基于碳卫星与电力排放数据的碳计量
2024-01-19章政文顾津锦赵俊华黄建伟吴海峰文福拴
章政文,顾津锦,赵俊华,黄建伟,吴海峰,文福拴
(1.香港中文大学(深圳)理工学院,广东省深圳市 518100;2.悉尼大学电气与信息工程学院,悉尼 2006,澳大利亚;3.香港中文大学(深圳)高等金融研究院,广东省深圳市 518100;4.浙江大学电气工程学院,浙江省杭州市 310027)
0 引言
为了应对全球气候变化问题,巴黎协议要求其成员国减少温室气体的排放,并最终实现碳中和。为了实现这一目标,准确客观的碳计量至关重要。尽管现在有基于自行测算申报的碳计量系统,但仍然需要另一种独立的方式来辅助、补充和校验自行披露数据。
碳卫星利用卫星遥感技术进行大范围观测,可以得到准确、统一和客观的CO2柱平均干空气混合比(碳卫星观测到的区域内柱平均CO2浓度,简称碳浓度,后文用XCO2表示)数据。联合国政府间气候变化专门委员会(Intergovernmental Panel on Climate Change,IPCC)将碳浓度遥感观测列为碳排放清单估算的重要验证手段[1]。然而,如何准确地从碳卫星测量的碳浓度数据中提取人类活动产生的排放量数据仍然极具挑战。
碳源的碳排放行为可以通过碳卫星观测到的碳源附近区域的碳浓度数据来反映[2]。例如,排放大量CO2的电厂会使得周围区域的局部碳浓度产生明显的升高,这是因为电厂排放的大量CO2会通过大气传播扩散到附近区域。文献[3-7]使用高斯烟羽模型对CO2在大气中的传播建模,用以测量电厂或区域的碳排放量。文献[8-9]基于横截面通量法建立CO2传播模型,用于中国城市级的碳排放计量。由于碳卫星数据和环境数据自身质量偏低且大气扩散模型对噪声较为敏感,此类方法的精度还不足以支撑准确的碳计量。
目前,电厂的碳排放计量主要使用清单法。由于清单法使用的排放因子一般由长时间尺度的统计平均值得到,其与当前时刻当前环境下的电厂或燃料的排放因子有所差异。因此,仅基于清单法提供排放因子的碳计量往往不够精确[10-12]。电厂也可以通过安装连续烟气监测系统(continuous emission monitoring system,CEMS)实现高频率(小时级)和高精度的直接碳排放监测[13]。然而,由于CEMS 设备价格昂贵,为每个火力发电厂的烟囱配备这种设备的成本过高。因此,仍有必要研究一种成本较低的方法来计量电厂的直接碳排放。
碳卫星数据具有统一、范围大、可重复观测等优点。电力数据具有极高的数据采样频率和质量。基于现有碳卫星数据和电力数据的特性,本文结合两者来构建碳排放计量模型,构建该模型无须安装任何额外设备。为了实现这一目标,本文收集了美国高精度碳卫星数据、CEMS 实测的美国电力排放数据,以及反映大气中CO2运动情况的环境数据,并基于这3 种多模态数据的特性设计了全自动的数据处理算法。
