基于GEE平台和多维特征优选的粮食作物提取——以西辽河流域为例
2023-12-22王振兴刘东王敏
王振兴 刘东 王敏
摘要:快速准确地掌握作物种植类型和布局,对农业生产和管理具有重要意义。选取西辽河流域为研究区,基于Google Earth Engine(GEE)云平台,以Landsat和MODIS影像作为数据源,构建时序NDVI、物候参数、光谱指数、反射率及地形因子等多维特征。分别采用随机森林、支持向量机、分类回归树等方法,对比不同特征和分类器组合,选择优选特征和随机森林分类器,完成西辽河流域玉米、大豆和水稻的提取。结果表明,基于GEE平台可快速构建作物识别的多维特征,进一步利用递归消除随机森林优选特征,当加入重要性前30位特征参数时,总体精度可基本达到最高。选择优选特征组合并基于随机森林模型进行训练分类,可以实现高效率、高精度的作物空间分布制图。在验证指标中总体精度、κ系数、统计R2等验证指标均大于0.9,说明作物识别精度较高。西辽河流域农作物主要沿河流两侧呈条带状分布,玉米是最主要的农作物类型,大豆、水稻种植面积较少。
关键词:西辽河流域;GEE云平台;多维特征;作物识别;种植结构
中图分类号:S127文献标志码:A
文章编号:1002-1302(2023)21-0200-09
我国是人口大国,粮食生产一直是党和国家工作的重中之重。准确及时地获取作物种植结构信息,可以为政府部门提供基础决策信息,提高农业生产的科学管理水平,对粮食安全和经济发展具有重要意义[1-2]。农作物的种植结构是指区域内农作物的种类、面积和分布特征[3]。遥感因具有观测范围广、时效高和成本低的优点,在农业应用中发挥了重要作用,成为获取作物空间分布信息的重要手段[4]。农作物识别主要依据作物间光谱、时相、纹理等多种特征的差异,按照一定规则进行提取。原先的土地分类仅用少量的波谱特征,在作物识别中难以区分光谱相似度较高的不同作物,而通过构建高维特征,如光谱指数、时间序列、后向散射、地形以及纹理等,能够体现出作物全方位、多元化的特征差异,可以有效提高作物的识别能力[5-7]。牛乾坤等采用Sentinel-2影像,通过构建光谱特征、纹理特征和植被特征提取河套灌区作物的种植结构[8]。杨泽航等将Sentinel-2影像与MOD09GQ影像进行时空融合,得到时间序列NDVI数据,可以增加作物生长信息并实现对黑河流域作物的早期识别[9]。在样本有限的条件下,特征超过一定数量会影响模型性能和处理效率,降低分类精度。因此,需要选择适当数量和作用明显的特征。朱梦豪等通过改进JM距离,确定作物识别的最优特征组合,并获得高精度的作物分类结果[10]。刘戈等使用Relief F算法在原始特征中选择出24个最优特征,并利用卷积神经网络方法完成分类,提高了运算效率[11]。因此,合理构建作物分类的多维特征并进行适当选择是实现作物高精度制图的重要工作。分类算法也是影响分类精度的关键因素,常用的随机森林、支持向量机等机器学习方法在多年实践中得到广泛应用并取得良好效果,近年来以卷积神经网络、递归神经网络以及全卷积网络为代表的深度学习算法进一步提高了作物识别的准确率,但深度学习模型训练需要足够数量的样本,在样本有限时难以适用[12-13]。与传统遥感影像处理平臺相比,Google Earth Engine(GEE)等云计算平台可以快速完成数据获取、预处理以及分类等任务,极大地提高了工作效率,成为大面积农作物制图的重要工具[14-15]。