基于多模态信息相关度计算的计算机教育领域实体链接
2024-01-02王会勇张晓明
郭 沛,王会勇,张晓明
(河北科技大学 信息科学与工程学院,河北 石家庄 050018)
0 引言
人工智能为教育智能化创造了机遇,特别是以知识图谱为核心的技术,能将学科中的知识体系联系起来构建知识图谱。但在学科教育中,其知识体系并不是一成不变的,因此学科知识图谱[1]的更新已成为研究热点和趋势,而实体链接作为更新知识图谱的关键技术显得尤为重要。在计算机学科领域,将与概念有关的图片关联到知识图谱对应实体上,可增强知识图谱的表达性,提高知识图谱[2]可用性。
目前,实体链接方法主要是针对文本和视觉两种模态。特定领域中,一些实体含义需要通过上下文语义确定,一词多义或多词一义等现象比较普遍[3],因而一些由单词拼接的领域实体较难识别,故仅使用文本的实体链接有一定局限性。多模态实体链接则是结合多种模态信息完成链接,多模态知识表示学习[4]则将图像特征和文本特征一起嵌入到统一低维空间[5-7],计算实体之间的相似性以寻找最佳链接点。但在多模态知识表示学习的训练过程中,能够实现对齐的多模态实体全部用人工标注,会造成巨大的浪费[7]。Zhang 等[8]设计了一个两阶段机制,首先确定图像和文本之间的关系,以消除噪声图像的负面影响,然后执行消歧。Gan 等[9]分别消除了视觉提及和文本提及的歧义,然后使用图形匹配探索模式、提及之间的可能关系。但这些模型泛化能力和其应用数据集中的实体类型都比较受限。
本文面向计算机学科领域提出一种实体链接方法,将图像及其文本描述分别转化成图像视觉实体和三元组以帮助图像完成链接。图像和文本属于两种不同的模态,如何有效地将两者结合以完成实体链接是一项关键挑战。本文主要贡献如下:①面向计算机学科领域提出一种从图像的文本描述中提取并筛选三元组的策略,先抽取图像文本描述中的三元组,过滤低置信度的三元组,再通过计算图像视觉实体和三元组头尾实体的相关度之和对集合中的三元组进行排序,最后得到与图像相关度最强的三元组,用于图像链接到多模态知识图谱后的扩展任务;②面向计算机学科领域提出一种实体链接规则(Visual Entity Linking Rules,VELR),该规则依次利用图像视觉实体、与图像视觉实体相关度最强三元组中的头或尾实体以寻找最佳链接点;找到链接点之后,利用不同的链接策略,通过图像视觉实体替换与图像相关度最强的三元组中头或尾实体形成的新三元组,对链接后的图像或文本进行扩展。
1 相关工作
