机器学习工程实践教学探索
2023-12-11王建花
王建花, 朱 凡, 茆 姝
(1.南京理工大学工程训练中心,南京 210094;2.浙江海洋大学船舶与海运学院,浙江舟山 316000)
0 引 言
目前,人工智能已成为各国新一轮科技和智力领域的必争之地[1]。人工智能的发展依托于算力、数据和机器学习算法等技术的发展,其中机器学习算法是计算机具有智能的直接原因,是促进人工智能发展的核心。
2018 年4 月,教育部发布的《高等学校人工智能创新行动计划》(教技(2018)3 号),提出要围绕新一代人工智能优化学科体系布局,提升人才培养质量,为我国跻身创新型国家前列提供科技支撑和人才保障[2]。各高校都积极开展“新工科”研究与实践[3-4],将人工智能与各学科专业教育交叉融合,以建设人工智能课程、建设区域共享型人工智能实践平台、建设多主体协同育人机制等多种形式培养人工智能人才[5]。当前高校人工智能教学中,大多数本科生缺少了解机器学习解决实际问题的流程途径,更缺少机器学习项目实践机会。针对本科生的工程训练实践课程,有必要开设配套于机器学习理论知识的基础实践课程,帮助学生理解利用机器学习方法解决实际问题的流程。
1 机器学习工程
1.1 项目流程
Tom Mitchell 认为“机器学习这门学科所关注的问题是:计算机程序如何随着经验积累自动提高性能[6]”。机器学习的核心价值是通过特定算法分析已知数据,识别隐藏在数据中的可能性,并基于此给出预测或辅助使用者进行决策。机器学习使用企业提供的研发、生产、经营等各方面数据来训练、修正、完善算法模型,再用模型为企业解决实际问题,创造价值,这个流程如图1 所示。

图1 机器学习解决问题的项目流程
在业务领域,企业提出要解决的业务问题,并根据业务知识给出有效的业务模型、数据模型、解决目标等信息。在人工智能领域,用人工智能知识指导进行数据收集、数据处理、特征工程、模型训练等步骤以得到合格的机器学习模型。最后,企业将合格模型用适合业务生产的方式部署,并在专业人员指导下对模型进行运维。这个流程中业务问题能否用机器学习方法解决以及数据适用性评估过程由业务领域和人工智能领域专业人士共同完成。
1.2 教学现状
目前部分高校已开设机器学习类通识教育课或专业课,其中不乏国家级精品课程,这些课程大多以知识体系教学为主,注重教授机器学习的理论知识,而基于项目的工程实践类课程较少[7-8],且多数实践案例使用的数据、特征等都是已处理好的。机器学习领域有一个共识:数据和特征决定了机器学习的上限,而模型和算法只是让我们逼近这个上限。可见人工智能教学除了注重理论算法之外,也要注重问题模型建立、数据收集、数据处理、特征选择、模型部署和运维等过程[9]。
部分高校也认识到有必要将人工智能实践项目引入到工程训练课程中,在工程训练课程使用了特定的人工智能平台,借助平台能力完成某个业务领域具体的工程实践[10-11],这种工程训练课程针对业务领域内容较多,分散了学生对机器学习工程知识的注意力,也增加了理解难度。
高校工程训练教学是衔接学生的理论知识和社会生产的桥梁,有必要在授课过程中尽量完善机器学习工程的完整流程。
2 实践教学课程设计
2.1 教学目标
为了让学生能更贴近实际问题,本课程选用学生容易理解的企业项目案例,老师和学生一起研究企业业务和数据处理中的各类问题,引导学生经历实际项目全流程,从而达到理论与实践相结合,培养学生解决实际问题的能力。教学中让学生对问题、目标、数据适用性评估、数据收集、数据处理、特征工程、模型训练等过程有了更全面的了解。对于理论课程很少涉及的数据和特征两个方面,着重引入数据整理及特征工程的一些基本方法和手段。
学生除了在课堂学习机器学习知识,也可通过参与各种比赛来提高自己。机器学习竞赛是这个领域发展的有效助推剂和交流平台,比较著名的竞赛有Kaggle、天池等[12]。本课程给学生介绍参加这些竞赛的途径和必须具备的技能,鼓励学生参加竞赛锻炼自己的创造力和才干。
2.2 教学内容
根据课程教学目标,教学内容以某个企业项目为案例,完成一次完整的机器学习项目流程,并让学生重点实践数据处理、特征工程两个环节,如图2 所示。

