基于集成数据驱动方法的焊接接头疲劳寿命预测模型
2023-12-09冯超赵雷徐连勇韩永典
冯超,赵雷,徐连勇,韩永典
(1.天津大学,天津,300350;2.天津大学天津市现代连接技术重点实验室,天津,300350)
0 序言
疲劳断裂是工程失效的最主要方式,随着工业大型化进程的推进,材料疲劳行为的研究已经成为避免工程失效的有效推动手段[1-2].焊接技术是工程上最常用的连接方式之一,作为一个多物理场耦合的不可逆过程,焊接接头的力学行为研究是一个多重非线性关系并存的复杂课题[3-4].
自疲劳概念在1854 年首次提出以来,对疲劳行为的研究已经取得了丰硕成果,逐步形成了以疲劳研究为基础的机械结构强度理论与技术,推动机械结构从经验设计走向安全设计.期间对于疲劳行为的研究,产生了经验解、解析解、数值解等多种研究手段[5-9],并广泛应用于工业的多个方面.由于焊接接头疲劳寿命受到多重影响因素的共同作用,并且各影响因素与疲劳寿命之间的定量关系不够清晰,导致目前没有一个通用的疲劳寿命预测模型适用于所有疲劳条件.随着数据的爆炸,数据驱动方法在疲劳行为的研究上发挥出色,并逐渐成为一种有效的疲劳寿命预测手段[10-11].但是目前不同的研究关注点不同,而数据驱动方法的可解释性较差,导致不同预测模型的性能难以评估.邹丽等人[12]利用监督策略对粒化条件邻域熵进行改进,提出基于监督粒化的条件邻域熵属性约简算法.并基于互信息理论分析了焊接接头疲劳寿命各影响因素之间的耦合关系,所提出的算法具有较高的约简率和分类准确率.Gao 等人[13]使用全尺寸现场测量评估了工程部件的疲劳特性,并开发了一个数据驱动模型来估计疲劳损伤.结果表明,基于数据驱动方法的疲劳损伤预测模型具有良好的精度.Amiri 等人[14]分别通过单目标和双目标神经网络研究了点焊接头的静态和疲劳行为.其中,神经网络模型被用作基本框架,遗传算法被用于优化神经网络的结构.该方法假定相似的超声波结果具有相同的抗拉强度和疲劳寿命,从而实现了同时预测抗拉强度和疲劳寿命的双目标神经网络.Lian 等人[15]于2022 年设计了一个基于领域知识的机器学习框架,将经验公式和随机森林(random forest,RF)模型相结合来预测铝合金的疲劳寿命.利用该方法(KRF 模型)的设计特点,通过经验公式传递知识,构建了疲劳寿命预测的通用方法,以减少实验时间和成本.Gan 等人[16]于2022 年提出了一种基于核极限学习机(kernel extreme learning machine,KELM)算法的疲劳寿命预测方法作为半经验预测模型的有用替代方法,并使用网格搜索法自动优化KELM 的超参数.
近年来,用于疲劳寿命智能预测方法的数据驱动方法经历了常规机器学习模型-混合多种机器学习算法的模型-深度学习模型几个阶段.基于此,文中通过建立一个以深度卷积神经网络(deep convolutional neural network,DCNN)为框架的疲劳寿命预测模型,并综合比较了集成不同技术的寿命预测模型的性能,为疲劳寿命智能预测的发展提供参考,进而为实现多重复杂条件下通用的疲劳寿命智能预测模型的构建奠定基础.相比目前已有的数据驱动模型,所提出的DCNN 模型具有良好的预测性能.DCNN 模型能够更好地理解焊接接头的疲劳行为的多重非线性关系,并通过数据增强与影响因素权重分析的考虑,具有较高的准确性和稳定性[17-18].所提出的模型也存在数据驱动方法的固有不足,目前的数据库的建设工作应该不断推进,使其能够包含更多不同疲劳条件下的性能数据以及更大的数据量.此外,对于数据驱动模型预测结果的解释以及物理规律的嵌入也是需要进一步发展的重要内容,上述问题的深入研究将进一步优化所提出的模型,并增强数据驱动方法在焊接接头疲劳寿命领域的适用性.