因此,利用GEE云平台的丰富资源和强大算力,构建并优化多维特征,选择合适的作物制图方法是目前农作物识别的重要工作。西辽河流域是我国重要的玉米商品粮种植基地,近年来不合理的生产活动导致流域生态环境恶化,同时受不同政策(生态修复工程、镰刀弯政策等)影响,农作物种植结构发生较大改变。本研究基于GEE云平台,以Landsat影像为基础数据源,建立作物分类的多维特征,探索适合该区域的作物制图方案,以期为推动未来种植业结构调整和绿色农业可持续发展提供数据支持。
1 研究区与数据源
1.1 研究区简介
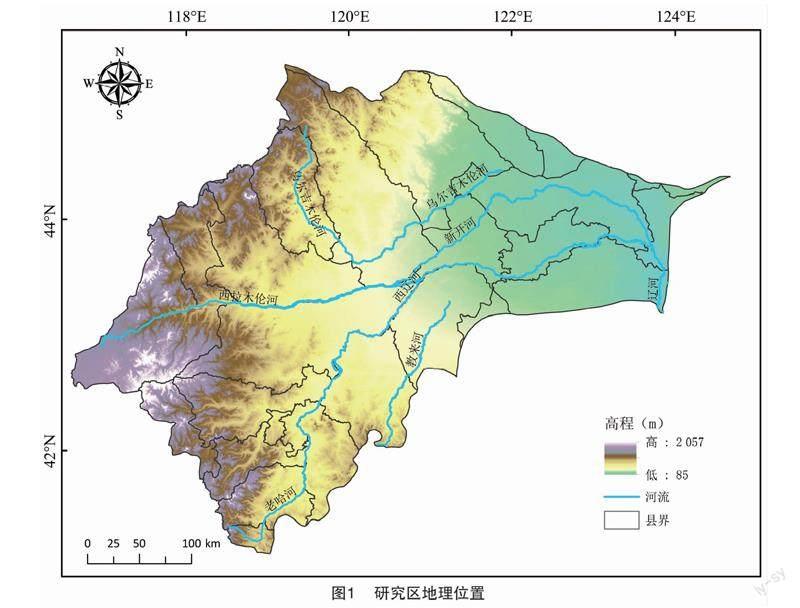
西辽河流域(116°36′~124°34′E,41°05′~45°12′N)位于我国北方农牧交错带东部三北交界处,连接华北平原、东北平原和蒙古高原,流经内蒙古自治区、吉林省、河北省和辽宁省4个省(区),主要涉及的地级市包括内蒙古自治区赤峰市、通辽市等,流域面积约13.6万km2(图1)。西辽河流域属于暖温带半湿润气候向中温带半干旱气候的过渡区域,年均气温5~6 ℃,年均降水量300~400 mm、蒸发量1 200~2 200 mm。主要河流包括西辽河干流、教来河、老哈河、西拉木伦河、乌力吉木伦河和新开河。西、南、北三面环山,整体呈扇状,地势表现为西南高东北低。流域内主要粮食作物有玉米、大豆、水稻等,1年1熟。
1.2 数据来源及处理
研究数据包括Landsat 8 OLI影像、MOD09Q1影像、DEM数据、统计年鉴数据及实地采样数据。
Landsat 8 OLI影像由GEE平台获取,该数据集已经过大气校正和正射校正处理。Landsat 8 OLI是美国Landsat系列第8颗卫星上的传感器,包括9个波段,除全色波段外空间分辨率为30 m,运行重访周期为16 d。Landsat影像因具有较高空间分辨率和长时间运行周期被广泛使用,也是本研究的主要数据源。卫星运行中会受到云、雨等天气状况的影响,造成可用像元数量的减少[16]。因此,本研究分析研究区内Landsat影像的覆盖分布与去云后的像元数量(图2)。以 2017 年作物生长季3—11 月为例,西辽河流域完整覆盖共需 22 幅不同编号的 Landsat 影像,其间共有 342幅影像记录数据。剔除云等因素干扰的像元后,在影像互有重叠的情况下,不同像元位置处最高有33次重访,最低仅有1次重访。进一步统计发现,未去云前,2.39%像元位置重访次数为0~15;去云后,42.9%像元位置的重访次数为0~15,充分表明云、雨等天气可以降低Landsat影像的有效可用数量[17]。
MOD09Q1影像由GEE平台获取,包含250 m空间分辨率8 d合成的红外波段和近红外波段,还包括1个质量控制波段。SRTM DEM由GEE平台获取,具有30 m空间分辨率。统计数据来源于《内蒙古调查年鉴》《吉林统计年鉴》《辽宁统计年鉴》《河北统计年鉴》《河北农村统计年鉴》,用来统计并验证西辽河流域各县(旗、区)玉米、大豆和水稻的种植面积。
作物采样数据是2017年于西辽河流域实地获取,包括作物类型和位置信息,用于农作物分类的训练和验证。原始样本由实地考察获取,受各种条件限制,采集数量较少,难以满足分类要求。通过计算已有样本的归一化植被指数(NDVI)和反射率序列特征的均值(见“2.1.1”节和“2.1.3”节),在耕地范围内计算与均值的光谱角距离,设定阈值为均值+1倍标准差,在阈值范围内选择距离最接近的样本,并利用高分辨率影像对比,删去错误明显的样本点后,扩充原始样本数量(表1)。将样本按照7 ∶3随机划分为训练集和测试集。
