基于众测操作记录的Web测试用例自动生成方法
2024-01-24张清睿孙乐乐
张清睿,黄 松,孙乐乐
(陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引 言
近年来Web应用变得越来越受欢迎,使用范围变得越来越广泛。因此,对Web系统的质量保证方法和工具的需求越来越高[1]。
软件测试是软件开发过程的重要组成部分,通过发现系统的故障从而提高系统的可靠性[2]。众包测试是一种新兴的软件测试方式,可用性测试、性能测试和GUI测试等方面应用广泛[3]。与传统的软件测试相比,众包测试可以随时随地进行,从而极大地提高了测试效率[4]。
但是由于众测工人水平参差不齐,测试用例书写不规范的问题,众测背景下Web测试用例自动生成技术应运而生。与基于软件源代码和基于需求文档的测试用例生成方法相比,众包测试更适用于基于测试工人操作记录的测试用例生成方法。在测试用例自动生成的研究领域,一些大型商业软件,如winrunner使用基于屏幕坐标的方法录制回放测试脚本[5]。该方法不仅对测试人员的专业水平要求较高,而且当网页修改后需要花费高成本重新录制脚本。Paiva[6]提出了从用户使用信息中自动生成测试用例的方法,通过OWA工具从系统日志中获取用户的频繁操作路径,然后通过自定义的规则集将其转换为PHP语言编写的测试脚本,但是该方法不适用于新研系统的测试。
因此,该文提出了一种基于众测工人操作记录自动生成测试用例的方法。该方法对Web页面进行录制,然后从庞大的录制数据中提取出众测工人的测试序列,并转化为文本测试用例,这是一种无代码化的测试用例生成方法。该方法不仅可以自动化地生成规范的测试用例,降低众测的门槛,提高测试效率,还可以将众测工人的操作进行回放,方便开发人员进行缺陷复现。
1 相关工作
本节介绍了软件测试中与操作记录相关的研究。Paiva等提出了从用户使用信息中自动生成测试用例的方法,通过OWA工具获取用户的频繁操作路径,然后通过自定义的规则集将其转换为PHP语言编写的测试脚本,但是该方法生成的脚本缺少测试数据,这些数据需要测试人员手动提供。Li等[5]提出了基于用户行为建模的Web功能测试自动执行系统,可以记录用户的操作顺序并自动生成XML格式的测试用例,通过组件类型和数据池的方式生成部分测试数据,但是该方法在实际应用中能够生成的测试数据极少,有很大的局限性。龙测科技公司提出了Web自动化测试的方法,首先录制测试流程,然后基于测试序列,测试人员可以通过搭积木的方式将对应的模块拖拉拽到编辑屏幕上,再通过箭头将序列连接,最终产生测试用例集合,这种无代码的形式,极大地降低了测试的门槛。但是该方法生成的仍然是测试脚本,可以应用于回归测试中,不适用于众测领域。Selenium IDE是火狐浏览器的一个插件,用户无需任何编程能力也可以生成测试脚本,只需记录与浏览器的交互从而创建测试用例。Katalon Recorder支持录制Web页面操作,并能实现基本的数据驱动测试。Selenium IDE,Katalon Recorder等测试工具虽然已经降低了测试的门槛,但是还不能完全称之为无代码化的测试工具,因为这些工具将测试人员与Web应用程序的交互信息表示为一个三元组(命令,目标,值)形式的录制脚本,对于不具备该领域知识的测试人员修改录制脚本的难度仍然很大,并且这种脚本化的测试用例也不适用于众测领域。