基于双通道的智能合约漏洞检测方法
2024-01-12李鑫杜景林陈子文王坤
李鑫, 杜景林, 陈子文, 王坤
(南京信息工程大学人工智能学院, 南京 210044)
作为区块链中四大核心技术之一的智能合约是一种以信息化方式传播、验证或执行的计算机协议,在区块链平台上自动运行[1],为各类分布式应用服务提供了基础。开发人员可以专门设计智能合约来实现数字资产管理。
智能合约极大地扩展了区块链的应用场景与现实意义。到目前为止,数百万个智能合约已经部署在各种区块链平台上,实现了广泛的应用,包括钱包、众筹、去中心化赌博和跨行业金融等。来自各个领域的智能合约现在持有价值超过100亿美元的虚拟货币,并且智能合约数量仍然在不断增多。巨大的财富使得智能合约成为网络攻击的完美目标。
相比传统程序,智能合约的安全问题更加复杂,现实情况也更加严峻。区块链具有不可变特性,智能合约代码部署后无法修改,一旦代码存在Bug极有可能被利用。2016年,黑客利用DAO(decentralized autonomous organization)合约[2]的可重入性漏洞窃取了超过360万的以太币,价值约5 500万美元。2018年,美链(beauty chain,BEC)的Token合约遭到攻击,导致BEC的价格几乎归零[3]。2020年,去中性化借贷协议Lendf.Me遭遇黑客攻击,合约内价值2 500万美元的资产被洗劫一空。这些安全问题严重阻碍了区块链的发展,并在用户之间造成了智能合约的信任危机。智能合约安全性问题的研究就显得尤为关键,因此,高效的智能合约漏洞检测工具是非常重要和迫切的。
传统的智能合约漏洞检测方法大多基于固定规则的检测,如Luu等[4]提出的一种基于符号执行的漏洞检测工具Oyente通过检测以太坊虚拟机(ethereum virtual machine,EVM)字节码能够检测7类智能合约漏洞。以太坊的官方智能合约漏洞检测工具Mythril同样使用符号执行来探索所有可能的不安全路径[5]。Tikhomirov等[6]提出的SmartCheck能够将Solidity源代码转换为基于xml的中间显示,并根据XPath模式对其进行检查。Tsankov等[7]是一个为智能合约提供可扩展和全自动安全分析的静态分析工具,用于检测智能合约EVM字节码的安全属性。模糊测试工具ContractFuzzer[8]能够根据智能合约的API(application programming interface)规范生成模糊测试输入,通过EVM记录智能合约的运行状态,分析日志并报告安全漏洞。除此之外还有Echidna[9]等模糊测试工具。
这些工具主要基于形式验证、符号执行、静态分析、污染分析和模糊测试,在进行漏洞检测时依赖于固定的检测规则。存在自动化水平低、高假阳性率等缺点。随着智能合约的发展,智能合约的结构越来越复杂,漏洞的种类越来越多,基于漏洞定义的规则已经跟不上智能合约漏洞更新的速度,攻击者很容易绕过这些规则来执行攻击。
近年来,深度学习在自然语言处理、计算机视觉、语音/音频处理等各个领域都取得了显著的成功,在漏洞检测领域也已大量运用。与传统方法相比,该技术具有降低人工成本和提高检测精度的潜力。李超凡等[10]提出了一种基于注意力机制结合CNN-BiLSTM模型的病历文本分类模型。解决了中文电子病历文本分类的高维稀疏性、算法模型收敛速度较慢、分类效果不佳等问题。杨锦溦等[11]结合深度卷积生成对抗网络与深度神经网络并改进激活函数用于入侵检测,得到了较高检测率。张俊等[12]使用残差门控图卷积网络进行源代码漏洞检测,在CDISC数据集上得到了较好的总体结果。Li等[13]提出了一种基于深度学习的漏洞检测系统VulDeePecker,将双向长记忆和短记忆神经网络应用于漏洞检测。
