基于改进Vision Transformer的光伏电池缺陷识别研究
2023-12-27吕潇涵
吕潇涵
(青岛科技大学,山东 青岛 266000)
光伏电池的基本成分是晶体硅,硅片到电池片是光伏电池生产的最重要流程之一。由于当前技术水平的限制以及硅片的材料特点的制约,易造成光伏电池片出现划痕、缺角、拼接缝隙过大等缺陷。这些缺陷不仅会大大降低光伏电池片的太阳能转换效率,还会影响其使用寿命[1]。因此,在生产过程中快速识别出缺损电池片是一个重要步骤[2]-[3]。
目前,太阳能电池板缺陷识别方法主要分为人工目视识别、物理识别[4]和机器视觉识别三种[5]-[6]。其中,人工目视识别对判别员本身的工作经验和技术水平要求较高,且不具备实时性。物理识别方法主要有声波、激光、可见光等,代价较高。基于机器学习和计算机视觉的太阳能电池板识别方法更加方便、快捷和经济,以实时性、精确性等优势成为太阳能电池板检测识别发展的主要方向。
最初的基于计算机视觉方法的缺陷识别主要依据人工设计的特征进行识别,如尺度不变特征变换[7]、方向梯度直方图[8]等。但是这种手工设计的特征具有很大的局限性,让分类模型自己学习特征无疑是一种更好的选择。随着以卷积神经网络(Convolutional Neural Network,CNN)为代表的深度学习的兴起,基于不同网络架构的光伏电池片缺陷识别和检测方法成为学者研究的主流,如对抗生成网络[9],CNN[10][11]等。近年来,以Transformer为代表的基于注意力机制的识别模型无论是在识别速度还是检测精度上,均向CNN发起了挑战,基于视觉Transformer(Vision Transformer,ViT)的各种模型在很多图像识别领域获得了目前技术水平(SOTA)的性能表现。但是由于Transformer本质上学习的是序列的关联信息,无法像CNN能够感知图像的全局,因此如何同时利用CNN的全局感知能力和Transformer的强大逻辑关联能力还有待进一步研究,并且Transformer的位置编码需要人工设计模型,存在一定程度的主观性。
