词典多模态释义对英语二语词汇学习影响的实证研究
2024-01-01陈贤德
陈贤德
(北京语言大学 教师教育学院,北京,100083)
释义是词典学研究的核心问题,着眼于2000 多年的辞书发展史,辞书的释义方法大体经历了随文释义、同义词释义、“属+种差”释义、整句释义、模板释义五个阶段[1]。但这五个发展阶段均都未突破纸媒的界限,词典释义研究也仍局限于对释义文本的“精雕细琢”,“循环释义”“内涵不彰”“以难释易”等释义问题仍旧显著。受限于信息媒介的限制,传统纸质词典并不能有效地解决上述问题,也因此纸质词典的“进化”变得越来越困难,“牛津”“朗文”等系列学习词典虽然还在不断修订,但在释义上已难以有较大的提升[2]。
在二语教学界,新伦敦团体(NEW London-Group 1996)认为传播媒介的飞速发展已经促使了人们读写方式的深刻改变,人们不再局限于通过纸质文本去获取知识,还要借助声音、图片、视频等进行多元识读[3]。因此,读写认知能力也该向更多符号系统组成的媒介转换(transmediation)朝多元识读方向发展,即从传统的读写能力(literacy)转向能通过语言、视觉、听觉等多模态形式批判性地识读和理解多媒介信息的多元识读能力(multiliteracies)[4]。为促进二语被试多元识读能力的提升,多元识读法也顺势而生,相关研究也已证明,多元识读法是一种有效的二语学习方法。[5-7]为顺应二语教学的深刻变化,在辞书研究领域,Lew(2010)在《多模态词典学:电子词典的意义呈现方式》一文中最早提出“多模态词典学(Multimodal Lexicography)这一概念”[8]。国内研究方面,党军则率先指出双语词典应实现多模态化,并以词典交际论为理论框架,引入多模态语篇理论,指出了词典的多模态化的诸多优势[9]。但正如章宜华所言,他们的研究混淆了“媒体”与“模态”的概念,把复杂的模态简化为了媒体[2],同时也忽视了各种模态的有效融合在词典中发挥的作用。
基于此,章宜华[10]、李宇明[11]、亢世勇[12]等人提出了“融媒体辞书”编纂概念。从辞书表征的视角讲,融媒体辞书融合的对象是词典的多模态表征。词典释义方式也应由单模态释义向多模态释义转变,释义不应只局限于语言文字模态释义,还应包含其他不同类型的非语言模态释义形式,应涵盖视觉、声音及触感模态释义等。目前的研究多已证实多模态释义效果要优于文字单模态释义,如武卫、许洪通过实证研究表明图文释义比只有文字的释义更加有利于词汇附带学习,“汉语+图画”的组合注释对词汇附带学习最有效[13]。李红、李于南(2007)的研究也证实,“图文”双模态释义更有助于英语新词词义的学习和长时记忆[14]。
然而,国内的“多模态释义”或“多模态词典”研究,虽名为“多模态”,但实为“图文双模态”研究,如罗永胜《多模态英语学习词典图文释义模式探究》[15]、田晶晶《高阶英语学习词典的多模态释义研究》[16]、陈思一叶《高阶英语电子词典图文关系的多模态研究》[17]等,多只局限于探讨词典中的图文配置关系、图片类型等,对于其他模态元素尤其是视频、音频在词典释义中发挥的作用探讨较少,多模态释义的实证研究也鲜见。
基于以上研究背景,本文以英语水平较弱和较高的的初中学生为被试,考察在刻意词汇学习条件下词典多模态释义是否比文字单模态释义更有助于汉语二语词汇学习。具体来说,我们要回答以下三个问题:(1)多模态释义下的词汇学习是否要显著优于文字单模态释义下的词汇学习?(2)相较于文字单模态释义,多模态释义是否在具体词和抽象词中的学习中均表现出促进优势?(3)相较于文字单模态释义,多模态释义是否在不同水平的初中英语学习中均具有优势?
