GNNSched:面向GPU的图神经网络推理任务调度框架*
2024-01-24孙庆骁杨海龙王一晴栾钟治钱德沛
孙庆骁,刘 轶,杨海龙,王一晴,贾 婕,栾钟治,钱德沛
(北京航空航天大学计算机学院,北京 100191)
1 引言
深度学习DL(Deep Learning)已在大量应用领域中得到广泛使用,从目标检测和图像分类到自然语言处理和机器翻译。随着更多新兴深度神经网络DNN(Deep Neural Network)模型被提出,DNN模型对算力的需求呈现快速增长的趋势,研究人员开始利用TPU(Tensor Processing Unit)和GPU等硬件加速器来提高DL任务运行性能。特别是GPU,由于其擅长处理DNN模型中的大量高度并行化矩阵计算,且得到了主流DNN框架的普遍支持,已经成为主流服务器中提供DNN模型算力的主体[1]。
与此同时,由于强大的节点表示能力,图神经网络GNN(Graph Neural Network)在基于图的预测任务上取得了不错的效果[2]。GNN结合图操作和神经计算来表征数据关系。由于图数据的不规则性,在GPU上实现高性能GNN极具挑战性。学术界虽然提出了基于节点分区和缓存合并的优化策略来解决GNN执行中的负载不均衡和线程分歧[3]等问题,但是图相关算子的实现仍使得GPU利用率低。例如,PyG(PyTorch Geometric)[4]通过消息传递单独更新节点特征,但其频繁的数据移动会导致计算停顿。DGL(Deep Graph Library)[5]使用类SpMM(Sparse Matrix-matrix Multiplication)的内核来实现同时更新,但稀疏数据读取会降低访存效率。
为了简化集群管理,最常见的方法是将GPU资源分配的最小粒度设置为整个GPU[6]。而由于GPU算力的不断提高,单个DL任务很难充分利用GPU资源[7],特别是对于GNN这类访存密集型任务,其性能会随着分配的计算资源的增加而达到饱和状态[8]。通过对DNN的研究发现,多个DNN任务可以在GPU上共置以提升资源利用率。工业界实现了多进程服务器MPS(Multi-Process Server)和多实例GPU MIG(Multi-Instance GPU),以使多个CUDA(Compute Unified Device Architecture)进程通过资源分区共享GPU。在学术界,时间共享[9,10]通过重叠预处理和计算来降低流水线延迟,而空间共享[11,12]允许并发执行DNN,以提供更高的吞吐量。上述机制只适用于具有固定大小输入的DNN,无法直接适配到显存消耗和计算强度与模型输入动态相关的GNN[13]。
相比训练框架,基于GPU的推理框架需要应对的问题更加复杂。除改进整体吞吐量以外,还必须在限定时间内提供推理结果,以满足服务质量目标QT(Quality-of-service Target)[14]。然而,单个GPU上运行多个推理任务可能会因为显存过载导致执行失败或延迟显著增加。因此,推理系统需要提前估计推理任务的显存占用情况,避免其需求超出显存容量进而触发开销较大的统一虚拟内存UVM(Unified Virtual Memory)数据交换[15]。另一方面,云服务商通常以多租户方式共享GPU集群资源[16]。在这种情况下,需要根据推理任务的计算模式和显存占用特点设计灵活的调度机制,以满足服务质量要求并降低推理响应时延。
为了应对上述挑战,本文提出并发GNN推理任务调度框架GNNSched(GNN Scheduler),其在GPU上高效地调度和管理并发GNN推理任务。GNNSched首先将推理任务打包到队列中,并提取有关任务输入和网络结构信息。之后,GNNSched分析每个推理任务的计算图,并量化算子对显存占用的影响。最后,GNNSched利用多种调度策略对任务进行分组并迭代地分配显存以供执行。本文最后开展了大量的实验来评估GNNSched,以验证其在满足服务质量和降低延迟等方面的有效性。
