云数据安全去重技术研究综述*
2024-01-11伍高飞袁紫依孙思贤陈永强孙润东付安民朱笑岩张玉清1
伍高飞, 袁紫依, 孙思贤, 陈永强, 孙润东, 付安民, 朱笑岩, 张玉清1,,6
1.西安电子科技大学 网络与信息安全学院, 西安710126
2.燕山大学 信息科学与工程学院, 秦皇岛066004
3.西安电子科技大学 通信工程学院, 西安710071
4.中国科学院大学国家计算机网络入侵防范中心, 北京101408
5.南京理工大学 计算机科学与工程学院, 南京210094
6.中关村实验室, 北京100094
7.成都信息工程大学 先进密码技术与系统安全四川省重点实验室, 成都610225
1 引言
随着云计算技术的飞速发展, 当前已经进入了大数据时代.很多用户将自己的数据存储到云服务器中, 这使得用户能够随时随地访问自己的数据, 更加方便地管理它们[1].根据国际数据机构IDC (International Data Corporation) 研究报告统计[2], 2013 年全球数据总量为4.4 ZB, 2022 年全球数据总量将增加至80 ZB, 而2025 年将会达到175 ZB.庞大的数据量使得如何经济、高效地在云端存储数据更加受到关注.
为了在实践中更好地使用和发展云存储的相关技术, 首先要解决云存储服务提供商的存储效率和功耗问题.最直接的方法是使用数据压缩技术, 将数据压缩后再上传至云端.然而, 不同的场景要求不同的压缩格式, 不同的压缩算法便会产生不同的压缩副本, 并不能解决存储效率问题, 同时还造成了额外的带宽消耗[3], 因此数据去重技术应运而生.数据去重技术通过删除存储系统中集中重复的数据, 只保留其中一份副本, 以达到消除冗余数据和提高云存储系统的带宽利用率等目的[4,5].为保证隐私和数据安全, 用户往往对需要上传云端的数据进行加密, 将数据以密文形式存储在云端, 这会阻碍云服务器的维护和重复数据的有效删除.因此, 如何同时实现数据的安全存储和有效去重, 是一个值得深入研究的方向[6].
为了提高云存储服务提供商的存储效率, 同时降低管理开销, 数据去重技术被广泛应用于各大云服务器提供商之间[7], 该技术可以找出不同用户上传的重复数据, 只保存唯一的数据单元, 并为该数据单元创建访问指针.用户将预处理后的数据上传至云服务器, 云服务器存储数据与相关数据标识, 并根据随机抽样、提取散列值等方法来检测数据是否重复, 若相同则执行删除操作, 将数据的访问指针发送给用户, 而不执行实际的上传.文献[8] 将重复数据删除技术分为相同数据检测技术、相似数据检测和编码技术两类, 从完全文件检测、固定块检测、可变分块检测、滑动块检测等方面对相同数据检测进行分析, 从基于shingle 的检测技术、基于Bloom filter 的检测技术、基于模式匹配的检测技术等方面分析了相似数据检测技术.Xiong 等[9]分析总结了云存储中的数据去重的相关技术, 从基于内容加密的安全去重、基于所有权证明的安全去重和隐私保护的安全去重3 个方面总结了相关技术的研究进展.Shin 等[10]从研究对象粒度、数据去重的操作位置、存储架构和云服务模型等方面对数据去重技术进行了分析, 描述了用于解决不同安全威胁的多种云数据去重技术.
与传统的数据存储模式不同, 用户将数据上传至云端后, 就失去了对数据的直接控制能力, 只能通过云服务器提供的接口对存储数据进行间接管理[11].在云环境中, 存储在云服务器的用户数据通常包含大量的隐私或敏感信息, 攻击者可以利用数据去重过程产生的侧信道来获取这些用户隐私[12].此外, 云环境下的数据安全去重系统还面临着安全风险及其解决方法带来的性能效率问题, 例如隐私保护去重方案中隐私与效率之间的平衡问题.为了解决上述问题, 在保证用户数据安全的同时实现数据安全去重迅速成为云存储领域的研究热点, 并取得了相关的研究成果.本文广泛调研了云去重领域自2016 年1 月至2023 年4 月期间来自DBLP (Database Systems and Logic Programming)、Web of Science、Elsevier、SpringerLink 和中国知网(CNKI) 等国内外知名数据库收录的现有相关研究工作, 如图1 所示, 并对主要期刊1期刊: IEEE Trans., ACM Trans., IEEE Internet of Things Journal, Information Sciences, Computers & Security 等、会议2会议: S&P, USENIX Security, CCS, NDSS, EUROCRYPT, CRYPTO, ASIACRYPT, INFOCOM, ACM SoCC 等收录的现有研究工作进行分类统计, 如图2 所示.
本文的主要贡献有3 个方面:
(1) 深入调研云数据去重领域自2016 年以来的相关文献, 总结云数据安全去重系统的一般结构和其面临的主要挑战及相关安全威胁.
(2) 以云数据安全去重技术的实现机制为分类依据, 从基于内容加密的安全去重、基于PoW 的安全去重、隐私保护的安全去重和基于数据流行度的安全去重四个方面分析近年来研究工作, 重点分析现有研究工作的去重效率, 并指出各种数据去重技术的优点、局限性以及存在的共性问题.
(3) 分析当前数据安全去重领域面临的各种机遇和挑战, 并对未来的发展趋势和研究方向进行展望.