一、研究方法
(一)被试
被试为就读于重庆某校的12~15 岁的80名初中学生。取被试期中成绩与期末成绩的平均值,并将平均值划分为四个分段:100~90 分为A 段,89~75 分为B 段,74~60 分为C 段,59 分及其以下为D 段。其中A、B 分段的学生代表了英语水平较高的被试,C、D 分段的学生代表了英语水平相对较弱的被试。A、B、C、D 四个分段各20 人,共80 人。
(二)实验材料
目标词的确立总共分三个步骤:(1)词类选择上主要选择开放性的词类如名词、动词、形容词和副词。确定了所要测试的词类后,为了保障所选词语被试从未接触过,从雅思、托福等有较高难度的英语测试中选择词语,所选词语均在人教版初中英语词汇表外。为降低词长因素对记忆的干扰,所选词语词长控制为8 到10 个字母间。为防止被试通过所学词根推理出词义,构词中的词根被试均未学习过,如“Arrogantly”中的“Arrogant”。(2)请与被试组语言水平相当但不参加正式测试的其他同学先行测试,并同时请被试的英语老师进行核对,以确保目标词被试从未学习过,如不达标则进行替换,替换词语要求与被替换词语词长、词性一致。(3)张萍根据认知语言学理论,从空间概念和感官体验两个角度对具体词和抽象词进行了划分。具体词即指那些通过感觉器官可以在现实世界被感知的物理实体如DOG [n]、被实践的行为动作如SMILE[v]、被体验的感觉特征如SOFT[adj.]。抽象词则指不能被五官直接感知的概念如INDIVIDUALISM [n]、肉眼难见的心理活动如SUPPOSE[v]、各类事物的特征属性如UNIQUE[adj.][18]。基于张萍的论述,实验中的具体词由15 个五官可以直接感知的名词、动词构成,抽象词由15 个五官不易直接感知的形容词、副词构成,共计30个词语:
具体词:Pentagon 五边形,Popsicle 冰糕,Gardenia 栀子花,Camellia 山 茶 花,Hibiscus 木 槿,Dromedary 单峰驼,Partridge 山鹑,Cardigan 开襟毛衣,Recliner 可调式躺椅,Hibernate 冬眠,Germinate 发芽,Pollinate 授粉,Excavate 挖掘,Meander 蜿蜒而流,Strangle 绞死。
抽象词:Periodic 周期的,Statutory 法定的,Soporific 催眠的,Deprived 贫困的,Ossified 僵化的,Inimical 有害的,Notorious 臭名昭著的,Frivolous轻浮的,Wantonly 恶意地,Brashly 盛气凌人地,Arrogantly 自 大 地,Strikingly 惊 人 地,Succinctly简洁地,Rigorously 严厉地,Scornfully 轻蔑地。
确定了目标词后,我们开始制作单模态释义与多模态释义的实验材料。单模态释义组只提供文字文本,文本内容根据《牛津高阶英汉双解词典》词语信息收录情况依次排列目标词词形、音标、词性、中英文释义和例句,其中例句在《牛津高阶英汉双解词典》例句的基础上进行简化以符合被试目前认知水平,如:
Gardenia n./a bush with shiny leaves and large white or yellow flowers with a sweet smell,also called gardenias 栀子花/Gardenias are white and beautiful.栀子花洁白而美丽。
根据章宜华对词典多模态元素的划分为每个词语制作多模态释义视频[2],视频中的模态元素包括:(1)音频,中英文朗读目标词读音、释义与例证。(2)图片,展示与目标词相关的动态图片或静态图片。(3)短视频,播放与目标词相关的释义短视频,如“Wantonly”一词所配备的短视频是一个人在恶意地破坏环境,“Soporific”则是一个人在上课时昏昏欲睡。释义模态呈现顺序为先用文字模态展示目标词词性、词形与释义,在展示的同时朗读上述目标词信息。随后,播放释义短视频,每个词语的释义短视频时长控制在1 分半左右。最后,同时呈现目标词词形、词性、释义、例证与图片,在展示的同时朗读上述目标词文字信息(如图1 所示)。此外,多模态释义组所使用文本的内容在文字释义文本的基础上增加了图片,以体现模态的交融性。为抵消词语呈现的先后顺序对记忆的影响,我们将词语呈现的顺序打乱为几个不同的版本。

图1 释义视频中模态元素展示顺序
(三)测量工具
实验的测量工具为两套结构和内容相同的测试题,分别用于即时测和延后测,题型为词汇理解测试与词汇产出测试。词汇理解测试有两类题型:
一是给出目标词词形,让被试者用汉语写出释义。如:
Arrogantly:____________Cardigan:____________
二是选词填空,如:
①Germinate ②Rigorously
③Periodic ④Ossified
Duanwu Festival is a traditional and____________holiday originating in China.