为此,提出了一种基于CNN和多尺度视觉注意力机制(CNN Based Scaled ViT, CSViT)的光伏电池缺陷检测方法。首先,基于残差网络设计了一个包含12个卷积层的特征提取网络,然后利用特征金字塔网络,融合三个尺度的浅层和深层特征,并对各个尺度的输出进行分割和池化,作为ViT的信息编码输入;其次,对于每个输入,设计了一个分支卷积模块以实现位置自编码;最后,信息编码和位置编码被同时作为Transformer编码器的输入。在公共的太阳能电池板缺陷数据集上的实验结果表明,CSViT在不增加计算量的情况下,提升了性能。
1 卷积神经网络与Transformer
1.1 卷积神经网络
传统意义上的全连接神经网络模型,由于每层之间的每个神经元均和上一层的所有神经元相连,因此参数量异常庞大,容易过拟合,并且sigmoid函数的收敛性造成梯度消失,无法训练较深的网络模型。而CNN通过卷积核的权值共享,大大降低了网络参数,减小了网络训练的难度以及对内存的需求。公认的第一个卷积神经网络模型LeNet-5被LeCun用于手写字符识别中,LeNet-5包含3个卷积层、2个池化层和1个全连接层,虽然结构简单,却定义了CNN的基本结构,当前流行的CNN模型基本遵循卷积-池化来搭建。但是,以支持向量机(Support Vector Machine,SVM)为代表的统计学习理论依靠坚实的数学基础以及在小样本上优秀的学习能力,在当时迅速成为学者追崇的焦点。
经过漫长的沉寂,从LeNet-5改进得到的AlexNet依靠多GPU并行、ReLU激活函数等众多的新特性,在当年的ImageNet大赛上取得了绝对优势,由此掀开了以CNN为代表的深度学习热潮。接下来的数年内,ImageNet的Top-5和Top-1,几乎各参赛组的主流方法均是基于CNN网络设计而来的,网络深度由最开始的8层增加到100多层,并且网络宽度也在不断增加。目前,CNN在朝着兼顾速度与精度的轻量化方向发展,例如MobileNet和EfficientNet等,成为当前在计算机视觉领域占有统治地位的学习模型。CNN与传统神经网络的最大区别就是基于卷积核的权值共享与基于池化的特征抽象,具体介绍如下。
(1)卷积

(1)
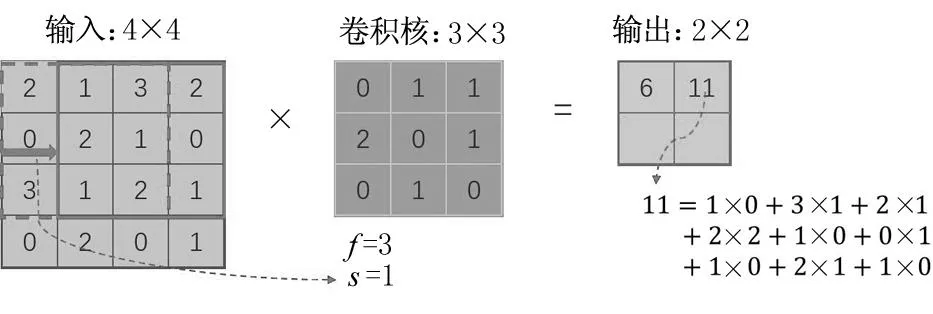
图1 卷积核计算过程