GNNSched在任务组内和任务组间分别使用了空间共享和时间共享技术。具体来说,组内的任务通过空间共享提高整体GPU吞吐量,而组间通过重叠数据预处理与计算降低流水线延迟。本文是首次针对并发GNN推理任务的调度优化和显存管理进行研究。GNNSched已开源于:https://github.com/sunqingxiao/GNNSched。
本文的具体工作如下:
(1)提出了并发GNN推理任务管理机制,通过细粒度的显存管理和工作器(Worker)分配以自动执行GNN推理任务。此外,提出了多种调度策略对任务进行分组。
(2)提出了GNN推理任务显存占用估计策略,针对GNN算子设计了显存成本函数,并通过遍历前向传播的计算图来估计GPU显存占用情况。
(3)实现了并发GNN推理任务调度框架GNNSched,其可以有效地调度和管理在GPU上的并发GNN推理任务。实验结果表明,GNNSched能够满足服务质量要求并降低推理任务响应时延。
2 背景
2.1 图神经网络简介
近年来,一些研究致力于将深度学习应用于图等非结构化数据[2]。不同于传统深度学习模型处理的图像和文本等密集数据,图表示稀疏且连接不规则。图中每个节点与一个特征向量相关联,节点之间的边表示图拓扑结构,并以边的权重进行量化。GNN以图结构数据作为输入,综合图结构和节点特征来学习数据关系。表1列出了重要的GNN符号。

Table 1 Explanations of important symbols in GNN表1 GNN中重要符号说明
图卷积神经网络GCN(Graph Convolutional Network)[17]是面向图学习的最成功的网络之一。GCN缓解了图的局部邻域结构过拟合的问题,其图操作如式(1)所示:
(1)
SAGE(SAmple and aggreGatE)[18]进一步应用采样的方式来为每个节点获取固定数目的邻居。SAGE的图操作如式(2)所示:
(2)
其中SN(v)是节点v的随机采样邻居,fk(·,·)是聚合函数。图同构网络GIN(Graph Isomorphism Network)[19]通过可学习参数εk调整中心节点的权重,其图操作如式(3)所示:
(3)
基于上述分析,GNN的核心计算可以抽象为式(4):
(4)

2.2 GNN框架的计算模式
图1展示了GNN前向传播的计算流程。典型的GNN层包含聚合阶段和更新阶段,其结合了图操作和神经计算。聚合阶段从节点的每个邻居检索一个特征向量,并将这些向量聚合成一个新的特征向量。更新阶段执行多层感知机MLP(MultiLayer Perceptron)等神经操作以转换每个节点的特征向量。GNN框架根据图结构进行图操作,其中边表示数据传输。DGL通过中心邻居模式引入了节点级并行,它从特征矩阵中获取数据,再执行类SpMM的归约操作以同时更新节点特征。PyG通过MessagePassing抽象引入了边级并行,它通过消息传递在所有边上直接生成消息,再分别执行归约操作。

Figure 1 Computation workflow of GNN图1 GNN计算流程
DGL和PyG都受到了GPU计算资源不足的限制。DGL应用类SpMM内核实现节点特征的更新,但是由于图结构的不规则性,显存访问成为了其性能瓶颈。PyG通过聚合内核实现单独的节点特征更新,以提高访存效率,但是耗时的数据移动会导致计算停顿。为解决上述问题,可以利用GNN推理任务的共置机制最大化GPU吞吐量。然而,这需要预知推理任务的显存消耗情况以免显存过载。不同于拥有固定大小输入的神经网络,GNN层的输出维度与图维度和特征长度紧密相关。此外,为了得到更精确的估计值,图传播的显存消耗也需要被纳入考虑。
