基于自适应GHNG的铝电解过程奇异性数据监测方法
2023-12-04刘天松吴永明李少波盛晓静刘应波
刘天松,吴永明,李少波,盛晓静,3,刘应波
(1.贵州大学 现代制造技术教育部重点实验室,贵州 贵阳 550025;2.贵州财经大学 信息学院,贵州 贵阳 550004;3.山推工程机械股份有限公司,山东 济宁 272000;4.云南财经大学 云南省经济社会大数据研究院,云南 昆明 650221)
0 引言
工业界的万能金属“铝”,在世界各国的工业地位日益提高[1-2],铝合金在国防工业和交通工具领域应用广泛,涌现出大量研究提高铝电解质量的生产工艺[3-4]。因此,通过智能算法对铝电解过程中的杂质含量进行聚类分析,同时对铝电解工艺过程输入参数进行调控,进一步控制杂质含量对提高铝电解质量具有重要意义。
在铝电解生产工艺方面,刘天松等[5]提出基于改进生长神经气算法,研究了电解铝液中Fe和Si含量的特征,构建了阈值机制,并以此实现对铝电解数据的实时监督和预警模型;秦浩等[6]提出在铝电解中应用集成电路技术提高稳流效果,同时有效降低能耗;为实现非线性工业过程小故障的监测,HUANG等[7]基于重构的故障隔离方法提出一种基于核函数非线性学习方法。上述生产工艺奇异性数据的监测大多采用离线数据分析,缺少应对大规模工艺数据流的挖掘算法,无法同时处理生产过程产生的大量在线数据,生产过程状态及存在问题无法准确识别。此外,在数据流聚类算法中,包括传统的生长层次神经气(Growing Hierarchical Neural Gas,GHNG)算法通常固定参数而非根据数据特点采用自适应参数学习。针对上述问题,为提高数据流监测准确性和模型稳定性,本文提出一种实时监测生产工艺过程奇异性数据和自适应聚类方法。
