融合协同过滤的神经Bandits推荐算法
2024-01-17张婷婷欧阳丹彤孙成林白洪涛
张婷婷, 欧阳丹彤, 孙成林, 白洪涛
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012;3. 吉林大学白求恩第一医院 内分泌与代谢科, 长春 130021)
随着互联网经济的迅速发展, 每天都有海量信息呈现在人们眼前. 对于电子商务、 视频、 音乐、 新闻等平台, 促进用户消费以将其提供的内容或物品转化为价值至关重要. 对于用户, 打开某平台就能快速找到自己感兴趣的内容, 降低搜寻信息成本, 是一种基本需求. 基于此, 针对个性化推荐[1]的研究备受关注.
协同过滤[2-4]作为最常用的传统推荐算法, 通过群体中个体的行为特征找出一组与目标用户相似的邻居用户, 并利用这种相似性进行推荐, 通过持续的协同作用, 可获得越来越精准的推荐效果. 但协同过滤算法自身存在一些不足, 即稀疏性[5-6]和冷启动问题[7-8]. 在实际推荐场景中, 用户和物品规模非常庞大, 用户通常只对小部分物品有涉猎(评分), 大部分用户之间没有相同评分项或相同评分项很少, 这种数据的稀疏性限制了用户间相似性的计算, 即使可计算, 可靠性也难以保证. 冷启动问题本质上也是数据稀疏问题的一种极端表现, 即当新用户进入推荐系统后, 由于其提供的评分信息有限, 因此系统难以找到相似用户从而进行协同推荐. 新物品同理, 由于用户都未对其进行评分, 因此即使确定了相似用户, 也无法获知这些用户对新物品的评分情况.
除对上述问题的考虑, 推荐系统还应尽可能兼顾推荐的多样性和广度, 即探索-利用(exploration and exploitation)问题. 利用表示对于已知用户感兴趣的物品要尽力迎合, 探索则表示推荐给用户其未涉猎过的物品以探索其新兴趣. 多臂老虎机(multi-armed Bandit)算法[9]是强化学习领域的一个解决探索-利用问题的有效方法, 可在每轮推荐中平衡探索与利用的关系.
在多臂老虎机算法中, 每轮向用户呈现一组物品, 通过一定策略选择一个物品并获得相应奖励, 问题的目标是最大化累计奖励. 传统的多臂老虎机算法未考虑用户和物品特征, 且对不同用户均采用相同的推荐策略. 为更好利用内容(物品)和用户信息使其适应个人用户, LinUCB算法[10]将新闻的个性化推荐建模为上下文多臂老虎机问题, 并基于上下文信息计算预期奖励为用户进行推荐, 同时根据用户反馈调整选择策略. 但LinUCB算法假设上下文与奖励呈线性关系, 这种假设在现实世界中可能并不正确[11]. 为学习非线性奖励函数, NeuralUCB算法[12]利用深度神经网络的强大表示能力学习潜在奖励函数, 并采用UCB(upper confidence bound)算法选择臂. 不同于NerualUCB算法, EE-Net[13]舍弃UCB算法, 采用了一种新的神经探索策略, 利用神经网络学习与奖励估计相比的潜在增益.
基于上下文的多臂老虎机算法充分适应了用户的个性化需求, 但未考虑相似用户在推荐中的重要性. 针对该问题, 已出现一些融合协同过滤与上下文多臂老虎机算法的研究[14-16]. 文献[14]基于目标物品动态地对用户聚类, 在推荐时进行集体决策, 并根据反馈调整用户聚类, 但用户聚类在物品间是独立的, 针对不同物品需分别计算, 在用户和物品规模较大时无法保证实时推荐; 文献[16]在LinUCB算法基础上加入相似用户的协同作用, 并利用当前用户与选定用户的相似性控制协同强度, 但受限于LinUCB算法对线性奖励函数的假设, 无法很好适应非线性奖励的情况.
本文基于上述研究, 提出一种融合协同过滤的神经Bandits推荐算法(collaborative exploration-exploitation net, COEENet), 该算法采用深度神经网络学习潜在奖励函数, 并采用探索神经网络学习与奖励估计相比的潜在增益, 同时引入协同作用, 利用用户特征及历史行为寻找与当前用户相似的邻居用户, 进而对目标物品进行集体决策. 最后在实验中, 从食谱数据集中构建用户、 菜品特征, 采用COEENet为用户选择菜品进行推荐, 并从累积遗憾角度与其他基线算法进行对比, 验证了本文算法的有效性.
1 预备知识
1.1 基于用户的协同过滤
假设推荐系统中存在用户集合U和物品集合I, 用户和物品分别表示为ui(i=1,2,…,n)和ij(j=1,2,…,m), scorei,j表示用户i对物品j的评分情况.在每次推荐前, 对每个候选物品j, 采用余弦相似度计算当前用户与其他用户的相似程度simi,j:

