基于改进SSD 算法的结构表观裂缝病害检测
2024-01-16刘永胜熊吉光游志杰吴勋杰翟天正
刘永胜,熊吉光,游志杰,吴勋杰,翟天正
(1.华东交通大学土木建筑学院,江西南昌330013;2.安徽理工大学深部煤矿采动响应与灾害防控国家重点实验室,安徽淮南232001)
裂缝作为土木工程中最为常见的表观病害形式,常见于隧道、公路、桥梁及墙体表面。 建构筑物随着表面裂缝的进一步扩展,结构的损伤将逐步从表观转移到内部, 严重的将影响结构的耐久性,甚至导致其整体性破坏引发重大事故,故此对结构表观裂缝进行检测识别就显得尤为重要。
近年来,不少学者将深度学习方法运用在土木工程学科各个领域,Xu 等[1]应用深度学习目标检测技术从图像中识别和定位受损钢筋混凝土柱的多类型地震损伤,此技术可为后期研究震害损伤提供资源。 丁杨等[2]将人工智能运用在监测大体积混凝土放热中,结合7 种人工智能方法,选择合适的算法并进行优化,可为今后土木工程领域监测-预测-预警提供依据。 Fang 等[3]利用深度学习计算机视觉领域技术,借助监控摄像头对施工现场进行安全检测实时识别工人有无佩戴安全帽。
学者利用深度学习中卷积神经网络可将低级特征通过卷积操作抽象成高级特征, 表示这一特点进行了结构表观裂缝病害检测研究。 Lei 等[4]利用深度卷积神经网络对道路路面裂缝进行检测。黄彩萍等[5]利用卷积神经网络对混凝土表观病害进行智能分类达到90%以上的准确率。王丽苹[6]运用深度学习目标检测中Faster R-CNN 模型对混凝土路面裂缝进行检测。袁泽辉等[7]将卷积神经网络运用在管道表面缺陷识别研究方面, 取得了较高的识别率。 廖延娜等[8]通过扩充数据集、聚类算法对数据进行聚类及对YOLOv3 网络进行改进的手段,使得修改后的网络能提高小裂缝检测精度。马健等[9]提出用YOLOv5 网络对古建筑木结构裂缝进行检测,相对于传统技术具有高效、便捷等较多优点。
除R-CNN 及YOLO 系列之外,SSD 网络在目标检测领域也备受关注。 SSD 网络采用回归思想,网络直接输出类别概率及位置信息, 具有检测性能较好、检测速度快、准确率高等特点,但对于小目标的识别效果一般。 故论文通过改进SSD 网络模型来实现多场景下结构表观裂缝病害检测,运用深度学习技术更加智能化的检测出结构表面裂缝病害。