2 问题描述
2.1 面临的挑战
云存储服务不同于传统的数据存储系统, 其中用户数据的管理权与所有权相分离.为保护用户的隐私与数据安全, 云存储服务通常会将数据加密处理.数据的加密方式以及安全去重方式也是当今学术界的研究热点.云环境下的数据外包与虚拟化等特征也给云数据的安全去重带来诸多如下挑战.
(1) 数据去重与语义安全.传统加密算法可以为数据提供安全级别较高的语义安全, 但传统加密算法与数据去重技术互不兼容.收敛加密(convergent encryption, CE) 采用数据的散列值作为加密密钥, 相同的数据加密后可得到相同的密文, 实现了加密去重.然而, CE 只能为不可预测的数据提供语义安全.若采用CE 对可预测的数据进行加密, 则易遭受离线字典攻击.因此, 在实现数据去重的过程中提供语义安全是一个关键问题.
(2) 隐私泄露.数据去重方案往往是在用户与服务器之间进行信息交互, 通过判断数据的重复性来执行数据去重.数据去重过程中会产生侧信道, 攻击者通过学习文件内容、识别文件、建立隐蔽通道等方式来对云服务器发起攻击[12], 窃取用户的隐私信息.此外, 用户的外包数据中通常包含大量的敏感或隐私信息, 攻击者也可以收集用户数据中的隐私信息来进行针对性的对策分析.因此,保护用户数据的隐私是非常必要和紧迫的, 这也是云存储服务提供商亟需解决的问题.
(3) 数据可用性.云存储系统中存在设备故障的风险, 可能会导致共享数据丢失以及数据不可用等问题.在云存储系统中只存储一份重复数据, 若设备发生故障且共享数据丢失, 则会导致多个文件不可读.此外, 云存储系统采用的设备还存在机械故障的风险, 可能会导致数据丢失以及系统服务中断.
2.2 系统模型
安全去重系统的模型大致分为两类: 含第三方服务器的安全去重系统模型(如图3 所示) 和不含第三方服务器的安全去重系统模型.整个系统的主要实体包括用户、云服务器和第三方服务器(如果有).文献[13–16] 引入了密钥服务器对收敛密钥进行管理.文献[17–20] 使用不含第三方服务器的安全去重系统,所有去重过程都在用户和云服务器之间完成, 摆脱了可信第三方的束缚, 同时减少了系统的通信开销.

图3 含第三方服务器的系统模型Figure 3 System model with third-party server
2.3 威胁模型
攻击者能够利用数据去重机制对云服务器发起攻击, 本节将描述攻击者对云服务器造成的各种安全威胁, 以及抵抗这些安全威胁的相关方案.
侧信道攻击.Harnik 等[12]提出了三种利用跨用户数据去重来攻击用户隐私的侧信道攻击, 侧信道攻击既可以发生在文件级去重中, 也可以发生在块级去重中, 如图4 所示, 主要分为三种: (1) 识别文件[21],攻击者将指定文件上传至云服务器并观察网络流量, 如果文件成功上传至云服务器, 则攻击者就会知道云服务器没有存储该文件, 否则, 攻击者可以发现云服务拥有该文件; (2) 学习文件内容, 攻击者通过对文件内容的所有可能值进行穷举攻击, 并通过去重检测来判断所猜测的内容是否正确; (3) 建立隐秘通道, 攻击者在客户端嵌入恶意软件, 恶意软件可以将一个文件的两个版本上传至云服务器, 通过观察文件是否发生去重, 将文件信息发送给攻击者.
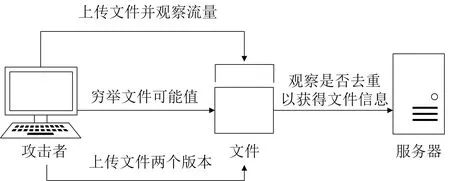
图4 侧信道攻击模型Figure 4 Side channel attack model
针对上述攻击, 文献[22] 提出了一种基于双层加密和密钥共享的云数据去重方案, 该方案基于服务器端进行去重, 使得用户难以判断上传的文件是否已经存在, 从而抵抗侧信道攻击.此外, 文献[23] 提出在去重标签中嵌入属性密钥, 实现了安全的授权去重, 未经授权的用户无法进行侧信道攻击, 数据对于未授权用户而言是语义安全的.
蛮力攻击.当攻击者拥有密文时, 可以对猜测的明文内容进行加密, 将所有猜测的明文加密后与密文进行比对, 就可以获取原始文件内容.针对该攻击, Xiong 等[24]提出了一个用于协作云应用中的安全访问和数据去重的混合PoSW 方案, 可以解决多用户共享所有权这一问题, 该方案使用多个密钥管理器分散地生成收敛密钥, 可以抵抗蛮力攻击, 同时可以解决云服务器和密钥管理员串通这一问题.Li 等[25]提出了一种安全的、有效的客户端加密数据去重方案, 采用密钥服务器来协助用户生成密钥, 通过采用速率限制策略来抵抗蛮力攻击.文献[26] 提出了一种基于Merkle 哈希树的数据去重方案, 该方案通过构造Merkle哈希树来生成加密密钥, 使得密文变得不可预测, 从而抵抗了蛮力攻击.
字典攻击.若攻击者与云服务器勾结, 获取了密文内容, 与已知的密文字典进行比对, 借此推测出明文内容.Puzio 等[27]指出了在基于CE 的加密中存在字典攻击, 在已知密文的情况下, 攻击者可以通过对猜测的明文进行加密, 再将加密后的明文与已知密文进行对比, 从而破解出密文对应的明文.Shen 等[28]提出一种轻量级云存储审计的数据去重方案, 用户的文件隐私不会被泄露给云端和其他各方, 解决了数据泄露问题, 能够抵抗字典攻击.Zheng 等[29]提出利用无证书代理重加密技术来抵抗字典攻击.
