基于改进YOLOv7 的安全帽佩戴检测算法
2024-01-10杨大为张成超
杨大为,张成超
(沈阳理工大学信息科学与工程学院,沈阳 110159)
安全帽在建筑工地或矿区等场所是一种必不可少的防护工具,也是我国生产规模和使用量最大的个体防护产品之一,是安全工业和应急产品领域的重要组成部分。 针对工人在作业期间不佩戴安全帽带来的安全隐患,我国大部分场所都是通过人工形式对安全帽佩戴情况进行监督,难免出现疏忽等情况[1]。 为此,研究一种智能化且实时有效的安全帽佩戴检测方法有着重要的意义。
基于深度学习的目标检测主要分为两类:一类是两阶段目标检测算法;另一类是一阶段目标检测算法。 前者先由卷积神经网络生成一系列作为样本的候选框,之后进行样本分类和回归[2],代表算法有R-CNN、Faster R-CNN[3];后者直接通过主干网络得到目标的类别和位置信息,代表算法有YOLO[4]、SSD 和RetinaNet[5]。 两阶段的目标检测算法在检测精度上优于一阶段的检测算法,但是检测速度慢。 随着一阶段算法的发展,其检测精度不断上升, 本文在一阶段检测算法YOLOv7 的基础上进行改进,以期在保证实时性的同时获得更高的检测精度。
在安全帽检测算法的研究中,文献[6]通过先检测人脸再使用边缘检测算法检测人脸上方是否有安全帽的半圆形轮廓,但此检测算法计算量较大且抗干扰能力较差,漏检和错检的情况较多。文献[7]在YOLOv5s 模型的主干网络中引入注意力机制并替换主干网络中原有残差块,达到增强细粒度融合的能力,提高了算法的精度和速度。文献[8]通过改进的YOLOv3 将整个人体作为检测对象,完成安全帽的检测,但由于人体特征较多,其检测精度较低。 在工地或高危工作厂区大都存在人员流动大,目标存在遮挡或目标较小的情况,文献[9]通过使用并行网络模块增加网络宽度,并使用四尺度特征预测代替三尺度特征预测等方式保留更多特征信息,以提高YOLOv3 模型检测精度。 文献[10]通过在Faster R-CNN 网络中引入样本注意力机制和可变卷积等方法优化样本不均衡等问题,以提高目标检测精度,但其检测速度只达到每秒5 帧,无法做到实时检测。