同时不少学者探索使用深度学习模型来检测智能合约漏洞。如Yu等[14]提出了基于深度学习的智能合约漏洞自动检测框架DeeSCVHunter,并提出了漏洞候选切片的新概念,帮助模型捕捉漏洞的关键点。Goswami等[15]提出了一种检测工具TokenCheck,使用单一LSTM(long short term memory)神经网络进行特征提取,在以太网智能合约数据集ERC-20上进行了测试,获得了良好的结果。Ashizawa等[16]提出了一种基于机器学习的静态分析工具Eth2Vec。它通过自然语言处理的神经网络自动学习易受攻击的智能合约字节码的特征。Huang等[17]开发了基于多任务学习的智能合约漏洞检测模型。通过设置辅助任务,学习更多的定向漏洞特征,提高模型的检测能力。Wang等[18]提出了一种新的方法AFS (AST fuse program slicing)来融合代码特征信息。AFS可以将来自AST的结构化信息与程序切片信息融合,通过学习新的漏洞签名信息来检测漏洞。Mi等[19]提出了一个新的框架VSCL(automating vulnerability detection in smart contracts with deep learning),该框架使用基于度量学习的DNN(deep-learning neural network)对智能合约中的漏洞进行检测。此外,通过CFG(control flow graph)提取生成新的特征矩阵来表示智能合约,并使用Ngram和TF-IDF(term frequency-inverse document frequency)对操作进行编码。Wu等[20]采用基于关键数据流图信息的智能合约表示方法,在进行智能合约漏洞检测之前,先捕获合约的关键特征,同时在训练过程中避免过拟合,提出了一种新的工具Peculiar。Pecialier通过利用关键数据流图技术提高了检测性能,但构建关键数据流的过程很复杂。Zhuang等[21]在智能合约中使用图神经网络进行漏洞检测,可以检测出时间戳依赖漏洞等3种类型漏洞。Zhang等[22]提出了一种基于信息图和集成学习的智能合约漏洞检测方法。张光华等[23]提出了一种基于BiLSTM(bi-directional long short-term memory)和注意力机制的漏洞检测方法,并通过大量的实验证明该方法可以达到更好的精度。Liu等[24]提出了一种可解释的方法,将深度学习与专家模式模型相结合,用于智能合约漏洞检测。该模型可以获得细粒度细节和权重分布的可解释全景图,其通过实验表明盲目地将源代码视为序列并不一定适合于漏洞检测任务。
这些方法大多是为了改进智能合约的处理而进行优化的,而且它们本质上都是使用单网络结构模型。不同类型的网络结构在提取抽象特征和语义特征时关注点不同,单一的网络结构可能会因为对智能合约的语义和句法信息学习不足而存在关键信息提取不完全的问题,因此考虑从网络结构的角度来探讨混合网络结构的特征提取是否会对智能合约的漏洞检测性能产生良好的影响。
基于上述研究背景,现提出一种高效的双通道模型DBTA来检测智能合约漏洞。该模型将改进CNN-BiGRU和图传递神经网络以并行方式形成两个通道分别提取特征,利用注意力机制将特征加强,最后通过全连接层输出。
1 基于双通道的漏洞检测模型
该模型包含改进DCNN-BiGRU、MPNN两个通道模块以及注意力模块,其中DCNN-BiGRU模块将源代码视为序列,MPNN模块将源代码建模为图并采用图神经网络。整体框架如图1所示。

