The concept of sUAS/DL-based system for detecting and classifying abandoned small firearms
2023-12-27JungmokOlegYkimenko
Jungmok M ,Oleg A.Ykimenko
aDepartment of Defense Science, Korea National Defense University (KNDU), Republic of Korea
b Department of Systems Engineering, Naval Postgraduate School (NPS), USA
Keywords:Small firearms Object detection Deep learning Small unmanned aerial systems
ABSTRACT Military object detection and identification is a key capability in surveillance and reconnaissance.It is a major factor in warfare effectiveness and warfighter survivability.Inexpensive,portable,and rapidly deployable small unmanned aerial systems (sUAS) in conjunction with powerful deep learning (DL)based object detection models are expected to play an important role for this application.To prove overall feasibility of this approach,this paper discusses some aspects of designing and testing of an automated detection system to locate and identify small firearms left at the training range or at the battlefield.Such a system is envisioned to involve an sUAS equipped with a modern electro-optical (EO)sensor and relying on a trained convolutional neural network (CNN).Previous study by the authors devoted to finding projectiles on the ground revealed certain challenges such as small object size,changes in aspect ratio and image scale,motion blur,occlusion,and camouflage.This study attempts to deal with these challenges in a realistic operational scenario and go further by not only detecting different types of firearms but also classifying them into different categories.This study used a YOLOv2 CNN(ResNet-50 backbone network)to train the model with ground truth data and demonstrated a high mean average precision (mAP) of 0.97 to detect and identify not only small pistols but also partially occluded rifles.
1.Introduction
Artificial Intelligence (AI) technologies have been incorporated into a variety of systems already,and shown the great potential for new opportunities in every aspect of our lives.Among them,computer vision is one of the most popular areas,which enables computers to acquire meaningful information from the visual inputs by utilizing AI technology.This allows machines to detect the objects of interest with no human input,which can be very useful for surveillance,autonomous driving,rescue operations,resource management,etc.
In military,Automatic Target Recognition (ATR) is frequently used as “an umbrella term for the entire field of military image exploitation”[1].ATR has actively been studied since it is a“key to automatic military operations and surveillance missions”[2].Accurate and fast detection of military objects can ultimately increase survivability of warfighters.In the stricter sense,ATR aims at automatically locating and classifying targets from the collected sensor data.Automatic Target Detection and Classification(ATD/C)is also widely used in a similar manner where a target represents“any object of military interest”[1].ATD/C can significantly improve the orient stage in the OODA (Observe,Orient,Decide,Act) loop which represents the military decision-making cycle,especially in the case on non-stationary targets.The faster and more accurate OODA cycle ensures major advantages for all units from the operational to tactical and strategical levels.In this paper,ATD/C is applied to small firearms.
Conventional object detection methods such as feature matching,threshold segmentation,background identification,etc.Are advantageous for certain situations but generally limited to noncomplex,non-diverse scenarios and require manual interference[3,4].In recent years,deep learning(DL)based models or variants of Convolutional Neural Networks (CNNs) have gained great popularity with adaptability and flexibility for object detection.Also,CNN-based detectors such as YOLO (You Only Look Once) [5],SSD(Single Shot MultiBox Detector)[6],and Faster RCNN(Region-based CNN) [7] have already demonstrated state-of-the-art performance on several public object detection datasets.
Another popular trend for military object detection (MOD) is utilizing small Unmanned Aerial Systems(sUAS).sUAS can provide higher efficiency,flexibility and mobility as compared to traditional ground-based platforms so that they are widely used in a diverse civil and military missions.According to the U.S.Army UAS roadmap 2010-2035 [8],sUAS will provide reconnaissance and surveillance capability for the battalion and below levels.Currently,a next-generation sUAS is developing with a focus on autonomous capability [9].
However,object detection with sUAS can face many challenges such as small object size,changes in aspect ratio and image scale,motion blur and occlusion [10,11].Moreover,detecting military objects in general,can increase the difficulty such as lack of data,camouflage,and complex background[3].Using sUAS for MOD can also suffer from limited computational and memory resources available on board [2].