词汇产出测试共两类题型:
一是汉翻英,如:
栀子花洁白而美丽。
_______________________________________________
二是用所给目标词造句,如用“Periodic”造出完整的句子。词汇理解型题目共计30 道,每题1 分,共计30 分,题型一中单词含义书写正确得1 分,字形错误如多笔划、少笔划等但不影响理解或用拼音代替汉字同样得分;题型二中正确写出单词所对应序号或直接写出正确词形得1 分。词汇产出型题目共计30 道,每题1 分,共计30 分,题型一中句子语法正确、单词书写正确且表意清晰,得1 分。语法错误、单词书写错误,出现一处扣0.5 分,扣完为止,目标词书写错误不得分,句子表意不明不得分。题型二与题型一评分标准一致。
(四)实验程序
实验程序包括:前测、目标词学习、即时测、延后测、问卷调查。
(1)前测。对未参加测试但与被试者语言水平相当的学生进行目标词测试,同时将目标词给被试的任课教师进行审核,以确保被试从未学过目标词。
(2)目标词学习。被试分别对30 个目标词进行学习。30 个目标词分为四类,多模态释义—具体词,多模态释义—抽象词,文字释义—具体词,文字释义—抽象词。实验时,A、B、C、D 四个分段的80 个被试平均分为A1、A2、B1、B2、C1、C2、D1、D2 八个组,每组10 个被试,其中A1、B1、C1、D1 四组被试参加单模态实验,A2、B2、C2、D2 四组被试参加多模态实验。单模态组的被试耗费30 分钟运用单模态纸质文本自行理解、记忆词语。多模态组的被试则是先耗费10分钟浏览图文双模态文本,再观看时长约为20分钟释义视频。
(3)被试完成目标词学习后进行及时测。
(4)24 小时后被试完成延后测。
(5)对参与多模态实验的被试进行问卷调查,主要考察对多模态释义方式的感受和所喜爱的模态元素组合。
三、实验结果
(一)CD组实验结果
1.CD 分段被试的词汇理解成绩
分别统计每名被试在多模态释义-具体词、多模态释义-抽象词、文字释义-具体词、文字释义-抽象词四种条件下的答题得分率(各条件下被试实际得分值/各条件下的满分值),并计算所有被试的平均得分率,结果如表1 所示。使用SPSS24.0 对统计结果进行2(释义模态)×2(词汇属性)×2(测试时间)的重复测量方差分析。结果显示:释义模态的主效应显著,多模态释义下CD分段的被试的词汇理解得分率(28.764%)显著高于文字单模态释义下的理解得分率(12.050%),F(1,40)=105.737,p=0.000。词汇属性的主效应显著,具体词的理解得分率(30.50%)显著高于抽象词的理解得分率(11.315%),F(1,40)=201.411,p=0.000。