Vi为关键函数调用或变量;ei为执行顺序图1 基于双通道的智能合约漏洞检测模型框架Fig.1 Dual-channel smart contract vulnerability detection model framework
(1)DCNN-BiGRU模块:输入数据是经过词法分析和向量化的智能合约数据集。首先,使用词嵌入模型Word2vec将预处理后的合约代码转换为词向量。然后利用DCNN获取输入信息的局部特征。为了提取更全面的局部信息,2个卷积层采用不同大小的卷积核从而获得不同距离词序列之间的特征。在DCNN后融合R-Drop方法缓解模型过拟合现象。然后将卷积后的特征矩阵输出,作为BiGRU神经网络的输入。用BiGRU获取输入信息的全局特征。接下来是全连接层作为输出层,并在其中再一次使用R-Drop。
(2)MPNN模块:将图归一化方法得到归一化后的图输入消息传递神经网络,得到输出向量。
(3)注意力模块:将两个通道的特征经过注意力模块处理后进行拼接,输入全连接层中,最后使用sigmoid函数进行分类。
1.1 改进DCNN-BiGRU
1.1.1 DCNN
DCNN[25]网络层由卷积和池化构成。该卷积结构将宽卷积层和动态k-max池化层交替使用。其中宽卷积相比窄卷积可以更有效提取句子的句首和句尾信息,folding折叠操作用于缩小特征图。
受残差网络启发,本文研究对DCNN模型进行改进,使用两个卷积层进行局部特征学习。第二层卷积根据第一层卷积的输出学习一个非线性表示,然后将学习到的表示与只经过一层卷积的输出结果通过如残差形式合并连接,得到输出向量。改进前后的具体模型结构如图2所示。

图2 DCNN 改进前后结构图Fig.2 DCNN structure before and after improvement
DCNN使用一维宽卷积,最大可能地保留句子中的所有信息,以提高最后分类的准确性。为保持卷积后输出序列的长度不变采用zero-padding法进行0值填充。矩阵X表示卷积层的输入,使用卷积核K与X中每一个连续子序列做点积运算,每个特征ci表示为
ci=f(KXi:i+k-1+b)
(1)
式(1)中:Xi:i+k-1为k个词向量首尾串接矩阵;f为非线性激活函数;b为偏置矩阵。
对各个窗口进行卷积操作得到对应特征图C,可表示为
C={c1,c2,…,cn-k+1}
(2)
卷积后去除folding层。考虑到动态k-max pooling层输出向量维度不固定,因此简化为最大池化层,取池化窗口内每个维度的最大特征值。
(3)
该层允许基于样本的参数离散化,以降低特征维数,从而减少训练时间和防止过拟合。在卷积计算中,使用ReLU函数作为激活函数保证神经网络的非线性。Flatten扁平化层完成从卷积层到全连接层的过渡。全连接层作用是降低输出向量的维数。
1.1.2 BiGRU
循环神经网络具有记忆功能,在处理顺序方面表现良好。与LSTM相比,GRU增加了一个更新门取代LSTM中的遗忘门和输入门,大大简化了网络的结果和参数,从而提高了模型的训练速度。考虑到智能合约之间的语义结构复杂,预测结果可能同时受到过去时刻和未来时刻输入的影响,因此选择双向门控循环(BiGRU)网络进行时间建模,进一步增强模型的特征提取能力。BiGRU是一个由两个方向相反的GRU共同决定的神经网络模型。单个GRU的隐藏状态ht计算公式为
rt=σ(Wr[ht-1,xt]+br)
(4)
zt=σ(Wz[ht-1,xt]+bz)
(5)
(6)
(7)


(8)
(9)
(10)
FBiGRU=(h1,h2,…,ht)
