基于残差神经网络模型的高压气井水合物生成预测方法
2023-12-06刘广胜邓泽鲲刘新福
刘广胜,郑 刚,邓泽鲲,魏 韦,刘新福
(1.长庆油田分公司 油气工艺研究院,陕西 西安 710018; 2.低渗透油气田勘探开发国家工程实验室,陕西 西安 710018; 3.青岛理工大学 机械与汽车工程学院,山东 青岛 266520)
引言
国内外预测水合物形成压力和温度的方法可分为经验法、图解法、相平衡算法、热力学模型以及智能算法5大类[1],经验法受限于使用范围且精度不高,图解法精度低且难以编程实现[2],相平衡算法和热力学模型由Vd W-P模型发展与补充,对含酸性气体的天然气水合物平衡条件预测误差较大,且计算难度较大[3-4]。
残差神经网络(ResNet)是一种改进的卷积神经网络(CNN)模型,引入残差深度学习的概念,设置带跳过连接线的残差学习单元,并采用多个残差学习单元首尾相连法加以构建,跳过连接线可使输入直接传递至输出层,从而避免梯度消失、过拟合等问题,提高网络的训练效率和泛化能力。ResNet主要用于图像分类、目标检测、语义分割等任务[3-4]。
目前很多学者利用支持向量机(SVM)与人工神经网络(ANN)等方法预测天然气水合物生成条件,而较少使用残差神经网络智能算法进行预测。卞小强等[5]引入酸性混合气体对CH4的影响,将交叉验证(CV)与支持向量机相结合的方法预测含H2S和CO2等酸性天然气水合物生成条件,并运用杠杆法提出一种检测SVM模型异常点和适用范围的方法。Mesbah等[6]针对SVM算法运行速度慢和大规模二次规划等问题,采用最小二乘支持向量机法(LSSVM)预测H2S和CO2含量高的酸性天然气水合物生成温度。顾新建等[7]使用全连接神经网络(FCNN)预测天然气水合物生成,彭远进等[8]使用FCNN理论预测部分烃类气体与含CO2等酸性气体水合物生成。FCNN存在训练速度慢、结果易陷入局部最优等缺点,使得FCNN的预测精度极易受到影响;FCNN改进过程中发现,使用小波神经网络(WNN)的效果良好。