生产过程奇异性数据指生产过程工艺参数出现的“新奇”和“异常”数据,简称奇异性数据。生产过程“奇异性”并非等同于生产异常,后者为前者子集,“新奇”模式促进生产过程朝着高效率、低成本方向发展,“异常”模式则表明生产过程已经/即将出现生产异常[8]。生产过程奇异性(数据)主要是通过聚类分析获得奇异点在所有数据中的位置分布[9]。聚类分析作为数据分析的重要研究工具,其主要思想是按照相似度将大量数据划分为若干簇,使簇内数据点的相似度高,簇与簇之间的相似度低[10-14],在处理多样性和海量工艺过程数据时大多采用距离聚类算法。
生产过程产生的数据大多存在海量性、多样性、时序性和在线特征,需要建立实时监测模型。因此,本文根据生产过程数据特征,提出一种基于改进GHNG算法的自适应监测模型,该模型能有效地对生产过程奇异性数据进行监测与分析。自适应GHNG算法可以实时监测离线和在线输入数据,算法中根据数据特征增加了自适应学习权重、删除、增加、更新模型节点,利用获胜节点累积误差计算权重有效克服固定权重造成节点误差较大情况和网络的不稳定性,同时展现实时聚类结果,为生产/管理者提供一个实时监测可视化结果参考。
1 改进GHNG算法
1.1 GHNG算法原理
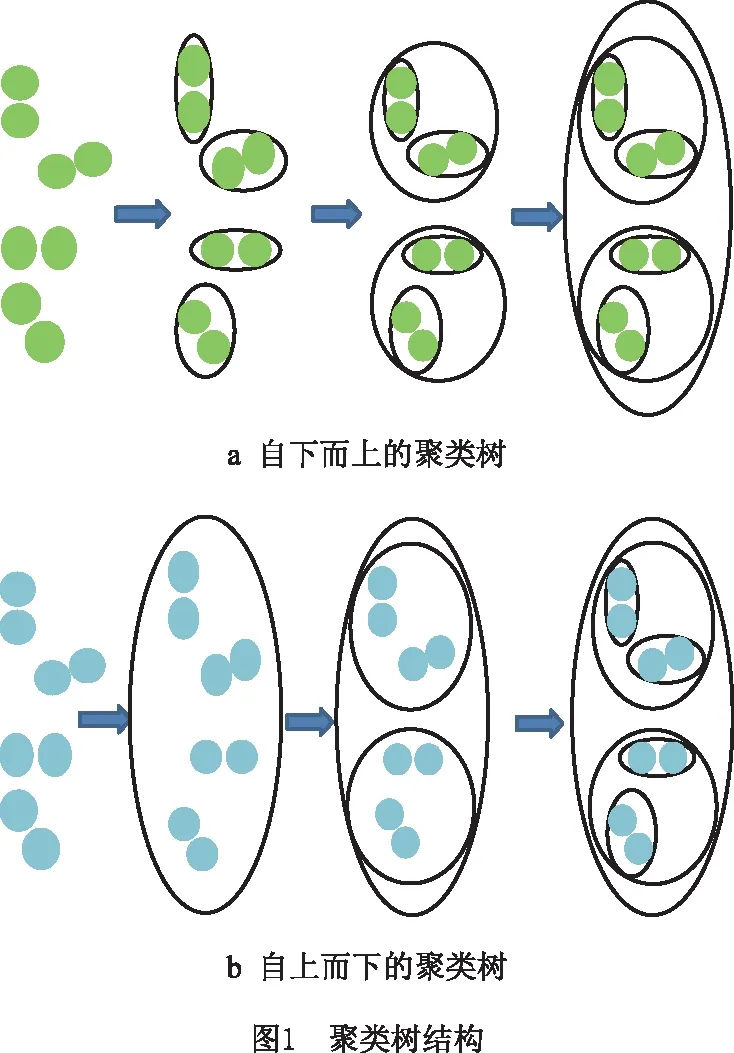