伪造攻击.攻击者首先提供合法的去重标签值, 同时上传与标签值不一致的加密文件, 由于标签是由数据所有者通过拥有的文件计算得到, 因此云服务器难以验证标签与加密文件的一致性; 当用户上传与该去重标签值相匹配的文件时, 该文件会由于去重机制而无法被云服务器存储, 用户只能下载得到攻击者伪造的文件, 如图5 所示.为了抵抗该攻击, 文献[30] 提出了一种基于秘密共享算法的安全数据去重方案, 采用基于中国剩余定理的秘密共享算法将密钥分为多个随机块, 并发送给相应的密钥管理服务器, 降低了密钥开销, 可以有效抵抗伪造攻击.

图5 伪造攻击模型Figure 5 Forgery attack model
频率分析攻击.现有去重方案大多采用确定性加密算法, 这使得相同明文经过加密后得到的密文相同, 每一对密文和明文都具有相关的频率模式, 因此攻击者可以对密文进行频率分析从而推断出原始明文的内容[31].Li 等[32]在频率分析攻击的基础上提出一种基于分布的攻击, 该攻击与频率分析攻击相比,能够更加精确地推断出去重系统中明文-密文对.针对频率分析攻击, 文献[33] 提出一种新的密码学原语TED, TED 提供了一种可调节的机制, 允许用户在存储效率和数据保密性之间进行平衡.其核心思想是削弱MLE 算法的确定性, 允许不同的密钥对重复的明文块进行加密, 有效地抵抗了频率分析攻击.Yang等[34]设计了一种在数据加密前对数据去重的方法DbE, 并根据该方法提出了一种基于Intel SGX 的数据去重方案DEBE.该方案首先对enclave 安全容器内频率较高的数据进行去重, 再对enclave 安全容器外频率较低的数据进行去重, 为去重提供了安全的执行环境, 从而抵抗了频率分析攻击.Xie 等[35]根据用户的安全需求为数据块提供不同级别的安全性, 保证去重效率的同时有效抵抗了频率分析攻击.
3 国内外研究进展分析
目前, 国内外对云数据安全去重的研究取得了一定的成果.我们给出了云数据安全去重系统的一般结构, 如图6 所示, 通常包含数据提取、指纹计算、指纹比较、指纹写入四个步骤.对于现有的去重方案主要有以下分类方式: 根据去重时机的不同可将去重技术分为Inline 去重和Post-Process 去重[36].Inline去重首先删除重复数据, 然后将其存储到存储介质中.在Post-Process 去重中, 数据首先被存储在介质中,然后系统进行去重工作.根据去重数据的粒度大小[37]可划分为文件级去重和块级去重.根据实施去重操作的主导者可划分为客户端去重、服务器端去重以及跨用户去重.

图6 安全去重系统结构Figure 6 Secure deduplication system structure
本文以云数据安全去重的实现技术为依据, 从以下四个方面展开论述: 基于内容加密的安全去重、基于PoW 的安全去重、隐私保护的安全去重以及基于数据流行度的安全去重, 如图7 所示.
3.1 基于内容加密的安全去重
基于内容的加密算法为对称加密算法, 它们通过文件的内容计算对应的密文, 主要包含以下两类算法:收敛加密(convergent encryption, CE) 算法和消息锁加密(message-locked encryption, MLE) 算法.
3.1.1 基于CE 实现云数据安全去重
收敛加密是一种确定性加密算法, 收敛密钥由原数据进行散列运算得到, 使得相同的数据能得到相同的收敛密钥.该算法由Douceur 等[38]首次提出, 并在Farsite 分布式文件系统中使用了基于CE 的去重方案, 该方案使得相同的明文文件被加密成相同的密文文件, 使得系统能够准确识别相同的文件从而有效地进行去重工作, 极大提高了重复数据的删除率, 减少了云存储中不必要的浪费.CE 的可扩展性强、效率高以及容错率高等优点使其在云数据去重领域中得到了广泛的应用.
为了实现有效的数据安全去重以及数据完整性审计, Guo 等[44]设计并实现了一个基于收敛加密的云安全去重和完整性审计系统.该方案使用基于盲签名的收敛密钥封装与解封算法以及基于收敛密钥的BLS (Boneh-Lynn-Shacham) 签名算法, 在保证收敛密钥安全性的同时能够删除冗余的密钥, 且减少了客户端存储开销和计算开销.
Li 等[45]结合CE 算法和文件扩散思想提出了CDStore 方案, 实现了文件的块级去重, 提高了数据的安全性.Tian 等[46]提出块级去重方案Sed-Dedup, Sed-Dedup 是一种有效的安全增量编码数据去重系统, 该系统在CE 的基础上引入了一种新的增量编码方法, 将修改后的内容存储在增量文件中并保持原始文件不变, 从而有效地减少了重复数据的产生.实验表明该方案能够很好地降低存储成本和计算开销.
Puzio 等[27]提出了一种基于CE 算法的云数据去重方案ClouDedup, 增加访问控制机制, 保证了数据的机密性.Agarwala 等[47]提出一种双重完整性收敛加密方案DICE.该协议执行标签检查, 并通过网络发送散列, 从而在不影响安全性能的情况下降低通信和计算成本.实验证明该协议有很好的安全性, 能够抵抗伪造复制攻击.