测试时间的主效应也显著,即时测的理解得分率(25.601%)显著高于延后测的理解得分率(16.214%),F(1,40)=54.830,p=0.000。释义模态与词汇属性的交互效应也显著,F(1,40)=74.376,p=0.000,说明对于不同属性的词语,释义时是否提供多模态的理解效果可能不同。释义模态与测量时间的交互效应也显著,F(1,40)=22.054,p=0.000,说明对于不同释义模态的词语,随着时间的波动变化不一样。三因素交互效应也是显著,F(1,40)=6.732,p=0.013。
2.CD 分段被试的词汇产出成绩
同样分别统计每名被试在多模态释义-具体词、多模态释义-抽象词、文字释义-具体词、文字释义-抽象词四种条件下的产出得分率(各条件下被试实际得分值/各条件下的满分值),并计算所有被试的平均得分率,结果如表2 所示。
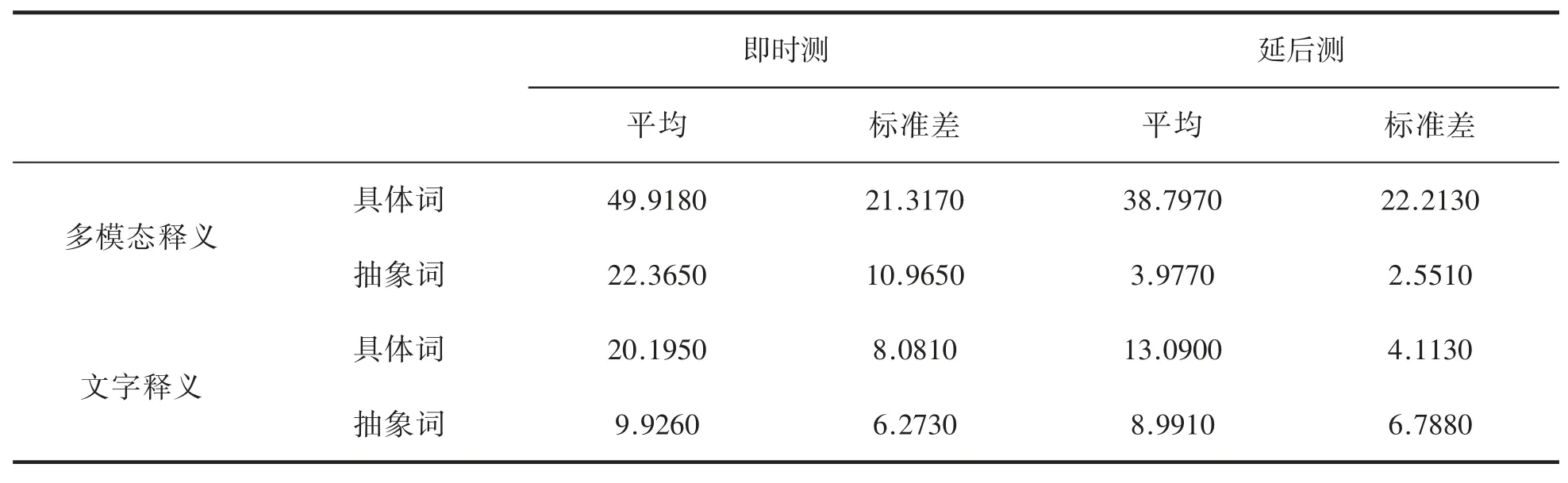
表2 CD 分段被试词汇理解的即时测和延后测得分率(%)
对产出成绩进行2(释义模态)×2(词汇属性)×2(测试时间)的重复测量方差分析。结果显示:释义模态的主效应边缘显著。多模态释义下水平较弱被试词汇产出得分率(22.038%)显著高于文字单模态释义下的产出得分率(10.886%),F(1,40)=66.689,p=0.000。词汇属性的主效应显著,具体词产出的得分率(20.282%)显著高于抽象词的得分率(12.642%),F(1,40)=31.642,p<0.001。测试时间的主效应也显著,即时测的得分率(17.729%)高于延后测的得分率(15.195%),F(1,40)=5.621,p=0.019。释义模态与词汇属性的交互效应也显著,F(1,40)=37.608,p=0.000,说明对于不同属性的词语,释义时是否提供多模态的理解效果可能不同。词汇属性与测量时间的交互效应也显著,F(1,40)=5.274,p=0.027,说明对于不同词汇属性的词语,随着时间的波动变化不一样。三因素交互效应也是显著的,F(1,40)=16.518,p=0.000。
(二)AB 组实验结果
1.AB 分段被试词汇理解
