一种基于半监督集成学习的软件缺陷预测方法∗
2024-01-23朱丽娜
张 莹 朱丽娜
(1.淮北理工学院电子与信息工程学院 淮北 235000)(2.淮北师范大学物理与电子信息学院 淮北 235000)(3.广西财经学院信息与统计学院 南宁 530003)
1 引言
近年来,随着信息化技术的高速发展,软件产品的数量急剧增加,在为生活带来便利的同时,由于种种原因都可能产生软件缺陷。软件内部隐藏的缺陷可能导致轻则无法满足用户的需求,重则严重影响软件质量造成经济损失,甚至会危及到人们的生命安全。对软件中包含的缺陷进行预测,开发人员可以基于预测结果分配有限的资源,以缓解开发过程中软件测试的压力,从而提高软件质量。
软件缺陷预测数据普遍存在着类不平衡的问题,常常造成预测结果偏向多数类,对少数类的预测精度降低。数据不平衡会导致预测模型的误分类代价较高、模型的泛化能力较差。因此,在软件缺陷预测中,需要重点考虑如何在一个不平衡的数据集中训练出一个更合适的分类模型,从而提高小样本的预测精度。
2 相关工作
针对标签样本不足,可以运用半监督学习的思想充实样本集。廖胜平等[1]基于半监督学习与SVM 构建预测模型,在训练集数据较少、无历史数据或者标签信息较少时都能获得较好的预测性能。Li等[2]提出一种名为EATT 的半监督缺陷预测模型,结果表明该模型不仅可以获得较高的分类精度,还具有很高的实用价值。
针对数据的特征冗余,目前已有很多特征处理的方法可供选择,蒋帅[3]在实验中选择更具有判别性和规律性的特征,移除无关特征,具有较好的预测效果和较高的应用价值。张俐等[4]提出WMRI特征选择算法改善特征子集的质量并提高分类精度。
针对类不平衡问题,大多数人会选择简单有效的数据重采样。Malhotra等[5]通过改进SPIDER2过采样方法提出了SPIDER3,同时还发现了在不平衡数据集中利用过采样方法可提高机器学习分类器的缺陷预测性能。其次,也会选择集成学习和代价敏感学习方法。如王铁建等[6]提出基于SSEL 的软件缺陷预测方法,预测效果良好。还有典型的代价敏感决策树算法—ICET方法[7]。
