中国英语学习者加工英语反身代词歧义句的策略研究
2024-01-15唐萌萌吴金超
唐萌萌 吴金超
引言
在句子理解过程中,读者需要建构非毗邻成分间的句法关系,如反身代词与先行词构成回指关系(anaphora)。在英语中,可以通过性、数和句法规则等线索来确定反身代词的先行词;然而,当同一性别的多个名词都可做先行词时(如:the son of Jack),反身代词(himself)的性别线索无效,指代歧义由此产生。反身代词歧义现象在自然语言中普遍存在,对其加工策略的研究却未得出统一结论。在母语加工中,不同的加工模型预测了歧义加工的不同结果:基于制约的加工模型(constraint-based parsing model)认为歧义句加工时间更长、难度更大;而非限制竞赛模型(unrestricted race model)、“足够好”理论(goodenough theory)、识解模型(construal model)和不指定理论(underspecif ication account)则认为歧义句加工时间更短、难度更小。即使预测结果类似,不同理论对其加工策略的解释也不尽相同。与母语歧义加工研究相比,在二语歧义加工领域鲜有研究者提出相关理论,对这一现象的探讨多基于实证研究寻找影响二语学习者歧义消解的相关因素,切入点多为因代词或名词指代不明而引起的歧义。在反身代词回指,特别是关系从句中的反身代词回指中,照应语与先行词线性距离较远,句式相对复杂,且在不同语言类型中回指倾向不同,比一般代词或名词指代不明引起歧义更能说明二语解歧加工的特点,对于深入了解二语与目标语句法加工的异同有重要意义。因此,本文拟以关系从句中的反身代词歧义加工为切入点,研究中国英语学习者与英语母语者歧义加工策略的异同,并验证二语中的非限制竞赛模型、不指定加工理论、“足够好”理论、识解模型以及基于制约的加工模型等歧义加工模型。
一、研究背景
1.歧义句加工模型
基于制约的加工模型认为,歧义句的加工时间更长、难度更大,因为在理解句子的过程中多种句子结构被同时激活,该句的所有可能分析互相竞争(如MacDonald et al.,1994;McRae et al.,1998;Spivey & Tanenhaus,1998;Tabor& Tanenhaus,1999)。换句话说,当句法或语境信息无法提供充足的制约条件时,人们需要在多种分析中选择,进而造成加工难度的增加。
然而,该模型受到了一些学者的质疑,他们认为歧义句不会引起加工时间的增长。非限制竞赛模型(Traxler et al.,1998;van Gompel et al.,2001;van Gompel et al.,2005)认为,人们在阅读句子时,句法歧义的各种分析平行建构,处于竞赛中,且会根据句子结构实时建构一种优势分析。若后续信息与起初建构的优势分析一致,则继续加工,反应时较短;若后续信息与起初建构的优势分析不一致,则需要重新加工,反应时较长。阅读歧义句时,无论已建构的是哪种分析,都不会被后续信息推翻,因此不需要重新加工,反应时也较短。例如,Traxler et al.(1998)采用眼动实验比较了英语母语者在加工反身代词指称不明的歧义句(如例1a)和结构相似、指称相对清晰的非歧义句(如例1b—c)时所使用的加工策略,发现实时加工歧义句(例1a)比非歧义句(如例1b—c)更容易。
例1
a.The maid of the princess who scratched herself in public was terribly humiliated.
b.The son of the princess who scratched himself in public was terribly humiliated.
c.The son of the princess who scratched herself in public was terribly humiliated.