早在2013 年,Chen 等[10]手动框出图像中的实体并打上标签,通过标签内容完成链接。但是人工注释成本不仅高,而且会造成巨大的人力物力浪费[11]。因此,Alberts等[12]直接计算输入图像和多模态知识图谱中所有图像的余弦相似性,将相似度最高节点作为其最佳链接点。但是单模态下,该方法有一定局限性,如信息量少、语义不够丰富等,会影响最终链接效果。
多模态实体链接则聚合了多模态信息。Moon 等[13]首先解决多模态实体链接任务,他们在社交媒体帖子中提取实体链接的文本、视觉和词汇信息,并利用社交平台上文字所附照片提供视觉背景辅助消歧。Wang 等[14]提出一个多模态实体链接数据集WIKIDiverse,并基于WIKIDiverse实现了一系列具有模态内和模态间注意力的多模态实体链接模型。Gan 等[9]则重新定义了多模态实体链接,先分别做文本和视觉实体链接,之后将文本提及和视觉提及的对齐建模为二部图匹配问题以完成多模态联合消歧。但这些多模态实体链接方法是基于自己数据集而提出,应用到特定领域的效果可能并不理想。还有在多模态实体链接中利用联合知识表示学习[15-16],将其转化为向量平移问题。由于图像和文本是不同属性的对象,需要通过矩阵乘法嵌入统一空间,因此计算量较大。Li等[17]先确定图像中的实体,然后在Web 上检索实体的链接,最后通过链接中的实体在知识图谱中检索图像的链接点。检测文本中的实体依赖于领域性词典的完整性,因而这些方法很难应用或迁移到计算机学科领域。
为了找到一种适用于计算机学科领域、计算量小且不需要大量标注数据的多模态实体链接方法,本文基于Li等[17]的思想,将图像和文本描述相结合,面向计算机学科领域提出一种简单有效的实体链接方法。与上述所有方法不同的是,对图像和其文本描述分别进行处理,首先识别出图像中的视觉实体,并将其文本描述处理成实体和关系较为明确的结构化三元组,最后按照提出的实体链接规则完成最后的链接和扩展。
2 问题描述与概念定义
图1 为任务描述图,将其分为3 个步骤:①输入:图像及其文本描述;②图文处理:检测图像视觉实体,提取并筛选文本描述中的三元组;③完成链接:将图像链接到知识图谱中,并利用视觉实体和三元组对图像进行扩展。
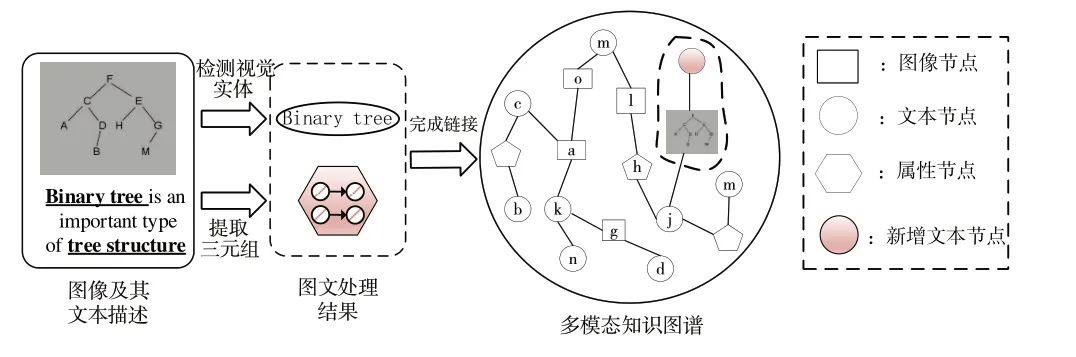
Fig.1 Task description图1 任务描述
对本文需要用到的概念和符号进行定义如下:
定义1多模态知识图谱。根据Zhu 等[18]思想将多模态知识图谱定义为G,G={E,R,A,V,T},其中E、R、A、V是实体、关系、属性和属性的集合,T为三元组集合。
定义2待链接图像、图像的文本描述和待链接三元组。待链接图像是要链接到G 中的图像,用p表示。ep表示p的视觉实体。m表示图像文本描述,ImgDesTriple表示从m中抽取的三元组集合。
