基于SVM 和GM-PHD 的密集杂波环境下的数据处理算法∗
2024-01-23武忠鸣郭剑辉楼根铨张文俊
武忠鸣 郭剑辉 楼根铨 张文俊
(1.南京理工大学计算机科学与工程学院 南京 210094)(2.江南造船(集团)有限责任公司 上海 201913)
1 引言
雷达利用物体的回波进行目标探测和跟踪,由于云层和地形反射等[1]因素的存在,雷达同时会接收到不同类型的杂波,如果不能很好地处理杂波会对雷达的性能造成严重的影响。因此,有关密集杂波环境下的雷达数据处理研究具有重要意义。在强杂波环境下,相较于已有的数据关联算法[2~3],使用概率假设密度滤波(PHDF)算法来解决多目标跟踪问题具有计算复杂度较低,工程上更加容易应用等优点,受到国内外学者的广泛关注[4]。该算法的核心思想是使用随机集合后验概率密度的一阶统计量,近似替代后验概率密度函数,以此来近似估计目标数目和目标状态[5]。Vo 等[6~7]提出了两种PHD算法的实现方法,非线性环境下的序贯蒙特卡罗(Sequential Monte Carlo,MSC)PHDF 算法[6]以及本文中会使用到的高斯混合概率假设密度滤波(GM-PHDF)算法[7]。
本文通过结合SVM 和GM-PHD 两种数据处理算法,在考虑扩展目标的情况下,将雷达接收到的航迹点和杂波数据分别视为正样本和负样本,然后进行训练,通过已经训练好的数据,对后续数据进行处理,其中杂波剔除主要通过GM-PHD 算法,并且参考文献[8],在标准GM-PHD 的基础上考虑扩展目标的情况,同时将原来的训练样本和当前的预测数据进行合并,并进行再次训练。仿真实验结果表明,在强杂波环境下,本文提出的算法能够有效过滤杂波,保留有效量测数据,提高计算效率的同时,保证计算精度。
2 高斯混合概率假设密度算法
高斯混合概率假设密度(GM-PHD)滤波算法的运动模型和观测模型都是线性的[9],通过将探测目标状态表示成多个高斯分布的和,从而获得包括均值、方差以及权值等特征数据,通过这些特征值对目标状态进行递推。
PHD 的高斯混合模型[5]可以表示为,其中的分别表示k 时刻第i个目标的高斯分布权值、均值和协方差,Jk表示该时刻高斯分量的个数。使用函数N(∙;m,P)表示变量服从高斯分布,则k时刻的PHD 函数可以表示为
在GM-PHD 滤波算法中,k-1 时刻的PHD 函数是高斯混合形式,因此k 时刻通过算法模型预测得到的先验分布也可以表示为混合高斯和的形式。同理,滤波更新得到的后验分布也可以表示成高斯混合形式。递推过程可以参考文献[7]。
3 基于SVM的数据分类算法
3.1 SVM算法简介
Vapnik 等[10]提出的支持向量机(Support Vector Machine,SVM)理论已经成功地应用于许多领域。与传统的分类方法相比,SVM 具有如下优点:1)几何间隔最大化问题可以转化为一个凸二次规划问题来进行求解从而得到全局最优的解决方案;2)所得到的分类器仅由支持向量来确定;3)对非线性数据集的泛化能力也更强[10],能够有效处理高纬度数据相关的问题。