对数据(表3)进行2(释义模态)×2(词汇属性)×2(测试时间)的重复测量方差分析。结果表明:释义模态的主效应显著,多模态释义条件下AB 分段被试的词汇理解得分率(51.552%)显著高于文字单模态释义条件下词汇理解的得分率(28.062%),F(1,31)=67.094,p=0.000。词汇属性的主效应显著,具体词的理解得分率(47.067%)显著高于抽象词的得分率(32.546%),F(1,31)=74.553,p<0.000。测试时间的主效应不显著,即时测的理解得分率(39.242%)不显著低于延后测的得分率(40.372%),F(1,31)=0.711,p=0.406>0.05。词汇属性与测量时间的交互效应也显著,F(1,31)=7.956,p=0.008,说明对于不同词汇属性的词语,随着时间的波动变化不一样。三因素交互效应不显著,F(1,31)=1.842,p=0.056。
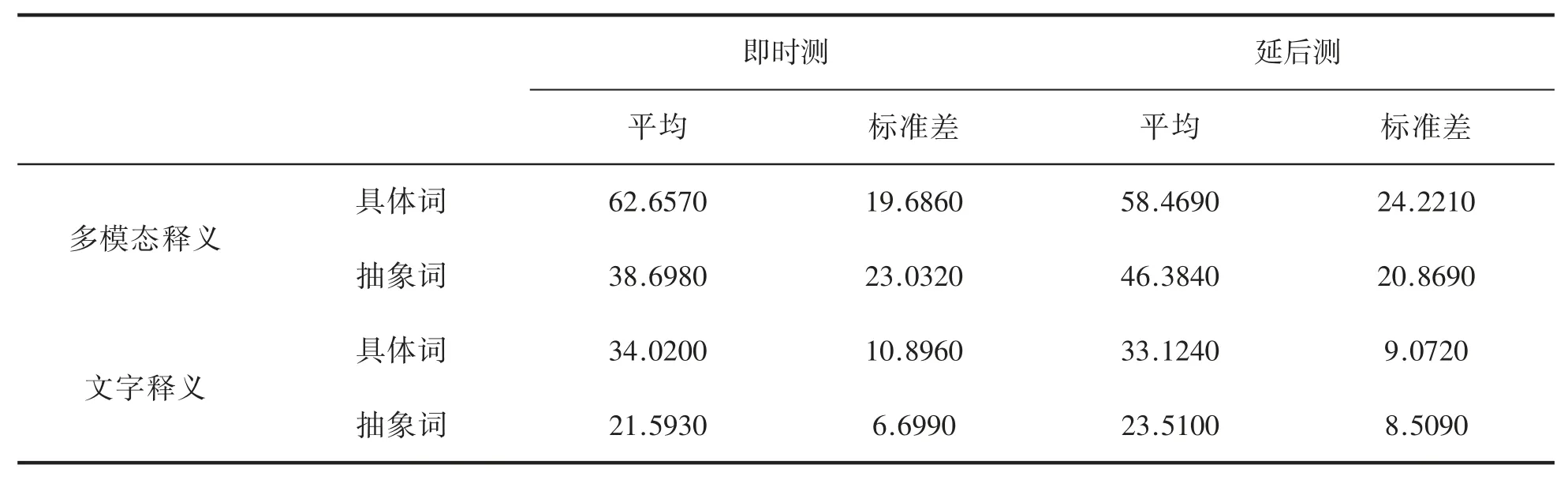
表3 AB 分段被试词汇理解的即时测和延后测得分率(%)
2.AB 分段被试的词汇产出成绩
对AB 分段被试的词汇产出成绩(见表4)进行2(释义模态)×2(词汇属性)×2(测试时间)的重复测量方差分析。结果显示:释义模态的主效应显著,多模态释义下AB 分段被试的词汇产出得分率(55.112%)显著高于文字单模态释义下的产出得分率(25.997%),F(1,31)=133.843,p=0.000。词汇属性的主效应显著,具体词的产出得分率(44.034%)高于抽象词的产出得分率(37.076%),F(1,31)=10.186,p=0.003。测试时间的主效应不显著,即时测的产出得分率(40.701%)与延后测的得分率(40.409%)无显著差异,F(1,31)<1,p=0.835。以上三因素的两两交互效应均不显著(ps>0.05)。三因素交互效应不显著,F(1,31)<1,p=0.190。

表4 AB 分段被试词汇产出的即时测和延后测得分率(%)
三、问卷调查结果
问卷以问卷星的形式发放给40 名参与了多模态释义实验的被试,其中参与多模态释义实验的AB 分段被试回收18 份,回收率为90%;参与多模态释义实验的CD 分段被试回收20 份,回收率为100%。所回收的问卷均为有效问卷。问卷首先调查了多模态释义在词汇理解和产出两方面能力的辅助程度。问卷调查结果如表5 所示,77.71%的AB 分段的被试和85%的CD 分段的被试认为多模态释义有利于生词的理解,55.55%的AB 分段的被试和70%CD 分段的被试认为多模态释义有利于生词的记忆,这说明多数被试认可多模态释义在英语词汇习得过程中所发挥的积极作用,但CD 分段选择“帮助较大”和“帮助非常大”的被试要显著大于AB 分段,这说明英语水平较弱的被试更认可这种积极作用。

表5 被试对多模态释义的评判结果
