基于混合深度神经网络的异常检测方法
2023-12-11刘汉忠黄晓华
邱 鹏, 刘汉忠, 黄晓华
(南京工程学院a.计算机工程学院;b.先进工业技术研究院,南京 211167)
0 引 言
随着工业控制系统越来越频繁地连接到企业局域网和互联网,系统管理变得更加便捷,维护成本大大降低,也更容易面临各种网络攻击。例如工业控制系统的监控与数据采集(Supervisory Control And Data Acquisition,SCADA),它不同于传统的互联网运行维护,安全软件补丁和频繁的软件更新并不适合SCADA的安全维护,它通常要求高可用性、静态拓扑和常规通信的运行模式。鉴于SCADA 的特殊性,如何快速检测系统异常,如何采用高效的异常检测方法确保系统的安全性,已成为目前工业控制系统异常检测中所面临的一个重要问题。
目前适用于SCADA的异常检测方法主要有:
(1)监督神经网络法[1-3]。将训练数据标记为“正常”或“异常”,然后训练系统区分“正常”或“异常”并观察结果,将新的数据结果分类为“正常”或“异常”类别,但是,对庞大的数据集采用人工标记的方法本身难以实现,并且会耗费大量时间,同时增加出错的概率。
(2)流量异常检测法[4-5]。使用技术手段学习系统的正常行为,并试图识别流量中的异常,即区别于正常行为的流量。这种检测方法准确率低,误检率高。
(3)基于模型或规范的检测法[6]。创建一个获得授权的工业控制系统模型并制定系统运行的相应规则,当观察到模型的行为与规则不匹配时发出警报。其缺点是在现实中很难百分之百模拟一个工业控制系统模型。
本文提出的混合深度神经网络的异常检测方法,在SCADA遭到入侵攻击或发生异常时,构建栈式稀疏去噪自编码器深度神经网络(Stacked Sparse Denoising Auto-encoder-Deep Neural Network, SSDADNN)模型并为其添加监督层,进行无监督特征学习,使用分布式训练策略来加快异常检测进程,可解决现有技术中异常检测方法准确率低、误检率高以及需要消耗大量时间等问题。
1 数据预处理
基于混合深度神经网络的异常检测模型如图1 所示,由数据预处理引擎和异常检测引擎组成。在进行异常检测之前需要预处理特征数据,包括归一化特征标准、数据拆分与均衡以及独热编码等一系列预处理措施。

图1 基于混合深度神经网络的异常检测模型