然而,在此实验中仅有部分句子之后配有阅读理解问题,并没有记录回答问题的准确率与反应时,对于解歧倾向也无相关论述。
Ferreira et al.(2002)、Sanford & Sturt(2002)等也认为歧义句加工时间不会增长,但将其解释为句子加工中的“足够好”原则。该理论认为,人们出于交际的需要,对于语言理解达到足够好的程度即可,因此在理解句子时对语法和语义的解析往往并不完整。以关系从句加工为例,当没有明确的语法、语义和语境信息来帮助消解歧义时,人们往往只进行浅层的语法加工。识解模型(Frazier & Clifton,1996)也给出了相似的解释,即引起歧义的反身代词虽不会立刻附着于其中某一个名词上,但可能会与整个复合名词短语的语义相联系,随后从各种联系中寻求一种解释。然而,当任务要求不需要消除歧义时,被试仅识别不恰当的解释,但不足以完全消除两种恰当解释之间的歧义。在此基础上,Swets et al.(2008)进一步提出了不指定加工理论,即加工歧义句时,我们先忽略对其具体的指定,进行浅层加工;必须进行具体指定时,才考虑歧义消解,并进行深层加工。Swets et al.(2008)采用类似于Traxler et al.(1998)的设计进行了进一步的研究,在所有实验句后增加了两类问题:一类为浅层问题,与歧义消解无关;另一类为深层问题,与歧义消解有关。实验结果表明,仅当被试回答浅层问题时,加工歧义句的反应时才会更短;而当被试被要求对歧义进行具体解释并指定某一种意义时,反应时的优势则会有所减弱。
简言之,关于母语中反身代词歧义的加工策略仍然存在争议。而二语学习者采取何种加工策略,是否与母语者类似,这些问题对于了解二语句法加工机制十分重要,但目前尚缺乏清晰的解答。
2.二语学习者指代歧义的实证研究
目前已有一些研究探讨了中国英语学习者的实时句法解歧。研究发现,影响中国英语学习者指代歧义消解的因素包括歧义激发点的位置(韩迎春、莫雷,2013)、语言类型及语言水平(王同顺等,2016)、动词的因果性倾向(吴明军、吴迪,2019)、加工深度(吴明军等,2018)等。从中国英语学习者歧义句的加工机制来看,吴明军等(2018)发现,在浅层加工中(话语理解中不涉及代词的具体所指),歧义代词条件(如:Mrs.Li lent Mrs.Wu the CD a week before she left for the holidays.)与无歧义代词条件下(如:Mr.Li lent Mrs.Wu the CD a week before she left for the holidays.)的阅读时间、回答问题的准确率不存在显著差异;而在深度加工中,两种条件下的阅读时间存在显著差异,无歧义代词指代主语和指代宾语存在显著差异,歧义代词更以压倒性的优势选择主句主语为先行语。研究结果支持“足够好”理论。唐慧君、文旭(2020)通过眼动实验发现中国英语学习者早期加工中的代词歧义可以加速阅读进程,而歧义代词的消解增加了阅读晚期的加工难度。然而,这些研究大多针对歧义代词、名词,至于关系从句中的反身代词回指是否也会出现这一特征、中国英语学者的加工策略是否与英语母语者一致、他们在加工歧义点时采取的实时策略如何等问题仍有待深入探讨。
关于二语学习者的解歧倾向,也有一些学者作了相关研究,但结论并不一致。例如,关于关系从句的歧义先行词(如“He likes the secretary of the professor who lives in America.”),Frenck-Mestre & Pynte(1997)发 现,以 法 语 为 母语的低水平英语二语学习者的挂靠倾向与母语一致(高挂靠,即指向中心词NP1),高水平二语学习者则与目标语一致,证明了母语迁移对语言学习的影响。Papadopoulou & Clahsen(2003)、Felser et al.(2003)分别发现,以西班牙语、德语或俄语为母语的希腊语二语学习者,以德语、希腊语为母语的英语二语学习者无明显的挂靠偏向。牛萌萌、吴一安(2007)和蔡莉、敖锋(2014)等发现,中国英语学习者在加工英语关系从句中带有属格结构的代词(of)的先行词时无明显的挂靠偏向。Felser & Cunnings(2012)通过两个眼动实验考察了母语为德语的英语二语者加工英语反身代词的情况(如:Adam noticed that the grandfather had explained himself carefully.),发现二语学习者将英语反身代词与主句主语关联,而英语母语者则采取临近原则与从句主语关联。但研究者认为,二语者的表现不能简单归因为母语影响,还可能是二语者更倾向于依赖话语、语境而非句法结构来解释反身代词导致的。
总的来说,关于中国英语学习者如何进行歧义加工已有部分研究,然而,关于二语与母语者反身代词歧义的加工策略是否相同,以及两者对反身代词解读的倾向性如何,仍不清晰。本研究将通过自定步速阅读实验具体探讨以下两个问题:
①中国英语学习者加工英语反身代词歧义句,是否采用与英语母语者类似的加工策略?
②中国英语学习者如何解读反身代词歧义?其解读方式与英语母语者是否相同?