Chang等[7]首次提出使用计算机视觉进行GUI测试的方法,测试用例可编写为一个可视化测试脚本,该脚本使用组件图像进行定位,降低了测试脚本编写的难度。Kirinuki等[8]提出面向无脚本测试的Web元素识别方法,首先利用NLP技术从Web元素中提取相关信息生成字符串,然后判断字符串与目标元素的相似性定位元素,进而生成DSL编写(接近自然语言)的测试用例,但该方法目前只能处理简单的操作,例如点击、输入和选择。
上述研究适用于具有相关领域知识的专业测试人员,部分工具自动化生成水平较低,需要测试人员进行大量的手动调整。该文研发了一款使用简单、自动化水平较高、适用于众测工人的无代码化测试用例自动生成工具,并且获取的测试信息更完善,测试信息可以表示为一个四元组(组件名称,组件类型,交互动作,交互数据)。
2 测试用例生成
本节介绍了如何将众测工人的操作记录转化为规范的测试用例。该方法可以划分为四个阶段:首先,录制页面信息和用户的交互信息,其中页面信息包含静态页面信息和动态页面信息;其次,使用深度优先遍历算法从录制信息中获取每个操作步骤的组件名称、组件类型、交互动作和交互数据,并按照众测工人的实际操作顺序生成规范的测试序列;然后,通过n元组算法对测试序列中的错误信息进行修改;最后,通过自定义规则集将测试序列转换为文本测试用例。测试用例生成流程如图1所示。
2.1 测试行为录制
rrweb[9](record and replay the web),一款针对Web页面进行录制、回放的开源库,可以将页面中的DOM以及用户操作保存为可序列化的数据,以实现远程回放。rrweb可以应用于很多应用场景,例如:
(1)记录用户使用产品的方式并加以分析,进一步优化产品。
(2)采集用户遇到bug的操作路径,予以复现。
(3)轻量级录制,清晰度无损的产品演示。
作为一款Web页面录制工具,尽管rrweb的应用场景很广泛,但是由于开源时间较短,目前网上与之相关的资料较少。该文的创新在于发现了录制数据之间的联系,并实现了从中提取测试用例的方法。
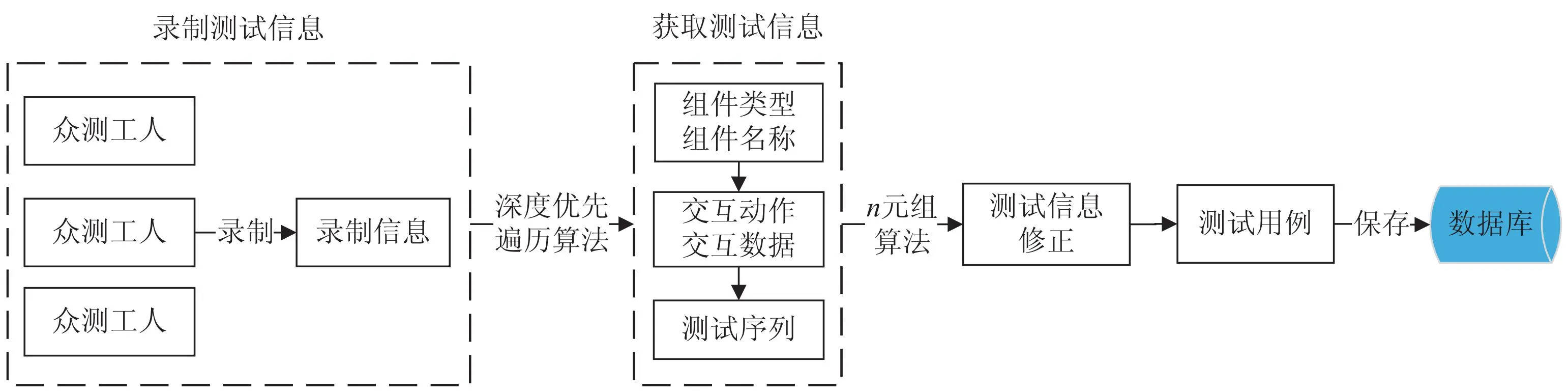
图1 测试用例生成流程
页面信息和众测工人的交互信息由rrweb的录制API收集,并以JSON字符串的形式存储到数据库中。当众测工人在测试过程中发现缺陷时,可以将录制的操作当作一种特殊形式的缺陷报告,有利于开发人员对缺陷进行回放复现,从而加快缺陷的修复速度。由于录制的数据量庞大,在录制时不录制鼠标的移动事件,在录制Form表单输入数据时,不录制输入过程,只录制最终的输入结果。页面的信息以DOM树的形式进行存储。众测工人的交互信息中记录了交互数据以及被操作组件的id。这些操作序列中具有大量的冗余、噪声数据,需要进一步的处理。
2.2 测试序列生成
在本小节中需要对录制的原始数据进行处理,从而提取出众测工人操作的组件类型、组件名称、交互类型和交互数据等信息。
主要分为四个步骤:
(1)将录制的JSON字符串转换为自定义的对象类型,方便后续的查询、封装操作。
(2)获取组件类型,如Input,Button,TextArea等。
