改进YOLOV5目标检测模型的实时抽烟检测方法
2023-12-27周翔宇曲喜悦许杰倪文瀚
周翔宇,曲喜悦,许杰,倪文瀚
(1.华北水利水电大学,河南 郑州 450045;2.哈尔滨工业大学,黑龙江 哈尔滨 150001)
在公共场所以及一些特定的禁烟场所抽烟具有很大的危害,传统的抽烟检测方法主要依靠烟雾警报以及人力监测,但烟雾警报主要应用在较小的室内封闭空间,且存在较高的误判性,如对各种喷雾型产品的误判等,不易针对抽烟行为进行单一监测;人力监测则是一种成本较高的方式,且适用场所十分有限。
目前,基于机器视觉的目标检测已在很多领域取得显著的成果[1-3],但在抽烟检测方面的相关研究较少。当前主流的目标检测网络对于小目标(如香烟)的识别具有一定局限性[4],追求针对小目标检测的精度,难免要加深网络的结构,导致整体模型参数量过大,速度下降,不利于部署在实际应用场景中成本较低的终端设备;若反之追求检测速度,则很容易导致精度的大量丢失,无法满足实际需求。
针对以上问题,本文基于YOLOV5网络进行改进,将颈部网络的FPN+PAN结构改为BiFPN结构,增强相同网络层之间的特征信息融合与不同网络层之间的特征信息传递。实验结果表明,改进后的YOLOV5网络在抽烟检测数据集上的检测精度更高,且检测速度满足实际场景应用需求。
1 改进YOLOV5网络
1.1 YOLOV5网络
YOLO[5-7]系列算法属于单阶段的目标检测算法,目前被广泛应用在各个领域。从YOLOV1到YOLOV7,近年来YOLO系列算法在不断地更新迭代,本文采用的YOLOV5相较于之前的版本,主要进行了以下几处优化:
1)Input:采用Mosaic数据增强,将4张图片通过随机缩放、裁剪、排布的方式拼接,丰富检测背景,对小目标检测有积极作用;同时采用了自适应anchor计算以及自适应图片缩放的计算方法,在一定程度上从数据处理方面提升了检测精度与检测速度。
2)BackBone:采用Focus结构,在一张图片上,每隔一个像素点取一个值,将一张图片分成4张,在不丢失信息的情况下将通道数扩充为原来的4倍,即由原来的RGB三通道变为12通道,较高地提升了检测速度。
3)Neck:采用FPN+PAN[8]结构。FPN和PAN分别采用自顶向下和自底向上的方式传递体征信息,进行特征融合,两者结合使得到的特征更加明显,进一步提升对不同尺度目标的检测能力。