(1)
根据所有用户u∈U对目标物品的评分情况, 计算当前用户ui对目标物品的喜爱程度:

(2)
其中rt,j表示奖励.通过计算当前用户对物品集中每个物品的喜爱程度, 可对物品进行降序排列, 选取评分最高的N个物品进行推荐.
1.2 通用上下文多臂老虎机框架
在上下文多臂老虎机算法中, 若已知推荐总轮数T[10], 则在第t(t=1,2,…,T)轮推荐过程中进行如下操作:
1) 算法观察用户特征ut并呈现给用户一组可供选择的臂At及它们的特征向量xt,a, 该特征向量结合了用户特征和臂的特征, 这里称为上下文;
2) 根据一定的选择策略, 为用户选择臂at∈At, 并获得真实世界中的实时反馈(奖励)rt,at;
3) 算法使用新的观测值(xt,a,at,rt,at)改进选择策略.
根据选择策略的不同, 奖励估计函数也不同, 但可以概括为
pt,at=h(xt,at)+ηt,at,
(3)
其中:h(xt,at)表示第t轮中用户ut选择臂at的潜在奖励, 该函数可能是线性的, 也可能是非线性的;ηt,at表示E(ηt,at)=0的噪声参数.T轮累积遗憾定义为
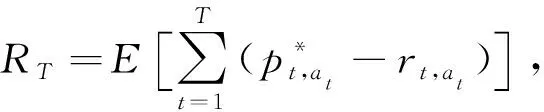
(4)

2 算法设计
算法1COEENet.
输入: 用户集合U={u1,u2,…,un}; 臂集合A={x1,x2,…,xm}; 推荐轮数T; 3个网络的迭代次数T1,T2,T3; 邻居用户数M; 3个网络的学习率η1,η2,η3;
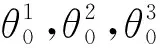
步骤1) fort=1,2,…,Tdo
步骤2) for eachxt,iinAdo
步骤6) end for

步骤8) 选择xt并观察真实世界奖励rt
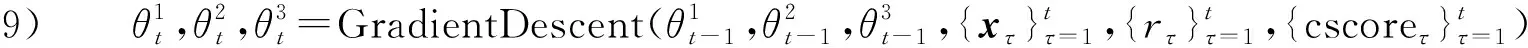
步骤10) end for
步骤12) for eachujinUdo
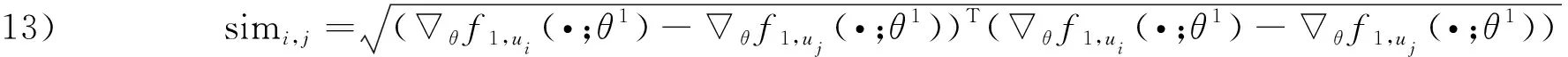
步骤14) end for
步骤15) Negi={ }
步骤16) 选择Top-M用户加入Negi

步骤18) return cscorei.
算法1包含4部分: 第一部分为利用网络, 用于估计预期奖励; 第二部分为探索网络, 用于学习与奖励估计相比的潜在增益; 第三部分为协同过滤模块, 用于计算相似用户的协同作用; 第四部分为决策器, 用于将前三部分的输出适当结合, 从而进行最终决策. 图1为网络整体结构, 表1对网络结构中各部分的输入、 输出进行了具体说明, 算法1中GradientDescent为梯度下降算法.