二、研究方法
本实验采用2×3 混合实验设计,组间变量为被试组别(母语组、二语组),组内变量为句子类型(NP1 指代句、NP2 指代句、歧义句)。实验任务为移动窗口的自定步速阅读,即按空格键呈现一个片段,新片段的出现会覆盖先前呈现的片段。阅读完成后回答问题。
1.被试
本研究被试共49 名,包括24 名中国英语学习者(年龄:18—22 周岁)与25 名英语母语者(年龄:18—22 周岁)。英语二语学习者均来自山东省某大学英语专业,英语母语者均为英国某大学的在读学生。中国英语学习者二语水平测试的题目是选自Oxford Prof iciency Test(Test 1B)的50道语法选择题(Allan,2004),最终成绩为18—29 分为初级水平(elementary),30—39 分为中低水平(lower intermediate),40—47 分为中高水平(higher intermediate)。所有被试之前均未做过这一测试。经二语水平测试,所有中国英语学习者的二语者水平均为中高水平。
2.实验材料
本研究共设计12 组(36 句)关系从句作为测试句,每个句子根据其语法功能划分为7 个部分(R1—R7),其中第4 部分为第三人称单数的反身代词。每组测试句均包含一个歧义句,如例2a 所示,由于sister、heroine 两词在性上均与反身代词herself 一致,反身代词回指存在歧义。每个测试句后均配有关于本句理解的问题。例2b—c 分别列举了一个NP1 指代句和一个NP2 指代句,前者由于反身代词与中心名词(brother)在性上保持一致,因此指向NP1;后者则指向NP2(heroine),照应语与先行词距离较短。实验控制了单词难度、单词数及字符数:实验句单词选自高中英语教学大纲,单词数一致,字符数无显著差异[F(2,33)=1.596,p=0.218,> 0.05]。
例2

测试句(36 句)均设置反身代词理解问题(即如何解释定语从句中反身代词的指向),填充句(84 句)一半(42 句)设置简单问题,一半(42 句)不设置问题。所有句子均以拉丁方形式随机出现。问题的正误大致控制在50%正确,50%错误。
3.实验过程
测试在安静的房间内进行,每次测试一个被试。被试首先阅读实验要求,然后进行自定步速阅读、二语水平测试,并填写个人语言背景表。最后,被试获得相应报酬。本实验由E-prime 2.0 软件呈现。正式实验前,被试先进行两组句子练习。实验开始后,被试按空格键出现一个片段,再按该片段消失,下一片段呈现,以此类推直到句子结束(R7)。阅读完句子后,可能出现一个与句子内容相关的问题,要求被试作正误判断。正确按“F”键,错误按“J”键。
三、研究结果
实验结束后,用SPSS 19.0 进行统计分析。NP1 与NP2 指代句中判断错误的数据不计入统计分析,另剔除极值以及3 个标准差之外的数据,共去掉总数据的10.8%。
1.反应时
从总反应时长来看,英语母语者加工3 类句子的反应时都快于中国英语学习者。在歧义区R4,两组被试在加工3 种类型的句子时呈现差异:中国英语学习者平均反应时NP2 指代句> NP1 指代句>歧义句;英语母语者则表现为NP1指代句>歧义句> NP2 指代句。在歧义区后一片段R5,中国英语学习者反应时表现为NP1 指代句> NP2 指代句>歧义句;英语母语者为NP1 指代句>歧义句> NP2 指代句。表1 为两组被试加工3 类句子时在各个片段的平均反应时。
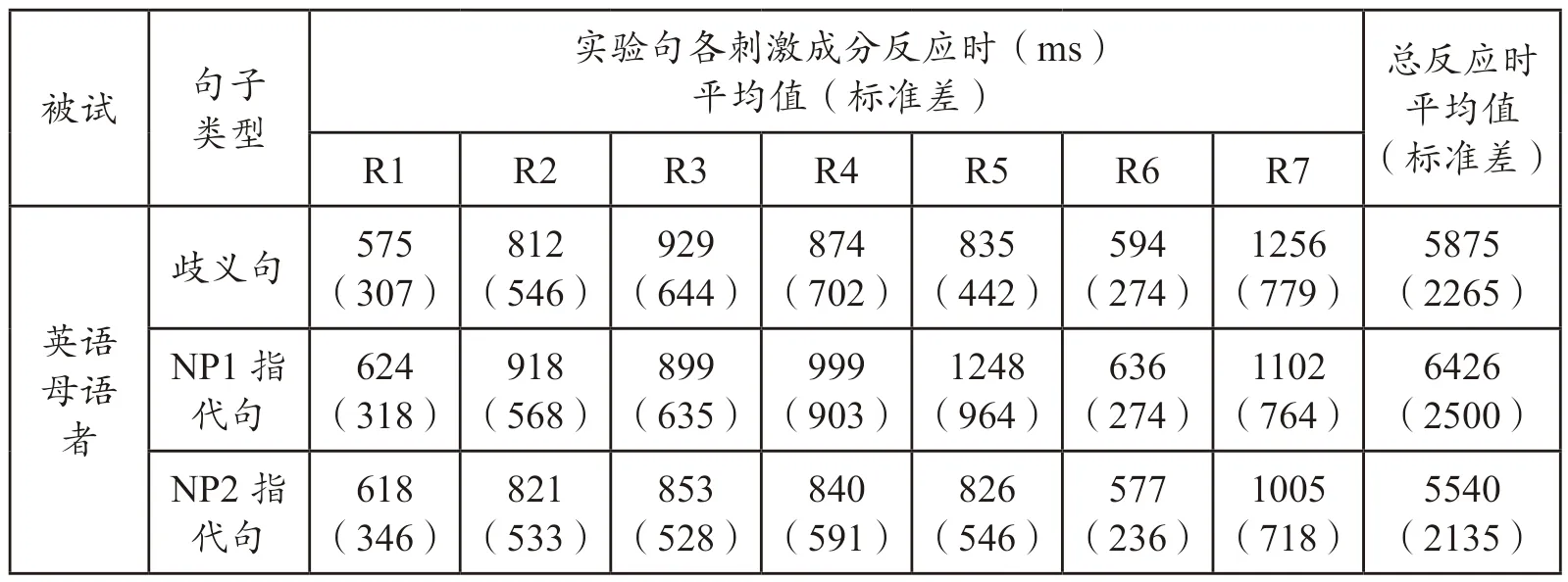