4)Prediction:采用CIOU_loss作为回归损失函数。近些年提出的回归损失函数有IOU_loss, GIOU_loss、DIOU_loss以及YOLOV5采用的CIOU_loss[9]。回归损失函数在不断进行着完善, YOLOV5采用CIOU_loss作为回归损失函数,使得预测框的回归速度和精度均有提升。
1.2 加权双向特征金字塔网络
Tan[10]提出的加权双向特征金字塔网络(BiFPN)增强了相同网络层之间的特征信息融合与不同网络层之间的特征信息传递,能够使目标检测模型具有更高的精度。
YOLOV5网络中使用的FPN+PAN网络,在自顶向下的特征融合之后,引入了自底向上的路径,使得底层信息更容易传递到高层。BiFPN结构主要有以下几点改进:
1)删除部分节点,将FPN+PAN结构(图1)中P3和P7的中间节点删除,因其仅有一条输入边或没有进行特征融合,则认为其对融合不同特征的网络贡献更小,故将其删除,简化了双向网络。
2)在有中间节点的相同层增加跳跃连接,越过中间节点,将输入节点与输出节点进行一个连接,因为它们属于同一层,所以这样的操作并不会增加许多计算成本,却可以融合更多的特征。
3)将每个自顶向下和自底向上的双向路径看作一个特征网络层,且重复利用同一层,能够实现更高层次的特征融合。
4)加权特征融合,不同的输入特征具有不同的分辨率,常用的方法是将其调整为相同的分辨率,但其对输出特征的贡献却总是不同的,所以对每个输入特征增加一个权重,以少量的计算量为代价,获取更好的特征融合输出。权重公式如式(1)。
(1)
其中wi是可学习的权重,可以是向量(通道)、标量(特征)或多维张量(像素),在其后添加ReLU激活函数确保其大于零。∈是学习率。
将YOLOV5网络中的FPN+PAN结构替换为BiFPN结构,其结构如图1所示。
2 实验
2.1 模型评估参数
本实验将选用以下几个指标对网络模型进行评估:
1)AP: 由Recall作为横坐标、Precision作为纵坐标,模型的RP曲线图(召回率和准确率的关系曲线)所围成的面积,计算公式如式(2)。
(2)
式中,P(Precision)为准确率,R(Recall)为召回率,P(R)为准确率-召回率曲线函数,IoU为真实框与预测框的交并比,本实验采用AP0.5作为评估标准。
2)Params:网络模型参数量,代表网络模型的大小。
3)FLOPs:每秒浮点运算次数,代表网络模型的计算量。
4)FPS:每秒能处理的图像数量,代表网络模型的检测速度。
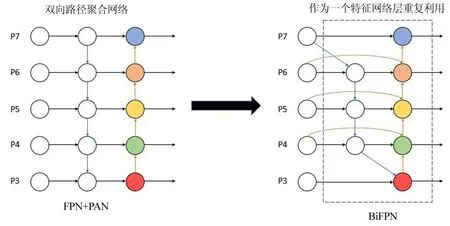
图1 使用BiFPN替换FPN+PAN示意图
2.2 数据集与实验设置
