基于情感可控文本生成的可解释推荐系统
2023-12-25卢香葵罗芳媛
邬 俊, 刘 林, 卢香葵, 罗芳媛
(1.北京交通大学计算机与信息技术学院,北京 100044;2.数字化学习技术集成与应用教育部工程研究中心,北京 100039;3.交通大数据与人工智能教育部重点实验室,北京 100044)
评论感知评分回归(review-aware rating regression, R3)是构建电商推荐系统的核心技术之一.该技术通过机器学习建立从文本评论到数值评分的统计推理模型,实现对用户信息需求的细粒度感知以及对商品受众群体的精准定位,是企业制定市场区隔与定向营销策略的重要依据,能够为管理者提供辅助决策支持[1].过去十余年里,学者们提出大量R3 方法,诸如早期基于主题模型(latent dirichle allocation, LDA)[2]与矩阵分解(matrix factorization, MF)[3]的浅层学习方法[4],以及当下以TextCNN[5]为基础同时结合各种注意力机制的深度学习方法[6-7].然而,这些方法仅把文本评论当作辅助信息,用以丰富用户和物品的特征表达,却忽视了其在增强推荐系统可解释性方面的潜在价值.
可解释推荐是提升用户对平台信任度和满意度的重要技术途径.伴随着神经计算语言模型的迅猛发展,基于文本生成的可解释推荐技术逐渐成为学术界和工业界共同关注的焦点.一种常见思路是采取注意力机制,从历史评论中挑选出对评分回归贡献较大的句子或单词[8-9].另一种思路是采取多任务学习机制,在评分预测的同时生成解释文本[10].尽管这些方法取得了一定成功,但未能充分考虑用户历史评论与当前评分回归任务之间的情感一致性,容易产生带有情感冲突的解释文本.例如,当前预测评分为2分时(表示用户对物品的不太满意),而解释文本中却出现了诸如“很喜欢,强烈推荐”等赞许性词汇.这种预测评分与解释文本之间的情感冲突会严重影响用户对推荐系统的信任度和满意度.
有鉴于此,提出一种基于情感可控文本生成的可解释推荐(emotion controlling text generation towards explainable R3,E2R3)框架,该框架由评分回归模型和解释生成模型串联而成.E2R3 主张根据评分回归结果甄选出与之具有一致性情感的历史评论,以此作为解释生成模型的输入语料,从而避免预测评分与生成文本之间发生情感冲突.同时,通过多任务学习设置,评分回归模型和解释生成模型可以相互影响,实现渐进式协同优化.四个真实电商数据集上的实验结果与案例分析表明,所提出E2R3方案在评分回归精度和解释文本生成质量两个方面均优于现有主流方法.
1 相关工作
本小节简要介绍评论感知评分回归和推荐解释文本生成两个研究领域的国内外研究现状,并对其存在问题及可能取得突破的方向进行重点剖析.
1.1 评论感知评分回归
评论感知评分回归任务自被提出以来就受到了广泛的关注,学者们在该领域进行了不同的尝试和探索.Ling等[11]提出将隐主题模型和矩阵分解技术结合的RMR 模型,将基于内容的推荐方法与协同过滤方法无缝结合;Zheng 等[12]从评论中学习用户和物品表示,并基于因子分解机模型提出DeepCoNN 模型;Chen 等[8]利用卷积神经网络(CNN)提取评论级特征,并通过注意力机制为不同评论赋予差异性权重,以学习在不同的用户-物品交互下评论重要性等级.类似地,Dong 等[6]提出的AHN 模型,Luo 等[7]提出的NRCMA 模型分别提出使用分层式注意力及跨模态式注意力机制实现有效的评分回归.Pugoy 等提出的BENEFICT[9]和ESCOFILT[13]均使用BERT 模型对评论文本编码,分别通过自注意力机制和K-均值聚类算法获取评论句子级重要性,并结合深度神经网络预测推荐评分.虽然上述方法在评论感知评分回归领域取得了不错的效果,但尚未充分探究评论文本在提高推荐系统可解释性方面所蕴含的潜在价值.
