融合相似性负采样和短期偏好的图卷积推荐模型
2023-12-19韦贵香张园园
韦贵香, 朵 琳, 张园园
1.昆明理工大学 信息工程与自动化学院, 云南 昆明 650504;2.黔南民族职业技术学院 大数据与电子商务系, 贵州 都匀 558022
随着万物互联时代的到来,人们所接触的信息呈现爆炸式的增长,如何从眼花缭乱的数据中挑选出适合自己的项目成了用户的一大困扰。而对信息提供商而言,面对海量的数据,用户的兴趣偏好可能会随时改变,如何为用户推荐贴合其真实偏好的物品是一大挑战。
传统的推荐系统以协同过滤[1]的方式对用户的兴趣进行建模推荐,这种方法存在着数据稀疏和冷启动问题。然而,随着互联网技术的不断发展,用户曝光在各类数据面前,如图像、文本、标签在内的多元异构信息,随之而来的是用户兴趣更加多元化,需要融合多元异构信息来对用户偏好进行学习[2]。知识图谱使用图结构数据模型来表示数据,可以提供丰富的辅助信息而被引入推荐系统[3]。现有的典型知识图谱数据集如Dpedia[4]、Yago[5]和Freebase[6]等规模已经相当大,但是面对庞大的用户数量来说还是不够完备[7]。有学者将图嵌入技术引入到知识图谱的表示学习当中,将知识图谱中的实体和关系映射到低维向量中进行知识图谱补全[8],同时捕获原始连接属性。知识图谱中只有正样本,引入负样本对改进学习模型非常重要。Bordes等[9]通过打乱正样本并随机地对头实体和尾实体进行替换得到负样本。Wang Zhen等[10]引入了一种更好的采样方案,即伯努利采样,通过减少头部和尾部实体之间的一对多、多对多和多对一关系中存在的假负三元组的出现来改进均匀采样。然而,这些方法得到的替换样本与被替换样本相似性低,若进行替换将得到一个低质量的负例三元组,导致学习模型在训练时损失值为0,模型将不会对实体向量与关系向量进行更新,无法获得更多的样本特征的同时还降低了模型的效率。
近年来,深度学习在各领域取得了突破性进展,且深度学习通过组合低阶特征形成更加稠密的高阶语义抽象,从而发现数据的分布式特征表示,解决了传统机器学习中需要人工设计特征的问题;深度学习[11]中的卷积神经网络(Graph Convolutional Network,GCN)可以很好地对序列进行建模而有效挖掘数据的序列结构;此外,基于深度学习的推荐方法能够融入多源异构辅助信息进行推荐,通过将用户的显式反馈和隐式反馈数据、用户的画像、物品的内容和属性等多源异构辅助信息作为输入,采用端到端的方式自动训练预测模型,从而缓解传统推荐系统面临的数据稀疏和冷启动问题。但同时也存在训练时间长、可解释性差的问题。本文利用知识图谱作为辅助信息,采用深度学习技术从辅助信息中学习用户和物品的特征表示,增强推荐系统的性能。
1 相关研究
1.1 知识图谱嵌入学习
近年来,在知识图谱的嵌入表示方面的研究取得了很大进展。知识表示学习的典型模型包括张量模型[12-13]、翻译模型[9,14]和神经网络模型[15-16]。知识表示学习可以捕获知识图中实体的语义信息,并将实体和关系映射到密集向量。在翻译模型中,Bordes等[9]提出TransE模型,该模型侧重于关系三元组中实体之间的关系,并将尾实体向量t视为头实体向量h加上关系向量r的翻译。如果三元组(h,r,t)成立,则头实体向量h、关系向量r与尾实体向量t应满足h+r≈t。Hao Yanchao等[17]提出了一种嵌入式知识库的联合方法JE,同时考虑了嵌入损失的实体向量和对齐向量。Chen Muhao等[18]提出了一种多知识图联合嵌入模型MTransE,与JE模型相比,MTransE提供了多种知识图对齐模型——轴校准模型和基于距离的平移向量模型。但现有的知识图谱嵌入模型在进行训练时往往通过随机使用负样本来对正样本进行替换,这样得到的负样本质量低,导致模型在训练时不能对实体向量和关系向量进行有效更新,对模型训练效率的提升意义不大。