2 研究方法
首先,在GEE平臺获取研究所需的数据并进行相关预处理;其次,构建时间序列NDVI、物候参数、反射率、光谱指数、地形等多个特征。利用递归消除随机森林进行特征选择,进一步设计6组对照特征方案,分别基于随机森林、支持向量机、分类回归树对比分析总体精度,选择最适分类方案。作物分类中,提取耕地分布作为掩膜图像,在上述方案的基础上完成西辽河流域主要粮食作物识别;最后,利用验证样本、统计数据评价分类精度(图3)。
2.1 特征集构建
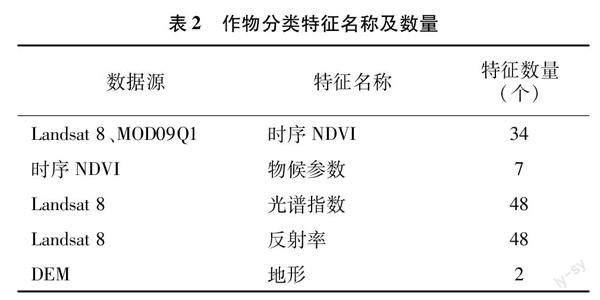
本研究构建包括时序NDVI、物候参数、光谱指数、反射率、地形特征等139 个作物分类特征(表2)。
2.1.1 时间序列 NDVI 特征
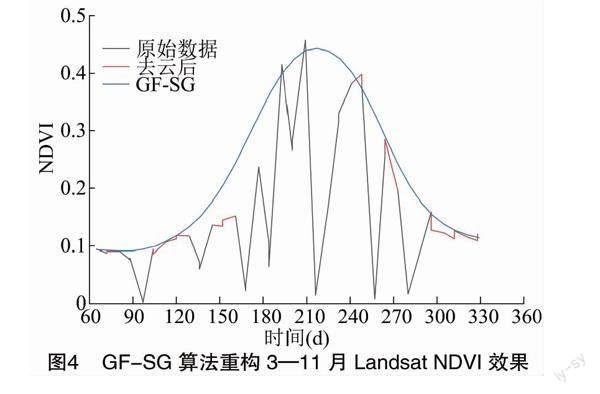
本研究通过GF-SG(Gap Filling and Savitzky-Golay)算法重构得到3—11月8 d、30 m分辨率的Landsat NDVI图像,共34期。GF-SG算法是利用Landsat和MOD09Q1 影像的高时空分辨率影像重建算法,有3个主要优点:第一,可有效提高 Landsat NDVI时间序列长期连续缺失情况下的重建精度。第二,通过加权SG滤波器可减少云检测误差引起的残余噪声影响。第三,方法简单易运算,没有复杂的非线性参数优化过程,可在GEE平台实现[18]。算法的具体过程参照文献[18]。利用GF-SG算法重构后的NDVI序列平滑连贯,可以有效弥补去云后Landsat NDVI的长时间缺失(图4)。
2.1.2 物候参数特征
利用GF-SG生成的时序NDVI计算植被物候参数,包括生长季开始时间、生长季结束时间、生长季持续时间、NDVI 最大值、NDVI最小值、NDVI幅度和NDVI最大值日期(图5)。NDVI最小值计算采用NDVI 时间序列前4个时间点(3月)和最后4个时间点(11月)的均值,这样可有效减少异常值干扰。NDVI最大值即为NDVI时间序列中的最大值。NDVI幅度即为最大值与最小值的差值。生长季开始时间是从 NDVI最小值增长到振幅的10%处所对应的时间日期。生长季结束时间是NDVI曲线下降距离最低点振幅10%处所对应的时间日期[19]。生长季持续时间是生长季开始时间和生长季结束时间的差值[20]。物候参数位置见图5。
2.1.3 反射率、光谱指数以及地形特征
分别计算3—11月OLI影像的 2~7波段和NDVI、EVI、LSWI、MNDWI、NDTI、NDSVI等植被指数的百分数(5%、25%、50%、75%、95%)、均值、差值(5%~95%)以及标准差影像,作为反射率和光谱指数特征,百分数、均值和标准差影像分别通过GEE中函数ee.Reduce.percentile()、ee.Reduce.mean()和ee.Reduce.stdDev()计算而来。植被指数具体名称及计算公式见表3。此外,选择 DEM 数据的高程和坡度信息作为地形特征。
2.2 耕地识别