卷积操作涉及的超参数有卷积核(特征图)数量、滑动步长、边界填充等。边界填充的目的是在卷积计算时,能够提取图像的边沿信息。一般,为了能够提取图像不同类型的抽象信息,单个卷积层会使用多个卷积核,得到多个输出。
(2)池化
池化就是提取输入中某个区域的主要信息,同时也可以对出入进行降纬。池化一般可以分为平均池化和最大池化。平均池化是将某一区域的输入取平均值作为输出,而最大池化是将取某区域的最大值作为输出。具体过程如图2所示。
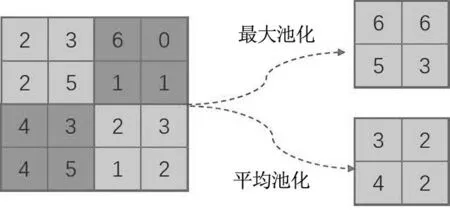
图2 池化计算过程
除了卷积和池化之外,以ReLU为代表的非线性激活函数缓解了神经网络训练过程中的梯度消失问题,BatchNormalization和Dropout降低了模型的过拟合,加快了训练速度,均称为CNN网络架构的不可或缺的组件。
1.2 视觉Transformer
注意力机制(Attention Mechanism)是用于对不同位置信息进行建模的一套方法,已有的基于注意力机制的方法在机器翻译、语音识别等任务中得到了广泛的研究。Transformer是Google团队在2017年提出的一种关于自然语言处理的经典模型,其结合了自注意力(Self-attention)机制,并且没有采用循环神经网络(Recurrent Neural Network, RNN)的顺序结构,使得模型可以并行化训练,能够捕捉全局信息,在当年自然语言处理的相关竞赛上取得了SOTA的结果。视觉Transformer是Transformer在图像分类任务中的开山之作,ViT采用多层Transformer架构完成特征提取过程,每层内部均使用自注意力作为特征函数,并利用后层Tansformer对前层特征函数的输出进行特征细化,逐渐捕获到图像全局特征,该模型架构如图3所示。

图3 ViT结构图
ViT的整体结构可以分为4个部分:
(1)输入图像的序列化
由于Transformer的原始输入是序列向量,因此ViT首先将图像无重叠切割成相同大小的图像块。设输入X∈H×W×C为宽(W)和高(H)的C通道图像,首先将X切割成大小p×p的图像块。然后将每个图像块拉伸为p2×C的向量,最后利用变换矩阵将输入转换到特定的维度D。
(2)位置嵌入
