基于深度学习的航天器位姿估计研究进展
2023-12-28朱文山牟金震
朱文山,牟金震,李 爽,韩 飞
(1.南京航空航天大学航天学院,南京 211106;2.上海航天控制技术研究所,上海 201109;3.上海市空间智能控制技术重点实验室,上海 201109)
0 引言
相对位姿估计是在轨服务的前提[1]。基于传统方法的航天器位姿估计技术已发展得非常成熟,成功应用于多项空间操控任务,如基于点∕线特征的方法[2-3]、基于几何特征的方法[4-8]与基于多特征融合的方法[9-10]。但针对不同的在轨任务,传统方法需要设计不同类型的位姿估计方法。此外,传统方法在复杂多变光照、低光照或高曝光环境下会失效,存在智能化水平低、多任务适应差等问题。
深度学习方法的快速发展,给航天器位姿测量提供了新的思路[11-20]。深度卷积神经网络绕过了传统特征提取过程,直接建立输入图像与输出位姿之间的伪逆映射关系。基于深度学习的位姿估计方法优势体现在[21-38]:1)图像特征提取具有学习能力和语义赋予能力,能够应对空间光照及复杂背景问题;2)通过域适应设计或多样化样本训练,位姿估计模型可以适应多目标、多任务场景;3)位姿任务与上下游任务结合,形成面向航天器精细化感知的统一模型。
国际上,ESA 通过资助Pose Estimation Challenge[11]与Pose Estimation 2021[12]两次比赛,公开了数据集SPEED 和SPEED+,初步具备了在轨演示验证能力。美国斯坦福大学是最早从事基于深度学习的航天器位姿估计的机构,提出的两阶段方法被广泛使用,目前的研究主要集中在域适应问题上[13]。西班牙马德里大学主要研究基于3D 引导的自适应深度学习位姿估计方法[16]。英国萨里航天中心是最早提出端到端的航天器位姿估计方法的机构[23]。卢森堡大学的研究集中在主动碎片清除过程中的位姿估计[28]。澳大利亚阿德莱德大学的研究集中在航天器关键点检测阶段[32]。日本九州工业大学的研究主要集中在如何基于FPGA(Field programmable gate array)实现航天器的位姿估计[35]。此外,美国商业航天公司Spire Global、Draper及瑞士航天初创公司ClearSpace SA 等通过资助学术会议等也开展了基于深度学习的航天器位姿估计研究[20-21]。国内,国防科技大学航天科学与工程学院[15]、上海交通大学航天学院[21]、复旦大学工程与应用技术研究院[38]等针对航天器在轨维修、空间碎片清除等场景,开展了基于深度学习的航天器六自由度位姿估计研究。
综上,基于深度学习的方法已成为解决非合作航天器姿态估计问题的热点方向。考虑到基于深度学习的航天器位姿估计的重要意义,有必要分析梳理其所涉及到的关键技术,总结目前存在的主要问题并给出后续发展的建议。
1 基于传统特征的航天器位姿估计
航天器与观测相机之间的位姿关系如图1 所示,xCyCzC表示相机坐标系,xByBzB表示航天器坐标系,uv表示图像坐标系,RBC表示航天器到相机的旋转矩阵,tBC表示航天器到相机的平移向量。相机坐标系下的三维坐标(XC,YC,ZC)与航天器坐标系下三维坐标(XB,YB,ZB)关系为
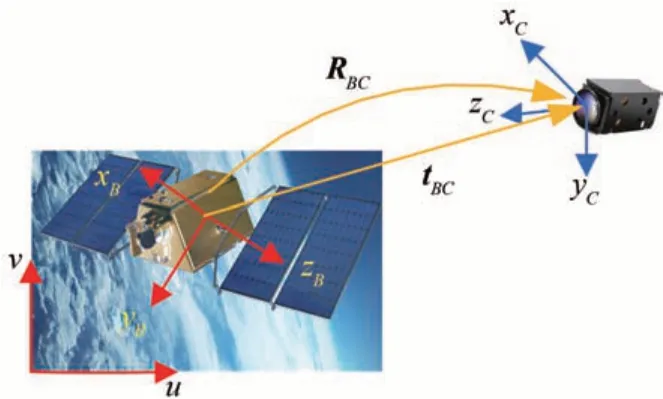
图1 航天器与相机的相对位姿关系Fig.1 The relative pose between spacecraft and camera
根据小孔成像原理,图像坐标系下的二维坐标(u,v)到目标系下的三维坐标(XB,YB,ZB)之间的转换关系为
式中:s是相机的深度比例因子;K为相机的内参矩阵。根据式(2),需要在图像上提取特征点的二维坐标(u,v),并得到特征点的三维坐标(XB,YB,ZB),以此来解算RBC与tBC。因此,传统位姿估计方法的关键在于特征提取。特征提取方式分为:基于点特征、线特性、椭圆特征、矩形特征、三角形特性与多特征融合。