研究在数据集及模型上进行了改进,相比于原SSD 模型在检测精度和检测速度上得到明显提升,主要工作有以下几个方面: 首先将SSD 网络原有Backbone 替换为轻量级的MobileNetV2 网络,目的是加快网络推理速度的同时减小模型的参数,使其能满足实时检测, 为后期部署在终端提供现实基础。 其次引入通道注意力机制SENet 结构,使模型学习到不同通道的信息,从而实现通道的自动校准来提升检测的精确率。 然后通过利用多个场景不同环境下数据集进行融合,增强网络对裂缝的识别能力, 使模型能运用于多场景条件下。 最后运用Kmeans 聚类算法对目标数据集先验框进行分析,根据所得结果修改原有数据集中的先验框宽高比例,从而提高网络对目标的学习能力,加快网络的收敛。
1 SSD 网络模型及其改进
SSD 全 称 为Single shot multibox detector,是Liu 等[10]在ECCV2016 上提出的。SSD 网络是基于回归的目标检测算法,相较于其他算法具有速度快以及检测准确率高的优势。同时结合了YOLO 的回归思想和Faster R-CNN 中的Anchor 机制。 采用回归思想,降低了模型的复杂度,从而提高算法的实时性; 采用Anchor 机制, 通过设计不同高宽比先验框,进行回归预测。
SSD 采用VGG16 模型作为前置骨干网络,并对VGG16 模型进行了一定的修改, 使其用于整个网络的特征提取。 骨干网络去除了原始VGG16 模型中的Dropout 层与FC8 层,将FC6 和FC7 替换为卷积层Conv6 和Conv7; 之后在末端添加4 个卷积层Conv8_2、Conv9_2、Conv10_2 和Conv11_2, 具体网络结构如图1 所示。向SSD 网络输入固定尺寸的图像, 将其传输到改进后的VGG16 模型中获得不同尺寸大小的特征图,在不同特征图上对预先默认的边界框计算其类别及置信度, 最终通过NMS 方法(非极大值抑制)移除掉一部分检验框,从而输出最优的检测结果。
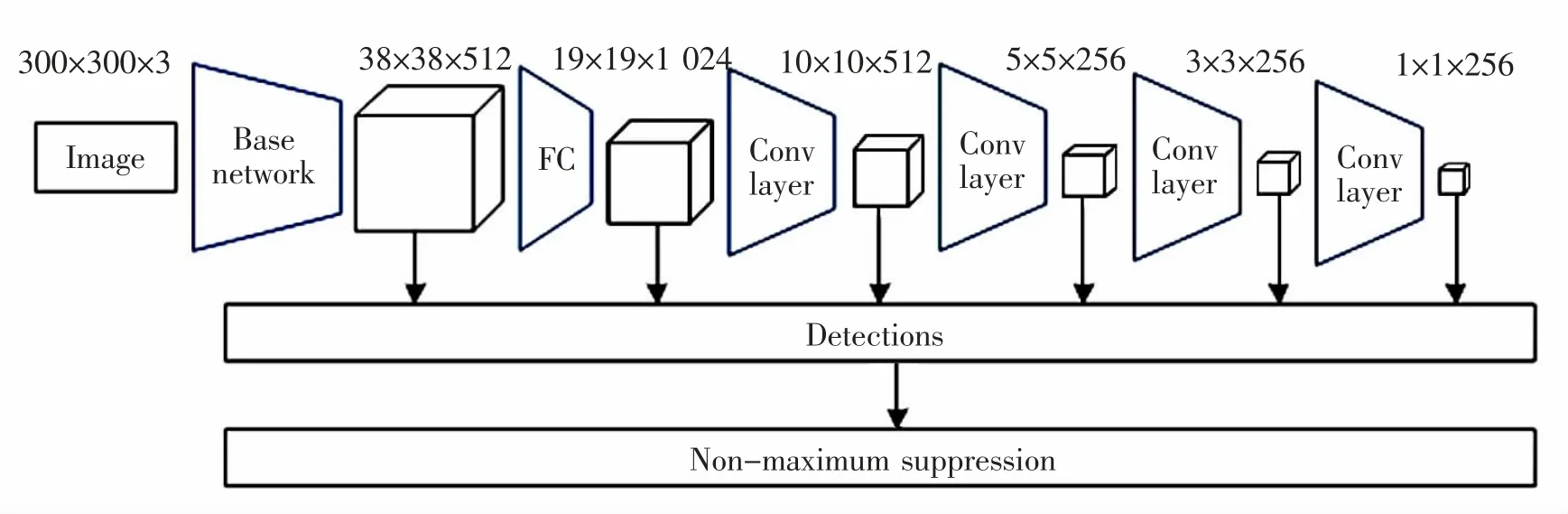
图1 SSD 网络结构示意图Fig.1 Schematic diagram of SSD network structure
2 基于MobileNetV2 改进的SSD 目标检测算法
2.1 轻量级网络MobileNetV2
