基于改进T5 PEGASUS模型的新闻文本摘要生成
2023-12-05范永胜
张 琪,范永胜
(重庆师范大学 计算机与信息科学学院,重庆 401331)
近年来,互联网上各种新闻、论文、法律文件等文本数据量大幅增长[1]。随着移动互联网的兴起,用户可从移动设备上获取大量文本内容,但这些文本内容大多存在内容冗余、重点模糊等问题,使得用户在阅读时出现耗时长、抓不住文本重点等情况。因此,为了让用户更快更准确地从海量互联网信息中获取更有效的核心内容,文本摘要算法应运而生。
根据文本摘要的获取方式可以将其分为抽取式文本摘要和生成式文本摘要[2],前者计算原文中的句子权重,根据权重进行排序,选择权重高的部分句子组成摘要;后者通过深度学习模型根据文章大致意思生成新的句子,而生成的摘要内容可能存在原文中没有的词语或句子。
文献[3]提出词频和单词的相对位置是衡量词语重要性的两个指标,文章中重要的句子是包含词频高单词的句子,摘要将这些重要的句子组合起来。随着深度学习的兴起,越来越多的研究人员开始进行生成式文本摘要任务的研究。文献[4]提出了PEGASUS模型,其基本思想是通过遮挡部分句子连接间隔句子[5],选取文本中与其他句子重合率最高(即公共子序列最长)的某些句子将其作为摘要,从而构建可用于训练的摘要语料。文献[6]在4个数据集上比较了T5、BART和PEGASUS模型的零样本学习和小样本学习效果。