在点特征方面,通过提取航天器图像的Harris角度、ORB(Oriented FAST and rotated BRIEF)特征点等建立式(2),通过特征点的2D-3D 匹配PnP(Perspective-n-Point)算法求解RBC与tBC。对于特征点3D 坐标获取,可以使用SfM(Structure from motion)、SLAM(Simultaneous localization and mapping)或者深度相机。文献[2]提出ORB 特征的失效卫星位姿估计方法,在ORB-SLAM 框架下,通过ORB 特征点的PnP 匹配求解RBC与tBC。由于使用的是单目相机,SLAM 恢复出的3D 坐标缺少尺度因子s。因此,还需要建立关于平面法向量和单目相机安装高度的非线性优化模型求解尺度因子s。
在线特征方面,通过提取航天器图像的直线特征等建立式(2),求解过程中将PnP 变换为PnL(Perspective-n-Line)求解RBC与tBC。D’Amico等[3]利用单目相机获取Tango 卫星的图像,通过Hough 变换检测Tango 卫星的直线,用检测到的直线表示Tango 卫星的2D 模型,将2D 模型与已知的3D 模型匹配求解RBC与tBC。
椭圆特征方面,弧段检测算法或者Hough 算法检测到的对接环椭圆特征满足:
由式(5)可知,基于椭圆特征的位姿估计存在二义性,需要进一步使用深度传感器或者其他异面辅助特征消除虚假解,最后将获得的真解O与n转换为RBC与tBC。Liu 等[4]以星箭的对接环为特征,采用弧段方法提取椭圆特征,提出空间锥视觉测量模型,以二次型的形式建立了2D 图像平面与3D 空间圆的映射关系,进而推导出位姿参数。通过优化双目空间锥约束方程以及姿态角的定义,解决了椭圆姿态二义性问题。但是,仅采用双目视觉与椭圆特征无法求出滚转角,还需要进一步考虑使用异面特征或者滤波方法估计出滚转角。
矩形特征方面,利用矩形的4 个顶点使用PnP或者利用矩形的边使用PnL 求解RBC与tBC,还可以利用4 个顶点与矩形中心点的非共面特性,建立目标坐标系的方法求解RBC与tBC。Gao 等[5]利用通信天线的矩形特性实现位姿参数估计。Du 等[6]研究了通信天线上矩形框架交叉点的位姿测量算法。
在三角特征方面,利用三角形的3 个顶点使用PnP 或者利用三角形的边使用PnL 求解RBC与tBC。但使用3 个顶点特征属于P3P 问题,存在4 解问题,需要额外使用三角形的中心点构建P4P 得出唯一解。李文跃等[7]选取航天器帆板的三角支架作为研究目标,分析了近距离情况下的双目视觉测量技术。支帅[8]研究了基于航天器帆板三角架的双目视觉测量算法,通过求解3个特征点的空间坐标,实现航天器相对位姿的解算。
多几何特征融合方面,是将点∕线∕圆∕矩形∕三角形进行组合,一方面消除位姿的多解问题,另一方面抑制视场角受限问题。多几何特征融合一般应用在接近段位姿估计,但如何制定特征组合准则是非常困难的。Meng 等[9]提出一种基于圆与直线组合的位姿测量方法。Long 等[10]提出一种多圆特征与矩形特征组合的位姿测量方法。
然而,基于传统特征的航天器位姿估计都需要人工预先设计算法提取几何特征,难以适用于多种空间操控任务。尽管基于主被动相机融合、多特征组合的多源融合位姿测量可以满足一定的精细化要求或者多任务场景,但受限于星载资源限制,多源融合会导致位姿数据更新低于10 Hz,无法满足在轨操控的实时性需求。基于深度学习的位姿估计方法在本质上绕过了传统的特征提取,试图使用卷积神经网络赋予图像特征提取学习能力和语义能力,进而建立位姿信息之间的非线性变换关系,提高了航天器的智能化水平。
2 基于深度学习的航天器位姿估计
基于深度学习的航天器位姿估计的最初发展,是受航天器位姿估计比赛牵引。在公开比赛中,以欧洲航天局(ESA)为代表的航天机构通过开源数据集评测参赛队伍所提模型的性能。比赛中,参赛队伍受人体位姿估计的启发,提出了两阶段和端到端两种位姿估计方法。
2.1 基于深度学习的航天器位姿估计比赛
Pose Estimation Challenge 是ESA 与斯坦福大学航空宇航系于2019 年举办的公开比赛。主要目的是利用深度学习估计Tango 卫星的位姿。比赛所使用的数据集SPEED[11]为斯坦福大学航空宇航系半物理仿真制作。有45 支参赛队伍提交了位姿估计方案。方案可分为两类,其中一类为“关键点+PnP”的两阶段方法,首先使用深度学习提取Tango卫星的关键点,再利用PnP 的方法求解位姿。另一类为端到端的一阶段方法。方法的详细介绍见2.3 节。