深度学习由于其强大的数据表达能力已经成功应用于计算机视觉[14]、自然语言处理[15]和其他众多领域[16]。本研究使用深度学习算法来赋能碳计量领域,结合先进的人工智能算法,基于碳卫星数据和电力数据构建碳计量模型。实验结果表明,本文结合碳卫星、电力排放数据和人工智能算法的碳计量方法要远远优于仅基于碳卫星数据的现有碳计量方法。目前,针对中国电厂尚未大规模部署CEMS 的现状[17],本文所提碳排放计量方法在模型训练完成后,只需要基于输入的碳卫星数据和电力数据便可估算电厂的直接碳排放量,实现直接碳排放计量目标。
1 多模态数据源介绍
1.1 碳卫星数据
本文采用美国 OCO-2(Orbiting Carbon Observatory-2)碳卫星的数据(即L2 级数据)[18]。OCO-2 碳卫星具有高精度的温室气体探测能力,空间分辨率为1.3 km×2.2 km,时间分辨率为16 d。OCO-2 碳卫星L2 级数据由OCO-2 碳卫星观测的原始光谱数据经过大气校正、云检测和云影响校正、反演算法和数据筛选控制等步骤得到[18]。该产品提供了高质量的区域碳浓度和其他重要补充信息。为了后续构建深度学习模型并提取有效的碳卫星数据深度特征,选择了其中重要的几项信息,包括每个碳卫星扫描区域对应的XCO2、经纬度、XCO2质量标签、XCO2不确定性、太阳方位角和卫星方位角。中国的碳卫星TanSat[19]并未公布L2 级XCO2数据,所以未使用TanSat 的数据来进行可行性验证。
1.2 电力排放数据
本文采用美国国家环境保护局(Environmental Protection Agency,EPA)公布的安装CMES 的电厂数据[20]。这是因为美国电厂已经大量部署了CEMS 设备,同时这些设备已经运行了多年且提供公开数据。经过统计,其中总计有1 304 个装有CEMS 的美国电厂,并且提供了电厂的精确经纬度位置信息、小时级发电量和小时级碳排放量数据。
1.3 环境数据
除了电厂本身的排碳行为,CO2在大气中的运动也是决定电厂周围区域大气中碳浓度的关键因素。风速和风向与大气中CO2运动的关系非常密切,它们是影响CO2运动和转移的主要环境因素之一。因此,本文采用了欧洲中期天气预报中心(European Centre for Medium-range Weather Forecasts,ECMWF)公布的再分析ERA-5 数据的风速和风向数据,具体为在电厂周围区域高度10 m以下经纬度方向上的平均风速,该数据的空间分辨率为0.25°(经度)×0.25°(纬度)。
2 多模态数据处理方法
对数据经过分析和统计,发现多模态数据具有下列问题:1)碳卫星数据测得的XCO2有大概0.3%的偏差(约10-6);2)由于云层会严重干扰碳卫星的观测,约25%的碳卫星扫描区域XCO2数据缺失;3)XCO2数据中存在大量无效点;4)电力排放数据中CEMS 碳排放数据存在大量缺失值。本文基于多模态数据结构和上述数据问题设计了如图1 所示的全自动数据处理方法。该方法完全基于多模态数据的特性,没有任何额外的时间间隔要求和假设,具体包括3 步:基于排放源位置的数据匹配、基于统计信息的数据筛选和基于碳排放量与风速的数据筛选。
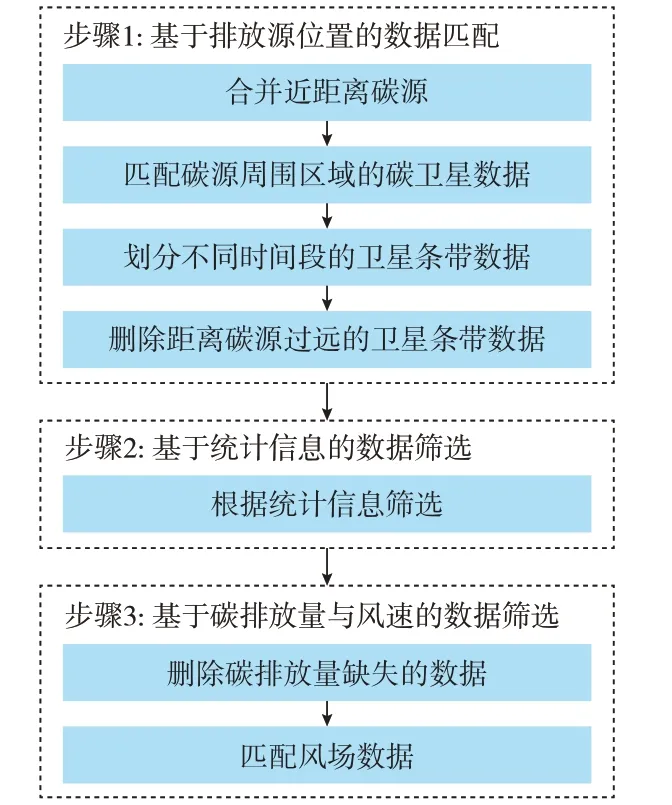