1.1 归一化特征数据
将数据集特征值按比例缩放,使得数据落在特定区间[0,1]之内,即归一化值[7]
式中:F为系统某一特征;x为描述F特征的数据集中的某一特征值;max(F)和min(F)分别为F的特征值的最大值和最小值。
1.2 数据拆分
将数据分割成互不相交的训练数据集、验证数据集和测试数据集,占比分别是60%、20%和20%;在训练集对模型进行训练并周期性使用验证数据集对模型性能进行评估,以避免过度拟合,如神经网络发生过度拟合,即当验证数据集正确率持平或下降时,则停止训练并调整神经网络本身的参数和超参数;利用测试数据集评估神经网络训练完成后的最终预测模型,且测试数据集只使用一次。
1.3 数据均衡和独热编码
数据均衡预处理操作是依据数据分布,从占较少的一类样本中重复随机抽样[8],将所得样本扩充至数据集,以改善由于建模产生的数据集失衡,实现类别平衡。独热编码操作是在表示特征分类时,编码一组由位信息组成的向量表示,只设置一个列值为1,其余列值全为0,与输出函数输出的概率向量进行损失分数计算[9]。
2 混合神经网络和监督分类器
图1 中的异常检测引擎模块混合深度神经网络由SSDA-DNN构建而成,其结构如图2 所示。
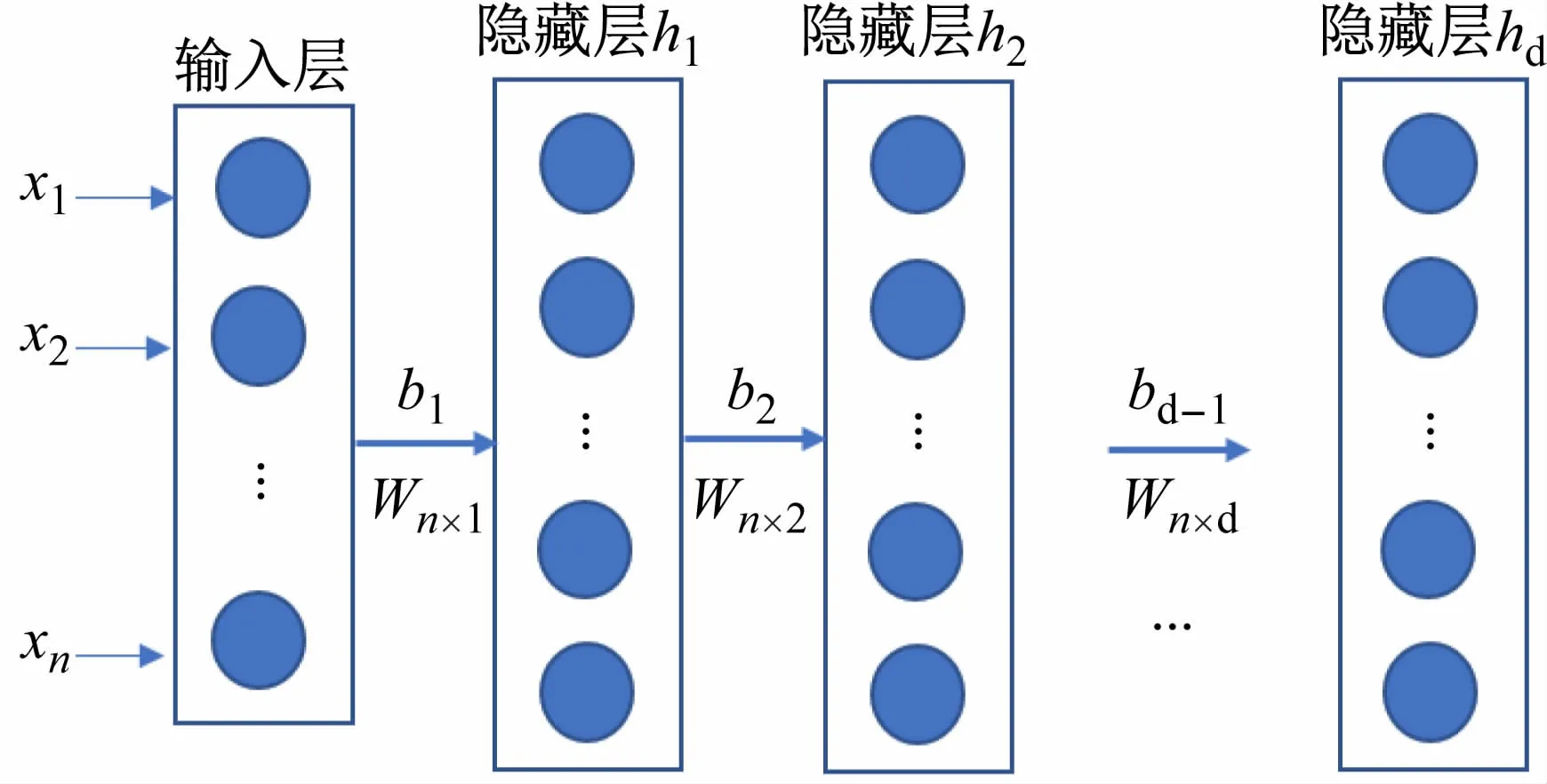
图2 混合深度神经网络
2.1 构建SSDA-DNN
步骤1 将系统数据集特征值作为第一个稀疏去噪自编码器的输入,用x=(x1,x2,…,xn,n>0)表示,该编码器的隐藏层h1带有一定数量的节点,同时丢弃该编码器的解码器部分。
步骤2 将第1 个稀疏去噪自编码器隐藏层h1作为第2 个稀疏去噪自编码器的输入,用h2表示第2 个稀疏去噪自编码器的隐藏层,同时丢弃该编码器的解码器部分。依此类推,一直进行堆栈处理至第d个稀疏去噪自编码器,其输入层是第d-1 个编码器的隐藏层hd-1,其隐藏层是hd。输出层节点用y=(y1,y2,…,yn,n>0)表示。SSDA-DNN的输入层到隐藏层的权重矩阵和偏差项分别用wn×d和b=(b1,b2,…,bd-1)表示。
步骤3 在设置深度神经网络层数时,深度神经网络越深,则训练深度神经网络模型需要的时间就越长[10],在模型中利用稀疏参数,设置隐藏层的节点数大于输入维度。
2.2 混合深度神经网络无监督特征学习
