多数据所有者场景下具有访问模式和搜索模式隐私的对称可搜索加密方案*
2024-01-11侯欣怡刘晋璐
侯欣怡, 刘晋璐, 张 茜, 秦 静
山东大学 数学学院, 济南250100
1 引言
随着云计算的发展[1]和对个人数据便捷存储需求的激增, 越来越多的组织和个人倾向于将数据外包到云服务器.为了保证外包数据的安全性, 数据所有者需要对外包数据加密.但是一般的加密方案不具有搜索功能, 如果数据用户不能有选择地检索他们需要的数据片段, 那么就丧失了云数据存储的优势.可搜索加密技术允许数据用户在密文数据库上执行搜索操作.数据所有者首先将加密文件和搜索索引上传到服务器存储, 之后数据用户向服务器发送对关键词的加密问询, 服务器在索引上安全地执行搜索操作, 并将与问询匹配的加密文件返回给客户端, 由客户端执行解密.Song 等人[2]首先给出能够在密文上搜索的SSE 方案.Goh 等人[3]给出一个基于布隆过滤器(Bloom filter, BF) 的SSE 方案.之后, Curtmola 等人[4]给出一个改进的安全性定义并构造了满足新定义的SSE 方案.后续工作[5–8]对SSE 方案的安全性、效率和功能性进行了进一步研究.
现有的SSE 方案[3–8]以一些泄漏为代价获得了效率, SSE 中的泄露包括访问模式和搜索模式.访问模式泄露了搜索陷门和被匹配文件之间的关系, 搜索模式泄露了搜索陷门中是否包含相同的关键词.近年来的研究表明, 半诚实的服务器利用暴露的访问和搜索模式能够恢复加密的搜索关键词[9–13].Liu 等人[9]的研究表明, 通过利用搜索模式, 云服务器能够从用户的搜索习惯中推断出搜索的关键词.研究表明[10–12], 通过利用访问和搜索模式, 云服务器能够使用关于文件的一些先验知识来导出文件中的关键词.Zhang 等人[12]给出了一个文件注入攻击,使用20%的文件先验知识能够实现70%的关键字恢复准确率.Oya 等人[13]提出了一种利用访问和搜索模式泄漏以及一些背景和查询分布信息的攻击, 能够恢复数据用户搜索的关键字.动态对称可搜索加密(dynamic symmetric searchable encryption, DSSE) 方案[14–16]允许对外包的加密数据进行阶段性更新, 但是一个半诚实的云服务器可以通过观察特定用户对数据库的更新操作来推断更敏感的信息, 另外, 关键词的更新频率也可以用于推导访问模式.
一个解决访问和搜索模式泄露问题的方法是不经意随机访问机制(oblivious random access mechanism, ORAM)[17], ORAM 通过在访问数据时不断洗牌和重新加密数据来隐藏访问模式.直接将ORAM与SSE 结合构造的隐藏访问模式的SSE 方案需要巨大的通信和计算开销.两轮不经意随机访问机制(two rounds oblivious random access mechanism, TWORAM)[18]是一种基于ORAM 的SSE 方案, 需要至少四轮通信.另外一种解决访问和搜索模式泄露问题的方法是基于隐私信息检索(privacy information retrieval, PIR)[19]技术的方案, 在从一个数据库中读取一个文件时也能够完全隐藏访问模式, 但是同样需要巨大的通信和计算开销.
Chen 等人[20]给出了一个与任意SSE 方案兼容的差分隐私混淆架构, 应用该架构的SSE 方案能够隐藏访问模式, 结果是服务器只会得到一个混淆的访问模式.但是, 由于混淆访问模式是固定的, 因此问询相同的关键词时总会产生相同的混淆访问模式, 服务器通过检查混淆访问模式是否相同就能够判断加密问询的潜在关键词是否相同, 这就向服务器泄露了搜索模式.
Shang 等人[21]给出了一个能够同时隐藏访问和搜索模式的对称可搜索加密方案, 称为混淆SSE(obfuscated symmetric searchable encryption, OSSE).OSSE 通过为每一次关键词问询提供一个全新的混淆访问模式来隐藏搜索模式.OSSE 在每一次关键词问询中, 会为每一个要搜索的文件生成一个专门的搜索陷门, 因此发送给服务器的搜索陷门数量与搜索的文件数量呈线性关系.另外, 由于OSSE 中加密索引和生成关键词搜索陷门时使用的是相同的密钥, 因此如果想要在不同密钥生成的文件索引上搜索, 需要使用与加密索引对应的密钥分别生成搜索陷门(且每一个密钥生成的搜索陷门数量与使用该密钥生成的文件索引数量呈线性关系), 因此OSSE 不适用于多数据所有者场景.
上述SSE 方案都是在一个单一的数据所有者上传的加密文件上进行搜索的场景, 一个更实际的场景是, 数据用户能够搜索不同数据所有者上传的加密文件.对此, 有两种直接的关键词问询方式: (1) 数据用户为每一个索引产生一个搜索陷门, 这使得发送给服务器的搜索陷门数量与云服务器上存储的文件总数呈线性关系, 这会造成巨大的通信开销; (2) 所有数据所有者使用同一个密钥加密文件索引, 这一方法显然缺乏安全保证.因此, 需要专门为多数据所有者场景设计可搜索加密方案, 即只需要一个单一的搜索陷门, 就能够在不同密钥加密的索引上搜索.Popa 等人[22]给出了一个多密钥可搜索加密方案, 解决了多数据所有者场景下可搜索加密问题, 数据用户只需要向服务器发送一个单一的关键词搜索陷门, 就能够在不同密钥加密的索引上搜索.Zhang 等人[23]给出了多数据所有者模型下的隐私保护的多关键词排序搜索系统.Sun 等人[24]针对Zhang 等人[23]方案中存在的关键词猜测攻击和等价测试攻击的问题进行了改进, 给出了一个能够抵抗上述两种攻击的多数据所有者场景下的多关键词排序搜索方案.He 等人[25]给出了一个基于属性的可搜索加密方案, 能够在多数据所有者系统中实现布尔关键词搜索.Miao 等人[26]提出了一种新的共享多数据所有者场景, 在共享多数据所有者系统中, 多个数据所有者能够共同维护一个文件, 他们给出了一个共享多数据所有者场景下访问策略隐藏的密文策略基于属性的关键词搜索系统.Ge等人[27]给出了一个多数据所有者系统中密文策略基于属性的关键词搜索和数据共享方案, 在数据共享过程中支持密文中的关键词和访问策略的更新.
本文给出一个多数据所有者场景下能够同时隐藏访问和搜索模式的SSE 方案.本文方案中, 数据所有者生成文件索引时, 将误报(返回文件中不包含问询的关键词) 和假阴性(包含问询关键词的文件没有被返回) 植入到每一个文件索引中.在关键词问询过程中, 数据用户发送给服务器的关键词加密问询能够以一种对服务器保密的方式概率地触发文件索引中的误报和假阴性, 这就为每一次关键词问询产生了一个全新的混淆访问模式, 从而同时隐藏了访问和搜索模式.另外, 本文方案适用于多数据所有者场景, 即问询者只需要向服务器发送一个单一的搜索陷门, 就能够在不同密钥加密的索引上搜索.
本文方案的主要贡献如下:
• 借助内积谓词加密和近似同态加密构造一个新的对称可搜索加密方案, 其主要特征为: (1) 能够同时隐藏访问和搜索模式; (2) 适用于多数据所有者场景, 即数据用户只需要向服务器发送一个单一的关键词搜索陷门, 就能够在不同密钥加密的索引上进行搜索.
• 证明本文给出的对称可搜索加密方案具有自适应的不可区分安全性, 并且方案具有访问和搜索模式的差分隐私性.
• 在具有代表性的真实世界数据集上对方案进行实验, 说明了本文方案的实用性.
本文结构如下: 第2 节介绍相关预备知识; 第3 节介绍本文方案的系统模型以及安全定义; 第4 节给出具体方案; 第5 节对本文方案的安全性进行分析; 第6 节对本文方案的复杂度进行分析并在一个真实数据集上进行实验.
表1 比较了本文方案与一些其他SSE 方案.