2.3 推理任务的GPU共享
在工业界,主流做法是将GPU分配的最小粒度设置为整个GPU[6]。虽然这样的设置简化了集群资源管理,但导致GPU资源的利用率较低。因此,GPU共享逐渐成为在GPU上共置推理任务的一项基本技术。例如,即使是单个服务也可能包含多个异构推理任务[21],如何将其映射到GPU是重要挑战。对具有自身计算要求的不同推理任务必须适时地加载到GPU,以满足其服务质量目标,同时提高整体吞吐量。
现有工作提出了基于时间或空间共享的机制[9,12],以实现深度学习任务在GPU上的共置。时间共享高度灵活,将GPU显存和核心专用于特定持续时间的单次执行。PipeSwitch[9]利用流水线模型传输和主备Worker来最小化切换开销,从而满足推理任务的严格服务质量目标。REEF[10]改造了GPU驱动以支持软件队列和计算单元的重置,并主动抢占批量内核从而在微秒级启动实时推理任务。尽管时间共享通过重叠数据预处理和计算来隐藏延迟,但仍难以充分发掘GPU的计算潜力。例如,对于递归神经网络构成的语言模型,计算单元往往会长时间闲置[16]。
相比之下,空间共享允许在不违反服务质量的情况下提供更高的GPU吞吐量。应用空间共享的一个限制是并发任务的工作集大小。如果工作集大小超过GPU显存,系统必须将数据交换到主机,这会掩盖空间共享的优势。GSLICE[14]采用自调整算法并根据性能反馈调整每个推理任务的线程占用率。Abacus[11]通过确定性算子重叠实现了并发推理任务的延迟可预测性,并设计基于配额的控制器以确定算子执行顺序。Choi等人[12]创建GPU资源抽象层为推理任务分配有效资源,再通过性能预测模型评估空间共享的潜在干扰开销。然而,这些方法均未考虑并发推理任务可能带来的显存过载,这可能会导致任务运行失败或耗时的设备-主机数据交换[15]。
上述机制针对的是具有固定大小输入的传统神经网络,没有量化不规则图对显存消耗的影响。此外,对于同一批次到达的推理任务,可以结合时间共享和空间共享在GPU上实现更灵活高效的调度机制。
3 方法设计与实现
3.1 设计概要
本节提出GNN推理调度框架GNNSched来维护GNN推理队列,每次从队列头部取同一批次的推理任务进行高效调度和管理。如图2所示,灰色模块是由GNNSched设计或扩展的。GNNSched由4个重要组件组成,包括显存管理器、峰值显存消耗PMC(Peak Memory Consumption)分析器、任务调度器和Worker分配器。显存管理器维护统一的显存池,按需分配显存;PMC分析器提取运行时信息以估计推理任务的显存消耗;任务调度器根据调度策略确定分组和任务执行顺序;Worker分配器将训练任务绑定到具体的Worker上,执行后返回结果。注意Worker是指负责任务执行的进程,其常驻在推理系统中,跨不同组串行执行推理任务。
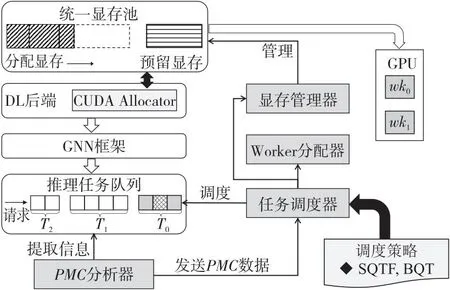
Figure 2 Design overview of GNNSched图2 GNNSched设计概要
图2为GNNSched的设计概要。GNNSched将CUDA Allocator集成到DL后端以实现显式的GPU显存管理。GNNSched将使用GNN框架实现的推理任务打包到任务队列中(T0,T1和T2为推理请求到达时间),其中PMC分析器提取模型输入和网络结构的详细信息。PMC分析器将GNN模型的计算图表示为有向无环图DAG(Directed Acyclic Graph),并使用公式量化每个算子对显存消耗的影响。PMC分析器将PMC信息发送给任务调度器,任务调度器使用特定策略对推理任务进行分组和重排,再迭代地从队列中弹出任务组。在每次迭代中,显存管理器和Worker分配器接收信号以分配共享GPU显存和执行推理任务。
