基于多门混合专家网络的情感分析与文本摘要多任务模型
2024-01-04车文刚
杨 程,车文刚
(昆明理工大学信息工程与自动化学院,云南 昆明 650500)
0 引 言
近年来,大量的文本数据得以生成并可用于进一步的分析与处理,这些数据主要来源于在线文档、文章、新闻和评论等。为了更好地完成下游任务,对这些长文本串进行摘要处理显得尤为重要[1]。文本摘要的方法通常被分为两大类:提取式摘要和抽象式摘要[2]。抽象式文本摘要需要理解文档来生成摘要,因此抽象式摘要的模型通常需要实词知识和语义类分析[3]。各种深度学习模型已被用于抽象摘要,包括RNN、卷积神经网络(CNNs)和序列到序列模型。很多研究者注意到情感分析的结果与文本摘要的结果结合可以对学习过程和结果进行优化。文献[4]通过将文本摘要及用户评价的情感结合分析,提出了一套评价推荐系统的方法;文献[5]使用BERTSUMEXT 提取文本摘要,采用LDA 进行主题建模,通过FinBERT 进行情感分析以及使用决策树和随机森林进行性能预测,最终为决策者提供了年度报告内容的详细解释,及其与未来公司业绩的关系;文献[6]通过有效性分析帮助提取基于情感分析酒店评论摘要。
目前针对多任务模型的优化主要基于针对结构的调整,通过不同的策略更好地学习任务的共享信息。例如:MMoE[7](Multi-gate Mixture-of-Expert)模型采用多门控制机制来平衡多任务,拓展了MoE[8](Mixture-of-Expert)模型;PLE[9](Progressive Layered Extraction)模型通过联合表示和信息路由的角度,采用渐进式分层的方法分离了任务的特定参数和共享参数。然而这些优化主要针对普遍领域的优化,在一些特定领域,仍然可以根据任务的特点进行进一步的模型架构和机制调优。
在MMoE 模型中,塔层网络结构和专家层网络结构均是由深度神经网络构成,然而在处理文本数据的能力上,循环神经网络模型被证实能获得更佳的效果[10]。文本摘要与情感分析任务均是基于文本数据进行学习,采用序列到序列的编码解码模型对MMoE 原有的深度神经网络进行重构,可以使模型能够学习到上下文信息以及更精确的文本理解能力,帮助模型获得更优的效果。但是在采用模型重构后,原有专家层的输出由一个单纯的输出变为了最后一个时刻的隐藏层状态和上下文信息,因此需要针对新的模型设计门控制网络机制。MMoE 中的门控制网络机制是根据输入计算然后不断学习得到权重矩阵,这种计算方式很难快速反映出每个输出针对每个任务的重要程度。