1 模型建立
基于数据驱动方法的疲劳寿命预测模型的建立过程可大体分为4 个步骤,如图1 所示.疲劳性能数据库的建立与处理,疲劳寿命影响因素的特征选择与重要性分析,用于理解疲劳寿命及其影响因素之间关系的数据驱动框架的搭建以及模型的训练、优化与应用.基于此,文中从疲劳性能数据库的建立与处理、疲劳寿命影响因素的分析、疲劳寿命预测模型的集成3 个方面对所提出的疲劳寿命预测模型进行描述.
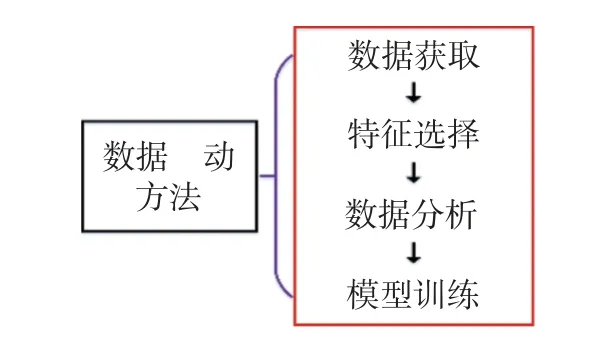
图1 数据驱动方法流程Fig.1 Process of data-driven method
1.1 疲劳性能数据库的建立与处理
使用DCNN 方法可以充分反映与考虑疲劳寿命及其之间的多重非线性复杂关系,有效地避免局部最优和过拟合,疲劳寿命预测模型的集成方案如图2 所示.
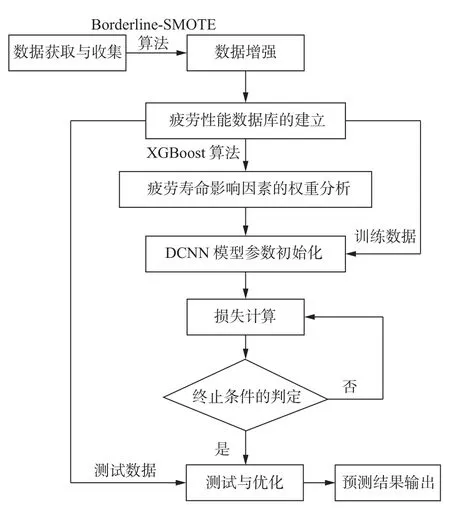
图2 焊接接头疲劳寿命预测模型的集成方案Fig.2 Integration scheme of the prediction model for welded joints of fatigue life
数据库的建立与处理通常可以直接影响预测模型的性能,而数据驱动方法对于数据库数据的数量和质量均具有较高要求[19-20].根据其对数据库数据的数量要求,文中从已发表的文献中[21-25]提取了相应的疲劳性能数据,用于疲劳性能数据库的组建.此外,根据数据驱动方法对数据库数据的质量要求,分别对数据库中的缺失值、重复值、离群值进行处理,并实施归一化处理.疲劳性能数据库一直以来都是我们工作的一项重要内容,并在不断扩充、优化疲劳性能数据库方面做了一系列研究[17-18].
不同文献中的不同测试条件以及疲劳行为的不确定性导致建立的数据库存在不平衡问题.因此,采用临界合成少数过采样技术(borderlinesynthetic minority over-sampling technique,Borderline-SMOTE)算法处理疲劳性能数据集.Borderline-SMOTE 是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特征化导致泛化能力欠佳,SMOTE 算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,从而增强所建立的疲劳性能数据库的平衡性以及数据质量.在疲劳寿命预测过程中,训练集与测试集的比例为8∶2.在此基础上,进行了焊接接头疲劳寿命影响因素的权重分析.
1.2 疲劳寿命影响因素的分析
疲劳寿命的影响因素具有非线性特征,对其权重系数的研究有利于更好地理解焊接接头的疲劳行为,从而在根源上提高焊接接头的疲劳性能.极端梯度提升算法(extreme gradient boosting,XGBoost)是集成学习算法的最有效手段之一,在绝大多数分类和回归问题上的描述和理解表现十分优异.XGBoost 算法的目标函数为
式中:j和J分别是当前和全部叶节点数目,i∈Ij表示第i个样本分为第j个叶节点,gi是一阶偏导数,hi是二阶偏导数,wj是叶节点的权重,Tl是叶节点的综述,λ和γ是XGBoost 算法的超参数.