Pose Estimation 2021 是ESA 与斯坦福大学航空宇航系于2021年继续举办的航天器位姿估计比赛。比赛的主要目的是在Pose Estimation Challenge 基础上,完成真实图像与地面模拟图像之间的域适应。所使用的数据集SPEED+[12]在SPEED 的基础上增加了lightbox、sunlamp 两个子数据集。Lightbox 考虑空间杂散光的干扰,sunlamp 考虑太阳光直接照射目标的强光干扰。解决航天器位姿估计域适应问题的方案有多尺度多任务多特征融合[13]、事件检测[14]、Transformer[15]、3D结构引导[16-17]等。
SPARK 比赛[18-19]由卢森堡国家研究基金资助,主要目的是基于深度学习实现航天器检测和轨迹估计,并将此应用到空间态势感知系统中。
AI4Space[20-21]是由美国商业航天公司Spire Global、Draper及澳大利亚航天局等资助,已经成功举办两届,分别开设CVPR(Computer Vision and Pattern Recognition)2021 与ECCV(European Conference on Computer Vision)2022研讨会。目前,该比赛吸引了来自以色列特拉维夫大学、美国斯坦福大学、澳大利亚阿德莱德大学、卢森堡大学、西北工业大学、悉尼大学等学校的学者参与。
通过以上航天器位姿估计比赛可知,基于深度学习的航天器位姿估计得到了以欧洲航天局为代表的航天机构的高度关注,以2019 年为起点,进入了快速发展阶段,起到了引领作用,如2.2所介绍的大部分数据集、2.3 节所介绍的大部分模型和算法均源于以上比赛。
2.2 基于深度学习的航天器位姿估计数据集
航天器位姿估计所使用的数据集一般由软件合成图像、地面半物理模拟环境采集与空间真实图像组成,其中代表性的数据集如下(汇总见表1)。
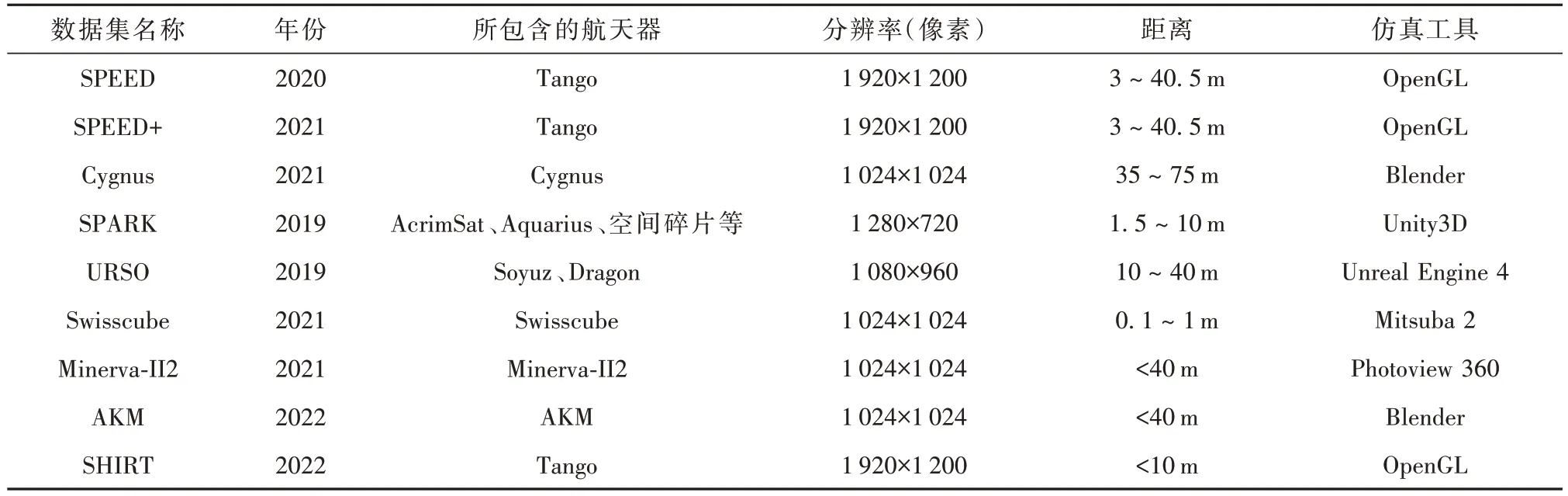
表1 用于航天器位姿的数据集Table 1 Datasets for spacecraft pose
SPEED数据集[11]是由欧洲航天局和斯坦福大学联合制作的航天器位姿估计数据集。该数据集可用于训练和评估基于深度学习的航天器位姿估计方法,数据集中的目标航天器模型依照PRISMA 任务中的Tango卫星真实尺寸的1∶2比例进行缩放制作。SPEED 测试集包含300 张真实图像和2 998 张合成图像,而训练集包含12 000 张合成图像和5 张真实图像。SPEED 数据集图像的尺寸为1 920×1 200 像素。合成图像中航天器的距离在3~40.5 m 之间,真实图像的距离在2.8~4.7 m之间。
SPEED+数据集[12]是在SPEED 数据集基础上,由欧洲航天局和斯坦福大学联合改进的航天器域适应位姿估计数据集。SPEED+由两个不同的图像域组成。第一个域由卫星软件模拟器中的光学相机模拟器生成,创建包含59 960 张合成图像的合成域synthetic。第二个是由半物理仿真生成,在模拟的光照条件下,使用太阳光模拟器、卫星模拟器、卫星表面材质模拟等生成与真实太空航天器图像相似的杂散光域lightbox 和太阳光域sunlamp。其中,合成域synthetic 带位姿标签用于网络训练,无标签的杂散光域lightbox和太阳光域sunlamp用于测试。
Cygnus 数据集[22]使用Blender 生成Cygnus 航天器的模型,利用Cycles 渲染引擎为图像进行光照渲染。为了更好地模拟真实空间环境中所拍摄的图像,使用Blender为合成图像添加各种类型的随机眩光、镜头耀斑。合成图像使用了两种类型的背景,第一个是真实的地球照片,旨在进一步提高真实感,第二种是完全随机化的非真实背景图像,旨在减少训练过程中的过拟合。