对SSDA-DNN中每一个自编码器的编码部分进行单独训练,重建其输入特征值,进行混合深度神经网络无监督特征学习。
使用均方差代价函数[11]优化自编码器模型的参数
式中:θ 为参数变量;m为训练样本的个数;hw为连接输入到隐藏层的权重;B是隐藏层的偏差向量;xi为训练样本第i个输入特征值;yi为训练样本第i个网络输出值。(hw,B(xi))则为真实标签。
只允许隐藏层的少量神经元激活状态稀疏参数
式中:g为隐藏层的神经元数量;ρ 为模型学习隐藏层中输入数据的稀疏参数所有训练样本隐藏层第i个单元的平均激活值。
在式(2)的基础上加入一个权值衰减进行正则化,加入稀疏参数后的代价函数:
式中,j、β为控制稀疏性惩罚因子的权重。
2.3 添加监督分类器
为混合深度神经网络添加监督分类器[12],主要是用来解决多元分类模型问题。将数据集按照多元分类标签进行分类,其中正常行为记录的分类标签为0,异常攻击记录的分类标签为(1,2,…,z,z>0);再将Softmax函数层作为一个监督分类器,用于混合深度神经网络输出层的激活函数。
2.4 多元分类模型
由Softmax 函数层计算出所有类的概率分布,换句话说就是通过Softmax函数层的argmax 函数获得所有类中的最大概率值。具体方法是在给定输入向量x中计算第u类的预测概率:
式中:W为权重向量;k为输出类别数量;Wu、Wv分别为第u、v类的权重向量;bu、bv分别为第u、v类Softmax函数每一个输出单元从输入层到隐藏层的偏差项。模型的预测值(具有最大概率值的类):
3 训练异常检测引擎
异常检测引擎模块由混合深度神经网络和监督分类器组成,如图3 所示。通过训练异常检测引擎模块来完成异常检测。
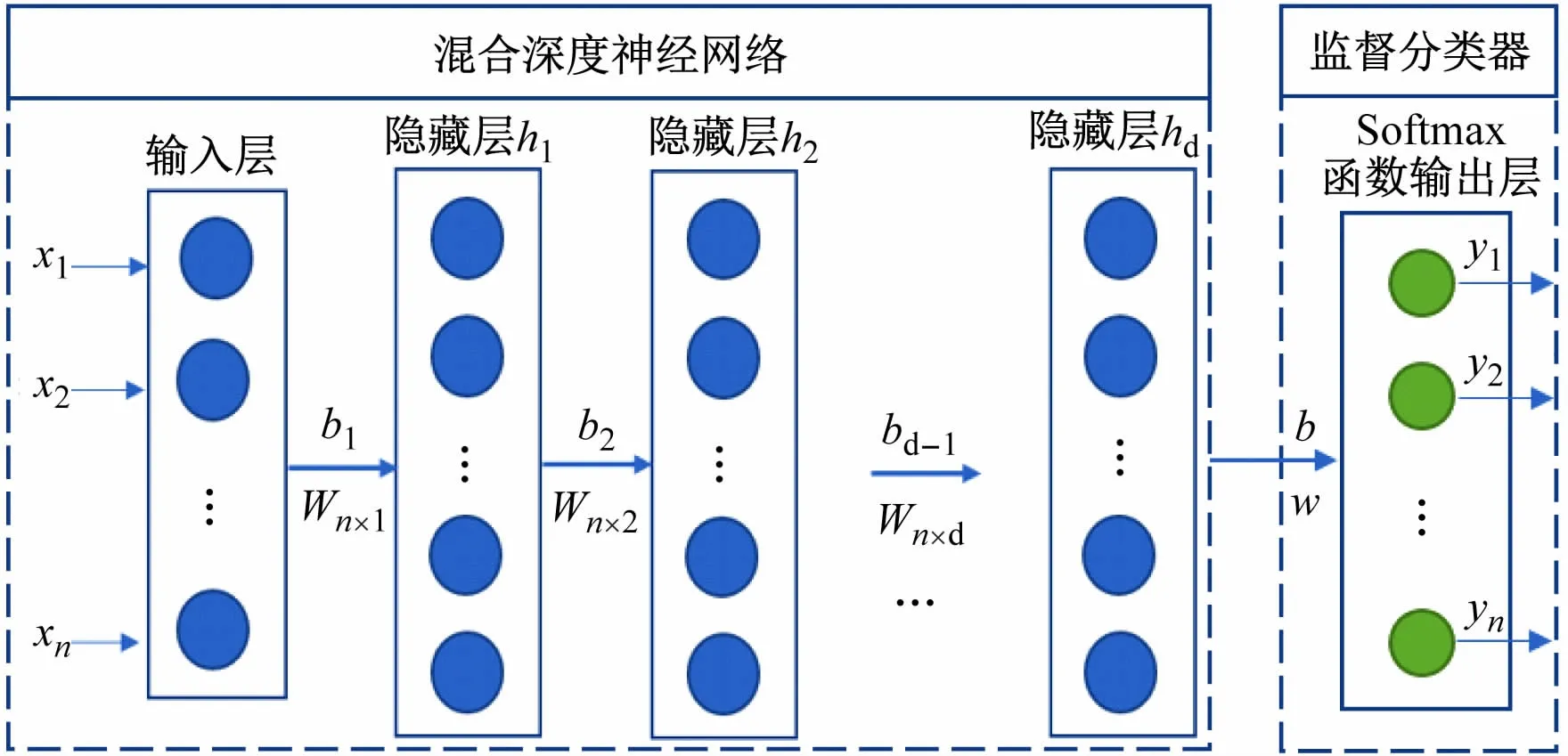
图3 异常检测引擎模块
3.1 交叉熵代价函数
利用交叉熵代价函数[13]训练混合深度神经网络和监督分类器,以最小化交叉熵。利用交叉熵代价函数D(L,Q)测量独热编码标签数据的真实分布概率L={l1,l2,…,lN}和Softmax函数输出的分类数据的分布概率Q={q1,q2,…,qN}之间的相似性:
式中:N为样本类别数;r为样本中的第r类属性。
3.2 训练混合深度神经网络
训练混合深度神经网络的第1 个稀疏去噪自编码器,第1 个隐藏层h1的编码表示特征作为第2 个编码器的输入,训练第2 个稀疏去噪自编码器,第2 个隐藏层h2的特征作为下一个编码器的输入抽象表示,训练最后一个自动编码器d,第d—1 个隐藏层hd-1作为它的输入特征抽象表示。