因此,文中基于XGBoost 算法对疲劳寿命影响因素的权重进行分析,并集成到疲劳寿命预测框架,实现可靠预测.
2 数据增强及影响因素分析
2.1 数据增强
在机器学习中,通常假设数据集是平衡的(不同类别的数据在数量和质量上是相等的),用不平衡数据集训练的疲劳性能预测误差较大.而不同文献中的不同测试条件以及疲劳行为的不确定性容易导致数据集的不平衡.因此,采用SMOTE 方法处理疲劳性能数据集,增加数据集中的少数样本,避免疲劳性能数据的重叠,以使样本更有效.此外,为验证数据增强的有效性,使用F值和真阳性(true positive,TP)率对数据增强前后的数据库的性能进行分析.F值是不平衡问题的常用评价指标,适用于疲劳寿命预测的精度分析,在研究中,F值的增加表示模型的分类和预测精度也相应提升,有利于可靠疲劳寿命预测结果的获得.TP 率是疲劳性能数据集中正确分类样本的百分比,能够反映数据增强对疲劳寿命预测结果的精度的影响,在研究中,TP 率值的增加表示模型能够更好地分类疲劳数据样本,模型能够更好地理解疲劳行为特点,实现可靠的疲劳寿命预测.通过10 倍交叉验证,可以获得数据库的TP 率和F值,其中,为减少边界SMOTE方法的随机性,得到的TP 率和F值均为三次独立交叉验证的平均结果.
如图3 所示,处理前与处理后的TP 与F数值均出现波动点,而波动位置并不对应,这是算法本身的特点,可以更好地追踪不同样本条件下的特征,这并不会对本研究的预测结果产生影响.数据增强后的疲劳性能数据库的TP 率最小值为0.79,比未经数据增强的数据库(0.58)高36.2%;处理后数据库的TP 率最大值为0.9,比未处理数据库(0.79)高13.9%;处理后数据库的TP 率平均值为0.84,比未处理数据库(0.68)高23.5%.处理后数据库的F值最小值为0.71,比未处理数据库(0.59)高20.3%;处理后数据库的F值最大值为0.86,比未处理数据库(0.74)高16.2%;处理后数据库的F值平均值为0.78,比未处理数据库(0.65)高20.0%.分析结果表明,数据增强对于疲劳性能数据库的分类准确性和精度均具有较好的提升效果,有利于实现可靠的疲劳寿命预测.

图3 数据增强前后模型性能分析Fig.3 Analysis of model properties with and without data augmentation
2.2 焊接接头疲劳寿命影响因素分析
基于深度学习框架的疲劳寿命预测方法可以全面考虑不同影响因素的综合作用而不会发生过拟合,为不同影响因素的权重的综合分析创造了条件.此外,不同影响因素的权重大小比较为应力范围 > 应力比 > 加载频率 > 材料强度 > 载荷类型 >表面状态 > 环境温度.如图4 所示,应力范围对疲劳寿命的影响权重(44%)最大,明显高于其他影响因素;此外,应力比对疲劳寿命的影响权重为14%,比加载频率的影响权重(13%)高7.7%,比载荷类型的影响权重(9%)高55.6%,比材料强度的影响权重(8%)高75.0%,比表面状态和温度的影响权重(6%)均高133.3%.Xue 等人[23]和Gkatzogiannis等人[26]对疲劳寿命影响因素重要性的研究中也得到了相似的结论,证明了影响因素权重分析结果的可靠性.
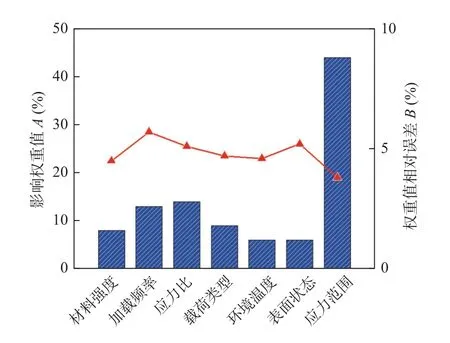
图4 疲劳寿命影响因素权重分析Fig.4 Wight analysis of factors influencing fatigue life
3 结果与讨论
3.1 基于不同技术组合的预测模型性能对比
分别设计了方案1、方案2、方案3 和方案4 用于比较有无影响因素权重分析以及有无数据增强情况下的疲劳寿命预测模型的效果.其中,方案1 进行了影响因素权重分析和数据增强(提出的方法);方案2 只进行了数据增强;方案3 只进行了影响因素权重分析;方案4 没有进行上述2 种处理手段.