1.2 融合多源信息的表示学习
为了更有效地利用图内结构信息,文献[19]提出一种融合了协同过滤模型FM和图嵌入模型TransE的融合推荐模型CoFM。它将知识图谱中多个实体的信息及其关系作为有效的辅助信息引入推荐系统,可以有效提高推荐的准确性,缓解用户历史交互数据稀疏的问题。文献[20]提出的IPAKG引入知识图来挖掘用户的隐式偏好表达,并将递归神经网络和注意力机制结合起来,捕捉用户不断变化的兴趣以及序列中不同项目之间的关系。文献[21]提出的KGCN-LS应用一个可训练函数通过识别给定用户的重要知识图关系来计算用户的项嵌入,这种方式将知识图转换为用户特定的加权图,然后应用图神经网络来计算个性化项目嵌入。这些方法只考虑了用户的长期兴趣,得到的用户偏好不准确。为了更好地进行推荐,本文将用户的短期偏好引入推荐系统。
2 基于Attention机制的GCN-BiGRU模型
2.1 模型概述
用户的兴趣偏好往往会受时间的影响,有的人一直以来都喜欢看纪录片,但是最近受情绪低落的影响喜欢看喜剧片;有的人一直喜食辣的食物,但是最近因为身体原因喜欢吃清淡的食物。如果这时候根据用户的长期兴趣来对用户进行推荐,往往会适得其反。现有的一些算法只关注用户的长期偏好而忽视用户的短期偏好,不能精准地为用户推荐其感兴趣的物品。本文使用图卷积神经网络提取用户近期交互物品序列的深层次特征并创建知识图谱,然后使用双向门控循环单元(Bidirectional Gating Recurrent Unit,BiGRU)网络对GCN层提取的特征向量学习用户的短期兴趣,并引入注意力机制赋予不同程度的偏好相应的权重,帮助模型更精准地学习用户兴趣,短期偏好学习框架如图1所示。最后,针对在训练中负样本对模型效率的影响问题,本文使用相似性负采样来对负样本进行采样。
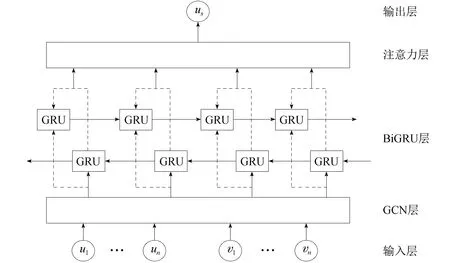
图1 短期偏好学习框架
2.2 预测模型结构
2.2.1 卷积神经网络(GCN)层
将数据转化为知识图谱后使用GCN处理图结构化数据,GCN通过将实体节点的初始表示和其邻居表示聚合到单个向量中,得到包含邻域信息的最终实体表示。GCN一般由卷积层、池化层和全连接层组成。其中,卷积层通过卷积核对数据进行卷积完成特征提取,在卷积层中加入偏置,最终生成多个特征向量;池化层是一个非线性的下采样过程,可以保存任务的相关信息,增加特征向量的接收域,并去除无关信息;全连接层通过将特征映射到神经元来进行分类[22]。本文使用GCN来对用户近期交互的K个序列进行特征提取,得到相应的用户和项目特征向量表示,输入到BiGRU网络中去学习用户的短期兴趣。
2.2.2 双向门控循环单元(BiGRU)层
门控循环单元(GRU)可解决长期记忆和反向传播中的梯度等问题,其网络结构如图2所示。

图2 GRU结构
GRU网络使用的双曲正切tanh激活函数存在软饱和性,当网络加深时会导致梯度消失,本文使用LeakyReLU激活函数代替tanh激活函数,既可以解决双曲正切函数存在的梯度消失问题,又可以避免ReLU激活函数在反向传播过程中由于梯度为0而导致权重不更新的问题。LeakyReLU激活函数如下:
(1)
式中,α是一个数值很小的常数,本文选取α=0.01。在ReLU的基础之上,LeakyReLU保留了一些负轴的值,使得负轴的信息不会全部丢失,调整了负值的零梯度问题。
循环神经网络(Recurrent Neural Network,RNN)具有记忆能力,在学习序列数据的非线性特征方面具有一定的优势。GRU是RNN的一个变体,它能有效地缓解传统RNN训练过程中的梯度消失和梯度爆炸问题。GRU简化了长短时记忆(Long Short-Term Memory,LSTM)网络结构,减少了模型的参数量[23],可用于从用户短期交互的物品序列中提取用户的短期偏好。GRU模型在计算当前状态值ht时考虑了历史信息ht-1和输入向量xt,如公式(2)—(5)所示:
rt=σ(Wr·[ht-1,xt]),
(2)
zt=σ(Wz·[ht-1,xt]),
(3)
(4)
(5)
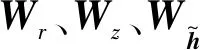
2.2.3 注意力(Attention)层
用户近期的交互序列经过BiGRU网络后得到相应的用户短期兴趣表示,不同的短期偏好对用户偏好的影响程度不同,引入注意力机制来对关键信息分配足够的关注,赋予不同短期偏好以不同的权重,提高对用户偏好建模的准确性。Attention机制层的输入为经过BiGRU网络层激活处理的输出向量ht,根据权重分配原则计算不同特征向量对应的概率,不断更新迭代出较优的权重参数矩阵。注意力计算公式为
gi=tanh(Wattht+batt),
(6)
(7)
式中,Watt、batt为注意力机制的权重和偏置,αi为注意力概率分布值。
得到用户u的短期兴趣us:
(8)
式中,vu,i为用户u对历史交互项目i的偏好分数,将用户短期兴趣us和项目表示v通过内积函数f,以获得用户u与项目v交互的概率。
2.3 实体相似性的负采样方法
负采样的目的是帮助模型进行特征学习训练,由于评分函数倾向于给观察到的(正)三元组赋予较大的值,随着训练的进行,大多数未观察到的(可能是负的)三元组会被赋予较小的值。因此,当使用随机采样方法来对负三元组进行采样时,可能会采样到梯度为0的负三元组,导致在知识图谱的嵌入训练中出现梯度消失的问题,不能帮助模型进行有效的特征学习。
知识图谱的嵌入表示学习主要有基于翻译、张量分解和神经网络的模型,本文基于翻译模型使用相似性采样方法对负样本进行采样。在这类模型中,知识图谱中的实体和关系被映射到低维向量空间中,对于头实体向量h、关系向量r和尾实体向量t要满足h+r≈t的近似条件,即h要满足t-r的限制条件。在向量空间中,两个向量之间的距离越近,则两个向量越相似,进行替换得到的负三元组质量越高,因此,我们提出一种基于实体相似性的负采样方法。首先,使用TransE算法从知识图谱中抽取每个实体的特征向量表示;然后,将提取的实体特征向量输入到K-means聚类模型[24]中进行聚类。与传统的K-means聚类算法不同,本文将实体按照其所在的关系类型进行聚类,即将同一关系类型下的实体聚集在一起。聚类的目的是将相似的实体分配到同一个簇中,从而减少模型需要处理的实体数量,提高训练效率。计算每个实体与每个质心之间的欧式距离,并将其分配到距离最近的质心所在的类别。公式为
(9)
式中,αi表示样本xi与所有向量距离最近时所在的簇,μj表示该簇质心。将样本分成K个簇之后,将每个簇中所有实体特征向量的平均值作为新的质心,重新计算每个簇的质心:
(10)
式中,当xi∈αi时,rij=1;当xi∉αi时,rij=0。重复划分聚类和更新聚类中心两个步骤,直到所有聚类中心不再改变,其损失函数为
(11)
本文使用简单有效的K-means聚类算法将相似度高的实体聚类在一起,与伯努利采样每次采样都要从整个实体集中进行选择不同,本文每次只要从实体所属的簇中选择与该实体距离最近的实体进行替换,减少了模型的计算量,在一定程度上提高了负样本的质量,使表示模型的性能得到了提升。
3 实验及分析
3.1 数据集
本文在MovieLens-1M、Book-Crossing和Last.FM数据集上进行了实验。其中MovieLens-1M是推荐模型中广泛使用的基准数据集,由MovieLens网站上约2×107条评价历史构成;Book-Crossing数据集是从Book-Crossing社区收集的,它包含139 746条评分记录(从0到10)对应的14 967个项目和17 860名用户;Last.FM是从在线音乐系统Last收集的音乐收听数据集,此数据集用于链接预测任务,并且此数据集中不包含任何标签或要素。
3.2 实验环境
本实验程序在基于X64处理器的Windows10系统,10th Gen Intel(R) Core(TM) i5-11320H@3.20 GHz,16.0 GB内存,Pycharm2018,Python3.8环境下运行。实验中基于深度学习的模型均由NVIDIA GeForce GTX 1050 4.0 GB、基于Python的TensorFlow包、i7-7700HQ、16.0 GB内存环境下进行训练。
3.3 对比模型
本文将采用随机负采样方法的TransE[9]、TransH[14]、TransR[25]、TransD[26]模型来作为链接预测对比试验。使用Ripple-Net[27]、KGCN[28]、KGCN-LS[21]、KGAT[29]模型来进行点击率(CTR)预测和TOP-K预测对比试验。
3.4 评价指标
链接预测的对比实验中使用平均倒数排名(Mean Reciprocal Rank,MRR)和正确实体排在前N名的概率(Hits@N)来衡量链接预测的效果,使用ROC曲线下方的面积(AUC)、召回率(Recall)、精确率和召回率的调和平均数(F1)指标来衡量模型的点击率预测和TOP-K预测效果。
其中,MRR是一个比精度(Precision)更加全面的指标,不仅考虑了模型的推荐结果是否准确,还考虑了准确推荐在推荐列表中的排序。计算公式为
(12)
式中,|U|表示用户数,ranku表示用户真实偏好对应的物品在推荐列表中的排名。如果该物品不在推荐列表中,则ranku取无穷大;MRR越大,推荐系统的性能越好。
Hits@N是一种常用的评估链接预测效果的指标,将正确实体排在前N名的概率作为效果的评价指标。
AUC为ROC曲线覆盖的区域面积,计算的是结果中正样本排在负样本前的概率,可以有效衡量推荐结果的准确性。
Recall表示测试集中用户交互过的项目出现在TOP-K推荐列表中的比例。Recall值越高,代表推荐系统性能越好,表达式为
(13)
式中,U表示用户集,L(u)表示用户u的TOP-K推荐列表,B(u)表示测试集中与用户交互的项目集。
3.5 链接预测