SPARK 数据集[18-19]是一个多模态数据集,包含10类航天器、1类空间碎片的150 000张RGB 图像和深度图像,分辨率为1 280×720。基于Unity3D生成包括不同轨道场景、不同背景噪声、不同传感器的多模态数据。其中,地球背景模型展示了云层和大气的散射效应。10 类航天器包括AcrimSat、Aquarius、Aura、Calipso、CloudSat、Jason、Terra、TRMM、Sentinel-6和1RU Generic CubeSat。空间碎片来源于航天飞机外部燃料箱、轨道对接系统、损坏的通信盘、隔热瓦、连接器等。
URSO 数据集[23]使用UE4(Unreal Engine 4)模拟Soyuz 和Dragon 图像,其考虑了航天器的表面材质、光学相机镜头的耀斑等。UE4 中的空间光照由定向光和聚光灯组成,其分别模拟太阳光和地气光。地球背景建模为一个多边形球体,分辨率为21 600×10 800。随机采样了地球日侧的5 000 个视点用于数据集生成。航天器位于相机视场内,距离相机的范围在10~40 m 之间。使用UnrealCV 插件为每个视点同步获取RGB 图像和深度图。图像的分辨率设置为1 080×960。
Swisscube 数据集[24]模拟了地球、太阳与目标的相对位置和空间环境。图像生成过程中,借鉴了NASA 可见光红外成像辐射计(VIIRS)获得的地球表面和大气的高分辨率光谱纹理,使用Mitsuba 2 renderer 光谱模拟器生成了最终数据集。数据集包含了500 个场景、100 个图像序列下的50 000 张图像。其中40 000 张用于训练,10 000 张用于测试。图像的分辨率设置为1 024×1 024。
Minerva-II2 数据集[25]参考了SPEED 数据集的制作过程中。以Minerva-II2 作为目标航天器,将Minerva-II2 的3D 模型导入到Solidworks 中,参考Hayabusa2 ONC-W2 相机参数,通过Photoview 360插件为每个视角的Minerva-II2 表面赋予相关的光谱特性。Minerva-II2 Dataset 包含了3 个部分,其中SetA 部分包含10 000 张真实的Minerva-II2 在轨图像;SetB 部分模拟了无太阳能帆板情况下的Minerva-II2;Tumble 部分模拟了Minerva-II2 失效翻滚状态下的图像。
Satellite point cloud 数据集[26]采用150 个卫星CAD 模型构建了云数据集,并使用blender进行了航天器ToF(Time-of-flight)相机成像模拟。为了更好地模拟空间在轨成像情况,航天器尺寸和成像距离分别随机设置在2~8 m和0.5~20 m范围内。为每个卫星模型模拟了360帧的点云数据序列。从位姿空间中随机采样卫星初始位姿,后续每帧欧拉角和沿各轴的位置在0.75°~1.25°和-0.2~0.2 m 范围内随机增大,得到不同位姿下的卫星点云数据。
AKM 数据集[27-28]以航天器发动机(Apogee Kick Motor,AKM)为目标,该目标为轴对称的椭圆球体且表面无纹理,其直径0.62 m,长度1.066 8 m。在空间环境模拟条件下,使用Blender合成10 000张图像,图像大小为1 024×1 024像素,成像距离为1~10 m。
SHIRT 数据集[29]是在SPEED 基础上,为每个交会场景创建两组图像,捕获间隔为5 s。第一组是使用斯坦福大学SLAB(Space Rendezvous Laboratory)的TRON 拍摄的模拟图像,TRON 由两条KUKA 6 自由度机械臂组成,分别安装相机和Tango 卫星模型。TRON 提供了每个机器人的末端执行器相对于测试平台的实时姿态。因此,SHIRT 是首个同类基准数据集,包含具有精确姿态标签的同一目标航天器的连续图像。
在合成数据集上训练模型,在真实空间所获取的图像上进行预测,会出现域差距问题[13-17]。目前,缩小域差距方法分为五类。
1)数据增强(方法汇总见表2)。数据增强通过改变图像大小和多样性变化,提高模型对不可见域的泛化。在航天器位姿算法中使用的数据增强技术可以进一步分为:像素级数据增强,如模糊、噪声或改变图像对比度;空间级数据增强,如旋转或缩放[13]。

表2 数据增强方法汇总Table 2 The summary of data augmentations
