基于CNN-BiLSTM的施工初期盾构机掘进速度预测
2023-12-19张纪奥马怀祥王承震李东升乔卉卉
张纪奥, 马怀祥, 王承震, 李东升, 乔卉卉
(1.石家庄铁道大学 机械工程学院,河北 石家庄 050043;2.中铁十四局集团有限公司, 山东 济南 250014)
0 引言
盾构机作为隧道与地下工程建设的专用装备,具有安全环保、掘进速度快和劳动强度低等优点,在盾构施工过程中,其掘进速度是装备运行操控与项目施工规划的参考依据[1],因此,对盾构机掘进速度进行预测研究具有重要工程意义。
近年来,国内外学者对此主要进行了理论模型、经验模型和智能模型方面的研究。在理论模型研究方面,张厚美等[2]修正了掘进速度与总推力、刀盘扭矩的计算公式;王洪新等[3]对土仓压力、总推力、螺旋机转速和掘进速度间关系的数学表达式进行了推导。在经验模型研究方面,李杰等[4]采用多元非线性回归建立了复合地层下掘进速度的预测模型;于云龙等[5]通过对原始掘进参数进行二次转换,修正了盾构机传统掘进速度模型。在智能模型研究方面,随着大数据和人工智能技术的发展,机器学习被广泛应用于盾构掘进预测中。黄靓钰等[6]、林春金等[7]、孙伟良等[8]采用BP神经网络建立了掘进参数、土仓压力和地表沉降的预测模型;GAO et al[9]使用循环神经网络、长短时记忆网络和门控循环单元建立了盾构掘进参数的预测模型;ELBAZ et al[10]将卷积神经网络和基于聚类算法的长短时记忆网络相结合,实现了盾构机掘进系统的能耗预测。
目前在盾构机掘进参数预测研究中,所用数据多为掘进循环下的参数均值,在工程施工初期,数据量不足会导致上述模型的预测效果降低,且现有研究大多依托某单一工程,缺乏不同工程下预测模型的适用性研究。鉴于此,依托南京长江隧道工程和芜湖过江隧道工程,采用迁移学习策略,提出一种基于混合指标分级的CNN-BiLSTM迁移预测模型。