表1 现有工作对比Table 1 Comparison of existing works
2 预备知识
2.1 对称可搜索加密
设一个数据所有者持有的文件集合为D={D1,D2,···,Dn},D[i] 表示D中第i个文件, indi表示D[i] 的标识符, 这里假设文件标识符(identity, id) 与文件内容独立.设D[i] 的关键词列表为Wi, 设关键词域为Δ={w1,w2,···,w|Δ|},|Δ| 为关键词域的大小, 则有Wi ⊆Δ,1≤i ≤n.设D(w) 表示所有包含关键词w的文件按照id 的顺序组成的文件列表.
下面给出SSE 方案的定义.
定义1 一个SSE 方案是以下4 个多项式时间算法的集合:

下面借用Curtmola 等人[4]给出的SSE 方案的安全定义, 其中为了定义SSE 的安全性给出历史记录、访问模式、搜索模式和轨迹的概念.
数据用户和服务器之间的交互由一个文件集合和一个数据用户想要搜索的关键词序列决定, 文件集合和问询的关键词序列都需要向敌手隐藏.上述这一交互的实例化称为历史记录.正式地, 一个文件集合D上的q-问询历史记录是一个二元组H={D,w}, 包括文件集合D和一个包含q个关键词的向量w=(w1,w2,···,wq).
访问模式是指一个历史记录中的每一个关键词对应的文件id.
定义2 (访问模式) 文件集合D上的访问模式α(H) 由一个q-问询历史记录H={D,w}诱导得出, 是一个元组(D(w1),D(w2),···,D(wq)), 也可以表示成一个大小为q×n的二元矩阵α(H), 使得
即如果第i行对应的关键词wi包含在第j列对应的文件D[j] 中, 则矩阵α(H) 位置[i,j] 处的值为1,否则为0.
搜索模式反映了哪些搜索陷门对应历史记录中相同的关键词.
定义3 (搜索模式) 文件集合D上的搜索模式σ(H) 由一个q-问询历史记录H={D,w}诱导得出, 是一个大小为q×q的二元矩阵α(H), 使得
wi=wj表示第i行对应的关键词wi与第j列对应的关键词wj相同, 反之,wi ̸=wj表示不同.
一个历史记录的轨迹包括能够泄露的关于历史记录的信息, 具体来说包括访问和搜索模式、文件大小和标识符, 除此以外不包含其它任何信息.
定义4 (轨迹) 文件集合D上的轨迹τ(H) 由一个q-问询历史记录H={D,w}诱导得出, 是一个序列
2.2 差分隐私
差分隐私(differential privacy, DP)[28]是一个重要的隐私性的理论概念, 已经被广泛地应用于数据库隐私中[20,29].差分隐私以一个隐私参数ε为特征, 它保证了隐私保护算法的相邻输入产生任意给定输出的概率是相近的, 因此通过观察算法的输出很难获得关于秘密输入的信息.借用Shang 等人[21]定义的SSE 中访问模式泄露和搜索模式泄露的差分隐私性.用函数SE表示一个SSE 方案, 其输入为一个文件集合D和一个关键词问询向量w, 输出为一个轨迹τ(H), 其中H表示一个历史记录H={D,w}.
定义5 (访问模式的差分隐私性) 一个由函数SE刻画的SSE 方案的访问模式具有ε-差分隐私性(ε-DP), 当且仅当对任意一个长度为q的关键词问询向量w ∈Δq, 对任意一对相邻文件集合D,D′⊆22Δ(只在第i个文件中的关键词w处不同, 其余位置处的关键词相同, 即w要么在D[i] 中, 要么在D′[i] 中,但不会同时在两者之中, 而D[i] 和D′[i] 其余位置的关键词以及D和D′中的其余文件完全相同), 以及对任意的轨迹τ(H), 成立
上述定义保证了给定轨迹(允许泄露的信息) 不能决定一个文件是否包含一个关键词, 这意味着具有ε-差分隐私性的文件也具有访问模式隐私.
定义6 (搜索模式的差分隐私性) 一个由函数SE刻画的SSE 方案的搜索模式具有ε-差分隐私性, 当且仅当对于任意一个数据集合D ⊆22Δ, 任意一对相邻的关键词问询向量w,w′∈Δ|w|(w和w′只有一个元素不同, 即w[i]̸=w′[i]), 以及对任意的轨迹τ(H), 成立
d表示D(w[i]) 和D(w′[i]) 中不同文件的数量.
上述定义保证了通过观察轨迹(允许泄露的信息) 不能确定客户端搜索的是哪一个关键词列表.这意味着搜索模式的隐私性, 即服务器不能猜测自己执行的两个问询是否包含相同的关键词.
2.3 对称加密
一个对称加密方案SE=(Gen,Enc,Dec) 由三个算法组成.密钥生成算法Gen 能够概率地输出一个密钥k ∈K,K是密钥空间; 加密算法Enc 输入一个密钥k ∈K和一条消息m ∈M, 能够输出一个密文c ←−Enck(m), 其中M是明文空间; 解密算法Dec 输入一个密钥k ∈K和一条密文c ∈C, 能够输出一条明文m ←−Deck(c), 其中C是密文空间.