综上所述,为保证实时性的同时获得更高检测精度,本文对YOLOv7 进行两处改进:首先,针对特征提取不充分等问题,在YOLOv7 中使用卷积块注意力机制(CBAM)替换原有卷积模块(CBS),增强特征的提取能力,使网络能够关注更多有用的特征;其次,为防止网络层数加深导致小目标的特征信息过多损失,采用增加小目标层的方法进行浅层和深层的特征信息融合,保留更多的目标特征信息。
1 YOLOv7 模型
YOLOv7 结构如图1 所示,包含输入端(Input)、主干网络(Backbone)、检测头(Head)三个部分。
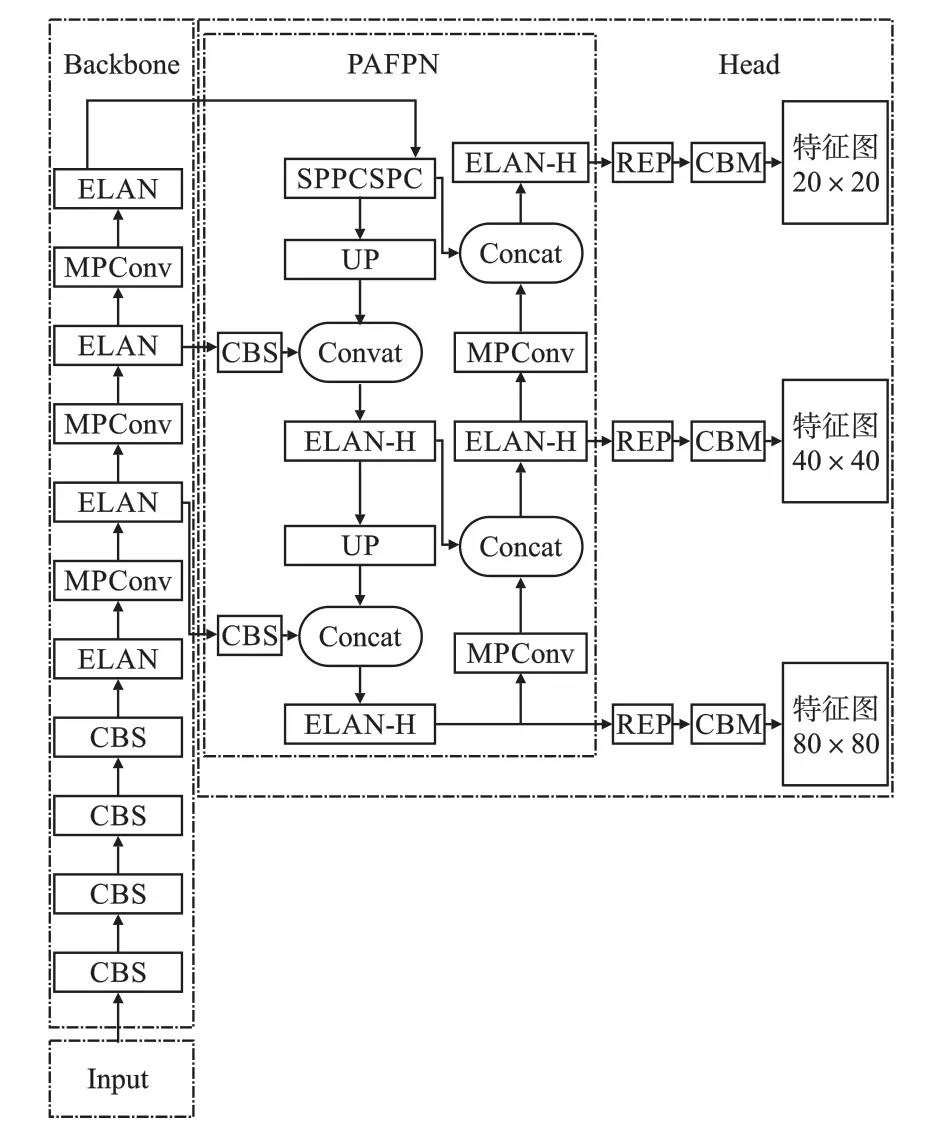
图1 YOLOv7 结构图Fig.1 YOLOv7 structure diagram
1.1 Input
Input 部分采用数据增强、自适应图片缩放等技术对图像进行预处理,数据增强方式能丰富数据集,自适应图像缩放则可有效地统一图像的尺寸。
1.2 Backbone
Backbone 的作用是提取输入图像的特征信息,为特征融合做准备。 其主要由若干CBS 模块、高效层聚合网络(ELAN)模块以及双分支下采样(MPConv)模块组成。 其中CBS 模块由卷积层、批量归一化层、激活函数组成。
ELAN 结构通过控制不同长度的梯度路径,使更深层次的网络在训练过程中能够有效收敛,其结构如图2 所示。

图2 ELAN 结构图Fig.2 ELAN structure diagram
MPConv 模块分为上下两分支,上分支通过最大池化(Maxpool)结合CBS 的结构进行一次下采样,下分支使用卷积步长为2 的CBS 模块进行下采样,最后将两者进行拼接(Concat)操作,防止在下采样的过程中丢失过多的特征信息,同时保持输入输出通道数相同,其结构如图3 所示。