ViT利用特定的位置编码函数,对每一个变换后的图像块特征向量注入位置信息。需要注意的是,因为是图像分类任务,除了图像的特征输入外,还添加了图像的类别信息以及对应的位置信息。
(3)Transformer编码
信息的编码过程是通过堆叠多个TransformerEncoder来实现的,Encoder的具体结构如图3右侧所示,包含1个Multi-head Self-attention模块,1个Multi-layer Perceptron模块,上面两个模块之后分别连接1个层归一化单元(Layer Norm)。
(4)多层感知机(Multilayer Perceptron,MLP)
MLP Head 是最终用于分类的层结构,由全连接层和激活函数组成。ViT虽然取得了比较好的识别效果,但是将图像分割会一定程度上破坏图像的整体信息,且图片进行分patch操作后,只有在每个patch内部有信息交互,而patch和patch之间,只有在最后的MLP Head层才有交互,patch之间的信息交互太少。另一方面,位置编码方式存在太大的人为经验因素。
2 基于改进ViT模型的光伏电池片缺陷检测模型
为了缓解图像分割造成的整体或区域信息破坏,以及克服位置编码人工设置随机性大问题,本节设计了一个基于多尺度CNN和ViT的光伏电池缺陷识别模型CSViT,模型包括四个模块,具体结构如图4所示,下面对不同模块分别进行介绍。

图4 CSViT结构图
2.1 特征提取网络设计
特征提取网络由一个卷积层和多个残差网络构成,模型结构与YOLOv3类似。与YOLOv3在横向堆叠多个残差单元,以提升骨干网络的特征提取能力不同,CSViT并没有在同一层堆叠多个残差单元以加深网络宽度,这是因为YOLOv3的特征提取过程几乎全部依靠骨干网络,而CSViT在骨干网络阶段主要是获得不同尺度的特征图,特征学习在ViT阶段同样能够实现。特征提取网络的具体结构如表1所示。
2.2 基于FPN的多尺度特征
FPN(Feature Pyramid Network)最初在目标检测中被提取,主要是为了获得不同尺度的特征图,进而实现在不同尺度特征图上的目标检测,这样做的好处是粗粒度特征图主要包含输入的全局信息,方便大目标的检测,反之细粒度特征图上包含图像更多的局部信息,有利于对小目标的检测。ViT中将原始输入图像进行分割裁剪,因此无法获得图像的整体或者区域信息。为此,CSViT借助FPN的思想,通过不同尺度特征图作为Transformer的输入,既可以通过深层特征图学习图像全局信息,又可以通过浅层特征获取图像细节。