是可忽略的.
2.4 隐私谓词加密
内积隐私谓词加密(inner product predicate encryption,IPE)方案涉及一个谓词函数P:A×B−→{0,1}, 其中A = B = Zlt,t是一个大质数, A 和B 分别称为属性向量空间和谓词向量空间.对于所有的x,y ∈Zlt, 如果〈x,y〉=0, 则P(x,y)=1,〈·,·〉 表示计算两个向量之间的内积.
一个IPE 方案由四个算法组成: (pp,SK)←−IPE.Setup(1λ) 中给定安全参数λ, 算法输出系统参数pp 和私钥SK; ctx ←−IPE.Encrypt(pp,SK,x,M) 中给定系统参数pp、私钥SK、属性向量x ∈A 和一条消息M, 输出x的密文ctx; sky ←−IPE.KeyGen(pp,SK,y) 中给定系统参数pp、私钥SK、谓词向量y ∈B, 输出对y的加密sky;M/⊥←−IPE.Decrypt(pp,ctx,sky) 中给定系统参数pp、属性向量和谓词向量的密文ctx和sky, 输出消息M或者错误符号⊥.
称IPE 方案是正确的, 如果对所有的λ ∈N,x ∈A,y ∈B, 对于(pp,SK)←−IPE.Setup(1λ),ctx ←−IPE.Encrypt(pp,SK,x,M) 和sky ←−IPE.KeyGen(pp,SK,y), 下式成立
IPE 中涉及三种安全性需求: 负载隐藏、属性隐藏和谓词隐藏.下面分别使用负载隐藏游戏、属性隐藏游戏和谓词隐藏游戏定义这三种安全性[31].
谓词函数P: A×B−→{0,1}的负载隐藏安全性由一个挑战者C和一个敌手A之间的游戏来定义.负载隐藏安全性保证了密文不会暴露关于被加密的消息的任何信息.
(1) 负载隐藏游戏
• 建立阶段: 挑战者C运行IPE.Setup(1λ) 产生系统参数pp 和私钥SK.将pp 发送给敌手A, 并秘密保管私钥SK.
• 问询阶段1:A能够对下列预言机进行多项式次数的问询:
– KeyGenOKey(y) :A发送一个关于y ∈B 的问询, 返回一个私钥sky ←−IPE.KeyGen(pp,SK,y).
– EncryptOEnc(x) :A发送一个关于x ∈A 和消息M的问询, 返回一个密文ctx ←−IPE.Encrypt(pp,SK,x,M).
• 挑战阶段: 敌手A向挑战者C提交一个x∗∈A 和两个长度相同的消息M0,M1.要求对所有在问询阶段1 中问询过预言机OKey的y ∈B 满足P(x∗,y)=0.C随机选择b ∈{0,1}, 返回一个挑战密文ctx∗←−IPE.Encrypt(pp,SK,x∗,Mb).
• 问询阶段2: 这一阶段与问询阶段1 相同, 但A只被允许向预言机OKey问询满足P(x∗,y) = 0的y ∈B.
• 猜测: 敌手A输出一个比特b′, 如果b′=b则赢得游戏.
敌手赢得上述负载隐藏游戏的优势被定义为
定义7 (IPE 的负载隐藏) 称IPE 是负载隐藏的, 如果不存在概率多项式时间的敌手A能够以一个不可忽略的优势赢得上述负载隐藏游戏.
下面通过一个挑战者C和一个敌手A之间的游戏来定义IPE 属性隐藏安全性.属性隐藏安全性保证了敌手不能通过密文ctx获得关于属性x ∈A 的任何信息.
(2) 属性隐藏游戏
• 建立阶段、问询阶段1、问询阶段2 和猜测与负载隐藏游戏相同.
• 挑战阶段: 敌手A向挑战者C提交两个属性x(0),x(1)∈A 和一个消息M.要求对所有在问询阶段1 中问询过预言机OKey的y ∈B 有P(x(0),y) =P(x(1),y).C随机选择b ∈{0,1}, 返回一个挑战密文ctxb ←−IPE.Encrypt(pp,SK,x(b),M).
敌手赢得上述属性隐藏游戏的优势被定义为
定义8 (IPE 的属性隐藏) 称IPE 是属性隐藏的, 如果不存在概率多项式时间的敌手A能够以一个不可忽略的优势赢得上述属性隐藏游戏.
下面通过一个挑战者C和一个敌手A之间的游戏来定义IPE 谓词隐藏安全性.谓词隐藏安全性保证了敌手不能通过私钥sky获得关于谓词y ∈B 的任何信息.
(3) 谓词隐藏游戏
• 建立阶段、问询阶段1、问询阶段2 和猜测与负载隐藏游戏相同.
• 挑战阶段: 敌手A向挑战者C提交两个属性y(0),y(1)∈B, 要求对所有在问询阶段1 中问询过预言机OEnc的x ∈A 有P(x,y(0)) =P(x,y(1)).C随机选择b ∈{0,1}, 返回一个挑战私钥sky(b)←−IPE.KeyGen(pp,SK,y(b)).
敌手赢得上述属性隐藏游戏的优势被定义为
定义9 (IPE 的谓词隐藏) 称IPE 是谓词隐藏的, 如果不存在概率多项式时间的敌手A能够以一个不可忽略的优势赢得上述谓词隐藏游戏.

2.5 基于近似同态加密的打包加密
近似同态加密(somewhat homomorphic encryption, SHE) 是一种支持在密文上进行有限次加法和乘法运算的公钥加密方案.Yasuda 等人[34]给出了一个基于SHE 的打包加密方式, 他们给出的打包方式能够高效计算向量内积.本文方案借助文献[34] 中的打包加密产生关键词的加密问询.
SHE 方案涉及一个基本环R=Z[x]/(f(x)), 其中f(x)=xn+1 是n阶的分圆多项式,n是2 的幂次.SHE 的密文空间是基本环Rq=R/qR=Fq[x]/(f(x)), 其中q是一个质数, 有q ≡1(mod 2n).SHE 的明文空空间为Rt=Ft[x]/(f(x)),t <q是一个整数.SHE 还涉及一个标准差为σ的离散高斯错误分布χ=DZn,σ.