针对块级文件去重中的密钥管理问题, Liu 等[48]设计了一种客户端安全去重方案KeyD, 采用CE和基于身份的广播加密算法, 在不引入密钥管理服务器或其他可信第三方的情况下, 实现了安全高效的密钥管理, 用户只需要与云服务器进行交互即可实现数据去重, 但没有考虑到数据所有者的身份隐私问题.
3.1.2 基于MLE 实现云数据安全去重
在CE 的基础上, 为了明确安全目标, 提供形式化定义的安全去重模型, Bellare 等[49]提出了消息锁加密方案, 该方案基于CE 方案实现, 其文件的密钥由文件原始内容和系统参数共同计算, 而后使用该密钥对数据进行加密得到其对应的密文.
Chen 等[40]提出BL-MLE 实现了块级的MLE 去重方法, 但块级的MLE 的生成和共享过程存在潜在的隐私问题和大量的计算消耗.针对此问题, Zhou 等[50]提出了一种具有灵活访问控制的云相似性感知加密数据去重方案EDedup.该方案采用基于代理的属性加密算法实现了细粒度的访问控制, 通过一个代表性哈希, 利用相似性减少了计算消耗.Zhang 等[51]提出SPADE 安全去重方案, 该方案提出一种服务器辅助MLE 的主动机制, 对密钥服务器进行定期更新, 以更新对密钥的安全保护, 能够抵抗蛮力攻击.
Bellare 等[39]利用完全同态加密算法扩展了MLE, 提出iMLE 方案, 该方案通过交互消息锁加密算法实现了跨用户的数据去重, 从而有效地实现了关联文件的去重.Pooranian 等[18]提出了一种消息锁加密和无解密同态加密协议LEVER, 该协议能够很好地抵抗外来的蛮力攻击, 且文件传输过程只有上传者和云参与, 无需CSP 在后台工作.LEVER 在客户端进行加密数据的去重, 且能够在保证通信效率的同时增加重复数据的删除率.
Bellare 等[52]提出DupLESS 方案, 该方案引入密钥服务器协助用户生成加密密钥, 有效抵抗了字典攻击.Chouhan 等[53]对DupLESS 方案进行扩展, 采用EC (eraser coding) 机制将数据和密钥分割成片段, 分别存储在云服务器以及密钥存储服务器, 进一步保证了数据和密钥的安全性.
Zhao 等[41]提出了可更新的块级消息锁加密UMLE, 该方法支持所有权证明可以很好地保护用户数据.Shin 等[15]基于UMLE 算法提出了一种可隐私保护且支持数据更新的加密文件块去重方案, 该方案通过指数运算和双线性实现文件块的密钥生成、加密和解密操作, 在一定程度上能够抵抗蛮力攻击.
3.1.3 小结
基于内容加密的安全去重能够更加有效地删除重复数据, 解决了用户加密和数据重复率的矛盾, 节省了许多存储空间.但依旧存在一些局限性: (1) 基于CE 的去重方案使得相同数据的密文也变得相同, 极大提高了数据的去重效率, 但它极易遭受离线的暴力攻击[54], 这使得数据无法得到很好的安全保障; (2)Sed-Dedup 方案[46]解决了文件发生较小改动时无效的相似性检测的问题, 但在计算文件的多个版本之间的差异时效果仍不是很好; (3) LEVER 系统[18]可以抵抗蛮力攻击, 但无法有效地抵抗侧信道攻击.表1 对上述基于内容加密的安全去重方案的性能进行了对比分析.
3.2 基于PoW 的安全去重
在客户端去重中, 为了防止用户只需拥有上传文件的散列值就可以获取到原始文件, 研究人员提出了所有权证明的概念, PoW 协议是由云服务器与客户端共同参与的交互协议, 用来证明客户端是否真实拥有该文件.
3.2.1 基于MHT 的PoW
基于MHT (Merkle hash tree) 的PoW 证明方法(MHT-PoW) 最早由Halevi 等[55]提出, 该方法中由服务器随机选取n个叶子节点, 并将这些叶子节点的路径作为挑战信息发送给客户端, 再根据客户端的应答信息来验证用户的所有权.然而在该方案中, 挑战与应答阶段中所有的数据块都没有加密, 可能会泄露数据隐私.针对上述问题, Xu 等[56]在Halevi 方案的基础上进行优化, 利用收敛加密处理数据, 对加密数据计算散列值来构建MHT, 因此在挑战与应答过程中不会泄露任何信息.
为实现云数据安全去重和完整性审计, Li 等[57]提出了两个安全系统, SecCloud 和SecCloud+.Sec-Cloud 方案利用MapReduce 云代替第三方审计者, 帮助客户端在上传文件前生成数据标签, 并对存储在云中的数据进行完整性审计.在SecCloud 方案的基础上, SecCloud+ 引入了一个密钥服务器, 除了能够实现数据完整性和安全去重外, 还能够保证文件的保密性, 但将数据直接发送给MapReduce 云没有考虑数据隐私问题.
Wang 等[58]提出了一种基于密钥共享的数据安全去重方案, 该方案基于所有权证明的密钥共享方法来解决收敛加密的密钥管理问题.通过构造MHT 来生成去重检测标签, 攻击者无法从中获得任何有价值的信息.实验结果表明, 该方案比其他方案具有更小的通信开销.然而, 该方案仍需借助第三方来实现数据去重、所有权证明以及密钥管理等, 没有摆脱对信任实体的依赖.