为了构建更高性能的预测模型,人们将分类思想相互结合形成综合方案。例如Iqbal 等[8]提出一种基于特征选择的集成分类框架,该框架的性能优于其他分类技术,但无法解决类不平衡问题。Zhou等[9]结合核心主成分分析(KPCA)和加权极限学习机(WELM)提出了名为KPWE 的缺陷预测框架。类似还有结合多核学习的Boosting 集成方法[10]、通过平衡训练集后使用NB算法得到映射子集最终集成的方法[11]、基于混合采样和三种基分类器集成的SSIDP算法[12]等。
综上,人们都会在数据的预处理阶段进行数据的重采样或特征处理,也会结合不同的分类思想来构建模型,但将半监督学习、数据重采样、特征选择和集成学习综合使用的研究却很少。针对上述软件缺陷预测中可能存在的若干问题,本文重点关注类不平衡和特征冗余问题,借鉴目前较成熟的方法并对其综合考虑,提出一种改进的软件缺陷预测方法。
3 改进的软件缺陷预测方法
改进的软件缺陷预测方法如图1 所示。首先,对训练集进行混合采样以获取一个相对平衡的训练集;然后,对采样后的训练集和测试集进行SMA特征选择选取效果最优的若干特征,以降低数据的特征冗余;最后,使用改进的半监督Adaboost 算法进行集成,得到最终的预测结果。
3.1 采样方法
软件缺陷预测中的数据在分布方面很不平衡,大多数都是没有缺陷的模块。处理不平衡数据最直观有效的方法就是数据分布调整,即抽样法,实现对不平衡数据的再平衡采样。本文对数据先欠采样[13]后SMOTE 采样[14]以弥补两者的不足,达到缓解数据类不平衡的目的。
3.2 特征选择
数据中包含大量的特征,这些特征中只有小部分特征对预测类别提供有用信息,所以若能将这些毫无用处的特征去掉,不仅可以降低计算成本,也能提高分类性能。同时各样本之间存在相似数据,不仅会增加模型构建的时间,也会降低数据预测的准确性。因此,应进行特征选择以减少数据中特征的冗余,形成新的数据子集。