(3)获取组件名称,如登录模块Button按钮的组件名为登录,Input输入框的组件名为用户名、密码。
(4)获取交互数据并根据组件类型进行分类从而生成交互动作,因为不同的组件类型具有不同的操作。
2.2.1 数据类型转换
Fastejson是一个Java库,可以将Java对象转换为JSON格式,同样也可以将JSON字符串转换为Java对象。该文通过自定义类,使其与录制的数据结构相符,并且类中的属性覆盖了录制数据中绝大多数的变量。然后将录制的JSON字符串转换为自定义的DataAnaly对象类型。自定义类图如图2所示。
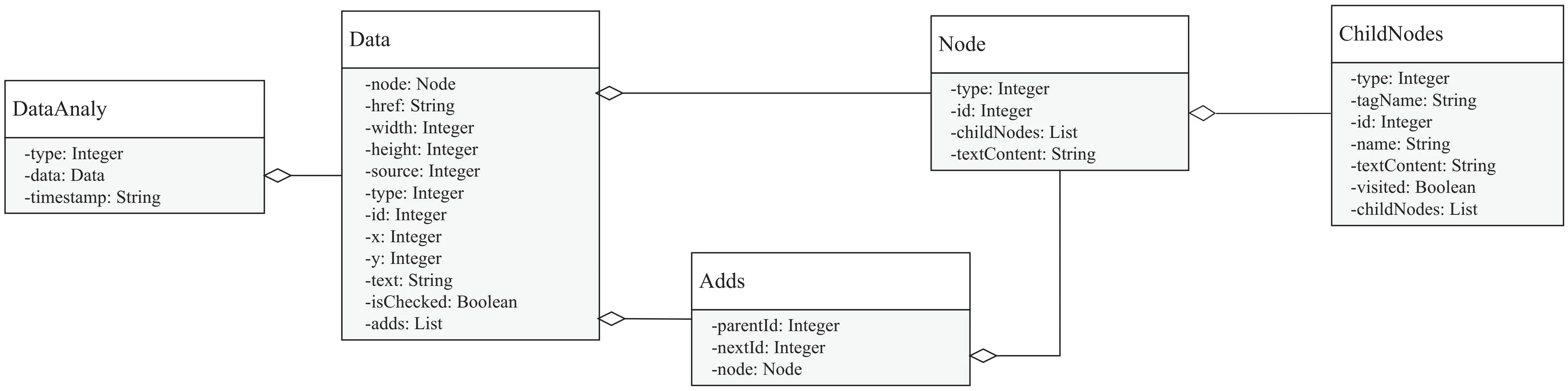
图2 自定义类图
2.2.2 获取组件类型
因为交互信息中的id与页面信息DOM树中的id是匹配的,该文采用深度优先遍历算法进行id匹配,从而获取组件类型。深度优先遍历算法会对每一条分支路径深入到不可能再深入为止[10]。由于交互信息存在冗余,会出现多个相同的id,因此在保证原始操作顺序的前提下需要对交互信息中的id进行去重操作避免重复查询。
获取组件类型方法如算法1所示。针对去重后的每个操作id,遍历body下的节点,并将访问过的节点进行标记,如果节点被标记则不再访问该节点(见算法1中的第6~9行),如果节点中有子节点,则调用deepFindTagName( )函数继续搜索其子节点(见算法1中的第10行)。遍历子节点,如果id匹配成功则将获取的组件类型封装到Operate对象中,并将Operate对象添加至tagNames集合中(见算法1第16~21行),Operate具有几个重要属性,分别是tagName记录组件类型,label记录组件名称,data记录交互数据,action记录交互类型。如果id没有匹配到并且该子节点仍然存在子节点则递归调用deepFindTagName( )函数(见算法1中第23行)。动态页面信息的获取同样采用深度优先遍历算法查看adds节点下的node节点。
算法1:获取静态数据的组件类型算法。
Input:操作id的集合
Output:operate对象的集合
1. function findTagName(ids)
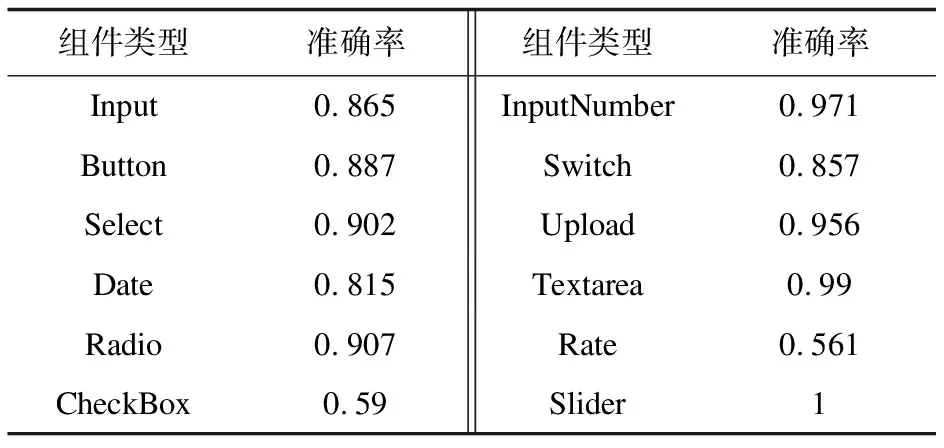
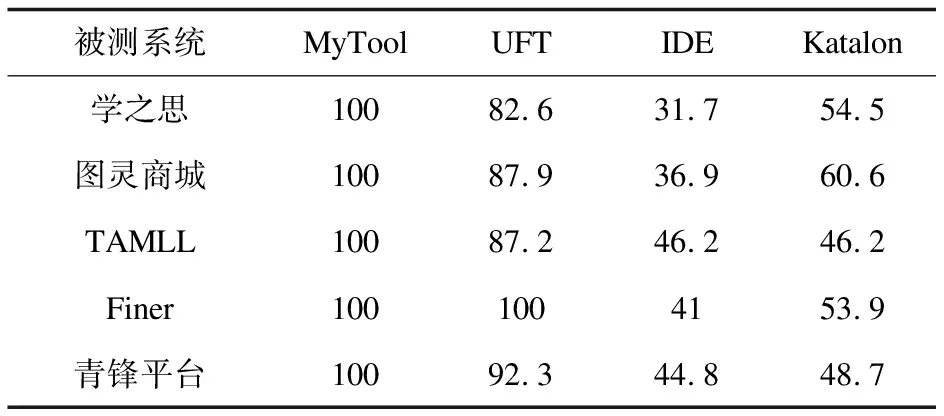
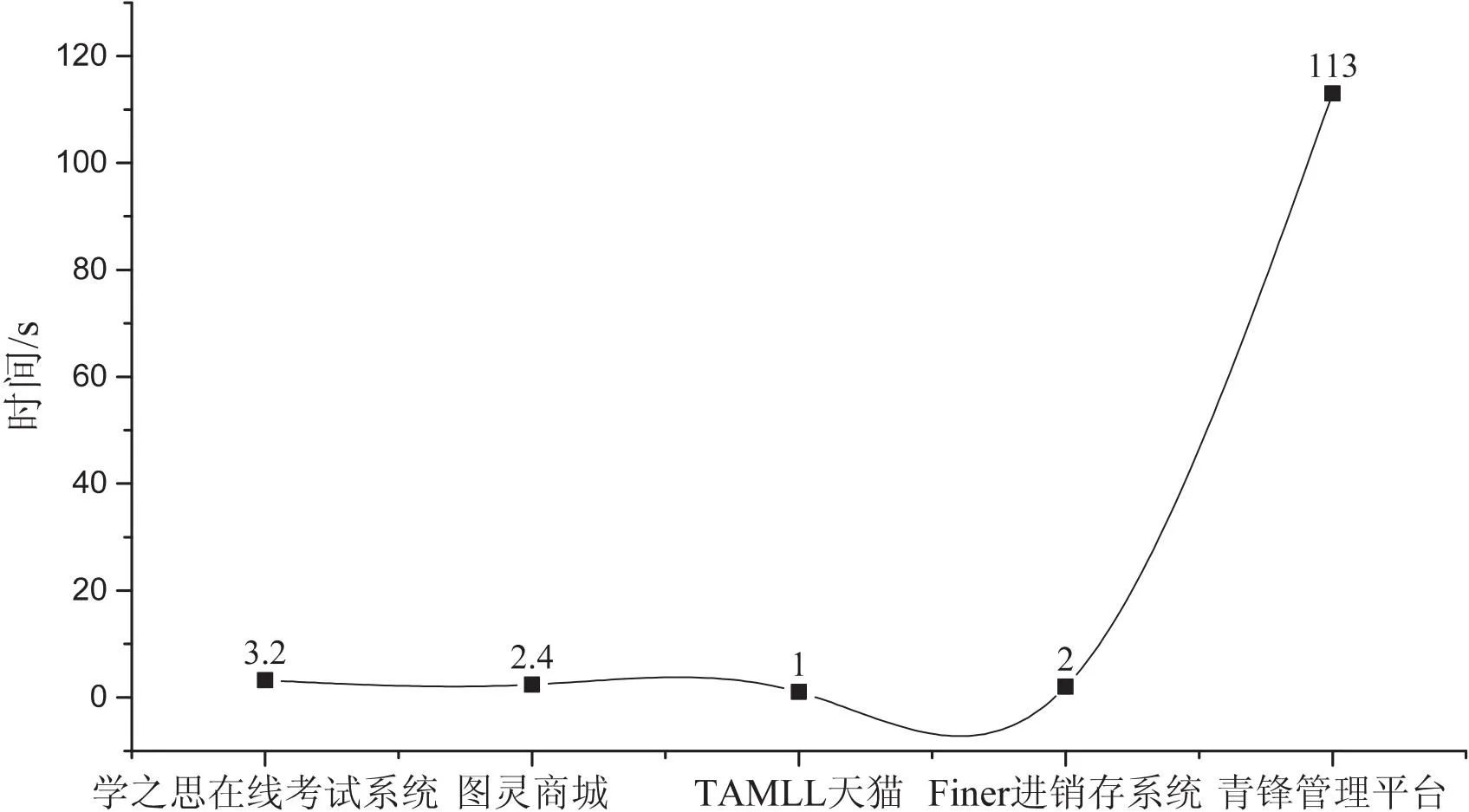
2. for i=0; i 3. Integer id= ids.get(i) 4. isfind= false 5. List 6. for j=0; j 7. if bodyNodes.get(j).getChildNodes() == null continue 8. if bodyNodes.get(j).isVisited() continue 9. bodyNodes.get(j).setVisited(true) 10. deepFindTagName(bodyNodes.get(j).getChildNodes(),id) 11. if isfind break 12.function deepFindTagName(childNodes, id) 