3.2 任务管理机制
并发任务空间共享的关键在于GPU显存的细粒度管理。本文扩展了DL后端(PyTorch)的统一显存池,针对DL任务的特点,将显存池划分为预留显存和分配显存。预留显存存储框架内部数据,例如CUDA上下文和模型工作区,通常在任务执行前预先分配,分配显存存储任务运行时产生的张量,例如层输出。GNNSched从分配显存的一端连续插入任务Buffer,以确保分配显存被完全占用(见图2)。GNNSched通过显存消耗估计来指定每个任务Buffer的分配大小,再将其插入到特定的显存位置。对于分配显存,GNNSched通过满足对齐要求的额外显存填充来处理内部张量碎片。
图3给出了GNNSched中任务管理的整体工作流程。对于同一批次的推理任务,任务调度器执行分组操作,Worker分配器以任务组为粒度迭代地提交到GPU。以这种方式,GNNSched避免了显存碎片问题。显存碎片可能浪费并发推理机会,同时使内存维护复杂化。在每次迭代中,Worker分配器将推理任务映射到具体Worker(wk0,wk1和wk2)。每个Worker串行处理Buffer插入、任务执行和结果返回等操作;Worker间并行以重叠相关操作,其中不同推理任务以空间共享的方式执行。并行Worker均返回结果后,GNNSched清除所有Buffer并前进到下一组。注意,GNNSched在GPU上执行当前任务组的同时,在主机端预先处理下一组的输入数据,因而有效地降低了流水线延迟。

Figure 3 Overall workflow of task management图3 任务管理的整体工作流程
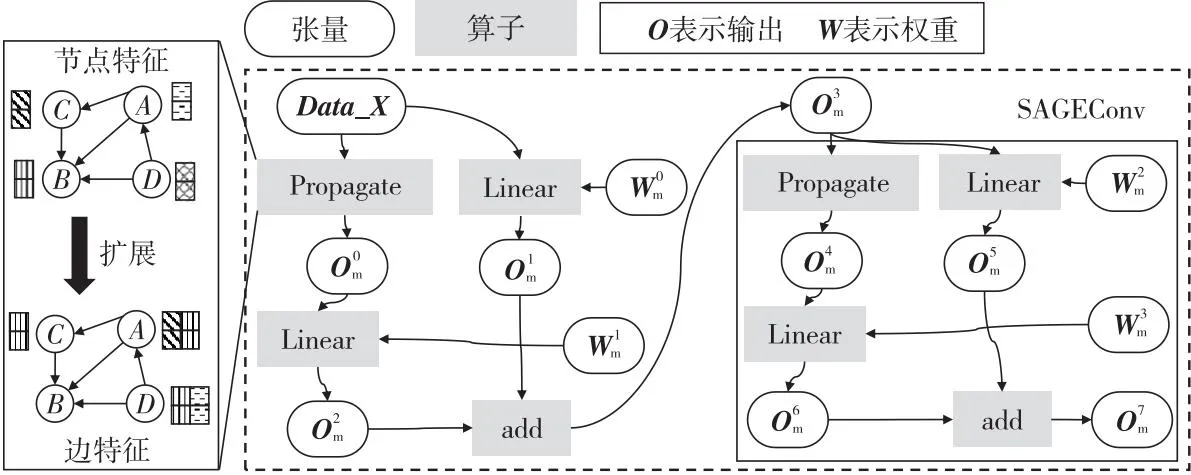
Figure 4 Computation graph of two-layer SAGE model图4 2层SAGE模型的计算图
从以上分析可知,GNNSched灵活的管理机制可以支持推理任务的任意分组和调度顺序。这对于提高输入敏感GNN的访存效率是必要的,其PMC随图维度和特征长度而显著变化。
3.3 显存消耗估计
受文献[22]的启发,本文将GNN推理的计算图CG表示为DAG,如式(5)所示:
(5)
其中,节点opi表示数学调用的算子,边edj指定执行依赖。TO=〈ed1,ed2,…,edm〉是DAG规定的拓扑顺序,其通过查阅DL后端[23]内的拓扑顺序预先生成。GNNSched利用TO遍历计算图并根据张量的分配和释放更新PMC。
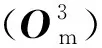
根据拓扑遍历,估计GPU显存消耗可以形式化为计算图上每个算子所需显存的累加。本文为每个算子定义了DL后端无关的显存成本函数MCF(Memory Cost Function)。显存成本函数返回一组已分配的具有类别和形状的张量,这些张量通过输入维度和形状推断来推导得到。算子op的MCF可以表示为式(6):
MCF(op)=W(op)∪O(op)∪E(op)
(6)
其中,W、O和E分别是权重张量、输出张量和临时张量的集合。
本文还需要考虑GNN的定制化细节。GCN补充自循环以使中心节点的聚合表示包含其自身特征。即便如此,GNN框架中仍不可避免地会创建部分临时张量来维护任务执行。因此,GNNSched将估计PMC乘以固定阈值threshhold,以保证插入的Buffer能够满足计算过程的显存需求。
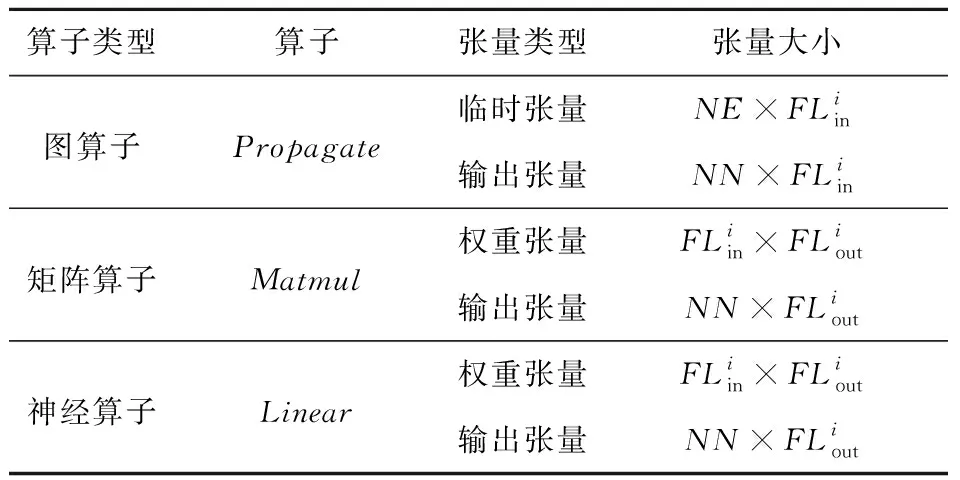
Table 2 Allocated tensors and their sizes表2 分配张量的类型和大小
上述抽象和形式化对于各种GNN框架的PMC估计是通用的。GNNSched还可以通过修改计算图或显存成本函数来适配其他GNN。