1.2 推荐解释文本生成
可解释推荐旨在为用户提供推荐结果的同时,提供有效的推荐解释,以提高推荐置信度和用户满意度.文本作为最直接的语义媒介,目前是推荐解释的主要形式.因此,实现自动化的推荐解释文本生成成为目前学者的研究重点.主流的方法有抽取式和生成式两种方式.Chen等[8]提出的NARRE 方法和Pugoy等[9]提出的BENEFICT 方法分别使用CNN 和BERT 编码评论文本,之后利用注意力机制从历史评论中抽取高权重的评论级或句子级内容作为推荐解释,在不引入额外的生成模块的同时提供推荐解释.但抽取式方法难以生成新颖的文本,抽取文本内容往往过于相似.与之相对的生成式方法是通过引入语言模型进行文本生成,如Dong 等[14]提出一种注意力增强的长短期记忆网络(LSTM),实现了“属性到序列”的文本生成方式;Li等提出的NRT 方法[15]和NETE 方法[16]分别使用门控循环网络(GRU)和门控融合循环网络(GFRU)将评分结果和评论文本进行联合编码以生成推荐解释;Chen等[10]提出的CAML 模型利用互注意力机制,在多任务框架下联合学习评分回归和解释生成任务,以探究两个任务的协同促进能力;Hada等[17]提出一个插件式解释生成模块ReXPlug,高效地实现了在大语言模型上的可控文本生成.尽管上述工作已经可以生成流利可读的解释文本,但是它们在考虑回归评分与生成文本之间的情感一致性上存在局限.
2 基于情感敏感摘要的可解释推荐
本节将详细介绍所提出的E2R3模型.具体而言,首先定义了可解释的评论感知评分回归问题以及相关符号系统,然后阐述模型构成和训练方式.
2.1 问题定义
给定推荐系统中的用户集合U和物品集合I,表示用户和物品之间的交互训练集,其中N表示训练集大小.每一个元素(u,i,rui,eui)∈X 记录了用户u对物品i的评分rui和评论(解释)eui.此外,在评论感知推荐中还需要考虑用户的历史评论,令表示用户u的历史评论列表,表示用户给出的对应评分列表.类似的,物品i收到的历史评论和对应评分列表分别定义为
给定一对用户和物品u∈U,i∈I,可解释的评论感知推荐目标是预测用户对物品的偏好评分,并生成相应的解释文本,这分别对应着评分回归任务和解释生成任务.
2.2 模型架构
E2R3 模型整体架构如图1 所示,主要由评分预测器和解释生成器两部分构成,分别对应着问题定义中的两个任务.其中评分预测器以用户u和物品i以及它们的历史评论列表Vu,Vi作为输入,输出用户对物品的预测评分;解释生成器基于预测评分,利用原始语料库数据生成情感敏感评论摘要作为解释文本,且生成的解释文本具有一定表达差异性,能够有效克服过度同质化问题.下面具体介绍这两个组成部分.
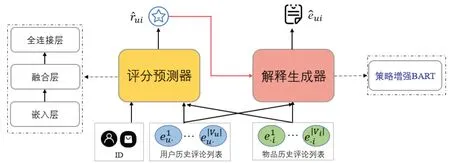
图1 E2R3模型架构Fig.1 Model architecture of E2R3
2.2.1 评分预测器
评分预测器模块如图1 左半部分所示,由嵌入层,融合层和全连接层组成.首先,使用深度神经编码器对给定用户和物品的历史评论进行编码,提取有效的语义信息.然后,使用融合层将用户和物品的评论嵌入和ID嵌入进行融合.最后,利用堆叠的全连接层进行特征转换,并输出预测评分.