陈哲等[9]提出将小波分析与神经网络相结合,唐永红等[10]提出群体最大误差比率代表机制,对WNN引入动量项系数进行改进,由此加速网络的收敛速度。Park[11]在小波神经网络基础上耦合遗传算法,来克服其陷入局部最优的缺点。综上所述,本文提出一种跳过连接卷积神经网络模型构建水合物生成大数据集处理方法,推导残差神经网络深度学习算法、大数据集特征获取与数据预处理算法、大数据集构造与划分算法及大数据集评价指标,构建多元体系残差神经网络模型,包括残差神经网络模型训练、残差神经网络超参自动调优以及参数动态微调,并依据实例分析和试验结果准确预测出高压气井多元体系天然气水合物生成条件。
1 水合物生成大数据集处理方法
1.1 残差神经网络深度学习算法
残差神经网络(ResNet)采用多个残差学习单元首尾相连法加以构建[12-14],残差深度学习方法见图1。
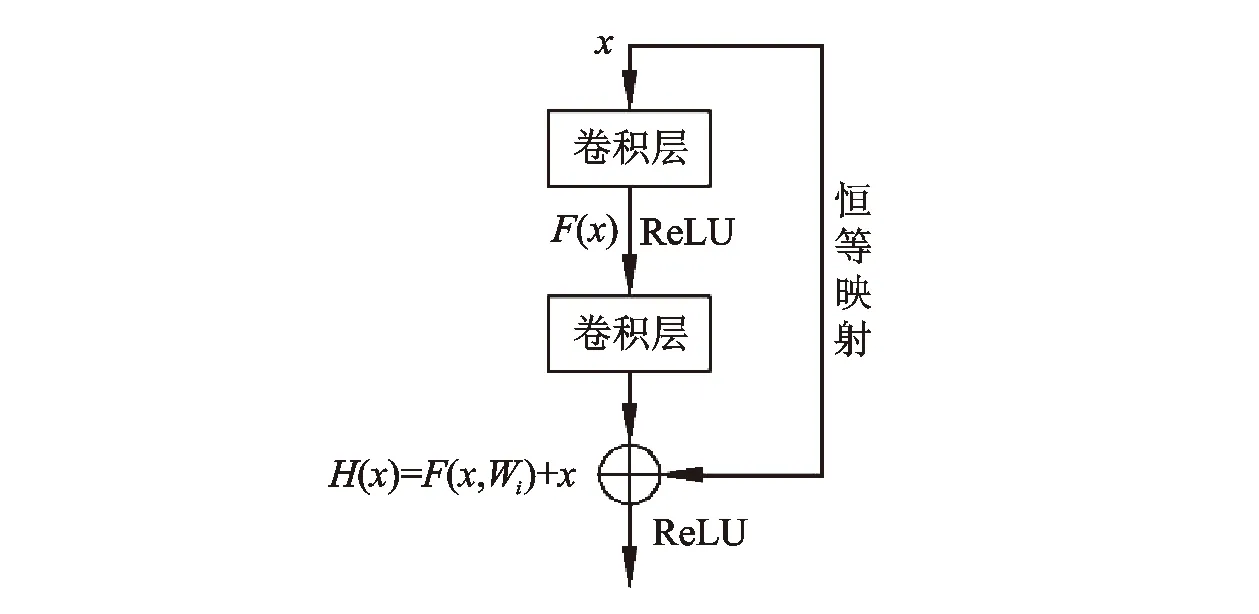
图1 ResNet神经网络深度学习方法
图中,x为残差单元输入,H(x)为残差单元输出,F(x)为残差射函数,表示学习到的残差,H(x)=F(x,Wi)+x为恒等映射函数,Wi为输入经过残差块中第i个卷积层时获得的权重。
1.2 大数据集特征获取与数据预处理方法
水合物生成模型需结合高压气井具体工况选择具有代表性的特征,同时综合考虑天然气多组分混合比例、临界压力、临界温度、实际温度、气体流速、压力波动及高压等因素的影响。由于获取的数据集特征有限,气体流速、压力波动及节流效应等因素无法获取,为此主要选取气体组分、水合物生成压力与生成温度作为模型特征。
所选取的部分特征不宜直接使用,需要通过合理有效的转化规则进行处理。ResNet神经网络优化与学习时,数据需要进行归一化与标准化等预处理,从而使原始数据映射到指定范围,并除去不同维度数据的量纲及其量纲单位。
最小与最大幅度归一化适合数值较集中的数据,即数据中不存在极端最大值和最小值,即
(1)