本实验使用的数据集为网上采集视频后,分帧提取图片,然后使用LabelImg软件进行数据标注得到的,大约1800张图片,多为影视剧场景中的手持抽烟镜头。数据集按8∶2划分训练集和验证集。
实验基于pytorch1.10环境;NVIDIA RTX A6000显卡一张。实验选取的优化器为随机梯度下降(SDG)算法,初始学习率为0.01,动量参数为0.937,训练批次大小设置为16,每个模型均训练200轮次。
2.3 实验结果与分析
本实验以YOLOV5-6.1版本作为Baseline,分别对YOLOV5-n、YOLOV5-s、YOLOV5-m、YOLOV5n-BiFPN和YOLOV5s-BiFPN这几个网络模型进行实验评估,实验结果如表1所示。将YOLOV5-s和YOLOV5s-BiFPN作对比,可以看出,替换为BiFPN的网络模型精确度明显提高,且网络模型参数量、计算量以及FPS几乎没有变化;再将YOLOV5n-BiFPN与YOLOV5s-BiFPN对比可知,s版本的网络模型精准度明显高于n版本,参数量与计算量仍满足部署在低成本终端设备的条件,且FPS仅下降3~4,完全满足实际应用场景中的实时性要求;再对比s与m版本的模型,发现m版本模型精度提升十分有限,且参数量与计算量大幅上升,已不适用于低成本终端设备的应用场景。故本实验最终选取YOLOV5s-BiFPN作为实时抽烟检测的算法模型。
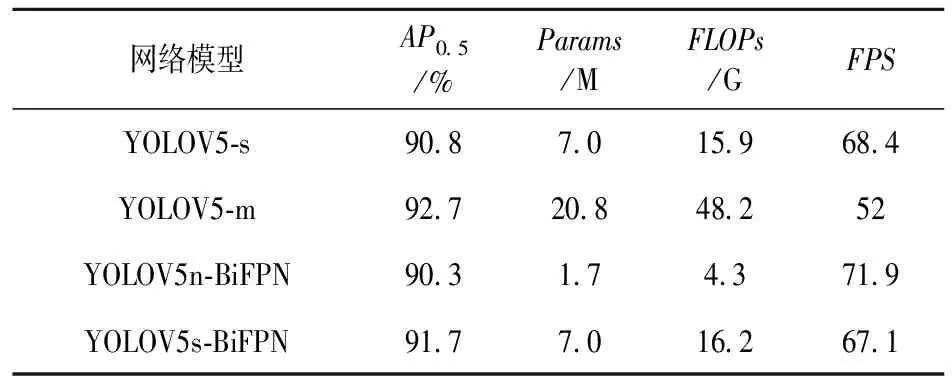
表1 各版本网络模型性能比较结果
2.4 模拟实验
在一般情况下,由于成本限制,实际应用场景中终端设备的计算能力比较低,因此选用100万像素的摄像头及NVIDIA GeForce MX150(2G)显卡进行模拟实验。模拟实验分别进行手持香烟特写镜头识别、正面抽烟识别以及侧面抽烟识别。实际效果如图2所示,可以看出,本文采用的方法针对抽烟检测具有良好的效果。
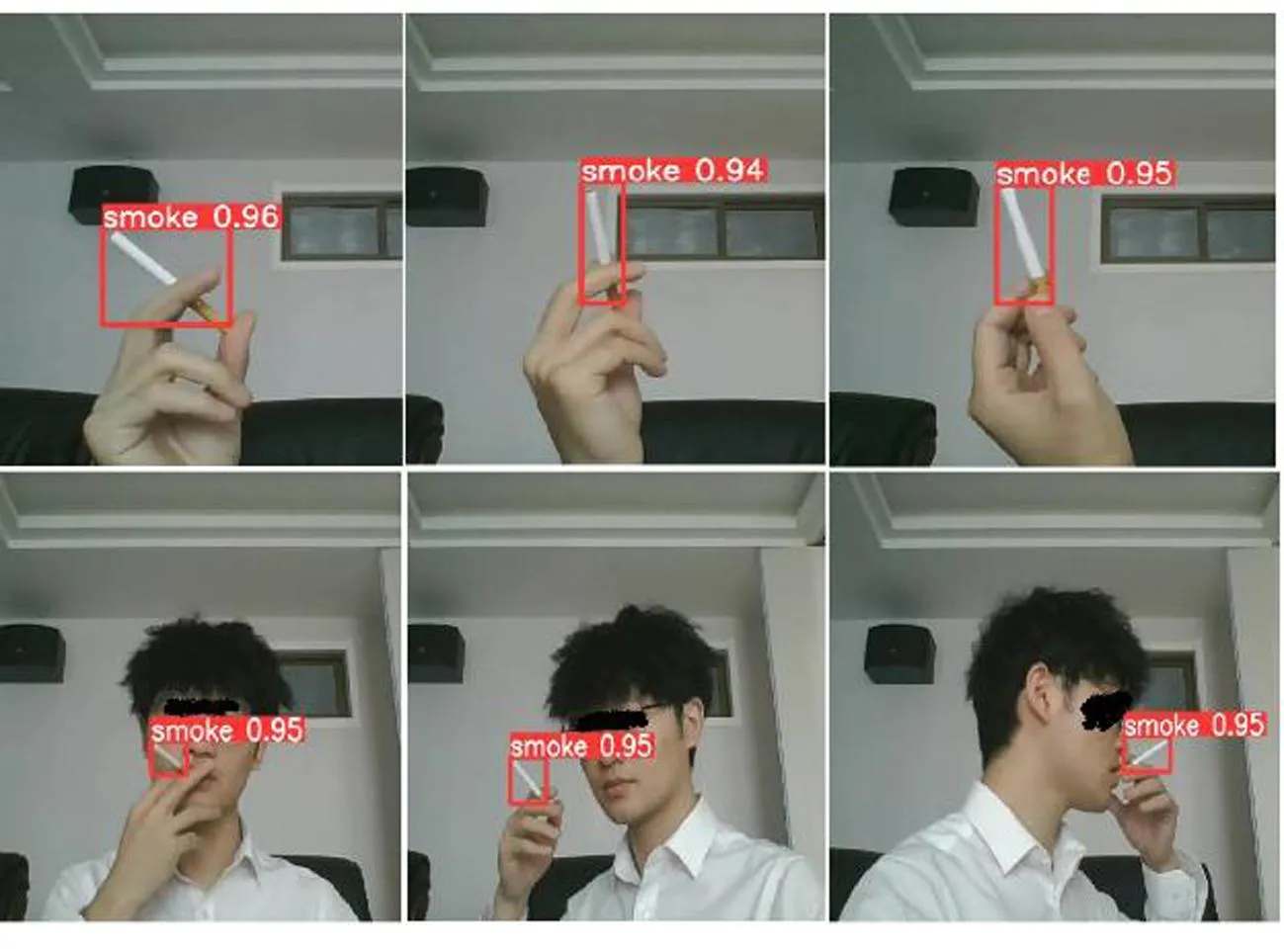
图2 模拟实际场景的抽烟检测效果
3 结 论
针对实际场景中抽烟检测困难的问题,提出了改进YOLOV5的模型应用在实时抽烟检测中的方法,将其中的FPN+PAN结构替换为BiFPN结构。实验表明,在几乎不增加模型大小以及计算量的情况下,本文方法提升了模型的检测精度,且满足部署在计算能力较低的终端设备上进行实时检测的条件。
小目标检测在现实场景中更容易受到背景噪声的影响,因此将来会继续对增加注意力机制等改进方案进行研究,进一步提升模型对小目标的检测能力。