1) 嵌入层
嵌入层主要用于学习用户和物品的评论嵌入和ID嵌入.对于ID嵌入,研究者们已在相关工作[1,3,18]中证实了它们对于提升模型能力,如表示学习和个性化推荐能力,具有显著作用.受此启发,本模型使用用户和物品的ID隐向量来描述其个性化特征,分别表示为pu∈Rd和qi∈Rd,其中d表示隐向量的维度.利用文本编码器对用户和物品的历史评论进行编码聚合,学习其相应的语义特征.E2R3 以层次化方式按词级、评论级、用户/物品级顺序逐层学习语义特征.具体来说,先将用户u的每条评论eu·∈Vu输入到预训练的文本编码器中,取编码器最后一层的输出作为融合了上下文信息的词表示.对于一条评论euk,编码器的输出结果为矩阵Euk∈Rck×cd,其中ck表示第k条评论中的单词个数,cd为文本编码器的输出向量维度.然后通过对评论中的单词进行平均池化将词级嵌入聚合成评论级嵌入,并通过进一步加权聚合成用户级嵌入,数学形式可表述为
其中:AvgPool(·)表示对词级嵌入的平均池化方法.用户u的语义特征为gu∈Rcd.使用类似的方法,可以计算物品i的语义特征gi.
2) 融合层
融合层对用户和物品的ID 嵌入和语义嵌入进行融合,得到完整的用户和物品表示,之后再对用户和物品表示进行融合,获取当前用户-物品对的交互特征.具体来说,将上述得到的语义特征gu/gi和ID 特征qu/qi组合,获得用户/物品表示hu/hi,即hu=[gu;qu],hi=[gi;qi].之后将用户表示hu和物品表示hi进行组合,得到交互级特征hui=[hu;hi],用于后续的特征转换.
3) 全连接层
全连接层主要实现特征转换并输出评分回归的结果.在这一层中,用户-物品对的交互特征被输入到多层感知机(MLP)中,以学习它们之间的高阶非线性关系.参照He等[18]提出的NCF算法,E2R3采用塔形结构的MLP,即底层具有最多的神经元,后续隐层神经元逐渐减少.通过这种塔状结构,MLP可以学习到更抽象的特征交互关系.这部分可以表示为
其中:Wl和bl表示第l层感知机的权重矩阵和偏置向量;ReLU 函数为神经网络的激活函数.最后,将第L层的输出vL送入最后一个线性层来预测当前用户u对物品i的评分,即
针对评分回归任务,使用均方误差损失(MSE Loss)作为目标函数,并在训练集上进行优化,MSE Loss可以表示为
其中:X为训练集;rui表示用户u对物品i评分的真实值.
2.2.2 解释生成器
1) 选择策略
用户和物品的评论与不同的评分相关,评分从低到高分别对应着用户从消极到积极的不同情感.如果这些情感不加以区分就直接用做推荐解释的输入语料,则生成的解释将不可避免地与预测评分产生情感冲突问题.所提出的选择策略旨在通过显式区分历史评论中的细粒度情感解决该问题,该策略利用评分预测器输出的预测评分,在历史评论列表中选择具有相同或相似评分的评论作为与推荐目标情感接近的语料内容.选择策略的具体算法流程如算法1所示,通过引入一个掩码向量m∈{0,1}l,其中l为历史评论个数,mt=1表示评论t被选择为情感相似语料,否则表示未被选择.经选择后的评论列表Vsu,Vsi将和预测评分具有高度的情感一致性.