CSViT中利用FPN的思想,将输入图像进行了三次降采样,分别是在16倍降采样、8倍降采样、4倍降采样,获得三种尺度特征图,大小分别是76×76、38×38、19×19(输入图像大小为304×304),如图5所示。网络越深,学习到的特征表达效果越好。对于8倍降采样的特征图,如果只使用8倍降采样后的特征进行识别,只是获取了输入图像的浅层特征,为此通过上采样把16倍降采样得到的特征图的大小提升一倍,与8倍降采样后的特征图进行拼接。同理,对8倍降采样的特征进行步长为2的上采样并与4倍采样特征图拼接,这样每张特征图同时获得了深层与浅层特征。
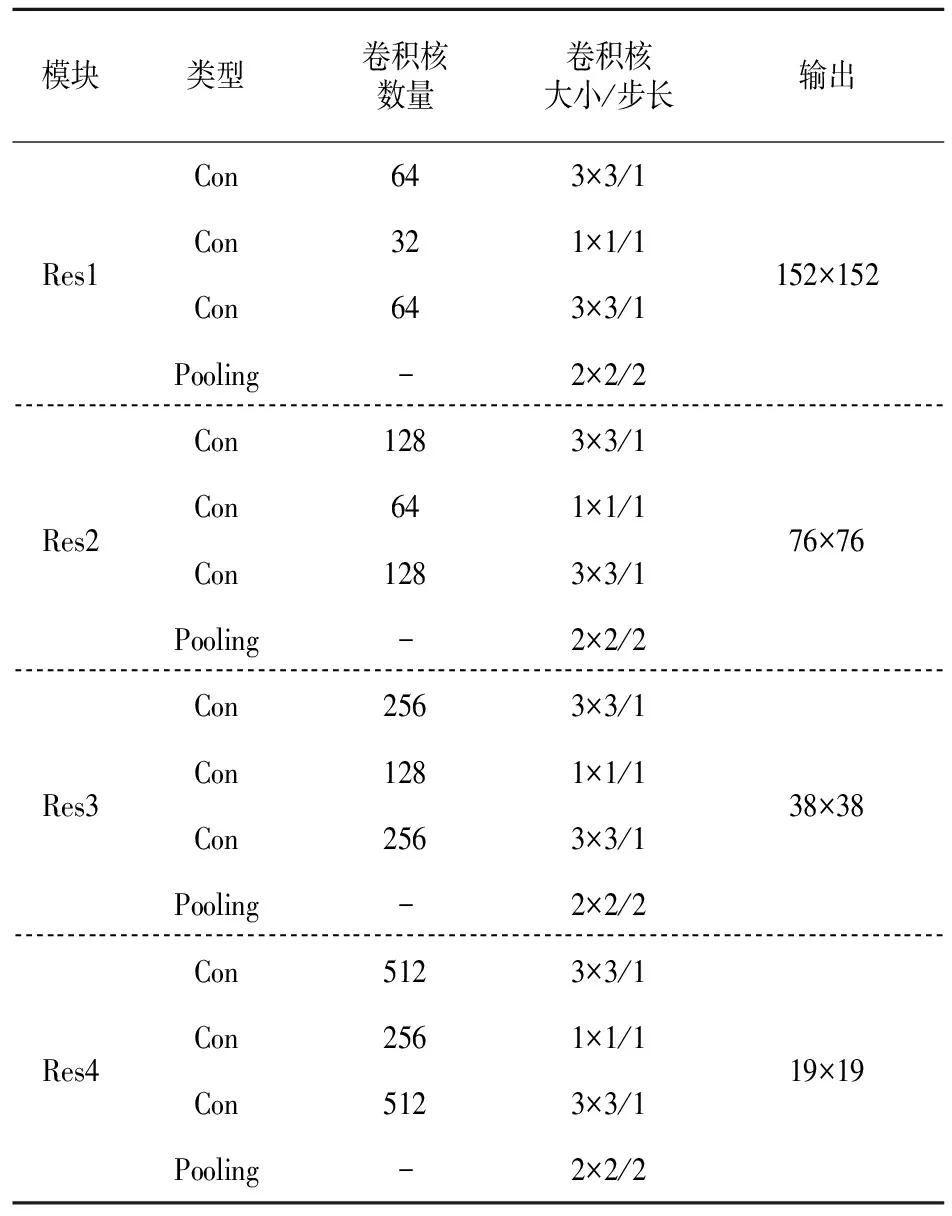
表1 特征提取网各层参数
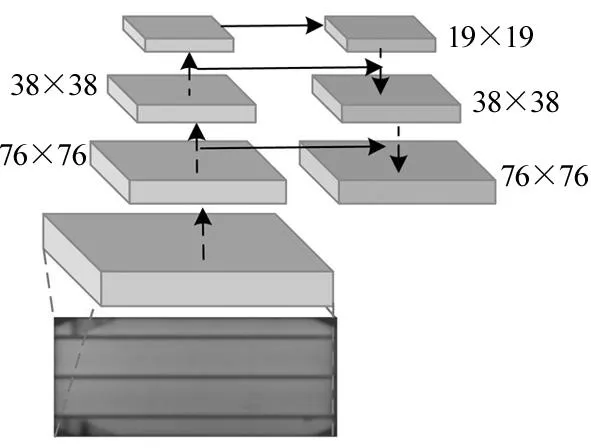
图5 CSViT中FPN结构示意图
2.3 分割与位置编码

由此可以得到总的信息输入个数为:
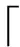
(2)

需要特别说明的是,在ViT中,同样将类别信息作为Transformer的输入。但是CSViT通过ReP学习类别信息的位置编码,显然是不合理的。为此,不管p的取值为多大,在最小特征图上,均会进行一个全局最大池化操作,最为图像的整体抽象输入信息,并同时对该信息利用ReP进行位置编码。
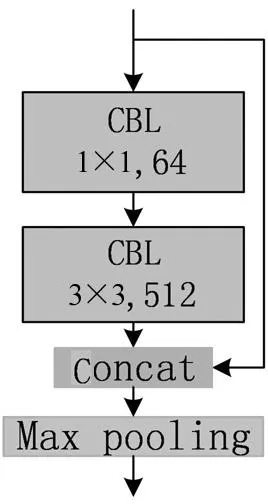
图6 位置编码分支结构
2.4 ViT
获得第三部分的信息输入和位置编码后,就可以利用Transformer编码器进行编码,通过循环L次进行多头注意力机制MSA、前馈神经网络MLP,并且在操作之前都要经过 Layer Norm(LN),最后做分类任务。具体过程为:
z0=[X0,X1,X2,…,XNx]+Epos,Epos∈(1+Nx)×C
(3)
(4)
(5)
(6)
