基于改进深度子域适应网络的图像分类方法
2024-01-10郝海燕
郝海燕,李 芳
(沈阳理工大学信息科学与工程学院,沈阳 110159)
以深度学习为基础的图像分类方法是计算机视觉中应用最广泛的技术之一。 为成功构建图像分类系统,需预先为每个特定的分类任务提供数量足够的标注数据集,且要保证测试数据和训练数据具有相同的数据分布[1]。 然而,人为采集的数据由于光照强度、拍照角度和使用场景各不相同,对其进行标注极为繁琐耗时,且对于医学影像、稀有动植物等特殊领域标准数据集的获取十分困难[2]。 此外,由于不同领域的数据分布存在差异,现有数据集训练出来的模型往往难以在有别于训练环境的目标领域保持良好的泛化性能,使得源领域的知识难以迁移到目标领域,即存在领域偏移[3]。 针对上述问题,人们提出了基于迁移学习的领域自适应方法,利用源领域中丰富的标记数据提高目标领域中未标记数据的分类准确率[4],从而改善模型在跨领域任务中的性能。
领域自适应方法按特征对齐方式分为两类:以度量学习为主的域适应方法和以对抗学习为主的域适应方法。 基于度量学习的域适应方法中用于衡量域与域之间分布差异的指标包括KL 散度、最大均值差异(maximum mean discrepancy,MMD)、沃瑟斯坦(Wasserstein)距离等[5]。 Pan等[6]将KL 散度与原型网络相结合,提出了可移植原型网络(TPN),使得源域和目标域中每个类的原型在嵌入空间中均比较接近。 Pan 等[7]使用MMD 衡量边缘分布的差异,并据此提出迁移成分分析(TCA)方法,实现了源域知识到不同但相关目标域的转移。 Li 等[8]基于TCA 提出了一种局部保留联合分布适配(LPJT)方法,将两个域的样本映射到一个低维特征空间,实现了条件概率分布和边缘概率分布的最小化。 基于对抗学习的域适应算法通过在域判别器上施加一个对抗性目标,将域间分布差异的度量转化为对源域和目标域进行领域混淆,从而使两个领域的特征分布尽可能一致。 Ganin 等[9]将生成对抗网络(GAN)的思想应用到域适应问题中,提出了域对抗神经网络(DANN),利用对抗学习方法对特征提取器和域判别器进行优化,实现了源域到目标域的知识迁移。 Shen 等[10]提出了Wasserstein 距离引导表示学习(WDGRL)方法,通过优化特征提取器,以对抗的方式降低了源域样本和目标域样本之间的经验Wasserstein 距离。 Tzeng 等[11]将对抗性学习与判别性特征学习相结合,提出了对抗判别域适应(ADDA)方法,通过非权重共享的方式完成源和目标的独立映射,从而学习更多领域特定的可提取特征。
与更细粒度的基于对抗学习的方法相比,基于度量学习的方法收敛更容易、收敛速度更快,但分类准确率较低。 Zhu 等[12]提出的基于度量学习的深度子域自适应网络(DSAN)则在保证收敛速度的同时,达到甚至超过了目前主流的基于对抗学习算法的分类准确率。 但DSAN 算法尚存在的问题有:缺少对数据集的处理,易在多种多样的跨域任务中出现过拟合现象;仅通过卷积运算提取特征,无法区分哪些特征更重要,导致丢失许多有价值的信息;只在子领域进行对齐,导致对全局特征的关注度不够,影响特征对齐效果。
针对以上问题,本文在DSAN 的基础上引入卷积神经网络正则化方法,加强模型在不同跨域任务中的泛化能力;加入高效通道注意力机制,使模型在提取特征时关注特征在通道间的关系,提取输入图像中的关键信息;增加全域适应损失约束,增强模型同时对齐全局特征和局部特征的能力,促使模型在训练过程中学习到更多用于域自适应的可转移特征,提升模型在无标签目标域上的分类准确率。
1 网络结构与原理
1.1 深度子域适应网络
DSAN 算法采用类别作为划分子领域的依据,其模型结构如图1 所示。 图中:Xs为源域数据;Xt为目标域数据;Ys表示源域数据的真实标签;和分别表示网络模型预测的源域和目标域数据标签;Zsl和Ztl分别表示Xs和Xt在l层激活(l=1,2,…,L),L表示神经网络的层数,在深度网络的第l层进行特征适应需将l层作为激活层。Xs和Xt通过深度神经网络时被映射到同一个特征空间,经过特征提取后,两个域的数据均被划分为若干个子领域,分别在l层的同一子域内对Ys和使用局部最大平均差异(local maximummean discrepancy,LMMD)计算源域和目标域数据分布的距离,通过使相关域的数据分布保持一致来减少域间的特征差异。