对西辽河流域进行土地利用分类,识别出耕地分布作为作物分类的掩膜图像。分类样本在Google Earth Engine平台按照均匀、随机的原则每类目视选取400~600个样本点。分类源数据是4—10月Landsat 8 OLI影像,分类特征包括2~7波段和NDVI、EVI、LSWI、MNDWI、NDTI、NDBI等光谱指数的时间序列百分数(5%、25%、50%、75%、95%)影像。利用随机森林分类器进行样本训练,通过精度评价,重复改进样本直至满足要求,最终得到耕地分布图。
2.3 特征选择
采用递归消除随机森林方法(RF-RFE)选择适当数量和作用明显的分类特征。该方法将随机森林和递归消除算法(recursive feature eliminate,RFE)结合使用。先利用随机森林计算特征重要性并进行排序,再把所有特征作为初始特征集,依次去除重要性最低的特征加入模型中训练,通过迭代计算出模型精度,最终在特征数量和模型精度间选择数量较少和精度较高的特征数据集。本研究鉴于原始特征数量较多,故每次去除特征数量设为5个。
2.4 分类算法
随机森林(random forest,RF)分类器是由多个决策树模型组合形成的集成学习分类器,可以有效地避免模型过拟合,使其具有良好的鲁棒性;同时可以处理高维特征数据,并提供比传统分类器更快、更可靠的分类结果,而无需显著增加计算工作量[21-22]。
支持向量机(support vector machine,SVM)是一类基于统计学习的机器学习算法[23]。SVM通过将特征向量映射到高维特征空间,寻找不同类别区别度最高的超平面实现分类,具有较高的泛化能力,适用于样本数量较少的情景。
分类回归树(classification and regression tree,CART)既可用于分类,也可用于回归。CART分类包括二叉树生成和“剪枝”,使用基尼系数进行特征选择和阈值划分。该方法计算简单快捷,对异常值不敏感。
RF分类器设置参数树的数量为30,其余参数选择默认。SVM分类器核函数类型为RBF,核函数γ值为0.5,cost参数为10。CART分类器参数默认。
2.5 试验方案
为验证不同特征组合在不同分类算法下的精度,本研究设置6组特征组合(表4),分别是反射率、光谱指数、反射率+光谱指数、反射率+光谱指数+时序NDVI、所有特征和优选特征。上述特征组合分别基于随机森林、支持向量机和分类回归树训练分类,得到总体精度,对比分析筛选出最适分类方案。
2.6 精度验证
通过混淆矩阵和统计数据2种方式对提取作物的结果进行精度验证。混淆矩阵别称误差矩阵,将分类结果与参考类别相比较得到分类结果的精度,是衡量遥感影像分类精度的常用方法。利用混淆矩阵计算制图精度、用户精度、总体精度和κ系数。
统计数据通过对比统计年鉴中的种植面积进行验证,包括流域尺度和县(旗、区)尺度。流域尺度是通过整理流域内各作物整体种植面积进行比较,其中部分行政区在流域内的县(旗、区),通过行政区面积所占比例折算作物种植面积。县(旗、区)尺度是将流域内具有完整行政单元县(旗、区)的统计数据与解译数据进行直线拟合,得到统计R2作为验证指标。
3 结果与分析
3.1 特征重要性及优选结果分析
按平均重要性排名,各类特征依次是地形、反射率波段、时序NDVI、光谱指数和物候参数。按平均排名,顺序类似。地形特征中高程特征重要性突出,坡度信息排名靠后。反射率波段特征整体重要性高于其他特征,时序NDVI和光谱指数重要性其次(表5)。由时序NDVI计算而来的物候参数特征整体重要性偏低。