文献[7]将PEGASUS模型应用在初等数学应用题中,且通过微调数据集大小来验证PEGASUS模型的小样本学习能力。文献[8]在两个数据集上比较TF-IDF、LexRank、TextRank、BertSum和PEGASUS模型的效果。文献[9]利用自然语言处理自动生成多项选择题,将PEGASUS模型生成的摘要作为多项选择题的问题,由KeyBERT确定答案的选项,使用Sense2Vec生成与问题相关的错误选项。
PEGASUS模型适用于英文,无法直接用于中文领域,因此追一科技将PEGASUS和T5模型的多国语言版mT5进行整合,开发出了预训练的中文生成式模型T5 PEGASUS。文献[10]通过提示学习、数据增强以及关键词提取等技术构建图书信息语料,将语料输入T5 PEGASUS模型中生成图书宣传语。
由于目前少有研究人员进行改进T5 PEGASUS模型的相关研究,因此本文针对该模型的中文分词方法进行改进,在原有基础上将Jieba分词替换为在新闻领域具有更好分词效果的Pkuseg分词,并在多个公开新闻数据集上验证了改进T5 PEGASUS模型的有效性。
1 模型介绍
T5模型[11]是Encoder-Decoder结构的Transformer预训练语言模型,mT5[12]是T5模型的多国语言变体。T5 PEGASUS是一种新的T5模型,其首先将mT5作为基础架构和初始权重;然后结合中文的特点将mT5的Tokenizer换为BERT的Tokenizer,并与Jieba分词相结合;最后在中文语料上借鉴PEGASUS模型的思路构建预训练任务。
T5 PEGASUS模型的基本思想是尽可能令文本中约25%的句子与剩余75%的句子重合率最高,即公共子序列最长。随后将75%的句子组成的文本作为原文,将25%的句子组成的文本作为摘要,从而构建可用于训练的摘要语料。
T5 PEGASUS模型在进行中文文本摘要生成任务时,需要先对中文数据集进行分词处理,再使用T5模型进行数据预处理。原有模型使用Jieba的精确模式进行中文分词,本文针对中文分词方法进行改进,通过多次实验发现北京大学发布的Pkuseg分词方法效果最佳。该分词方法具有多领域分词、高分词准确率的特性,并支持用户使用自己的标注数据进行训练[13]。
目前开源的T5 PEGASUS模型有Base版和Small版,本文采用Small版进行研究,模型流程如图1所示。
2 实验设置
2.1 实验环境与参数设置
本文的实验环境如表1所示。
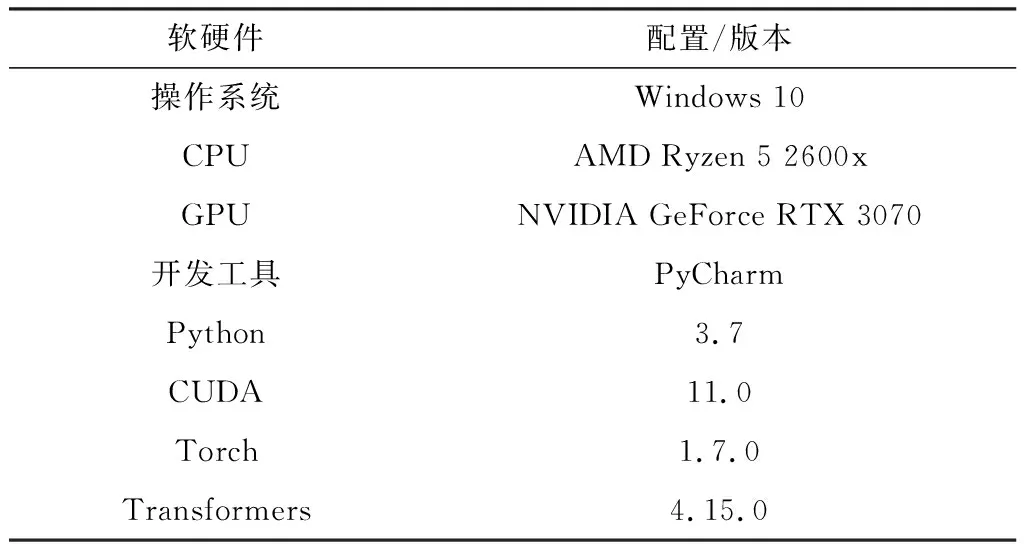
表1 实验环境
在实验中需要进行多次迭代来调整超参数[14],最终的参数设置由表2所示。
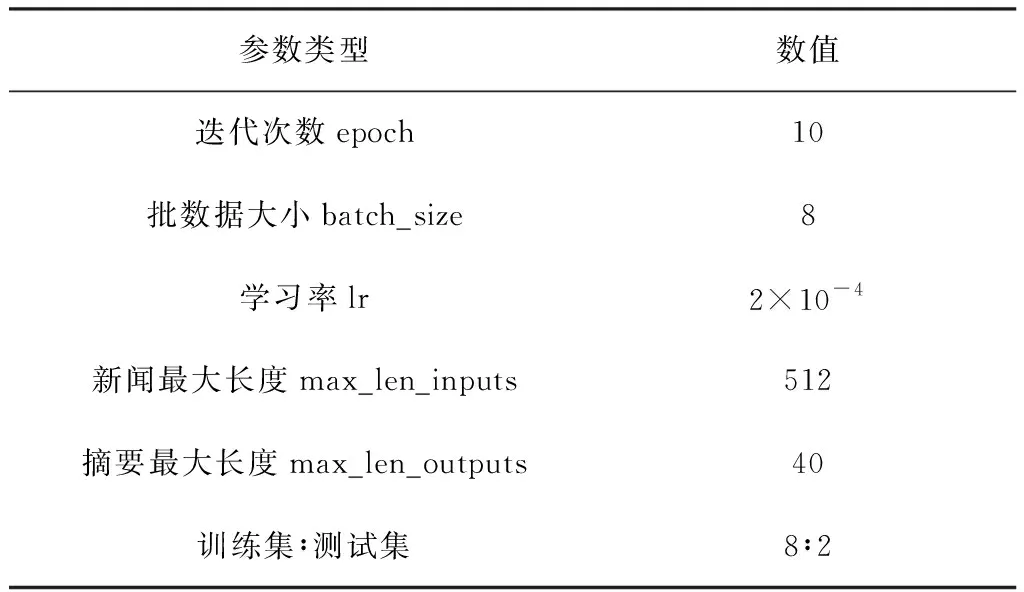