In this paper,the DL-based military object (small firearm)detection system is prototyped and tested using a realistic scenario and real object imagery collected using a typical sUAS electrooptical (EO) sensor.The contribution of the paper can be summarized as follows.First,there were few studies to provide the proof of the feasibility of DL-based sUAS for MOD with real data.The recent study by Cho et al.[12] proposed a YOLO-based unexploded ordnance (UXO) detection model with sUAS and assessed its effectiveness on a small set of imagery collected under severe security constraints.The paper concentrated on small firearm detection only leaving classification for follow-on research.The current paper extends the work of Cho et al.[12] by conducting both detection and classification using real data and exploring other than YOLO object detection algorithms explicitly demonstrating YOLO's superiority.Second,the military data collection and analysis are designed to tackle the challenges of small object size,motion blur,occlusion,and camouflage.While this paper does not provide any methodological advancement in object detection and classification in general,it represents a real data driven feasibility study of employing a widely used YOLO algorithm in a specific reallife application.The achieved results proved that the overall concept is viable and demonstrated a very high precision of detection and classification.Reliability and robustness of small firearm detection in a wider range of underlying terrain and weather conditions can be enhanced by utilizing the recent novel techniques like going beyond a common image augmentation used in this paper and employing albumentation approach [13],as well as incorporating the oriented bounded boxes [14].These proven enhancements would need to be used for a higher technological readiness level of the proposed system but were out the scope of this paper.
The paper is organized as follows.Section 2 provides an overview of the previous research as related to the DL-based object detection methods in general and MOD in particular.Section 3 describes an operational scenario and data collection procedure utilized in this research,and designs and tests the automatic detector based on the military object videos recorded by sUAS.The paper ends with conclusions.
2.Background
This section provides an overview of the known previous research efforts dedicated to using DL for object detection and DLbased MOD systems integrated with sUAS.
2.1.DL-based object detection
Object detection methods can be classified as traditional image processing methods and DL-based methods [10].The DL-based methods can be further subdivided into region-based (or twostage network)and single-shot(or one-stage network)approaches.
The region-based detection establishes Regions of Interest(ROI)at the first stage,and then defines the bounding boxes(BBs)around potential objects of interest and classifies them using a trained DL network.Such methods as RCNN [15],Fast RCNN [16],and Faster RCNN are widely known and popular in this category.After introducing RCNN in 2014 as a two-stage network,its major weakness was a slow speed since each candidate region required a CNN forward propagation procedure.Fast RCNN uses a ROI pooling layer to make the CNN forward propagation performed only once on the entire image.Faster RCNN proposed in 2016 uses a Region Proposal Network (RPN) for selective search which is a region proposal algorithm.
While region-based detection methods can achieve high localization and recognition accuracy,the inference speed seems to be inefficient,especially for real-time applications.That is why the single-shot detection methods,computing the BBs(spatial location of objects) in a single step,were developed.The SSD and YOLO algorithms belong to this latter category.
SSD uses a single feed-forward CNN to calculate scores for the potential presence of objects within the BBs and detects objects using the Non-Maximum Suppression (NMS) procedure.NMS selects the best BB and suppresses other overlapped BBs with the best one based on Intersection over Union(IoU).IoU of the two boxes is computed as an intersection area divided by the union area between them.In addition to the base network (VGG-16),SSD features multi-scale feature maps,convolutional predictors,default boxes (similar to anchor boxes) of different aspect ratios [6].
YOLO is also a one-stage network which splits the input image into the grids and predicts BBs with confidence scores for each grid.Then,NMS selects the best BB based on IoU.The authors of YOLO characterized the model as refreshingly simple,with a single CNN,extremely fast,and with a global reasoning about the whole image.YOLO evolved into YOLOv2[17],YOLOv3[18],YOLOv4[19],YOLOv5[20].YOLOv2 was introduced in 2016 with the key futures of anchor boxes with K-means clustering,batch normalization,highresolution classifiers for better accuracy in addition to the backbone network of Darknet-19.YOLOv3 was rolled out in 2018 with the multi-scale features (three scales) and Darknet-53 as a backbone network.Starting with YOLOv4,researchers keep adding new features as new YOLO versions[21-23].