然而采用循环神经网络替换深度神经网络后,可以应用注意力机制中针对每个输入向量计算出的上下文权重值替换简单根据输入计算出的权重,由于上下文权重值表示的是每个输入向量需要注意的程度,因此,学习起来会更加快速。此外,MMoE 没有专注于特殊任务的信息学习,采用的是共享专家层的信息进行学习后加权输入到特殊任务的塔层网络,由塔层网络进行学习。将专家层和塔层设计为序列到序列的模式之后,每个专家网络的隐藏层信息不进行加权,直接输入塔层网络,结合两个任务互相学习到的上下文信息进行解码,既可以获得任务之间的共享信息,也可以学习到任务之间的独有信息。最后,基于文献[11]使用的方法证实的文本摘要任务和情感分析任务有相互促进的效果论证,提出了一种新的门控制网络之间的权值注意力修改机制。该机制在对于一个文本需要摘要和情感分析的情境下,可以优化注意力机制针对实词知识和语义分析的学习,从而帮助带有注意力机制的模型获得更高的准确率和更快的收敛。
1 专家层及塔层网络重构
序列到序列的模型[10]在许多自然语言处理的问题上获得了最优的成果,包括文章摘要[12]、情感分析[13]等。其中由两个循环神经网络组成的编码器解码器的模型已经被证实在处理由一个序列生产新的序列问题上相比普通的模型有着更优的效果[14]。序列到序列模型重构后的MMoE 模型架构如图1 所示。
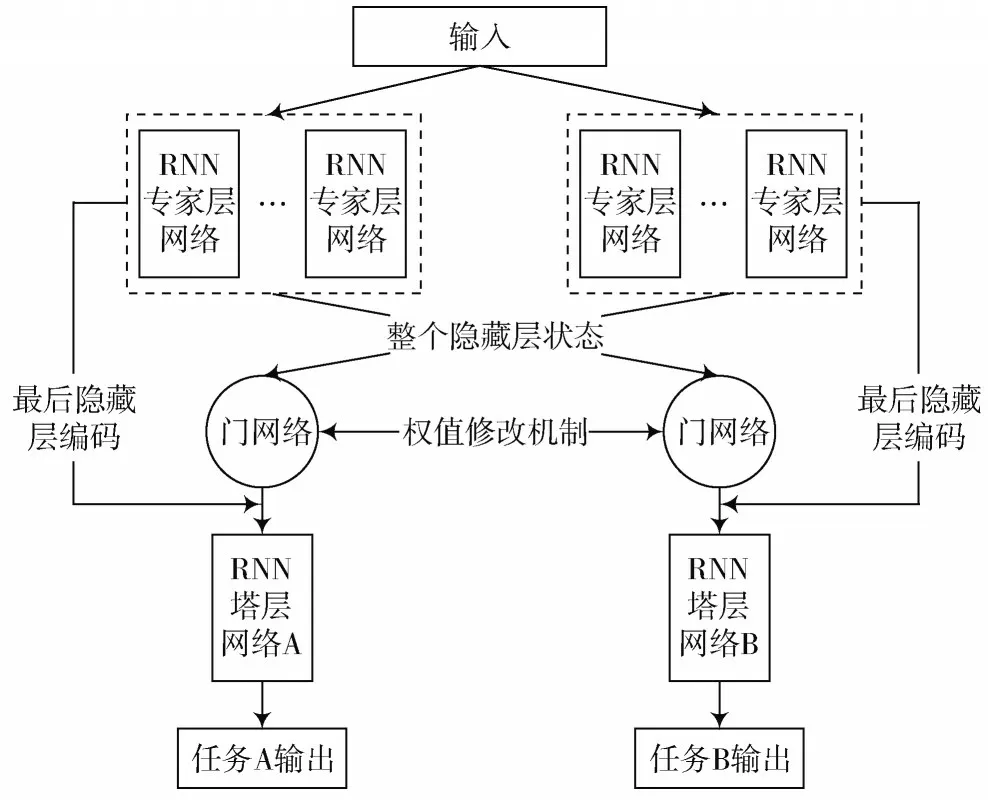
图1 使用序列到序列模型重构后的MMoE 模型架构
如图1 所示,由于每个任务是由带注意力机制的序列到序列模型组成,为了让模型能够学习到特定任务独有的信息,将注意力机制计算出的最后一层隐藏层编码传入塔层协助解码工作,同时专家层学习到的上下文信息会输入到门控制网络进行加权学习共享信息。在门控制网络之间将会利用文献[10]提出的理论重新设计权值矩阵,并且在门控制层网络之间相互共享权值信息,之后根据共享的权值信息对自身权值矩阵进行更新,从而加快权值矩阵的学习。
其中RNN 专家网络层模块的设置需要进行一定的调优。在MMoE 模型中,由多个专家层模块同时学习输入值,之后由各自任务的门控制网络对所有专家层的输出进行加权。然而在替换后的模型中,由于需要将每个专家层的隐藏层状态直接传入到塔层模块,以学得任务自身独有的信息,因此每个任务需要有一个独立的专家模块,但该专家模块中可以有多个专家网络,之后将多个专家网络学习到的信息进行加权输出,那么专家层模块中的专家网络数量即为一个超参数,可根据实际情况进行调整。
在采用序列到序列的模型网络后,将会面临如下几个问题:
1)专家层的输出由原始的运算结果矩阵变为了隐藏层的状态,需要对门控制网络进行修改。
2)MMoE 模型中的门控制网络是根据输入学习权重矩阵,然后根据权重矩阵对专家层学习到的信息进行加权。这一做法忽视了对每个任务独有信息的学习提取,仅仅针对共享信息进行加权之后传入各自任务的塔层结构。
3)上下文信息更加符合对于目前每个词向量信息的描述,因此相比专家层的输出更加适合作为两个任务进行加权学习的对象。
为解决以上问题,针对MMoE 的网络架构进行如下修改:
设计新的门控制网络结构,其详细架构将在第2 节进行介绍,新设计的架构不仅能够匹配序列到序列模型的解码层信息进行学习,同时在学习任务联系时相比MMoE 有着更全面的信息和更好的初始状态。
为了使得每个任务能够学习到专注于自己任务的信息,将每个专家层网络的隐藏层编码私有,直接传到塔层网络架构。同时,为了获得任务之间的共享信息,将每个任务之间的上下文信息共享,并且通过第3 节中的权值机制修改计算上下文信息的权重,从而更快地促进当前任务的学习。
2 门控制网络重构
如图2 所示,输入向量通过不同的权重矩阵加权相加后进行Softmax 操作,得到了一个用于决定专家网络的所有输出在对应任务中分别应该占有的权重。这一做法很难真实地反映出任务之间的联系和区别,与输入加权的权重矩阵也需要由随机值不断学习,其学习的速度也相对较慢。因此,本文采用注意力机制计算出针对每个词向量的权重作为对应专家网络的加权矩阵,同时结合另一个专家网络注意力机制计算出的权重计算在本任务中对专注另一任务的专家网络的输出加权。
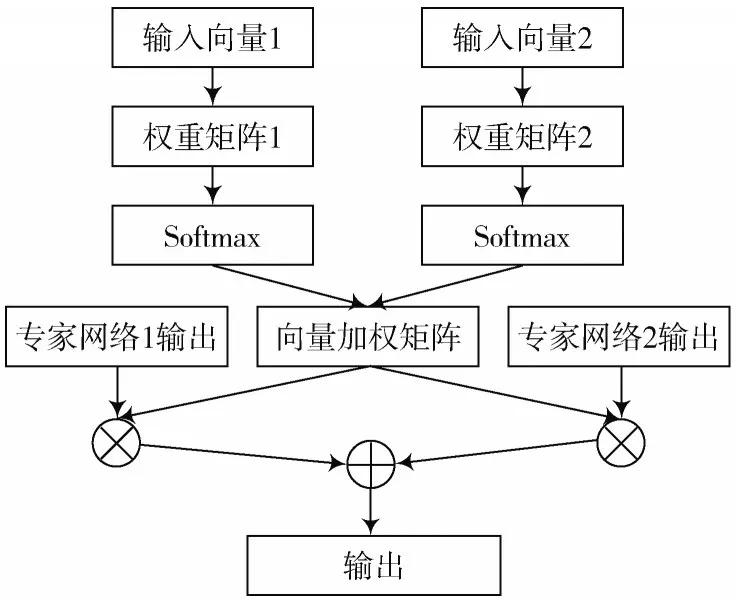
图2 MMoE 门控制网络层结构
从MMoE 模型的门控制网络层的计算公式可以看出,门控制网络层的思想类似于Attention 机制中使用权重矩阵相似函数计算相似度,其权重计算依赖的是输入值,且每个任务的权重由自己学习得到。
根据文献[15]提出的在序列到序列模型中加入注意力机制的思想,将原本的权值计算改为结合循环神经网络注意力机制的权重计算。在序列到序列的模型中,解码层除了接收到编码层的隐藏层信息,还有上下文信息,上下文信息的权重计算公式如下:
公式(2)为对齐模型,可以用于评估位置j附近的输入和位置i的输出的匹配程度,其程度大小由i-1 的隐藏层状态和j的注释决定。在新的门控制网络中,每个任务的权重矩阵由上下文信息权重组成,而不是MMoE中随机生成的权重矩阵。同时,该矩阵在生成之后还会经过第3 节中的权值修改机制进行修改。最终,将两个专家层网络中的注释信息通过各自的门控制网络中的权重矩阵进行加权求和,分别输送给各自的塔层任务。