图3 MPConv 结构图Fig.3 MPConv structure diagram
1.3 Head
Head 部分首先使用特征融合网络(PAFPN)进行两次特征融合,保留更多的浅层信息,其中SPPCSPC 模块通过不同尺寸的最大池化增大目标感受野,并提高了算法的计算速度。 UP 模块调整输入的特征图通道数并进行上采样,为与浅层特征融合做准备。 Concat 操作将输入特征图按通道维度进行拼接,以保留更多特征信息。 ELAN-H的结构与ELAN 类似,唯一的不同是ELAN-H 将每一层CBS 都进行了Concat 操作,保留更多的特征信息。 PAFPN 中的MPConv 模块与Backbone中的类似,通过调整输入特征图通道数为原来的两倍,并进行下采样与浅层特征尺寸对应,以便于进行特征图的Concat 操作。
其次,将输出的三个不同尺度的特征经过结构重参数化(REP)网络进一步提炼并经过卷积进行通道数的调整后进行目标预测。 其中REP 网络在训练时为一个三分支网络,通过不同尺寸卷积核进行特征提取,增加模型对特征信息的提取能力,在部署时三分支结构会转为单分支结构,增加模型的运行速度。 CBM 模块整体结构与CBS类似,主要作用是通过卷积层调整特征通道数。
2 YOLOv7 模型的改进
YOLOv7 虽有一定的先进性,但其在Backbone 中连续使用CBS 模块导致特征提取不够充分,丢失信息过多,且在特征融合时损失较多小目标的特征信息。 本文通过CBAM 替换原有CBS模块和增加小目标层的方式对模型进行改进,以期达到更好的检测效果。
2.1 CBAM
注意力机制是模拟人脑、将有限的算力聚焦于重要区域的算法[11],能够高效地分析复杂场景信息。 CBAM 结构如图4 所示。 CBAM 整体又可分为通道注意力模块(CAM)和空间注意力模块(SAM)两部分,CAM 结构如图5 所示,SAM 结构如图6 所示。

图4 CBAM 结构图Fig.4 CBAM structure diagram

图5 CAM 结构图Fig.5 CAM structure diagram