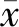
Z分数标准化涉及距离度量、协方差计算的工况数据,一般用于分类、聚类与主成分分析(PCA)算法。其算式为
(2)
式中:μ为数据均值;σ为数据标准差。
根据特征数据特点,对大部分学习特征采用最小与最大幅度归一化,具体的学习特征选取和转化规则见表1。

表1 学习特征选取与转化规则
1.3 大数据集构造与划分方法
依据ResNet神经网络多对一回归方法,并结合混合气体组分比例、临界压力、临界温度、实际压力等预测水合物实际生成压力和生成温度。ResNet模型使用一维卷积层(Conv1d)并输入二维张量(n,m),m为特征向量维度,n为样本数量,M1~Mn分别为甲烷、乙烷、丙烷、正丁烷、异丁烷、二氧化碳、氮气、硫化氢及其混合组分以及临界压力和临界温度,Mn+1为气体压力。
综合甲烷、乙烷、丙烷、正丁烷、异丁烷、二氧化碳、氮气与硫化氢等水合物实验数据[15-17],结合大数据集构造方法组装样本数据集,部分实验数据作为训练集,余下部分作为数据验证集。大数据集训练时使用k折交叉验证(k-Fold)的方式将部分训练集划分为测试集。大数据集共收集1 900多个实验数据,收集的所有数据被随机打乱,并且划分为15折进行训练和测试。
1.4 大数据集的评价指标
水合物ResNet预测模型的损失函数可选择均方误差(SSE)、平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)以及均方对数根误差(RMSLE)。SSE、MAE、RMSE效果类似,对预测值与真实值间的误差惩罚一致,RMSLE对预测值小于真实值的误差惩罚较大,且当少量数据预测值与真实值相差较大时,通过取对数的方式可减轻局部误差对整体的影响。为此采用RMSLE作为训练的损失指标,选取MSE作为模型的精度指标,其计算式为
(3)
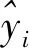
无论选择何种指标作为损失函数,ResNet神经网络的最终优化目标均为最小损失。