3.4 调度策略
GNNSched的灵活管理机制为调度策略提供了很大的设计空间。与文献[11]一致,本文将每个推理任务的QT设置为其单独运行时间的2倍。因此,高QT任务具有更长的执行时间,而执行时间通常与计算强度正相关。本文实现了2种非抢占式的调度策略,包括最短QT优先SQTF(Shortest-QT-First)和平衡QTBQT(Balanced-QT)。所有策略均具有“安全”条件,以确保并发任务的显存使用不超过GPU显存容量。幸运的是,GNNSched可以估计推理任务的PMC并进行累加,从而使每个任务组都处于“安全”位置。接下来,说明本文2种调度策略的具体细节:
(1)SQTF策略:最简单的先进先出FIFO(First-In-First-Out)算法可以在满足“安全”条件下尽可能地将更多的任务打包到同一组中。然而,FIFO算法可能会导致短期任务因等待大型正在进行的任务完成而遭受长时间的排队延迟。因此,提出了最短作业优先算法和最短剩余时间优先算法[24],以降低队列中任务的排队延迟。然而,任务持续时间或剩余时间需要离线分析,这会影响可用性和运营成本[25]。为了解决以上问题,本文提出SQTF策略(见算法1),其将队列中的任务索引按照QT的升序进行排序,然后遍历排序生成任务组。此外,本文设置了分组阈值以改善时间维度的负载均衡。具体来说,分组阈值由当前批次的推理任务的PMC总和计算得到,在分组过程中保证不同任务组的显存分配大小相近。

算法1 SQTF调度策略输入:升序队列Deque,分配显存大小MA,推理任务的PMC总和SP;输出:任务组列表taskGroup。1:queSize←Deque.size;//原始队列大小2:gTH=ceil(SP/ceil(SP/MA));//分组阈值//初始化组PMC和组计数器3:gPMC,gCounter←MA,-1;4:for i in range [0,queSize)do5: task←Deque.popleft();//从右侧弹出任务6: if gPMC>gTHthen7: taskGroup.append([]);//前进到下一组8: gPMC,gCounter←0,gCounter+1;9: end if10: taskGroup[gCounter].append(task);11: gPMC←gPMC+task.PMC;//累加PMC12:end for
(2)BQT策略:该策略继承了SQTF策略的QT排序和分组阈值机制。尽管SQTF策略降低了短期任务的排队延迟,但将具有高QT的推理任务置于同一组可能会加剧资源冲突。BQT策略用于平衡任务时长和排队时间。BQT策略的原则是将计算强度高的任务和强度低的任务归为一组,从而降低并发执行的性能干扰。算法2为BQT策略的实现细节。该策略根据QT的升序将推理任务推入双端队列(Deque)。每次迭代从Deque的右端或左端弹出任务(第5~9行),再将任务分到当前组并累加PMC(第14,15行)。当组PMC大于分组阈值时,前进到下一组并初始化组计数器(第10~13行)。重复上述步骤直到Deque为空,当前批次的任务组生成结束。

算法2 BQT调度策略输入:升序队列Deque,分配显存大小MA,推理任务的PMC总和SP;输出:任务组列表taskGroup。1:queSize←Deque.size;//原始队列大小2:gTH=ceil(SP/ceil(SP/MA));//分组阈值//初始化组PMC和组计数器3:gPMC,gCounter←MA,-1;4:for i in range [0,queSize)do5: if i%2==1then6: task←Deque.pop();//从右侧弹出任务7: else8: task←Deque.popleft();//从左侧弹出