图1 多模态数据处理方法示意图Fig.1 Schematic diagram of multi-modal data processing method
2.1 基于排放源位置的数据匹配
首先,基于排放源的地理位置选择有效数据。根据碳卫星数据的空间分辨率,将距离过于接近的电厂合并为一个碳源(两个电厂之间的距离小于3 km,例如美国纽约州的某两个电厂仅相距0.7 km)。因此,本文中碳源的最小分辨率约为碳卫星的空间分辨率。合并后得到了1 245 个位置独立的碳源。以这些碳源的位置为中心匹配周围区域(1°(经度)×1°(纬度))内所有时间段的碳卫星数据。由于碳卫星的单次扫描区域呈条带状,所以将其称作“卫星条带”。再根据卫星扫描时间段的不同将这些卫星条带数据分离,得到63 931 个位置、时间匹配的碳源和卫星条带数据,即其中每个卫星条带作为碳卫星在碳源周围区域某个时刻扫描记录的条带状碳浓度数据。由于碳源的碳排放在大气中的传播造成的影响随距离而逐渐衰减,本文删除了碳源距离卫星条带最小距离超过40 km 的数据,总计得到46 179 条卫星条带数据。
2.2 基于统计信息的数据筛选
筛选出匹配后碳源附近的卫星条带记录区域数(卫星条带长度)大于200 的条带以确保其中包含有效信息。根据统计的卫星条带中XCO2值的分布,发现其中存在部分离群点,其XCO2值远远超过了平均值。因此,本文将这些条带也从数据集中删除。为了保证卫星条带数据周围的环境不要过于复杂,根据电厂周围区域(1°(经度)×1°(纬度))内的碳源个数,删去同个区域内超过10 个碳源的条带数据。最后,根据太阳方位角和卫星方位角删除了卫星条带宽度过窄的数据(小于8 km),最终得到10 930 个卫星条带数据。
2.3 基于碳排放量和风速的数据筛选
匹配卫星条带和对应的CEMS 数据,删除CEMS 小时级碳排放量缺失的数据。最后,与风速数据匹配,提取其中碳卫星观测区域和电厂位置下经纬度方向的风速数据。最终得到总计5 304 个卫星条带数据作为数据集。
3 基于多模态数据特性的深度学习模型
本文首先设计了符合此多模态数据特性的深度学习模型CarbonNet。由于碳卫星数据相较电力数据过于复杂的特性,本文提出了两步走的人工智能碳排放计量模型:1)基于无碳排标签的模型预训练方法用以提取碳卫星数据向量形式的深度特征;2)结合提取的深度特征和电力数据,使用线性回归方法防止过拟合[21],并学习碳排放估算模型。
3.1 深度学习模型设计
针对多模态数据的特性,本文提出了一种新型的深度网络结构CarbonNet。首先介绍碳卫星数据的数据编码方法。OCO-2 碳卫星观测所得的数据经过数据处理后得到电厂和对应卫星条带的数据集。其中,第j个卫星条带数据以向量组表示:
式中:j为数据集中卫星条带序号;i为在一段卫星条带中观测区域的序号;和分别为卫星条带中的第i个观测区域中心的经度和纬度坐标;xi为第i个观测区域的XCO2值;nj为第j个条带中卫星观测区域的个数,也就是该卫星条带的长度,本文中nj长度设置为200 至450 之间。