(11)
式中:wt和vt为隐层在t时刻不同方向间的权值;bt为t时刻可训练参数向量。
1.1.3 R-Drop
通常情况下,联合使用CNN和RNN的过拟合概率较高,在测试集中表现较差。在训练过程中通常采用dropout等正则化方法来防止过拟合和提高深度模型的泛化能力。
dropout在神经网络的每一层随机丢弃部分单元,给网络带来了一定程度的随机性,容易造成训练阶段和测试阶段之间的不一致。因此本文研究引入R-Drop[26]进行正则化,缓解不一致性。
18-Drop思想是控制两次预测尽量保持一致,从而去优化模型。在每个批训练中,对于同一个数据样本前向传播两次,通过Dropout得到两个不同但差异很小的概率分布。R-Drop通过最小化两个分布之间的双向Kullback-Leibler(KL)发散度迫使两个子模型输出的数据样本分布相同,实现参数更新。
R-Drop具体实现过程如下。
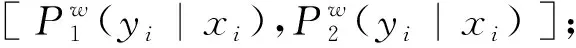
(12)

(13)
(14)
1.2 MPNN
与序列数据相比,图结构的数据能够编码对象之间丰富的句法或语义关系。在智能合约中体现在忽略了合约程序的结构信息,如数据流和调用关系。因此使用消息传递神经网络进行漏洞建模和检测。具体过程如下。
(1)消息传播阶段:在开始传递信息前用节点的特征初始化每个节点的隐藏状态。按照边的执行顺序依次传递信息,每个时间步传递一条边。具体公式为
xk=hsk⊕tk
(15)
mk=Wkxk+bk
(16)
式中:⨁表示串联操作;矩阵Wk和偏置向量bk是网络参数;原始消息xk包含来自ek的起始节点的隐藏状态hsk和边ek自身的信息tk,然后使用Wk和bk将其转换为向量表示。在接收到消息之后,ek的结束节点通过聚合来自传入消息的信息mk及其先前状态来更新其隐藏状态hek。hek更新公式为
(17)
(18)
式中:U、Z、R为矩阵;b1和b2为偏置向量。

(19)
式(19)中:f为映射函数,如神经网络;|V|为主要节点的数量。
1.3 注意力机制
由于序列特征和全局图特征存在差异,自注意机制通过计算所有特征的系数来学习不同特征并突出重要特征的权重,然后通过交叉注意力机制挖掘不同特征类别间的关系来预测最终结果。注意力模块图如图3所示。

Q、K、V分别为查询向量序列、键向量序列和值向量序列图3 注意力模块Fig.3 Attention module
(1)自注意力机制。假设注意力层输入序列为X=[x1,x2,…,xN],首先通过线性变换得到三组向量序列,即
(20)
式(20)中:WQ、WK、WV为可以学习的参数矩阵。最终的输出向量h为
h=softmax(QKT)V
(21)
将DCNN-BiGRU模块的输入向量X1和MPNN模块的输入向量X2两个分别经过自注意力机制得到输出向量p、q。
(22)
(23)
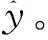
(24)
2 实验
2.1 实验数据集
本文研究重点是现有已知漏洞中的可重入性漏洞、时间戳依赖漏洞。使用SB-wild[27]数据集和ESC[21]数据集进行实验。其中SB-wild数据集总共包含约203 716个智能合约。ESC数据集包含以太坊中的40 932个智能合约。采用Smartcheck和Oyente两个工具标记所有源代码文件并获取标记的数据,同时进行人工判断,从而准确判断智能合约内包含的漏洞类型。最终数据集包含的漏洞数量如表1所示。

表1 数据集漏洞数量统计Table 1 Vulnerability count statistics
