基于改进遗传算法的车门优化分析
2023-12-26张瑞乾
刘 锋,张瑞乾,2,陈 勇,2
(1.北京信息科技大学机电工程学院,北京 100192;2.北京电动车辆协同创新中心,北京 100192)
1 引言
目前为占领汽车市场,各大汽车厂商都在加快汽车更新换代的速度。而在更新换代的过程中每次都伴随着车身设计的改变。为了浓缩车身研发时间与成本,计算机辅助设计(CAE,Computer Assistance Engineering)被广泛运用到整车设计阶段。
随着计算机水平的进步,车身优化方法与原来也出现了很大不同。其设计方法与现代优化算法广泛结合起来。文献[1]通过增加车门内部防撞板厚度,同时采用高强度钢,提高车门耐撞性能,对车门进行优化。文献[2]使用正交试验设计方法对车门系统参数进行优化。文献[3]用有限元分析以及综合性能优化设计对某车型前门进行结构优化,提高疲劳寿命。文献[4]采用灵敏度分析对车门进行尺寸和拓扑优化。文献[5]采用部分因子设计对悬架系统进行优化。文献[6]使用拉丁超立方试验设计和构建Kriging模型对某车门进行多目标轻量化设计。文献[7]采用响应面法对某微型车车门进行模态分析与优化。文献[8]使用响应面法,径向基函数,以及Kriging模型对汽车耐撞性进行优化分析。文献[9]通过径向基函数和神经网络构建白车身优化近似模型以及侧面碰撞二阶逐次替换的自适应响应面模型,最后利用退火算法对目标车身进行了多目标优化。文献[10]根据最优拉丁试验设计方法对设计变量数据进行分析与抽样,利用移动最小二乘响应面法构建白车身多目标优化近似模型,最后利用多目标遗传优化算法对模型进行求解与优化。各种试验设计方法、近似模型以及优化算法被用到车身及部件优化过程中来,使得优化过程速度更快,优化的结果更为准确。相比原来的靠经验设计方法表现出很多的优越性和先进性。
以某还在分析阶段的车门为例,对车门进行有限元分析。为了尽量减少用料,满足性能,达到轻量化研究的目的。提出的研究方法为,采用哈默斯雷(Hammersley)抽样方法对车门部件进行抽样。然后采用Hyper Kriging完成拟合近似模型的建立。最后在Hyper Study中通过改进的遗传算法进行优化求解。对求解后的模型进行模态验证。
2 车门有限元建模及分析
进行有限元分析前,反复检查车门三维数模的正确与规范性。将车门薄板使用2D壳单元模拟。为了提高有限元仿真的精度与计算时间,设定网格的基本尺寸为8mm,尺寸标准为3mm≤8mm≤15mm。有限元模型建立完成后共有51801个2D 单元,网格分为CQUAD4单元和CTRIA3单元。其中三角形网格为2640个,占总数5.1%,符合建模要求。部件之间包边区域采用一排单元模拟,用RBE2模拟螺栓连接,Adhesives模拟粘胶连接,用Spot面板实现点焊,采用ACM类型3D单元完成二层焊和三层焊的模拟。
网格模型建立完成后在Hyper Mesh中对各部件赋予属性和材料主要为高强钢(密度ρs=7.9×103kg/m3、弹性模量Es=206800MPa、泊松比μs=0.3)。同时采用结构胶(密度ρG=1.1×103kg/m3、弹性模量EG=40MPa,泊松比μG=0.49)。模型建立完成后质量为16.22kg,其有限元模型,如图1所示。

图1 车门有限元模型Fig.1 Car Door Finite Element Model
3 总体目标优化数学模型
针对上述车门分析情况,对车门进行优化。提出的研究思路为在保证一阶弯曲模态和一阶扭转模态符合目标值的情况下,将车门部分零件厚度尺寸作为设计变量,提升内板局部模态,同时减轻车门质量。其目标优化数学模型如下:
式中:mass—车门质量;ti—优化部件厚度值;mi—变量板块质量;m0—非优化变量质量总和—第i部件的原始厚度;tmax、tmin—设计变量的上下限;ω1、ω2—一阶弯曲和一阶扭转模态值。
考虑到车门部件在设计优化阶段的复杂性,通过Altair Hyper Works软件进行优化。采用哈默斯雷实验设计方法对样本数据进行估计。并且采用Hyper Kriging模型构建车门优化近似模型。然后采用改进的遗传算法对质量、模态等性能参数目标进行优化求解。最后结果在满足车门模态的同时,追寻车门的轻量化设计。
4 哈默斯雷采样
目前针对车身部件优化的主要问题在于对车身优化部件的选取问题。因为车身部件众多,全部优化不仅会耗时费力,可能优化效果也得不到提高。随着现代抽样技术的发展,很多试验设计方案涌现出来。例如全因子、部分因子、中心复合、最优拉丁超立方以及哈默斯雷等试验设计方法对优化部件有多个设计变量时进行采样。这里针对模型表征和所用优化软件的特性,采取哈默斯雷采样评估方法对样本进行试验设计。
文献[11]介绍Hammersley抽样属于类蒙特卡洛方法的研究范畴。该方法基于Hammersley点,利用伪随机数值发生器在超立方体中均匀采样。其突出点在于可用较少的样本来提供可靠的输出统计估计值。并且它能在K维超立方体上获得良好的均匀分布,这是Hammersley抽样优于全因子、中心复合设计以及拉丁超立方等采样方法的特点。与拉丁超立方DOE(Design of Experiment)一样,哈默斯雷DOE在探索整个设计空间和创建精确响应的拟合函数方面特别有用。同时可以分别提供每个维度的良好一致性。为了拉丁超立方体DOE获得高质量的拟合函数,应该计算最小运行次数。为此哈默斯雷采样为N个设计生成n个设计变量值,如式(2)所示。
式中:N—设计数;n—变量数;P—设计指数;Ri—第i个n-1 素数,ϕR计算如下:
式中:pi—系数;p可以用基数R表示为:
本次优化根据系统默认在部件上采取了120个样本点进行统计分析。其中某部件的哈默斯雷采样结果,如图2所示。

图2 质量随某部件的Hammersley采样关系Fig.2 Hammersley Sampling Relationship Between Quality and a Component
进行Hammersley抽样试验设计的目的是确定车门哪些部件对输出目标响应影响最大。确定将有影响的部件尺寸变量设置在何值时使输出响应接近所设定的目标值。通过控制系统的不可控参量达到对输出响应影响最小的目的。使输出目标变化最小,最终用来搭建车门优化近似模型来替换计算量巨大的实际模型求解。
5 Hyper Kriging近似模型
对模型进行试验设计之后就是对优化构建近似模型。常用的近似模型方法有Kriging、最小二乘法(LSR)、人工神经网络(ANN)以及移动最小二乘法等近似模型。Altair Hyper Study 在Kriging 模型改进基础上,为用户提供了一种Hyper Kriging 模型近似方法,和其它近似方法一样,Hyper Kriging使用DOE模型点处采样点的响应值来构建近似模型。其响应值与自变量之间的关系,如式(6)所示。
式中:f(x)—未知的近似模型;D(x)—关于x的确定性函数,常用多项式表示;c(x)假设为高斯静态过程。
Kriging最初是在地质统计学领域发展起来的。他是由采矿工程师D.G.Krige发展起来的统计技术。同时也被称为计算机设计与分析(Design and Analysis of Computer Experiments,DACE)。
克里金法是依据协方差函数对随机过程进行空间建模和预测的回归算法,能给出最有线性无偏估计(Best Linear Unbiased Prediction,BLUP)。其协方差为:
克里金法基于Kriging方法构建近似模型,同时在工程问题的数值试验中可作为代理模型对有限的模拟结果进行插值。在曲线原有DOE采样点处的响应值产生一个插值模型。
Hyper Kriging方法是基于Kriging方法的Hyper Study近似模型构建方法。Hyper Kriging 试图通过残差趋近于0的精确采样点。由于没有关于拟合质量的相关信息,为了对Hyper Kriging拟合的质量进行一些诊断,在创建Hyper Kriging拟合模型时使用验证矩阵是非常重要的。使用Hyper Kriging模型中质量响应随某两个设计变量取值图,如图3所示。表示出Kriging模型经过采样点处的响应值,从而使近似模型结果更准确。

图3 质量响应与设计变量关系图Fig.3 Relationship Between Quality Response and Design Variables
通常为了对模型拟合质量进行评价,采用模型校正样本点增加拟合质量。近似模型经过所有的初始样本点,但有可能不会经过校正样本点。
构建近似模型后采取优化算法对优化模型进行计算。经过近似模型的适应性和优化算法的遴选,此处使用改进的遗传算法对其进行计算。
6 改进遗传算法(Genetic Method,GA)
遗传算法是一种基于进化论的机器学习技术。遗传算法区别于传统优化方法在于其是一种种群进化技术。首先选择具有高适应性的个体。根据选定的初始个体,进行遗传操作算子衍生成为下一代,一代代子个体将与所选的另一类个体遵循一定变异率进行交叉和变异。所繁衍的个体成为下一代的候选解,这一过程将被重复很多代,以使总体不断演化,种群不断优化,从而获得优化问题的最佳解。
6.1 改进遗传算法的优越性
这里所使用的遗传算法是基于Hyper Study优化程序改进的一种遗传算法。该算法具有以下特点:
(1)将种群中的一小部分精英种群直接保存至下一代。
(2)根据所定义的优化问题自动确定种群大小,如果(种群规模,Genetic Method Population Size)GAPOPS=0,则根据以下函数计算种群大小,式中N是设计变量的数量。
(3)提供三类交叉操作:单点交叉,两点交叉和均匀交叉。
(4)采用指定子种群大小的竞赛选择,从随机选取的子种群中选出最优个体。
(5)在任一代中如果存在两个完全相同的个体,则用随机产生的新个体取代其中之一。
(6)以一定概率对个体进行变异同时可设置变异率。突变率范围一般在(0.1~0.6),数值越大,随机效应越大。因此GA 在全局范围内进行更多的探索。但这种趋同可能会更为缓慢。
(7)对于约束优化问题,采用外点罚函数将约束问题转化为无约束问题。将罚函数定义在可行域外部,这样在计算时只需考虑违反约束的设计。适应度函数定义如下:
(8)与其它优化方法相比,遗传算法没有明显的收敛特性。关于遗传算法收敛问题可以用允许运行最小迭代次数(Minimum Iterations,MINDES),m次迭代目标变化小于0.001来表示。数学模型表述为:
式中:f—目标值;k—当前迭代次数;m—全局搜索参数比例;cmax—最大违反约束;gmax—允许违反约束。
(9)用户可以通过最大迭代次数和种群数来控制计算量。数值越大,解的精度越高,找到最优解就需要更多的计算时间。
(10)除了最大迭代次数,Hyper study引入全局搜索水平来强化对收敛进程的控制。其基本原理为:越高的全局搜索水平有着相应的严谨的收敛准则,算法将使用更多的随机运算来搜索整个设计空间。设置全局搜索GAGLOB(Genetic Algorithm Global Search)值越大,得到全局最优解的概率就越大,但需要计算时间就越多。
6.2 改进遗传算法过程