定义3最佳链接点。实体链接的目标是将文本中的实体提及指向知识库中的特定实体,定义这个特定实体是实体提及的最佳链接点。
根据所定义的概念和符号将问题的形式化表述为式(1),其中f函数表示根据p和m返回一个找到最佳链接点且包含图像的三元组,整体含义为在多模态知识图谱G的三元组集合T中增加了一条新三元组,T发生了变化。
3 视觉实体链接
3.1 系统总体架构
图2 为系统总体架构图,用户输入待链接图像及其文本描述,首先通过检测图像中的视觉实体并从文本描述中提取并筛选出待链接三元组,然后根据领域特性设计实体链接规则,最后将图像视觉实体和待链接三元组链接到知识库中。
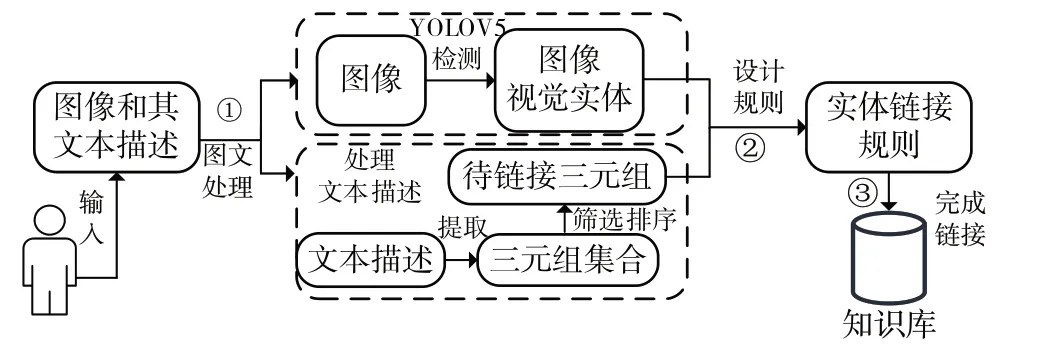
Fig.2 Overall system architecture图2 系统总体架构
3.2 总体方法描述
总体方法描述如图3所示。
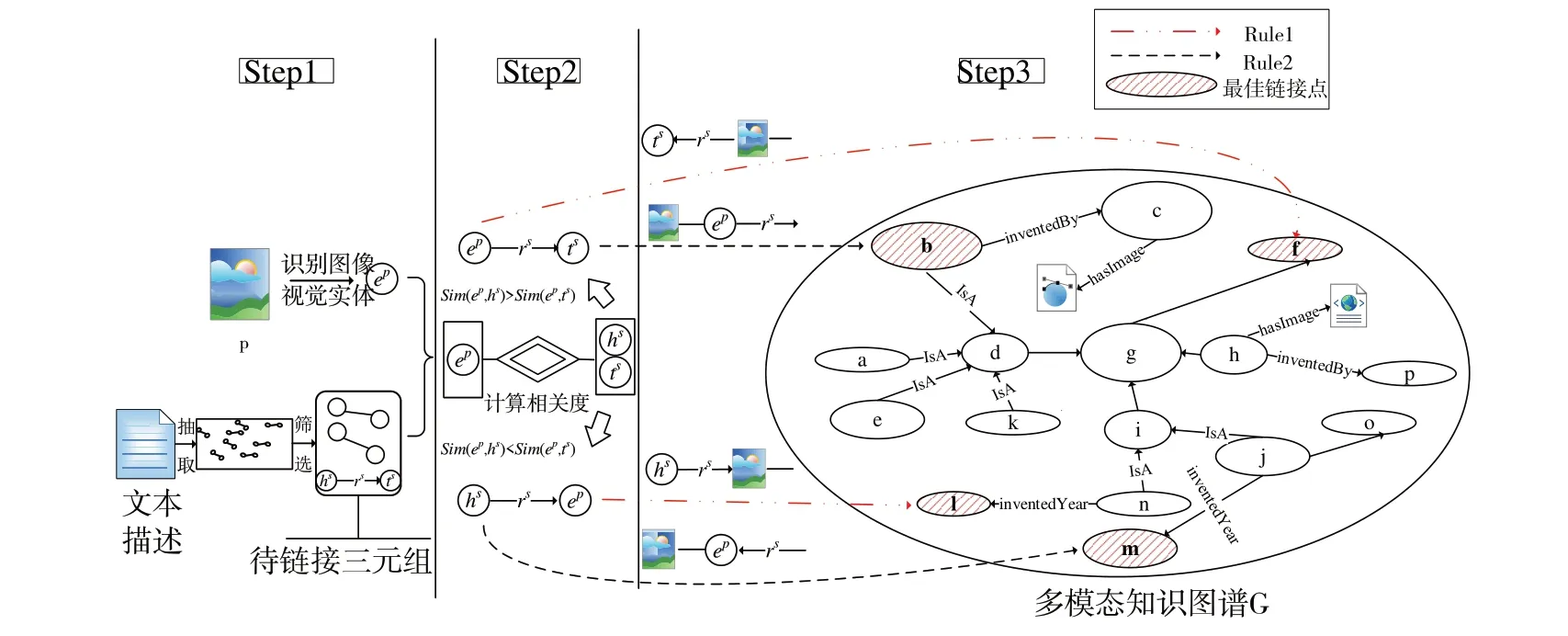
Fig.3 Overall approach description图3 总体方法描述
Step1:p和m的信息抽取。利用YOLOV5 检测p中的视觉实体ep,抽取并筛选m中的三元组,确定一个置信度高且与ep相关度最高的三元组
Step2:首先计算ep和
Step3:用ep在G 中寻找p的最佳链接点,如果找到,则将ep替换为p;如果没有找到ep的最佳链接点,则用待链接三元组中hs或ts寻找最佳链接点,如果找到,p与待链接三元组一起链接,p作为ep的属性值。
3.2.1 图像及其文本处理
视觉实体识别是对用户输入图像中的实体进行识别,利用YOLOV5 训练计算机学科领域的视觉实体识别模型,数据集使用CE-Detection。YOLOV5 对图像的视觉实体识别结果如表1所示。
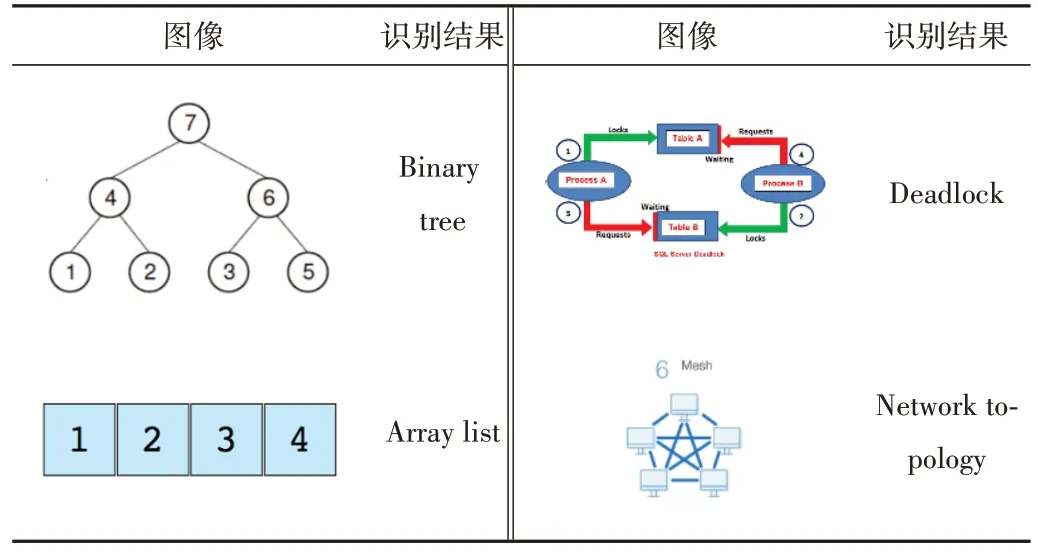
Table 1 Visual entity recognition results of images表1 图像的视觉实体识别结果
为了获得准确且与图像相关度较高的三元组,针对计算机学科领域设计了一种从图像文本抽取并筛选三元组的规则。
(1)过滤低置信度的三元组。用OpenIE[19]、OLLIE[20]工具对图像文本进行抽取,得到两个三元组集合Open(h,r,t)和Oll(h,r,t)中。如式(2)所示,一个三元组同时存在于两个集合中,则存放在ImgDesTriple,取两个集合的平均置信度作为三元组新置信度。其余三元组合并到ImgDesTriple,选取一个置信度阈值对ImgDesTriple中的三元组进行筛选,过滤低于阈值的三元组。