表2 参数设置
2.2 实验数据
本文采用3种新闻文本长度不同的数据集进行实验。为了避免数据集条数对结果产生影响,选取NLPCC2017 Shared Task3评测任务的数据集(NLPCC2017)、LCSTS数据集[15]以及搜狗实验室整理的2012年6月至7月期间18个频道的新闻数据(SogouCS)这3种数据集的前50 000条数据进行研究。
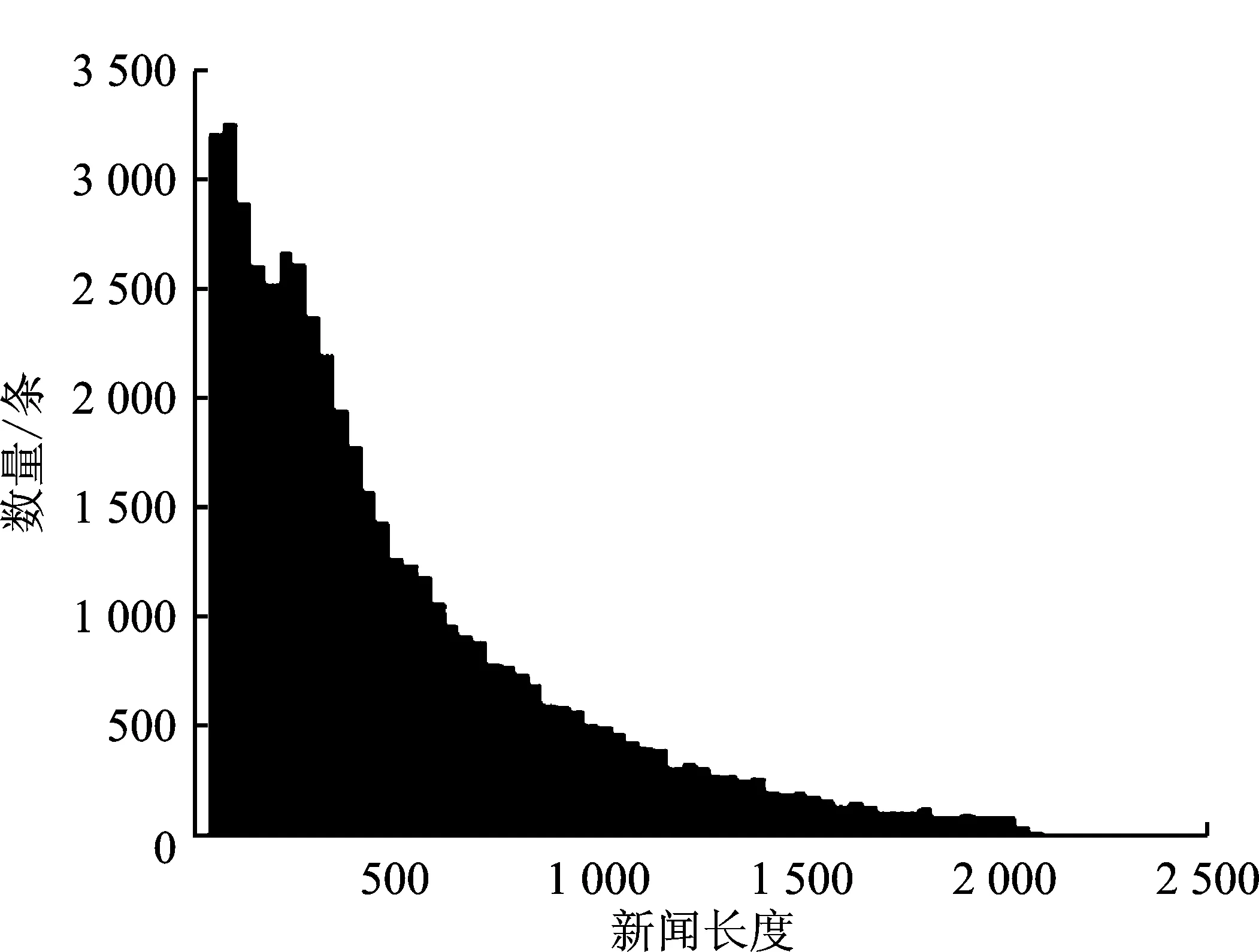
统计NLPCC2017、LCSTS、SogouCS这3种数据集的新闻文本和参考摘要的长度,分别如图2、图3和图4所示。
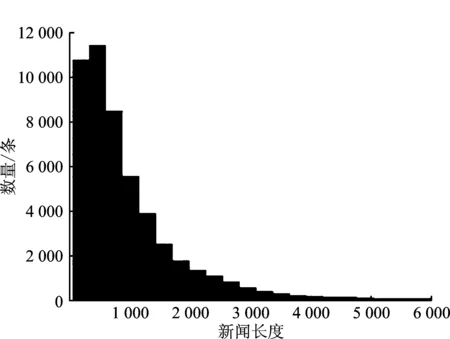
(a)
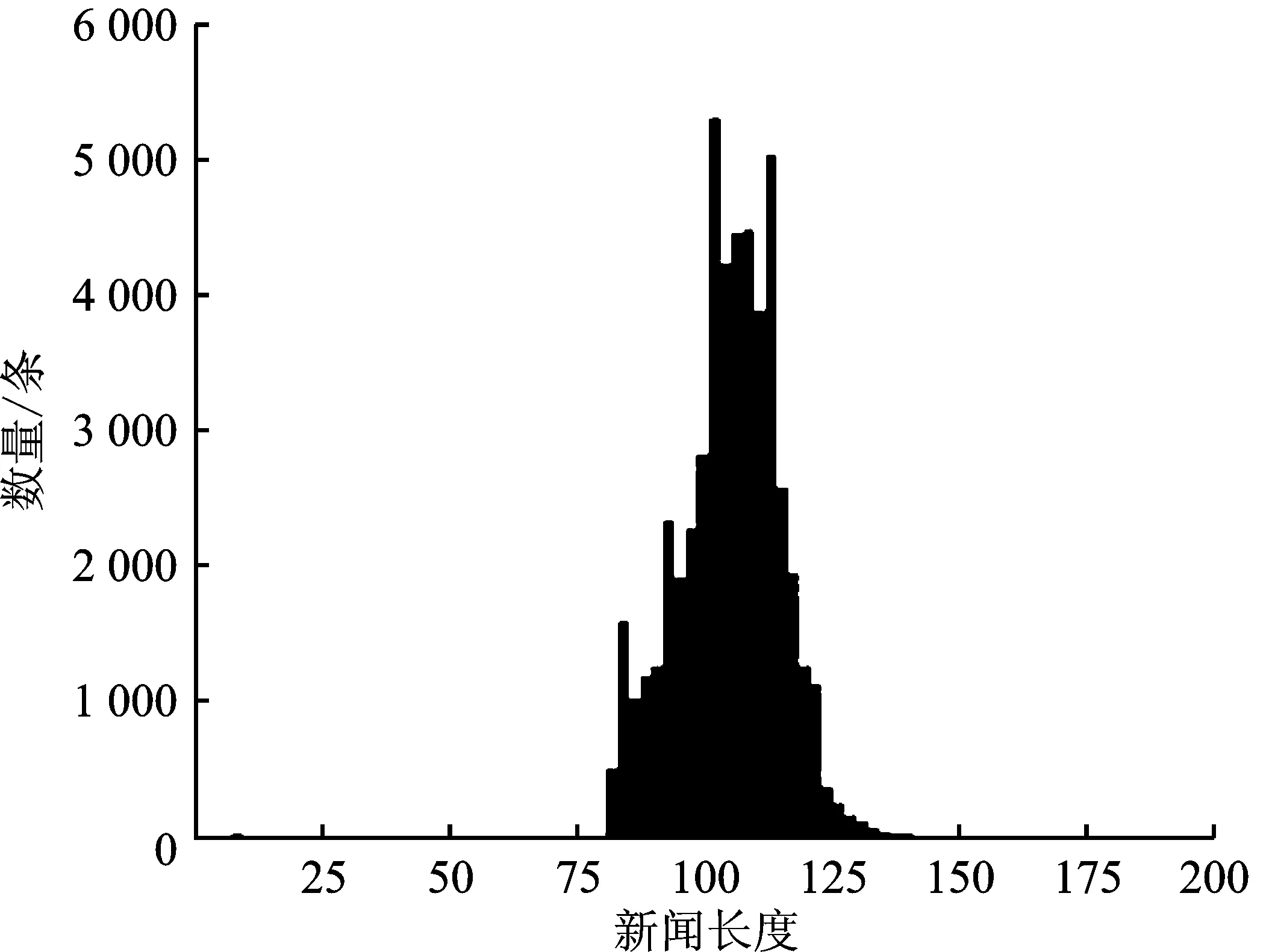
(a)
(a)
从图2~图4可以看出,NLPCC2017属于长文本数据集,其新闻平均长度为991字,摘要平均长度为46字;LCSTS属于短文本数据集,其新闻平均长度为105字,摘要平均长度为18字;SogouCS属于中长文本数据集,其新闻平均长度为487字,摘要平均长度为19字。
2.3 评价标准