考虑到环境因素对碳卫星区域碳浓度数据的影响,本文将风速风向的信息也嵌入卫星条带的向量组中。条带中第i个观测区域10 m 下的平均风速为(ui,vi),其中,ui和vi分别为沿着经度和纬度方向的风速。在本文所提CarbonNet 方法中,将编码卫星条带中第i个观测区域数据的向量si称为条带形符(swath token),其表达式为:
因此,整个卫星条带为S'j=[s0,s1,…,snj]。由于每个卫星条带长度nj不同,为了方便后续训练网络,将每个向量组S'j都补充零向量直至最大长度N(在本文中,N=450),表达式为:
同时,将卫星条带j对应碳源的信息以相同的形式编码为碳源形符(source token)Pj,表达式为:
因为碳源j的地理位置在绝大多数情况下不直接位于卫星条带数据上,所以将碳源位置的碳浓度统一设为0。
如图2 所示,最终将碳源形符和条带形符堆叠为CarbonNet 网络的输入,即输入形符Sj为:
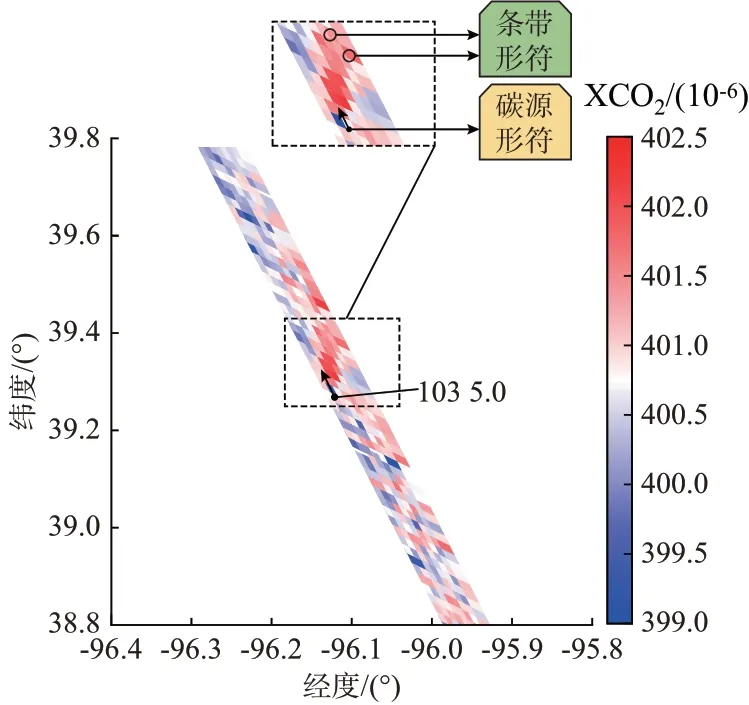
图2 卫星条带数据编码Fig.2 Data coding of satellite strip
CarbonNet 的详细网络结构如附录A 图A1 所示。已知网络输入条带S,经过一个全连接的嵌入层E(·)得到特征F0为:
网络最终提取的深度特征FDF为:
式中:HDF(·)为深度特征提取模块,由K个基于自注意力机制的残差模块H(·)[22]组成。具体而言,中间特征F1、F2、…、FK是由残差模块逐步迭代得到的Fk=Hk(Fk-1),其中,Hk(·)为第k个残差模块,FK=[f0,f1,…,fN]为网络最后的第K个深度特征提取模块的输出,f0、f1、…、fN为相同维度的向量。
为了降低深度特征的维度,本文取中间特征FK在特征维度上的平均值为模型最终提取的深度特征FDF:
式中:FDF为长度等于特征维度的特征向量;c为特征的维度。
3.2 无碳排标签的模型预训练方法
模型预训练方法的目的是提取多模态数据中能够帮助后续碳排放估算的特征表达。模型预训练方法通过在输入过程中随机丢弃部分卫星条带数据,要求网络学习恢复完整卫星条带数据。上述模型预训练方法在训练阶段仅依赖于卫星条带数据,而未使用碳排放标签,因此被称为无碳排放标签的模型预训练方法。
无碳排放标签的模型预训练方法如图3 所示,以置零概率(又称为掩膜率)为ρ∈[0,1]的条件下,随机生成一个二进制掩膜M。该掩膜是一个输入数据长度相同的二进制向量,这个掩膜向量中0 元素的概率为置零概率ρ,1 元素的概率为1-ρ。
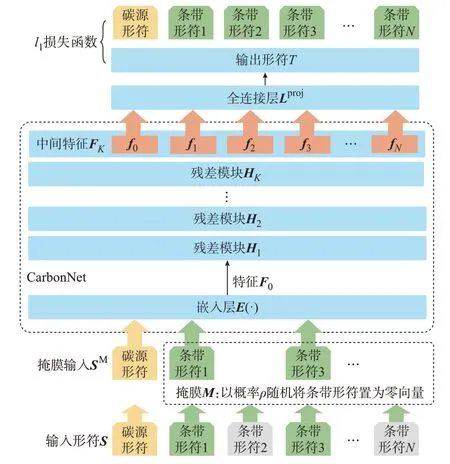
图3 无碳排标签的模型预训练方法Fig.3 Model pre-training method without carbon emission labels
使用二进制掩膜M乘输入S得到掩膜输入SM:
条带数据S中的掩膜向量中0 的位置对应的输入将被置为零向量,相当于部分碳卫星条带数据在预训练输入时被遮挡了,这部分信息没有输入网络中。 对于OCO-2 碳卫星数据,设置掩膜率ρ=25%。将掩膜输入SM输入,通过CarbonNet 得到中间特征FK。再使用另一个全连接层Lproj(·)将维度为c的中间特征FK映射回原来的5 维特征的输出形符:
式中:Wproj和Bproj分别为全连接层的权重和偏差。
在预训练阶段,将掩膜数据SM输入网络中,得到 输 出 形 符T=(Lproj(FK),HK,HK-1,…,H1,E(S))。本文使用l1损失函数来优化模型输出的输出形符T和未掩膜的输入S的距离。掩膜预训练使得模型能够基于部分卫星条带的信息恢复完整的条带信息。无需对应的碳排放量标签,CarbonNet 仍然能够学习从碳卫星掩膜数据中重建缺失的信息以及提取高质量的深度特征FDF。在预训练完成后,舍弃最后的全连接层Lproj(·),并保留网络的其他部分用于特征提取。在本文中,预训练好的模型最后提取的深度特征为长度256 的向量。模型预训练要求模型学习重建遮挡部分的数据,可以有效地应对碳卫星碳浓度数据存在大量缺失值这一现象,充分利用了碳卫星数据的特性。
3.3 基于碳排放标签数据的线性回归方法
首先,将训练好的预训练模型参数固定;然后,输入多模态数据得到其深度特征。结合提取的深度特征和电力排放数据中的小时级发电数据作为输入,并将对应的CEMS 小时级碳排放标签数据作为标签。所提取的深度特征维度为256,而电力排放数据中的小时级发电数据为一维,两个特征维度相差较大。因此,本文采用线性回归模型来进行监督学习,用于防止产生过拟合问题,并最终估算电厂的小时级碳排放量。
基于碳排放标签数据的线性回归方法如附录A图A2 所示。基于预训练完成的CarbonNet,固定其模型参数,提取所有带标签数据的深度特征为:

设第j个卫星条带提取的CEMS 发电厂的发电数据为Gj l。结合提取的深度特征和发电数据作为线性回归模型的输入Ij=[],模型的输出为估算的碳排放量ej:
式中:We为线性权重;Be为偏差。
4 算例及结果分析
4.1 模型预训练方法的结果
使用所有多模态处理后的5 304 个样本进行无碳排标签的预训练。模型预训练优化方法为Adam方法[23],本文中设置批量大小为64,初始学习率为0.000 5,指数衰减率控制因子β1和β2分别为0.90 和0.99,优化最大迭代次数为100 000,学习率在60 000 和80 000 次迭代时下降为原来的50%。模型预训练时,l1损失随着训练迭代次数的收敛情况如附录B 图B1 所示。图中:l1损失在前20 000 次迭代后较训练开始时大幅下降,且在80 000 次迭代后趋于平稳。这个变化趋势说明预训练模型确实学习了利用部分碳卫星条带信息重建出完整的条带信息。
预训练模型在测试集上的可视化案例如图4 所示。图中:横轴代表经度坐标,纵轴代表纬度坐标;卫星条带由许多四边形小区域组成,每个四边形小区域代表碳卫星的最小扫描区域单元,这些区域的颜色表示区域对应的XCO2值(单位为10-6)。
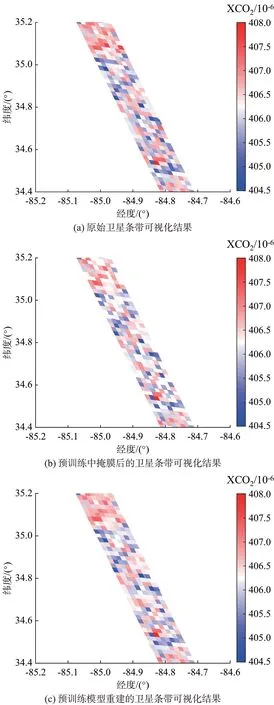