链接预测是指预测一个三元组中缺失的实体或者关系,将测试三元组中缺失的实体或关系视为正确的实体或关系,除此之外称为候选实体或候选关系。本文在Last.FM数据集上进行实验,以评估本模型和其他基线模型在链接预测任务中的性能。将Last.FM数据集中链接的用户-艺术家对视为正节点对,4种基线模型使用随机替换样本的方法来进行负采样,本文模型则使用相似性负采样方法来对未连接的用户-艺术家链来进行负采样,将负样本根据得分进行排序。
链接预测的对比模型中的TransE、TransH、TransR、TransD均使用随机替换的方法给三元组进行负采样,使用平均倒数排名(MRR)和正确实体排在前N名的概率(Hits@N)来衡量链接预测的效果,表1记录了5个模型链接预测的结果。
如表1所示,本文提出模型的MRR和Hits相较于随机负采样模型都有较大的提升,首先,本文使用简单高效的K-means聚类将相似实体聚类在一起,每次负采样只需要在簇内进行选择,提高了计算速度;其次,本文使用在向量空间中与目标实体最相似的实体进行替换,提高负三元组的质量,大大提升了模型训练的效率。
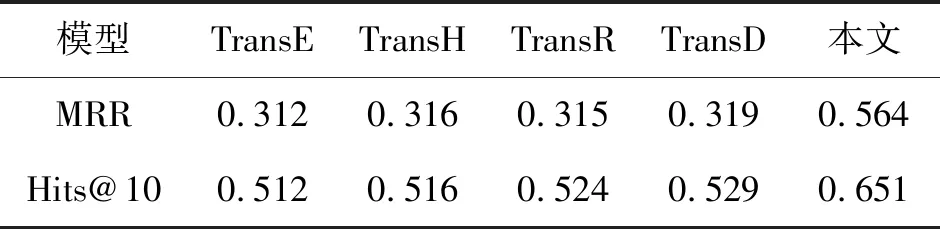
表1 Last.FM数据集的链接预测结果
3.6 点击率(CTR)预测
表2列出了点击率预测的实验结果。从结果可以观察到本文模型(SPKG)相较于其他模型在AUC和F1指标上都取得了最好的效果,在movielens-1M、Book-Crossing、Last.FM数据集中相较于性能表现最好的模型KGAT分别有AUC值1.7%、2.3%、4.5%的提升,F1指标有2.1%、2.7%、1.8%的提升。由此可见,将知识图谱作为辅助信息引入推荐系统挖掘用户和项目之间的深层次特征,可以提高推荐的准确性;其次,使用基于注意力机制的GCN-BiGRU网络来对用户的短期兴趣进行建模,可以更准确地学习用户偏好。

表2 不同模型在点击率预测场景下的AUC值和F1值
3.7 Top-K推荐对比
在Top-K任务中,本文取K=5、10、20、30、40、50六种情况,在3个数据集上进行实验,结果如图3所示。
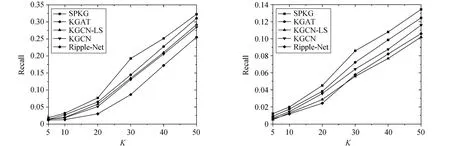
(a) Movielens-1M (b) Book-Crossing

(c) Last.FM图3 不同模型在Top-K预测场景下的Recall@K值
如图3所示,随着推荐项目数量的提高,5种推荐模型的召回率(Recall)逐渐提高。在MovieLens-1M数据集中,当K=30时,本文模型在召回率上相较于KGCN-LS模型提高了6%,较Ripple-Net模型提高了10%;在Book-Crossing和Last.FM数据集中召回率较对比模型也有一定的提升。说明对近期交互的序列进行用户短期兴趣建模更能描述用户的兴趣变化,最终得到的用户兴趣与真实的用户兴趣更为相近。
4 结论
针对现有基于知识图谱的推荐系统存在的没有充分考虑近期因素对用户偏好的影响和在训练知识图谱表示模型时负样本质量低的问题,本文引入基于注意力机制的GCN-BiGRU网络来从用户的近期序列中学习用户的短期兴趣,使用相似性采样方法来对知识图谱中的实体进行负采样,提高了负三元组的质量。使用本文模型与其他8种模型进行对比实验,实验结果表明,本文提出的模型基于其他基线模型并有了一定的提升,充分说明了相似性采样能够提升模型效率,融合知识图谱和短期偏好能够提高系统的推荐精度。在接下来的工作中将研究使用其他丰富的辅助信息来对知识图谱进行补全,增强知识图谱对用户偏好的建模能力。