如图3 所示,在任务1 的门控制网络模块中使用当前专家网络的每个隐藏层状态和信息求出的权重作为当前专家层网络任务权重矩阵,而针对另一个专家层的权重矩阵,则是结合两个任务中的门控制网络收到的权重根据权值修改机制生成,最后将两个专家层网络的注释信息传入各自门控制网络后加权求和作为各自塔层网络的输入。这一权重矩阵对比其随机初始的权重矩阵可以更合理地表示针对专家层每个输出的重要性,通过使用每个向量对应的隐藏层状态权重来替代随机初始化的权重矩阵,使得整个模型收敛速度加快。通过将针对两个任务的专家层的输出权重分开处理,保证了本任务的主要影响性,同时也兼顾了另一任务与本任务之间的联系和共享信息,并且由于权值修改机制是基于两个任务之间相互促进理论设计,可以使得权重矩阵进一步体现出任务之间的联系。
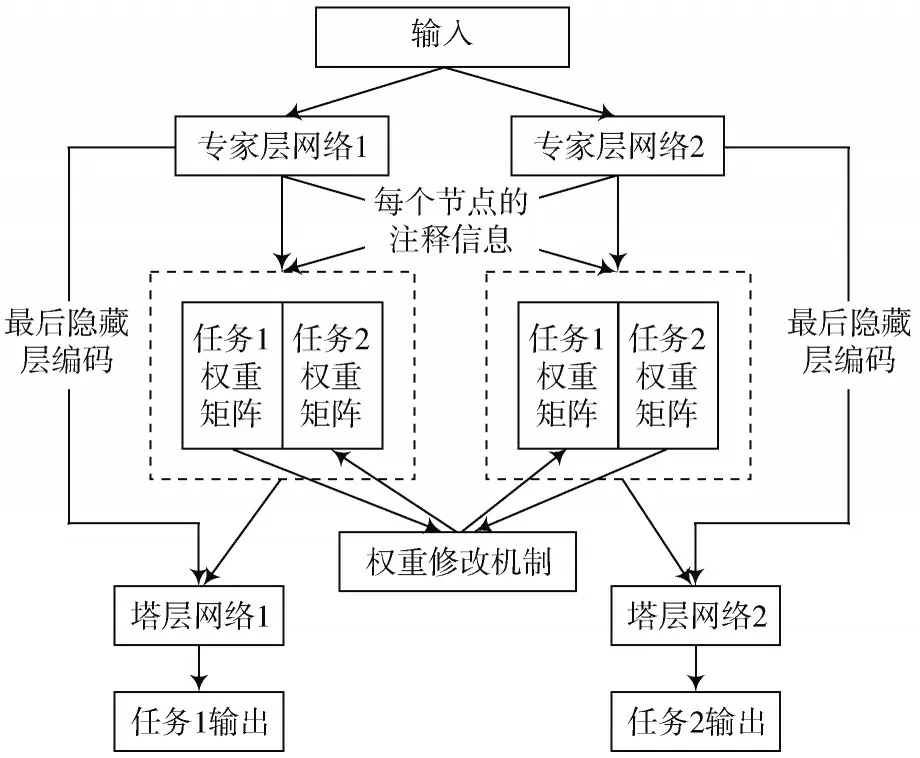
图3 优化后的MMoE 门网络层模型
3 权值共享修改机制
文献[11]研究了从非结构化文本中获取情绪、观点、态度等多方面信息的方法,同时发现,在文本提取时模型会尽可能详细地查看文本中感兴趣的领域,但是由于主观性的句子经常包含一些隐喻性或者看似与文本摘要相关的表达,导致模型会错误地关注这些主观性的句子。因此,如果能在文本摘要的材料中剔除主观色彩的部分,将会提高文本摘要提取的速度和准确率,在主观分析中亦是如此。
本文总共提出了两种权重修改机制:
1)直接修改策略。使用文章摘要作为主导,仅使用注意力机制的权重计算机制计算出文章摘要任务的权重,然后根据文章摘要任务的权重生成情感分析任务的摘要。情感分析任务的权重为单位矩阵减去文章总结任务的权重矩阵,为了方便后续计算,再进行归一化。WE为事件提取任务的权重矩阵,WS为情感分析任务的权重矩阵,可以形式化表示为:
2)辅助修改策略。使用文章摘要任务作为主导,但是同时计算两个任务的权重矩阵,然后按照一个设定的比例,依据文章摘要任务的权重对情感任务的权重进行修改,可以形式化表示为:
式中λ为设定的0~1 的数值,用于决定文章摘要任务中的权重对于情感摘要任务的权重影响大小,在第4 节实验中,当λ取0.8 时取得的效果最优。其思想为:当文章摘要任务的权重小于权重平均值时,则适当增加该信息在情感任务中的权重,反之,则减少,起到决定事件提取任务中对于该向量的权值是增加还是减少的作用,若事件提取任务中,该词向量的权值大于该向量在情感分析中的权值,则增大比重。公式最后一部分确定修改权值的大小,若情感分析任务中该向量权值较大,则修改较大。同时,两个任务针对该向量权值之和作为分母,可以使两个权值都较大时,适当减少修改的值。