图4 预训练模型在测试集上的可视化案例Fig.4 Visualization cases of pre-training model on test set
图4(a)为原始卫星条带的可视化结果,图4(b)为经过掩膜处理后的卫星条带可视化结果,图4(c)为预训练模型重建的卫星条带可视化结果。通过比较图4(a)和图4(b),可以观察到掩膜输入确实导致了部分原始卫星条带信息的丢失。然而,通过对比图4(a)与图4(c)发现,预训练模型在很大程度上成功地重建了掩膜后卫星条带所缺失的信息。因此,可以从预训练好的网络中提取卫星条带数据的深度特征,这些特征可被用于重建卫星条带的丢失信息。进一步的实验证明,所提取的深度特征能够与电力数据相结合,从而实现对电厂碳排放的估算。这为在实际应用中监测和计量碳排放提供了有力支持。
4.2 线性回归估算碳排值的结果
首先,将多模态处理后的5 304 个样本中随机抽取1 060 个样本作为测试集,其他样本用于有监督训练。结合预训练模型所提取的碳卫星数据深度特征和电力数据,使用碳排放标签监督学习线性回归模型后,本文选择了统计学中常用的4 个指标来衡量回归效果的好坏。其中,R2为1 减去残差平方和与总平方和的比值,越接近1 表示回归模型效果越好。均方根误差(RMSE)可以衡量观测值同真值之间的偏差,其值越小表示估算值和真实值的偏差越小。本文还采用了衡量二者相关性的斯皮尔曼秩相关系数(SRCC)和皮尔逊线性相关系数(PLCC)作为指标。其中,SRCC 为非线性相关系数,可以衡量任意两个变量相关性强度,PLCC 为线性相关系数,更适合衡量两个变量之间的线性相关性。本文通过同时计算深度学习模型给出的碳排放估算值和CEMS碳排放标签间的SRCC 和PLCC 值,希望从相关性强度和线性相关性两个层面来描述模型估算值和标签值的相关程度,更全面地评价碳排放计量模型效果的好坏。SRCC 和PLCC 取值范围都在0 到1 之间,值越高代表模型的估算值与真实值的相关性越强。
结合碳卫星数据和发电量数据构建的回归模型定量指标结果如表1 所示。该模型R2值为0.831,表明模型解释了1 060 个测试样本中电厂碳排放量的83.1%。RMSE 的值为194.1,表明平均碳排放量误差为194.1 t。SRCC 和PLCC 的值分别为0.906 8 和0.911 6,表明模型估算的碳排放量和CEMS 实测的碳排放量之间具有良好的相关性。

表1 回归模型定量指标结果Table 1 Results of quantitative indices of regression model
在测试集上,CEMS 和模型估算的碳排放量如图5 所示。从图中可以直观地看出,拟合线性度较高,模型估算的碳排放量与真实排放量具有较为明显的线性关系。
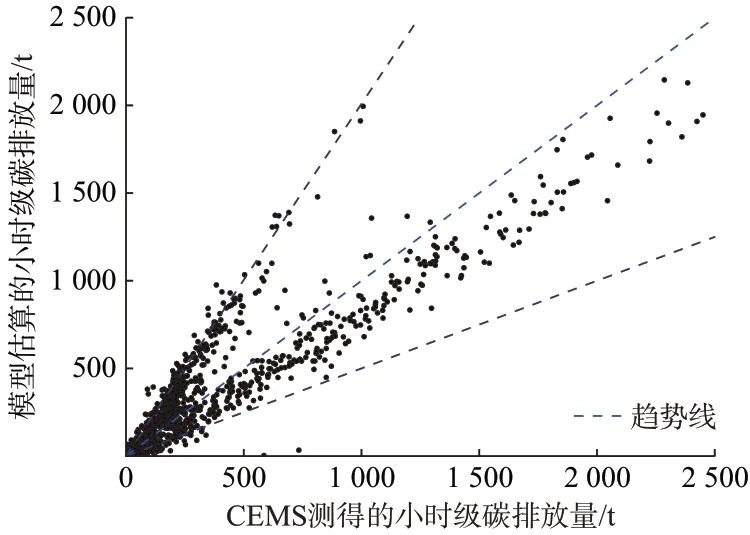
图5 CEMS 和模型估算的碳排放量Fig.5 Carbon emissions from CEMS and model estimation