9: end if10: if gPMC>gTHthen11: taskGroup.append([]);//前进到下一组12: gPMC,gCounter←0,gCounter+1;13: end if14: taskGroup[gCounter].append(task);15: gPMC←gPMC+task.PMC;//累加PMC16:end for
3.5 实现细节
GNNSched的系统原型由C++和Python代码实现,并构建在PyG和PyTorch[26]之上。然而,GNNSched背后的思想可通用于其他GNN框架或DL后端。本文使用CUDA IPC扩展PyTorch的Allocator模块从而实现GPU显存池的显式管理。本文通过添加函数来支持在特定CUDA流中插入Buffer以及从显存池中清除Buffer。Buffer插入函数可以被多次调用,以实现GNN推理任务的空间共享。任务组执行完成后,Buffer清除函数被调用来清除显存分配。注意PyTorch为张量分配的实际显存大小需满足一定的对齐要求。为了解决这一问题,本文通过填充来使得显存分配大小满足512字节的倍数。
GNNSched由分别负责队列管理和任务执行的调度进程和Worker进程组成。调度进程监听客户端通过TCP端口发送的任务请求,将任务打包到队列中并加载模型结构。接下来,调度进程通过计算图遍历来分析PMC并生成任务组。在每个组迭代中,调度进程将任务的哈希索引发送到Worker进程。Worker进程根据哈希索引识别任务并将其分配给Worker线程。每个Worker线程加载相应的GNN模型并将其附加到CUDA流。结果返回后,Worker线程通过PyTorch Pipe API向调度进程发送“完成”信号。当接受到的信号数量等于组大小时,调度进程迭代到下一个任务组。
4 实验与结果分析
4.1 实验设置
(1)硬件和软件配置。硬件规格如表3所示。操作系统为Ubuntu 20.04,编译器版本为GCC v9.3和NVCC v11.1。GNNSched基于PyG v1.7和PyTorch v1.8构建。本文修改了PyTorch以支持GNNSched的显式任务共置和显存管理。
Table 3 Hardware configuration表3 硬件配置
(2)图数据集和任务队列。用于实验的图数据集如表4所示。本文为每个图数据集随机生成25个子图,用作网络输入。本文选取3个典型GNN(包括GCN、SAGE和GIN),其中层数和层宽分别设置为8和256。本文将SAGE的采样率设置为0.5(与PyG默认设置一致)。本文为每个GNN生成由100个推理任务组成的队列,不同任务具有不同的子图输入。此外,本文从以上队列中均匀采样100个任务以获得具有不同GNN的任务队列(命名为MIX)。队列中任务到达的时间遵循泊松分布。同时到达的任务数量均值被设置为1和2,分别代表低负载(Low Load)和高负载(High Load)。多样的任务组织用于对GNNSched的有效性进行全面评估。

Table 4 Graph datasets表4 图数据集
(3)对比方法和指标。本文将具有2种调度策略(SQTF和BQT)的GNNSched与Default和MPS进行对比。Default采取FIFO的方式串行执行推理任务。为了公平起见,本文基于MPS实现了2个变体MPS-Base和MPS-Aggr。MPS-Base的最大并发数量为4,MPS-Aggr并发执行同一批次的所有任务。本文为MPS启动UVM以处理可能的显存过载。为了评估推理任务的服务质量和执行效率,本文选取服务质量违反率(QoS violation)、响应延迟(medium/90%-ile/99%-ile latency)、作业完成时间JCT(job completion time)和排队时间QUET(QUEuing Time)作为评估指标。本文将每种方法运行10次并给出平均结果以隔离随机性的影响。