本文使用ROUGE[16]指标对T5 PEGASUS模型生成的摘要进行评估。ROUGE将多位专家撰写的人工摘要作为参考摘要,统计参考摘要和模型生成摘要之间重叠的基本单元数量,以衡量参考摘要和模型生成摘要之间的相似程度,从而评价摘要质量。ROUGE分别计算准确率P、召回率R和F值,计算式分别如式(1)~式(3)所示。
(1)
(2)
(3)
其中,{RS}代表参考摘要;gramn代表n-gram的长度;Countmatch(gramn)代表参考摘要和模型生成摘要之间重叠的基本单元数;Countsummary(gramn)代表模型生成摘要中基本单元数;Count(gramn)代表参考摘要中基本单元数。
本文主要从ROUGE-1(基于1元词)、ROUGE-2(基于2元词)和ROUGE-L(基于最长子字串)3方面的结果来评测实验效果。
3 实验结果及分析
3.1 中文分词方法对ROUGE值的影响
T5 PEGASUS模型在进行数据预处理时使用Jieba的精确模式进行中文分词。本文使用北京大学发布的Pkuseg和清华大学发布的THULAC分词方法在3种不同公开数据集上与Jieba进行对比,对比结果如表3所示。
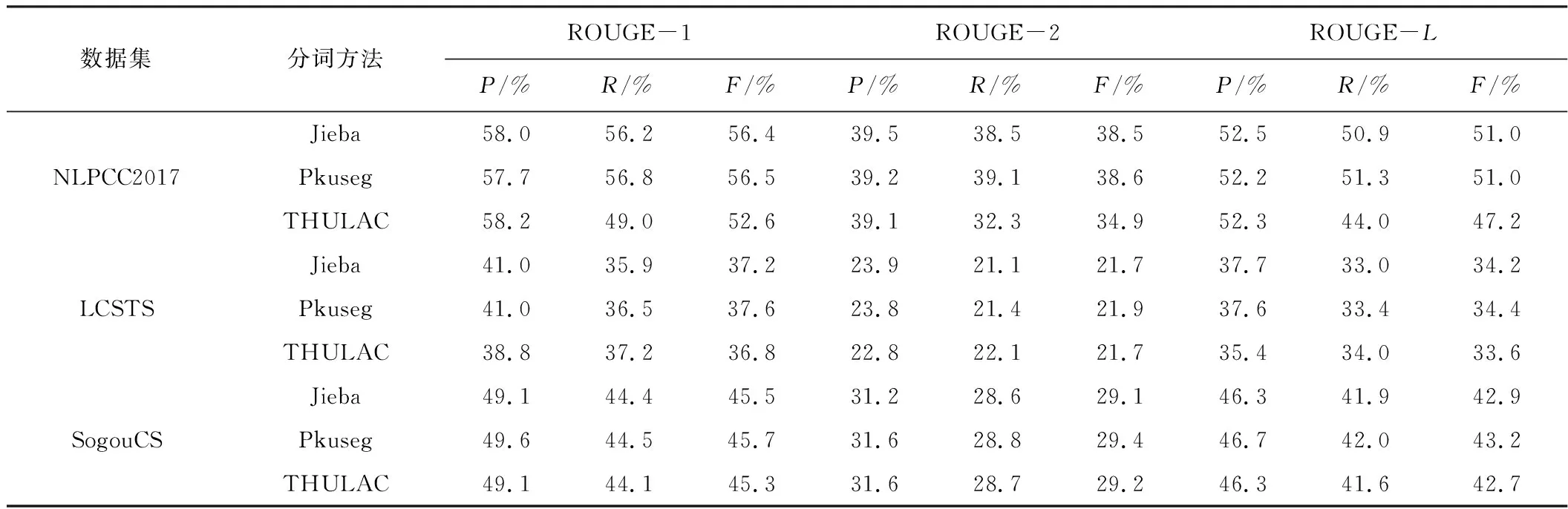
表3 中文分词方法对ROUGE值的影响