4.3 对比仅基于碳卫星数据的现有碳计量方法
本节旨在比较所提出的碳计量方法和现有仅基于碳卫星数据和高斯烟羽模型的碳计量方法。由于碳卫星数据和环境数据质量偏低,且基于高斯烟羽模型的碳计量方法容易受到噪声数据的干扰,现有研究往往需要使用比较严格的数据筛选算法,所以适用的多模态数据总量要远远少于本文提出的数据处理方法。此外,本文构建的碳排放计量模型结合了碳卫星数据和电力排放数据,充分发挥了电力数据的优势,有效提高了碳卫星数据的利用率。
为了公平比较,本文参照文献[4]筛选出116 个符合条件的碳卫星条带数据及其相应的环境数据。这些数据将作为测试数据用于对比实验。同时,本文也从所提数据处理方法得到的5 304 个数据中删除了这些样本,使用其余数据作为训练数据进行监督学习,拟合线性回归模型。
实验结果如表2、附录B 图B2 和图B3 所示。可以直观地看出,本文提出的碳排放计量模型在定量指标和趋势方面均有明显优势。综上所述,结合电力排放数据可有效提高碳卫星数据的利用率,同时提高碳排放计量的准确性与可靠性,这对于制定有效的碳减排政策和缓解气候变化具有重要意义。
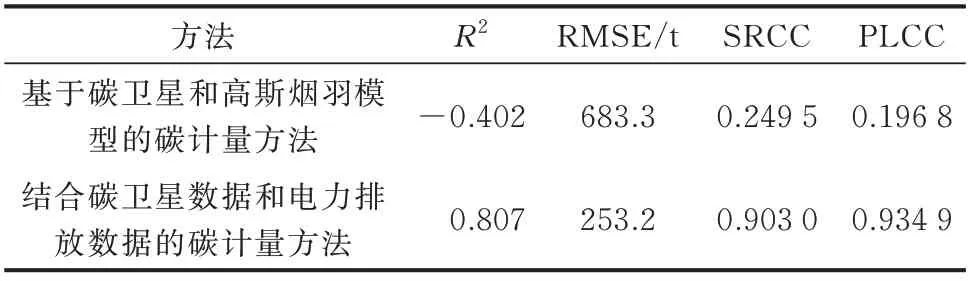
表2 定量指标结果Table 2 Results of quantitative indices
此外,本文以单颗碳卫星数据为基础进行实验验证。然而,本文提出的方法可以轻易泛化至其他碳卫星上构建碳排放计量模型。理论上,利用多颗碳卫星的数据可以将碳排放计量频率提高数倍。未来,随着具有更高时空分辨率的碳卫星的发射,如欧洲航天局计划于2024 年发射的碳卫星CO2M[24]和美国航空航天局计划于2025 年发射的碳卫星GeoCARB[25],基于下一代碳卫星发布的更高频率和更高分辨率的碳浓度数据,可以借助本文所提方法,实现更高精度和频率的碳排放计量。
5 结语
本文结合了碳卫星与电力排放数据,提出一种新的人工智能方法以实现发电厂碳排放计量。首先,提出了多模态的数据处理算法,用于碳卫星数据、电力数据和环境数据的匹配和筛选,以得到有效的多模态数据。然后,提出了针对此多模态数据特性的新型深度模型CarbonNet,以及无碳排放标签的模型预训练方法,以提取碳卫星数据的深度特征。最后,结合预训练模型提取的深度特征和电力数据进行监督学习,最终实现了碳排放计量模型。实验结果表明,结合碳卫星数据和电力数据构建的碳排放计量模型可以有效提高碳卫星数据的利用率,同时,能够取得更准确的碳计量结果。这将为后续碳市场的运作,减碳政策的制定、企业的低碳转型、气候变化的应对等提供帮助。
本研究未考虑火力发电厂排放中其他碳化合物的影响,这主要是因为当前的碳卫星仅配备有CO2探测仪器[18-19,26]。然而,在未来其他国家将发射搭载不同气体监测设备的碳卫星。例如,碳卫星GeoCARB 将额外配备CO 探测仪。因此,本研究所提出的方法也可以帮助未来研究基于新型碳卫星对其他碳化合物排放的计量。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