遗传算法从设计群体的创造开始。然后根据这些设计的适合度进行排名。通过违反约束和目标函数值的函数来进行计算评估一个设计的适应度。然后通过遗传算子的应用,典型的交叉和变异,复制选定的设计变量。从这个过程中产生的个体成为下一代成员。这个过程重复很多代,直到种群进化收敛到最优解为止。其求解流程,如图4所示。

图4 遗传算法不同阶段的流程图Fig.4 Flow Chart of Different Stages of Genetic Algorithm
在遗传算法求解过程中满足以下条件时,遗传算法终止优化:(1)满足收敛条件;(2)到达最大迭代次数;(3)分析失败。
6.3 结果分析
在使用改进遗传算法对车门优化过程中,通过近3000次新的种群进化。某部件遗传迭代求解结果,如图5所示。为质量随设计变量在遗传算法过程中的响应。
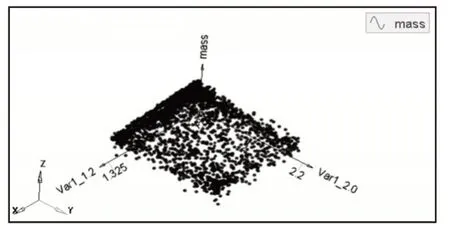
图5 质量响应Fig.5 Mass Response
经过上述设计变量的迭代结果,同时为将部件设计尺寸与汽车板件推荐公称厚度值一致,对其进行圆整结果,如表1所示。

表1 原车门与优化后设计变量对比Tab.1 Comparison of Original Door and Optimized Design Variables
从上述结果可以看出,所使用的改进的遗传算法比传统优化技术的先进在可以将该遗传算法归纳为探索性方法,可以在短时间内完成大量设计工作,同时种群设计可以并行运行,最后不表示其它算法的典型收敛性。
运用Hyper Works 对车门自由模态进行分析。其质量和一阶弯曲模态、一阶扭转模态等相关数值,如表2所示。根据企业的分析标准。其一阶弯曲模态和一阶扭转模态均大于目标值,符合要求。
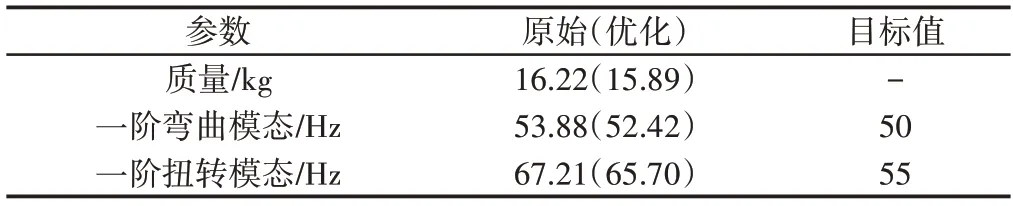
表2 优化前后质量、模态对比Tab.2 Quality and Modal Comparison Before and After Optimization
6.4 改进遗传算法总结
适合度值高的直接传给下一代,这是遗传算法保证解质量不下降的一个非常重要的策略。更大的种群意味着更多的个体将直接传递给下一代,所以新基因被引入的机会较小,可以提高收敛速度。缺点是过大的值可能导致过早收敛,同时根据生成随机数序列的方式控制运行的重复性。同时还应注意以下几点:(1)惩罚权重与惩罚乘数:罚权在适应度函数中的表述为外部罚函数。初始惩罚乘数在适应度函数的形式化为外部惩罚函数。随着迭代步骤的进行,惩罚乘数将逐渐增大。一般来说,值越大,迭代步骤越小,解就越可行;但值太大,可能导致解越差。(2)分布指数:实数编码遗传算法使用的分布索引。此参数控制子代个体接近或远离父代个体,增加这个值将导致后代个体更接近父代个体。(3)约束阈值:此参数用于约束值计算。一般来说,约束值被规范化为其边界值。一个例外是如果约束值的绝对界限值小于此参数,则约束值不会规范化。
7 总结
国内对车身工程设计阶段的方法已经由原来的靠经验设计转变到现在利用现代设计方法辅助车身工程设计阶段的过程。通过车身部件与现代设计优化算法相结合的理念对车门进行优化分析。与此同时也可以总结为以下几点。(1)Hammersley抽样能很好的解决车门等车身部件对设计变量在优化过程的选择。(2)Hyper Kriging近似模型的使用优越于其它近似模型在于它的准确性要高。(3)通过Hyper Study改进的遗传算法在优化设计过程中有很好的适应性,同时可以据此发展采用胡可-吉维斯法(Hooke-Jeeves Method)的混合算法和基于元模型的方法(Meta-Model Based Method)。(4)经过上述优化,车门质量减轻了0.33kg。同时其一阶弯曲和扭转模态没有多大变化。为车身及其部件优化提供新的设计方法和途径。