表1 COEENet网络结构信息
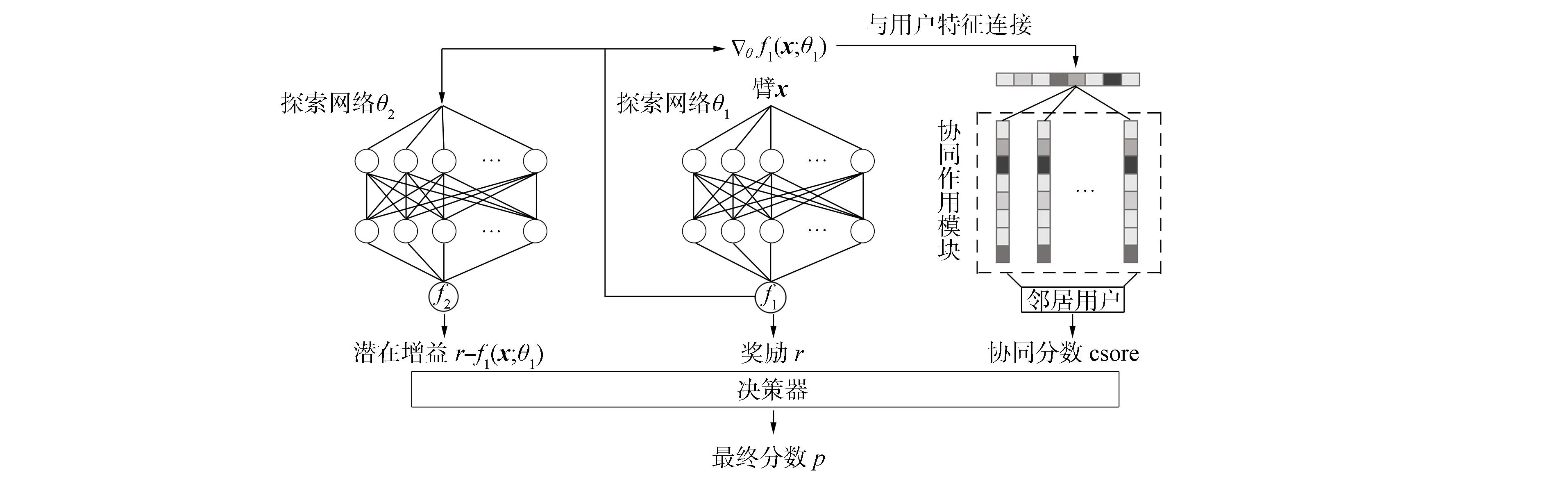
图1 COEENet网络结构Fig.1 Structure of COEENet
2.1 利用网络
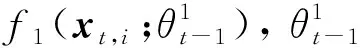
2.2 探索网络


(5)
设yt,i=|rt,i-f1(xt,i)|, 当yt,i很大时, 表示当前臂的收益估计与实际收益相差较大, 算法更倾向于赋予该臂更大的奖励值, 使其有更大概率进行探索; 当yt,i很小时, 表示当前臂的收益估计已接近实际收益, 算法会尽量避免探索该臂.

2.3 协同过滤模块
在推荐场景中, 为每个用户u∈U, |U|=n构建探索和利用网络, 并对利用网络最后一次更新的参数梯度θf1,ui(·;θ1,i)进行保存.对于用户ui, 在第t轮推荐中, 利用不同用户在利用网络上的参数梯度计算相似度.采用欧氏距离衡量相似度, 公式如下:
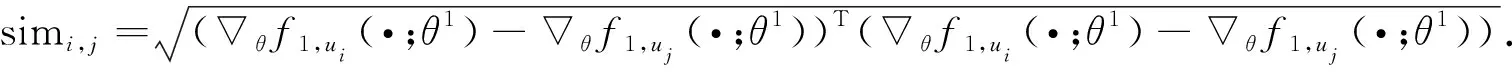
(6)
选取相似度最高的M个用户加入邻居用户集Negi, 用户uj对目标物品xt的协同分数cscorei,j定义为目标物品在该用户利用和探索网络的输出之和与该用户和当前用户ui的相似度乘积, 用公式表示为
cscorei,j=simi,j×(f1,uj(xt;θ1,j)+f2,uj(θf1,uj(·;θ1);θ2,j)).
(7)
当前用户ui的协同分数定义为其所有邻居用户的协同分数之和, 计算公式为