Reviewing multiple research efforts on DL-based object detection employing sUAS,Ramachandran and Sangaiah [10] and Wu et al.[11]established that Faster RCNN,YOLO,and SSD were the top three commonly used methods.
2.2.DL-based MOD systems with sUAS
A majority of modern sUAS (aka Group 1 and Group 2 UAS)feature light weight(less than 30 kg)and endurance not exceeding 1 h [11].By combining with remote sensors and wireless communications,these sUAS play an important role in a variety of missions including surveillance,monitoring,smart management,delivery services,etc.Literature review reveals that despite a remarkable progress in developing object detection algorithms (as briefly described in Sec.2.1),they are not widely employed on the sUAS yet[10,11].
In Ref.[11],the DL-based object detection research was conducted to overcome the challenges of object detection using sUAS such as small objects,scale and direction diversity,and detection speed.Chen et al.[24] proposed RRNet,which removed prior anchors and added a re-regression module for better capturing small objects with a scale variation.This research used a public dataset(VisDrone)and was able to detect people and vehicles captured by sUAS EO sensor.Liu et al.[25] developed sUAS-based YOLO platform,which attempted to improve the network structure of YOLOv3 by enlarging the receptive field for small scale of the target.Both public dataset (UAV123) and collected dataset were used to detect people.Liang et al.[26] proposed a feature fusion and scaling-based SSD model for small objects with a public dataset(PASCAL Visual Object Classes (VOC)).Jawaharlalnehru et al.[27]built a YOLOv2 detection model with some revised approaches such as fine-tuning with both ImageNet dataset and self-made dataset,changing input sizes of the model during training,and changing NMS to the maximum value of the operation.There were also some trials to enhance the detection speed,including SlimYOLOv3 [28],Efficient ConvNet [29],and SPB-YOLO [30],as well as determine the best angle for detecting targets for UAVs [31].
Even fewer number of publications (in the open literature) are available on the challenges and successes of the MOD missions.One of the main reasons is lack of available data due to operational and security issues.D’Acremont et al.[32] reported training the CNN models using simulated data and test on infrared (IR) images(SENSIAC (Military Sensing Information Analysis Center) open dataset).Zhang et al.[33]constructed an intelligent platform which can generate a near-real military scene dataset with different illumination,scale,angle,etc.Yi et al.[34]suggested a benchmark for MOD which has characteristics such as complex environment,inter-class similarity,scale,blur,and camouflage.Liu and Liu [2]utilized fused images of the mid-wave infrared image (MWIR),visible image,and motion image as an input for the Fast RCNN in lieu of insufficient data.SENSIAC dataset was used to detect military vehicles.Janakiramaiah et al.[4] proposed a variant of the Capsule Network CNN model,Multi-level Capsule network under the case of small training dataset.Five military object images(armored car,multi-barrel rocket,tank,fighter plane,gunship)were collected from the Internet for the classification task.
Nevertheless,a few studies have reported a success of conducting MOD using the real imagery captured by an sUAS sensor.For example,Gromada et al.[35] used YOLOv5 to detect military objects from open synthetic aperture radar (SAR) image datasets.The objects included tanks and buildings from MSTAR dataset and ships from SAR Ship Detection Dataset(SSDD).Cho[36]proposed a YOLOv2-based UXO detection model using fused images of Blue,Green,Red,Red Edge,and Near Infrared spectra captured by sUAS’multispectral sensor.However,UXO data was collected using a ground-based system.The feasibility of the proposed paradigm and performance of the developed detector were tested on small firearms but were limited to just detection(i.e.,no classification).This paper continues this latter line of efforts,but this time involves detection and classification.