2)域随机化。域随机化是通过在一组足够随机化的源数据上训练模型来促进模型的泛化性,使目标(测试)领域看起来只是模型的另一种随机化[30]。
3)多任务学习。多任务学习是指训练单个深度学习模型同时执行多个相关任务。实现多任务学习最常见的方法是使用一个共享的骨干网络来提取特征,并将这些特征提供给特定任务的网络层。
4)对抗学习。文献[17]将对抗学习应用于航天器位姿估计,以缩小域差距,该方法的基本思想是,分类器区分源域和目标域的能力越弱,模型的域适应性就越强。
5)深度迁移学习。源域与目标域存在一些共同的交叉特征,通过特征变换技术,将源域和目标域的特征变换到相同空间,使得该空间中源域数据与空间目标域数据具有相同的数据分布。
综上所述,目前的数据集仍然不足以支撑在空间任务中部署基于深度学习的位姿估计算法,主要原因是合成数据集的真实感不足。渲染逼真图像的难点在于,其涉及到空间复杂光照的模拟及其与各种附件的相互反光作用。因此,如何渲染更逼真的合成空间图像是未来值得深入研究的方向。
2.3 基于深度学习的航天器位姿估计方法
目前,基于深度学习的航天器位姿估计方法分为:两阶段方法[30-38]、端到端方法[39-44]、域适应方法[45-47]及轻量化方法[48]。两阶段方法指第一阶段使用深度卷积网络提取航天器图像中的关键点,通常与目标识别网络配合使用,在完成航天器目标检测后,使用关键点预测网络,第二阶段使用PnP方法求解3D-2D 的位姿关系,如图2 所示。端到端方法为单阶段层次化端到端可训练方法[49-50]。端到端方法仅使用一个深度学习模型,以端到端方式直接从图像中回归航天器位姿,而不依赖中间阶段,最后使用由位姿误差计算的损失函数对模型进行训练。域适应方法将目标域(如SPEED 中的图像)和测试域(SPEED+中的图像)的数据特征映射到同一个特征空间,以完成航天器位姿估计的迁移任务。轻量化是在星载算力和内存限制情况下,通过减少网络参数等方式提高位姿估计的运行速度。
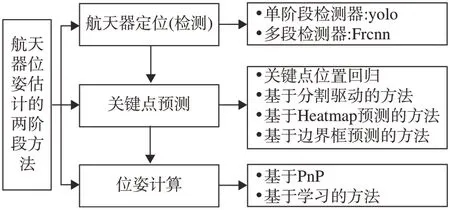
图2 两阶段方法Fig.2 Two-stage method
两阶段方法方面,本文重点叙述关键点检测与位姿计算两部分。在关键点检测部分,使用深度学习模型在图像预测预先定义的3D 关键点的2D 投影。关键点检测又分为关键点位置回归、分割驱动、热图预测、边界框检测这4种方法。关键点位置回归是目前常用方法。Chen 等[32]首次采用HRNet,将2D 关键点位置直接回归为1×1×2N向量,其中N为关键点个数。Park 等[30]使用YOLO-v2 架构,提出基于MobileNet-v2网络的位姿模型,关键点回归网络的参数量仅有5.64 Mb,在SPEED 测试集20 m 的观测范围内,该方法的位置误差小于210.3 mm,姿态误差小于3.10°。Lotti等[33]提出基于EfficientNet-Lite的关键点回归模型,该模型是从原始的EfficientNets中删除不支持硬件部署的网络层。文献[24,31,34]提出多种变体模型,使其参量减少。热图预测是对关键点位置的热图编码概率进行回归,从热图中提取概率最高的像素坐标表示关键点的方法。HRNet架构在整个网络中保持高分辨率的特征图,使其适合热图预测任务。UNet 架构也用于预测关键点的热图[35]。Huo 等[36]提出一种轻量级的混合架构,将YOLO 与热图回归子网络相结合用于关键点预测。在目标检测和关键点预测之间设置共享网络,使参数总量减少到89 Mb。边界框预测中,Li 等[37]将关键点预测表述为关键点边界框检测问题,与置信度分数一起预测关键点上的封闭边界框。文献[38]使用CSPDarknet 与特征金字塔网络(Feature pyramid network,FPN)进行多尺度特征提取,然后使用检测头进行关键点边界框检测,最后将卷积网络提取的2D 关键点与预定义3D 点进行2D-3D 匹配,利用PnP 计算位姿。由于PnP 对异常点敏感,随机样本一致性(RANSAC)通常用于去除异常值。Legrand等[34]利用多层感知器架构,提出使用姿态推理网络MLP 取代PnP,使得姿态计算过程可微。两阶段方法汇总见表3。