(8)
2.4 决策器

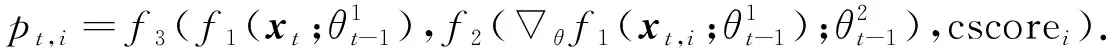
(9)
对于第t轮中提供的m个臂xt,i∈At,i∈[m], 选择其中分数最高的一个臂, 选择策略表示为

(10)
可采用神经网络对f1,f2,cscorei进行拟合, 同时基于不同推荐场景对探索利用的不同倾向性和对协同过滤强度的弹性控制而需要手动设置f1,f2,cscorei权重的现实需求, 本文将分别考虑决策函数为线性和非线性的情况.
1) 线性决策函数:f3定义为关于f1,f2,cscorei的线性函数, 表示为
pt,i=αf1+βf2+γcscorei,
(11)
其中α,β,γ作为权重参数, 由使用者自行设置.

3 实 验
本文在真实数据集上模拟推荐过程, 并与其他基线算法进行比较, 以验证本文算法COEENet的有效性. 采用l轮内的累积遗憾作为评价指标, 实验结果表明, 在食物推荐问题中, 本文算法较其他算法性能有一定提升.
3.1 数据集
本文在食谱网站爬取3 526名用户信息, 以及这些用户在过去一段时间内对菜品的评分情况共340 734条, 并收集了评分中所涉及的共9 766道菜品的信息. 用户信息包含id、 性别、 年龄、 地址、 自定义喜好等信息, 菜品信息包含id、 名称、 烹饪工艺(炒、 蒸、 煎、 炸等)、 难易程度、 口味等信息. 评分情况定义为(用户id,菜品id,评分)的三元组形式, 其中评分包含极差、 差、 一般、 推荐、 非常推荐5个等级.
由于菜品集中存在大量菜品仅有极少数用户对其进行评分, 而且用户群体在这些菜品上的评分大概率无法覆盖每个评价等级, 从而影响数据平衡性. 因此, 本文首先对菜品热度按照评分数量进行排序, 选择前1 000道热门菜品加入菜品数据集dish.dat, 同时将为这些菜品打分的2 871位用户加入用户数据集user.dat, 并收集这些用户对菜品的打分信息加入评分数据集rating.dat.
3.2 特征构建
每个用户由100多个分类的原始特征向量表示, 其中包含: 1) 用户基本信息, id、 性别(二类)、 年龄(离散为7个等级); 2) 地理特征, 主要分布于中国各地100多个城市及地区; 3)用户自定义喜好信息, 主要包括甜、 辣、 麻等14种分类. 菜品同理, 每个菜品都以相同方式构建约1 000个分类的原始特征向量表示, 其中包含: 1) 菜品基本信息, id、 烹饪工艺、 难易程度等; 2) 用户评价标签, 由用户历史评价数据中抽取得到的约1 000个标签表示. 本文将用户和菜品特征编码为固定长度的二进制向量, 用户和菜品的特征分别由156个和1 153个条目的特征向量表示.
本文方法为所有用户单独构建模型进行个性化推荐, 算法中的上下文信息只需对菜品信息进行表征而无需包含用户自身信息, 故用户对菜品的评分信息定义为(用户id, 菜品特征, 评分)的形式, 其中一条数据表示用户与系统的一次交互. 由于大部分用户的评分记录数较少, 无法支持独立训练模型, 因此本文对用户采用K-Means方法[18-19]进行聚类, 进一步将用户规模缩减至20大类, 以该类别中所有用户的特征均值作为该类用户特征.
3.3 离线模拟在线推荐
在线推荐模型将预期收益最高的前若干物品展示给用户, 并基于用户的实时反馈调整模型参数, 使其在后续推荐中逐渐适应用户需求. 由于无法实时获得用户的反馈信息, 因此本文将在上述离线数据集上模拟在线推荐过程, 验证本文算法的推荐效果. 通过数据集中用户对菜品的评分信息模拟用户和菜品之间的交互情况, 在利用网络和探索网络中, 评分可作为用户对相应菜品的实时奖励, 在决策器中, 设定评分不超过3时表示奖励为0, 否则奖励为1. 在每轮中, 随机向用户展示10道菜品, 其中包含9道评分不超过3的菜品以及1道评分大于等于3的菜品, 每道菜品对应的上下文为当前菜品的特征向量.
3.4 基线算法
为更好地评估本文算法在推荐问题中的性能, 本文选择4种算法作为基线算法, 分别是LinUCB,NeuralUCB,Neural-Epsilon和EE-Net.
1) LinUCB: 假设奖励函数为关于上下文的线性函数, 并采用岭回归和置信上界算法共同确定所选臂.
2) NeuralUCB: 使用神经网络学习奖励函数, 并采用置信上界算法选择臂.
3) Neural-Epsilon: 使用神经网络学习奖励函数, 以1-ε的概率选择当前与其奖励最大的臂, 并以ε的概率进行探索.
4) EE-Net: 用一个神经网络学习奖励函数, 用另一个神经网络学习潜在的奖励增益, 并结合两个网络的输出共同决策.
3.5 评价指标
本文采用T轮推荐内的累积遗憾作为算法评价指标, 计算公式为