(2)利用图像视觉实体对过滤后ImgDesTriple中的三元组进行排序。在计算机学科领域中,许多术语实体是由词缀拼接而成[21],但基于字符串相似性的特征有局限性,没有考虑实体间结构语义相似性,因此基于WML 模型[22]计算三元组中的实体和ep语义相关度r(ep,a),利用SMOA算法[23]的Comm方法计算三元组中的实体和ep字符串相似度Comm(ep,a),再采用张晓明等[21]实体过滤的思想将基于结构的语义相关度r(ep,a)和基于字符串的相似度Comm(ep,a)相加作为ep和a的相关度Sim。最后由本文提出的式(6)计算ep和ImgDesTriple中三元组相关度。
式(3)中,I、J 分别是链接到候选实体ep和a的维基百科的超链接集合,W 是维基百科中实体的集合,r(ep,a)表示两个实体间的相关度。式(4)中,分子为两个字符串的最大公共子串的两倍,分母为两个字符串的长度之和。式(5)中,Sim(ep,a)表示ep与实体a之间相关度。式(6)中,h、t分别表示三元组中头、尾实体,Reltation(ep,
将ImgDesTriple中三元组按此相关度为依据由大到小排序,与视觉实体相关度最高的三元组为
3.2.2 计算机学科领域实体链接规则
VELR 中将ep和
Rule 1视觉实体链接规则。利用ep寻找最佳链接点,首先计算ep和

Fig.4 Visual entity link extension rules图4 视觉实体链接扩展规则
式(8)中,isVisualEntity(ep,p)表示ep是p的视觉实体,beLinkTriple(
如图5 所示,输入图像及其文本描述,首先通过领域实体识别得到图像视觉实体‘AVL tree’,提取文本描述中的三元组,筛选排序得到与视觉实体相关度排名最高的三元组

Fig.5 An example of rule 1图5 Rule 1实例
Rule 2待链接三元组头尾实体链接规则。
如图6 所示,当ep在G 中无法找到最佳链接点,并且

Fig.6 Tail entity link图6 尾实体链接
式(10)表示ep在G中没有找到最佳链接点,且ep与三元组中的头实体hs相似度最高,此时ep替换hs,用ts寻找最佳链接点链接。式(11)表示ep在G中没有找到最佳链接点,且ep与三元组中的尾实体ts相似度最高,此时ep替换ts,用hs寻找最佳链接点链接。
4 实验与结果分析
4.1 数据集构建