将特征按重要性排名依次递减5个投入随机森林模型中,观察到特征数量由5到10时,总体精度较大幅度增加,由10到20时平缓增加,特征数量达到20后,总体精度随着特征数量增加在94%附近波动变化,在特征数量为30时,总体精度达到局部最大值94.51%。虽然在特征数量80和120位置处,总体精度仍存在局部最大值,但此时特征数量较多且与特征数量30时总体精度相差不大,考虑到特征数量增加导致的计算效率下降等问题,把特征重要性前30位的特征作为优选特征方案(图6)。进一步统计优选特征中各类别数量,反射率波段特征依然最多,其次是光谱指数和时序NDVI,物候参数和地形特征仅有1个。
3.2 不同方案对比分析
本研究利用6种特征组合分别在3种分类器下训练分类,得到总体精度并进行比较分析(图7)。基于随机森林分类器中,仅利用反射率或光谱指数的总体精度分别为90.57%、90.35%;当两者都加入模型后,精度增加至91.89%;再加入时序NDVI,精度再次增加至94.74%;当加入所有特征时,精度下降,为93.64%;利用优选特征时,精度为94.52%,稍低于方案四的0.22%。该结果表明,不同类型特征的加入能提高作物识别总体精度,但重要性较弱的特征加入后反而会降低精度。基于分类回归树分类器中,仅加入所有特征时,精度超90%;优选特征组合的精度紧随其后,为89.47%。基于支持向量机分类器中,方案一至方案四精度逐渐增加至94.96%,但加入所有特征时,精度骤降至42.98%;优选特征方案也只有72.15%。这是因为支持向量机需要输入特征的数据量度范围统一,物候参数和地形特征的加入破坏了方案四中特征的一致性。综合来看,随机森林模型在处理多类型、多维度特征时,无需进行数据的归一化操作,精度便可高于另外2个分类器;优选特征组合在特征数量较少的前提下,模型也基本可以达到较高的分类精度。因此,选择优选特征组合并基于随机森林模型进行训练分类,既可以降低运算复杂度,又可以保证较高分类精度。
3.3 提取作物精度及布局分析
耕地制图的精度是作物识别准确性的前提,对其分类结果进行验证。耕地制图精度为95.2%,用户精度为89.7%,分类结果可以满足农作物制图的使用要求。本研究分别基于样本数据和统计数据验证作物提取的准确性(表6)。2017年作物分类的总体精度为0.94,κ系数为0.92,均大于0.9,各作物的制图精度和用户精度也均大于0.9,说明从验证样本的角度考虑,模型分类精度较高。其中水稻的制图精度和用户精度均等于1,间接表明扩充样本由于依赖于实际采集的少量数据,虽然样本数量在分类过程中满足了要求,但是样本的代表性、多样性有所下降,导致模型存在一定程度的过拟合。进一步从统计数据的角度分析作物分类精度。全域来看,3类作物的面积误差绝对值在10%以内,玉米的提取面积和统计数据基本一致,大豆提取面积高于统计面积8 km2左右,水稻提取面积低于统计面积38 km2左右。本研究用西辽河流域内行政区单元完整的11个县(旗、区)的解译面积和统计面积拟合直线得到R2,3类作物R2均大于0.9,表明识别作物整体布局与统计结果基本吻合。基于统计数据的拟合方程中,玉米斜率为1.22,大豆斜率为1.15,水稻为1.08,3类作物拟合斜率均大于1,表明在部分验证县(旗、区)解译面积有高估趋势。综合来看,虽然部分县(旗、区)解译面积与统计面积有所出入,但分类结果的作物整体布局和面积基本准确,基于优选特征的隨机森林分类方案可以得到高精度的作物分布。