文献[15-16]在2016年基于生长神经气(Growing Neural Gas,GNG)提出GHNG层次聚类模型,模型中增加了垂直生长机制,即同时具有水平生长机制和垂直生长机制。层次聚类算法(Hierarchical Clustering Algorithm,HCA)又被称作树聚类算法[17],主要是通过数据点联接规则,利用一种层次结构将数据有效划分为不同的类。HCA依据聚类方式的不同可以划分为自上而下的聚类树结构和自下而上的聚类树结构,如图1所示。
CIRRINCIONE等[18]利用改进GHNG算法不断增长的分级GH-EXIN(growing hierarchical excitatory inhibitory)神经网络以增量(数据驱动架构)和自组织的方式构建分级树,定性和定量地显示和分析了其方法优点,并应用于结直肠癌基因数据分析研究。AYOOB等[19]利用GHNG和混合遗传算法对入侵系统进行评估,通过层次学习过程对遗传算法的分类器进行拓扑结构展示。然而,该算法无法应对多样性、海量数据流,即在处理海量数据流时出现性能相对不稳定、误差较大的情况。因此,本文采用自适应学习系数的实时聚类方法,实现在线数据流动态监测和结果展示。
1.2 改进GHNG算法
1.2.1 自适应机制
传统GHNG网络模型获胜神经元权重计算公式如下:
Jn*=Jn*+α×(X-Jn*),
(1)
Jn**=Jn**+β×(X-Jn**)。
(2)
式(1)和式(2)中:X表示输入数据;Jn*和Jn**分别表示获胜神经元和邻域神经元的权重;α和β分别表示获胜节点和邻域获胜节点固定学习系数的权值,并满足α>β。
针对每一层神经元在适应性机制中学习系数唯一性,GHNG神经网络模型的每一个拓扑结构是在层数(H)大于2之间建立联系,改进GHNG算法自适应机制主要基于新输入数据驱动获胜神经元节点发生改变,对获胜神经元及邻域神经节点进行权值计算,获胜神经元节点误差定义为:
Esn=Esn+‖X-Sn‖2。
(3)
式中:X为输入数据,Sn表示第n个获胜节点,Esn表示第n个获胜节点的节点误差。为确保算法自适应性,获胜节点和邻域获胜节点的学习系数权重定义为:
α1=(E(S1)/sum(E))×α,
(4)
β1=(E(S2)/sum(E))×β。
(5)
式(4)和式(5)中:α、β分别表示获胜节点和邻域获胜节点的固定学习系数;E(Sn)表示第n个获胜节点的节点误差;sum(E)表示获胜节点误差总和;α1和β1分别表示获胜节点和邻域获胜节点的自适应学习系数权值,获胜神经元和邻域获胜神经元权重定义为:
Jn*=Jn*+α1×(X-Jn*),
(6)
Jn**=Jn**+β1×(X-Jn**)。
(7)
式(6)和式(7)中:X表示输入数据,Jn*和Jn**分别表示获胜神经元和邻域神经元的自适应权重。
自适应GHNG算法基于误差分析,利用实时数据与获胜节点累积误差动态调节权重系数,即依据神经节点权重朝实时数据输入方向移动,同时增加了获胜节点依据误差比重移动的限制,有效保证获胜节点的移速远大于其他节点的移速,进一步提高聚类算法的实时性和精确性。
1.2.2 生长机制
由于传统GHNG算法创建神经元具有周期性,当新数据输入到竞争网络中且属于新的特征空间区域时,算法无法立即适应该区域的表示,因此需要创建新的神经元,其插入新神经元步骤为:首先找到最大获胜节点误差max(ESn)和邻域节点最大误差max(ESL),同时创建一个新获胜节点,使其在最大获胜节点误差max(ESn)和邻域节点的最大误差max(ESL)范围内,其获胜节点坐标定义如下:
Wt=0.5×(WSn+WSL)。
(8)
式中:WSn,WSL,Wt分别表示获胜节点、邻域节点和新获胜节点位置坐标。在插入获胜节点后,断开原来最大误差的获胜节点与最大误差邻域节点的连接,并与新获胜节点重新进行连接。
1.2.3 改进GHNG算法拓扑结构
传统GHNG算法中最终展示结果为获胜节点的拓扑结构,虽然可以展示良好的拓扑结构,但是对于聚类展示结果并不理想。根据K-means聚类算法思想对GHNG划分簇,并且每个簇依据获胜节点展现不同的样式,可以直观展示,具体展示步骤如下:
(1)将第一层获胜节点顺序存储在数据集P矩阵的最后一行。
(2)根据数据集P矩阵中最后一行对所有矩阵X中所有数据分配,方法如下:
P(1:n,:)=X(:,:),
(9)
P(n+1,:)=W。
(10)
式(9)和式(10)中:P表示含有获胜节点顺序的n+1行矩阵,X表示数据集矩阵,W表示获胜节点。
(3)将每一个数据划分到其所有的获胜节点,每个数据有且仅属于一个获胜节点。
(4)对原始数据根据获胜节点的不同划分不同样式。
1.2.4 改进GHNG算法实现
改进GHNG算法主要包括权重计算、节点生成、节点删除和结果展示等机制,具体实现步骤如下:
算法1自适应GHNG算法。
输入:λ:创建单元之间的步骤数
Levelmax、α1、α2、Amax、D、S:最大层数、GNG参数(获胜节点权值系数、邻域节点权值系数、神经元链接的最大年龄、误差系数、样本数据)
垂直生长机制——垂直生长判断条件:
if ((Level>1)&&(n
终止;
else