算法 1 选择策略输入: 评论列表Vu和Vi,对应的评分列表Ru和Ri,预测评分rui,评论最小选择数量δ.输出: 情感一致性评论子集列表V su 和V si.1: for ob in {u,i} do 2: m ←0, b ←0; // 初始化掩码向量和偏置.3: while SUM(m)<δ do // SUM(m)表示m中1的个数.4: for t=1,2,…,|Vob| do // |Vob|为Vob长度.5: if Rob[t] == ■■ui+0.5 ±b then 6: mt ←1;7: end if 8: end for 9: b ←b+1;10: end while 11: V sob ←Vob ◦m;12: end for 13: return V su,V si;
2) 扰动策略
对于上述选择策略,当同一用户(物品)与不同物品(用户)交互且预测评分相同时,面临一个挑战:在用户(物品)侧产生的评论语料完全相同,这引入了极大的数据相似性,可能导致生成的解释文本高度同质化,损害用户体验.因此,为了增强评论聚合文档的多样性,进一步引入了扰动策略.该策略通过使用随机的顺序聚合被选择出来的评论,形成文档级语料,一方面可以避免因为固定的聚合顺序所带来的先验错误,另一方面也可以通过提高输入语料上下文的差异促使大语言模型生成更多样化的表达.E2R3采用的扰动方法为Knuth-Durstenfeld洗牌算法[19],该算法可在线性时间复杂度内完成等概率的随机洗牌.经随机聚合后的文档级语料定义为dui,dui为上下文敏感的语言模型提供了高质量的输入文本,从而缓解了生成文本过度相似的问题.
3) 策略增强的BART模型
与目前基于RNN 的现有方法不同,本方法采用了迁移学习的方式,将预训练语言模型应用到解释生成任务中.已有研究表明[20-21],迁移学习在提升摘要性能方面具有重要作用,而解释生成任务与文本摘要任务在本质上具有相同的目标,即从冗余文本中提取关键信息并以抽象的形式进行总结.因此,选择了目前在文本摘要领域表现出色的预训练语言模型BART[22]作为生成模块的基础模型,并通过引入本章提出的选择和扰动策略来对BART 模型进行策略式增强.与标准的BART 模型相比,增强后的模型具有更细粒度的情感对齐能力和多样性的文本生成能力,从而产生更高质量的摘要式解释.
本工作在商品推荐评论数据集上对经过策略增强的BART 模型进行微调,以生成与推荐场景相匹配的解释文本.具体来说,给定的评论列表Vu和Vi,对应的评分列表Ru和Ri,预测评分,以及评论最小选择数量δ,增强后的BART 通过生成情感敏感的摘要式解释,向用户u呈现与物品i相关的解释.对于解释生成任务,使用负对数似然(negative log-likelihood,NLL)损失作为损失函数.在第t个时间步,模型生成的单词为ot,对应的标签词为,T为序列长度,则NLL可以表示为
在推理阶段,针对已训练的模型,采用束搜索方法寻找具有最大对数似然和的最佳序列.
2.3 模型训练
对于模型训练,E2R3将评分回归任务和解释生成任务结合在一个统一的学习框架中,旨在使两个任务相互促进,相互补充,且能够保持评分模块与生成模块对于用户-物品交互信息捕获的一致性,平衡考虑评分回归的准确性和解释生成的质量.联合优化的目标函数可以表示为
其中:LR为式(5)中的评分回归任务损失;LE为式(6)中的解释生成任务损失;Θ表示模型中的全部可学习参数;λe和λl为损失项权重,用于平衡不同损失的重要性.整个学习框架可以使用反向传播算法在端到端范式中进行优化.
3 实验分析
首先介绍所使用的数据集、基准方法、评价指标等实验设置,然后通过大量实验尝试回答以下研究问题,以评估所提出E2R3方案.
问题1相比于基准方法,E2R3在评分回归和解释生成两项任务上表现如何?
问题2相比同样使用文本生成的可解释推荐方法,E2R3是否能够通过情感引导进一步改善所生成的解释文本质量?
问题3E2R3所采用的两个核心策略对模型的影响是什么?
3.1 实验设置
为了全面验证E2R3的有效性,使用来自电商领域不同商品类目的四个亚马逊数据集,它们具有不同数据规模和密度,包括Patio Lawn and Garden, Digital Music, Clothing Shoes and Jewelry 和Movies and TV.这些数据集已在之前文献中被广泛使用[8,15-16],统计信息如表1所示.