图1 DSAN 模型结构Fig.1 DSAN model structure
1.2 改进深度子域适应网络
1.2.1 神经网络正则化
为使源域上训练的模型在目标域上仍有良好的表现,需要提高模型的泛化能力。 DSAN 仅采用随机水平翻转的方式对训练集数据进行增强,该方式对模型在不同域适应任务中泛化能力的提升有限。
Dropout 是一种卷积神经网络正则化方法[13],Cutout 是基于Dropout 的扩展操作,Dropout 对经过网络提取后生成的图像特征进行遮挡,而Cutout 直接遮挡输入的图像,对噪声的鲁棒性更好。 Cutout 通过在输入图像中随机选取一固定比例的正方形区域,将这一区域的像素值设定为0 或其他统一值,从而对训练数据集进行加噪处理,防止模型过度拟合,同时增加数据集的多样性,进而提升模型在不同数据集上的泛化能力。经Cutout 处理后的数据集如图2 所示。

图2 经Cutout 处理后的数据集Fig.2 Data sets after Cutout processing
1.2.2 高效通道注意力机制
DSAN 模型主要依赖深度神经网络提取源域和目标域的特征,然后在该特征空间中对两个领域的特征进行对齐。 神经网络提取领域特征的效果对减少两个领域间的特征差异有直接影响,DSAN 采用ResNet50 网络模型进行特征提取,对图片的所有信息给予相同的关注度,无法区分图像的哪个部位更重要。 本文将高效通道注意力(ECA)模块[14]应用于DSAN 模型的特征提取网络,改进后的特征提取网络结构如图3 所示。