3.2.2 基于随机抽样的PoW
由于MHT-PoW 中计算和I/O 开销较大, 研究者提出基于随机抽样的PoW 方法, 该方法要求服务器随机选择文件的比特位来作为文件所有权的证据发送给客户端, 客户端将对应的应答返回给服务器, 再验证是否与挑战信息相匹配.Di 等[42]提出了一种优化方案(s-PoW), 利用伪随机数生成器产生随机的索引位置, 保证了计算开销不随数据块的数量变化而变化.Blasco 等[43]利用Bloom filter 的高检索效率, 提出了一种基于Bloom filter 的灵活且可扩展的数据去重方案(BF-PoW), 提高了服务器端的工作效率.González-Manzano 等[17]提出了一种CE-PoW, 采用CE 算法对数据进行加密, 该方案相较于其他PoW 方案具有较小的开销.
Yang 等[59]提出了一种可证明的文件所有权证明方案(POF), 通过动态系数和随机选择的原始文件索引值来实现安全与高效的目标, 即使攻击者收集到大量挑战-响应信息, 也无法从中获取到与所有权证明相关的信息, 可以抵抗重放攻击和合谋认证攻击.在该方案中, 客户端只需要访问原始文件的很小一部分来生成所有权证明, 减少了客户端的计算开销.
为了实现分层环境下的授权数据去重和所有权证明, González-Manzano 等[60]提出了一种属性对称加密的PoW 方案(ase-PoW), 采用轻量级的访问控制程序来抵抗文件内容猜测攻击, 其中文件加密密钥与用户的属性相关.然而, 该方案并未考虑到密钥的更新和撤销.为了解决上述问题, Xiong 等[61]提出了一种基于RSE 的角色对称加密PoW 方案(RSE-PoW), 采用了一个分层的树状结构来管理用户的角色密钥, 只有具有特定权限的用户才能够访问相应的文件, 当用户的权限被撤销时, 相应的角色密钥则会被删除和更新, 实现了对数据授权访问的安全去重.该方案可以防止隐私泄露和侧信道攻击.
由于所有权动态变化过程会产生大量的开销, 为了改进这一问题, Jiang 等[62]提出了一种支持动态所有权管理的安全去重方案, 支持跨用户、块级和文件级去重, 采用懒人更新策略以减少更新频率和计算开销.实验表明, 该方案保证了数据的机密性和标签的一致性, 并且减少了密钥的存储空间.
为解决数据去重方案中共享文件的所有权问题, Xiong 等[24]结合所有权证明、秘密共享、Bloom filter 等技术, 提出了一种用于协作云应用的共享所有权证明方案(ms-PoSW), 实现协作云应用中对共享文件的安全访问、所有权证明与安全去重.
Liu 等[63]提出了一种可以同时支持数据去重和可搜索加密的方案, 该方案将所有权证明和MLE 结合, 同时引入密钥服务器参与密钥生成, 密钥服务器与客户端之间采用盲签名进行交互, 未经授权的用户无法获取加密密钥, 可以有效抵抗蛮力攻击.
表2 对上述基于随机抽样的PoW 方案的性能进行了对比分析.

表2 基于随机抽样的PoW 去重方案的对比分析Table 2 Comparison of PoW based on spot-checking
3.2.3 基于数字签名的PoW
为了保证用户数据的隐私, 收敛加密被广泛用于客户端数据去重的场景中, 但收敛加密易遭受暴力字典攻击, 且无法为可预测数据提供语义安全.因此, 研究者提出将数字签名与所有权证明方法相结合.基于数字签名的PoW 方案具有较高的安全性, 因此被广泛应用于安全去重方案中.
用户需要定期检查云中存储数据的完整性, 但大多数方案不能同时支持数据的安全去重和完整性审计.针对这一问题, Youn 等[64]提出了一种可以同时支持加密数据的客户端去重和完整性审计的方案, 使用基于BLS 签名的同态线性认证器执行PoW 协议来实现安全去重, 同时该方案支持第三方审计师进行公共审计.
Liu 等[65]利用代理重签名技术, 实现了用户间审计标签去重, 进一步提高了去重的效率.该方案不需要额外的代理服务器, 只需将审计任务委托给第三方审计机构, 但是审计过程需要用户参与, 且云服务器中存储了大量代理重签名密钥, 增加了云存储开销.
Zheng 等[29]提出了一种基于无证书代理重加密的安全去重方案, 该方案由无证书代理重加密和基于无证书签名的PoW (PoW-CLS)组成, 使用无证书代理加密技术解决了密钥托管问题, 密钥由客户端和密钥生成中心共同生成, 可以避免密钥生成中心冒充用户对密文进行解密, 实现了跨用户的数据去重.
Li 等[66]提出了一种基于区块链的安全去重方案, 采用双向的PoW 机制, 使用户和云服务器能够互相验证双方对目标数据的所有权.通过集成双向PoW 机制、MLE、密钥累加器以及区块链技术, 实现了安全透明的数据去重方案.
除了保证云存储数据的安全去重, 验证存储在云服务器中数据的完整性也十分重要, 验证数据完整性的方案可分为可证明数据持有(provable data possession, PDP) 机制[67]和数据可恢复证明(proofs of retrievability, POR) 机制[68].现有大部分PDP 和POR 尚未考虑损坏数据定位这一问题, Zheng 等[69]提出了一种可以支持密钥更新的安全审计方案, 该方案将用户部分密钥的计算委托给TPA, 减少了用户端的计算开销, 并且每一轮更新的密钥都不相同, 提高了用户密钥的不可伪造性.