2 多元体系残差神经网络模型
2.1 残差神经网络模型训练
随机初始化ResNet 神经网络参数,设置神经残差学习单元为1、训练循环次数为1 000、批量大小为32。使用训练集进行模型训练且完成后验证模型,以预测乙烷水合物生成压力和生成温度为例。使用单个残差学习单元时,模型预测精度指标MSE为0.053 28。
2.2 残差神经网络超参自动调优
采用初始化的神经网络参数,计算结果不一定符合预期要求,且ResNet神经网络的超参数量巨大,取值范围宽泛。为此采用手动设定超参取值范围,程序框架自动搜寻最优解的方法建立ResNet模型,通过增加网络层数的方法来过拟合模型,同时关注训练损失和验证损失的变化,寻找验证数据集上性能降低的初始位置,确定超参数范围。
超参数的选择会影响ResNet模型的训练效果和速度,ResNet模型超参自动调优常用的搜索策略包括网格搜索、随机搜索、贝叶斯优化等[4]。ResNet模型发生过拟合通常由模型过于复杂或训练数据过少造成的,缓解或避免过拟合的方法主要包括正则化、随机丢弃、提前终止等[5]。
以ResNet模型的学习单元个数为例,使用Nakamura等[18-20]的实验数据,预测274.25~285.78 K的I型CH4水合物,结果见图2和图3。
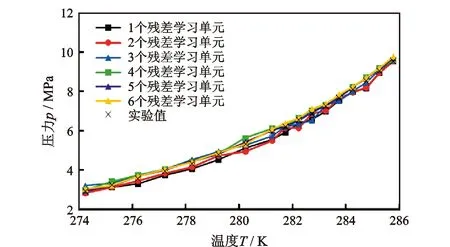
图2 CH4水合物生成压力和温度预测值与实验值对比
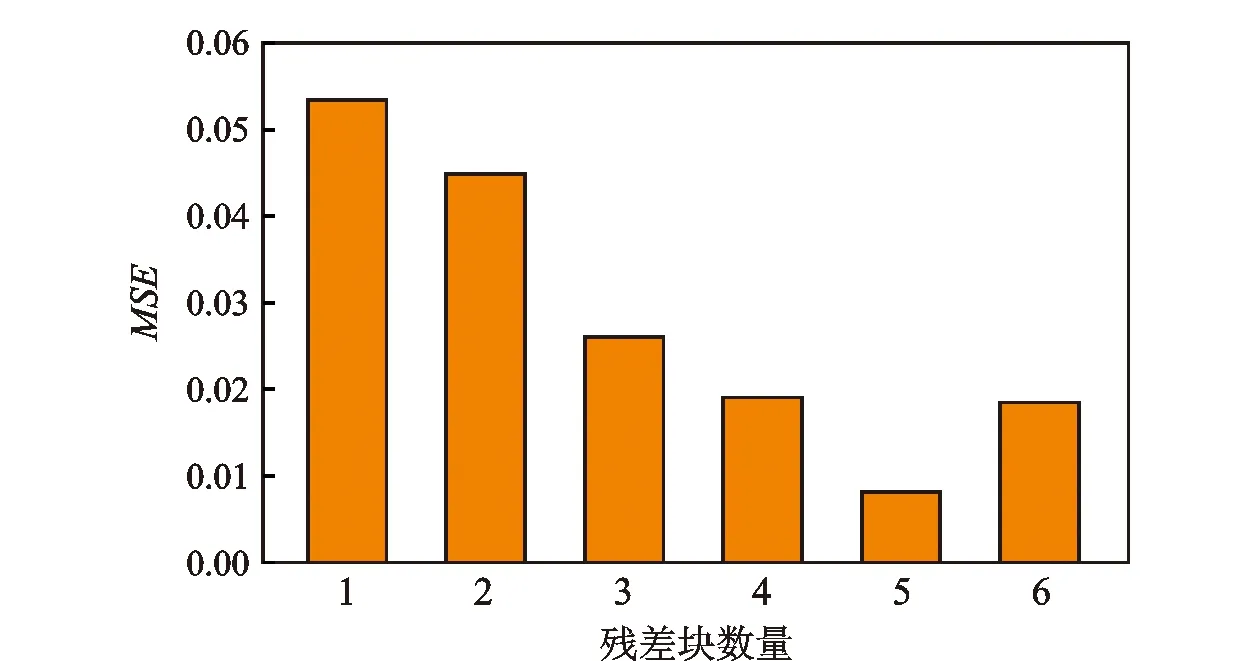
图3 CH4水合物生成的预测精度
ResNet预测模型的残差块为2个时,ResNet模型预测精度指标MSE为0.044 89;ResNet模型的残差块为5个时,精度指标MSE为0.008 09;ResNet模型的残差块达到6个并继续增加时,ResNet模型发生过拟合,预测精度指标MSE升高,预测结果与实际值偏差变大。因此合理的ResNet模型残差块数量应设为4~5。