实验中构建了一个包含图像和图像标签的数据集CE-Detection,用于计算机学科领域的图像实体识别。CE-Detection 中12 个类别的图像来自于CSDQA[26],由计算机相关专业的研究生手动绘制边界框并打上标签,确保标签内容的一致性,其中80%作为训练集,20%作为验证集。同时,构建了一个包含图像和文本的多模态数据集CS-IMG,该数据集中的图像来自于CSDQA[26]和Wikipedia,文本包括图像的文本描述和图像中实体对应的文本。CSDQA 中图像的文本由5 名计算机专业研究生根据CSDQA 中的图像内容和相应的图像问答对进行总结得到,从Wikipedia 上搜集的图像的文本也是由5 名计算机专业研究生根据图像所在网页中的文字信息总结而来。表2 为使用数据集的信息,CMMKG 是课题组Zhang 等[21]利用领域实体抽取方法构建的计算机学科领域多模态知识图谱。本文的任务是在CMMKG 中完成实体链接。

Table 2 Data sets表2 数据集
4.2 计算机领域图像实体识别
4.2.1 评价标准
验证YOLOV5 在计算机学科领域中图像视觉实体的识别效果,选择COCO128 数据集作为对比。实验的评测指标为P、R、mAP@0.5 和mAP@0.5:.95。mAP@0.5 表示将IoU 设为0.5 时,每个类所有图片AP 的平均值。mAP@0.5:.95 表示在不同IoU 阈值(从0.5 到0.95,步长为0.05)上的平均mAP。
4.2.2 实验结果与分析
表3 中,本文随机从CE-Detection 中选取了6 个类别进行实验,Images 列代表每个类别图像的总数。12 种图像的P和R均在0.8 以上,且在每个值上的表现都与COCO128 相差不大,可以证明YOLOV5 在CE-Detection 上有良好表现,可用于计算机学科领域中图像视觉实体识别。

Table 3 Entity recognition results in images表3 图像中实体识别结果
4.3 三元组置信度阈值选择
4.3.1 评价依据
随机选取500条图像的文本描述,按照3.2节所述方法加以处理,得到3 000 条三元组存放在TotalTriple集合中。将TotalTriple中的三元组随机平均分成3 组,设置不同的阈值并筛选,观察剩余三元组数量平均占比和阈值之间的关系。
4.3.2 结果与分析
如图7 所示,图中实线表示随着置信度阈值的增加剩余三元组的数量占比也在下降,虚线则为实线的趋势线。从两条线的趋势看,当阈值增加时,集合中剩余的三元组数量在减少,这是因为三元组的置信度反映的是三元组的准确率,置信度越高,三元组的准确率越高,但置信度越高,集合中剩余的三元组数量会越少。当阈值大于0.79时,集合中三元组的数量减少迅速。但是当阈值选择0.95时,与0.79 相比相差10%左右。因此,可以选择0.79 以上的置信度阈值对三元组进行筛选。