需要说明的是,相较于ViT,式(3)中利用全局最大池化得到的X0替代类别编码。此外,由于在输入编码器前,已经通过CNN进行了特征提取,所以在式(3)中省去了线性变换操作。
本文模型的流程图如图7所示。
图7 模型流程图
3 实验结果与分析
3.1 实验数据
实验数据为开源的ELPV数据集,包含2624张光伏电池正常或缺陷图像,每张图像均为大小均为300×300像素,像素值范围0-255,所有图像均是从44个不同退化程度的太阳能电池板采用电致发光(Electro Luminescence,EL)技术得到,所有的图像都按照尺寸和视角进行了标准化处理。此外,在提取太阳能电池图像之前,所有的由捕捉EL图像的相机镜头引起的任何失真均被消除。不同模块类型的正常与缺陷图像如图8所示。
每个图像均有领域专家标注完成,注释信息包含两方面的内容:提取图像的太阳能模块类型(单晶或多晶);判定为缺陷的概率值(0, 1/3,2/3 或1)。所有的缺陷分为内在和外在缺陷,这些缺陷均会造成电池性能的下降。图9给出了不同模块类型和不同缺陷程度的图像数目的统计结果。从图中可以看出,缺陷程度存在明显的不均衡性。

图8 ELPV数据集样本示例
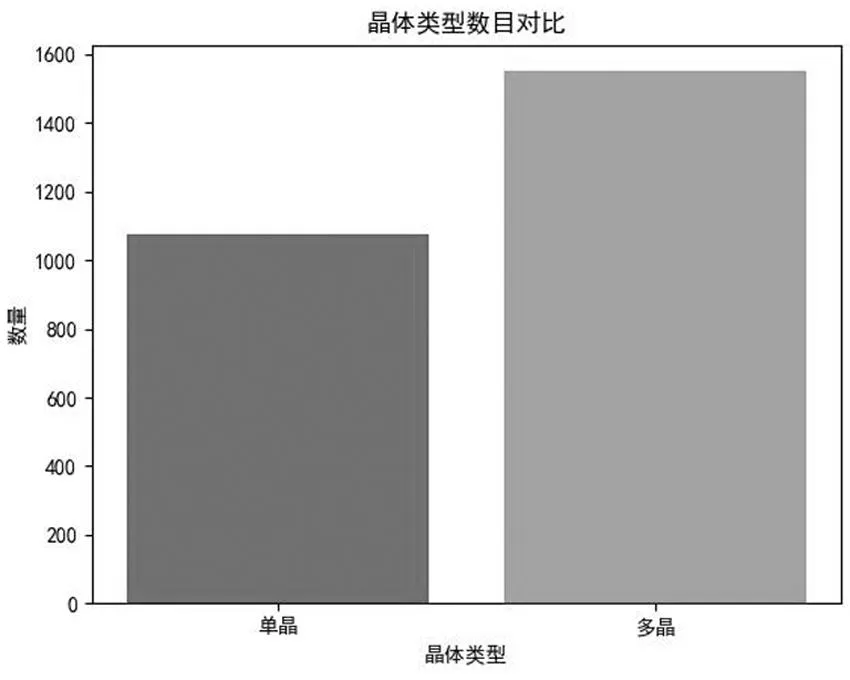
图9 不同缺陷程度(上)和不同模块类型(下)图像数目统计结果
3.2 数据预处理
所有的图像均被归一化至[0,1],训练样本和测试样本按照7∶3进行随机划分,得到1836张训练图像和788张测试图像。
对于每张训练图像,分别执行水平翻转和随机旋转进行增强。由于训练和测试图像均为固定像素大小,且拍摄角度一致,因此旋转角度固定为180°,且未采用图像裁剪进行增强,最后得到1836×3张训练图像数据。
由于本文主要针对的是分类任务,因此强制将缺陷概率标签进行了转换,即将1/3概率强制转换为0,将2/3概率转换为1。
3.3 实验设置
利用ViT的三种不同模型作为对比试验,分别为ViT-Base,ViT-Large,ViT-Huge,以上三种模型的配置与原文相同。