3.CONOPS and imagery collection procedure
The tactical background for the MOD mission explored in this research and concept of operations (CONOPS) can be described as follows.A military commander is required to conduct a MOD mission of a certain operating area.One or multiple sUAS are deployed to execute this mission utilizing standard onboard EO sensors.The sUAS executes a serpentine search pattern transmitting imagery to the ground control station where the objects of military interest are localized and classified using the pretrained CNN.
For the small firearm detection mission,the multirotor sUAS can fly a pattern maintaining a fixed~3 m height above the ground level at a constant speed of~1.4 m/s.In this case,during a 30 min flight,a single sUAS can cover on the order of 1300 m2.
In this study,a DJI Inspire 1 Pro(Fig.1(a))was integrated with a Zenmuse X5 sensor (Fig.1(b)).DJI Inspire features a maximum takeoff weight of 3.5 kg,maximum speed of 18 m/s,maximum flight time of~15 min and maximum line-of-sight transmitting distance of 5 km.Zenmuse X5 is a 16-megapixel EO RGB sensor with a video resolution of 4096 pix×2160 pix and shutter speed of 1/8000 s.

Fig.1.(a) sUAS;(b) EO sensor used in this research.
To collect imagery for CNN training,this sUAS flew search patterns over a 28.7 m×15.2 m(440 m2)operating area.Three classes of small firearms were considered: pistol (Fig.2(a)),black rifle(RifleBK) (Fig.2(b)),and brown rifle (RifleBN) (Fig.2(c)).2.During the data collection,the positions and orientations of the objects were varied.Obviously,finding and classifying a pistol appears to be a more challenging task compared to finding the larger objects(rifles)because a smaller object can sometimes be confused with a shadow or a black stone.The confusion may also occur when even the larger objects are partially obscured.To this end,Fig.2(c) illustrates an example of part of a brown rifle being intentionally hidden in the grass/leaves.

Fig.2.Objects of interest: (a) Pistol (in red box);(b) Black rifle;(c) Brown rifle.
In total,18 about 1-min-long video clips were collected.These video clips were transformed into 3140 images which have 4096 pix × 2160 pix resolution.Then,the images were resized as 416 ×416 pixels for reducing a computational cost of DL.Since it is common to have partially occluded objects in military applications[37],images with less than half occluded firearms were included in the dataset as well.
All further analysis was conducted using the MATLAB (R2021b version) interpretative environment using a generic laptop with a single CPU.This laptop featured an Intel(R)Core™i5-8265U CPU@1.60 GHz 8 GB RAM processor.
4.Choosing the best candidate detector
Following imagery collection and conditioning,the Faster RCNN,YOLO,and SSD models were explored to see which one delivers the best performance in detecting small firearms.Since the previous study[12]used YOLOv2,for the sake of comparison,this study was based on YOLOv2 as well.No doubt,that the latest versions of YOLO,for example YOLOv3 [18] or YOLOv4 [19],that became available in MATLAB R2023a,or YOLOv5-YOLOv8[20-23]available in Python would work more efficiently(be more precise and faster).A randomly selected subset of 300 images was used for assessment of the three models.
These object detection models are composed of feature extraction network (backbone) and subnetworks trained to classify objects from the background,trained to classify the detected objects,etc.For a feature extraction network,ResNet-50 was selected among other well-known networks such as VGG-16/19,DarkNet-19/53,and Inception-v3 based on the tradeoff between accuracy and speed.ResNet-50 has 48 convolution layers along with 1 maxpooling layer and 1 average pooling layer,which uses deep residual learning.While this study used the 40-layer version of ResNet-50 for improving speed,it reused the pretrained version of the network trained on the ImageNet database in MATLAB,which is transfer learning with 25.6 million parameters.
The Faster RCNN model adds two more subnetworks,a RPN for generating object proposals and a network for predicting the objects.Both YOLOv2 and SSD models add a detection subnetwork which consists of a few convolution layers and layers specific to the models such as yolov2TransformLayer(transforms the CNN outputs into the object detection forms) and yolov2OutputLayer (defines the anchor box parameters and loss function).