由表3可知,Pkuseg分词方法的F值均优于Jieba、THULAC分词方法,多数R值、P值优于Jieba、THULAC分词方法。其中,Pkuseg分词方法应用在SogouCS数据集上的ROUGE值均达到最佳,并且相关研究发现Pkuseg分词方法针对词汇的边界识别问题优于Jieba和THULAC[17],因此本文使用Pkuseg替换原有Jieba分词方法。
3.2 新闻文本长度对ROUGE值的影响
本文研究了3种新闻文本长度不同的数据集对ROUGE值的影响,实验结果如表4所示。

表4 新闻文本长度对ROUGE值的影响
由表4可知,NLPCC2017数据集的ROUGE值均最高,其次是SogouCS数据集,LCSTS数据集的ROUGE值最低,证明改进T5 PEGASUS模型生成摘要的ROUGE值与新闻文本长度成正相关,更适用于长文本数据集。
3.3 训练集损失值与迭代次数的关系
本文研究了3种不同数据集的训练集损失值与迭代次数的变化关系,结果如图5所示。
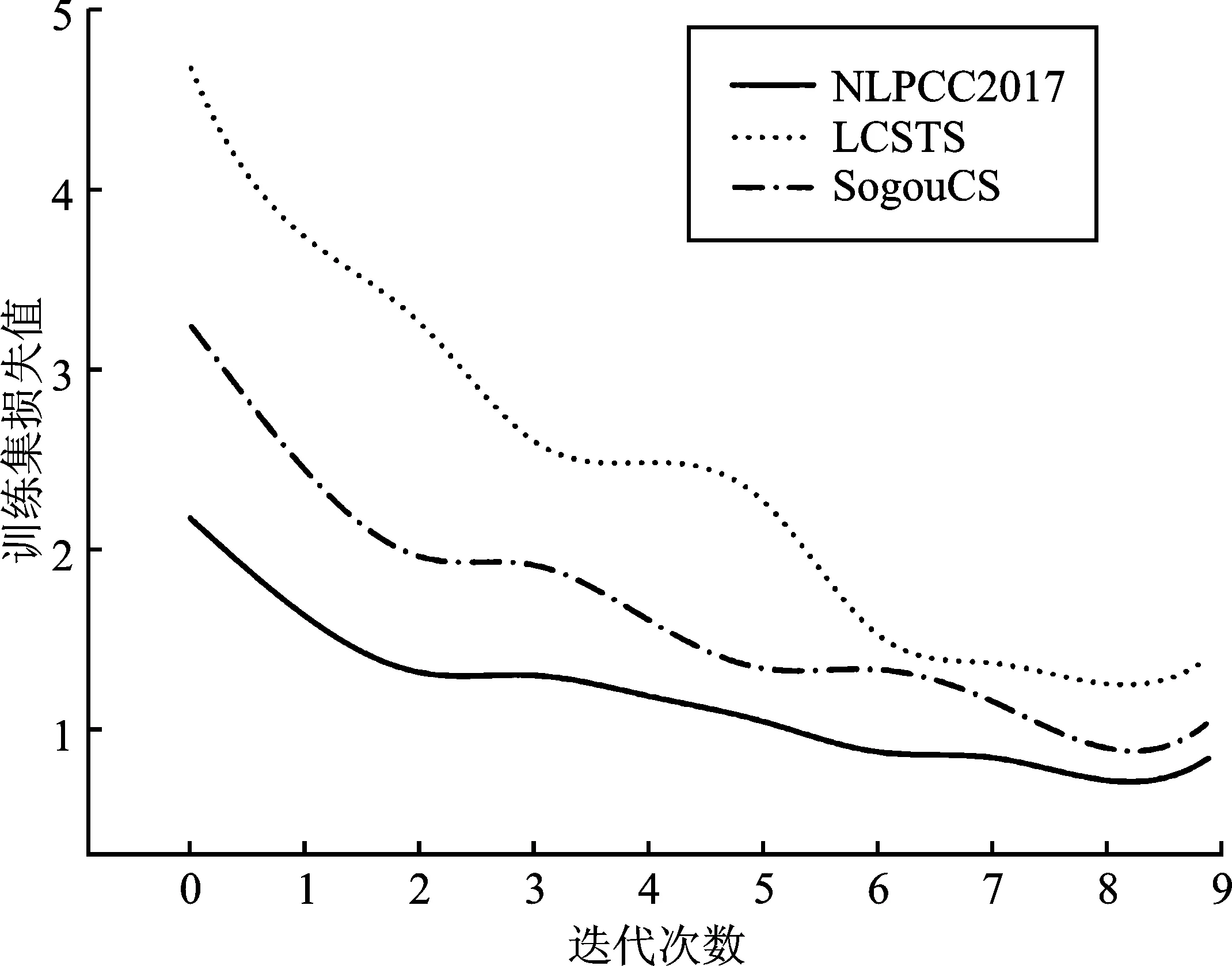
图5 训练集迭代次数与损失值的关系Figure 5. Relationship between the number of iterations of the training set and the loss value