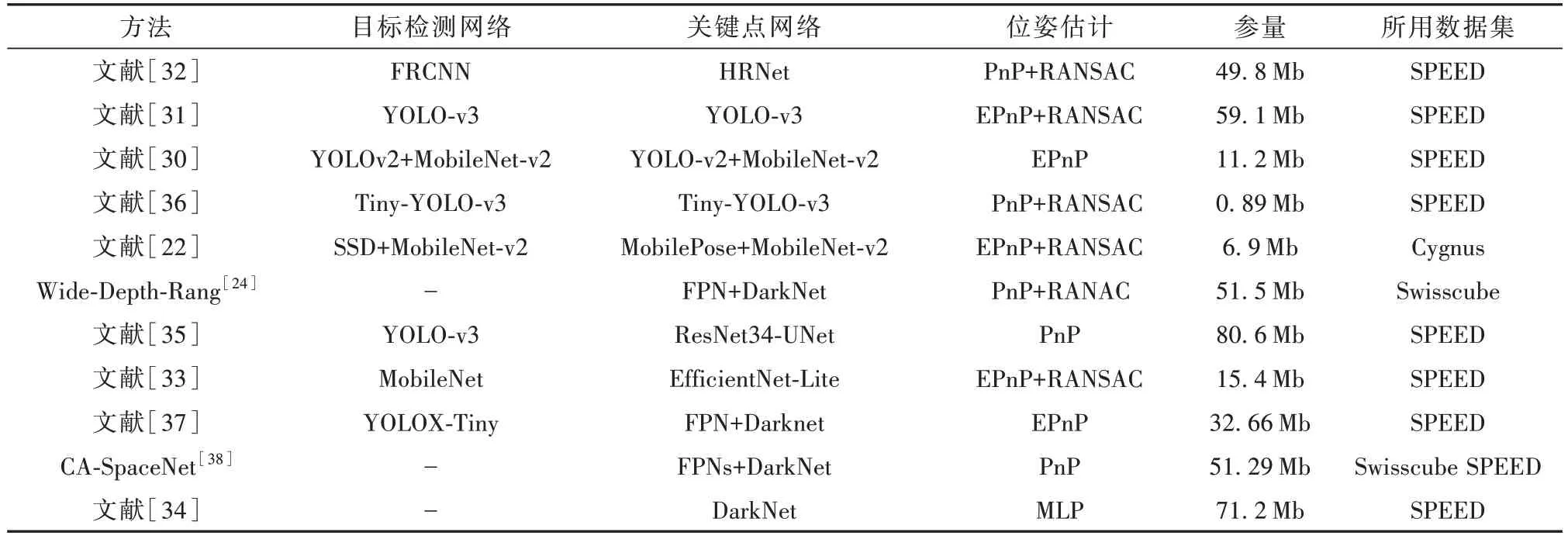
表3 航天器位姿估计的两阶段方法Table 3 Two-stage methods for spacecraft pose estimation
端到端方法方面,Phisannupawong 等[39]基于GoogleNet 回归代表位置和方向四元数的位姿向量,该网络使用指数损失函数和基于欧几里得的损失函数进行训练。Sharma等[40]提出沿4个自由度将姿态空间本身离散为姿态分类标签。然而,受到姿态类标签总数的限制,在softmax 层中,更大数量的姿态标签将需要等量的神经元,这将增加模型的参量。Sharma 等[41]提出航天器姿态网络(SPN),在SPEED 的测试中,其位置误差小于220.7 mm,姿态误差小于8.43°。文献[42]采用ResNet 作为基础网络提取特征。其中,姿态预测子网络通过软分类和误差四元数估计航天器的方向,姿态回归子网络通过直接回归预测航天器的位置。Proença 等[23]提出URSONet 位姿估计模型,基于ResNet 直接回归航天目标的位置和姿态向量,并将位姿分类定义为基于高斯混合模型的软分类,以处理位姿模糊问题,在SPEED 测试集20 m 的观测范围内,位置误差小于170.3 mm,姿态误差小于4.02°。URSONet 在训练阶段对姿态细粒度设置得较高,不可避免地会增加网络训练的时间以及位姿解算时计算资源的消耗。Posso 等[43]提出mobile-URSONet,使用MobileNet-v2提取特征,将URSONet网络的参数减少178倍,而精度损失不超过URSONet 的4 倍。Park 等[13]提出SPN-v2,对原始SPN 进行了改进,以解决域差距问题。SPN-v2 具有多尺度多任务网络架构,其共享特征提取器使用EfficientPose。Garcia 等[44]提出一个包含位置模型和选择模块的姿态估计网络。平移模块属于UNet 架构,用于预测航天器在相机坐标下的3D 位置和在图像坐标系下的2D 位置。旋转模块采用回归网络预测航天器方向。Diff-6dofregression[50]利用可微分渲染技术首先重建出航天器的三维模型,然后使用姿态回归网络对位姿进行粗略估计,接着使用位姿细化网络进一步优化位姿结果。Gao 等[49]提出DR-U-Net(Dense Residual Ushaped Network)提取特征,然后结合Transformer 形成SU-Net。为了解决图像模糊导致航天器轮廓识别精度低的问题,在DR-U-Net 基础增加了残差模块。最后,将一层前馈神经网络用于航天器在轨位姿估计。文献[21]提出基于Efficientnet 网络的航天器位置和姿态回归方法。将旋转回归损失函数转换为预测值与真实值之间的黎曼测地线距离。此外,针对航天器数据集规模小导致的过拟合问题,提出了多种数据增强技术。文献[15]基于Transformer实现航天器的位姿估计。端到端的方法汇总见表4。

表4 航天器位姿估计的端到端段方法Table 4 End-to-end method for spacecraft pose estimation
域适应方法方面,文献[13]提出SPN-v2 网络。SPN-v2 是一个多尺度、多任务的CNN,由一个共享的多尺度特征编码器和多个预测头组成,这些预测头在共享的特征输出上执行不同的任务。在SPEED+上的实验表明,通过对不同但相关的任务进行联合训练,仅对合成图像进行大量数据增强,共享编码器学习了与合成图像相比具有不同视觉特征的图像域的共同特征。文献[14]提出基于事件感知的航天器位姿估计方案,只对合成数据进行训练,不进行自适应,可以有效地推广到目标域。文献[16]提出将3D 结构引入到航天器位姿估计模型中,以提供对强度域偏移的鲁棒性,并提出了一种具有鲁棒伪标签的无监督域自适应算法。文献[45]提出基于域不可知几何约束的自我训练框架,训练神经网络预测卫星的二维关键点,然后利用PnP 估计位姿。将目标样本的位姿作为潜在变量,将任务转化为最小化问题。此外,利用细粒度分割将卫星抽象为稀疏关键点所引起的信息丢失问题。最后,通过伪标签生成和网络训练两步迭代解决最小化问题。文献[46]使用少量实际目标图像进行迁移学习,实现航天器图像高层抽象特征的自动提取,设计基于回归模型的位姿映射网络,建立图像高层特征与三轴位姿角之间的非线性关系。文献[47]考虑到航天器的非精确3D结构,提出融合误差感知与几何引导的位姿估计模型。综上,域适应方法汇总见表5。