2.2 实验环境与参数设置
本文模型基于Keras深度学习框架,所有实验都是在一台Intel Core i7和32 GB内存的计算机上进行的。实验的运行环境为Windows 10。显卡型号为NVIDIA GeForce RTX 3090。
为了验证本文方法的效果,随机将70%的数据集分割为训练集,剩余的30%为验证集。从模型参数选择方面对模型进行优化。其中损失函数为二分类交叉熵损失,优化器选择Adam算法。学习率在[0.000 1,0.000 5,0.001,0.002,0.005]中调整选择。为了防止过拟合,R-drop内dropout在[0.2,0.4,0.6,0.8]内调整选择。此外,词向量维度选择区间为[200,300,400,500]。经过对比最终模型参数设置如表2所示。

表2 模型参数设置Table 2 Setting of model parameters
2.3 预处理
数据需分别经过词向量转化和图转化。
2.3.1 向量化
DCNN、BiGRU等深度神经网络通常以向量作为输入,因此需要将智能合约代码片段表示为语义上有意义的向量。首先,将定义的变量和函数转换为符号名称,如var1、var2、fun1、fun2。然后通过词法分析对合约片段进行划分。
在进行分词操作后,通过word2vec转换为向量。该工具是使用浅层神经网络学习单词嵌入的最流行的技术之一,它将标记映射到一个整数,然后将该整数转换为一个固定维数的向量。由于合约片段词数不固定,因此转换后的相应向量可能具有不同的长度。为了取等长度的向量作为输入,当长度小于固定维数时,将零填充到向量的末尾;当长度超过固定维数时,截断向量的结束部分。
2.3.2 图归一化
程序源代码被转换为图表示能够保持代码间的语义关系。因此根据程序语句之间的数据依赖和控制依赖,将智能合约的源代码描述为图,其中的节点表示关键函数调用或变量,边表示执行顺序。
节点可分为主要节点和次要节点。其中主要节点表示对自定义或内置函数的调用,这些函数对于检测特定漏洞非常重要。例如,对于可重入漏洞,一个主要节点对传输函数或内置call.value函数的调用进行建模。对于时间戳依赖漏洞,内置函数调用block.timestamp被提取为主要节点。次要节点用于建模关键变量。
节点之间的关系通过构造边来建模。每个边描述了被测试的合约函数可能经过的路径,并且边的顺序表征了它在函数中的执行顺序。具体为边的特征被提取为元组(Vs,Ve,o,t),其中Vs和Ve为其起始节点和结束节点,o为其时间顺序,t为边类型。为了捕获节点之间丰富的语义依赖关系,构建了4种类型的边,即控制流、数据流、前向和后退边。语义边的详细信息如表3所示。
2.4 实验结果
本次实验的评价指标为精确率(Accuracy)、查全率(Recall)、准确率(Precision)、精度-召回率权衡(F1-score)。通过消融实验和对比实验验证本文方案的性能。
2.4.1 消融实验
为了比较各个模块对模型检测效果的影响,通过对比BiGRU、MPNN、DCNN、DCNN-BiGRU和DBTA等模型的漏洞检测性能,验证本文模型的有效性。其中DCNN-BiGRU(dropout)模型表示使用dropout正则化方法,DCNN-BiGRU(R-Drop)表示使用R-Drop正则化方法。DBTA(FC)表示直接经过全连接层而不经过注意力层。实验结果如表4所示。

表4 消融实验的实验结果Table 4 Experimental results of ablation experiments