首先,在已完成工程上对盾构机混合指标进行k-means聚类分级,构建CNN-BiLSTM模型进行预训练;然后,对新工程上的混合指标等级进行判别,并将预训练模型应用到新工程上进行微调,使预测模型在旧工程下学习到的特征知识能更好地应用到新工程中。
1 工程概况和数据清洗
1.1 工程概况
南京长江隧道位于江苏省南京市,横越长江南北两岸,全长5 850 m。盾构段施工部分为左右两线,采用2台海瑞克泥水式盾构同时施工,刀盘开挖直径为14.96 m,左右线从浦口区同向始发。隧道地层断面如图1所示[11],盾构隧道分别穿越淤泥质粉质黏土地层、粉细砂地层、砾砂地层、圆砾地层和强风化泥岩地层。
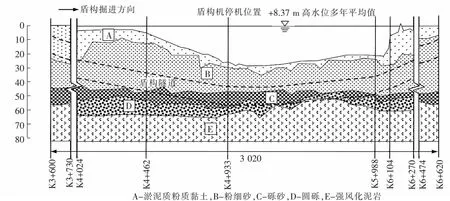
图1 南京长江隧道地质断面图(单位:m)
芜湖城南过江隧道位于安徽省芜湖市长江大桥和长江二桥之间,长约4.9 km。采用2台气垫式泥水平衡盾构,刀盘开挖直径为15.07 m,盾构从江北同向先后始发,分别穿越长江后,在江南接收[12]。地质断面如图2所示,盾构隧道分别穿越粉细砂、泥质粉砂岩、凝灰角砾岩和粉质黏土等多种地层。
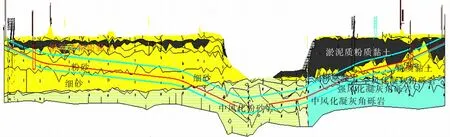
图2 芜湖过江隧道地质断面图
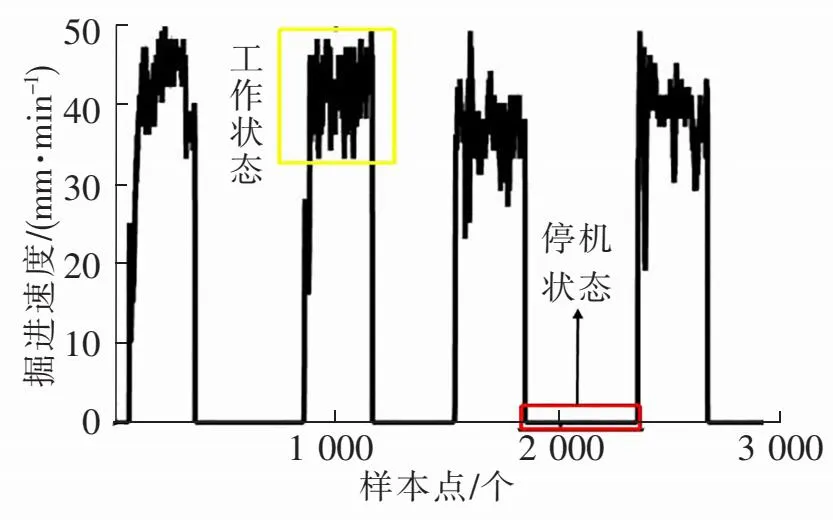
图3 不同状态下掘进速度
1.2 数据清洗
施工过程中,盾构机数据监测系统会对掘进参数进行采集保存,在管片安装、设备维护和其他情况下,监测系统通常会连续工作,导致大量的无效数据被保存下来。以南京长江隧道工程部分掘进速度为例,如图3所示,其中每个样本点为盾构机监测系统的采样点,采样间隔为10 s。