由图5可以看出,训练集的损失值基本随着迭代次数的增加而降低,且收敛速度逐渐变慢[18],其中3个数据集均在迭代次数为8时损失值达到最低。LCSTS数据集的训练集损失值最高且损失值下降速度最快,其次是SogouCS数据集,NLPCC2017数据集的训练集损失值最低且损失值下降速度最慢,证明训练集的损失值和损失值下降速度均与新闻文本长度成负相关。
3.4 迭代次数与ROUGE值的关系
由于F值受P值和R值的共同影响,因此将F值作为代表分析研究迭代次数与ROUGE值的关系,结果如图6所示。
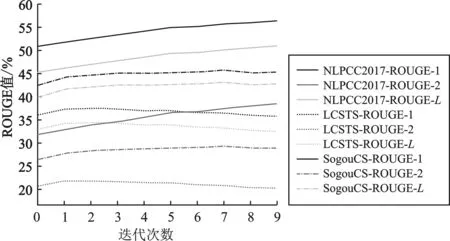
图6 迭代次数与ROUGE值的关系Figure 6. Relationship between the number of iterations and ROUGE value
由图6可以看出,NLPCC2017数据集的ROUGE值均随迭代次数增加而增大。LCSTS和SogouCS数据集的ROUGE值分别在迭代次数为2和7时达到最高值,随后ROUGE值随迭代次数的增加呈减少趋势。从图6中观察到每个数据集的3条线均呈平行现象,证明随着迭代次数的增加,ROUGE值的变化趋势相同。
3.5 新闻数量对ROUGE值的影响
本文研究不同新闻数量对ROUGE值的影响,分别选取NLPCC2017数据集中的前10条、50条、100条、500条、1 000条、5 000条以及10 000条数据进行测试,测试结果如表5所示。
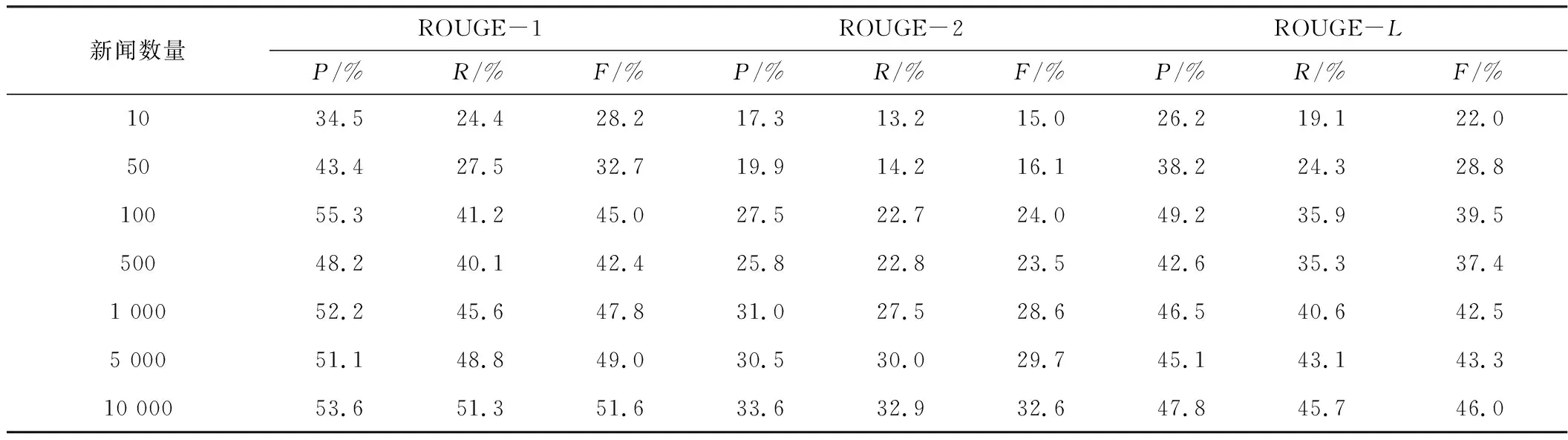