MobileNetV2 是由Sandler 等[11]提出并在Mobile-NetV1 基础上改进后得到的轻量级、 高效化卷积神经网络。 MobileNetV2 也被称之为深度可分离卷积,其主要特征是将传统的卷积过程分离成了深度卷积和点卷积两个过程,以及网络中添加了倒残差结构和线性激活函数,这使得网络能在加快推理速度的同时,又能不损失模型的检测精度。 图2 为深度可分离卷积和传统卷积计算过程对比图。
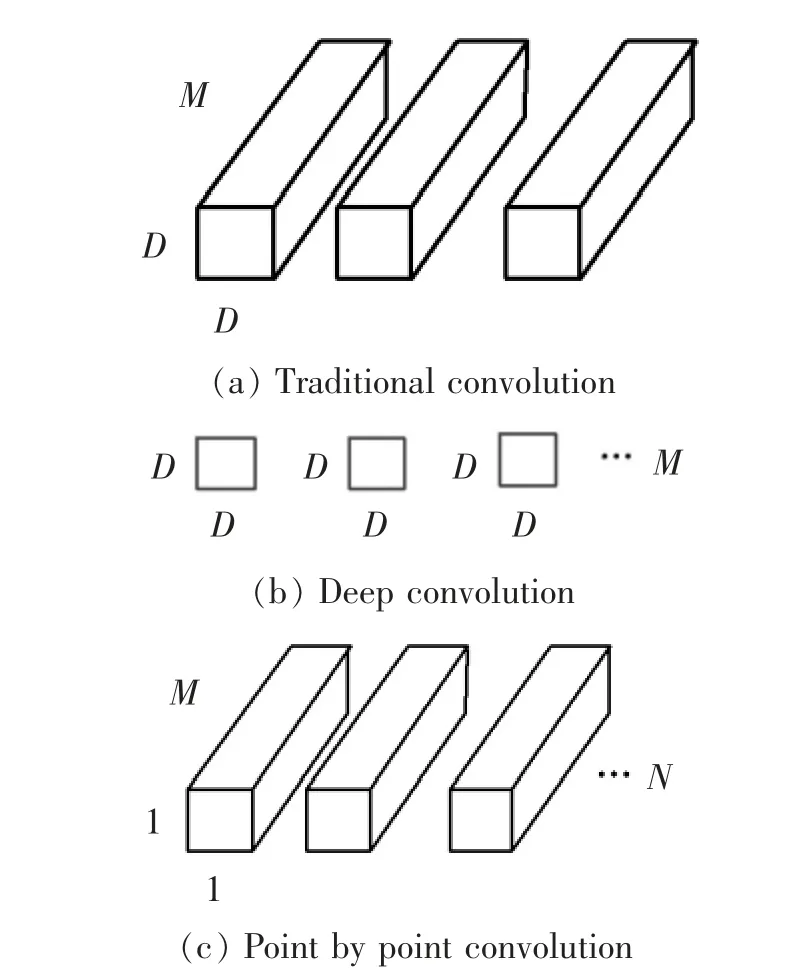
图2 传统卷积与深度可分离卷积Fig.2 Traditional convolution with depth-separable convolution
从图2 可知, 传统卷积过程的计算量为D×D×M×N,而深度可分离卷积过程的计算量D×D×1×M+1×1×M×N,两者之比为
本算法使用卷积核尺寸D=3,从上述比值结果中可得出, 深度可分离卷积可减少8/9 网络结构计算量,因此可加快模型的检测速度。
MobileNetV2 网络结构中还加入了倒残差结构,如图3 所示,参考了ResNet 模型中残差块而进行改进的。 与ResNet 模型中不同的是,该结构先利用1×1 卷积对特征进行升维,扩张其深度,再用3×3卷积在高维度空间进行特征提取,可获得更丰富的特征,最后经过1×1 卷积降低通道维度并利用线性激活函数,该结构使得网络能够获取到图像更多的特征从而增强网络的表达能力。
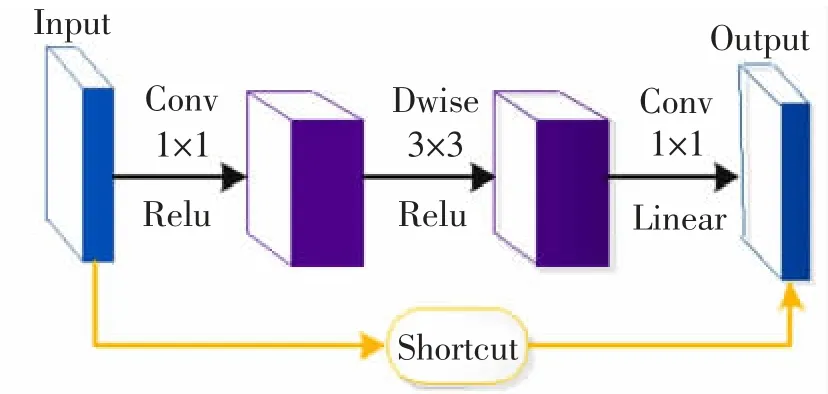
图3 倒残差结构示意图Fig.3 Diagram of inverted residual structure
2.2 改进SSD 算法
为了能更好的满足工业中对目标实时检测要求, 论文用轻量级的MobileNetV2 模型作为特征提取网络替换掉SSD 中原有VGG16 模型。 具体操作如下,保持原有SSD 算法中输入图像尺寸,即300×300×3,去除原本MobileNetV2 模型中的全连接层和池化层,并在尾部添加4 个由倒残差结构组成的卷积层。 为了实现对不同尺度裂缝均有较好的检测效果,选取网络中6 个不同尺度特征图来实现裂缝的分类和定位, 分别为19×19,10×10,5×5, 3×3,2×2,1×1,改进后的SSD 算法网络结构参数如表1所示。
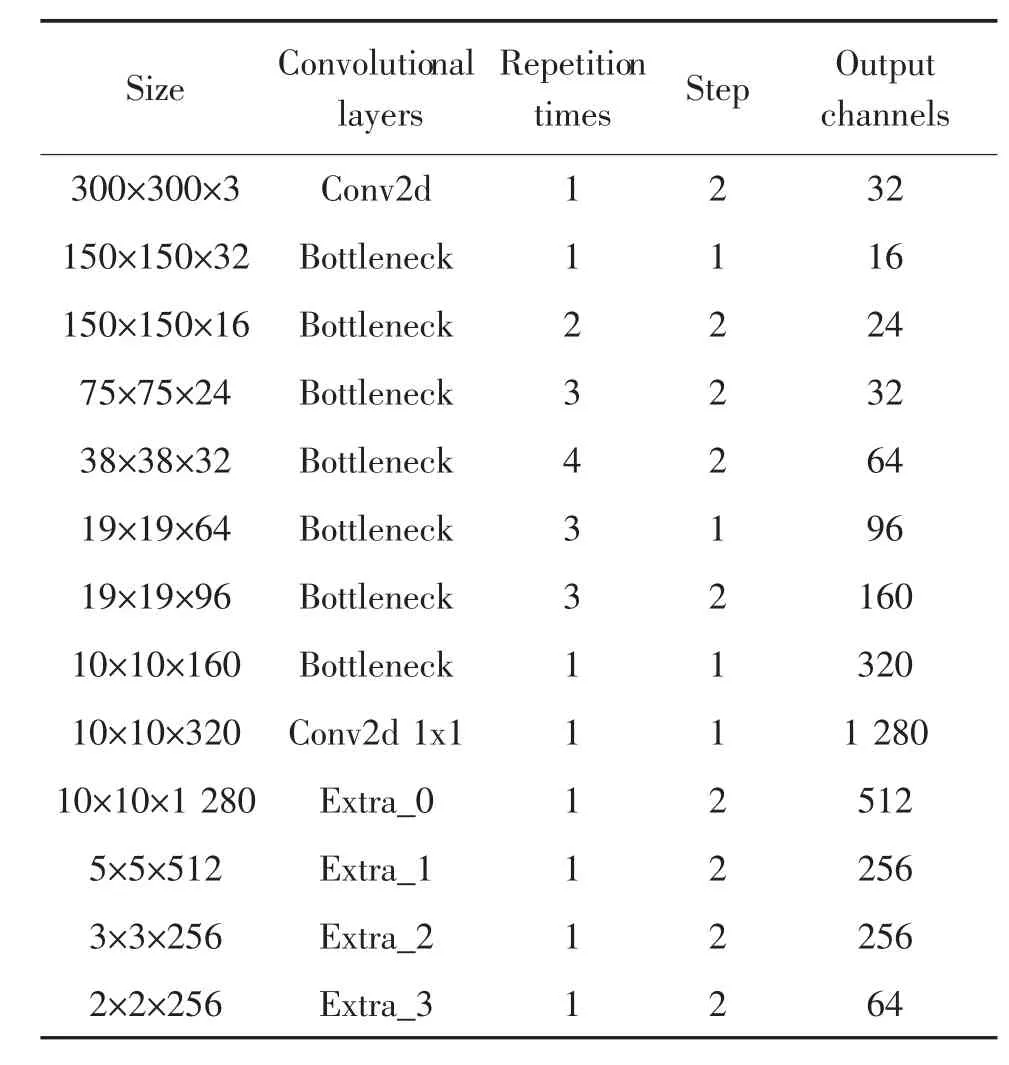