s选自噪声分布χ,ai是Rq中的一个均匀随机元素, “错误多项式”ei选自错误分布χ,ui是Rq中一个均匀随机的环元素.c≈表示计算不可区分.
定义10 (两种打包加密PackEncrypt)[34]对于一个长度为n的向量A=(A0,A1,···,An−1)∈Znt,定义两种类型的打包密文:
(1) 设pm1(A) = ∑n−1i=0Aixi, 对于足够大的t, 可以将多项式pm1(A) 认为是Rt中的元素.然后,定义ctpack(1)(pm1(A))←−SHE.Encrypt(pm1(A),pk) 为第一种类型的打包密文.
(2) 设pm2(A) =−∑n−1i=0Aixn−i, 定义ctpack(2)(pm2(A))←−SHE.Encrypt(pm2(A),pk) 为第二种类型的打包密文.
定理 1 (打包密文上的安全内积计算)[34]对于两个长度为n的向量A,B, 设密文 ct 为ctpack(1)(pm1(A)) 和ctpack(2)(pm2(B)) 之间的同态乘积.定义m0为解密结果SHE.Decrypt(ct,sk)∈Rt中的常数项, 则m0=〈A,B〉modt, 即解密结果中的常数项是向量A,B的内积.
注意到, 对于两个向量A= (A0,A1,···,An−1) 和B= (B0,B1,···,Bn−1).计算A的第一种类型的打包密文ctpack(1)(pm1(A)) = (c0,c1), 并计算B按照第二种类型打包后得到的多项式pm2(B)·ctpack(1)(pm1(A)) = pm2(B)·(c0,c1) = (pm2(B)·c0,pm2(B)·c1), 调用SHE.Decrypt 对其解密后得到的多项式的常数项也为〈A,B〉.
2.6 伪随机函数和伪随机生成器
定义11 (伪随机函数(pseudorandom functions, PRF))[36]一个PRFF:K×X −→Y是一个定义在密钥空间K、一个域X和一个范围Y上的带密钥的函数(这些集合被安全参数λ参数化),F的输出与一个真正的随机值不可区分.一个PRF 的安全性由两个与敌手A的实验EXP(0) 和EXP(1) 定义.首先从密钥空间K中均匀随机选择一个密钥k, 给定对PRF 的描述, 敌手被允许对以下预言机进行问询:
−Evaluate:A输入x ∈X, 返回F(k,x).
−Challenge:A输入x ∈X,要求x没有在Evaluate 预言机中被问询过.如果b=1,返回F(k,x);如果b=0, 预言机返回一个随机值y ∈Y.
敌手完成对上述预言机的问询后, 输出一个比特b′∈{0,1}.定义Wb为敌手在实验EXP(b) 中输出b′=1 的事件.敌手A的优势定义为
称一个PRF 是安全的, 如果对于所有PPT 敌手A, AdvPRFA(1λ) 是可忽略的.
定义12 (密钥同态的PRF (key-homomorphic PRF))[37]设(K,◦) 和(Y,∗) 是群.称一个带密钥的函数F:K×X −→Y是一个密钥同态的PRF, 如果
(1)F是一个安全的PRF;
(2) 对于任意的k1,k2∈K和x ∈X, 有
定义13 (伪随机生成器(pseudorandom generators, PRG))[37]一个PRG 是一个高效的可计算的函数G:X −→Y, 其中(X,◦) 和(Y,∗) 是群.称一个PRG 是安全的, 如果对于任意的PPT 算法A
是可忽略的.
3 模式隐藏的对称可搜索加密方案
3.1 符号说明
设Δ 表示所有可能的关键词组成的关键词域,|Δ| =s.设N个数据所有者DO ={DO1,DO2,···,DON}, 考虑一个数据所有者DO∈DO, 设其文件集合为D={D1,D2,···,Dn},D中的第i个文件D[i] 的关键词列表为Wi,1≤i ≤n,Wi中的元素满足如下条件: 对于关键词列表Δ 中的第j个关键词w=Δ[j]:
(1) 如果w ∈Wi, 则令Wi[j]=w,1≤j ≤s;
(2) 如果w/∈Wi,Wi[j]=w−1,w−1是不属于Δ 的随机元素.
这样, 对于所有的1≤i ≤n, 有|Wi|=s.另外, 小写加粗字母表示向量, 大写加粗字母表示集合, 其它符号首次出现时会进行说明.表2 概括了方案中用到的符号.

表2 方案的符号表示Table 2 Symbolic representation of scheme

表3 概率分析Table 3 Probabilistic analysis

表4 通信开销Table 4 Communication Overhead
3.2 参数说明
本文方案中, 每一次关键词问询都会产生一个混淆访问模式, 即返回的文件中有的包含问询的关键词,有的不包含问询的关键词(误报), 还有一些文件虽然包含了问询的关键词但是没有被返回(假阴性).误报和假阴性的存在会产生一些效用损失, 效用损失可以用真阳性率(true positive rate, TPR) 和误报率(false positive rate, FPR) 来刻画:
• 真阳性率(TPR) 指返回文件中包含问询关键词的概率.• 误报率(FPR) 指返回文件中不包含问询关键词的概率.
大多数情况中, 数据用户会要求尽量高的真阳性率(TPR).另外, 为了减少通信开销以及对精确度的要求, 需要尽量低的误报率(FPR).本文方案中, 文件索引中的误报和假阴性由数据用户发送的关键词搜索陷门触发, 因此数据用户能够在产生关键词搜索陷门时对TPR 和FPR 进行调节.
3.3 方案的系统框架
本文方案分为建立阶段和搜索阶段, 由三个实体组成: 诚实的数据所有者DO、数据用户U以及一个诚实且好奇的服务器S.
3.3.1 建立阶段
建立阶段由数据所有者DO 完成.这一阶段中, 不同数据所有者会使用各自的密钥生成文件索引和文件的搜索令牌列表, 对文件加密, 并将文件索引、搜索令牌列表以及加密文件上传到服务器.