图2 项目教学内容及流程
(1)问题分析及项目建立。首先向学生展示一个具体的业务问题,引导学生分析问题,寻找解决问题的方法,并判断是否可以用机器学习技术来解决。明确后将问题、目标、解决方案、团队组建、过程计划等以项目的方式运作。
(2)数据处理。确立机器学习项目后,学生进行目标问题的数据处理。此过程将目标问题用数据来表征,可进一步细分为数据适用性评估、数据收集和数据整理三个子过程,如图3 所示。数据适用性分析是对目标问题能否用数据表征、数据能否获得、数据需要具备的质量和规模等方面进行可行性评估,涉及问题的业务领域知识较多,需要丰富的专业知识支撑,这也是数据对机器学习项目重要性的一个体现。数据收集是从生产现场或其他途径获取样本原始数据的过程。数据整理在原始数据中提取有效数据的过程,即根据数据特点和算法要求来整理数据,得到数据集。

图3 数据处理过程
(3)特征工程。特征工程开始于将数据集划分成训练集、测试集和验证集。从数据集中取出少量样本作为验证集,剩余样本进一步分为训练集(大部分样本)和测试集(少量样本)。特征工程就是对数据集的属性进行取舍,进而训练模型达到预期性能。取舍方法因机器学习算法、数据集特点及项目目标等因素而不同,常见的方法有特征选择、特征缩放、特征合成以及特征降维等[13]。有时会因为数据质量、样本数量等达不到算法要求而需要再回退到数据处理过程继续修正数据或补充采集数据样本。
(4)模型训练及评估。模型训练是学生运用训练集、测试集和验证集输出模型的过程。首先采用经过特征工程处理后的训练集来训练模型,再采用测试集对训练出来的模型性能进行测试。如果模型性能未达预期,则需从特征工程或数据处理过程开始重新分析和优化;如果模型性能达到预期,即可用验证集进行模型评估,模型识别的准确性符合预期时项目目标可达成,否则要重新讨论问题模型是否正确、选择的算法是否合适、数据处理和特征工程过程中哪些步骤要改进等。可见,训练过程和验证过程可能会因为无法达到理想效果而回退到特征工程或数据处理过程重新迭代处理。
通过上述过程实践,学生了解到人工智能项目的处理流程并不是单向流动的,而是对整理数据、分析、训练、测试、评估过程的多次迭代,直到达到项目目标。
2.3 教学实践
本课程主要面向对人工智能感兴趣的本科生,由于多数学生在人工智能方面的理论知识较少和实际经验不足,实践课程必须以学生能理解为基础,故教学案例所需的专业知识及讲解的特征工程的方法都是易于学生理解的。通过简单易懂的案例实践,建立学生掌握机器学习的信心。
2.3.1 项目建立的教学实践过程
本课程引入企业项目“机器学习识别计算系统故障”作为教学案例。目标问题“计算系统故障”对于电子类本科生不难理解,计算系统由软件和硬件组成,在计算系统运行期间,系统会随时对运行状态进行记录,但系统只能片面被动地记录运行状态,要分析出故障的原因则需要专业人员做大量的事后逻辑推理。在此引导学生思考能否用一个机器学习模型,通过系统的运行数据直接分析出故障原因,替代人工分析。事实上只要能够积累足够的故障数据样本,就可以用这些数据样本训练出机器学习模型。系统下次有故障时,将故障数据输入此模型,就能快速识别出是什么类型的故障。通过以上分析和引导,组织学生建立“机器学习识别计算系统故障”项目的目标,即训练出一个机器学习模型来识别系统故障。
2.3.2 数据处理的教学实践过程
确立项目目标后,即可进行数据适用性分析、数据收集和数据整理,这部分涉及目标问题领域知识较多,学生仍然以理解和思考为主。计算系统运行时会记录日志,日志以文本形式存储到磁盘,内容包括事件发生的时间、各模块运行状态和描述事件的关键字等。比如系统运行期间,某个硬件不稳定,会让使用此硬件的软件模块记录对应失败事件日志。图4 展示了一个硬件故障的日志片段。

图4 计算系统故障日志片段
系统运行一段时间后可以获得大量的日志,找出历史上故障发生的时间,可为这些日志打上具体故障类型的标签。本案例将故障类型分为软件故障、硬件CPU故障和硬件主板故障。可以根据系统的设计方案将日志中的事件分类为问题相关的属性。本案例中计算系统自动输出日志文件,数据收集过程就是获取每个故障的日志文件。再用python 编写程序从日志文件中提取故障时间段的各类事件次数,将其作为对应的属性值记录下来,同时对本故障打上类别标签,这样就完成了一个故障样本数据的整理。从系统运行一段时间保存的数百万条数据中按上述处理,筛选出2 982 个故障样本和18 个属性作为本案例的原始数据集,如图5 所示。图中数据集列标号1 ~18 为属性,0为样本序号,19 为每个样本的故障标签。