Training the models (in a supervised learning mode) requires ground truth data.This was accomplished by utilizing the Image Labeler of MATLAB resulting in the BBs (locations) with the object names(three different firearms)added to all 300 images.Then,the images were randomly divided into three groups -70% (210) for training,15% (45) for validation,and 15% (45) for testing.
Next,to estimate the number of anchor boxes for Faster RCNN and YOLOv2,the K-means clustering based estimation was implemented.Based on the plot of numbers of anchors and mean IoUs,5,8,and 11 anchors were tested with the mean IoU of 0.75,0.82,and 0.87,respectively.Note that utilizing more anchor boxes can increase the IoU values between the anchors and ground truth boxes,but at the same time,increases the training time and leads to overfitting.
Table 1 shows the results of testing Faster RCNN,YOLOv2,and SSD detectors based on five runs (five random splits of data onto training,validation and testing subsets).Specifically,this table shows the mean Average Precisions (mAPs) computed for all the object classes.The AP,the area under the precision-recall (p-r)curve,is computed using the 11-point interpolation [38,39].

Table 1 Comparison of detectors’ mAPs.
where
In Eqs.(1)-(2),pis the precision (true positive/total positive),andris the recall (true positive/total true).The detection IoU threshold was set to 0.5.Obviously,different runs(different threeway split of imagery) result in different mAP values.
As seen from this table,in one of the YOLOv2 runs the mAP of 1 was achieved over three firearms(which is a perfect performance).This case corresponds to the YOLOv2 model been trained with the 8 anchors,mini-batch size of 8,learning rate of 0.001,and maximum number of epochs of 10.The training time happened to be about 1 h and 20 min for each run.When the learning rate was increased to 0.01,the mAP dropped to almost 0,and when the number of anchor boxes was increased to 11,the mAP was 0.948(AP for Pistol was 1,for RifleBK-0.85,and for RifleBN -1).Other variations of parameters did not improve the YOLOv2 mAP.
The SSD model was trained with the mini-batch size of 8,learning rate of 0.001,and maximum number of epochs of 10 as well(the MATLAB ssdLayersfunction selected 8 anchor boxes too).The best mAP achieved was only 0.486 (AP Pistol was 0.357,for RifleBK-0.267,and for RifleBN-0.833).It took about the same 1 h and 20 min to train the model for each run.Varying other model parameters did not improve mAP either.
The Faster RCNN was attempted to be trained with the 8 anchors,mini-batch size of 2(due to the memory issue),learning rate of 0.001,and maximum number of epochs of 10.However,just a single epoch required over 2 h to be trained so further exploration of this model was abandoned due to computational inefficiency.
As a result of different detectors exploration,the YOLOv2 CNN model was chosen as the best candidate for the proposed sUAS/DLbased system for detecting and classifying abandoned small firearms.
5.YOLOv2 model testing on a full set of data
Based on the preliminary tests reported in Sec.4,the whole 3140-image data set was used with the YOLOv2 model.The structure of a YOLOv2 model (40-layer version of ResNet-50 as backbone) is shown in Fig.3.

Fig.3.Structure of a YOLOv2 model.
The images were labeled to obtain ground truth data and then randomly divided into three groups -70%(2198) for training,15%(471) for validation,and 15% (471) for testing.Also,in order to improve the performance of the model,data augmentation such as rotation,contrast,and brightness change was applied to the training data group.As a result,the training dataset was increased fourfold to 8792 images.
The dependence of the mean IoU vs the number of anchor boxes is shown in Fig.4.In the following analysis,7 and 11 anchors were tested with the mean IoU of 0.78 and 0.81,respectively.

Fig.4.Mean IoU vs the number of anchor boxes.