(12)

3.6 实验结果分析
利用网络结构定义为一个二层的神经网络, 隐藏层节点数为100.探索网络结构为二层神经网络, 其隐藏层节点数也为100.在协同过滤模块中, 考虑当前用户的3个邻居用户的协同作用.线性决策器公式为
pt,i=f1+f2+r×cscorei,
其中利用网络输出f1和探索网络输出f2的权值均为1以模拟UCB策略, 并通过调节协同作用强度r调整邻居用户评分cscorei对最终推荐的影响. 非线性决策器定义为二层神经网络, 隐藏层节点数为50.
图2和图3分别为决策器是线性和非线性情况下的累积遗憾比较结果. 由图2和图3可见, 本文算法COEENet在recipe数据集上的性能优于基线算法. 由于食谱数据集中上下文与奖励预期并不是简单的线性关系, 故LinUCB算法在该问题中并不适用. NeuralUCB和Neural-Epsilon算法使用神经网络学习奖励预期, EE-Net算法采用一个神经网络学习奖励预期, 并采用另一个神经网络学习潜在增益, 三者都能较好适应非线性奖励函数的情况. 本文算法在很好拟合非线性函数的同时考虑邻居用户的协同作用, 进一步提升了推荐效果, 且对于线性决策器, 随协同强度增加, 推荐效果有一定提升.
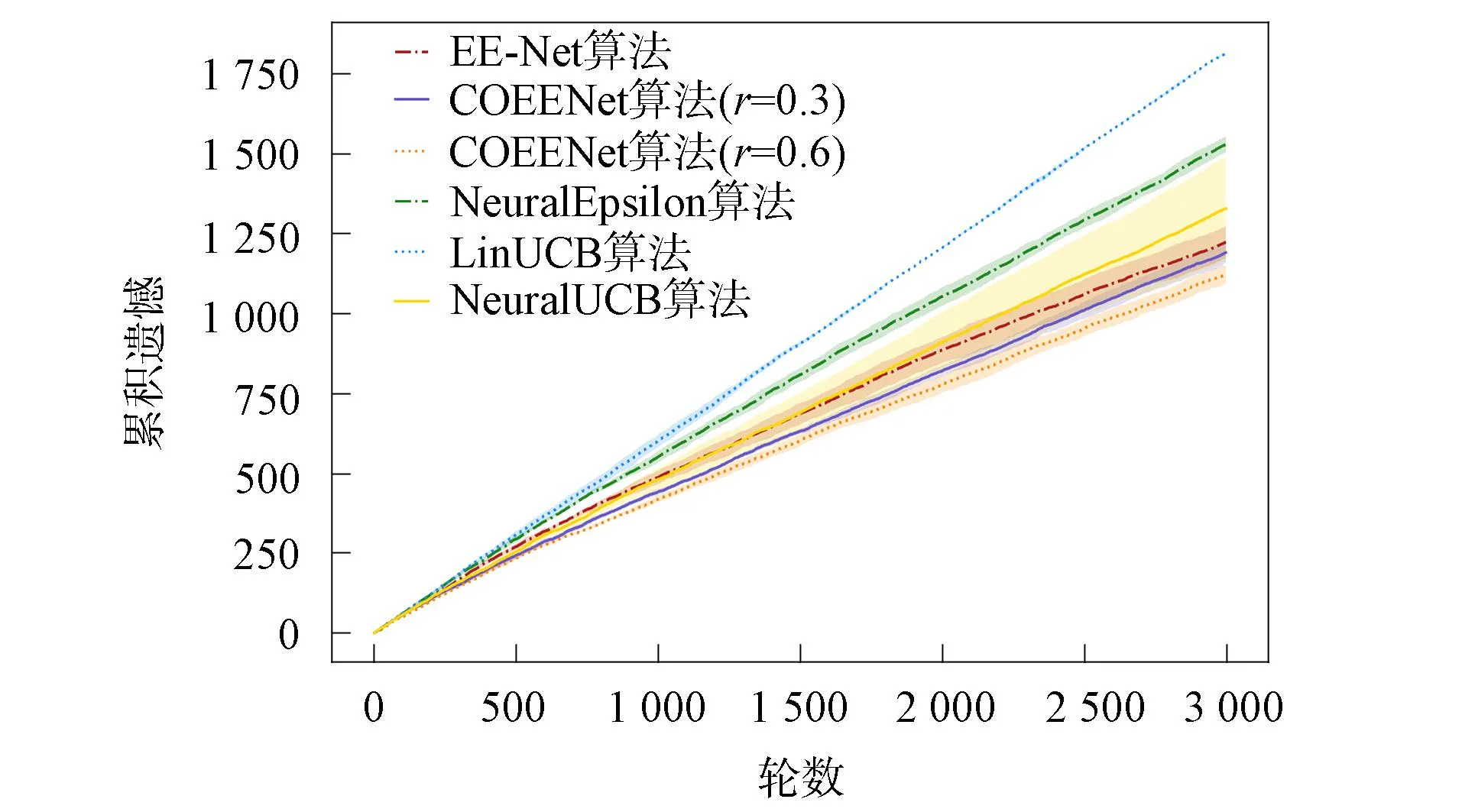
图2 线性决策器在食谱数据集上的累积遗憾比较Fig.2 Cumulative regret comparison of linear decision-maker on recipe datasets
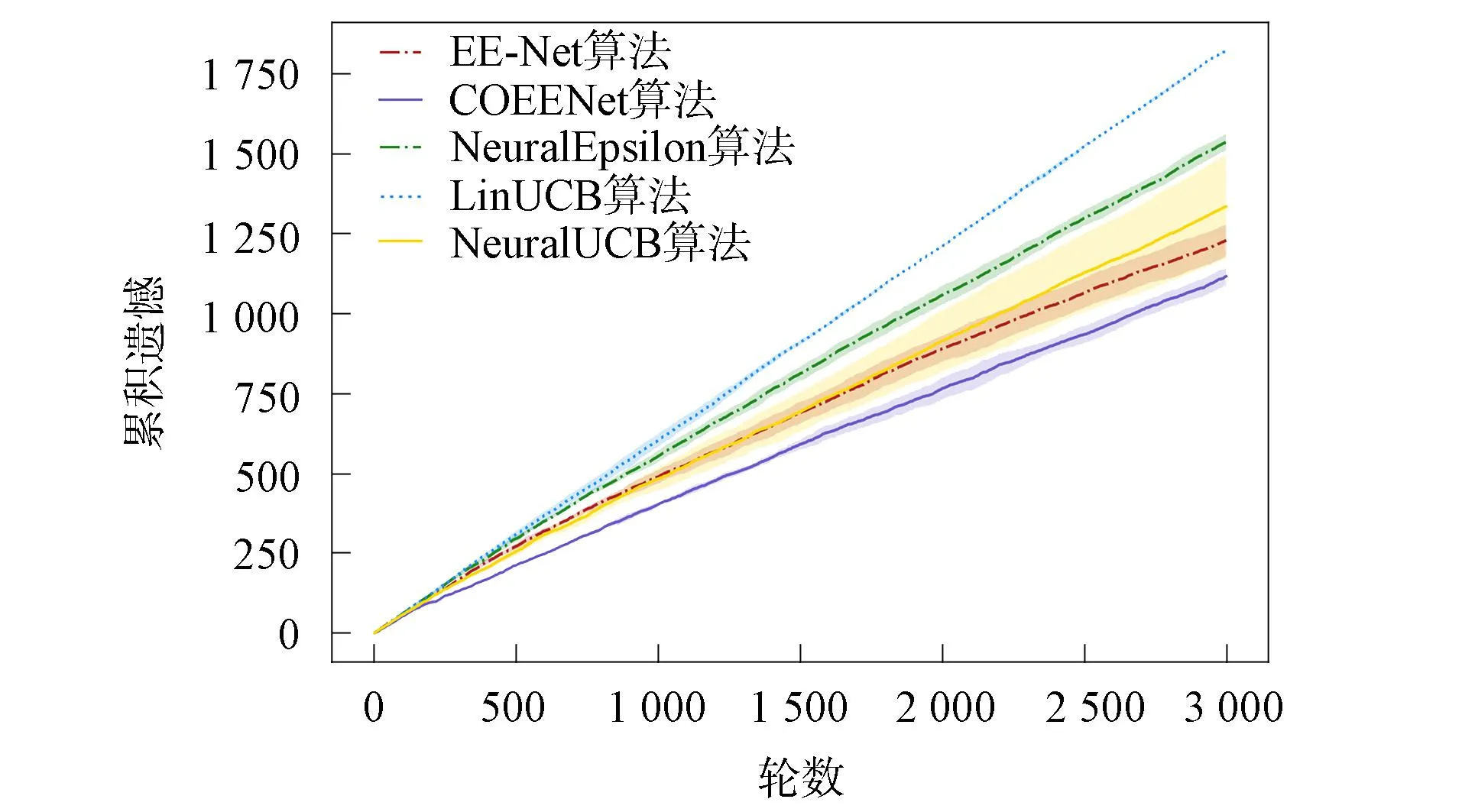
图3 非线性决策器在食谱数据集上的累积遗憾比较Fig.3 Cumulative regret comparison of nonlinear decision-maker on recipe datasets
综上所述, 本文针对推荐系统中用户和物品频繁变动导致的数据稀疏和“冷启动”限制了传统协同过滤的发展及现有考虑到协同作用的多臂老虎机算法并不适用于非线性奖励函数场景的问题, 提出了一种融合协同过滤的神经Bandits算法COEENet, 采用利用网络学习关于用户和物品特征的奖励函数, 采用探索网络学习与奖励估计相比的潜在增益, 同时加入邻居用户的协同作用, 并构造决策器进行最终决策. 针对数据稀疏性问题, 不同于协同过滤, 本文算法并不简单依赖对相同物品的评分判定用户间的相似性, 而是基于用户对上下文中各特征的关注度进行计算. 在针对新用户的推荐问题中, 本文根据用户特征寻找邻居用户并进行协同推荐, 同时多臂老虎机算法还可帮助用户在尽量少的次数内快速试探用户喜好, 并根据用户反馈挑战模型参数, 改善推荐效果. 最后, 通过平衡探索网络和利用网络的结果以及控制协同作用的强度, 可有效保证推荐中用户自身的决定性作用以及推荐的多样性. 在真实数据集上将本文算法与基线算法进行比较, 实验结果表明, 本文算法在推荐问题上有效.