13. for i=0; i 14. if childNodes.get(i).isVisited() continue 15. childNodes.get(i).setVisited(true) 16. if id == childNodes.get(i).getId() 17. String tagName= childNodes.get(i).getTagName() 18. isfind= true 19. Operate operate= new Operate() 20. operate.setTagName(tagName) 21. tagNames.add(operate) 22. break 23. deepFindTagName(childNodes.get(i).getChildNodes(),id) 2.2.3 获取组件名称 组件名称的获取分为两种情况,一种是前端在编码时通过标签显示组件名称,这种情况下采用就近匹配的原则,通过深度优先算法获取组件名称;另一种是前端在编码时不使用标签,而是在组件内部显示提示信息,这种情况可以直接获取提示信息作为组件名称。 第一种情况,组件名称无法直接通过操作组件的id进行匹配,因为组件名称与被操作的组件通常存在以下两种关系,即左右相邻关系和包含关系。因此需要对组件进行分类,然后针对不同类型的组件分别进行相应的操作。 (1)IF组件类型为Input,TextArea等THEN 采用深度优先遍历算法自底向上遍历其相邻节点。 (2)IF组件类型为Button等 THEN遍历其子节点。 针对第二种无标签的情况,可以直接根据操作id采用深度优先遍历算法获取placeholder的属性值(输入框中的默认值)作为组件名称。 2.2.4 测试序列生成 在获取组件类型和组件名称后,还需要获取交互类型和交互数据。交互数据可以直接从测试工人的操作信息中进行获取。为了获取众测工人的交互类型,需要对组件类型进行分类,因为不同的组件具有不同的操作,为此定义了一组规则集: (1)IF组件类型为Input‖TextArea THEN设置交互类型为输入并获取交互数据。 (2)IF组件类型为Radio‖CheckBox‖Select‖Date THEN设置交互类型为选择并获取交互数据。 (3)IF组件类型为Upload THEN设置交互类型为上传并获取交互数据。 (4)IF组件类型为Input Number THEN设置交互类型为点击并获取交互数据。 (5)IF组件类型为Button‖Switch THEN设置交互类型为点击。 组件名称、组件类型、交互类型和交互数据全部获取后,按照众测工人的操作顺序有序地存放到集合中。虽然生成了规范的测试序列,但是测试序列中仍然存在噪声数据,如点击开始录制和保存录制按钮的事件,以及一些并非测试工人操作生成的数据。为此,定义了一组规则集用于去除噪声数据: (1)IF组件名称为开始录制‖保存录制 THEN 去除该数据。 (2)IF组件名称为空 THEN 去除该数据。 (3)IF 交互动作为空 THEN 去除该数据。 (4)IF 交互数据为空 &&组件类型不为Button THEN 去除该数据。 测试序列效果图如图3所示。 