表5 航天器位姿估计的域适应方法Table 5 Domain adaptation methods for spacecraft pose estimation
轻量化方法方面,文献[48]利用TPU(Tensor Processing Unit)加速位姿估计。在SPEED 数据集上测试,以每秒7.7 帧的速度运行,仅消耗2.2 W。文献[42]开发了适合50 kg 微纳星的6 自由度位姿估计模型,基于人体位姿估计lite 架构的启发,提出lite-HRNet。文献[36]针对单目位姿估计方法依赖于已知目标航天器的三维模型及计算量大的问题,提出基于卷积神经网络航天器单目位姿估计网络。文献[35]提出一种基于深度学习的航天器位姿测量轻量化方法。通过引入轻量级类YOLO 网络用于检测航天器并实时预测先前重建的3D 模型投影关键点的2D 位置,利用PnP 和几何优化器对位姿进行优化。文献[26]提出可在FPGA 上运行的航天器位姿估计方法。在Xilinx 公司的Zynq UltraScale 上验证了FPGA-CPU混合架构的有效性。
2.4 基于深度学习的航天器位姿估计模型分析
在边缘设备上部署位姿估计模型,使其在星载计算机上使用,是航天器位姿估计的最终目的。因此,未来的研究需要在大型、高性能模型和小型、可部署模型之间进行权衡。算法的另一个考虑因素是模块化性质。两阶段方法由检测、关键点回归和位姿计算3部分组成,为构建不同位姿估计任务的应用提供了更大的灵活性。相比之下,端到端方法只包含一个端到端训练的深度学习模型,整个模型必须重新训练以适应如相机参数的变化。在两种方法之间的性能比较方面,通过对Pose Estimation Challenge比赛中方法分析表明[17],两阶段方法的性能相对优于端到端方法。两阶段方法和端到端方法的平均定位误差分别为0.008 3 m±0.026 9 m 和0.032 8 m±0.043 0 m,平均定位误差分别为1.31°±2.24°和9.76°±18.51°。此外,现有算法仍需要考虑如下几个方面的局限性。
1)对光照条件的鲁棒性:现有算法通常对光照环境的变化敏感,直接影响位姿估计的准确性和鲁棒性。Pose Estimation Challenge 2021 结果表明,即使是训练最好的模型,在动态变化光照条件下所获取图像上表现不佳。
2)自主持续学习:现有的模型仅考虑训练域与合成域之间的域差距问题,但图像所包含的航天器种类并未改变,只是光照与背景发生了变化。当模型应用于在轨操控以后,会面临许多类型的航天器,提高模型对未见类的自主持续学习能力非常关键。
3)传统方法与深度学习的结合性:从两阶段方法来看,结合传统方法与深度学习也是未来提高模型鲁棒性和精度的一条途径。
4)目标的非合作特性:现阶段的模型,大部分都假设航天器为合作目标。实际的空间操控任务中,航天器大多都是非合作目标,其关键点的位置、3D 模型结构都是未知的。因此,两阶段方法所使用的关键点回归可能会失效。发展融合深度估计网络、目标三维重建网络的位姿估计模型是必要的。
5)模型的可扩展性:空间在轨操控一般包括观测阶段、绕飞接近段、超近距离操控段。目前的模型一般仅考虑了超近距离段的位姿。观测段与绕飞段获取的航天器图像可能存在低分辨率、运动模糊等问题。因此,后续的模型设计应该考虑添加图像超分辨网络、图像去运动网络等模块。
6)模型轻量化:由于星载计算机算力有限,现有位姿模型的轻量化网络设计也是实现在轨应用的一个关键问题。相较于两阶段方法,端到端方法结构简单、更具有轻量化优势,但目前的研究较少。两阶段方法的轻量化设计仅使用了类似轻量级类YOLO、lite-HRNet 等。面向航天器位姿估计,未来发展模型压缩技术、知识蒸馏、模型剪枝、模型量化、低秩分解是必要的。