在第4 节的实验中,对比了两种机制两个任务的消耗和结果,最终选择第二种权值修改策略。
4 实验与分析
本节一共设置3 个实验,首先是针对优化前后的MMoE 在两个任务的准确度和时间损耗进行对比,证明模型优化的有效性;之后针对直接修改策略、不同参数的辅助修改策略以及原始MMoE 的性能进行对比,证明权值修改策略的有效性及得出最佳参数;最后,采用消融实验证明每一步优化的有效性。
实验采用NLPCC2017 摘要任务数据集,对于文本摘要任务的评估,采用数据集中的标题作为标准,计算预测结果的Rouge-1、Rouge-2 及Rouge-L分数;对于情感分析任务,将文献[16]提出的Bert 模型运用于情感分析进行训练,并且将训练好的模型对NLPCC2017 数据集进行情感标注,之后用于情感分析任务训练。
4.1 MMoE 与优化后的MMoE 模型性能评估
如图4 所示,优化后的模型针对原始MMoE 在任何一个Rouge 指标的评价下都取得了更好的得分,其中Rouge-L的得分差距最为明显,而Rouge-L指标是依据最长子序列的准确率进行计算,表明优化后的模型在正确找到最长子序列的能力优于原始模型,具备更佳的理解能力。

图4 MMoE 与优化后的MMoE 在摘要任务上的预测能力评估
如图5 所示,将每次训练两个模型的准确率进行对比,在第一次训练中,优化后的MMoE 与MMoE 差值最大,准确率提高了5.12%。然而在第二次训练时,准确率低于原始模型。通过对判断错误的评估数据集进行分析,发现优化后的MMoE 由于权值修改机制,导致在一个任务学习到错误的权重矩阵后,对另一个任务权重矩阵进行修改将会使得学习到的错误信息进行传递,从而出现更多的错误预测。因此,提出以下两种可深入研究的解决方案:
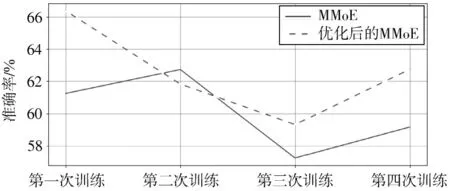
图5 MMoE 与优化后的MMoE 在情感分析任务上预测能力评估比较
1)采用随机不进行权值修改的机制,牺牲部分性能来减少错误传递。
2)采用预训练,减少学习到错误信息的情况。
4.2 权值修改机制性能评估
针对权值修改策略,在第3 节中提出了两种方法:第一种为直接使用情感分析的权重矩阵决定事件提取的权重;第二种为参考事件提取任务的权重对情感分析任务的矩阵进行一定程度上的修正。实验将针对几种不同策略进行对比,得出性能最佳的策略。不同权值修改策略Rouge 分数对比如表1 所示。