此外,我们还调查了被试所喜爱的模态元素组合。根据表6 的数据显示,被试最喜爱的模态元素组合是“短视频+动图+音频”,其次是“短视频+动图”,其中“短视频”选中率为100%,可见被试比较偏爱于能够进行动态展示的模态元素。

表6 被试喜爱的模态元素组合
四、分析与讨论
(一)讨论一
实验结果表明,对于各阶段的被试而言,多模态释义下的词汇理解和产出成绩均显著优于文字单模态释义下的成绩。此外,多数被试主观上认同多模态在词汇学习中的积极作用。可见,整体而言,多模态释义比文字单模态释义更有助于英语二语者的词汇学习。
实际上,人类语言交际本身就是多模态化的,当幼儿还未发展出识读能力时,就是依靠多模态元素来感知世界从而习得概念,研究显示,幼儿最先发展起的中文词汇多是与其能直接所观、所听、所触的名词、动词为主[19]。同样,在二语习得中,多模态释义也可帮助被试建立起词形与概念之间联系,简化或消除“目的语—母语”的翻译过程,从而弱化母语负迁移的影响。
焦虑是影响二语习得的重要情感变量之一,语言焦虑与语言课程成绩以及教师对被试成就的评定呈负相关。刘会霞、燕浩等人的研究显示焦虑情绪会削弱大脑的执行控制能力,进而降低工作记忆的加工效率,最终对语言学习产生负面影响[20]。相反,愉悦情绪对语言学习有促进作用,李成陈、韩晔发现愉悦对英语考试成绩及自评网课学习成效有显著正向预测作用[21]。在进行词汇学习前,教师明确告知被试学习完成后要进行测试,这在一定程度上引起了被试的焦虑。然而,多模态呈现方式能够调动被试多感官的参与并激发他们的学习兴趣,从而有效削减被试的学习焦虑,尤其是在播放视频模态时,能够明显感觉被试的状态要放松许多。郑群、徐莹的研究也证实多模态呈现方式有助于降低被试词汇学习的交际焦虑[22]。
认知负荷理论认为由于人的工作记忆容量是有限的,当被试所学内容或所接受内容超过工作记忆的处理极限时,就会导致认知超载,教学设计的核心原则就是要降低内在和外在认知负荷,而促进有效认知负荷[23]。傅晓玲指出人们在视觉、听觉的双通道同时进行信息加工时,需要在两种通道之间建立关联,即将有关联的听觉表象和视觉表象进行转换。也只有这样,人的大脑视觉、听觉认知资源才能得到充分地利用[24]。多模态释义围绕释词的形、音、义将视觉、听觉两个通道联通并建立起有效关联,将文字表征转换成被试更容易感知的视频模态、图片模态和音频模态等,并利用同步呈现“图像和文本”信息相近的原则,增加视觉、听觉表证认知加工,从而有效降低了被试的认知负荷,促进了被试长时记忆的提升。
(二)讨论二