对于CSViT,分别取p=3,12,19三种模型,分别记为CSViT-3,CSViT-12,CSViT-19,除了p值外,三种模型其余部分均相同。此外,为了检验CSViT模型中的骨干网络与整个模型的性能对比,同样将骨干网络作为对比模型,记为Res-12(骨干网络包含12卷积层),训练阶段,Res-12直接在训练集上训练100个epoch,然后移植到CSViT中,重新在整个训练集上微调,所有模型中的ViT组件均来自官方预训练模型。
实验系统为Windows 10, Intel Corei7-9750H CPU(2.60 GHz),32 GB内存,Quadro T2000显卡(显卡内存16 GB),实验软件平台为Pycharm,语言为Python3.7.8,所有模型使用的深度一致。
3.4 实验结果
(1)收敛速度对比
图9给出了7中模型训练过程中的收敛曲线。从图中可以看出,Res-12由于模型比较简单,收敛速度较快,但是训练误差同样是最大的。6种ViT模型的收敛速度差距不大,但是仍然可以看出,CSViT-3的收敛速度略微块,由此可以得出,基于预训练Res-12和FPN的网络能够提取出输入的有效特征,进而加快了模型后一部分ViT的收敛速度。
(2)准确率对比
选择准确率 (Accuracy)、召回率(Recall)和精确率(Precision)三个指标评价模型性能。设缺陷图像/单晶正确识别表示为TP,缺陷图像/单晶错误识别表示为FP,正常图像/多晶正确识别表示为TN,正常图像/多晶错误识别表示为FN,则三个指标的计算如下:
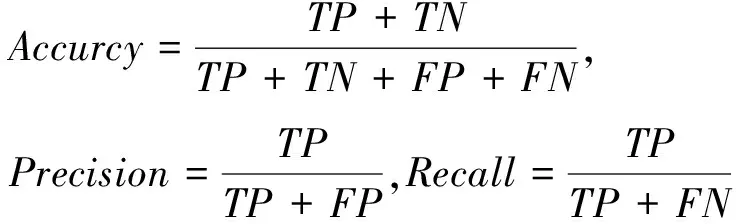
(7)
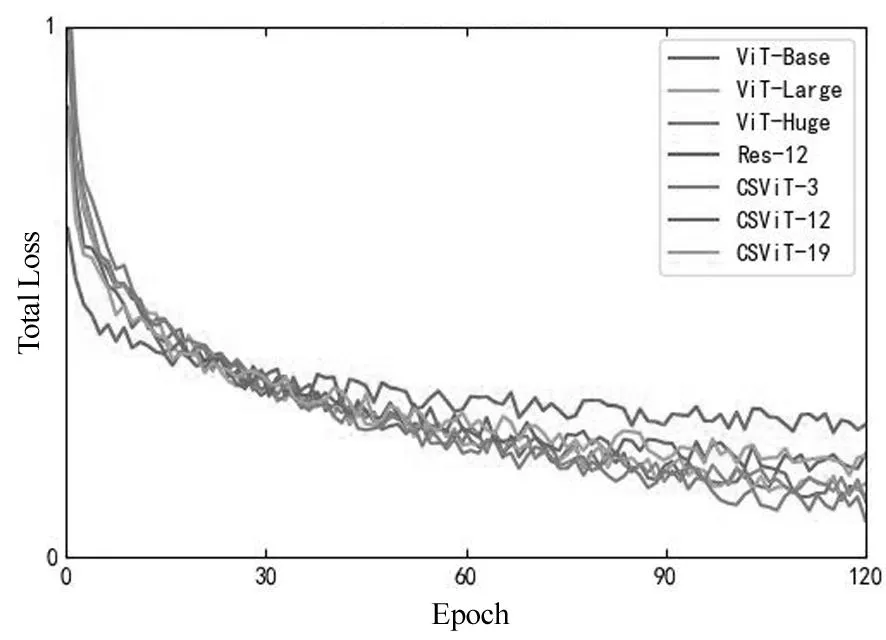
图9 不同方法的训练过程中损失函数收敛曲线图
表2给出了不同方法对于电池片类型的分类结果。从表中可以看出,Res-12的准确率最低,这主要是因为Res-12仅有12层卷积网络,与其他模型相比,结构比较简单。ViT系列的方法中,ViT-Huge性能最好,紧接着是ViT-Large,表明更多的编码模块能够提取更加抽象有效的特征。CSViT系列方法中,CSViT-3模型准确度要略高于ViT-Base,充分说明了CSViT中特征提取网络以及位置编码策略的有效性。但是随着p值的增大,CSViT的性能下降明显,这主要是因为较大的p值导致输入Transformer模型的编码信息迅速减少,尤其当p=19,只有1+4+16个信息向量,引起性能下降,这同样说明在Transformer之前,通过特征提取网络和位置编码策略得到的信息是有效的。表3给出了不同方法对电池片缺陷类型的分类结果,可以得出与表2相同的结论。