3.3 训练监督分类器
对监督分类器的Softmax 函数层进行监督训练,Softmax函数层有n个节点,对应着n个不同类型的记录数据集,这一层作为输出层附加在混合深度神经网络之后,训练该层时使用带有标签的数据集。
通过之前完成无监督特征学习和分类训练确定混合深度神经网络参数,如:权重、偏差项和标签训练集。应用梯度下降法,对异常检测引擎实行进一步微调,使用标签测试数据集评估系统的异常检测能力,直至网络收敛,最小化重建误差,提高分类精度。
3.4 分布式训练
采用数据平行的分布式训练[14]来加快计算随机梯度下降,以减少异常检测时间。基于TensorFlow 框架,训练数据集在变量服务器和工作点A、B和C之间来回传输。变量服务器保存权重向量W 并分配给工作点作为工作负荷,工作点则负责在反向传播训练算法中计算梯度。把来自工作点的梯度计算结果c反馈给变量服务器,用于优化权值并再次传播给工作点,最终得到梯度加权平均值,用于更新整个模型的参数,以缩短梯度计算耗时,图4 为混合深度神经网络分布式数据训练过程图。

图4 混合深度神经网络分布式数据训练过程
4 仿真分析
实验平台是通过Openstack 云计算管理平台建立云基础架构服务,设置一个海杜普(Hadoop)分布式系统基础架构集群,它包括1 个主节点和5 个工作节点,每个节点含8 核心虚拟CPU,8GB内存,10GB硬盘,运行Ubuntu 18.04.2 LTS服务器操作系统,深度学习训练由基于Python 2.7 语言的分布式TensorFlow 2.0 支持,主节点上的海杜普分布式文件系统用于存储SCADA数据集。实验数据使用某大学建立的实验室规模的燃气管道系统作为工业控制系统SCADA 数据集来源。燃气管道系统使用PID控制器来保持管道中的空气压力,系统的数据集包含正常记录和攻击记录,见表1。

表1 数据记录分类表
表1 数据集按照多元分类方式分成了1 类正常行为(标签是0)和5 类攻击行为(标签为1 ~5)。为避免不必要的训练偏差,对占比60%的训练数据集进行数据平衡处理,占比20%的测试数据集则使用原始系统数据。图5 所示为将异常数据进行多元分类时燃气管道数据训练集和测试集类型图,使用独热编码计算方法处理所有数据标签。