图3 测试序列效果图 上一节针对左右相邻关系的组件和组件名称,在匹配上采用了就近匹配的原则,但是该方法在Radio,CheckBox组件上存在匹配错误的情况,以单选框(性别 ○男 ○女)为例,当选择男时,就近匹配原则不存在问题,获取的测试信息为(组件名称:性别,交互数据:男);当选择女时,按照就近匹配原则生成的测试信息为(组件名称:男,交互数据:女),很明显获取的组件名称是错误的。除此之外,其他组件名称匹配错误同样可以通过n元组生成方法进行自动修改,例如输入框可以生成(组件名称,交互数据)二元组。 基于DOM的方法无法解决上述问题,新一代基于机器视觉的方法为Web应用复杂组件的测试提供了一种有效途径[11]。该文利用YOLOv5算法构建了Web应用页面组件识别模型,识别页面组件类型并标注其位置;利用百度通用OCR接口识别页面文字信息。OCR技术可以实时高效地定位并识别图片中的所有文字信息,进而得到文字框位置与文字内容[12];最后通过n元组生成算法生成组件名称与组件选项的对应关系或者是组件名称与交互数据的二元组对应关系,并通过测试序列中的交互数据与n元组进行匹配,进而获取正确的组件名称,从而达到已生成测试序列中的错误测试信息自动修改的目的。n元组生成流程如图4所示。 图4 n元组生成流程 2.3.1 组件识别 本小节利用YOLOv5算法训练了Web组件识别模型,从而识别组件的类型和位置。YOLOv5是Glenn Jocher在2020年提出的一种单阶段目标检测算法,采用了马赛克数据增强方法,通过对输入图像进行随机变换和拼接,在小目标检测中表现更好[13]。由于Web系统主要是针对Form表单进行操作,该文选择了Form表单中频繁使用的12种组件进行识别,分别是Button(按钮)、Radio(单选框)、CheckBox(复选框)、Input(输入框)、InputNumber(计数器)、Select(选择框)、Switch(开关)、Date(日期)、Upload(上传)、Textarea(富文本框)、Rate(评分)、Slider(滑块)。 数据集来源于Gitee中的各种商用以及开源Web系统,其中前端框架涉及ElementUI,Bootstrap,LayUI,EasyUI和Ant Design Vue,共搜集1 500张图片,标注了12种频繁操作的组件类型,按照7∶2∶1的比例随机抽取训练集、验证集和测试集。通过对精度与识别速度的衡量选择yolov5m.pt为预训练权重,训练时输入图像大小为640×640,初始学习率为0.001,最大迭代次数为400,batch-size设置为8。通过训练后得到的模型在测试集上的组件识别的准确率如表1所示。 表1 测试集中组件识别的准确率 训练完成以后,将该模型应用于Web页面组件类型及位置识别。为了提高预测的准确率,将置信度设置为0.7,只有置信度大于0.7的组件才会在页面上进行标注。 2.3.2n元组生成 OCR技术是利用光学技术和计算机技术通过检测字符每个像素的暗、亮模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程[14]。在经过YOLOv5模型识别出组件类型和位置,以及百度通用OCR接口识别出文字内容与位置后,通过n元组生成算法生成组件名称与选项的对应关系。