在可重入性漏洞检测中,使用R-Drop正则化方法后DCNN-BiGRU模型的评价指标提升1%至2%。DCNN-BiGRU(R-Drop)方法的准确率可达79.42%,召回率可达78.99%,F1得分可达98.7%。在未引入注意力机制层时,DBTA(FC)的准确率可达87.96%,召回率可达87.63%,F1得分可达87.79%。DBTA的准确率最高,达到79%。在时间戳依赖漏洞检测中,DBTA较其余模型准确率、F1得分同样有所提升。实验结果表明,R-Drop正则化方法可以提高模型的有效性,特别是准确性和F1得分的整体有效性。此外,注意力机制更有利于特征提取,能够进一步提高模型的有效性。
为了演示提出方法的检测性能,绘制了如图4和图5所示的准确率和损失函数值随迭代次数变化图。随着epoch数的增加,精度和损失相应增加或减少。在40个epoch后趋于平稳。从结果中可以得出结论,基于本文的检测方法在检测中取得了较好的检测性能。

图4 准确率曲线图Fig.4 Accuracy graph
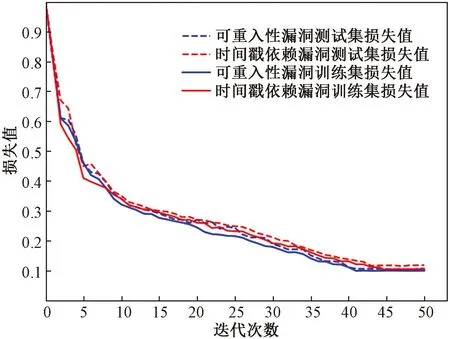
图5 损失函数曲线图Fig.5 Loss function graph
2.4.2 对比实验
为了客观地评估本文提出模型的性能,将本文模型与已有的智能合约漏洞检测方法进行比较。包括4种传统的检测方法(Oyente、Securify、Mythril和SmartCheck)以及4种基于深度学习的方法(LSTM、TMP、AME、BLSTM-ATT)。实验结果如表5所示。
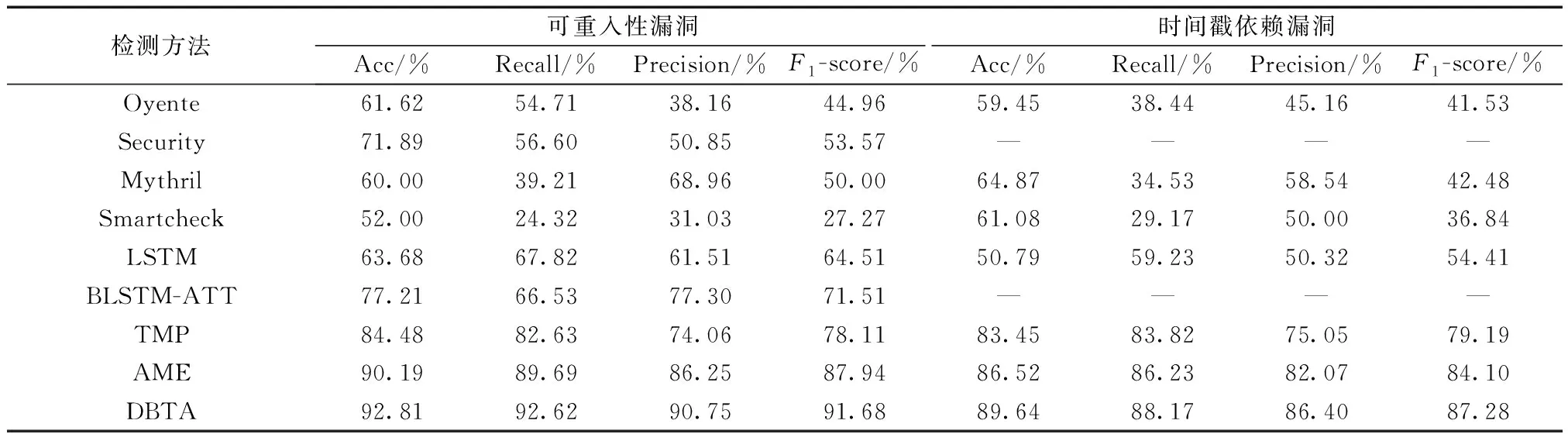
表5 对比实验的实验结果Table 5 Experimental results of comparative experiments
由表5可以看出,传统的漏洞检测方法各项指标较低。在可重入性漏洞检测中,DBTA方法的F1得分最高,为91.68%,Smartcheck方法的F1得分最低,为27.27%;在时间戳依赖漏洞检测中,DBTA方法的F1得分达到87.18%,最低的Smartcheck则为36.84%。这表明在更有针对性的数据集中,本文模型DBTA具有明显优势。与LSTM、GRU、TMP、AME等现有深度学习模型相比,DBTA同样具有更好的性能。其中TMP考虑了数据流和控制流引起的时间信息,使得模型效果相比LSTM、GRU有了大幅提升。AME融合专家特征和图神经网络,使得准确率达到了86.25%和82.07%。而本文模型DBTA结合了不同类型的网络结构使得模型在两类漏洞检测的准确率分别达到了90.19%和86.40%。
3 结论
带有漏洞的智能合约可能出现严重的安全问题,因此提出了一种基于双通道的智能合约漏洞检测方法,通过融合不同深度学习方法改变网络结构来优化模型的检测能力。与现有方法相比,结合了传统词向量特征和图特征,考虑了程序元素之间的丰富依赖关系。
通过实验证明,本文提出的DBTA模型结合了不同深度学习的优点,具有较好的检测性能。得出如下结论。
(1)融合动态卷积神经网络、双向门控递归单元和图神经网络并应用于网络安全中的漏洞检测领域。
(2)改进DCNN,提出改进DCNN-BiGRU模型,提升漏洞检测能力。
(3)引入了简单有效的正则化方法R-Drop,以防止模型过拟合,同时提升模型的泛化。
(4)运用注意力机制对改进DCNN-BiGRU和MPNN所提取的特征分配权重,关注关键特征。
(5)结合以上工作进行多次实验验证本文方法的有效性。
大量的实验表明,本文方法能够较为准确地识别出可重入性漏洞和时间戳依赖漏洞。在未来,将收集更多的数据集对其余类型的智能合约漏洞进行检测。