如图5a 所示,基于方案1 和方案2 得到的疲劳寿命预测值可以保持在±1.5 倍误差带内,并且没有明显的离群值.然而,基于方案3 和方案4 得到的大多数疲劳寿命预测值仅能保持在±3 倍误差带内,并且这两种方法都包含误差较大的预测结果.如图5b 所示,方案1 的平均预测误差为5.2%,比方案2 的平均预测误差(48.6%)小89.3%,比方案3 的平均预测误差(25.0%)小79.2%,比方案4 的平均预测误差(69.8%)小92.6%.方案1 的预测误差的标准差为4.1%,比方案2 的预测误差的标准差(26.0%)小84.2%,比方案3 的预测误差的标准差(12.6%)小67.5%,比方案4 的预测误差的标准差(41.7%)小90.2%.如图5c 所示,方案1 的最大预测误差为12.5%,比方案2 的最大预测误差(116.4%)小89.3%,比方案3 的最大预测误差(50.6%)小75.3%,比方案4 的最大预测误差(152.2%)小91.8%.
此外,采取数据增强但未进行权重分析的方案2 的预测误差和误差标准差比未采取数据增强和权重分析的方案4 分别小30.4%和37.6%.未采取数据增强但进行了权重分析的方案3 的预测误差和误差标准差比比方法4 分别小64.2%和69.8%.总体而言,进行权重分析和数据增强的模型 > 进行权重分析而未进行数据增强的模型 > 进行数据增强而未采取权重分析的模型 > 权重分析和数据增强均未进行的模型.分析结果强调了数据增强,特别是权重分析对于可靠疲劳寿命预测的重要性.
3.2 不同预测模型性能对比
选择Lian 等人[15]设计的K-RF 模型以及Gan 等人[16]提出的KELM 模型2 种先进技术作为对比,以评估所提出算法的可靠性.
如图6a 所示,DCNN 模型的疲劳寿命预测值在±1.5 倍误差带内,K-RF 模型和KELM 模型的疲劳寿命预测值大部分位于±3 倍误差带内.如图6b 所示,DCNN 模型的平均预测误差为5.2%,比K-RF 模型(47.4%)小89.0%,比KELM 模型(55.7%)小90.7%.此外,DCNN 模型的预测误差的标准差为4.1%,比K-RF 模型(19.9%)小79.4%,比KELM 模型(23.0%)小82.2%.如图6c 所示,DCNN 模型的最大预测误差为12.5%,比K-RF 模型(91.0%)小86.3%,比KELM 模型(120.5%)小89.6%.

图6 不同预测方法性能对比Fig.6 Comparison of different prediction methods.(a)error band analysis;(b) prediction error analysis;(c) conparison of prediction error
Lian 等人[15]指出,通过知识转移的机器学习模型将成为小规模数据集领域知识和数据驱动方法之间的桥梁.然而,在多个非线性问题的情况下,当前模型无法获得良好的预测结果.此外,KELM 模型的训练需要相对较大的数据库,如此高的数据要求可能会阻碍模型扩展到其他疲劳问题.此外,KELM 模型不适用于与训练多重材料,难以研究各种焊接接头疲劳寿命的预测[16].综上所述,结合数据增强与疲劳寿命影响因素权重分析的DCNN 模型表现出良好的预测性能,具有较高的准确性和稳定性.此方法对评估工程构件的可靠性和避免工程事故具有重要意义.
4 结论
(1)基于Borderline-SMOTE 算法对疲劳数据库进行了数据增强,处理后数据库的TP 率平均值为0.84,比未处理数据库(0.68)高23.5%;处理后数据库的F值平均值为0.78,比未处理数据库(0.65)高20.0%.
(2)于XGBoost 算法对疲劳寿命影响因素进行分析,发现不同影响因素的权重大小为:应力范围> 应力比 > 加载频率 > 材料强度 > 载荷类型 > 表面状态 > 温度.
(3)与其他先进预测技术相比,考虑数据增强和权重分析的DCNN 模型的平均误差和预测误差标准差分别降低79.4%和96.3%以上.