将盾构机的总推力、掘进速度和刀盘扭矩作为划分工作状态和停机状态的指标[13],式(1)、式(2)为指示函数,将导致的数据认为是停机状态下的数据,进行清洗。
F(X)=f(F)f(V)f(T)
(1)
(2)
2 研究方法
2.1 k-means算法
k-means算法作为一种非层次聚类算法,通过迭代过程把数据集划分为不同类别,并逐次更新聚类中心直至达到要求的精度[14]。基本步骤为:首先,随机选取个初始聚类中心;然后,将每个数据点分配到距离最近的聚类中心所在簇中;最后,计算每个簇中数据点均值,并将其作为新的聚类中心,重复以上2个步骤,直至收敛或达到最大迭代数。
2.2 CNN模型
卷积神经网络是一种常用的深度学习模型,由卷积层、池化层和全连接层构成,具有一定的深度结构与自主学习能力,通过模拟人脑系统,对输入信息进行处理,提取主要信息特征[15]。卷积核作为CNN的核心部分,对数据进行卷积操作提取数据的内部特征,表示为
Cj=f(wi⊗Ai+bi)
(3)
式中,f为激活函数;wi为权值矩阵;⊗为卷积操作;bi为偏置矩阵。
2.3 BiLSTM模型
长短时记忆网络(LSTM)通过引入输入门、输出门和遗忘门来解决梯度消失问题。LSTM的核心结构为记忆细胞,包含一个细胞状态c、一个隐藏状态h,其神经元的网络结构如图4所示。BiLSTM是一种双向循环神经网络模型,如图5所示,可同时考虑输入序列的前向和后向信息,能够更好捕捉上下数据特征,提升模型预测精度和特征数据利用率[16],其核心结构为2个方向相反的LSTM模型构成的堆叠结构,正向LSTM从前向后遍历输入序列,反向LSTM从后往前遍历输入序列,正向和反向过程均有其隐藏状态h和细胞状态c。

图4 LSTM网络结构示意图

图5 BiLSTM网络结构示意图
3 工程验证