自动调优的参数包括全连接层网络层数、全连接层神经元个数、训练循环次数、批量大小等,设置每个参数的步长,并使用网格搜索的方式确定最优参数组合。ResNet 神经网络各参数及其取值见表2。
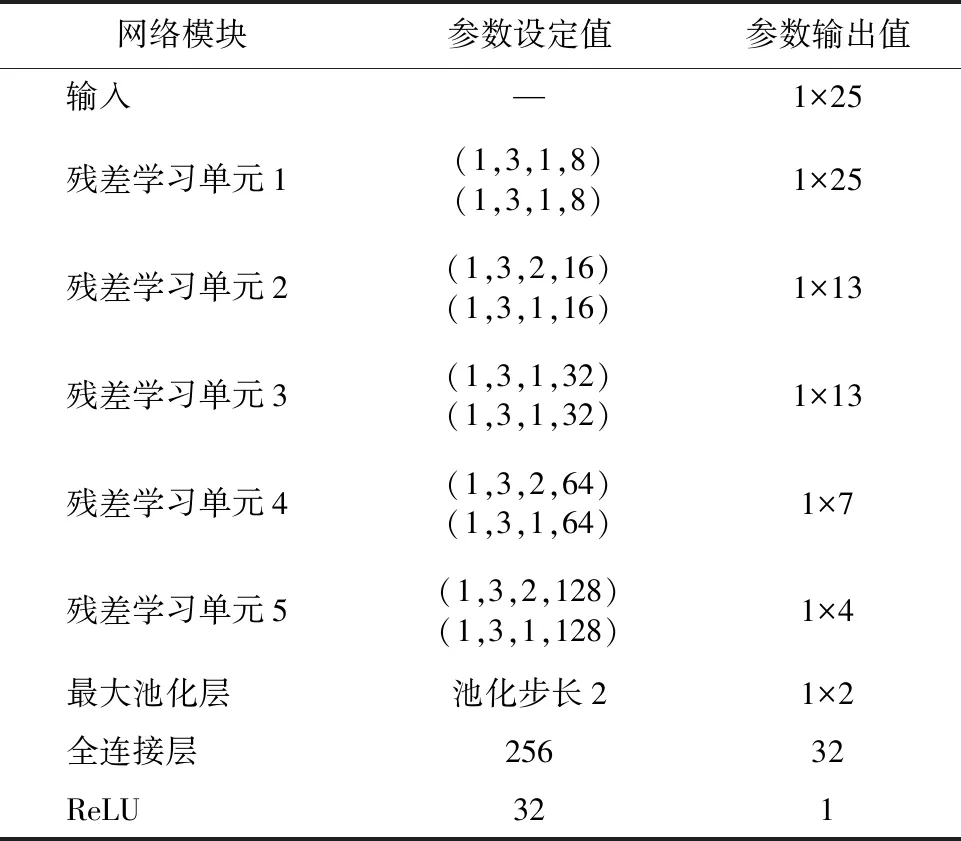
表2 残差神经网络模型参数设置
表2中ResNet学习单元的参数分别表示其前后两个卷积层的参数,如残差块1 中参数(1,3,2,16)表示第一个卷积层卷积核大小为1×3、步长为2、通道数为16,参数(1,3,1,32)表示第二个卷积层卷积核大小为1×3、步长为1、通道数为32。因为残差学习单元2第一个卷积层的步长为2,会将输入数据长度减少一半,而使输入与输出大小不匹配,需在残差学习单元2中跳过连接部分添加步长为2的1×1卷积核处理,保证该残差学习单元的输入与输出维度匹配,同理需在残差学习单元4与残差学习单元5跳跃连接线部分加入步长为2的1×1卷积核进行处理。卷积核的实现方法为
(4)
式中:yi,j为输出数据第i行和第j列的输出元素;C为卷积核通道数;xi,j+k为输入数据第i行和第j+k列的输入元素;wk为卷积核第k个权重。
2.3 残差神经网络参数动态微调
为提高ResNet网络的扰动能力并保持良好的鲁棒性,在训练时加入正则化防止极端权重的产生和随机丢弃,避免模型过于依赖局部特征,建立带有不同随机丢弃系数与正则化系数L2的网络,并使其初始化、优化器类型、学习率以及训练的步数一致,预防无关变量对模型训练效果和该系数的影响,最终比较模型在测试集上的损失。使用Nakamura[18]的实验数据,得出正则化与随机丢弃对均方误差(MSE)的影响,见表3。
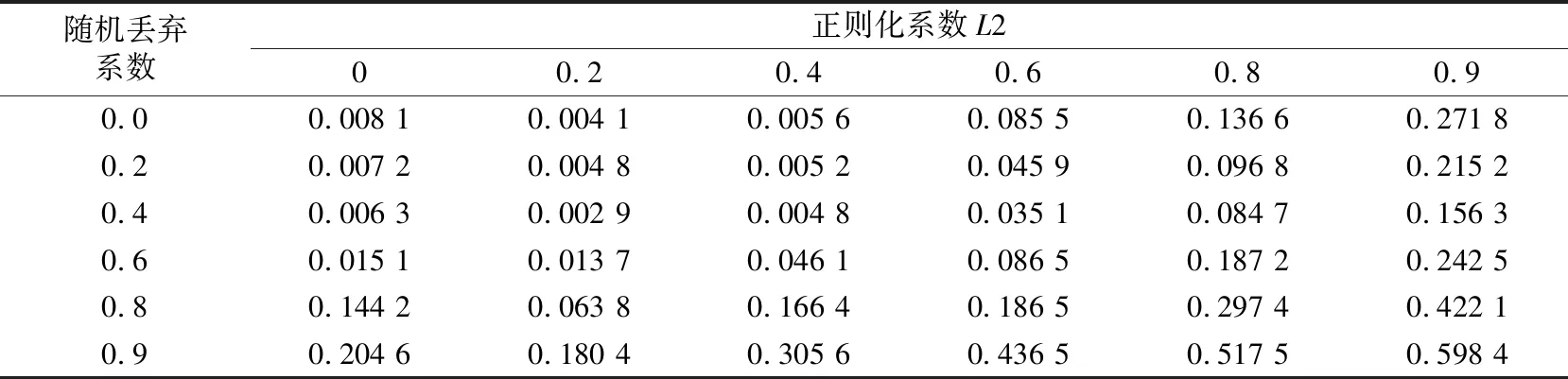
表3 正则化与随机丢弃对ResNet模型结果的影响