在索引生成算法BuildIndex 中, 将关键词列表Wi中的元素和文件标识符indi作为多项式的根.DO 调用多项式生成函数GenPoly(Wi,indi) 生成多项式的系数向量x= (x1,x2,···,xs+2)∈Zs+2t(因为有s+ 1 个根(s个Wi中的元素和1 个文件id 作为根), 所以多项式有s+ 2 个系数), 将其作为文件的属性向量.然后使用隐私谓词加密对x和文件标识符indi ∈{0,1}m加密, 得到加密索引Ii=ctx=(c0,c1,···,cs+2)∈{0,1}m×Zs+2t.在令牌列表生成算法TokenList 中, 对于Wi中的每一个元素, DO 调用谓词生成函数GenPred(w) 生成元素w ∈Wi的谓词向量y=(y1,y2,···,ys+2)∈Zs+2t,其中yi=wi−1,1≤i ≤s+2.使用隐私谓词加密对y加密, 得到sky ∈Zt.另外, 调用GenPred 分别生成文件标识符indi和一个随机元素w−1/∈Δ 的谓词向量, 并使用隐私谓词加密对这两个谓词向量加密.上述得到的所有谓词向量的密文能够组成一个s+2 维的列表TKi ∈Zs+2t, 将其作为文件D[i] 的搜索令牌列表.
3.3.2 搜索阶段
这一阶段由数据用户U和服务器S共同完成.数据用户U使用自己的用户密钥KU生成关键词搜索陷门并发送至服务器进行关键词问询, 服务器S使用接收到的搜索陷门能够在不同数据所有者上传的文件索引上执行搜索操作并将与陷门匹配的文件返回给数据用户U.

图1 给出了本文方案的系统模型图.

图1 系统模型图Figure 1 System model diagram
3.4 方案的安全定义
根据Curtmola 等人[4]给出的安全性定义, 考虑一个挑战者C和一个敌手A=(A0,A1,···,Av+1)之间的游戏IndSSE,A(λ), 其中λ ∈N 是安全参数.
(1) 挑战者C运行(pp,KI,KDO)←−Setup(1λ,1s) 产生对称加密密钥KDO、索引密钥KI和系统参数pp; 运行KU ←−KeyGen(1λ) 产生用户密钥KU;C将pp 发送给A并公开, 保持KDO、KI和KU的隐私性, 选择一个随机比特b ←−{0,1}.
(2) 运行(stA,D0,D1)←−A0(1λ), 将两个文件集合(D0,D1) 发送给C.stA是一个字符串, 用于捕捉A的状态.
(3) 对于文件集合Db中的每一个文件,C分别运行BuildIndex 和TokenList, 产生文件索引集合Ib和令牌列表集合TKbi;C运行Cb ←−Encrypt(KDO,Db)产生密文集合Cb;C将(Ib,{TKbi},Cb)返回给A.
(4) 运行(stA,w0,1,w1,1)←−A1(stA,Ib,{TKbi},Cb) 将关键词对(w0,1,w1,1) 发送给C.
(5)C运行tb,1←−Trapdoor(KU,wb,1), 将tb,1返回给A.
(6) 对2≤i ≤v, 运行(stA,w0,i,w1,i)←−Ai(stA,Ib,{TKbi},Cb,tb,1,tb,2,···,tb,i−1), 将关键词对(w0,i,w1,i) 发送给C.
(7)C产生关键词wb,i的搜索陷门tb,i ←−Trapdoor(KU,wb,i), 将tb,1返回给A.
(8) 令tb=(tb,1,tb,2,···,tb,v), 运行b′←−Av+1(stA,Ib,{TKbi},Cb,tb).
(9) 如果b′=b, 则输出1; 否则输出0.其中限制τ(D0,w0,1,w0,2,···,w0,v) =τ(D1,w1,1,w1,2,···,w1,v).称SSE 在自适应不可区分性的意义上是安全的, 如果对于所有多项式大小的敌手A= (A0,A1,···,Av+1),v= poly(λ),赢得上述游戏的优势
是可忽略的.概率来自于对b的选择以及算法中用到的概率.
4 具体方案
4.1 建立阶段
这一阶段由数据所有者DO∈DO 运行, 受到Tseng 等人[33]利用密钥同态的PRF 构造的具有属性和谓词隐藏性的IPE 方案(下面简记为KIPE) 的启发, 建立文件D[i]∈D的搜索索引Ii, 搜索令牌列表TKi, 并对文件加密, 将Ii、TKi和加密文件上传到服务器.
设文件D[i] 的关键词列表为Wi,1≤i ≤n,Wi中元素的性质如前文所述.

4.2 搜索阶段
这一阶段由数据用户U和服务器S共同完成.利用Yasuda 等人[34]给出基于SHE 的打包加密方案生成数据用户的搜索面门.
考虑问询关键词Δ[k],1≤k ≤s.注意到, 如果Δ[k]∈D[i], 则有Wi[k]=Δ[k].
其中yid是indi的谓词向量.服务器S将ct1,ct2,ct3返回给数据用户U.
数据用户U接收到来自服务器的ct1,ct2,ct3后, 首先调用SHE.Decrypt 对ct1,ct2,ct3解密, 分别得到m1= TK[j] (j可能的取值为k,s+1,s+2),m2=〈c,y〉, 令m3= ct3.数据用户U按如下步骤计算:
在搜索阶段中, 由于搜索陷门是通过近似同态加密中的打包加密算法SHE.PackEncrypt 生成的,因此根据SHE.PackEncrypt 算法的性质, 搜索陷门能够与存储在服务器上的密文索引中的c和搜索令牌列表TKi的打包形式pm2(c) 和pm2(TKi) 直接进行同态乘操作, 从而得到计算结果(ct1,ct2,ct3), 数据用户可以通过服务器返回的(ct1,ct2,ct3) 得到搜索结果.由于在服务器的搜索过程中只在搜索陷门和密文索引之间进行了同态乘操作, 所以数据用户的搜索陷门可以在不同密钥加密的文件索引上搜索, 同时生成的陷门大小只与要求的真阳性率和误报率有关, 而与要搜索的文件数量独立.

5 安全性分析
5.1 参数分析
本文方案中, 数据用户产生的加密问询能够概率地触发文件索引中的误报和假阴性, 因此每一次关键词问询都会产生一个全新的混淆访问模式, 这样就同时隐藏了访问模式和搜索模式.
在文件索引的建立过程中, 需要向索引中添加误报和假阴性, 因此, 一个文件的索引中一共存在四种状态: 真阳性、假阳性(即误报)、真阴性和假阴性.在一次问询的过程中, 文件中的哪一种状态被触发完全由关键词搜索陷门决定.下面对一个文件索引中的4 种状态被触发的概率进行分析.

要求:
(1) TPR>FPR, 即v(PTP+PFP)>(1−v)PFP;
(2) FNR>FPR, 即vPFN>(1−v)PFP(为了减少带宽开销要求尽量低的误报率).
5.2 方案的自适应的不可区分安全性
定理2 如果方案底层的密钥同态的PRF 和PRG 是安全的, SHE 在PLWE 假设下是安全的, 对称加密方案SE 是CPA 安全的, 则本文给出的SSE 方案具有自适应的不可区分安全性.