表1 改进后SSD 算法网络结构参数Tab.1 Parameters of the network structure of the improved SSD algorithm
3 通道注意力机制模块
注意力机制[12]已广泛运用在计算机视觉各个领域,利用注意力机制可使网络更多关注特征中的一些细节信息,从而一定程度上提高特征的表达能力。SENet 是通道注意力机制模块的缩写, 该机制主要通过关注特征图各通道之间的关系,从而达到提高性能的效果。
SENet 模块结构示意图如图4 所示,其先对由卷积得到的特征图进行全局平均池化, 然后对全局特征进行激励操作,学习各通道之间的关系,此时,网络会重点关注信息量较大的通道特征,而对一些信息量较小的通道进行忽略。 完成上述操作后将得到不同通道的权重,最后权重与先前的特征图相乘得到最终的特征图,送入到检测头进行分类和定位。
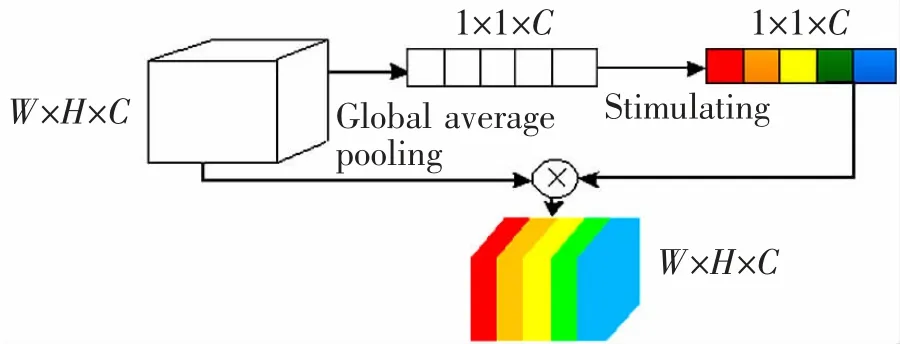
图4 SENet 模块结构示意图Fig.4 Schematic diagram of SENet module structure
4 数据集的制作
由于文章更多关注的是多场景不同环境下结构表面的裂缝,故将收集到的隧道(混凝土)、公路(沥青)及桥梁(钢材)3 种场景下裂缝数据进行混合,混合后的数据集涵盖了工程中可能出现的多种常见背景及裂缝形式,丰富了研究样本数据。 与现有文献数据集大多只关注一类环境下的裂缝不同,混合构建的新数据集使网络能更好的学习到不同环境下裂缝对象,从而提高网络的识别能力(图5)。
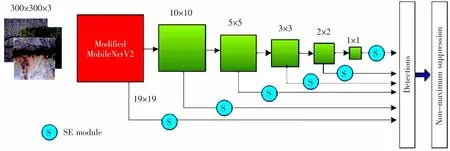
图5 改进后SSD 模型网络结构示意图Fig.5 Schematic diagram of the network structure of the improved SSD model
根据网络训练需求,将收集到原始图像全部分割成统一大小300×300 像素,并确保每张图片中都至少包含一个目标,总共得到1 000 张图片数据将割成统一大小300×300 像素,并确保每张图片中都至少包含一个目标, 总共得到1 000 张图片数据将其命名为S_Crack(图6),作为最终网络训练验证数据集,对照实验采用同等数量的单一裂缝数据集。

图6 S_Crack 部分数据Fig.6 S_Crack section data