图6 SAM 结构图Fig.6 SAM structure diagram
在CAM 部分,首先将输入的特征图分别经过平均池化和最大池化,得到两个长、宽均为1 的特征图,再将两者送入共享多层感知机中,将得到的两个特征图相加之后经过激活函数得到通道特征图,整体过程用公式表示为
式中:Mc为输出的通道特征图;F为输入特征;MLP 为多层感知机;AvgPool 为平均池化;Max-Pool 为最大池化;σ为激活函数。
将CAM 部分所得特征图与F相乘得到特征图F' 作为SAM 部分的输入,分别经过最大池化和平均池化,得到两个通道数为1 的特征图,将两者Concat 到一起,通过卷积降维操作和Sigmoid 激活函数生成空间特征图,整体过程用公式表示为
式中:Ms为输出的空间特征;F' 为输入的空间特征;f7×7为7 ×7 卷积。 在CBAM 前添加一个卷积模块,用于调整输入特征图的通道数,使CBAM能够直接替换原CBS 模块,简化网络的修改。
2.2 小目标层
小目标的划分主要分为两类:一类是以相对尺寸划分,要求检测目标的高宽要小于图像高宽的十分之一;另一类是以绝对尺寸进行划分,如MS COCO 数据集要求小目标的像素值小于32 ×32。 小目标相比于大、中目标在特征提取时信息过少,匹配锚点框的训练效果较差,影响检测精度[12]。 文献[13]通过改进Faster R-CNN 算法提高无人机对小目标的识别精度,文献[14]通过改进YOLOv5s 的网络模型提高算法对安全帽的检测精度,文献[15]通过改进SSD 算法提高模型对于小目标的检测精度和速度。 在目标检测过程中,小目标的特征信息会随着网络模型的加深逐渐消失,在环境复杂多变、人员流动性强的情况下,小目标检测精度仍需提高。
本文提出在YOLOv7 模型的基础上增加一个小目标层的方法。 该方法的思想源于PAFPN,在原YOLOv7 结构中,通过PAFPN 会输出三种尺寸的特征,该方法是将浅层特征与深层特征融合,达到即使在深层网络中依然可以保留小目标信息的作用。 本文增加的小目标层可以将更浅层特征与深层特征相融合,进一步保留小目标特征。 本文改进后的YOLOv7 模型结构如图7 所示。