考虑到组件与文字的位置关系包含相邻关系和包含关系,算法中以组件位置为基准,分别进行向左匹配获取组件名称和内部匹配获取选项名称。以上思路是理想情况下的实现思路,但是实际情况中会出现以下两个问题:一是当组件名称与选项距离过近时,OCR会将其识别为一个整体;二是OCR存在一定误差,文字中存在特殊字符,将多选框的方框、单选框的圆圈等包含在内。 n元组生成算法如算法2所示。首先进行向左匹配,针对每个YOLOv5模型识别出的组件,遍历OCR识别出的文字信息列表,若存在一个文字框位于组件框左侧距离不大于50,且文字框上下边界位于组件框上下边界之间,则判断该文字为该组件的组件名称(见算法2中的第4~6行)。然后进行内部匹配,如果文字框位于组件框的内部,则认为该文字为组件的选项或者是交互的数据,将其添加至组件名称的后面(见算法2中的第8~10行)。针对问题一中的情况,文字框框与组件框相交,如果组件名称还未匹配到则添加到列表的开头位置,如果组件名称已经存在则添加至组件名称后面(见算法2中的第11~16行)。针对问题二中的情况,通过自定义函数remove(n)将n元组中的特殊字符去除(见算法2中的第17行)。 算法2:生成n元组算法。 Input:页面中元素信息列表,页面中文字信息列表 Output: n元组列表 1. def generate(yolov_infors, ocr_infors): 2. for yolov5_info in yolov_infors: 3. for ocr_info in ocr_infors: 4. if 0 <= yolov5_info.x1 - ocr_info.x2 <= 50 and ocr_info.y1 >= yolov5_info.y1 and 5. yolov5_info.y2 >= ocr_info.y2 6. n.append(ocr_info.word) 7. label= true 8. if yolov5_info.x1 <= ocr_info.x1 and yolov5_info.x2 >= ocr_info.x2 and 9. ocr_info.y1 >= yolov5_info.y1 and yolov5_info.y2 >= ocr_info.y2 10. n.append(ocr_info.word) 11. if (ocr_info.x1 12. ocr_info.y1 >= yolov5_info.y1 and yolov5_info.y2 >= ocr_info.y2 13. if label: 14. n.insert(1,ocr_info.word) 15. else: 16. n.insert(0,ocr_info.word) 17. n= remove(n) 18. list.append(n) 19. return list 自动生成测试序列以后,需要把测试序列自动转化为文本测试用例。该文通过自定义规则集对测试序列中的测试信息进行排列,进而生成文字描述形式的测试用例: (1)IF 组件名称为Input‖TextArea‖Radio‖CheckBox‖Select‖Date‖Upload‖InputNumber THEN组件名称+交互动作+交互数据。 (2)IF 组件类型为Button‖Switch THEN 交互动作+组件名称。 在众包测试过程中,众测工人会提交大量质量参差不齐的测试用例报告,测试用例报告中存在大量冗余测试用例[15]。因此在保存测试用例时需要进行去重操作,减少冗余的测试用例。由于众测工人测试水平不同,因此就算是测试步骤和测试数据完全相同的测试,测试工人书写的测试用例依然具有差异性,这就增加了去重的难度。在测试步骤与测试数据相同的前提下,文中的测试用例自动生成工具可以生成规范统一的测试用例,解决了众测中测试用例去重困难的问题。 文本测试用例在保存时,首先与数据库中已有的测试用例进行对比,如果存在相同的测试用例则不再保存。为了评估众测工人生成测试用例报告的质量和多样性,该文提出了测试用例覆盖率(Test Case Coverage,TCC),定义如下: (1) 其中,save_testcase代表众测工人保存到数据库的测试用例数量,record_testcase代表众测工人录制的测试记录数量。测试用例覆盖率越高,表示冗余测试用例越少,测试用例报告质量越高。 文本测试用例效果图如图5所示。 图5 文本测试用例效果图 由于录制回放工具普遍存在两个问题,一是操作步骤录制不完整,二是生成的测试信息不完整。为了评估文中方法所实现测试工具的性能,提出了以下四个研究问题。 研究问题1:实现的测试用例自动生成工具是否支持不同技术开发的Web系统?对不同框架不同结构的Web系统是否适用? 研究问题2:实现的测试用例自动生成工具在测试步骤完整性上效果如何? 研究问题3:实现的测试用例自动生成工具在测试信息完整性上效果如何? 研究问题4:实现的测试用例自动生成工具在时间性能上效果如何?能否在较短的时间内将录制数据转化为测试用例? 针对问题1实验对象为Gitee中5款不同技术开发的Web系统,其主要开发技术如表2所示。 实验环境:操作系统为Windows10,CPU为Intel(R) Core(TM) i7-10875H @ 2.30 GHz,GPU为RTX 2070 Ti 8G,运行内存16G,模型训练框架为Pytorch,使用CUDA并行计算框架并配合CuDNN来加速网络模型训练。 表2 被测Web系统详情 实验过程中招募5名众测人员进行测试。选取了三款不同的最新版本的录制回放测试工具,分别是UFT 15.0.2,Selenium IDE 3.17.2,Katalon Recorder 5.9.0,与该文实现的工具进行实验对比。针对问题2,使用平均操作覆盖率(AOCR)来衡量不同测试工具对众测工人测试记录的覆盖率: (2) 其中,n代表众测工人的数量,record_operations代表测试工具生成的正确操作集合,real_operations代表执行测试任务时众测工人的实际操作集合。被测系统的平均操作覆盖率如图6所示。 图6 平均操作覆盖率 实验结果显示,在ElementUI框架开发的Web系统中文中工具在测试步骤完整性方面要优于其他测试工具。