引理1 如果方案中底层的密钥同态的PRFF是安全的, 则对于k= 1,2,···,s+2, Gamek−1与Gamek之间是不可区分的, 并且对于k′=1,2,···,s+2, Games+3+k′−1与Games+3+k′之间是不可区分的.
证明: 首先证明, 对于k=1,2,···,s+2, Gamek−1与Gamek之间是不可区分的.
假设存在一个敌手A能够以一个不可忽略的优势区分Gamek−1与Gamek,k=1,2,···,s+2.则能够构建一个挑战者C1区分定义11 中的实验EXP(0) 和EXP(1).在调用实验EXP(b) 并接收到对PRFF的描述后, 挑战者C1模拟与敌手A的游戏.
• 建立阶段: 挑战者首先从Zt中随机选择a1,···,ak−1,ak+1,···,as+2, 从X中随机选择h, 并选择一个PRGG, 将pp = (F,G) 发送给敌手A.挑战者使用h对底层实验进行挑战查询, 并获得f作为响应.
• 问询阶段1: 在这一阶段中, 敌手被允许对以下预言机进行多项式次数的问询:
– KeyGenOKey(y): 输入一个向量y=(y1,y2,···,ys+2)∈Zs+2t, 挑战者计算
并将sky返回给敌手.通过将ak设置为底层实验选择的密钥, 可知sky是一个y的有效的私钥.
– EncryptOEnc(x): 输入一个向量x=(x1,x2,···,xs+2)∈Zs+2t和一个消息M.挑战者执行以下操作:
(1) 从Zt中随机选择δ,σ.
(2) 计算ck=F(δxk,h)+f+σ.
(3) 对于i=1,···,k −1,k+1,···,s+2, 计算ci=F(δxi+ai,h)+σ.
(4) 计算c0=M ⊕G(σ).
(5) 返回ctx=(c0,c1,···,cs+2).
• 挑战阶段: 敌手提交两个具有相同长度的消息M0,M1, 和一个向量x∗=(x∗1,x∗2,···,x∗s+2), 要求对于所有问询过预言机OKey的y有〈x∗,y〉̸= 0.在接收到x∗,M0,M1之后, 挑战者随机选择β ∈{0,1}, 然后按照如下方式计算挑战密文ct∗:
(1) 从Zt中随机选择δ,σ.
因此预言机的回应都是形式正确的.
下面分析挑战者C1攻破底层PRF 的优势.首先, 如果挑战者与实验EXP(0) 交互, 则f是Zt中的一个随机元素, 因此挑战密文中的c1,c2,···,ck是随机元素, 此时是在Gamek中, 则有
如果挑战者与实验EXP(1) 交互, 则f是输入为h的PRF 的输出.将ak设置为底层实验的密钥,则有f=F(ak,h), 此时预言机的回应显然是形式正确的.挑战密文

因此, 如果底层的PRF 是安全的, 则对于k=1,2,···,s+2, Gamek−1和Gamek是不可区分的.
以上从负载隐藏模型下证明了Gamek−1和Gamek是不可区分的,k= 1,2,···,s+2, 下面证明在属性隐藏模型下Gamek−1和Gamek是不可区分的,k=1,2,···,s+2.
假设存在一个敌手A能够以一个不可忽略的优势区分Gamek−1与Gamek,k= 1,2,···,s+2.则能够构建一个挑战者C′1区分定义11 中的实验EXP(0) 和EXP(1).在调用实验EXP(b) 并接收到对PRFF的描述后, 挑战者C′1模拟与敌手A的游戏.

所以, 如果底层的PRF 是安全的, 则对于k=1,2,···,s+2, Gamek−1和Gamek是不可区分的.
因此无论是在负载隐藏模型下还是在属性隐藏模型下Gamek−1和Gamek都是不可区分的,k=1,2,···,s+2.
下面在谓词隐藏模型下, 证明对于k′= 1,2,···,s+2, Games+3+k′−1与Games+3+k′之间是不可区分的.′

Gamek′−1,s+2和Gamek′,s+2显然是一致的.下面证明如果底层的PRFF是安全的, 则对于i=1,2,···,s+2, Gamek′−1,i−1和Gamek′−1,i是不可区分的.
设存在一个敌手A能够以一个不可忽略的优势区分Gamek′−1,i−1和Gamek′−1,i, 则能够构建一个挑战者C2区分定义11 中的实验EXP(0) 和EXP(1).在调用实验EXP(b) 并接收到关于PRFF的描述后, 挑战者C2按如下方式模拟与敌手A的游戏:

将sk∗返回给敌手A.
如果挑战者与实验EXP(1) 交互, 则f是PRF 输入h后的输出.将ai设置为底层实验选择的密钥,则有f=F(ai,h), 因此有

引理2 如果方案中底层的PRGG是安全的, 则Games+2与Games+3之间是不可区分的.
证明: 挑战者C3接收到关于PRGG的描述和ψ ∈{0,1}m之后, 模拟下述与敌手A的游戏:
建立阶段: 挑战者首先选择一个密钥同态伪随机函数F: Zt×X −→Zt, 从Zt中随机选择a1,a2,···,as+2, 从X中随机选择h, 然后将(F,G) 发送给敌手.
问询阶段1: 按照引理1 中的预言机OKey,OEnc回应问询.
挑战阶段: 敌手提交两个长度相同的消息M0,M1和一个向量x∗, 要求对于所有在问询阶段1 中问询过OKey的y满足〈x∗,y〉̸=0.在接收到M0,M1,x∗之后, 挑战者随机选择β ∈{0,1}并计算挑战密文ct∗: 随机选择R1,R2,···,Rs+2∈Zt, 对于i= 1,2,···,s+2, 设ci=Ri, 计算c0=Mβ ⊕ψ.返回挑战密文ct∗=(c0,c1,···,cs+2).
问询阶段2: 与问询阶段1 相同, 但要求敌手不能向预言机OKey问询满足〈x∗,y〉=0 的y.
猜测: 敌手输出一个比特β′.如果β′=β则敌手输出1.设Ss+2表示敌手在Games+2中正确输出这一事件.如果ψ=G(σ) 是由PRGG输入σ后生成的, 则此时是在Games+2中, 并且有