4.2 服务质量评估
图5给出了不同方法的服务质量违反率对比。相比Default和MPS,GNNSched在所有任务队列下均取得更低或等同的服务质量违反率。在低负载下,GNNSched使得所有任务均满足其服务质量要求。即便在高负载下,GNNSched的服务质量违反率最高仅为8%,而Default和MPS的最高违反率分别达到了93%和91%。另外,还注意到,MPS-Base和MPS-Aggr呈现明显差异性的实验结果。MPS-Base的服务质量违反率总是低于20%,而MPS-Aggr在半数队列下甚至比Default的违反率更高。这是因为MPS的贪心机制使得显存过载,UVM的分页开销显著降低了并发任务的性能。尽管MPS-Base的静态分组有效规避了UVM的使用,然而其欠缺任务调度的灵活性。GNNSched通过PMC预估计和高效调度来保证在显存安全下尽可能地充分利用计算资源。
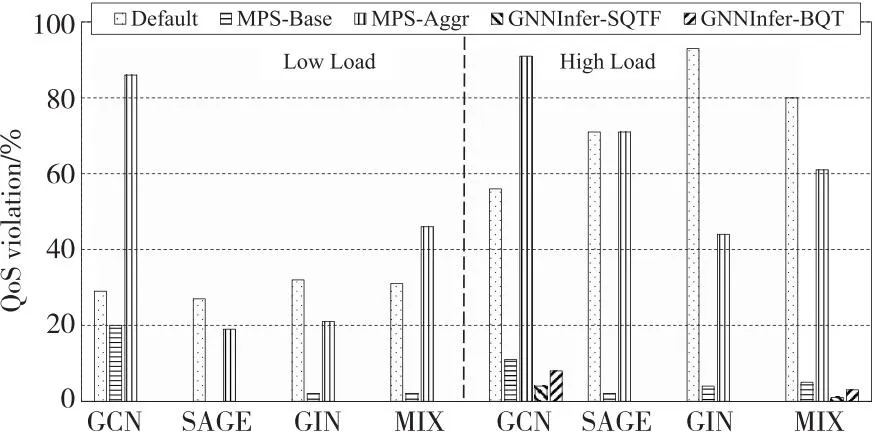
Figure 5 Comparison of QoS violation rate图5 服务质量违反率对比
4.3 延迟评估
图6给出了归一化为QT的响应延迟对比。Default的串行执行忽略了任务并发的机会,在GIN队列下的medium延迟、90%-ile延迟和99%-ile延迟分别达到了QT的6.6倍、12.2倍和17.3倍。MPS-Aggr由于UVM开销表现不稳定,在GCN队列下取得7.5倍QT的99%-ile延迟。相比之下,GNNSched和MPS-Base在所有任务队列下均取得小于2倍QT的99%-ile延迟。以上结果表明,GNNSched和MPS-Base具有更低的尾延迟,这对于提升用户粘性尤为重要。

Figure 6 Comparison of request latency图6 响应延迟对比
从图6可以观察到,GNNSched在大多数案例中取得了最低延迟。GNNSched相比MPS-Base分别平均降低了26.2%,27.4%和31.9%的medium延迟、90-ile延迟和99-ile延迟。这说明GNNSched能够提供稳定的服务质量,有效避免了处理批量任务时的长尾延迟。GNNSched的优越性主要来自于其充分发掘了推理任务的并发机会。另外,GNNSched设置的分组阈值不但改善了时间维度的负载均衡,还在很大程度上缓解了任务空间共享时的性能干扰。
4.4 性能评估
图7给出了归一化为QT的平均JCT对比。GNNSched在所有任务队列下均取得了最短的JCT。与Default、MPS-Base和MPS-Aggr对比,GNNSched的JCT分别平均降低了60.6%,26.8%和62.7%。除了灵活的任务并发机制,GNNSched的显存池管理同样有助于性能提升,其避免了张量的频繁分配和释放。值得注意的是,GNNSched-BQT在大多数任务队列下略微好于GNNSched-SQTF,JCT平均降低了0.6%。这是因为BQT策略将计算强度高的和计算强度低的任务归为一组,降低了对计算和缓存资源的竞争。
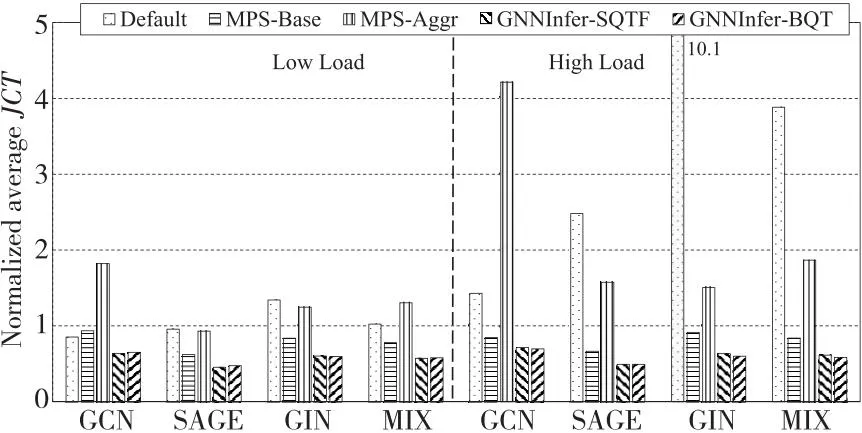
Figure 7 Comparison of average JCT图7 平均作业完成时间对比
图8给出了归一化为QT的平均排队时间对比。对于低负载,MPS-Base和GNNSched在所有任务队列下的排队时间均为0。这意味着上一批次的推理任务总能在当前批次到达前完成,侧面证明了空间共享的有效性。对于高负载,MPS-Base在所有队列下均存在等待延迟,而GNNSched在SAGE队列和GIN队列下的排队时间仍为0。GNNSched的灵活共享机制重叠了数据预处理和计算,改进了任务组间的流水线执行效率。另外,GNNSched-SQTF明显比GNNSched-BQT的排队时间更短,平均降低了0.8%。原因是SQTF策略优先调度短时执行任务,缓解了等待长时任务完成时的队头堵塞。