表1 数据集统计信息Tab.1 Statistics of the datasets
为了更好地说明所提出方案的有效性,实验中将E2R3与六种基准方法进行了比较分析:1)MF[3]通过矩阵分解获得用户和物品在共享隐空间的向量表征,并通过向量内积实现评分回归;2)NeuMF[18]结合了矩阵分解与多层感知机的技术优势,同时借助低阶和高阶特征交互,以期更好地拟合评分;3)NARRE[8]通过双塔结构的神经网络,从文本评论中独立学习用户和物品的向量表征,同时结合注意力机制评估不同文本内容的有用性;4)NRT[15]使用门控循环单元(GRU),将预测评分编码与评论编码融合,生成提示文本作为推荐解释;5) NETE[16]利用文本中的特征词生成模板指导的推荐解释;6)ESCOFILT[13]利用预训练的BERT 模型提取评论语料中的句子级表示,并对这些表示进行聚类,将聚类中心的句子作为推荐解释.前三种为经典评分回归方法,后三种为可解释推荐方法.
针对评分回归任务,使用均方误差(MSE)评测模型性能,该指标用于度量预估评分与真实评分之间偏差,MSE值越低说明回归性能越好.对于解释生成任务,综合测评了生成文本相对于标签文本的忠诚性以及生成文本间的差异性.对于忠诚性,分别采用Rouge 系列指标(Rouge-1,Rouge-2 和Rouge-L)和BERTScore测评生成文本与标签文本间的表达相似性和语义相似性.对于差异性,采用Distinct系列指标(Distinct-1和Distinct-2)衡量生成的解释文本之间的差异性.对于解释生成任务所使用的六个测评指标,其值越大说明生成文本质量越高.
实验数据按照“训练集∶验证集∶测试集=8∶1∶1”比例进行划分.模型训练阶段,使用Adam优化方法,初始学习率设置为10-4.超参数最小评论数δ在[1,3,5,8]中进行测试,权重参数λe在[0.3, 0.5, 0.8, 1.0]中搜索;经测试,δ=5和λe=0.5时,模型取得最佳性能.关于模型正则化,丢弃率设置为0.5,L2正则化系数λl=10-4.
3.2 总体性能比较(问题1)
表2显示了E2R3方案与其他基准方法在MSE指标上的性能对比,其中“改进(%)”表示E2R3相对于最优的对比方法所取得的性能改进.通过比较分析,本小节得出以下几点结论.首先,相对于纯评分回归方法(MF、NeuMF),使用了文本评论的R3方法(NARRE、NRT、NETE、ESCOFILT、E2R3)大多数情况下表现出更优越的性能.这表明使用评论数据对于提高评分回归准确性具有积极作用.其次,对比五种R3 方法,伴有解释文本生成的几种R3 方案(NRT、NETE、ESCOFILT、E2R3)性能更胜一筹.这说明多任务学习有助于进一步优化推荐性能.最后,在四种可解释R3方法中,E2R3在绝大多数情况下都取得了最佳的性能.尤其在具有多元商品类目的数据集(Patio Lawn and Garden 和Clothing Shoes and Jewelry)上,E2R3 分别取得了2.90%和6.03%的性能提升,而仅在单一类目数据集Digital Music 上有0.38%的下跌,这表明E2R3在复杂类目场景下更具优势,能够更好地学习用户的综合偏好,实现更准确的评分回归.