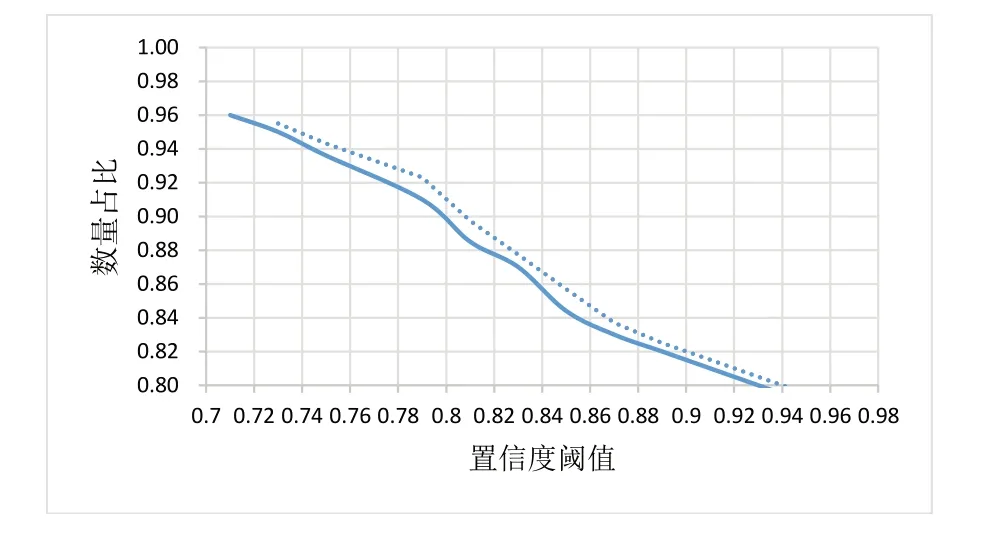
Fig.7 Threshold selection图7 阈值选择
应确保每个图像的ImgDesTriple中至少剩余两个三元组。选0.79 以上的阈值对ImgDesTriple,观察集合中剩余三元组,统计500 组图像的ImgDesTriple中剩余三元组的数量。
如表4 所示,当阈值选择在0.85 及以下时,500 组图像的ImgDesTriple中没有出现少于两个三元组的集合。当阈值为0.87 时,有10%图像的ImgDesTriple集合中会少于2个三元组,不符合设定的筛选规则,因此最终将阈值限定为0.85。
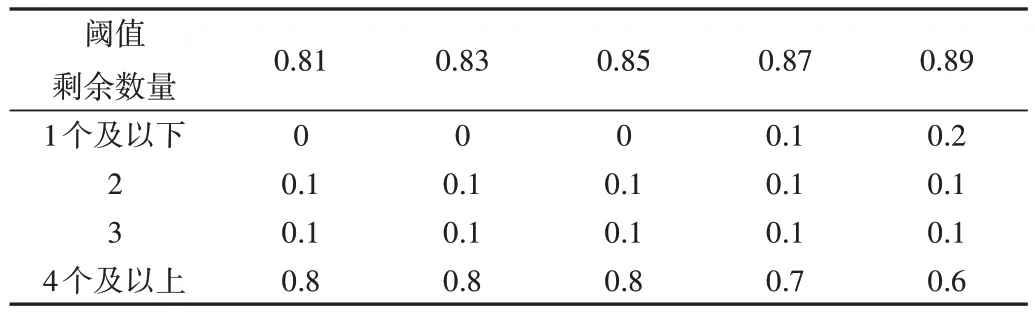
Table 4 The proportion of the set of different remaining triples to the total表4 剩余不同数量三元组的集合占总数的比例(%)
4.4 实体链接
4.4.1 评价标准
TALN[24]和VCU[27]是在小规模知识图谱融合中表现很好的系统,具有较高的召回率,选择VCU 作为TALN 的对比实验,测试两个系统在计算机学科领域中寻找实体提及最佳链接点的性能。数据集选择CMMKG 和CS-IMG 中除图像外的全部数据,随机分成训练集和测试集。评价指标为WuP、R、F1。WuP 为相似度度量,用来计算两个词的语义相似度。式(12)中,s1、s2表示两个词,lcs表示连接s1和s2的最短路径。
4.4.2 结果与分析
由表5实验结果可知,TALN 的R和F1值均比VCU 高,可能是因为VCU 在阈值的设定上有些不足,低于设定阈值即为下位词,这就导致一些分数极低的噪声插入图谱。虽然TALN 和VCU 中以实体、其词性和文本描述作为输入,但是TALN 将实体和其所有输入转化成向量之后,更多的考虑了句法、词性和短语之间的联系。而TALN-RunHeads的WuP 值更高,说明在计算机学科领域中TALN-Run-Heads映射方法相对表现更好。

Table 5 The results of two model test表5 两个模型测试的结果
4.5 三元组分类任务评测实体链接规则
4.5.1 评价标准