因此有
是可忽略的.
引理3 如果底层的SHE 在PLWE 假设下是安全的, 则对于l= 1,2,···,v, Game2s+5+l−1与Game2s+5+l之间是不可区分的.
证明: 假设存在一个敌手A能够区分Game2s+5+l−1和Game2s+5+l, 1≤l ≤v.下面构造一个挑战者C4:
(1)C4选择s ←−χ作为私钥sk=s, 另外选择a1←−Rq和e ←−χ.
(2) 对于来自A的关键词对(w0,l,w1,l),C4选择一个比特β.C4选择u,f,g ←−χ, 计算wβ,l的陷门tβ,l= (c0,l,c1,l),c0,l=a0u+tg+pm1(x),c1,l=a1u+tf x是wβ,l的谓词向量.其中a0∈{−a1s,−(a1s+te)}, 将事件a0=−a1s记做~W0, 将事件a0=−(a1s+te) 记做~W1.C4将tβ,l返回给A.
(3)A接收到tβ=(tβ,1,tβ,2,···,tβ,v) 后, 输出一个比特b′.如果b=b′,C4输出1, 否则输出0.首先说明C4计算出的挑战密文是符合规范的.如果a0=−a1s,则c0,k=−a1su+tg+pm1(x),计算[c0,k+c1,ks]qmodt可解密得到pm1(x).如果a0=−(a1s+te), 则(c0,k,c1,k) 显然为合法密文.设Si表示敌手A攻破Gamei这一事件.当a0=−a1s, 即事件W0发生时,a0为一随机元素,所以(c0,k,c1,k) 是(Rq)2中的一个随机元素, 则此时是在Gamek中, 因而有

是可忽略的.
注意到, Pr[S0]=Pr[IndSSE,A(λ)=1], 所以有
是可忽略的.
5.3 方案的差分隐私性
本文方案通过随机地添加误报和假阴性同时隐藏了访问和搜索模式.下面刻画泄露的访问模式, 即混淆访问模式, 利用混淆的访问模式定义本文方案的泄露(即混淆轨迹), 并使用混淆轨迹概念进行方案的差分隐私性证明.

其中Bern() 函数表示Bernoulli 分布.
下面给出混淆访问模式的定义.
定义14 (混淆访问模式) 一个历史记录H上的混淆访问模式˜α(H) 是一个大小为q×n的二元矩阵, 其中第i行用式(1)来刻画.
混淆轨迹概括了本文方案的泄露.
定义15 (混淆轨迹) 本文方案中, 在对q个关键词搜索时, 一个历史记录的轨迹称为混淆轨迹, 定义为˜T, 有

最后, 如果考虑q个问询的序列, 最坏的情况是, 这q个问询都是对w∗或者都是对w′∗的问询, 则根据访问模式的差分隐私定义, 可以得到
(2) 搜索模式的差分隐私性证明

所以
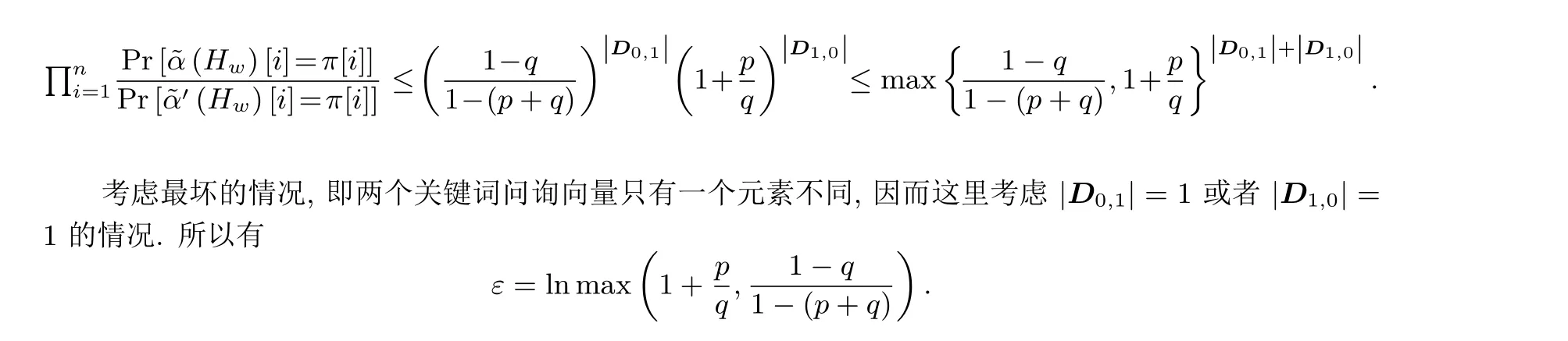
6 方案的性能分析
6.1 理论分析
6.1.1 通信开销
设数据用户U授权访问的文件数量为ndoc.对关键词w= Δ[k],1≤k ≤s进行问询时的通信开销依赖于:
(1) 客户端发送给服务器的搜索陷门大小;
(2) 服务器返回给客户端的在文件索引上计算出的密文总数ndoc(为授权访问的文件总数);
(3) 客户端发送给服务器的id 总数(≤ndoc);
(4) 服务器返回给客户端的所有文件.