此外,实验结果还表明,词语属性和语言水平两个变量共同调节图文双模态释义的效果。具体而言,对于各个阶段的被试而言,无论是学习抽象词还是具体词,多模态释义下的词语学习成绩均显著好于文字单模态释义下的词语学习成绩。但相比之下,具体词的理解和产出程度要好于抽象词。双重编码理论认为,具体词在进行心理加工时较抽象词有优势。具体词能在以言语为基础和以意象为基础的两个系统中同时被加工,而抽象词则主要是在言语系统中被加工。具体词的呈现比抽象词更经常地唤起意象表征,言语和意象表征的唤起使具体词具有了加工优势[25]。虽然,多模态释义使得抽象词的呈现方式较之单模态释义更为具体,但无论如何抽象词构成义素的模糊性使其难以通过多模态语境实质地唤起意象表征,也因此抽象词的多模态释义是一种间接释义方式,加工优势较之具体词并不显著。如对具体词“Gardenia”的多模态释义可以通过展示茉莉花的图片被试直接建立起与概念的联系,而抽象词“Periodic”的多模态释义实则是通过多模态元素的互动对“Periodic”的例证语境进行再现,而并不是对“Periodic”的语义进行直接解释。
五、对词典编纂的启示
综上所述,模态元素之间互动、互补比单一的文字更有助于用户解读语义,多模态释义能有效促进英语词汇的学习。同时,从此次实验中我们也获得了一些启示。
首先,在进行多模态释义之前,应对被释词的语义进行分析,根据语义特征设置不同的模态元素进行释义。具体词可以直接用图片,但抽象词如“Notorious”“Frivolous”用图片进行释义其效果并不一定显著。怎样才能使得抽象词的多模态释义效果实现最大化,我们认为需要做到以下两点:(1)构建真实生活语境,图式具体化过程中语境首先起着刺激作用,能激活处于休眠状态的图式,同时语境能成为图式解释、预判和推理的对象,从而有助于理解。词典中构建的多模态语境应是用户所经历、体验过的真实生活语境,如若缺乏这样的语境则无助于图式的具体化[26]。如词典用户为学生群体,我们可以围绕“Periodic Examination”来为“Periodic”构建多模态语境。(2)调动词典用户积极情绪,郭晶晶、王敏帆等人的实验结论显示,当被试在愤怒韵律背景下学习抽象词时加工的正确率更低、反应时更长[27]。因此,在进行多模态释义时,我们可以尝试从色彩搭配、人物形象塑造、背景音乐配置等方面来调动词典用户的积极情绪。
其次,我们注意到视频模态受到了被试的广泛喜爱,被试在收看视频时的专注度也要比观看图片时更高。但同时部分被试在收看视频时容易被释义视频中的人物表情、服饰、外貌等次要元素所带偏而忽视了释义的核心内容。释义视频的内容、时长、场景等都需要根据词典用户的喜欢仔细研究。
最后,在进行多模态释义时,各个模态元素之间应是互融、互动和互补的,而不是孤立地对词语进行释义。这需要我们理清各个模态的释义优势,从而实现释义效果的最大化。