为了验证在链接过程中是否出现噪声,使用三元组分类任务对结果进行评测。三元组分类任务目的是判定三元组(h,r,t)是否正确,其本质是一个二分类的任务。实验采用张晓明等[28]提出的可信度得分,通过其定义公式(13)和公式(14)计算能量函数后转化为三元组的可信度得分,得到[0,1]区间的数值作为其可信度得分,0.5 以上的分数被分为正确三元组。式(13)中,E(h,r,t)表示能量函数;R(h,t)表示实体之间关联强度;T(h,r,t)表示实体类型评估结果;RRP(h,r,t)表示基于多步路径信息计算的结果;λ1、λ2为超参数。
向数据集CMMKG 中添加VELR 规则产生的0,100,300个三元组,分别表示为CMMKG、CMMKG-100、CMMKG-300。采用PTransE[29]、CKRL[30]、TransE[31]模型对进行三元组分类实验。通过对比实验结果,验证添加的三元组中是否存在噪声以及是否会对整体准确率产生影响。
在此之前,需验证在三元组中掺杂噪声会对分类准确率的影响有多大。在CMMKG-100 和CMMKG-300 的训练集中加入噪声,其中噪声比分别设置为新增数据的10%、30%、50%。
4.5.2 结果与分析
如表6 所示,当在CMMKG-100 和CMMKG-300 加入10%噪声时,分类准确率没有变化。说明3 个模型在分类任务上存在少量噪声可能不会影响整体分类准确率。但是,当加入30%噪声和50%噪声时,准确率都略有下降。这说明随着噪声的增加,3 个模型在分类的准确率上会有所下降,同样也证明了3 个模型在检测噪声方面有一定的能力和适用性。

Table 6 Classification results of adding noise to CMMGG-100 and CMMGG-300表6 在CMMKG-100和 CMMKG-300中加入噪声的分类结果
如表7 所示,CKRL 在三元组分类任务上的表现最好,是因为CKRL 中路径信息的使用方法优于PTransE,而TransE 在学习过程中没有用到路径之间的关系。但是3个模型对加入100 三元组的数据集进行三元组分类实验,准确率没有变化,可能是因为少量的数据变化不会影响3 个模型分类的准确率,该结论在上述实验中也被证明。而PTransE 和CKRL 在加入300 个后准确率会提高0.1,是因为PTransE 和CKRL 在分类时采用了知识库中丰富的内部结构信息,在加入较多三元组后路径会更丰富,因此准确率也相应提高。由以上结论可以证明,使用提出的链接方法增加新三元组对整体三元组分类的准确性没有影响,从侧面证明本文方法的有效性。
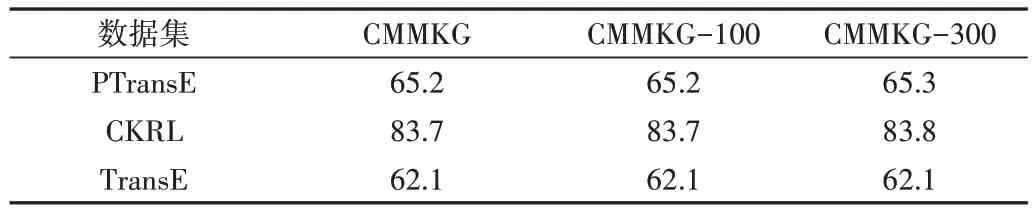
Table 7 Triplet classification results表7 三元组分类结果