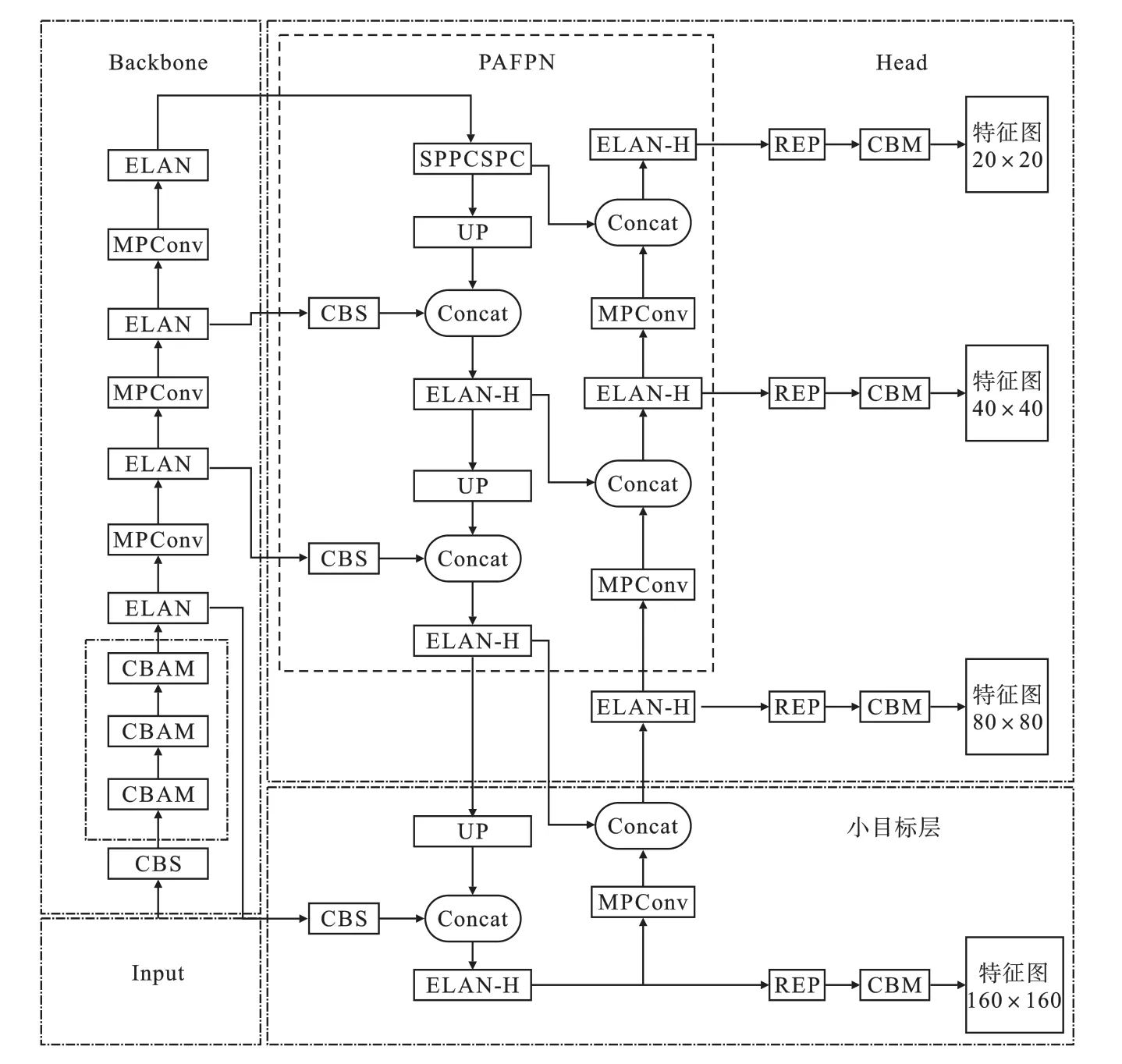
图7 改进后YOLOv7 结构图Fig.7 Structure diagram of improved YOLOv7
3 实验与结果分析
实验运行的服务器环境配置如下:CPU 型号为E5-2680 v4@2.4 GHz,显卡型号为RTX2080Ti,系统为Ubuntu 20.04,深度学习框架采用pytorch 1.9.0。
3.1 数据集与评估指标
本次实验采用的数据是从开源的SHWD 数据集中抽取1 500 张图片,该数据集中被检测对象共分为两类:佩戴安全帽的人(hat)和未佩戴安全帽的人(person),两者样本个数比约为1∶13。 将本次实验所用图片按照8∶2 的比例划分为训练集和验证集进行实验。 采用数据集样本如图8 所示。

图8 样本图像Fig.8 Sample images
SHWD 数据集虽然不是完全的小目标数据集,但小目标占比较大,一定程度上能够反映算法对小目标的检测能力。
本次实验所采用的评估指标包括准确率(Precision),召回率(Recall),均值平均精度(mAP)。
3.2 实验结果分析
为验证不同个数的 CBAM 替换对原YOLOv7 模型的影响,本文进行四组对比实验,结果如表1 所示。
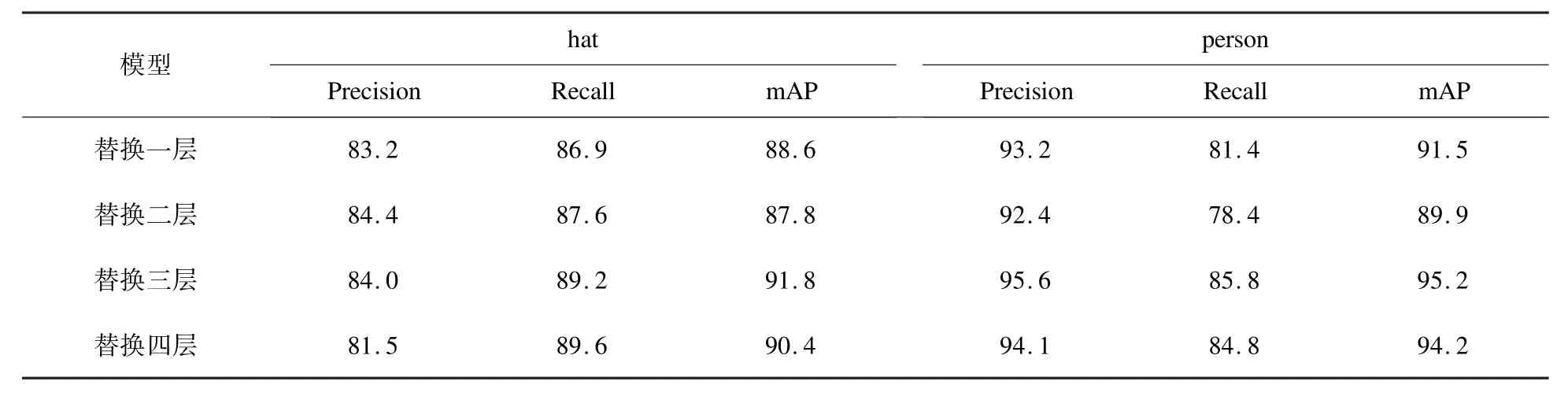
表1 四组实验结果对比Table 1 Comparisons of four experimental results %
从表1 可见,随着CBAM 替换数量的增加,算法的检测精度并未一直随之上升,替换三层后的结果相对较好。
为验证本文算法的改进效果,将本文改进算法与其他检测算法进行对比实验。 具体结果如表2 所示。