3.2 回波特征提取
理论上,特征数越多对于进行数据分类会更有利,不过由于算力的限制,如果特征维度过高,反而会为算法带来很多麻烦[11]:高维度会增加计算成本,同时在试验过程中,不能保证完全区分有效特征与无效特征混杂。结合SVM 和LDA[12]的使用方式已经被应用到各个领域,包括人脸识别,文本分类和生物信息学等[13~14],通过LDA 提取特征后,在使用SVM 进行处理具有良好的性能表现[15]。LDA的核心思想是:给定训练集,设法将训练样本投影到一个子空间中,并使得同类样本的投影尽可能接近,异类样本的投影尽可能分开,本文主要用于特征提取,最终拟定的特征值包括目标的位置、信噪比和多普勒频移。假设在M维空间中,则:
对于第i 个点迹,位置Loc=(xi,1,xi,2,xi,3,…,xi,M),在本文中针对的是2 维空间;信噪比SNR=,其中Psignal为信号功率,Pnoise为噪声功率;多普勒频移,其中v为移动台的速度,c 为电磁波传播速度,f 为载波频率,θ为移动台方向与入射波方向的夹角。
3.3 SVM数据处理
分类任务通常涉及将数据分离为训练集和测试集。训练集中的每个实例都包含一个类标签和几个特征变量。通过SVM 对数据进行处理,最终生成一个计算模型,通过该模型对测试数据的目标值进行预测。在本文的目标数据处理过程中,主要思想是通过算法处理点迹时,将航迹点数据视为正类(+1),杂波点迹视为负类(-1),在训练过程中当前时刻预测获取的数据集会作为新的训练集不断扩充旧的训练集,并通过自适应调整参数。
由于我们的数据集是线性不可分的,所以考虑引入核函数的方式进行处理,常用的核函数包括线性核、多项式核、高斯核以及拉普拉斯核。由于数据是满足高斯分布的,通过高斯核函数将数据从原始空间投影到更高维的特征空间,从而使得样本在这个空间内线性可分。高斯核的本质是在衡量样本与样本之间的相似度,让同类样本更好地聚在一起,进而线性可分。高斯核函数的计算公式如下:
4 仿真实验与结果分析
假设在[-1000,1000]×[-1000,1000](单位m)的二维空间中共有三个目标出现,并且空间中有杂波干扰。目标1 的初始状态为[250,250,0,0]T,目标2 的初始状态为[-250,-250,0,0]T,都是从k=1时刻开始运动,在k=100 时结束,在k=61 时刻由目标2 衍生出目标3。对于每一时刻的目标,考虑扩展目标的存在,即一个目标在一个时刻可以产生多个量测值,假设每个扩展目标的量测数目服从泊松分布。在本实验中目标的发现概率为0.99,存活概率为0.99。目标运动遵循线性高斯运动模型:
模型中的Fk和Hk分别是状态转移矩阵和观测矩阵,其中过程噪声和量测噪声全都服从均值为0 的高斯分布,协方差矩阵,其中过程噪声的标准差为δw=2,观测噪声的标准差为δe=20。采样间隔为1s,观测区域内的杂波服从泊松分布,其强度函数为κk(z)=λVu(z),其中杂波强度λ=2.5×10-4,观测区域的面积为V=4×106。仿真过程中,设定剪枝阈值Tth=10-5,合并门限U=4,高斯分布个数最大值为Jmax=100。