正则化与随机丢弃对MSE、随机丢弃系数和L2的影响见图4。ResNet模型MSE随着随机丢弃系数的增大先降低而后逐渐提高,增大随机丢弃系数可减轻ResNet模型的过拟合,而随机丢弃系数过大则会导致网络训练困难,反而降低ResNet模型的预测效果;正则化系数L2的变化趋势与随机丢弃系数类似,适度选取L2系数可减少ResNet模型的过拟合,但L2系数过大可能会导致ResNet模型欠拟合,影响预测效果。依据表3的结果数据,最佳ResNet网络参数为L2系数取0.2,随机丢弃系数取0.4。
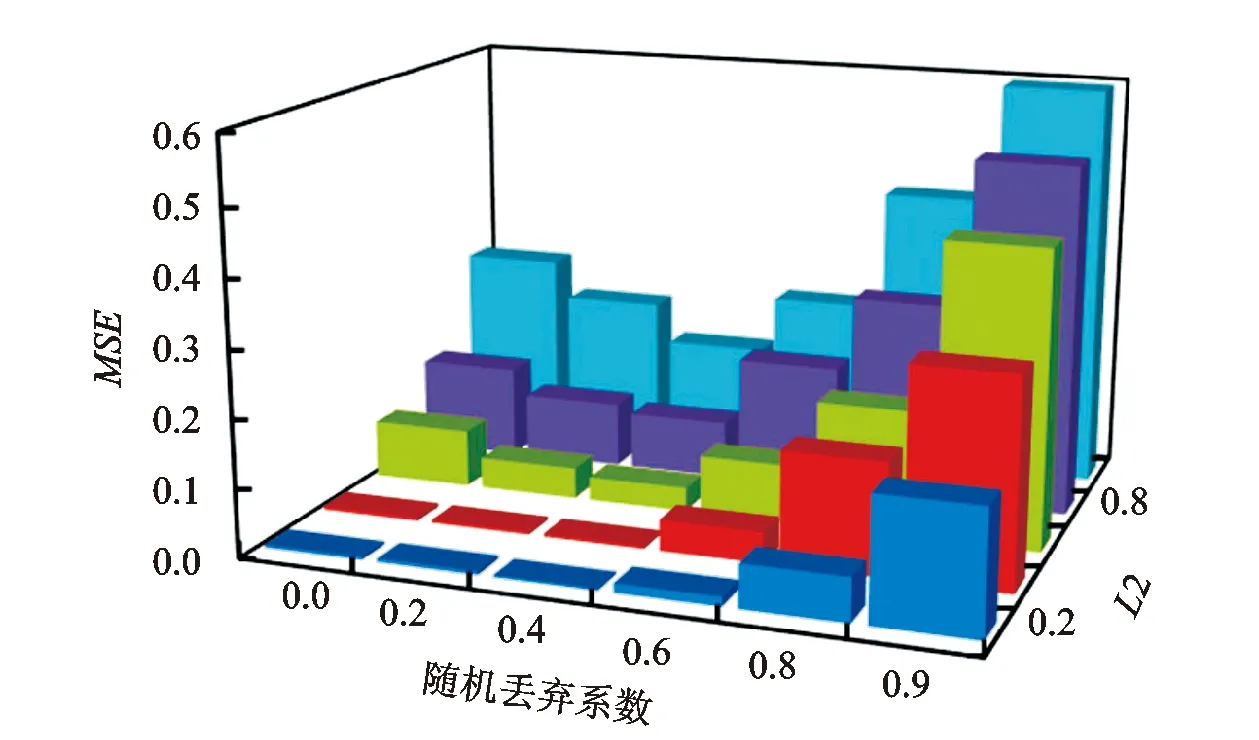
图4 正则化与随机丢弃对ResNet模型MSE的影响
采用优化算法更新ResNet网络训练参数,初始值设为0.001,衰减率为0.9,每迭代500次进行衰减,L2系数为0.4,随机丢弃系数为0.2,训练策略为提前终止以获得更好效果[21-23]。ResNet神经网络采用5个残差学习单元,批量大小为64,训练循环次数为3 000,并依据分布式技术将每组参数生成对应的模型文件和预测结果进行存储。
3 天然气水合物生成预测实例分析
3.1 单组分体系水合物生成预测结果与分析
选取长庆油田高压气井单组分、二元以及多组分天然气水合物井场试验测试数据,对比分析ResNet、WNN和FCNN等不同神经网络模型预测天然气水合物生成条件的准确性。ResNet、WNN和FCNN 3种模型的预测结果与甲烷水合物相平衡试验结果[14,19]的对比情况见图5。

图5 不同网络法甲烷水合物生成预测值与实际值对比
ResNet模型与WNN模型和FCNN模型的预测结果趋势一致, 均有较高的精度。依据计算误差统计曲线, 3种模型中ResNet模型的计算误差最小, WNN模型次之, FCNN模型最大。模型预测精度指标MSE更加明显体现3种模型预测结果的差别, 对于CH4水合物预测,ResNet模型的MSE为0.005 72,WNN模型的MSE为0.015 22,FCNN模型的MSE为0.034 52,由此推知ResNet模型预测甲烷水合物的准确度较高。
ResNet、WNN和FCNN 3种模型预测单组分体系水合物生成结果见图6。
