其中加粗数据表示最优结果。从表4和表5可知,基于插值的Bicubic模型性能低于其他基于学习的模型(SRCNN、ESPCN、SRGAN、ESRGAN和FASRGAN)的。由表4可知,本文模型的PSNR值比SRCNN的平均提高1.82 dB,比ESPCN的平均提高1.84 dB,比SRGAN的平均提高1.87 dB,比 ESRGAN的平均提高1.14 dB,比 FASRGAN的平均提高1.44 dB。由表5可知,本文模型的SSIM值比SRCNN的平均提高0.035 4,比ESPCN的平均提高0.041 9,比 SRGAN的平均提高0.022 5,比ESRGAN的平均提高0.033 3,比FASRGAN的平均提高0.037 1。综上,当图像放大因子为 4 时,本文模型在PSNR和SSIM评价指标上均取得了较优的结果,表明了本文模型的有效性。
本文从Set5和Set14测试集上选取了部分细节丰富的重建图像,与其他模型的可视化对比如图9~图11所示。可以看出,Bicubic模型重建的图像非常模糊,锯齿状严重;SRCNN和ESPCN模型较Bicubic有所改进,但重建出的图像仍较为模糊和平滑;SRGAN模型重建的图像减轻了模糊程度,但出现了伪影问题,视觉效果没有得到明显提升;而ESRGAN、FASRGAN和本文模型重建的图像明显更加清晰,恢复出了更多的纹理细节,具有良好的视觉效果。不过,ESRGAN和FASRGAN模型生成的部分纹理是HR图像中不存在的,而本文模型是基于像素进行鉴别的,一定程度上避免了生成不真实的纹理。观察图9的局部放大处不难发现,本文模型恢复出了ESRGAN和FASRGAN模型未能恢复出的线条,局部纹理与HR图像的最为相似。从图11可以看出,本文模型重建的图像更为清晰,鼻梁处没有多余的线条,五官轮廓更接近于HR图像的。这些实验结果在主观视觉上表明了本文模型的有效性,说明其可以恢复出清晰且逼真的SR图像。

Figure 9 Reconstruction comparison of image “monarch” in Set14 test set图9 Set14测试集中图像“monarch”重建对比图

Table 4 Comparison of average PNSR of each super-resolution reconstruction model

Table 5 Comparison of average SSIM of each super-resolution reconstruction model表5 各超分辨率重建模型平均SSIM 值对比

Figure 10 Reconstruction images comparison of image “baby” in Set5 test set图10 Set5测试集中图像“baby”重建对比图

Figure 11 Reconstruction images comparison of image “comic” in Set14 test set图11 Set14测试集上图像“comic”重建对比图
5 结束语
本文提出的结合坐标注意力与生成式对抗网络的图像超分辨率重建模型利用了空间中的位置信息,对局部纹理进行了细粒度的判断,稳定了GAN的训练过程。通过将坐标注意力嵌入到残差块中,捕获了跨通道的信息,充分地利用了特征信息。在生成器引入高级视觉任务中的Dropout正则化,有效提升了模型性能。利用U-Net式判别器实现了像素级的鉴别过程,更专注于局部纹理。在判别器中引入谱归一化操作,使训练过程更加稳定。在损失函数方面结合了内容损失、感知损失和对抗损失,使得重建图像具有真实的细节和清晰的轮廓。实验结果表明,本文模型在PSNR和SSIM评价指标上均取得了较好的结果,在基准测试集Set5和Set14上取得的峰值信噪比平均提高了1.75 dB,结构相似性平均提高了0.038,生成的SR图像更接近于真实图像,具有良好的视觉效果。