为了提升模型的数据分类性能,首先将数据进行归一化操作,然后将雷达接收到的数据不断增加到训练集中对其进行扩充,通过5 折交叉验证寻找最佳惩罚参数c 和RBF 核参数g,并进行自适应调整参数,如图1所示。
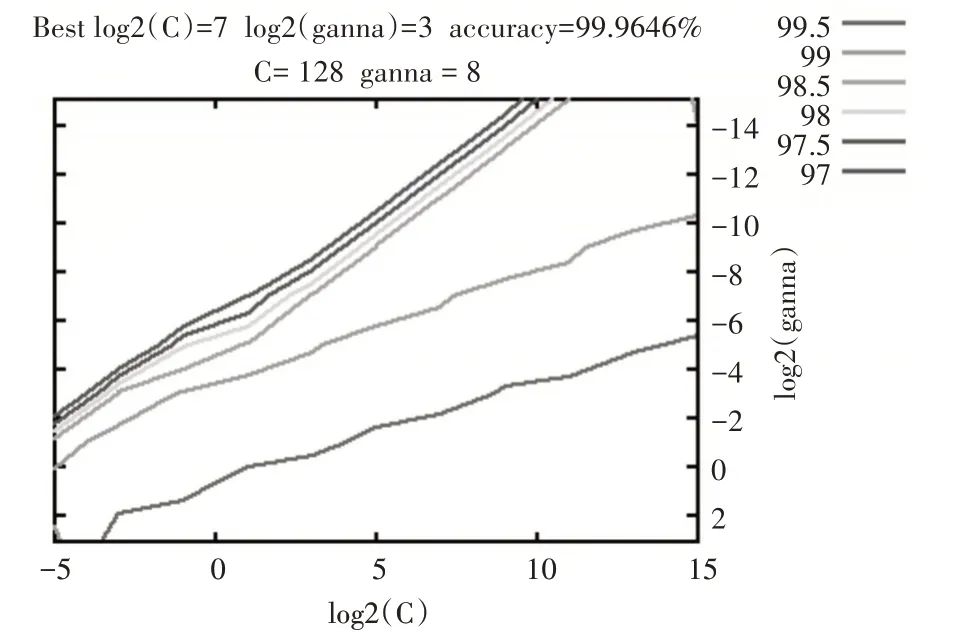
图1 交叉验证寻找最佳参数c、g
仿真结果如图2~图5 所示。图2 是目标量测与杂波量测的对比,图3是经过SVM 进行处理后保留的量测数据,图4是不使用SVM 进行处理直接使用GM-PHD算法对目标状态的估计情况,图5是使用SVM 进行处理后使用GM-PHD 算法对目标状态的估计情况。

图2 目标量测和杂波量测

图3 SVM处理后的量测数据
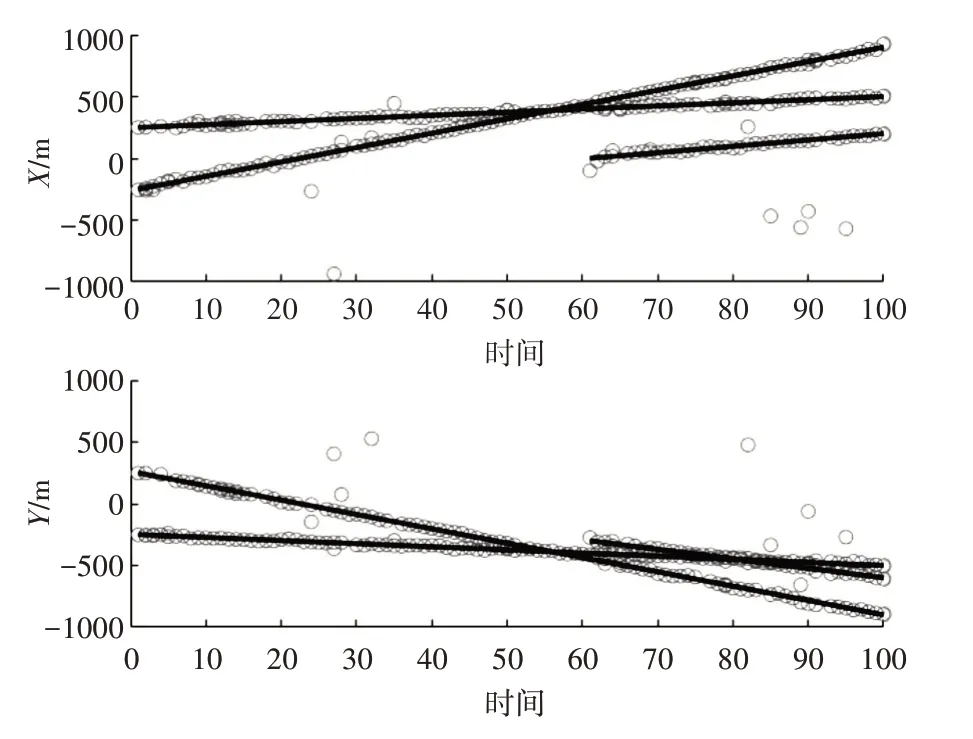
图4 直接使用GM-PHD算法处理结果

图5 通过SVM预处理后GM-PHD算法处理结果
从图2 和图3 可以看出,通过SVM 对观测数据进行处理后,能够有效地减少杂波的数量,同时保留绝大部分的目标点迹。图3 为通过SVM 处理后保留的量测数据集,在预测过程中,会将获取的预测值追加到训练集中进行训练,提高预测效果。
从图4和图5可以看出,在强杂波环境下,未经过SVM 处理的情况下,使用GM-PHD 进行航迹估计会出现较多的误差,相比之下,结合SVM 和GM-PHD 的方式,能够有效减少计算误差,并且由于目标点迹经过SVM 过滤后较完整地保存下来,因此对于目标轨迹估计的影响是非常小的。
表1是每一次使用SVM 进行估计时,预测的真实目标点迹数目占总的目标点迹数目的百分比以及将杂波点迹预测为目标点迹的数目占总的杂波点迹的百分比,我们使用TPR(Target Positive Rate)和CNR(Clutter Negative Rate)分别进行表示。同时我们定义有效的目标点迹为阳性,杂波点迹为阴性,对于每个点迹,我们定义TP表示正确分类的阳性个数,FP 为错误分类的阳性个数,TN 为正确分类的阴性个数,FN 为错误分类的阴性个数。则TPR和CNR可以表示为

表1 目标点迹预测成功率和杂波点迹预测失败率
从结果来看,通过SVM 进行处理后,能够保留大部分的目标数据并且只有很少一部分杂波被预测为目标点迹。表2 是在不同的杂波强度下不使用SVM 进行处理和使用SVM 进行处理后算法的平均运行时间,随着杂波强度的增长,算法的运行时间是在逐步增加的,但是通过SVM 处理后,杂波强度的增长对于算法性能的影响是比较小的。
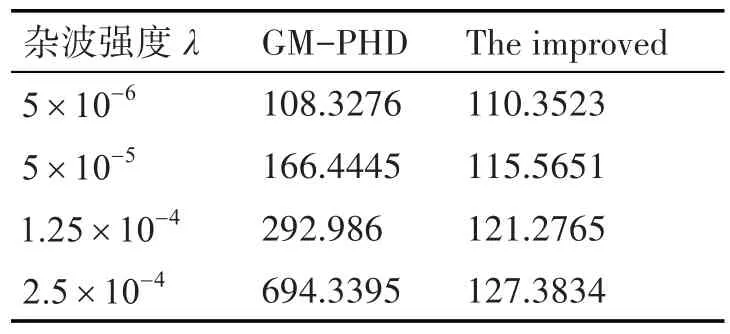
表2 平均运行时间/s
5 结语
针对雷达在高杂波环境下,处理目标点迹和跟踪目标性能下降的情况,本文提出了一种结合SVM和GM-PHD 的杂波过滤方法。结果表明,该方法能够有效地剔除杂波,同时对于目标数据能够完整地保留,提高了计算效率的同时,增加了计算精度。但是,我们的模型开始阶段需要采用带标签的样本进行训练,这需要耗费一定时间对训练样本进行标记。