4.5 显存估计精度
PMC的精确估计对于保证并发执行的显存安全是必要的。本文使用相对误差RE(relative error)来度量估计精度。图9给出了GNN推理任务的PMC估计的相对误差,可以观察到所有任务的误差均低于8%。原因是显存成本函数准确地获取了GNN算子的显存消耗。另一方面,随着子图节点数和边数的变化,GNNSched取得了稳定的估计精度。这表明基于网络结构生成的DAG很好地表示了前向传播的计算流程。根据以上结果,本文将乘法阈值(threshhold)设置为1.1从而确保空间共享下的显存安全。
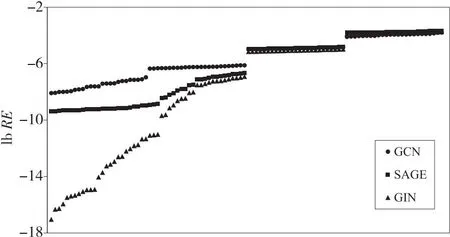
Figure 9 Relative errors of PMC estimation图9 PMC估计的相对误差
4.6 开销分析
本节将GNNSched的处理开销归一化为任务推理时间。处理开销可以分为PMC估计、任务调度和Buffer插入3个部分。PMC估计通过显存成本函数遍历计算图以获取PMC信息。任务调度将并发推理任务组织为队列,再根据调度策略对队列进行重排并生成任务组。Buffer插入基于PMC信息将Buffer插入到分配显存的特定位置。图10显示了GNNSched处理开销的时间分解。可以看到,处理开销相对于任务执行可以忽略不计,在低负载和高负载下的平均时间仅为推理时间的2.4和3.0。这表明使用GNNSched来管理相异的推理任务可以有效提高GPU吞吐量。

Figure 10 Time breakdown of processing overhead图10 处理开销的时间分解
5 相关工作
5.1 图神经网络的算子加速
最近研究工作深入挖掘了GNN的计算特征,并针对GPU架构进行细粒度优化。FeatGraph[27]结合图划分与特征维度优化聚合阶段的缓存利用。Huang等人[3]通过局部敏感哈希对节点进行聚类,再对邻居进行分组以缓解负载不均衡。GNNAdvisor[13]通过引入warp对齐的线程映射和维度划分来减少线程分歧。QGTC(Quantized graph neural networks via GPU Tensor Core)[28]基于低位数据表示和位分解的量化技术实现了张量核心定制的计算内核。本文工作与上述工作在性能优化上互补,GNNSched的重点在于GNN推理任务的并发调度。
5.2 深度学习推理调度系统
许多研究工作提出了各种调度系统来改进部署在集群上的深度学习推理任务的服务质量。Clipper[29]设计了模型抽象层以在框架之上实现缓存和自适应批处理策略。MArk[30]动态处理批量推理请求并适时地使用GPU以改进性能。Nexus[21]通过打包机制将推理任务组调度到集群并指定每个任务的GPU使用。Clockwork[31]提供性能可预测系统,其通过中央控制器调度请求并预先放置模型。这些系统均未考虑推理任务在单GPU上的空间共享,从而导致计算资源的利用率较低。
6 结束语
本文提出了并发GNN推理任务调度框架GNNSched,其可以高效管理GPU上共置的推理任务。GNNSched将推理任务组织为队列,并提取图输入数据和模型网络结构信息;之后,GNNSched对每个任务的计算图进行分析,并利用算子成本函数估计任务显存占用;最后,GNNSched实现了多种调度策略用于生成任务组,并将其迭代地提交到GPU上执行。实验结果表明,GNNSched可以满足推理任务服务质量要求并降低响应时延。