表2 E2R3与基准方法在四个数据集上的评分回归结果对比Tab.2 Results of E2R3 compared with other baselines on four datasets in terms of rating regression task
表3 展示了对四种方法所生成解释文本的定量分析结果.由实验结果可知,在绝大多数情况下,E2R3 各项指标均优于其他三种方法,表明E2R3 生成的解释文本与真实文本之间的内容重叠度、语义一致性,以及生成文本间的表达差异性上都具有优势.就Rouge-L 指标而言,E2R3 较最先进的对比方法有3.67%~24.53%的性能提升,而对于Distinct-2 指标,E2R3 有8.45%~22.44%的提升.这证明了E2R3 所生成的解释文本更贴近真实文本,且生成内容之间较其他方法更具备多样性.在BERT Score指标上,E2R3 在绝大多数情况下都能取得最优效果,与最先进的基线对比,在Patio Lawn and Garden,Digital Music 和Clothing Shoes and Jewelry 三个数据集上分别提升0.24%,0.60%和0.59%;仅在Movies and TV 数据集上稍有不足,主要原因是该数据集中商品类目较为单一,且评论/评分数据量较大,基线方法已表现良好;而在多元类目数据集上,E2R3 均能取得最优性能,进一步证实了本方法对复杂场景更具优势.
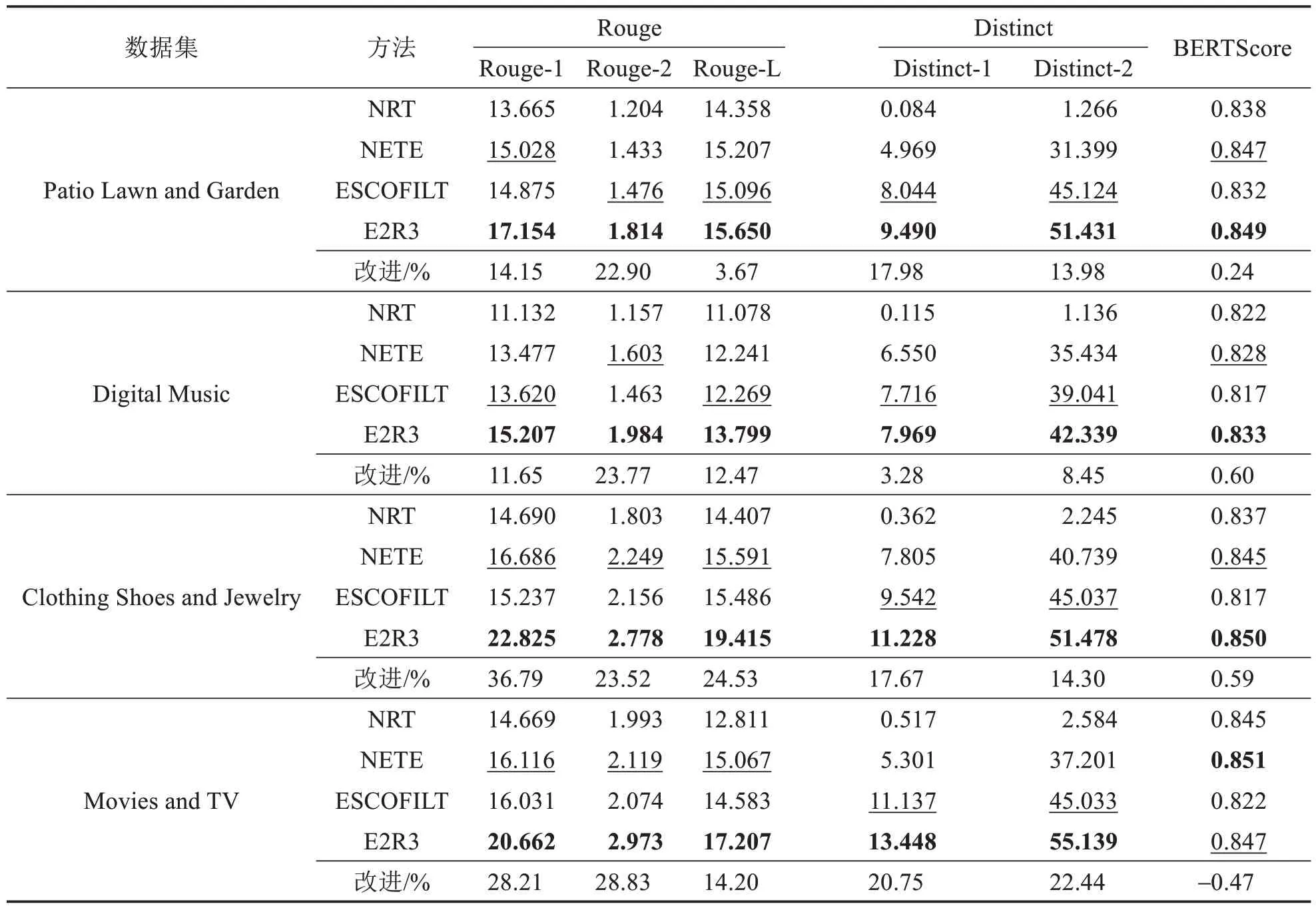
表3 E2R3与基准方法在四个数据集上的文本生成质量对比Tab.3 Results of E2R3 compared with other baselines on four datasets in terms of text generation task
3.3 案例分析(问题2)
为了进一步验证解释文本质量,通过案例分析对比E2R3 与基准方法所生成解释与真实文本之间的差异,以及生成文本与预测评分之间的情感一致性.限于篇幅,此处仅展示和分析了在Clothing Shoes and Jewelry 数据集上的部分实验案例.表4 展示了四种解释性R3 方法所产生的预估评分及解释文本.