最后,使用深度学习目标检测中常用的标注工具Labelimg 进行数据标签的制作,该工具可快速便捷的构建进行训练所需要的文件。
5 数据集目标框的聚类分析
根据不同尺度特征图,网络生成对应大小与高宽比的先验框,计算公式如下
式中:Smax和Smin是原SSD 论文[9]中设定好的最大和最小特征层尺度,默认为0.9 和0.2。 m 为特征层层数,默认取m=6,k 的取值为[1,m],中间各特征层尺度按上述公式计算。
当特征层尺度一定时, 变化高宽比设定Aspect_ratios=[3,2,1,1/2,1/3]来计算先验框宽、高。
由于论文数据集所关注的目标类型与通用数据集相差较大, 采用原始VOC 数据集宽高比的先验框生成候选框,将会造成候选框的冗余,从而增加计算量。 K-means 聚类算法在众多场景下都有较好的表现[13-15],故为消除人工设计先验框存在的主观因素, 使用K-means 算法设计自适应先验框,对前文所建立的S_Crack 目标检测数据集中裂缝的真实框作聚类分析,从而得到先验框宽高比。 图7 为数据集中所有先验框聚类后的结果。
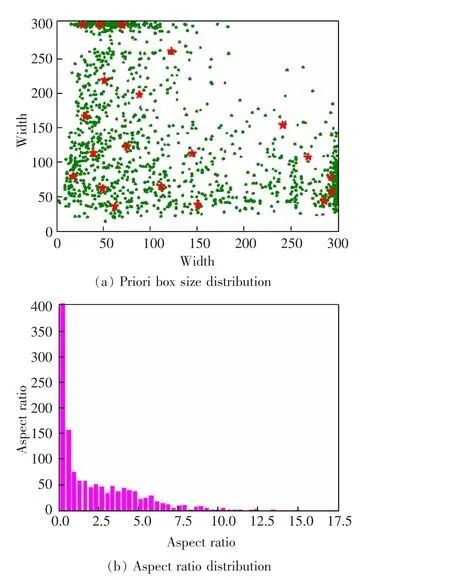
图7 先验框聚类结果Fig.7 Priori frame clustering results
根据聚类后的结果, 进一步设定适合文章数据集的宽高比Aspect_ratios=[6,3.5,1,1/3.5,1/6]。
6 实验结果与分析
6.1 模型参数设置
运用Google Colab 深度学习开放平台, 以Pytorch 深度学习为框架,Python 为编程语言实现论文裂缝目标检测模型训练及验证。实验环境为Ubuntu操作系统,GPU Tesla T4,CUDA 11.2,Pytorch 1.2.0。本次实验数据集为S_Crack 共1 000 张混合环境下的裂缝图像,按9∶1 划分训练集和验证集,故900 张作为训练集,100 张作为验证集。Epoch 设置为200,Batch_size 为16,Initial_learning_rate 为1e-4。
6.2 评价指标
本实验选取的评估指标是精确率(precision,P),其可直接反映模型的精确性,公式如下
式中:TP为模型预测为正的正样本;FP为模型预测为正的负样本。