Level←Level+1(生长下一层开始水平生长机制)
end
水平生长机制——训练生长神经气
fori←1:n
forj←1:m(m个获胜节点)
end
I←Sort(d)
S1←I(1);S2←I(2)
w←S1
C(S1,:)←C(S1,:)-1
C(:,S1)←C(:,S1)-1
Esn←Esn+‖X-Sn‖2
获胜节点学习权重调整:
α1←(E(S1)/sum(E))×α
W1←W1+α1×(X-W1)
邻域节点学习权重调整:
forj←1:i
α2←(E(Sj)/sum(E))×α
Wj←Wj+α2×(X-Wj)
end
{C(S1,S2);C(S2,S1)}←Amax
删除旧节点和孤独节点:
C(t>Amax)=0
N←sum(C)
{C(Sn,:);C(:,Sn);t(Sn,:);t(:,Sn);W(Sn,:);E(Sn)}←[]
增加新节点:
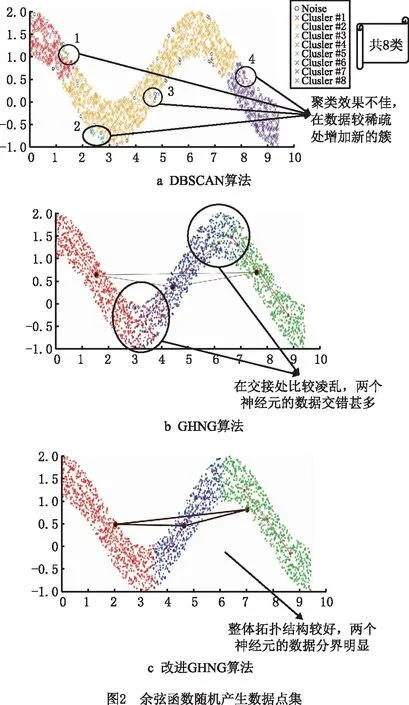
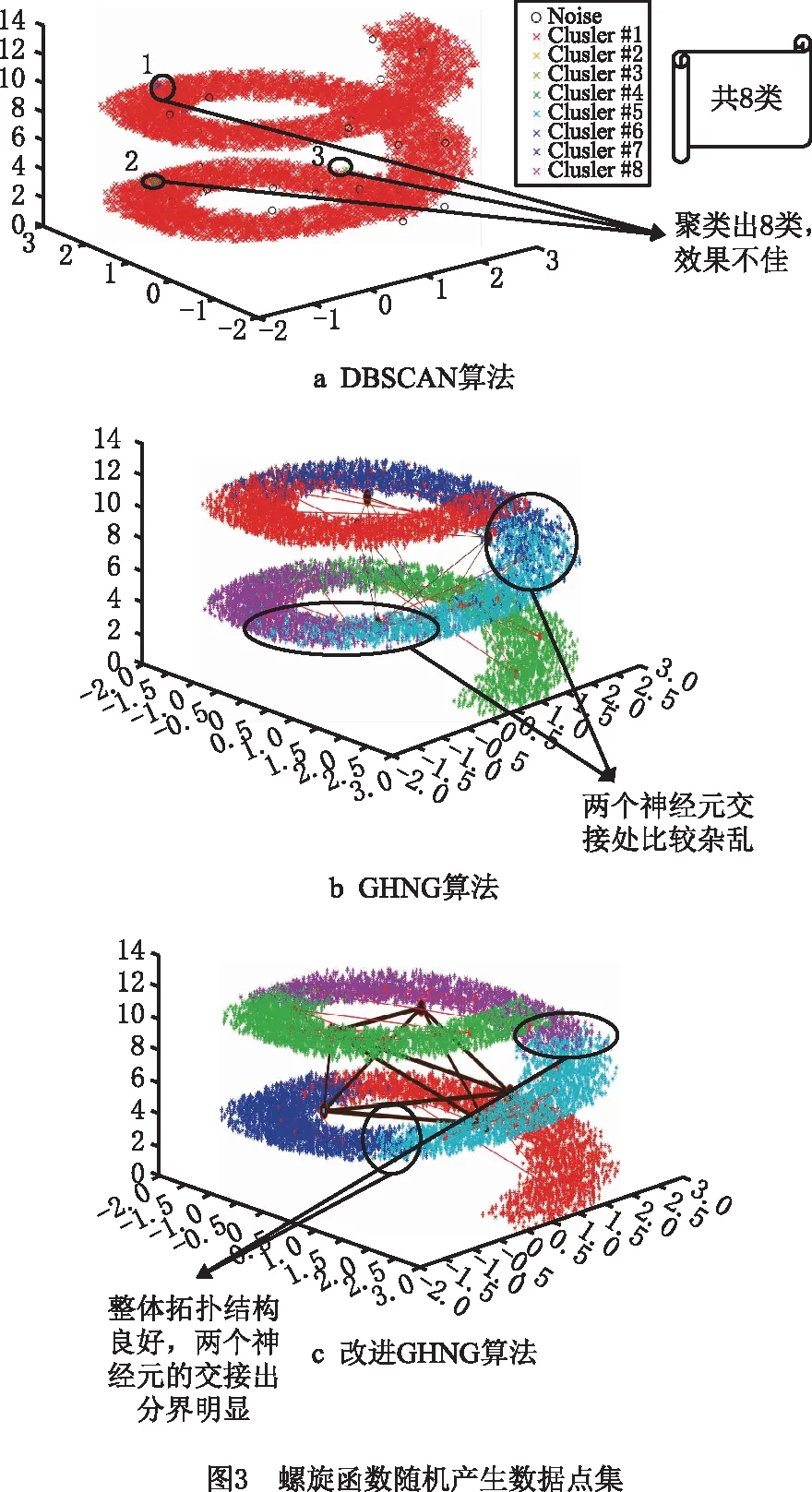
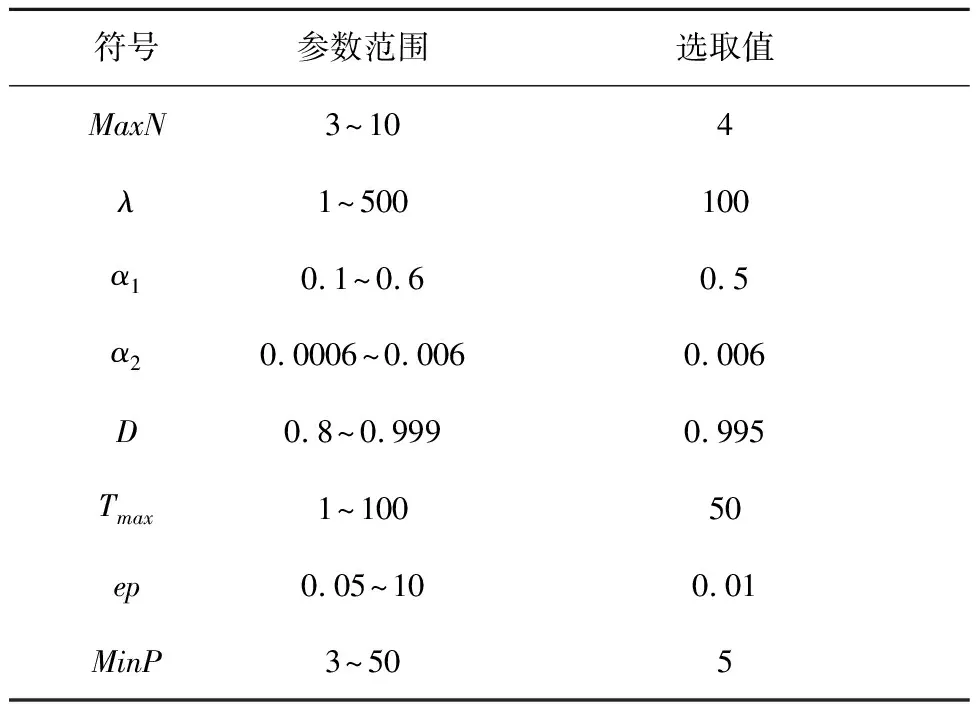
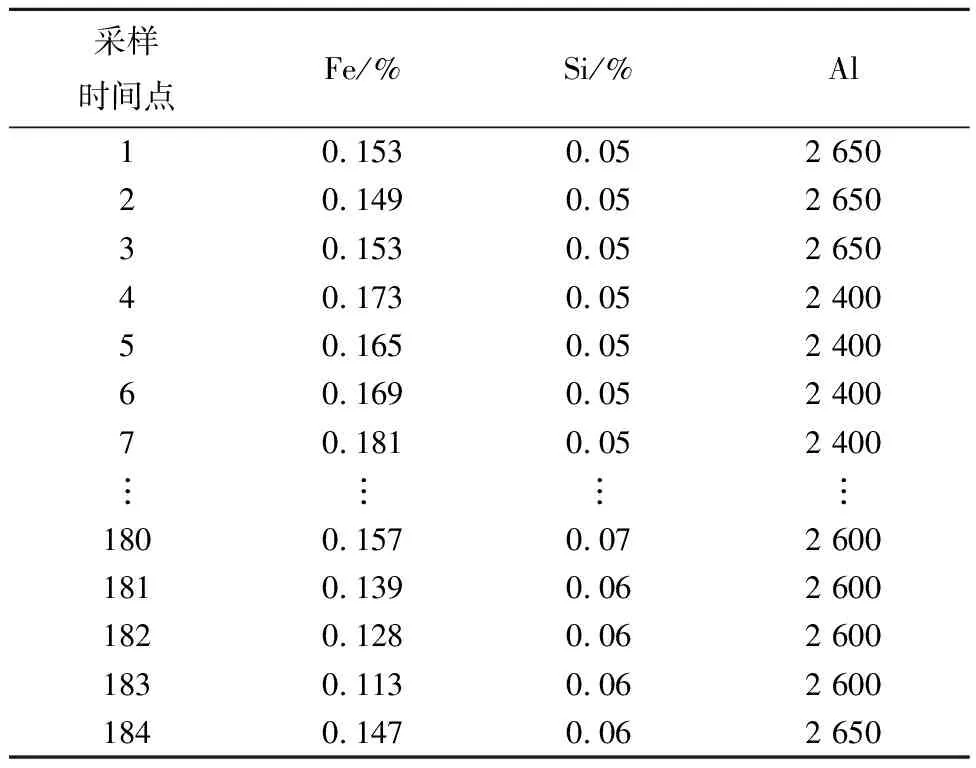
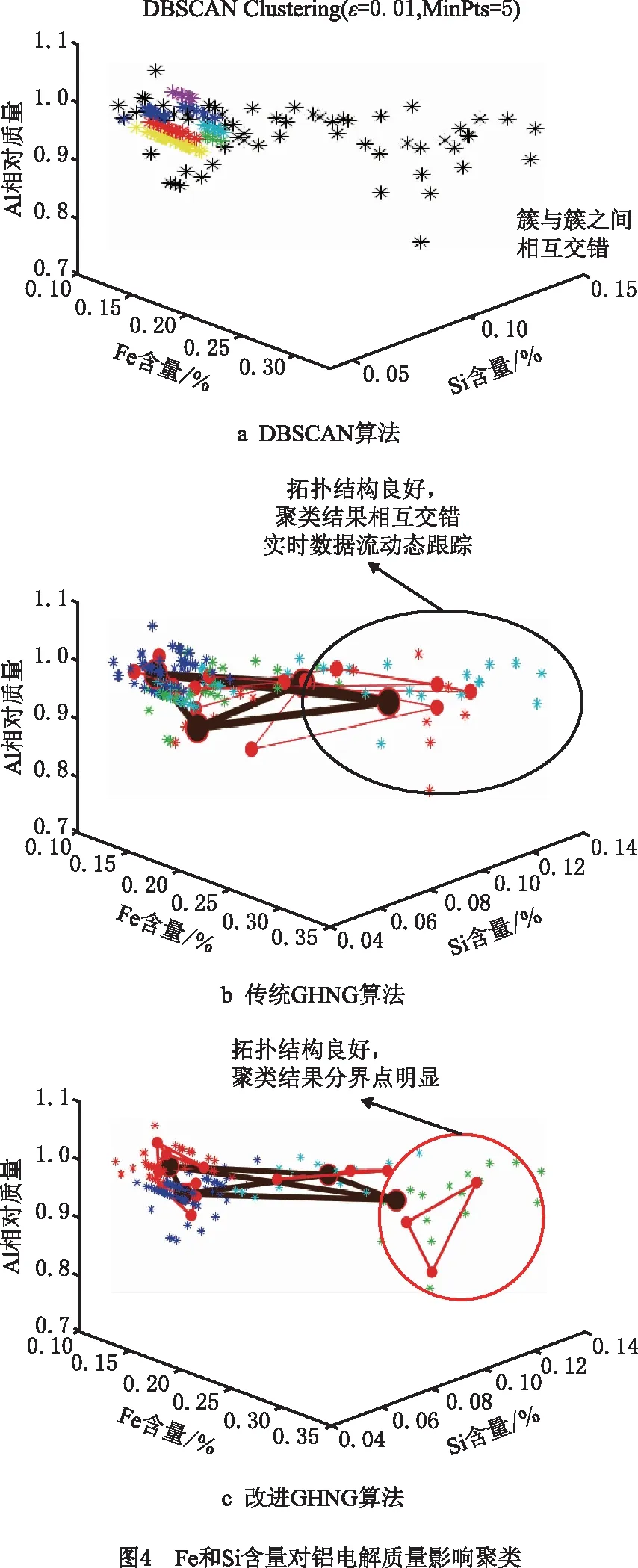
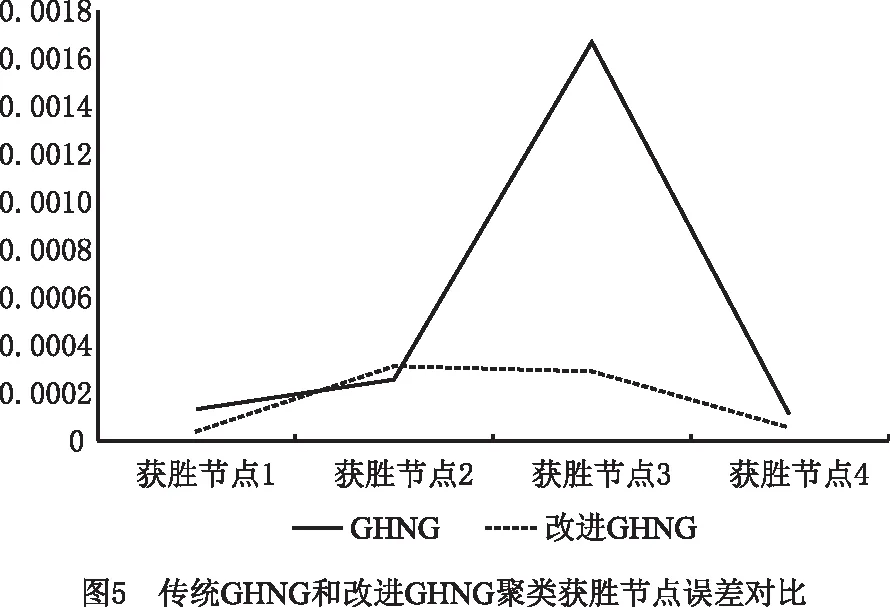
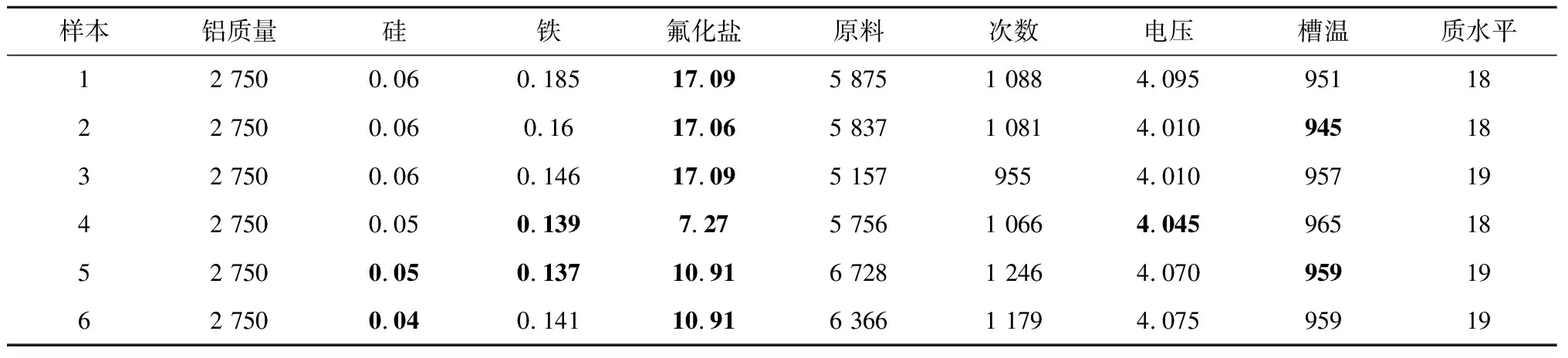
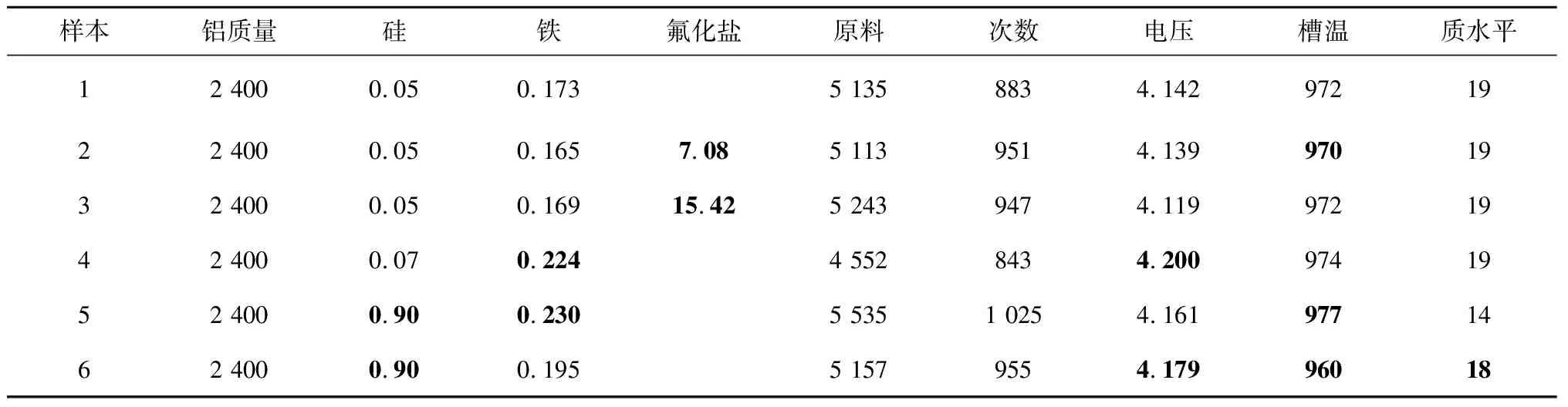