实验过程中发现UFT,Selenium IDE,Katalon Reconder无法有效定位富文本编辑器插件以及获取其交互数据,导致在被测试系统学之思在线考试系统中录制的正确步骤较少;UFT无法成功定位日期选择框、级联选择器以及获取其交互数据,Selenium IDE,Katalon Reconder无法成功获取文件上传的有关信息,在日期框交互次数较多的情况下,会出现获取交互数据不准确的情况;在传统的前后端一体的Web系统上(TAMLL天猫、青锋管理平台),文中工具在获取测试步骤中要差于其他测试工具,主要原因是前端页面中的大量组件都是通过JavaScript渲染生成,测试人员的某些操作会导致录制数据中出现部分无规则数据,进而导致文中工具在获取组件名称时出现错误,不过n元组算法在TAMLL天猫系统中发挥了重大作用,将添加产品功能的步骤覆盖率提高了29%。 针对问题3,在已经生成的正确的测试步骤前提下,为了评估工具生成测试用例的信息完整性,包括组件名称、组件类型、交互数据和交互动作,提出了平均测试信息覆盖率: (3) 其中,gen_testInfo代表工具生成的每个测试步骤中的测试信息数量,exp_testInfo代表期望的测试信息数量,m代表测试用例中的测试步骤数量,n代表众测工人的数量。被测系统的平均测试信息覆盖率如表3所示。 表3 平均测试信息覆盖率 % 实验结果显示,文中工具的平均测试信息覆盖率达到100%,生成的测试用例中包含了组件名称、组件类型、交互动作和交互数据,证明了文中方法生成的测试用例具有很高的信息完整性。实验过程中发现UFT生成的测试用例中缺少大部分组件的名称,只有少数组件可以获取到组件名称,如按钮,UFT也可以获取组件中的默认值作为组件名称。UFT是基于对象库的录制方式,可以间接获取大部分组件的组件类型,因此UFT的平均测试信息覆盖率要高于其他两款测试工具。 Katalon Reconder生成的测试用例中缺少组件名称,部分组件缺少交互数据,如下拉框,日期框,单、多选框等。在组件属性不存在id的时候,Katalon Reconder通过优先级较高的XPath进行定位,可以间接获取组件类型,Selenium IDE通过优先级较高的CSS进行定位,因此在Vue架构下的Web系统中,Katalon Reconder的测试信息覆盖率要高于Selenium IDE的测试信息覆盖率。Selenium IDE生成的测试用例缺少组件名称、组件类型,部分组件缺少交互数据,如下拉框,日期框,单、多选框等。 针对问题4,该文统计了在不同被测系统上录制数据转化为测试用例的平均时间,如图7所示。 图7 转换为测试用例的平均时间 实验结果显示在前四个系统上录制数据自动转化为测试用例的时间最多不超过4秒,但是在青锋管理平台时间较长,通过对录制数据进行分析发现,该系统基于LayUI框架开发,具有丰富的弹框组件,且该系统存在大量JavaScript渲染的页面,导致录制数据中出现较多的动态节点树,因此在测试信息搜索过程中花费了大量时间。 该文研究了众测背景下测试用例自动生成的问题,提出了一种基于众测工人测试记录自动生成规范测试用例的方法,并实现了该工具。这是一款真正无代码化的测试工具,更加适合没有编程能力的众测工人,降低了众测的门槛,提高了测试效率。实验结果表明,该方法能够获取较高的平均操作覆盖率,平均测试信息覆盖率达到百分之百,生成的测试用例信息更加完整。
2.3 测试信息修改

2.4 文本测试用例

3 实验分析
3.1 实验对象
3.2 实验结果


4 结束语