除上述指标外,论文还考虑为满足实际生产将检测速度作为该实验的评估指标,以每秒传输帧数FPS 作为评估,FPS 越大说明检测速度越快。
6.3 实验结果
为验证修改后模型的性能,论文对修改前后算法进行训练并测试,各算法检测结果如表2。可以看出,未经修改的原始SSD 算法精确率不高且FPS 较小,无法满足工程实际上的实时性要求,替换Anchor为K-means 聚类优化后的算法,精确率和检测速度都有所提升,这是因为聚类后的先验框更符合裂缝的宽高比,因此不会造成候选框的冗余,加快网络的推理速度。 使用融合数据集进行训练,可使算法性能略有提高,说明网络从不同环境下裂缝数据中学习到了信息。 更换Backbone 为MobileNetV2 且加入通道注意力机制模块后精确率提高到73.9%, 相比于原始SSD 算法增加了3.6%,且FPS 为122 frame,检测速度是先前的2 倍多,足以满足生产生活中的实时检测。

表2 算法检测结果Tab.2 Algorithm detection results
从图8 损失曲线中可以得出, 经论文方法改进后的SSD 算法相较于原始算法, 训练得到的平均损失率更低,说明改进后模型的收敛性更好。
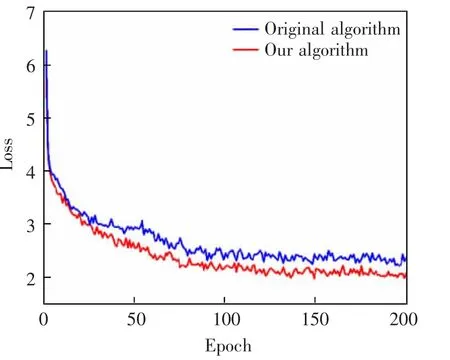
图8 训练平均损失曲线Fig.8 Training average loss curve
从互联网上获取房屋内外墙体表面裂缝图像进行测试,实验结果如图9 所示,改进后算法对裂缝的置信度明显高于原始算法,且对未经过训练的图像仍有较高的准确率,说明了模型的普适性。

图9 算法修改前后效果对比Fig.9 Comparison of the effect before and after algorithm modification
7 结论
1) 在原有SSD 目标检测算法的基础上进行修改,提出了一种新的建筑表观裂缝检测算法,在提高算法准确率、加快网络推理速度的同时框选出裂缝可能出现的位置还在预测图像上标注出裂缝的个数,方便观测人员对裂缝数量进行统计。
2) 改进后算法的精确率较先前增加了3.6%,检测速度是先前的2 倍多,可满足实时检测。
3) 相比于费时费力的传统检测方法,利用该算法对裂缝进行检测可减少检测人员因视觉疲劳所带来的误差。 模型小、推理速度快,后期可将模型部署在无人机或智能小车上,进行房屋建筑外墙和隧道衬砌的表观裂缝识别,从而更快速、更精确实现大批量场景检测。