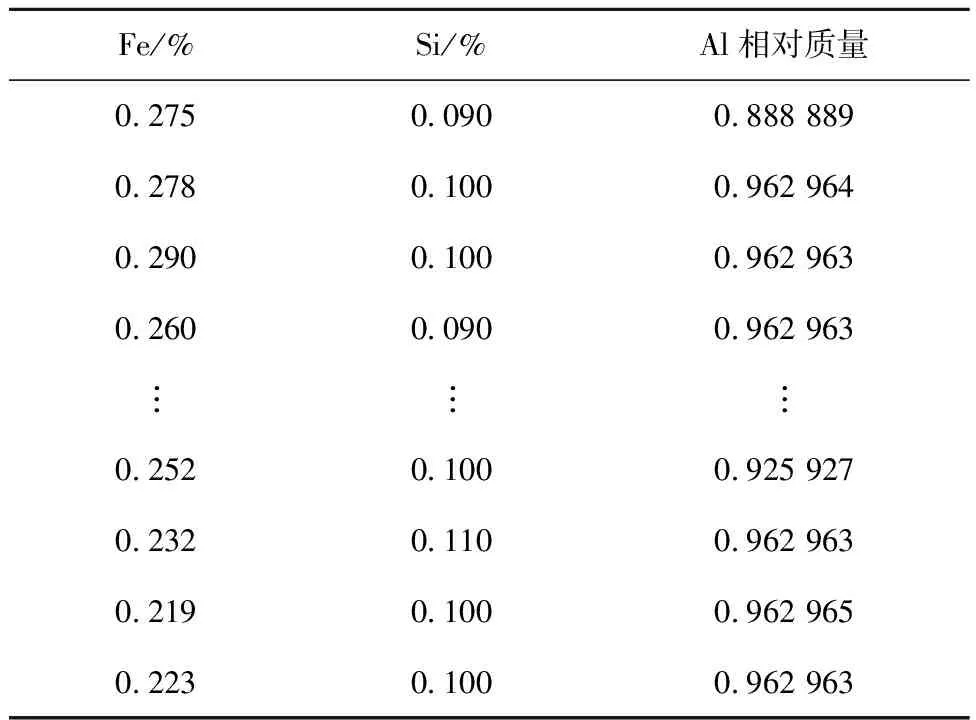
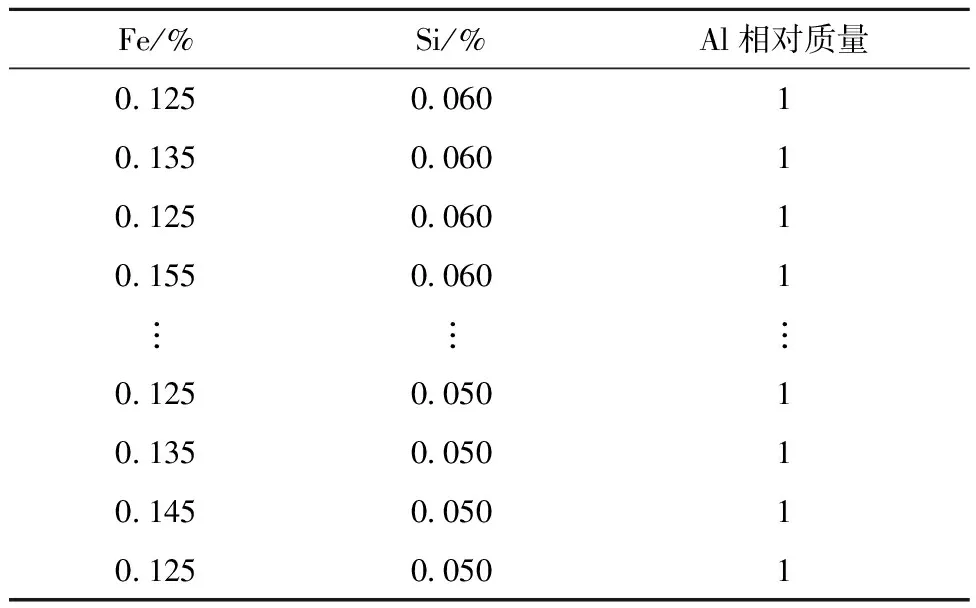
if mod(nx,l)==0&&size(W,1) r←size(W,1)+1 Snewnode←(Serrmax+Serrmax2)/2 {C(Serrmax,Serrmax2);C(Serrmmax2,Serrmax)}←0 {C(Serrmax,r);C(r,Serrmax);C(r,Serrmax2);C(Serrmax2,r)}←1 {t(r,:);t(:,r)}←Amax end end 结果展示: fori=1:n ifpattern(p+1,i)==1 (p是数据的维度) h=plot3(pattern(1,i),pattern(2,i),pattern(3,i),′.′,′Color′,[1 0 0]) else ifpattern(p+1,i)==2 h=plot3(pattern(1,i),pattern(2,i),pattern(3,i),′.′,′Color′,[0.1137 0.6941 0.2471]) else ifpattern(p+1,i)==3 h=plot3(pattern(1,i),pattern(2,i),pattern(3,i),′.′,′Color′,[0 0.5961 0.8588]) end end 