图3 特征提取网络Fig.3 Feature extraction network
首先通过卷积(Conv)操作对输入神经网络的源域和目标域数据进行特征提取,同时使用批归一化(BN)和激活(ReLU)操作加速模型收敛。为提升网络模型的表征能力,在最大池化(Maxpool)操作前加入ECA 模块,将卷积层输出的特征图进行通道注意力加权,以强化重要的特征并减少不重要的特征。 然后将加权特征图输入到残差网络中进行多个残差块(Residual Block)的计算,进一步对输入特征图进行特征提取,最终输出具有更高层次语义信息的特征图。
在特征提取网络中,ECA 模块通过全局平均池化(GAP)将维度为H×W×C的特征图进行空间特征压缩,获取1 ×1 ×C的特征图;对压缩后的特征图进行通道特征学习,通过一维卷积,学习不同通道之间的重要性,此时输出图像的维度仍为1 ×1 ×C;将经过通道特征学习的特征图(维度为1 ×1 ×C)与原始输入特征图(维度为H×W×C)逐通道相乘,最终输出带通道注意力的特征图。
在执行卷积操作时,卷积核大小会影响感受野的范围,对于不同尺度的特征图,需使用不同大小的卷积核才能有效提取信息,但这样会增加模型的复杂度和计算量。 为解决该问题,ECA 使用动态卷积核,通过自适应函数确定卷积核的大小,进行一维卷积,然后利用Sigmoid 函数学习通道注意力。 在通道数较大的层,使用较大的卷积核,更多地进行跨通道交互;在通道数较小的层,使用较小的卷积核,较少地进行跨通道交互。 卷积核大小s和通道数C的关系定义为
式中:odd 表示取奇数;γ和b用于改变通道数和卷积核大小之间的比例,分别设置为2 和1。
将ECA 引入DSAN 的特征提取网络可有效提高模型捕获跨通道交互信息的能力,有助于模型学习更高效的通道注意力,从而提取输入图像中的关键信息,学习更多用于域自适应的域不变特征。
1.2.3 全局特征对齐
DSAN 在进行特征对齐时,根据类别划分子领域,只考虑了源域和目标域相关子领域之间的关系,在对齐局部特征的同时,忽略了源域和目标域的整体对齐。
MMD 是一种用于度量源域和目标域分布距离的核学习方法[15],根据所选择的核函数不同,MMD 有不同的类型,对于某一个具体任务而言,选择最适配的MMD 比较困难。 多核最大均值差异(multi-kernel MMD,MK-MMD)是将多个核函数综合起来构造一个总的核函数,可避免核函数选择困难的问题。 MK-MMD 定义为
式中:p和q分别表示源域和目标域数据的概率分布,(p,q)为p和q之间的MK-MMD 距离;E(·)表示期望值;Hk表示一个再生核希尔伯特空间;φ(·)表示映射函数,通过该映射函数可将源域数据和目标域数据映射到同一个Hk;k表示与特征映射φ(·)相关的特征核。
MK-MMD 中的特征核k定义为m个不同核的加权和,设βu表示第u个特征核ku的权重系数,若满足βu≥0,且,则
将式(2)计算得到的(p,q)作为源域和目标域的全域适应损失项添加到损失函数中,重新构造的损失函数E表示为
式中:J(·,·)为交叉熵损失函数,用于计算分类损失;表示子域自适应损失函数;λ为域适应损失和分类损失的权衡参数。
为使模型更好地适应训练的不同阶段,采用动态调整λ的方式平衡域适应损失和分类损失之间的权重,λ计算式为
式中:t为当前的训练轮数;T为总训练轮数。 在训练初始阶段,λ取值接近于0,该阶段的主要任务是训练分类器;随着训练的深入,λ逐渐增大,最终趋近于1,域适应损失约束逐渐增强,该阶段的主要任务是将源域数据的特征迁移到目标域,并根据目标域的数据分布对特征进行调整和优化。
本文通过在损失函数中增加全域适应损失约束,促使深度自适应网络在训练过程中更加关注全局特征,源域和目标域数据达到更好的特征对齐效果,提高模型在跨域任务中的适应能力。
2 验证实验与结果分析
2.1 数据集
为证明改进算法的有效性,本文在公开数据集Office-31 上进行验证。 该数据集是域适应领域广泛使用的标准数据集,包含了31 类办公室环境中常见的目标物体,共4 110 张图像。 这些图像主要源于在线电商图片Amazon(A)、网络摄像头拍摄的低解析度图片Webcam(W)和由单反相机拍摄的高解析度图片DSLR(D),A 中有2 817张图片,W 中有795 张图片,D 中有498 张图片。
由于使用单一域适应任务会导致实验结果出现偶然性,因此本文选取并设定了A→W、A→D、D→W 三种不同的域适应任务,其中箭头左边代表源域,右边表示目标域。
2.2 实验环境与参数设置
实验环境采用Ubuntu 20.04 操作系统,GPU为Tesla P40,使用Python 3.8 版本,深度学习框架为Pytorch 1.11.0。
为方便训练,在数据集输入模型前,首先将图片大小裁剪为256 ×256。 实验中采用带动量的随机梯度下降算法进行参数更新,动量为0.9,批量大小为32。
2.3 实验结果分析
2.3.1 对比实验
本文采用未经域适应算法的普通模型(Source-only)及原DSAN 模型进行对比实验,各模型在A→W、A→D、D→W 三种跨域任务中的分类结果如表1 所示。
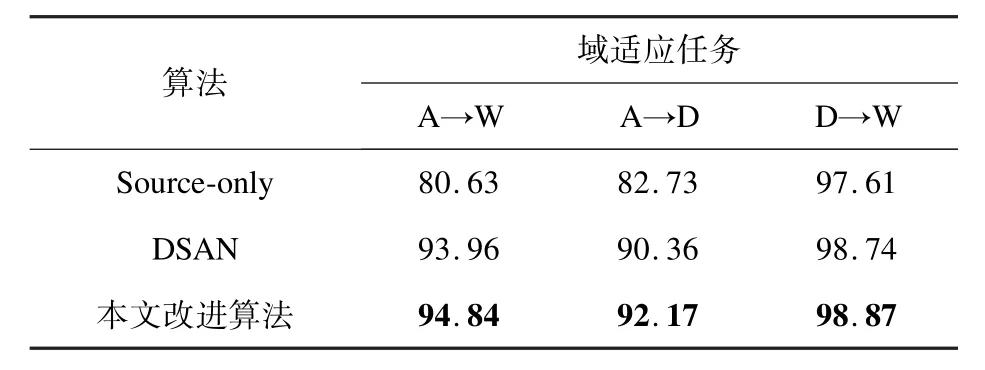
表1 不同域适应任务下的分类准确率对比Table 1 Comparisons of classification accuracy underdifferent domain adaptation tasks %
由表1 可以看到,与Source-only 相比,两种域适应算法均可显著提高跨域任务的分类准确率。 与原DSAN 模型相比,本文改进算法的性能在三种域适应任务中都得到了提升,在A→D 的域适应任务中,本文改进算法的准确率达到了92.17%,比原DSAN 算法提高了2.00%,在A→W的域适应任务中,本文改进算法的准确率相较于原算法提升了0.94%,在D→W 的域适应任务中,本文改进算法的准确率提升了0.13%。
为对比原算法和改进算法在不同迭代次数下的分类准确率,直观反映不同算法在整个训练进程中的性能差异和优化效果,图4 和图5 给出两个算法在A→D 和A→W 两个域适应任务中的分类准确率与迭代次数的关系。
由图4 和图5 可见:在训练的前20 轮,随着迭代次数的增加,原算法和改进算法的分类准确率均有较大提高;随着训练的深入,两个算法的分类准确率在达到一定水平后趋于稳定;在两个域适应任务中,本文改进算法在第10 轮到第50 轮的训练中始终比原算法保持更高的准确率,且在A→D 任务中分类准确率的提升优于A→W 任务。
2.3.2 消融实验
为进一步评估本文方法对域适应图像分类效果的影响,在DSAN 算法的基础上,通过依次改进损失函数、加入ECA、引入Cutout,探究各模块对算法性能的影响,在A→W、A→D 两个域适应任务中进行实验,结果如表2 所示。