本文采用SMA 优化算法对数据进行特征选择,选择效果最优的若干特征。黏菌算法(Slime Mould Algorithm,SMA)是一种通过模拟黏菌在觅食过程中的行为和形态变化得到的优化算法[15]。通过使用权重来模拟黏菌在觅食过程中产生的正反馈和负反馈,从而形成三种不同的形态,黏菌在觅食过程中发现食物时,会有振荡收缩的特性[16]。
用数学公式表示黏菌接近食物的行为
其中,t 为当前迭代次数;Pb(t)为当前最优个体位置;PA(t)和PB(t)为从黏菌中随机选择的两个个体位置;W 为权重;vb和vc为控制参数,vb∊[-a,a],vc从1到0线性递减;c为[0,1]的随机数。
参数a、p和权重W的公式如下:
其中,SI(n)为适应度值排序,S(n)为当前个体适应度值,n=1,2,3…N,cof表示群体中适应度值排名前一半的部分,others表示余下的个体;bF为当前迭代取得的最佳适应度;WF 为当前迭代取得的最差适应度值。
即使黏菌已经找到了更好的食物来源,但仍会分离一些个体去探索其他领域试图寻找更高质量的食物来源,黏菌位置更新公式如下:
其中,UB 和LB 分别为上界和下界;rand 和c 为[0,1]的随机数;z为自定义参数。
3.3 集成学习
集成学习结合多个基分类器进行学习构建最终的分类模型,是目前比较热门的分类学习方法。集成学习在一定程度上也可以缓解数据的分布不平衡。
本文提出一种基于UDEED算法[17]改进的半监督AdaBoost 算 法[18]—SUDAdaBoost(Semi-supervised AdaBoost based on unlabeled data)。UDEED算法不仅能最小化集成学习器在有标签训练样本上的损失函数的,而且利用无标签训练样本能最大化地提升基学习器的多样性。基于此,SUDAda-Boost算法在从训练的弱分类器集合中选择个体分类器时,同时考虑误差和不同分类器间的多样性。
在第t-1次迭代确定的基分类器对无标签训练样本分类时,利用相关系数ρij对不同基分类器间的预测结果进行多样性度量:
ρij∊[-1,1]表示分类器,hi与hj的相似性。若hi与hj正相关,则ρij为正;若hi与hj负相关,则ρij为负;若hi与hj之间无关,则ρij为0。ρij越小,表明两个分类器相似度越小,差异性越大。
评价n 个分类器的多样性,需要计算每对分类器之间多样性的平均值,其中Div 表示两个分类器之间的多样性。
基分类器选择策略:
ρt-1表示候选基分类器与上一轮迭代中已确定基分类器之间的相关系数值;w1为选择基分类器时错误率所占比重;w2为已进行集成的前t 个基分类器之间的平均相关系数值,且w1+w2=1。
算法SUDAdaBoost的集成步骤如下:
4 实验与分析
4.1 数据集
选用具有代表性的NASA 数据集(清洗后)、AEEEM 数据集和MORPH 数据集开展实验。表1列出了所用数据集的部分信息。

表1 数据集信息
4.2 实验结果与分析
实验设定训练集和测试集各50%,其中有标签训练集和无标签训练集各占20%和80%,迭代次数T=100,基分类器为单层决策树,数量50 个。实验另选取了四种典型的机器学习分类算法(NB、RF、DT 和AdaBoost)与SSFSAdaBoost 算法作对比,选用Accuracy、Precision、Recall 和F1-measure 为评估指标。表2、表3、表4 和表5 分别为这几种算法的Accuracy、Precision、Recall和F1-measure值。

表2 Accuracy结果比较
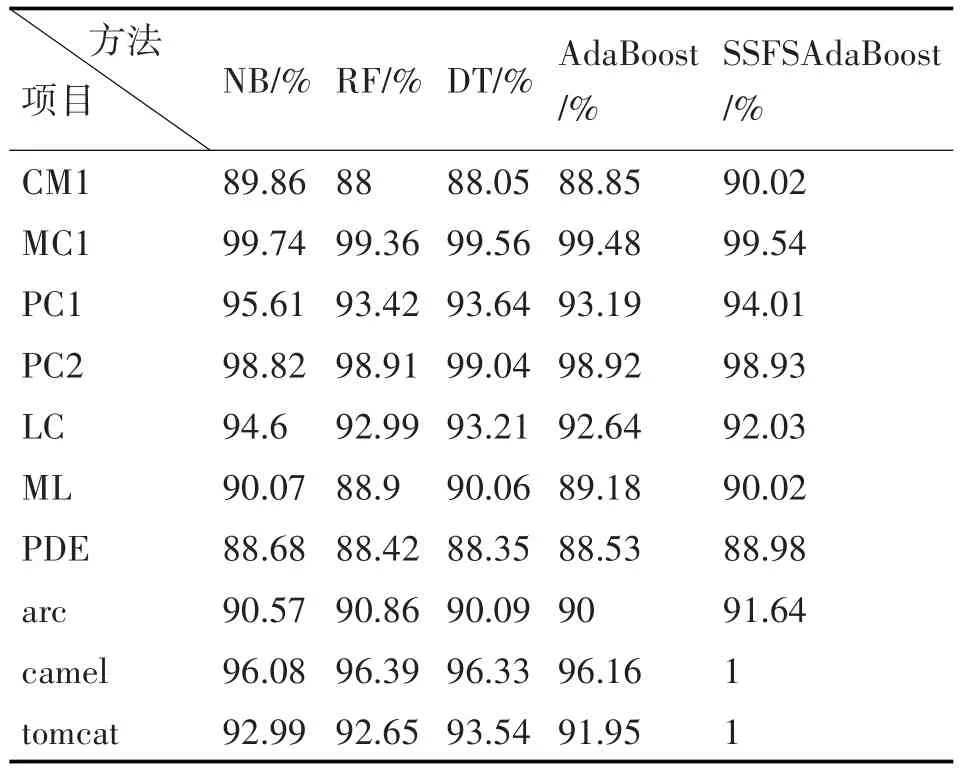
表3 Precision结果比较
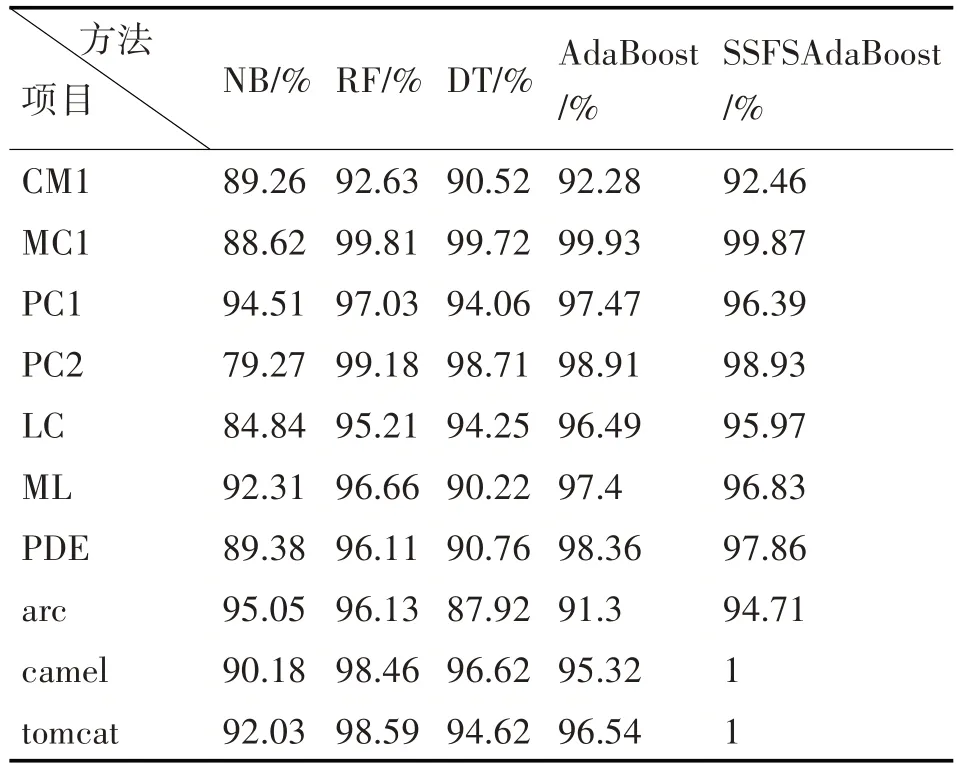
表4 Recall结果比较
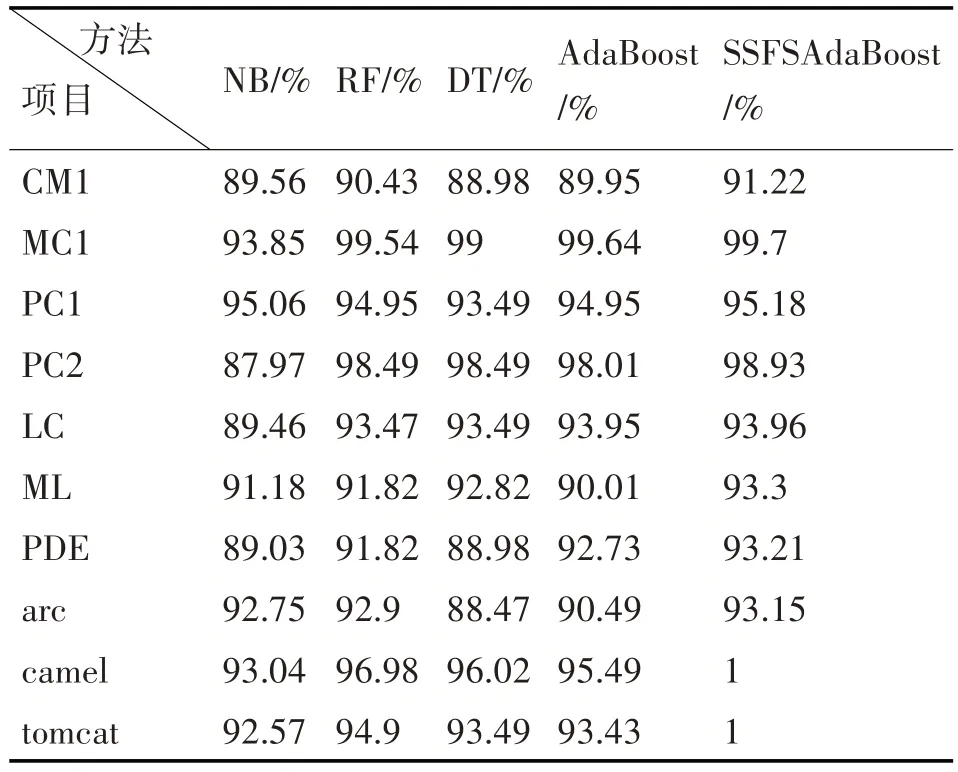
表5 F1-measure结果比较