To begin with,the YOLOv2 model was trained with the 11 anchors,mini-batch size of 8,learning rate of 0.001,and maximum number of epochs of 5.With these settings,the mAP of 0.971 was achieved.Specifically,the AP for Pistol was 0.988,for RifleBK -0.984,and for RifleBN-0.942(Fig.5).The training time was about 11 h and 45 min.The training loss started at 518 for the first iteration,gradually decreasing to 2 at the 50th iteration and then keeping decreasing down to almost 0.
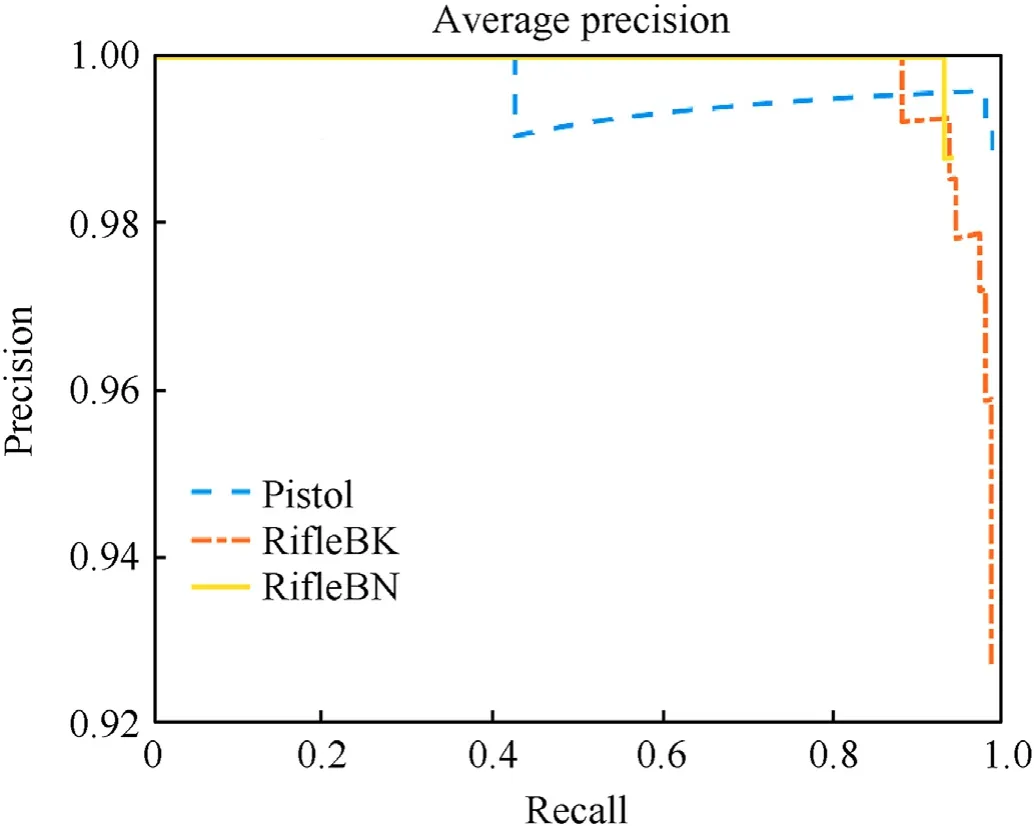
Fig.5.Average precision vs.recall.
Next,some of the parameters were varied to see their net effect.Increasing the number of epochs twofold (to 10) had only some minor effect.When 7 anchors were used,the mAP dropped to 0.845.
In general,the achieved results are very encouraging and prove the overall feasibility of the proposed concept.It was also proven that the trained detector can effectively detect the relatively small objects (pistols) and partially occluded objects as well (Fig.6).Indeed,the partially visible objects are more difficult to be detected than the fully visible objects (which was reported by other researchers as well).However,data augmentation (an artificial fourfold increase of the training data set) allowed to increase the number of images with partially occluded small firearms (which was only a small fraction of the 3140-image data set) to the point when the trained detector became efficient even for these images.

Fig.6.Illustration of partially occluded object detection capability: (a),(d) Pistol;(b),(e) Black rifle;(c),(f) Brown rifle.