在新工程掘进初期数据量不足的情况下,提出一种基于混合指标分级的CNN-BiLSTM迁移预测模型。首先,以南京长江隧道工程数据为源域数据,对混合指标进行聚类分级,以芜湖过江隧道工程数据为目标域数据,判断该工程上混合指标的对应等级;然后,构建模型在源域的相应等级数据上进行预训练,将模型迁移至目标域进行微调;最后,实现在施工初期少量数据下盾构掘进速度的预测。
3.1 混合指标的聚类分级
为降低不同工程下盾构机型号、地质信息和施工环境等信息对模型的影响,引入场切深指数(FPI)、扭矩切深指数(TPI)、掘进比能(SE)和切割系数(C)[17]4种混合指标进行聚类分级,4种指标的计算公式为
(4)
(5)
(6)
(7)
式中,F为刀盘总推力;n为刀盘上刀具数量;P为贯入度;T为刀盘扭矩;r为刀具力矩半径;R为刀盘半径。
由于施工过程中刀具磨损会造成持续变化,难以确定具体数值,故忽略刀具力矩半径对切割系数的影响,将式(7)简化为
(8)
对南京长江隧道工程中盾构机采集的掘进参数进行混合指标计算,4种指标变化趋势如图6所示。FPI指数描述了盾构机在单位贯入度下所需推进力,反映盾构机与土体的相互作用,既考虑了地质因素影响,又考虑到机器设备影响,通过FPI指数可以快速估算岩石强度。TPI指数描述了盾构机在单位贯入度下所需刀盘扭矩,同FPI指数的考虑类似,能够对盾构机掘进状态进行更加完整的表述。掘进比能SE表示盾构机在掘进单位体积土体时所需能量,主要用于刀具开挖土体和盾壳克服摩擦力向前推进。切割系数C反映了刀盘总推力和刀盘扭矩之间的关系,主要受地质状况和刀具磨损的影响。
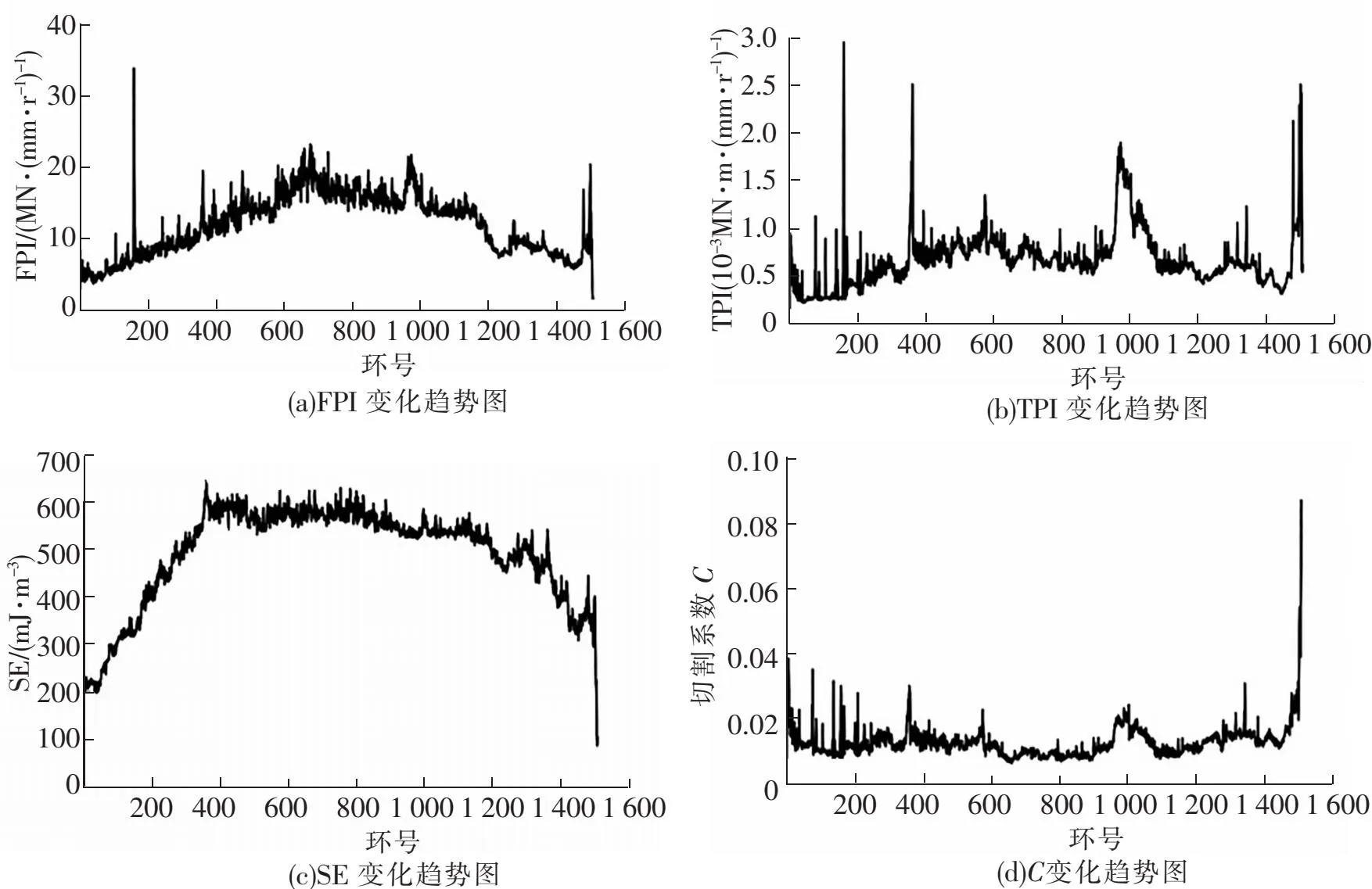
图6 混合指标趋势图
为避免不同指标物理量纲的影响,聚类之前对指标进行归一化处理,具体为
(9)
式中,x′为参数处理后的值;x为当前参数值;xmax、xmin分别为参数样本的最大值、最小值。