表1 中国英语学习者与英语母语者实验句加工反应时
为清晰地展示关键片段(R4)及其他片段的反应时情况,我们用图1 和图2 分别加以展示。

图1 中国英语学习者加工3 类句子的平均反应时

图2 英语母语者加工3 类句子的平均反应时
为检验歧义区R4(himself/herself)的差异是否显著,以被试组别(母语组、二语组)、句子类型(NP1 指代句、NP2 指代句、歧义句)作为自变量进行2×3 的方差分析。结果表明:被试主效应显著[F(1,141)=13.834,p=0.000,< 0.01],英语母语者的反应时显著短于中国英语学习者;句子类型存在显著差异[F(2,141)=3.763,p=0.023,< 0.05];被试及句子类型的交互效应显著[F(2,141)=8.935,p=0.000,< 0.01]。简单效应分析发现,中国英语学习者加工歧义句和NP1 指代句的反应时无显著差异(MDNP1-歧=31 ms,p=0.595,> 0.05),但加工NP2 指代句的反应时显著长于歧义句(MDNP2-歧=305 ms,p=0.000,< 0.01);而英语母语者加工歧义句和NP2 指代句的反应时无显著差异(MDNP2-歧=-34 ms,p=0.639,> 0.05),加工NP1 指代句反应时显著高于歧义句(MDNP1-歧=125 ms,p=0.007,< 0.01)。因此,在R4 片段,中国英语学习者加工NP2 指代句显著慢于另两种句型,而英语母语者加工NP1 指代句显著慢于其他两种句型。
考虑到实时加工中的溢出效应(spill-over e§ ect),研究者进一步检验了R5片段,发现被试组别和句子类型无交互效应[F(2,141)=1.736,p=0.177,> 0.05]。但被试组别主效应显著,即英语母语者反应时显著较短[F(1,141)=42.957,p=0.000,< 0.01];句子类型主效应显著[F(2,141)=3.763,p=0.023,< 0.05]。简单效应分析显示,中国英语学习者加工NP1 指代句显著慢于其他两种条件(MDNP1-歧=269 ms,p=0.000,< 0.01;MDNP1-NP2=240 ms,p=0.002,< 0.01)的句型;英语母语者也呈现NP1 指代句显著较慢的情况(MDNP1-歧=413 ms,p=0.000,< 0.01;MDNP1-NP2=422 ms,p=0.000,< 0.01)。由此可见,在R5 片段,中国英语学习者与英语母语者对3 类句子的加工模式类似。
为确认两组被试在歧义区之前加工3 类句子是否存在差异,研究者分别在片段R1—R3 作了统计分析。结果表明,母语组、二语组在R1—R3 片段对3类实验句的反应时差异均不显著。
以上数据表明,两组被试在3 类句子的R1—R3 片段反应时无显著差异,直到出现R4 片段(歧义区):虽然两组被试加工歧义片段反应时均无显著增加,但对NP1 和NP2 指代句型的加工模式显著不同,即中国英语学习者加工NP2 指代句难度更大,而英语母语者加工NP1 指代句难度更大。在随后的R5片段,两组被试的加工模式趋同。
2.正确率、倾向率
NP1 和NP2 指代句反身代词指称明确,正确选项以性别线索指示为准。在歧义句中,被试以反身代词指向NP2(反身代词临近词)进行倾向性解读,由此研究者考察被试如何解读歧义句中反身代词的指代问题。两组被试的正确率与倾向率详见表2。

表2 中国英语学习者和英语母语者3 种句子类型条件下测试句正确率情况