While the trained YOLOv2 detector showed the good performance over all three objects studied in this research,two quick experiments were conducted to test the effect of data augmentation and performance of the detector using a different background.Since the brown rifle showed the worst AP among all objects,the imagery with the brown rifle was used in this experiment.As an example,Fig.7(a) shows the original image with the brown rifle and Fig.7(b)successful detection/classification result by the trained detector.

Fig.7.(a) Test image with a brown rifle;(b) successful detection/classification.
In the first experiment,the brown rifle was cropped from the original image,rotated and placed in different locations within the image.These ten modified images were then tested using the original trained detector.Eight of those ten were processed correctly resulting in a brown rifle being detected and correctly identified.The results of processing two of the eight images are illustrated in Fig.8(a)and 8(b).As seen from Fig.8(c)and 8(d),the rotated background within the cropped image apparently messed the overall pattern in two images preventing a rifle from being detected.
A similar test but repeated with the different background images.This time,out of ten artificially modified images,only three successful detections existed.Two of these three processed images are shown in Figs.9(a) and 9(b).As seen,even though a rifle was detected (Fig.9(a)),it was incorrectly classified as a black rifle.Fig.9(c) and 9(d) show two cases of failed detection.These experiments prove that data augmentation does lead to a better performance,however,background may play a major effect and therefore different types of background should be used while collecting imagery for CNN training.Alternatively,if background changes drastically,the detector needs to be retrained.

Fig.9.(a),(b) Successful,and (c),(d) unsuccessful detection with a different background.
6.Conclusions
This paper explored a feasibility of a concept of MOD system based on a small multirotor sUAS equipped with a high-resolution EO sensor.From the previous studies,it was known that object detection with sUAS could face challenges imposed by the small object size,changes in object aspect ratio and image scale,motion blur and occlusion.Hence,the main goal of this study was to see if the current technological and algorithmic levels can support detection and classification of small firearms left/lost at the battlefield/training area.The total of 3140 images of three different shape/size/color small firearms were collected to train an artificial convolutional neural network.A YOLOv2 model (ResNet-50 backbone network)was determined as being the most effective one for small firearms detection and classification.Data augmentation was applied to improve overall performance of the proposed system.The trained network demonstrated the very good results featuring a mean value of average precision of 0.97(even more,0.98,for the good contrast objects regardless of their size,and slightly less,0.94,for a lower contrast object).Good performance was demonstrated even for the partially occluded objects.A high probability of correct detection/classification proves that such a system can be developed,prototyped and tested in a realistic operational environment which will be the direction of a follow-up research.Another direction of research is to further explore different ways of augmenting existing(limited)data sets by applying various rendering effects ([13]) and varying background complexity.Also,it will be interesting to quantify how the shape,size,and orientation of BBs can affect the performance of detectors[14].Finally,there are other critical research directions of MOD systems with sUAS such as realtime implementation [40] and utilization of sUAS swarming for mission acceleration [41].
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
The authors would like to thank Maj.Seungwan Cho and NPS Base Police LT Supervisor Edward Macias for designing an operational scenario,executing it,and collecting imagery for this study.Maj.Cho has also developed the original algorithms to condition and train the DL model.The authors are also thankful to the Office of Naval Research for supporting this effort through the Consortium for Robotics and Unmanned Systems Education and Research,as well as the Engineer and Scientist Exchange Program of the U.S.Navy International Programs Office for enabling a fruitful collaboration between KNDU and NPS.
杂志排行

Defence Technology的其它文章
- Interaction of water droplets with pyrolyzing coal particles and tablets
- Multifunctional characteristics of 3D printed polymer nanocomposites under monotonic and cyclic compression
- Modelling and predicting the dynamic response of an axially graded viscoelastic core sandwich beam
- Development of bimetallic spinel catalysts for low-temperature decomposition of ammonium dinitramide monopropellants
- Thrust characteristics of nano-carbon/Al/oxygenated salt nanothermites for micro-energetic applications
- Ballistic response of skin simulant against fragment simulating projectiles