通过结果比对不难发现,NRT 和NETE 均倾向于生成带有积极情感的解释文本,即使在预估评分表现出“中性(2~4 分)”甚至“消极情感(小于2 分)”的情况下,可见直接将预测评分作为解释生成器的输入特征难以实现对生成内容情感的有效控制.相比之下,ESCOFILT 和E2R3 都能够生成具有丰富情感的解释文本,但通过案例1 可见,ESCOFILT 以“先解释再评分”的方式面临一个严重问题:“主题句”的生成仅依靠文本特征分布,脱离于评分的控制.当“主题句”与真实文本情感差距过大时,将导致预测评分严重偏差.如案例1 中ESCOFILT 方法抽取到的“主题句”存在过多的积极情感内容,这是在真实文本中没有出现的,也因此导致了预测评分为3.8 分,与真实评分1.0 偏差过大.E2R3 方法在两个案例中预测评分都与真实评分最为接近,且在第一个案例(低分案例)中没有出现积极情感内容,在第二个案例(中等评分案例)中积极情感内容和消极情感内容能实现与真实文本的类似的均等长度,这也是ESCOFILT 方法在案例2 中不能实现的.总的来说,E2R3 方法能够通过情感引导的方法生成高质量的推荐解释.

表4 几种方法的解释文本与预估评分之间情感一致性对比Tab.4 Comparisons among several methods in terms of emotional consistency between generated texts and estimated ratings
3.4 消融分析(问题3)
为了验证E2R3 所采用的两个核心策略在解释生成任务中的有效性,将E2R3 与其两个退化版本(E2R3 w/o P 和E2R3 w/o SP)进行性能对比,其中w/o P 表示去除扰动策略,w/o SP 表示同时移除选择和扰动策略.消融实验主要从生成文本的表达差异性以及与真实评论之间的语义相似性两个维度进行比较,结果如表5所示.不出所料,E2R3在Distinct指标上明显优于E2R3 w/o P,这说明扰动策略对于提高生成文本的差异性具有显著的效果.值得注意的是,由于扰动策略并非是针对语义层面提出,故在E2R3 在Movies and TV 数据集上的BERTScore 指标略低于E2R3 w/o P.同时,E2R3 在所有指标上都比E2R3 w/o SP 表现更好,说明考虑评分和评论之间的情感一致性对于生成语义明确的解释文本是有必要的.综上,E2R3所采用选择和扰动策略效果显著,能够明显改善解释文本质量.