以句型与组别为变量进行2×3 方差分析,结果显示母语组与二语组差异不显著[F(1,141)=2.194,p=0.141,> 0.05],句子类型差异显著[F(2,141)=16.581,p=0.000,< 0.01],被试与句子类型未产生显著的交互效应[F(2,141)=2.300,p=0.104,> 0.05]。简单效应检验发现,英语母语者在歧义句中反身代词指向NP2 的倾向性显著高于中国英语学习者(MD英-中=14.4%,p=0.012,< 0.05);当有明显性别线索指向时,两组被试在正确率上无显著差异(NP1 指代句:MD英-中=-2%,p=0.712,> 0.05;NP2 指代句:MD英-中=2.1%,p=0.702,> 0.05);两组被试加工NP1、NP2 指代句时正确率均无显著差异(中国英语学习者:MDNP1-NP2=6.6%,p中=0.672,> 0.05;英语母语者:MDNP1-NP2=2.5%,p英=0.234,> 0.05)。
四、讨论
本研究以英语母语者作为对照,探讨中国英语学习者反身代词歧义句的加工策略及解歧倾向。自定步速阅读实验表明:中国英语学习者与英语母语者在歧义区反应时均无明显减慢,但对NP1 和NP2 指代句的加工模式不同。此外,英语母语者倾向于将无性别线索提示的歧义反身代词指向临近词,而中国英语学习者倾向于指向中心词。
1.反身代词歧义的加工策略
中国英语学习者与英语母语者在实时加工反身代词歧义的策略上有相同之处,两组被试在加工带有歧义的反身代词(R4)时,反应时没有显著增长,而是快于NP1 指代句或NP2 指代句。这说明,中国英语学习者同英语母语者一样,在加工歧义句时,没有因为制约条件的缺失而在多种语义解释中进行选择,并没有造成加工难度的增加,因此不支持基于制约的加工模型(MacDonald et al.,1994;McRae et al.,1998;Spivey & Tanenhaus,1998;Tabor & Tanenhaus,1999)。这一结果与以往关于中国英语学习者歧义加工的发现有一致之处,即当无明确解歧信息时,歧义消解过程不会启动(韩迎春、莫雷,2013),歧义区的阅读速度无明显减慢(吴明军等,2018),早期加工中代词歧义可以加速阅读进程(唐慧君、文旭,2020)。
中国英语学习者和英语母语者加工歧义反身代词的反应时都无显著增加,这一结果与非限制竞赛模型、不指定加工理论、“足够好”理论以及识解模型的预测一致。按照非限制竞赛模型(Traxler et al.,1998;van Gompel et al.,2001;van Gompel et al.,2005),句法歧义的各种分析平行建构处于竞赛中,当一种分析处于优势时,这种分析就被采用(于秒等,2016)。二语学习者对歧义反身代词最初的解读一直没有被推翻,因此在歧义区及后续片段的反应时间无显著增长。如果这一理论解释成立,则二语学习者在加工带有性别线索的非歧义反身代词时有偏向性的解读,与优势解读相同时加工时间较短,与优势解读不同时加工器需要重新分析,加工时间较长。从非歧义句加工结果来看,中国英语学习者加工反身代词指代中心词时反应更快,指代临近词时反应时明显较长。这可能是因为中国英语学习者在加工反身代词时优势解读反身代词指代属格结构的中心词,当优势解读与后面信息不一致时,会造成加工时间增长。而英语母语者加工指代临近词反应更快,因为其在加工中优势解读反身代词指代临近词。从以往关于不同语言关系从句高低位挂靠的研究中可知,英语对属格结构(NP1 of NP2)的先行词具有低挂靠NP2 偏好(临近原则)(Carreiras & Clifton,1999),而汉语则是高挂靠NP1 偏好语言(中心词原则)(何文广等,2017)。因此,挂靠偏好使得英语母语者和中国英语学习者对非歧义反身代词呈现不同的加工模式,但对于未重新分析的歧义反身代词,两组被试加工策略趋同,反应时均与优势解读的非歧义反身代词无显著差异。从两组被试对3 类句子的反应时间上看,本研究结果支持非限制竞赛模型。