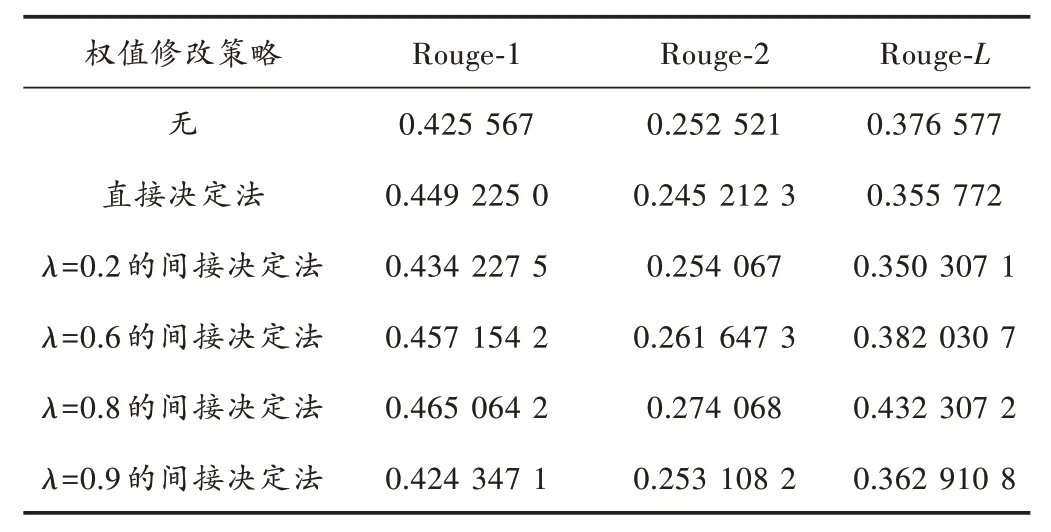
表1 不同权值修改策略Rouge 分数对比
如表1 所示,可知当λ取值较低时,对于文本摘要任务权值的修改并不大,从而并不能很好地体现出权值修改策略的优化效果。随着λ的提升,情感分析任务对于文本摘要任务的促进效果逐渐明显,在λ=0.8 时达到最优效果。而对于直接决定策略,有时候过于简单的判断二者之间的关系,导致在部分得分上甚至低于不采取任何权值修改策略。
4.3 模型消融实验
表2 为不同优化的模型性能对比,仅仅进行网络架构和门控制网络重构的MMoE 模型针对原始MMoE 在文本摘要任务上性能提升,最低为Rouge-2 分数提升,在MMoE 的基础上提升了4.3%;最高为Rouge-L分数提升,在MMoE 的基础上提升了6.6%。而加入权值共享机制的完全优化MMoE 在网络结构重构的MMoE 基础上又进行了提升,其中完全优化的MMoE 在Rouge-L分数上提升最明显,比仅结构重构的MMoE 提升了7.7%。同时,在情感分析任务中,准确率也在每一步优化后都得到了提升。因此,本文提出的方案都对MMoE 模型进行了有效的优化。
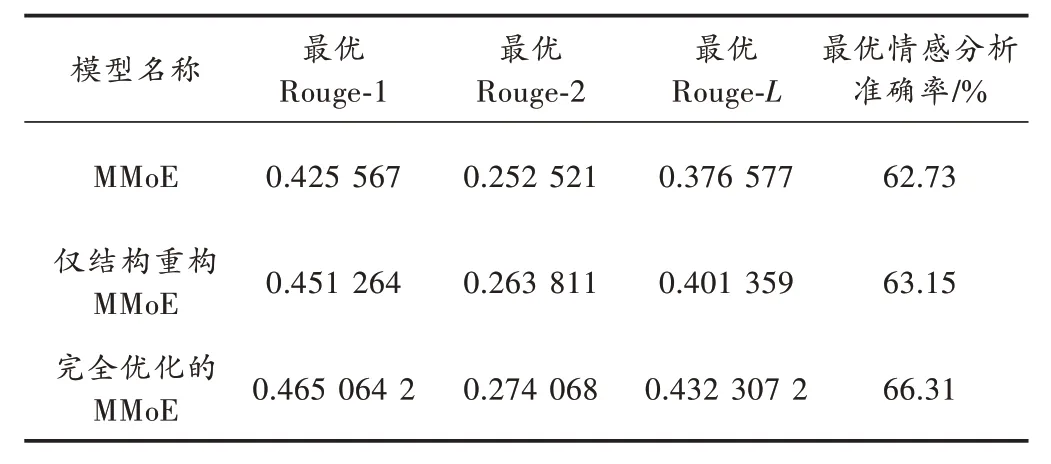
表2 不同优化模型的性能对比
5 结 语
为解决MMoE 模型针对情感分析和文本摘要这一特定领域内对文本信息处理能力的不足,采用带有编码解码架构的序列到序列模型替换原始MMoE 模型中的深度神经网络。同时,为了解决架构替换后带来的数据不匹配及MMoE 模型缺少针对任务独有信息的学习不足问题,对网络架构进行调整,并设计了新的门控制网络架构。为了解决MMoE 模型针对任务之间联系学习能力不足,引入注意力机制并设计了新的门控制网络权值初始化机制,同时基于文献[11]证实的情感分析和文本摘要互助理论,提出了权值共享修改机制,帮助门控制网络更好地学习到任务之间的联系。最终,通过实验选择最佳的权值共享修改机制,同时证明了经过以上优化的模型相比于MMoE,在文本摘要任务上,Rouge-L的分数在MMoE 的基础上提高了14.82%,在情感分析任务上准确率最高提升了3.64%。
但是模型仍然存在着错误传递的问题,即当一个任务学习到错误的信息,在依照该任务权值进行权值修改时会将错误传递至另一个任务的权重矩阵。可以从减少错误的传递、减少错误的出现等方面进行改进,例如:设计一定概率不进行权值共享的机制或者使用预训练提高模型学习的准确率等。