3.2.4 小结
基于所有权证明的安全去重方法是通过执行验证数据的所有者是否拥有数据源的过程, 来证明数据所有者的所有权, 并以此抵御所有权伪造攻击或其他侧信道攻击, 但仍存在一定局限性: (1) 现有的PoW 方法能够抵抗隐私泄露和哈希证明攻击, 但同时也存在计算开销大或误判导致隐私泄露的风险; (2) 较少考虑到所有权动态变化这一问题, 未能实现对所有权的更新和撤销; (3) 云服务器利用Bloom filter 能够迅速验证客户端的响应结果, 但Bloom filter 存在一定的误判率, 且随着元素增加, 误判率也不断增加.
3.3 隐私保护的安全去重
在云存储领域中, 数据安全与用户隐私一直以来都是人们关注的一个热点问题.在进行云数据去重的过程中, 攻击者能够利用侧信道来侵犯用户隐私.因此, 保障数据隐私对云存储发展极为重要.云数据去重方案中侧重于数据隐私保护的去重方案可大致分为两类: 基于随机化方法实现的隐私保护安全去重和基于差分隐私实现的隐私保护安全去重.
3.3.1 基于随机化方法的隐私保护安全去重
数据去重过程中去重请求和去重响应之间的确定性关系是产生侧信道的主要原因, 因此抵抗侧信道攻击的一个简单策略是随机化去重检查过程.Harnik 等[12]提出了一种简单的随机化机制, 为每个上传文件都设置了一个随机阈值, 当文件的存储副本数量达到阈值则执行客户端去重, 否则数据去重只在服务器端执行.该方案支持跨用户数据去重, 同时降低了数据泄露的风险.
Armknecht 等[70]在Harnik 等[12]方案的基础上证明了随机化数据去重方案在安全性和效率之间存在一定的平衡, 并表明Harnik 等[12]方案的统一随机阈值比Lee 等[71]方案的可变阈值更具有安全性.Wang 等[72]采用博弈论对去重过程中遇到的安全问题进行模拟, 经实验证明该方案能够有效抵抗侧信道攻击.
Yu 等[73]提出了ZEUS 方案, 该方案要求每次上传两个数据块, 并根据数据块的去重结果生成模糊化的响应, 可以防止攻击者通过去重检查来判断数据的存在状态, 从而保护了数据存在性隐私.但该方案需要维护一个去重检查响应表来记录所有用户已检测但未上传的数据块, 增加了云服务器的存储和计算开销.Pooranian 等[74]在Yu 等[73]方案的基础上增加了少量的开销, 提供了更强的隐私保护.
Tang 等[75]提出了基于请求合并的数据去重方案RMDS, 该方案使用基于异或的区块级服务器端存储结构, 在去重过程中添加冗余块来混淆攻击者, 可以有效地抵御附加块攻击.经实验证明RMDS 方案所需的通信开销明显小于ZEUS 方案[73].
Ha 等[76]提出了针对侧信道攻击的防御方案, 该方案将已存储和未存储数据块的去重响应分组到不同的集合中, 可以消除数据去重响应与数据存在之间的相关性, 降低攻击者破坏数据隐私的可能性.安全分析以及性能评估表明, 该方案可以有效地保护用户数据隐私, 同时降低系统的通信开销.
3.3.2 基于差分隐私的隐私保护安全去重
该方法主要是引入了差分隐私机制, 差分隐私概念是由Dwork[77]首先提出的, 通过添加噪声对数据造成污染, 使得改变任意一条数据也无法使查询结果发生明显变化, 在对数据造成污染的同时保证原数据的某些特性不变.
Harnik[12]等的随机化去重方案都基于每个文件相互独立这一前提, 并未考虑文件的相关性.Shin等[78]提出相关文件攻击这一概念, 在实际环境中, 一些文件存在着一定的关联, 攻击者会通过上传文件或与相关的文件来推断出上传文件的存在.针对这一攻击, Shin 等[78]引入了差分隐私机制来保证数据去重过程中的隐私, 该方案基于存储网关来实现数据去重, 通过上传虚拟数据来混淆数据去重的发生, 使得攻击者无法判断出文件是否发生去重, 达到了保护文件的目的, 从而抵抗侧信道攻击和相关文件攻击, 实现了更强的隐私保护.
针对攻击者利用侧信道来攻击用户隐私这一问题, Ren 等[79]提出一种可以控制文件副本数量的混合云架构的去重方案, 结合差分隐私技术及收敛加密算法来计算密钥值并对其二次加密, 保证每个上传文件在服务器中只存在一份副本, 该方案可以抵抗相关文件攻击和侧信道攻击, 节约了带宽和存储空间.
3.3.3 小结
面向隐私保护的安全数据去重方案采取一定的方法能够有效地抵抗侧信道攻击, 使得用户的数据隐私与安全得到保障, 但仍存在以下缺陷: (1) 随机化方法由于随机响应阈值带来的不必要的文件上载会导致巨大的网络带宽消耗, 会给云服务器带来一定的负担, 寻求一种更轻量、便捷的随机化机制是目前亟待解决的问题; (2) 差分隐私去重方法虽然对抵抗侧信道攻击有着很好的效果, 但引入的噪声会对模型的可用性和准确性造成一定影响, 如何在隐私保护和数据的准确性之间取得很好的平衡还需要深入的研究.
表3 从隐私保护程度的高低、带宽通信消耗以及数据缺损等方面, 对上述方案进行了对比分析.