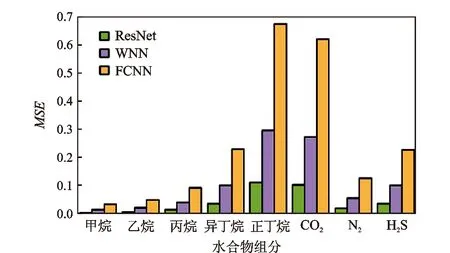
图6 不同网络法单组分水合物生成预测值与实际值对比
ResNet、WNN和FCNN 3种模型对于单组分天然气水合物预测均有较高的精度,其MSE均小于0.7,且正丁烷与二氧化碳的预测精度较低,这与正丁烷水合物的数据量少和数据稀疏有关。横向对比3种模型预测结果,ResNet模型的MSE最小,WNN模型的MSE次之,FCNN模型的MSE最大,由此推知3种模型均能有效预测纯组分的水合物生成条件,且ResNet模型预测单组分体系水合物的准确度最高。
3.2 二元体系水合物生成预测结果与分析
水合物类型为I型和所在相为Lw-H-V以及不含抑制剂与促进剂和温度范围283.2~301.2 K工况,ResNet、WNN和FCNN等不同神经网络模型预测二元体系水合物形成条件,水合物相平衡预测结果与试验结果[16,20]对比情况见图7。

图7 不同网络法二元体系水合物生成预测值与实际值对比
二元体系水合物生成压力为3.97~62.23 MPa,ResNet模型预测的水合物生成条件值与实测值间的MSE最小,WNN模型和FCNN模型的平均相对误差均大于1%,表明ResNet模型预测二元体系水合物的准确度最高。
4 结 论
(1)综合天然气多组分混合比例、临界压力、临界温度、实际温度及高压等因素的影响,提出跳过连接的卷积神经网络模型,利用残差神经网络深度学习算法,可有效提高天然气水合物生成条件的预测精度和效率。
(2)基于大数据集训练以及参数自动调优和动态微调构建ResNet神经网络模型,仅需将预先整理的水合物生成数据在模型中学习,即可准确预测出高压气井多元体系水合物生成条件,且ResNet神经网络保持良好的鲁棒性。
(3)11种单组分体系以及二元和多组分体系水合物相平衡预测结果和井场试验结果对比分析表明,预测均方误差由WNN模型的0.006~3.417和FCNN模型的0.008~3.722降至ResNet模型的0.001~1.020,ResNet模型的预测效果较优且吻合程度较高。