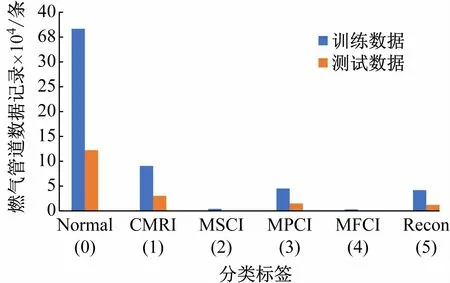
图5 分类燃气管道数据训练集和测试集类型
设计SSDA-DNN 时,定义训练参数和超参数,其中学习率为1%,稀疏参数为0.05,噪声水平为35%。采用多元分类划分数据集,隐藏层数为2,设置的第1层隐藏层节点数是58,第2 层隐藏层节点数是34,输入层节点数为24,输出层节点数为6,训练迭代次数为50。
4.1 对比协调平均值及假阳性率
选用精度与召回率的协调平均值(F1-score)和假阳性率作为评估异常检测方法的评价指标,精度表示衡量异常百分比的精确程度,召回率为正确检测出异常的比例,由于精度和召回率是相互制约的两项指标,所以使用精度与召回率的协调平均值综合权衡精度和召回率,假阳性率是将正常行为错误地识别为异常行为的比例。
通过混合深度神经网络的异常检测方法与其他异常检测算法进行比较,用于对比的标准异常检测算法包括决策树算法[15],朴素贝叶斯算法[16]以及随机森林算法[17]。仿真结果如图6 所示,所提异常检测方法无论是在检测正常行为特征还是在检测5 种异常攻击,获得的精度与召回率的协调平均值百分比几乎都高于其他几种标准异常检测算法,特别是相较于决策树算法和朴素贝叶斯算法优势更加明显。此外,图7所示仿真结果进一步表明所提方法在检测5 种异常攻击特征方面,假阳性率指标基本低于其他标准异常检测算法。
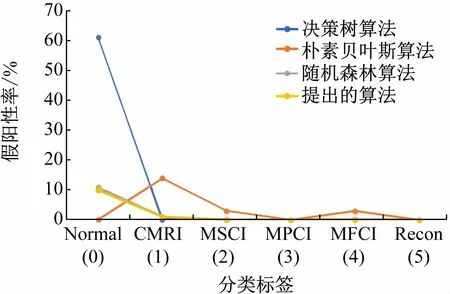
图7 不同算法的假阳性率对比
4.2 对比检测时间
图8 所示为使用单机和分布式集群2 种方式训练混合深度神经网络异常检测模型,在不同训练迭代次数下的耗时。由图8 可见,使用分布式训练混合深度神经网络模型用时明显少于单机训练方式,提高了计算效率,加快了异常检测进程。

图8 单机训练与分布式集群训练耗时对比
5 结 语
为提高SCADA 中的异常检测精度和效率,本文提出一种异常检测方法,首先预处理数据集,然后构建SSDA-DNN,再进行无监督特征学习并为混合深度神经网络添加监督分类器,完成异常检测,此方法尤其适用异常行为呈现多类的情况。仿真结果表明,在精度与召回率的协调平均值以及假阳性率指标上都优于其他传统异常检测方法,在异常检测的时间效率上也有所提高,表明该方法可行且有效。未来将围绕在扩大实验数据集和进一步加快训练时间上进行优化。