表3 隐私保护的安全去重方案的对比分析Table 3 Comparison of secure deduplication of privacy protection
3.4 基于数据流行度的安全去重
现有的去重方案大多采用CE 加密, 将数据散列值作为去重检测标签(如CE[38]、ClouDedup[27]),而CE 只能为不可预测数据提供语义安全, 若采用CE 对可预测数据进行加密, 则易遭受离线字典攻击.因此, 如何在实现数据去重的过程中提供语义安全是一个关键问题.
针对上述问题, Stanek 等[80]首次提出了数据流行度的概念, 根据数据的隐私程度将数据划分为流行数据和非流行数据, 对不同类型的数据采用不同的保密措施.该方案为所有数据设立一个阈值t, 当某一数据F的所有者数量count(F) 大于t时, 就将该数据标识为流行数据; 否则, 当count(F) 小于t时就将数据标识为非流行数据, 如图8 所示.由于流行数据的隐私程度较低, 采用安全性较弱的算法对流行数据进行加密, 从而降低用于加密数据的时间开销.而非流行数据的隐私程度较高, 需要对数据采用语义安全的对称加密算法.Stanek 等[80]使用真实数据集对该去重系统的存储效率进行分析, 结果表明当流行数据文件较多时, 方案的去重效率较高.

图8 数据流行度转换Figure 8 Transition of popularity status
Puzio 等[81]提出了PerfectDedup 方案, 通过完美散列函数计算出数据标识, 将数据标识发送至索引服务器IS (index service), IS 则根据数据标识来查询数据流行度.如果数据为流行数据, 将数据块采用CE 加密后上传至CSP 再执行数据块去重; 若为非流行数据, 则对数据块采用对称密钥加密.该方案对流行数据块进行去重, 实现了更高效的数据去重.
Stanek 等[82]在原有方案的基础进行优化, 提出了一种新的门限数据去重方案, 引入门限密码系统,提高了非流行数据的安全性.该方案引入IRS (index repository service) 提供索引服务, 对数据流行度进行查询.若为流行数据, 则采用CE 进行加密; 若为非流行数据, 则采用双层加密, 内层为收敛加密, 外层为门限密码加密, 提高了对非流行数据的隐私保护程度.该方案开销较小, 且能抵抗用户合谋攻击.
现有方案大多未能实现对非流行数据的去重, 针对这一问题, Zhang 等[83]提出了一种无可信第三方的加密数据去重方案, 基于椭圆曲线实现了对数据的流行度查询, 在查询过程中不泄露数据的任何明文信息, 拥有相同数据的初始上传者能够通过云服务器将加密密钥安全离线共享给后继上传者, 实现了非流行数据的去重, 提高了去重的执行效率.
Ha 等[84]引入半可信的同态解密服务器来统计数据流行度, 使用同态加密生成随机标签, 避免使用确定性标签来记录数据流行度, 然而其中的同态解密服务器易成为单点故障和效率瓶颈.针对这一问题, Ha等[85]提出了一个无第三方服务器的基于数据流行度的加密去重方案, 在不依赖于第三方服务器的情况下实现了对数据流行度的精确检测, 同时可以为非流行数据提供语义安全以及加密去重.
基于数据流行度的安全去重要求用户在上传数据之前, 按照数据的隐私程度对数据进行划分, 对不同类型的数据采用不同的加密算法进行保护.基于数据流行度的去重方法能有效地提高数据去重的效率, 但仍存在如下局限性: (1) 不同数据的隐私程度不同, 应该具有不同的流行度阈值, 而现有方案大多为所有上传数据设定统一的阈值, 可能会增加数据隐私泄露的风险; (2) 文献[80–82] 均未能执行非流行数据去重.
表4 对上述去重方案进行对比, 分析了非流行数据首次上传、后续上传和流行度转换三种情况下的客户端计算开销.表5 从主要算法、去重粒度、优点和局限性等方面对数据去重方案进行系统梳理和归纳.
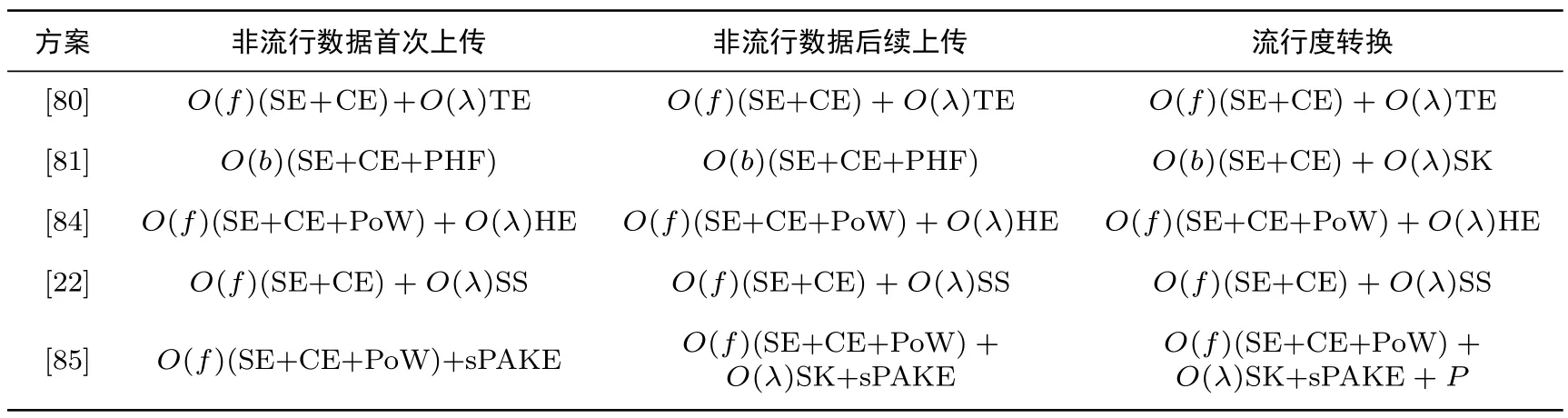
表4 基于数据流行度的去重方案的客户端计算开销对比分析Table 4 Comparison of client computation of popularity-based deduplication scheme

表5 云数据安全去重方案的对比分析Table 5 Comparison of secure data deduplication
4 发展趋势与未来研究方向
目前云加密数据去重已经取得了一定的成果, 但与成熟的体系结构还有一段距离.图9 给出了本文所提及的具有一定代表性的云数据安全去重方案的时间线.在大数据时代, 数据的爆炸增长和多样性也给加密数据的安全去重带来了更大挑战, 也是今后应该研究的重点和方向.未来的研究方向应分为如下几方面.表6 总结了云数据去重领域的挑战和机遇.