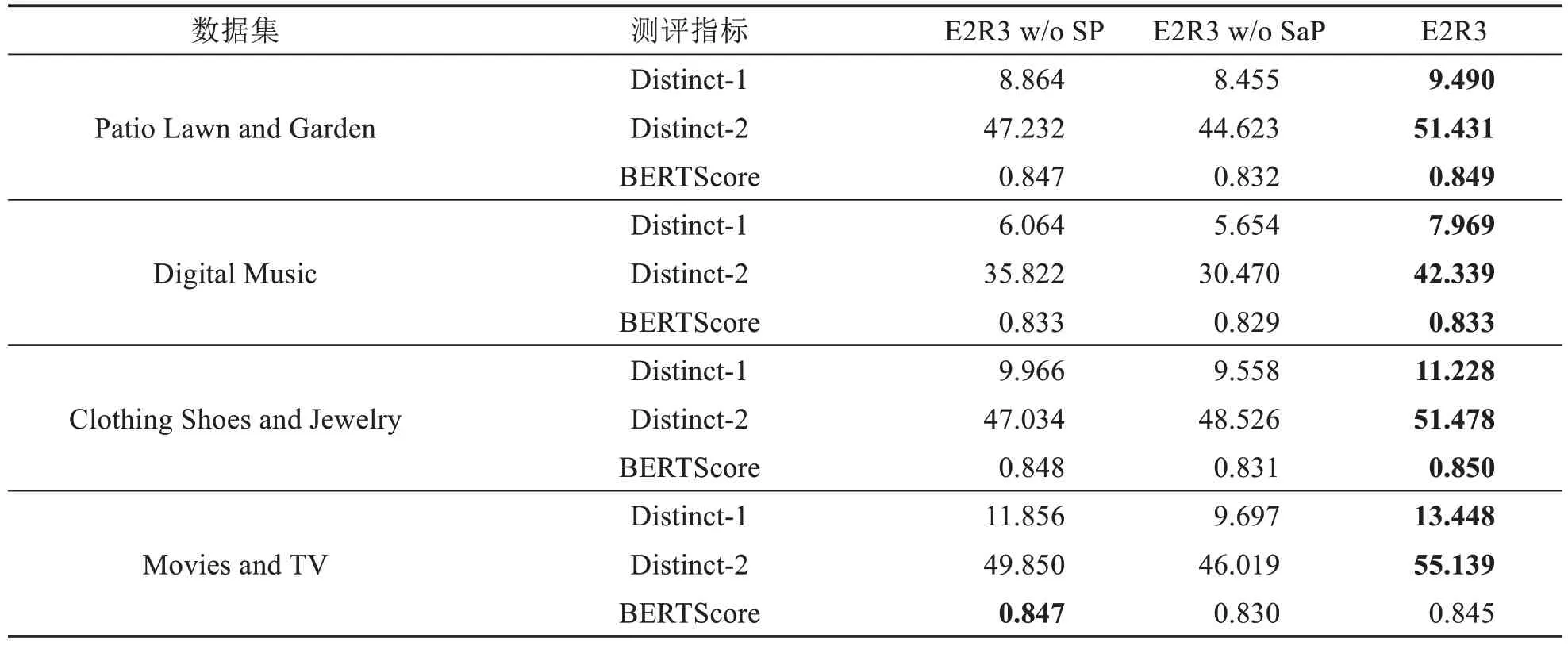
表5 E2R3与其退化版本在Distinct和BERTScore指标上的性能对比Tab.5 Results of E2R3 compared with its degenerated versions in terms of Distinct and BERTScore Metrics
4 结论
提出基于情感可控文本生成的可解释推荐框架E2R3,根据评分回归结果引导评论语料选择并据此生成解释文本,避免了评分预测任务与解释生成任务之间发生情感冲突.通过多任务学习设置,实现了评分回归模型与解释生成模型之间的双向互通和协同优化.实验结果与案例分析验证了E2R3的有效性.在未来工作中,将深入结合推荐场景设计自监督学习任务,使得预训练语言模型能够更好地适配于下游应用.此外,计划将基于可控文本生成的可解释推荐系统研究思路扩展至其它场景,如社交推荐系统、兴趣点推荐系统等.