表5 NLPCC2017数据集新闻数量对ROUGE结果的影响
由表5可以看出,在新闻数量达到100时,仍有部分数值超过新闻数量为10 000时的结果,证明改进的T5 PEGASUS模型具有较强的小样本学习的能力。使用LCSTS、SogouCS数据集佐证模型的小样本学习能力,ROUGE结果分别如表6和表7所示。

表6 LCSTS数据集新闻数量对ROUGE结果的影响

表7 SogouCS数据集新闻数量对ROUGE结果的影响
由表6和表7可以看出,LCSTS、SogouCS两个数据集在新闻数量为100时,多数ROUGE值超过新闻数量为50 000时的结果,进一步证明了改进T5 PEGASUS模型具有较强的小样本学习能力。
4 结束语
本文使用T5 PEGASUS模型进行摘要生成,在原有模型基础上使用Pkuseg中文分词方法替换原有Jieba分词方法进行分词处理,并使用3种新闻长度不同的公开数据集NLPCC2017、LCSTS和SogouCS进行摘要生成结果研究。通过研究发现,改进T5 PEGASUS模型生成摘要的ROUGE值与新闻文本长度成正相关,更适用于长文本数据集NLPCC2017,并且模型的训练集损失值和损失值下降速度均与新闻文本长度成负相关,在面对少量训练集时能得到较高的ROUGE分数,因此该模型具有较强的小样本学习能力。