图5 数据集信息概况
2.3.3 特征工程的教学实践过程
特征工程的目标是构建适合算法要求的数据和改善机器学习模型的性能。为了便于学生理解,本案例通过直接查看csv文件或使用pandas工具来引导学生实践常用的特征选择方法。
(1)异常值和缺失值观察。在数据收集和处理过程中,可能会出现数据异常或缺失。pandas 的DataFrame类型数据的describe()方法可以呈现每个属性列的最大值、最小值、均值等数值分布情况,而isnull().sum()方法可查找出数据集中的缺失值。
分析出缺失值和异常值后需进行处理。在样本足够多时,可以删除缺失值或异常值的样本。在样本数量不充裕时,一般用0、此属性列的中值或均值来填充缺失值或异常值。有时异常值也可以不处理,而选用能容忍异常值的算法。
(2)训练集、测试集和验证集划分。划分样本时,先人工随机从各类样本中各挑选出10 个留作验证集,再从剩下的各类样本中各挑选出大约10% ~20%作为测试集,其余为训练集。在此提前将样本进行划分,还能在后续机器学习中防止信息泄露,即算法在训练时不能提前感知到测试集或验证集中的信息,以保证训练出的模型有最好的泛化效果。实际生产中依据样本情况,可以选用更适合的划分方法,如K 折交叉验证法、自助法、留出法等[14-15]。
(3)样本标签的类平衡性观察。查看数据集样本标签,分析是否存在类不平衡问题。如果数据集中某类样本太少,不满足训练和验证要求,则需要继续收集数据,直至获取到足够的样本为止。如果数据集中每类样本数量足够,只是分布比例严重不平衡,则只需要对训练集采用过采样、欠采样等方法对样本类进行平衡。本案例数据集中3类故障样本的数量比是31.8%∶31%∶37.2%,相对平衡,不用实施类平衡方法。
(4)特征选择。在处理完缺失值、异常值和类平衡性问题后,需要再观察训练集各属性的有效性以确定哪些属性作为特征。各属性的统计数值含义为:0表示某样本没有此属性;非0 表示有此属性的样本个数。故某属性的0 数值占比越大,此属性作为特征的有效性越低。所有数值都是0 的属性对训练无价值,可删除。大部分数值为0 的属性称为长尾属性,为了提高训练速度,在不降低训练性能的前提下,可删除训练集中的1 个或多个长尾属性。本案例通过多次尝试对比,选择删除2 个长尾属性,对应的耗时数据如表1所示。在大数据集复杂算法的工程中删除长尾属性提升训练速度的效果更明显。
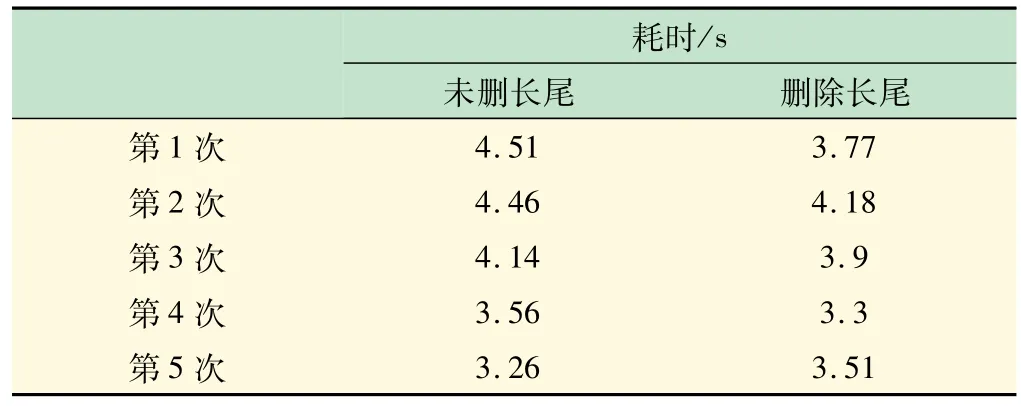
表1 删除2 个长尾属性的训练耗时
2.3.4 模型训练和验证的教学实践
本案例为多分类问题,特征较多,选择xGBoost 算法进行训练。训练和验证流程如图6 所示。模型训练过程和专业知识、数据处理、特征工程等密切相关,需通过反复迭代以确保达到理想效果。

图6 模型训练和验证流程图
特别地,在本案例训练过程中,发现属性1 作为特征的模型性能:训练准确率88.24%,验证准确率为83.33%。属性1 不做特征的模型性能:训练准确率91.18%,验证准确率为86.67%。分析发现几乎每个故障在该属性上都有表征,此属性属于预测能力非常差的特征,也应删除。需要注意的是,对训练集数据删除属性时,在对应的测试集和验证集中也需同步删除。
3 结 语
本文探索了机器学习教学在面向本科生的基础工程训练课程中的实践。选用学生容易理解的项目案例,引导学生经历项目全流程,着重实践了数据处理及特征工程的一些基本方法和技术。通过基础实践课程的开设,使得更多的学生能实践机器学习项目。在后续教学过程中,可进一步建设机器学习实践平台,引入更多与不同专业相关的实验案例,学生可根据自己专业选择合适的案例实践机器学习工程。