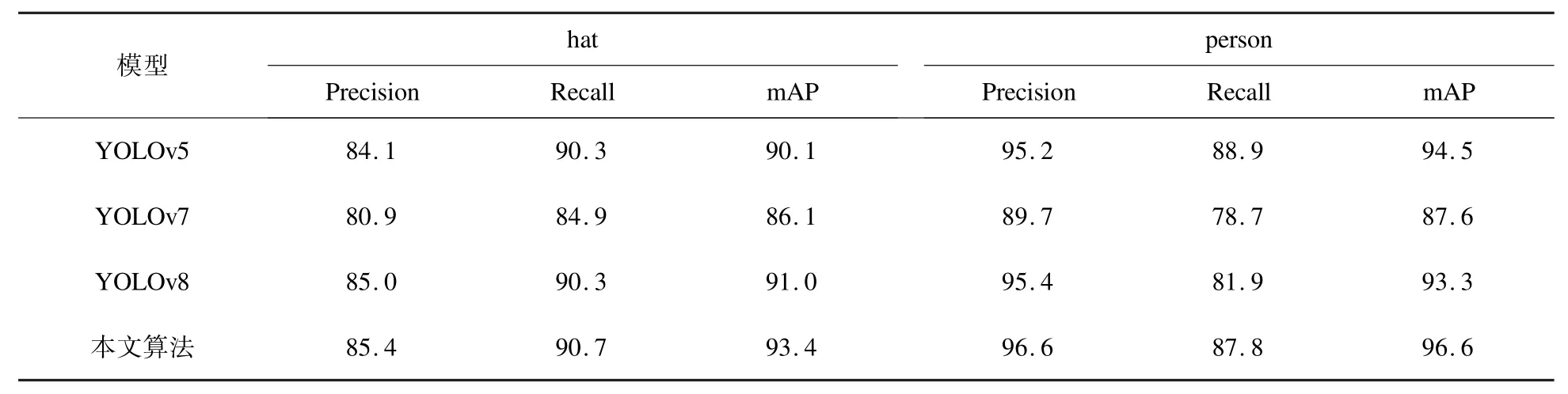
表2 不同算法检测结果对比Table 2 Comparisons of detection results with different algorithms %
从表2 可见,本文提出的改进算法的检测精度优于其他算法。 在研究过程中,还进行了不同改进方式的对比实验,具体实验结果如表3 所示。
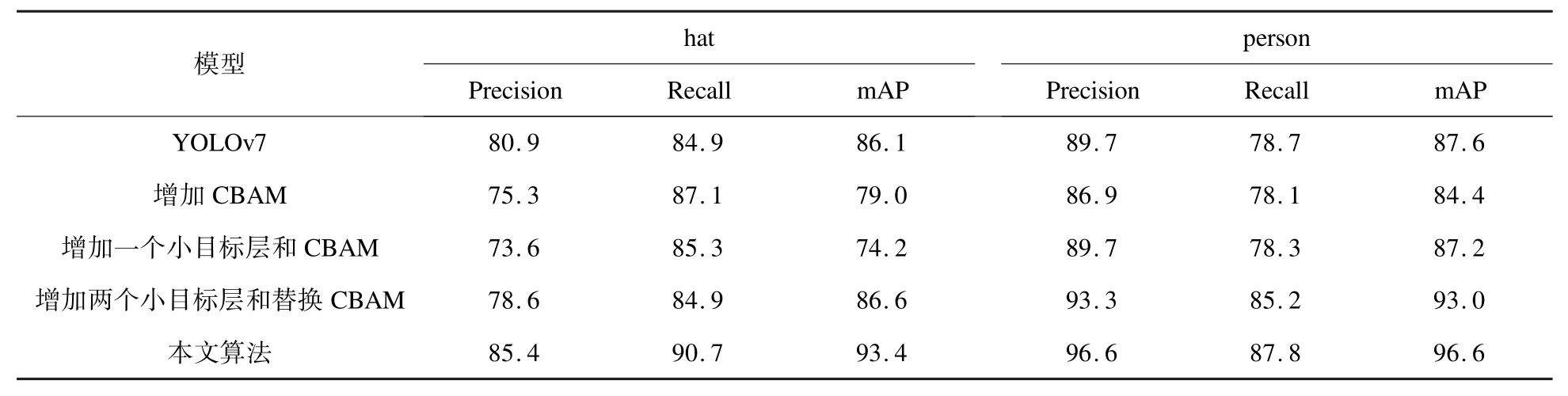
表3 不同改进方式检测结果对比Table 3 Comparisons of detection results with different improvement methods %
在改进方式的对比研究中,首先在Backbone中每相邻的两个CBS 模块之间增加一层CBAM,具体增加位置如图9 所示。
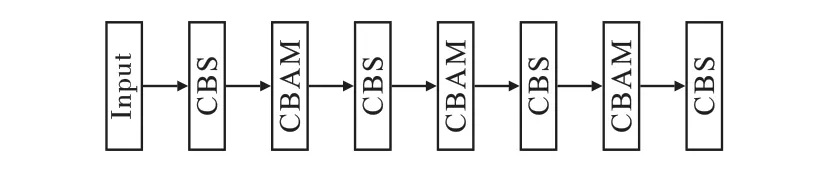
图9 CBAM 增加位置结构图Fig.9 CBAM added position structure diagram
在此基础上增加小目标层再次进行测试,通过表3 中数据可以看出,本文改进算法目标检测效果更好;增加多个小目标层后精度不升反降,并且会导致模型参数量增加,降低模型的检测速度。
经实验测试,原YOLOv7 模型检测速度约为每秒60 帧,本文改进算法约为每秒45 帧,虽然检测速度有所下降,但较大提升了目标的检测精度。
4 结论
针对工地或矿区等场所因环境复杂多样,工人在工作期间时常会出现人员聚集、人员遮挡等不利于安全帽佩戴情况检测,造成漏检或错检的问题,本文提出了改进的YOLOv7 检测模型,该模型在YOLOv7 的Backbone 中使用CBAM 替换CBS 模块,使算法能够提取更多有效特征,再加入小目标层以防止小目标特征随着模型深度的加深而损失过多。 与原YOLOv7 模型所进行的对比实验表明,对安全帽佩戴检测的mAP 指标由86.1%提高到93.4%,实现了目标检测精度的提升。