7)参考地面物体6 自由度位姿估计:可借鉴目前地面物体的6 自由度位姿网络设计思路,如几何引导直接回归网络(GDR-Net)、编码器解码器位姿网络(EPOS)、标准化物体坐标空间(NOCS)、自监督学习姿态估计(Self6D)以及基于目标检测改进的Yolo6D与SS6D等设计航天器的位姿估计模型。
2.5 基于深度学习的航天器位姿估计开源模型
目前,基于深度学习的航天器位姿估计开源模型汇总如表6 所示。其中表6 的YOLOv5-SPEED_SLN、HRNet-SPEED_MP 主要用于关键点检测,可直接在SPEED 数据集上测试,没有对应的论文。表6中的Spacecrafts-6D-Pose-Estimation 研究两阶段位姿估计,pose_estimation_domain_gap 研究域适应位姿估计,没有对应的论文。

表6 基于深度学习的航天器位姿估计开源模型汇总Table 6 Summary of open-source models for spacecraft pose estimation based on deep learning
3 发展趋势与建议
由基于深度学习的航天器位姿估计方法研究现状,从数据集逼真度、模型可部署、多任务域适应3 个维度提炼出当前亟待解决的问题并给出研究建议[51-54]。
1)样本标注:面向航天器位姿估计的数据集所标注的特征一般为关键点,缺少对接环、帆板等自然特征的标注。因此,易标注样本引导的难标注样本的预训练方法值得研究。
2)多模态数据集:当前基于卷积神经网络的位姿估计方法仅使用单目图像进行训练,仅有文献[26]使用点云进行训练。实际空间任务中,服务航天器搭载多种传感器,如双目视觉、ToF 相机、激光雷达、红外相机等。因此,后续的数据集制作及位姿模型还需考虑红外图像、深度图像或点云图等模态的融合。
3)合成数量的逼真性:深度学习方法应用于空间在轨操控的主要问题是缺乏数据。使用合成数据会面临域适应问题。解决这个问题可以通过将渲染引擎合成的图像与实际空间图像进行深入分析,该分析的结果可以作为开发渲染引擎的起点,用于生成较为逼真的图像。
4)可部署性:尽管航天器位姿估计算法的发展取得了进展,但部署仍然是一个重要问题。在目前的研究工作中,只有一小部分模型在边缘系统上进行了测试和评估[33]。此外,现有文献很少报告影响算法可部署性的因素,如延迟、推理时间、内存需求、功耗和算力等。
5)可解释性:深度学习模型的黑箱性质使得基于深度学习的航天器位姿估计的可解释性变得困难,特别是对于端到端算法。考虑将贝叶斯深度学习或保形推理方法应用于航天器姿态估计,提高其可解释性,这是未来值得研究的方向。
6)考虑多种关键点提取网络:两阶段方法中,关键点提取网络使用HRNet。但HRNet为保持特征图像高分辨率,多阶段级联结构会引起参数规模与运算量过大和处理速率下降等问题,不利于在资源受限的星载计算机上实现。
7)航天器具有对称性和表面光滑性:大部分航天器由于表面贴覆保温材料,其纹理特征弱甚至无纹。此外,航天器一般设计为对称结构。目前的两阶段方法一般先采用检测算法定位目标,而目标检测算法依赖于目标的纹理与结构,在低光照或者复杂背景情况下可能会导致检测失效。
8)遮挡和截断问题:对于在轨操控任务,狭小空间场景中的目标往往是存在遮挡的;另外待测目标很可能会脱离相机的视野,使得获取的目标图像不完整。
9)多任务联合学习:当前深度学习的位姿估计处于单独任务中,无法与上下游任务(如特征跟踪、语义分割、三维重建、运动参数解耦等)结合形成一个航天器精细化感知模型。
10)适应远距离:当前基于深度学习的位姿估计方法主要研究近距离(<20 m)情况下的位姿估计问题。实际空间操控任务场景中,服务航天器是从100 m 以外逐渐接近目标航天器。因此,远距离(>100 m)获取的航天器图像纹理模糊、超近距离(<2 m)获取的航天器局部或遮挡情况下的位姿估计值得研究。
11)泛化性:当前基于深度学习的位姿估计方法主要研究特定场景的单目标位姿估计,后续还需进一步研究多任务场景下的多目标位姿估计问题。
12)时间连续性:目前的航天器位姿估计模型孤立地考虑每一帧图像,并从单个图像帧中提取特征信息来估计姿态。然而,在空间在轨操控中,姿态估计算法通常用于自主导航,视觉相机可以获得一系列连续图像。未来,考虑帧间时间连续性的位姿估计方法值得进一步研究。