本研究得到2017年西辽河流域玉米、大豆以及水稻的空间分布(图8)。西辽河流域主要粮食作物分布在海拔较低的东、北部平原地区,沿河流两侧呈条带状分布。西辽河干流和新开河流域一带的县(旗、区)种植分布最密集;老哈河、教来河、西拉木伦河及乌尔吉木伦河种植面积相对较少。玉米是西辽河流域最主要的作物类型,在整个流域内均有种植,分布范围广,面积约17 193.45 km2,在流域东部、南部地区最集中。流域内科尔沁左翼中旗、科尔沁区和开鲁县是种植面积最多的县(旗、区),面积分别为2 199.62、1 941.87、1 726.66 km2;元宝山区和红山区种植面积较少,仅分别为193.54、43.20 km2。大豆整体种植面积较少,约为 348.42 km2,种植集中分布在流域东北部的长岭县、双辽市部分地区和流域中南部的敖汉旗、翁牛特旗部分地区(图8-a、图8-b)。水稻种植面积较少,约为492.78 km2,分布区域较集中,主要在西拉木伦河和老哈河流域的翁牛特旗北部、东部和科尔沁左翼后旗东部区域,其他地区种植分布较零散(图 8-c、图8-d)。
4 结论与讨论
本研究以Landsat 8 OLI 和MOD09Q1影像为基础数据源,构建时序NDVI、物候参数、光谱指数、反射率以及地形等多维特征。对比分析不同特征和分类器组合,最终使用基于RF-RFE选择的特征子集和随机森林分类器,提取西辽河流域玉米、大豆和水稻的种植信息。主要结论有以下4点。第一,基于GEE平台可快速获取并构建作物分类的多维特征,分别从时序曲线、物候、地形、光谱反射以及光谱指数等多方面区分作物间的细微差距。进一步利用RF-RFE方法选择特征时,发现模型中加入重要性前30名的特征时总体精度可基本达到最高。第二,利用6种特征组合方案分别在3种分类器下训练分类,对比分析发现选择优选特征组合并基于随机森林模型进行分类,可以保证在特征数量较少的前提下,处理多类型、多维度特征,分类模型总体精度基本可以达到较高水平。第三,分别基于样本数据和统计数据展开作物制图精度验证,作物分类的总体精度、 κ系数、各作物的制图精度和用户精度以及统计R2均大于0.9,3类作物解译面积误差绝对值在10%以内,说明解译作物整体布局和面积准确度较高。第四,西辽河流域农作物主要分布在海拔较低的东、北部平原地区,沿河流两侧呈条带状分布,西辽河干流和新开河附近区域最密集。玉米是流域内最主要的农作物类型,分布范围广,大豆、水稻种植面积较少,仅在部分区域集中分布。
本研究没有使用空间和时间分辨率更具优势的Sentinel系列影像,是因为本研究意在探索适用于以Landsat为基础数据源的作物分类方案,将有助于向前或向后拓展监测年份,而Sentinel卫星在轨运行时间短,难以完成2015年前历史年份的监测。同时,西辽河流域作物种植分布集中,以平原地区为主,没有复杂地形的干扰,30 m分辨率可以清晰地展现作物的空间细节。受篇幅和时间限制,后续将进一步探究基于现有年份的分类模型迁移方法,并完成长时间序列作物制图任务。
参考文献:
[1]史 舟,梁宗正,杨媛媛,等. 农业遥感研究现状与展望[J]. 农业机械学报,2015,46(2):247-260.
[2]何 可,宋洪远. 资源环境约束下的中国粮食安全:内涵、挑战与政策取向[J]. 南京农业大学学报(社会科学版),2021,21(3):45-57.
[3]唐华俊,吴文斌,杨 鹏,等. 农作物空间格局遥感监测研究进展[J]. 中国农业科学,2010,43(14):2879-2888.