从不指定加工、“足够好”理论以及识解模型的解释来看,在加工歧义句时,我们先忽略对其具体指定,对于语言理解达到足够好的程度即可;引起歧义的反身代词虽不会立刻附着于其中心名词,但可能会与整个复合名词短语的语义相联系(Ferreira et al.,2002;Swets et al.,2008)。如果这些理论解释成立,那么被试在加工指代NP1 或NP2 的非歧义句时有明确的性别线索提示,他们会据此进行识解,NP1 与NP2 指代句中的反身代词加工时间均应慢于歧义代词,且非歧义反身代词之间无显著差异。但实验结果显示,在两组被试中,指代NP1 与NP2 的反身代词加工均有显著差异,而未具体指定(或未识解)的歧义代词加工时间与其中一类非歧义反身代词加工时间无显著差异。因此,实验结果虽然与不指定加工、“足够好”理论和识解模型的预测部分类似,但不支持对于歧义加工模式的解释。这一解释与吴明军等(2018)关于中国英语学习者加工代词指代歧义的“足够好”理论解释不同。
2.反身代词歧义的理解
歧义句之后的问题涉及无性别线索的反身代词回指,统计结果发现,英语母语者更倾向于采用临近原则(指代NP2)解歧,而中国英语学习者则采取中心词原则(指代NP1)。这进一步呼应了在实时加工中,中国英语学习者对指代NP1 的反身代词加工更快,而英语母语者对指代NP2 的反身代词加工更快的结论。这一结果不同于以往关系从句先行词歧义研究中关于中高水平二语者与目标语母语者挂靠倾向类似的论述(如Frenck-Mestre & Pynte,1997),也不同于二语加工无挂靠倾向的结论(如Papadopoulou & Clahsen,2003;Felser et al.,2003;牛萌萌、吴一安,2007)。本研究结果与Felser & Cunnings(2012)的结论一致,但Felser & Cunnings(2012)着重强调二语学习者普遍将英语反身代词与主句主语关联,因为二语学习者更倾向于依赖话语和语境,而非句法结构。结合实时加工证据,我们认为:中国英语学习者可以利用句法线索进行NP1(高)、NP2(低)指代的关系从句加工,而不仅仅依赖语境和语义等因素。对歧义反身代词的解歧倾向体现了高挂靠母语的跨语言影响,在这一问题上还需要更多来自低挂靠母语的证据。
结语
本研究以关系从句中的反身代词回指为例,通过反应时与句子理解问题分别测试了中国英语学习者与英语母语者的歧义加工策略及解歧倾向。实验结果表明,两者加工歧义反身代词时反应时均无明显增长,加工策略类似;但与英语母语者相反,中国英语学习者加工指代NP1 的反身代词显著快于NP2,对歧义反身代词的解释也更倾向NP1,说明其更倾向于采用中心词原则预测以及解歧。实验结果支持非限制竞赛模型,不支持不指定加工理论、“足够好”理论、识解模型对结果的解释,同时否定了基于制约的加工模型。这一发现为歧义加工理论增加了新的证据,揭示了跨语言影响在二语句法解歧中的作用,并说明二语者可利用语义和语境之外的句法线索进行句子加工。