选取由Sun 等[32]提出的视觉实体链接模型中的一个子任务:视觉到视觉实体的链接(Visual to Visual Entity Linking,V2VEL)作为基线模型。在与上述实验相同的数据集和相同实验设置下,用V2VEL 完成图像到CMMKG 的链接,之后用三元组分类任务对结果进行评测并与本文方法进行比较。
如表8 所示,本文所提方法在计算学科领域的实体链接表现结果比Baseline-V2VEL 好。可能是因为V2VEL 中仅用图像视觉特征链接,此时会出现找不到最佳链接点或者最佳链接点与其相关性低的问题,进而影响链接准确性。而本文方法考虑到该情况,为不同链接点设置了不同的链接规则,提高了链接准确率。还可能是因为V2VEL更专注于视觉人物数据集,面对计算机学科领域中一些概念性的图像时,视觉特征提取效果不好从而导致视觉实体链接效果表现不佳。由此结论表明,本文所提方法更适用于计算机学科领多模态实体链接。
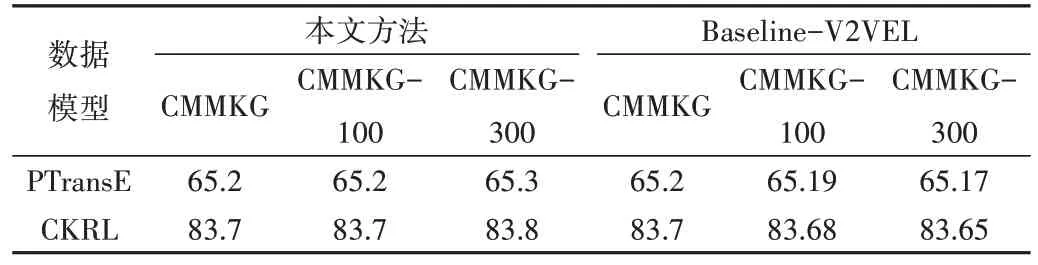
Table 8 Method comparison表8 方法比较
4.6 结果展示
如图8 所示,虚线框对应VELR 规则中的Rule 1、Rule 2。Rule 1中,AVL tree 的图像链接到对应实体,扩展了balancing search tree 实体。在Rule 2 中,实体ordered sequence链接到知识图谱中的实体Array,图像作为ordered sequence的属性值。
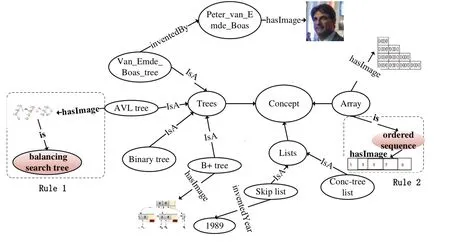
Fig.8 Results presentation图8 结果展示
5 结语
面向计算机学科领域提出了一种视觉实体链接规则VELR。在理论价值方面,为特定领域的实体链接提供了一种新思路。首先识别出图像中的实体,然后对其文本描述进行抽取筛选,最后利用提出的VELR 完成图像链接和知识扩展。对链接后产生的新知识进行评测,实验结果表明,通过对比有无噪音实验结果,证明了VELR 的有效性。在应用价值方面,VELR 对计算机学科领域知识图谱的更新和演化提供了一种新的有效方法,提高了计算机学科领域知识图谱的可用性,对其他学科领域也具有借鉴意义。
识别图像视觉实体时,YOLOV5 虽是一个准确的轻量模型,但模型对标注数据有依赖性,使其可能不具有泛化能力。为了解决该问题,后续工作将从如下几点入手:①尝试融合多种目标检测模型,使其能识别多类别图像,增加模型泛化能力;②研究更加高效的图像视觉实体识别模型,尝试结合图像文本描述准确定位图像中的目标实体,提高目标检测精度,降低目标检测任务复杂性;③考虑包含多实体图像的链接规则,增加多模态实体链接系统的功能。