[4]赵子娟,刘 东,杭中桥. 作物遥感识别方法研究现状及展望[J]. 江苏农业科学,2019,47(16):45-51.
[5]Tatsumi K,Yamashiki Y,Canales Torres M A,et al. Crop classification of upland fields using random forest of time-series Landsat 7 ETM+data[J]. Computers and Electronics in Agriculture,2015,115:171-179.
[6]郭昱杉,刘庆生,刘高焕,等. 基于MODIS时序NDVI主要农作物种植信息提取研究[J]. 自然资源学报,2017,32(10):1808-1818.
[7]宋宏利,雷海梅,尚 明. 基于Sentinel2A/B时序数据的黑龙港流域主要农作物分类[J]. 江苏农业学报,2021,37(1):83-92.
[8]牛乾坤,刘 浏,黄冠华,等. 基于GEE和机器学习的河套灌区复杂种植结构识别[J]. 农业工程学报,2022,38(6):165-174.
[9]杨泽航,王 文,鲍健雄. 融合多源遥感数据的黑河中游地区生长季早期作物识别[J]. 地球信息科学学报,2022,24(5):996-1008.
[10]朱梦豪,李国清,彭壮壮. 特征优选下的农作物遥感分类研究[J]. 测绘科学,2022,47(3):122-128.
[11]刘 戈,姜小光,唐伯惠. 特征优选与卷积神经网络在农作物精细分类中的应用研究[J]. 地球信息科学学报,2021,23(6):1071-1081.[HJ2.06mm]
[12]Ji S P,Zhang C,Xu A J,et al. 3D convolutional neural networks for crop classification with multi-temporal remote sensing images[J]. Remote Sensing,2018,10(2):75.
[13]王德军,姜琦刚,李远华,等. 基于Sentinel-2 A/B时序数据与随机森林算法的农耕区土地利用分类[J]. 国土资源遥感,2020,32(4):236-243.
[14]Amani M,Ghorbanian A,Ali Ahmadi S,et al. Google earth engine cloud computing platform for remote sensing big data applications:a comprehensive review[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2020,13:5326-5350.
[15]张紫荆,华 丽,郑 萱,等. 基于GEE平台与Sentinel-NDVI时序数据江汉平原种植模式提取[J]. 农业工程学报,2022,38(1):196-202.
[16]黄 波. 时空遥感影像融合研究的进展与趋势[J]. 四川师范大学学报(自然科学版),2020,43(4):427-434,424.
[17]刘建波,马 勇,武易天,等. 遥感高时空融合方法的研究进展及应用现状[J]. 遥感学报,2016,20(5):1038-1049.
[18]Chen Y,Cao R Y,Chen J,et al. A practical approach to reconstruct high-quality Landsat NDVI time-series data by gap filling and the Savitzky-Golay filter[J]. ISPRS Journal of Photogrammetry and Remote Sensing,2021,180:174-190.
[19]周玉科. 基于遙感的中国东北植被物候不对称特征分析[J]. 遥感技术与应用,2019,34(2):345-354.
[20]项铭涛,卫 炜,吴文斌. 植被物候参数遥感提取研究进展评述[J]. 中国农业信息,2018,30(1):55-66.
[21]张馨予,蔡志文,杨靖雅,等. 时序滤波对农作物遥感识别的影响[J]. 农业工程学报,2022,38(4):215-224.
[22]刘 杰,刘吉凯,安晶晶,等. 基于时序Landsat 8 OLI多特征与随机森林算法的作物精细分类研究[J]. 干旱地区农业研究,2020,38(3):281-288,298.
[23]丁世飞,齐丙娟,谭红艳. 支持向量机理论与算法研究综述[J]. 电子科技大学学报,2011,40(1):2-10.
收稿日期:2023-02-21
基金项目:国家自然科学基金(编号:41671525)。
作者简介:王振兴(1998—),男,山东东营人,硕士研究生,从事农作物遥感识别研究。E-mail:wangzhenxing20@mails.ucas.ac.cn。
通信作者:刘 东,博士,副教授,从事资源环境遥感与区域发展研究。E-mail:lldking@ucas.ac.cn。