表2 不同模型对电池片类型识别结果对比
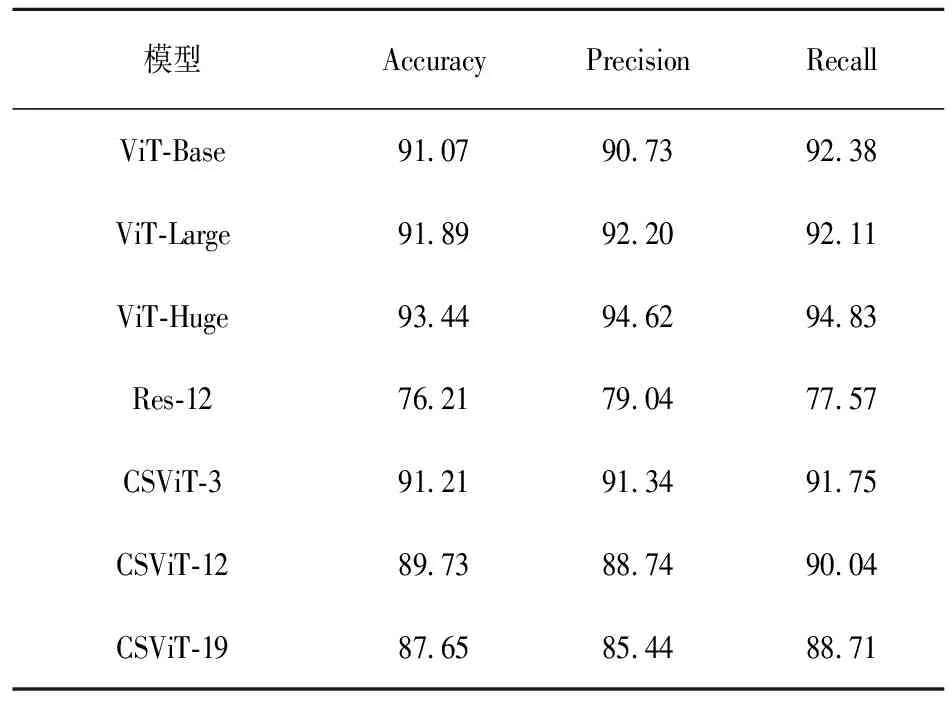
表3 不同模型对电池缺陷类型识别结果对比
(3)识别速度对比
图10给出了不同方法识别速度与精度的对比图。从图中可以看出,虽然ViT-Huge和ViT-Large两种方法的识别精度远远高于其他方法,但是两者的识别时间开销同样是最大的。CSViT-3的识别速度几乎和ViT-Base相同,但是经度略高于ViT-Base,说明CSViT的特征提取网络不仅能够很好地提取深层次特征信息和提供有效的位置编码,且不会带来比较大的时间开销,这主要是因为经过特征提取后输入encoder的信息数量比直接分割图像输入的信息数量要少得多。CSViT的另外两个模型虽然经度有所降低,但是速度上带来的优势更加明显。
以上结果表明,Res-12和基于FPN的多特征图虽然相比其他模型较为简单,但是依然能够从输入中提取出有效的特征。同样,CSViT的位置自编码机制能够成功学习不同输入之间的差异信息,证明了位置自编码策略的有效性。
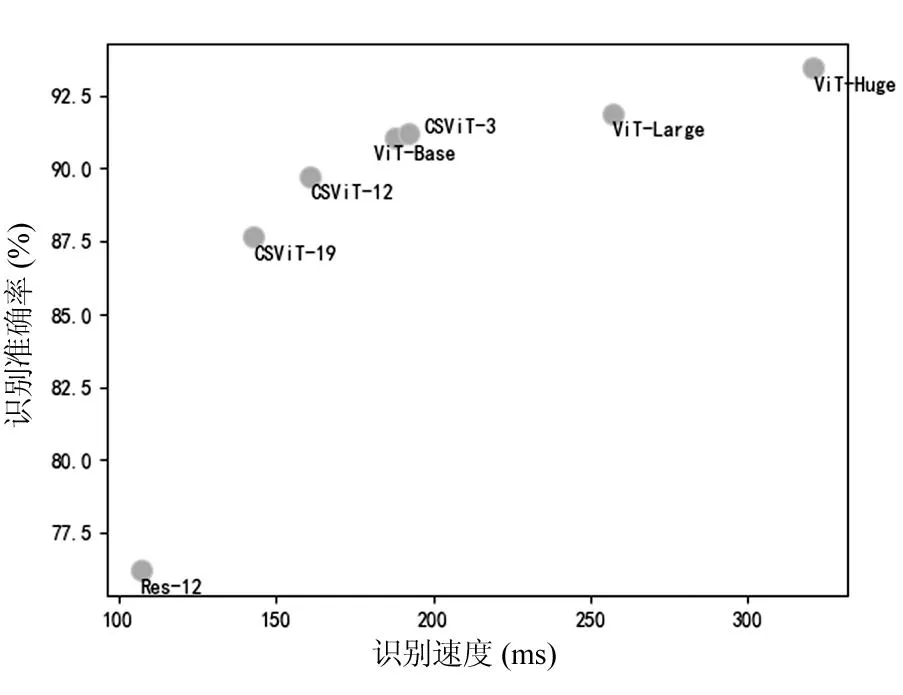
图10 不同方法缺陷识别速度与精度对比结果
4 结 论
设计了一个基于改进的ViT光伏电池片缺陷检测模型。首先基于残差模型设计了一个简单的特征提取网络Res-12,包含12个卷积层和4个最大池化层;然后利用特征金字塔网络FPN,对Res-12的三个不同下采样的特征层进行特征融合,提取不同层次的抽象信息;接着对FPN的输出按照ViT的输入分割策略进行裁剪和压缩,为ViT提供多尺度输入信息的,避免了图像分割造成ViT无法感知输入的全局信息的缺陷;此外设计了位置自编码分支网络,避免了手动设计位置编码模型的随机性。在公共数据集上的结果表明,该模型能够提升训练收敛速度,在不明显增加计算量的情况下,提升了识别精度,证明了模型的有效性。