表6 云数据去重领域面临的挑战和机遇Table 6 Challenges and opportunities in field of cloud data deduplication
(1) 基于内容加密的安全去重仍然是目前安全去重的主流方法, 但CE 不能为可预测的数据提供语义安全, 容易遭受暴力字典攻击.为了解决这一问题, 许多研究者引入第三方服务器协助云服务器进行数据去重, 例如, Bellare 等[52]提出了基于服务器协助加密的去重方案DupLESS, 在密钥服务器的协助下生成随机的安全密钥, 保证数据的安全性, 该方案可抵抗蛮力攻击, 但要求密钥服务器完全可信.然而, 完全可信的第三方实体在现实中难以实现, 可行性较低.在实际应用中, 第三方可信实体可能和攻击者共谋获取用户数据, 则用户数据安全难以保证.现有数据去重方案大多依赖于第三方可信实体, 导致方案的执行效率与安全性较低, 因此, 寻求能够摆脱第三方可信实体的数据去重方案成为了目前研究的热点问题.
(2) 现有的所有权证明方法能够防止隐私泄露同时抵抗哈希证明攻击, 但仍然存在计算开销大或是误判导致隐私泄露的问题, 同时现有方法不支持灵活的用户撤销.Jiang 等[62]利用随机收敛加密RCE 对文件加密, 并以密文文件来构建BF-PoW, 同时利用密钥加密树实现密钥分享和用户管理.但Bloom filter存在一定的误判率, 攻击者可以产生Bloom filter 中误判的块从而通过PoW 协议导致隐私泄露.因此, 如何构建一个低开销和隐私保护的所有权证明方法, 从而更好地达到云存储系统中数据共享与管理的要求,仍然是一个亟待解决的问题.
(3) 隐私保护的安全去重方案能够抵抗侧信道攻击, 同时保护用户的隐私, 但现有方案大多无法很好地平衡安全性能与带宽开销之间的关系.Yu 等[73]提出一种数据块对去重检测方案, 该方案可以同时对一个数据块对进行去重, 采用去重检查响应表、上传数据对的异或值等方法, 使得攻击者无法确认数据块是否发生去重, 但是造成了一定的网络带宽开销.Pooranian 等[74]在Yu 等[73]的基础上结合随机化方法提出了RARE 方案, 提供了更强的隐私保护, 但却造成了更多的网络带宽消耗.因此, 如何在隐私保护、安全去重以及效率之间取得折中, 还需要深入研究.
(4) 在基于数据流行度的安全去重中, 现有方案大多为所有上传的数据设置统一的阈值, 当统一的阈值过大时, 对于隐私程度较低的数据, 则在数据的副本数量未达到阈值之前, 需要全部存储在云服务器中,在一定程度上会造成存储空间浪费; 当统一的阈值过小时, 对于隐私程度较高的数据, 则会被过早地执行去重操作, 可能会增加数据隐私泄露的风险.因此, 隐私程度不同的数据应当具有不同的流行度阈值, 如何判断数据的隐私程度, 并根据其隐私程度设定一个合理的阈值, 是云存储服务发展过程中一个重要的研究课题.
5 结束语
随着大数据时代的来临, 大量的企业和个人选择将数据外包至云服务器进行存储和管理.当存储在云服务器中的数据不断增加时, 如何高效且安全地存储不断增加的数据, 是云服务器需要解决的一个关键问题.数据去重技术使得云服务器只需存储重复数据的单一副本, 极大地提高了存储利用率, 但同时也带来了隐私泄露、未授权访问等一系列安全问题.针对云数据安全去重的研究越来越广泛且深入, 但目前已有的各种去重方案均存在一些安全缺陷, 云环境下实现数据的安全去重领域仍需要不断地深入研究.
本文首先分析了数据安全去重技术面临的主要挑战, 包括数据外包与加密方式、侧信道攻击以及相关文件攻击, 详细阐述了数据安全去重过程中可能面临的安全威胁; 然后, 依据云数据安全去重的技术实现机制, 从基于内容加密的安全去重、基于PoW 的安全去重、隐私保护的安全去重和基于数据流行度的安全去重四个方面对当前研究工作进行了深入分析及总结, 指出了各种数据去重技术的优点、局限性及存在的共性问题; 最后探讨了数据去重技术研究的发展趋势.