上述数据表明,SSFSAdaBoost算法与其他四种典型算法相比具有明显的优势。从这四种评估指标的结果来看,SSFSAdaBoost 算法比原始的Ada-Boost算法性能更优;NB、RF和DT的某一评估指标可能会高于SSFSAdaBoost算法,但从整体而言,SSFSAdaBoost算法依然优于它们。同时也反映出SSFSAdaBoost 算法在缓解类不平衡问题上取得了优异的成绩。
为了更清晰地反映出实验的对比度,图2 展示了上述算法评估指标的平均值。NB 算法的Accuracy、Precision、Recall 和F1-measure 平均值为84.85%、93.7%、89.51%和94.88%;RF 算法的Accuracy、Precision、Recall 和F1-measure 平均值为90.7%、92.99%、96.98%和94.53%;DT 算法的Accuracy、Precision、Recall 和F1-measure 平均值为88.33%、93.18%、93.74%和93.32%;AdaBoost 算法的Accuracy、Precision、Recall 和F1-measure 平均值为90.64%、92.89%、96.4%和93.86%;SSFSAdaBoost算法的Accuracy、Precision、Recall 和F1-measure 平均值为93.42%、94.51%、97.3%和95.86%。可以明显看出,SSFSAdaBoost 算法的各项平均值均为最高,整体都要优于其他四种典型分类算法。
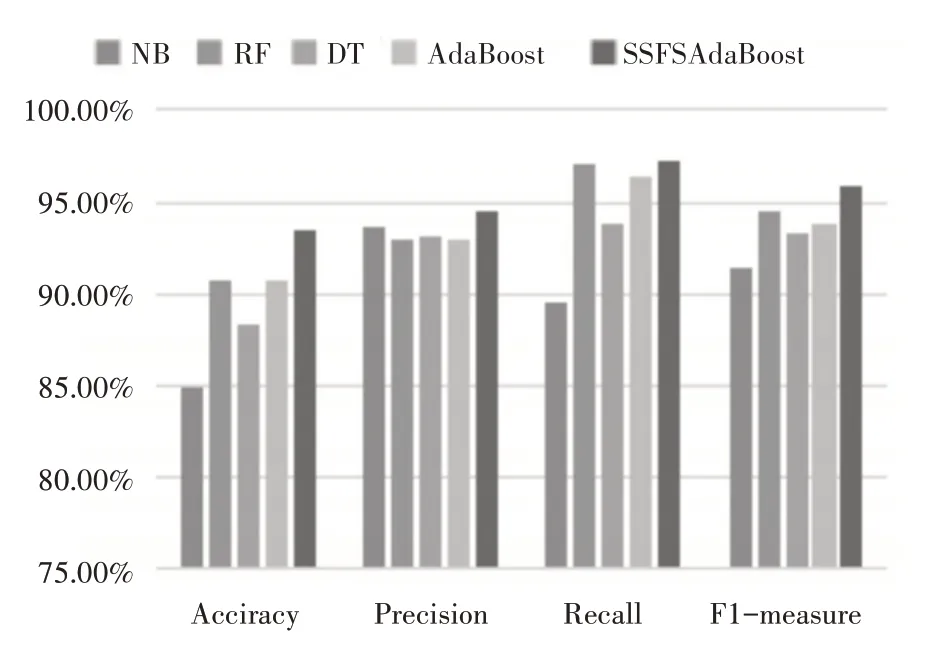
图2 各算法评估指标平均值
5 结语
本文提出一种改进的基于半监督集成学习的软件缺陷预测方法SSFSAdaBoost:利用混合采样对训练集进行预处理以降低数据的不平衡度;利用SMA优化算法做特征选择以缓解特征冗余;利用改进的半监督集成算法SUDAdaBoost 提高预测精度。实验表明该方法要比原始的AdaBoost 算法更好,对缓解类不平衡效果较好且整体预测准确度更高。下一步将继续针对标记样本不足的问题,探究迁移学习在半监督预测模型上的应用。