引入DB指数评价聚类效果,该指数通过计算每个簇与其他簇之间的平均距离和每个簇内元素之间的平均距离之和的比值来度量聚类的性能,最优聚类结果对应的DB值越小越好。对上述混合指标进行聚类后对应的DB指数如图7所示。可知当聚类数为4时,聚类效果最优,选取k=4对混合指标进行聚类,聚类后各环在混合指标上的等级如图8所示。
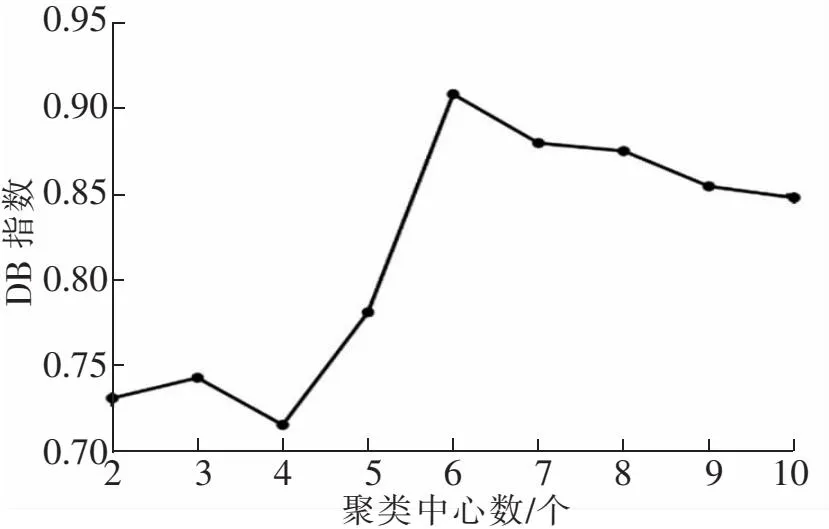
图7 不同聚类数下DB指数
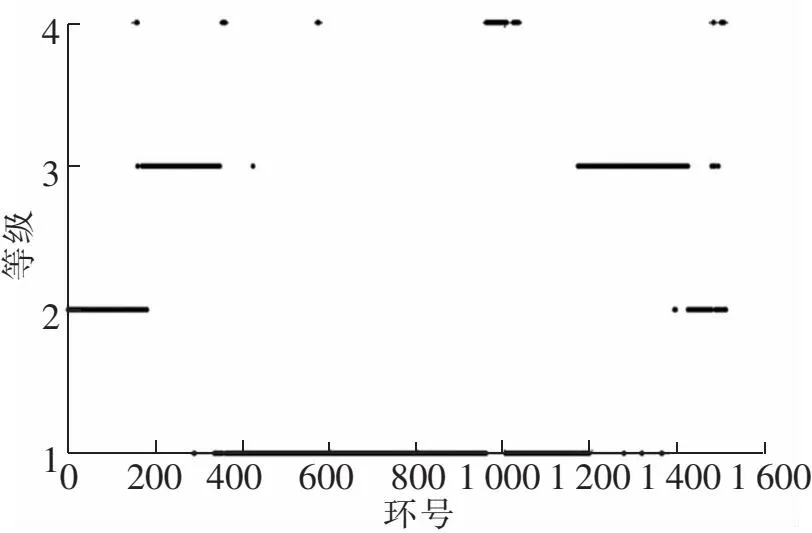
图8 南京长江隧道各环聚类等级
以芜湖过江隧道工程建设初期第13、14环掘进参数为对象,计算可知,其混合指标距离南京长江隧道工程中第3个聚类中心距离最近,因此选取南京长江隧道工程第3等级下212~228环掘进参数对模型进行预训练,以芜湖过江隧道工程中第13环掘进参数对模型进行微调,第14环掘进参数对模型进行验证。
3.2 模型预测
取前一采样时刻的掘进速度、总推力、刀盘扭矩、刀盘转速、贯入度、进浆流量、出浆流量、气垫仓压力和泥水仓压力作为输入数据,搭建CNN-BiLSTM预测模型。采用式(9)归一化方法对数据进行预处理,下一时刻的掘进速度为输出数据对模型进行训练。其中CNN层包含2层1D-CNN,卷积核数目为32和64,卷积核大小为3,激活函数为relu函数,池化层大小为2。BiLSTM层包含2层BiLSTM,神经元数量为32和64,激活函数为tan h,添加Dropout正则化防止模型过拟合。最后添加一层全连接层(Dense)作为模型输出,即下一采样时刻的掘进速度。
3.2.1 模型预训练