所以本文方案的全部通信开销为

所以本文方案的通信开销是一个标准SSE 方案的通信开销的cost_over 倍, 其值取决于Ew, 即取决于问询内容和关键词的分布.
6.1.2 计算开销
本文方案除了相关参数和密钥以外不需要额外的客户端存储.另外, 由于建立阶段只需要进行一次,因此忽略建立阶段的计算复杂度和通信开销的分析.
考虑对一个关键词问询时的计算复杂度.首先考虑服务器的计算复杂度, 这里将其衡量为服务器需要执行的搜索陷门和文件索引之间的计算次数, 即为数据用户U能够访问的所有文件的数量ndoc.对于客户端的计算复杂度, 将其衡量为客户端需要执行的计算次数, 由于服务器将每一个文件索引上计算得到的密文返回给问询用户, 因此客户端计算文件id 时需要执行的计算次数也为ndoc.
6.2 实验分析
这一节将对本文方案的效率进行实验分析.
使用Enron 电子邮件数据集[39]中的数据,在设备Intel(R)Core(TM)i7-6700HQ CPU@2.60 GHz上使用java 对本文方案进行测试.
根据不同的应用环境, 为了保证SHE 方案的安全性和正确性, 需要设置合适的密钥参数(n,q,t,σ).这里主要基于文献[29] 中的工作设置参数.
根据文献[40] 中的结论, 如果满足
就能够保证SHE 方案的正确性.具体来说, 取σ=8,t=2048 作为明文空间的参数, 另外, 取n ≥2048,根据上述不等式可以得到q >260, 所以
将本文方案与Shang 等人[21]给出的能够同时隐藏访问和搜索模式的OSSE 方案进行对比.
图2 展示了在真阳性率TPR=0.99 时, 客户端生成一个关键词的搜索陷门的时间与授权搜索的文件数量ndoc之间的关系.本文方案生成一个关键词的搜索陷门的时间大约为11 s, 受文件数量的影响非常微小.另外, 一个打包密文的大小为2n·lg(q)≈31 KB, 所以在一次关键词问询时客户端发送给服务器的搜索陷门的大小为(#tw·31) KB, 与授权搜索的文件数量是独立的, 因此本文方案适用于多数据所有者场景.OSSE 方案中, 一次关键词问询所生成的搜索陷门数量等于要搜索的文件数量, 所以生成搜索陷门的时间与文件数量呈线性关系, 故OSSE 方案显然不适用于多数据所有者场景.
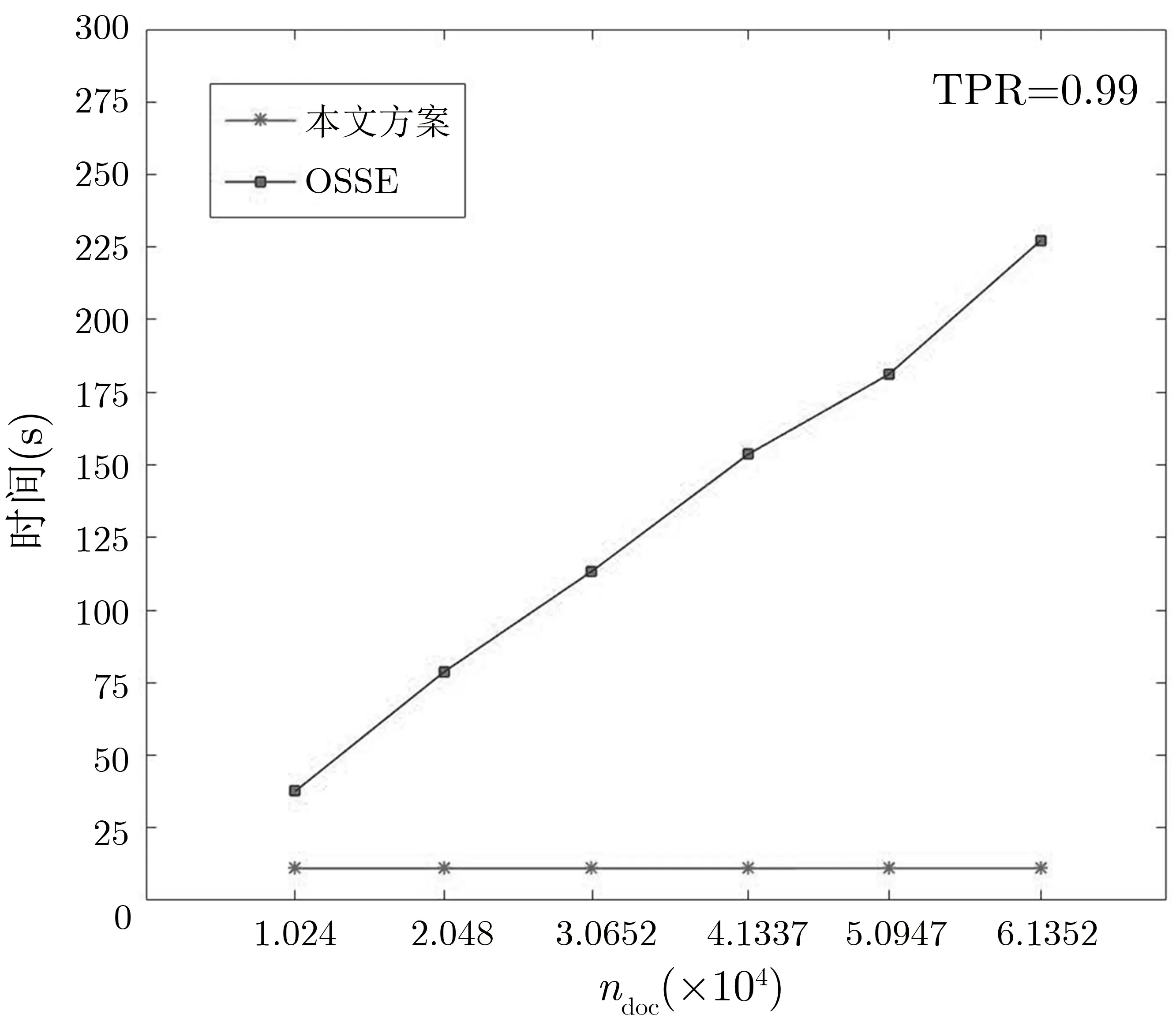
图2 生成搜索陷门时间与文件数量的关系Figure 2 Relationship between trapdoor generation time and number of files
图3 展示了本文方案与OSSE 方案在不同真阳性率(TPR)下客户端生成搜索陷门的时间.结果显示,本文方案中, 生成关键词搜索陷门所需的时间随着TPR 的变大而增长, 而OSSE 方案陷门生成时间不受TPR 的影响.由于本文方案中的TPR 完全由问询用户决定, 因此数据用户可以根据自身需求选择合适的TPR 以平衡效率和安全性.

图3 不同TPR 下搜素陷门生成时间Figure 3 Trapdoor generation time under different TPRs
图4 展示了一次关键词问询中本文方案的搜索时间与ndoc之间的关系.结果显示, 搜索时间会随着文件数量的增长有明显增长.

图4 搜索时间与文件数量的关系Figure 4 Relationship between search time and number of files
图5 展示了一次关键词问询中本文方案中客户端计算文件id 的时间与ndoc之间的关系.结果显示,客户端的计算时间会随着文件数量的增长有明显增长.

图5 客户端计算时间与文件数量的关系Figure 5 Relationship between client computing time and number of files
7 总结
针对现有大多数可搜索加密方案中普遍存在的访问和搜索模式泄露问题, 本文给出了一个多数据所有者场景下能够同时隐藏访问和搜索模式的对称可搜索加密方案, 满足自适应的不可区分安全性, 并且能够证明方案具有访问和搜索模式的差分隐私安全性.本文方案借助内积谓词加密生成文件索引, 使用近似同态加密生成关键词搜索陷门, 最终实现了只需要一个单一的关键词搜索陷门, 就能够在不同密钥加密的文件索引上进行搜索, 并且每一次关键词问询都会产生一个全新的混淆访问模式, 从而同时隐藏了访问模式和搜索模式.本文考虑的是静态数据库中隐藏访问和搜索模式, 未来将进一步研究动态数据库中隐藏访问和搜索模式.