表2 各模块对域适应图像分类准确率的影响Table 2 Impact of each module on the classification accuracy of domain adaptation image %
由表2 可见,本文方法通过改进DSAN 算法的损失函数,增加全域适应损失约束,在A→W 和A→D 任务中的分类准确率分别提升了0.40%和0.66%,说明全域适应损失约束能够促进特征对齐,增强对目标领域的适应性。 本文方法在网络结构中引入ECA,在A→W 和A→D 任务中的分类准确率分别提升了0.26%和0.67%,说明注意力机制能够更好地捕捉到特征之间的关系,进一步验证了其在域适应图像分类任务中的有效性;本文应用Cutout 神经网络正则化方法,在A→W和A→D 两个域适应任务中的分类准确率分别提升了0.26%和0.66%,说明Cutout 能够有效增强模型在不同数据集上的泛化能力。
2.3.3 实验结果可视化
三种域适应任务下源域数据和目标域数据在域适应前后特征对齐效果的t-SNE 图分别如图6、图7 和图8 所示。 图中红色表示源域样本,蓝色为目标域样本。

图6 A→W 任务的t-SNE 图Fig.6 t-SNE diagram of A→W task

图7 A→D 任务的t-SNE 图Fig.7 t-SNE diagram of A→D task

图8 D→W 任务的t-SNE 图Fig.8 t-SNE diagram of D→W task
由图6 ~8 可以看出:在域适应前,源域和目标域样本散乱地分布在一起,并没有呈现出明确的不同域间的特征关系;经过本文算法进行域间对齐后,源域和目标域中相同类的类间距离非常接近,同一类呈现出较好的聚集效果,不同类之间分散且类间距离较大。 本文提出的改进算法能够捕获每个类别的更多细粒度信息,使源域和目标域的分布尽可能保持一致,提升了特征对齐的效果。
3 结论
本文以DSAN 算法为基础,应用Cutout 缓解了过拟合现象,增强了模型的鲁棒性和泛化能力;引入ECA 增强了模型通道权重的选择能力,提升了模型特征提取效果,有利于模型在后续过程中进行特征对齐;训练过程中引入全域适应损失进行约束,提高了模型的全局特征对齐能力,促使模型在训练过程中学习更多用于域自适应的域不变特征。 在Office-31 数据集上的实验表明,相较于原算法,改进算法在跨域图像分类任务中表现更好。