在源域(南京长江隧道212~228环)上选取相应参数对模型进行预训练,共5 410条样本,取前5 000条作为训练集,后410条作为测试集对模型进行验证,其中测试集样本包括第227环部分稳定掘进段以及第228环上升段和稳定掘进段,预测效果如图9所示。可以看出,模型能够较好地预测掘进速度的变化,明显预测掘进过程中速度波动点,选取MAE、RMSE为评价指标,并与CNN模型、LSTM模型、BiLSTM模型进行对比,结果如表1所示。可知CNN-BiLSTM模型在预测精度上均优于其他模型,选取该模型可更好地提取输入数据的特征,反映掘进速度和其他掘进参数之间的映射关系。
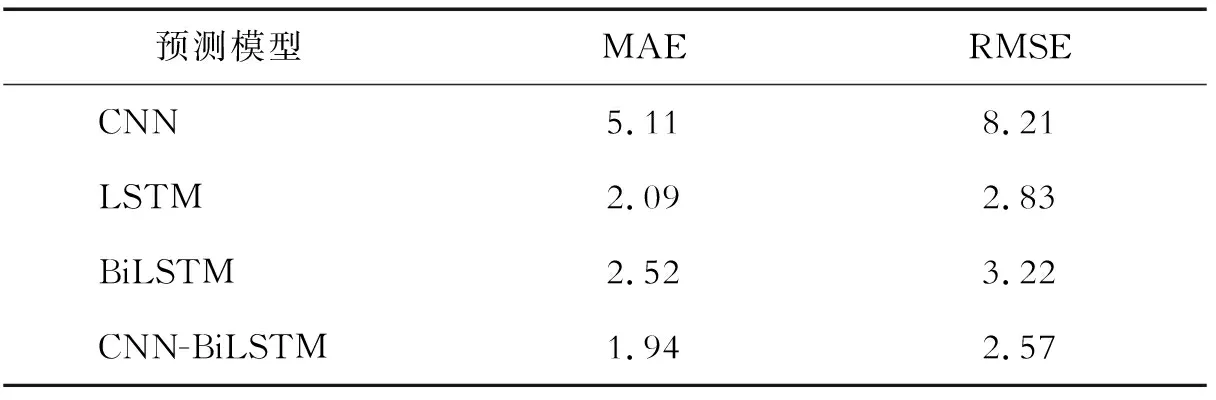
表1 不同预测模型性能比较
3.2.2 模型微调
将预训练模型中的CNN层和BiLSTM层冻结,在目标域(芜湖过江隧道)上选取第13环相应数据对模型全连接层进行微调,在第14环上进行预测,并与不经迁移学习预测结果进行对比,效果如图10所示。
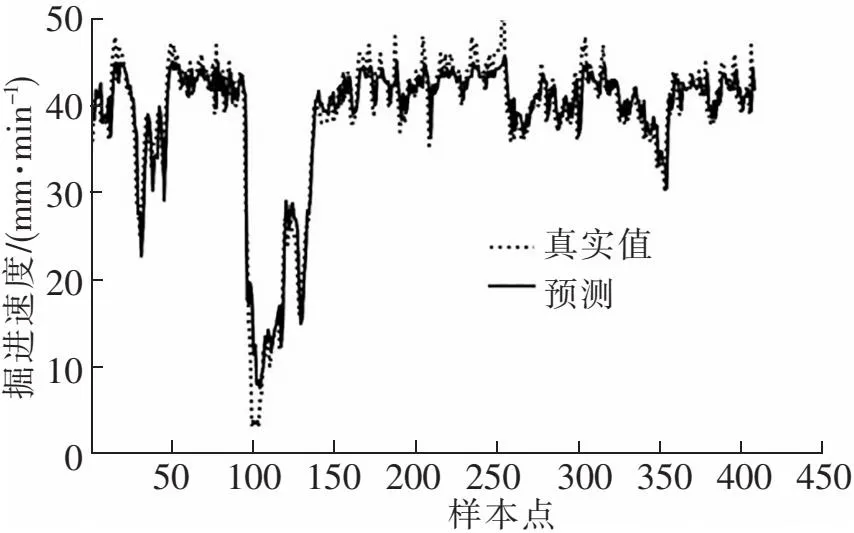
图9 源域预测效果

图10 目标域预测效果
由图10可以看出,模型迁移后可准确预测目标域掘进速度的变化,反映其变化规律,在评价指标MAE和RMSE上的表现分别为1.44和1.92。无迁移模型由于数据量较少,产生过拟合现象,无法正确反映掘进速度的变化,由此可知迁移学习预测模型在工程建设初期的必要性。
4 结论
(1)采用k-means聚类方法,基于FPI、TPI、SE、C4种混合指标,可对盾构机的掘进进行聚类分级判定。
(2)建立的CNN-BiLSTM预测模型,其在源域和目标域上的掘进速度预测值可以很好地拟合实测数据,在源域上的MAE和RMSE为1.94和2.57,拟合效果优于CNN、LSTM、BiLSTM模型,在目标域上的MAE和RMSE为1.44和1.92。
(3)所提模型采用迁移学习策略后,可有效解决在盾构掘进初期数据量较少的情况下,深度预测模型产生的过拟合问题,在工程施工初期具有一定指导意义。