改进GHNG算法中,当一个新数据输入到网络中时,计算该数据点到所有获胜节点的欧氏距离并且排序,其复杂度为O(bd)+O(b)=O(b),其中:d为一个常数,O(bd),O(b)分别表示输入数据到获胜节点的距离与所有距离排序的复杂度;在自适应权重系数调整阶段的复杂度为O(1)+O(b);在水平生长机制中的复杂度为O(b)×(O(1)+O(b))=O(b2);在垂直生长机制中,生成K层的复杂度是O(KNb),K表示聚类层数,N表示父代数目。因此,改进GHNG算法复杂度为O(b2×KNb)=O(KNb3)。 为验证本文改进GHNG算法的有效性与可行性,选取DBSCAN、传统GHNG算法和本文改进GHNG算法进行性能分析与对比,同时选用多组数据进行适应性验证,数据分别由余弦和螺旋函数随机分布产生,3种算法参数经过多次调整和实验选取参数如表1所示,其聚类结果如图2和图3所示。 表1 3种算法运行参数 表1中:N表示最大种族个数,λ表示步长,α1和α2表示调节系数,D表示误差调节系数,T是最大年龄,ep表示半径,r表示中心的邻域内最少点的数量。分析数据分别来源于余弦函数(y=cos(x),x∈[0,3π],2 000个数据点,如图2)和螺旋函数(y=2×cos(z),x=2×sin(z),z∈[0,4π],10 000个数据点,如图3)。 由图2a可知,DBSCAN算法聚类效果不佳,在数据稀疏处出现新的簇;图2b和图2c虽然都展示出良好的拓扑结构,但在图2c聚类簇之间数据分界明显。因此,改进GHNG算法聚类效果最佳。图3a中,DBSCAN算法聚类结果不均匀,在均匀分布的数据中聚类效果在边界会出现零散的簇;图3b中,GHNG算法虽然拓扑结构良好,但获胜节点下的数据点在交界处比较模糊,区分度较低;图3c中改进GHNG算法不但具有良好的拓扑结构,而且其聚类结果能充分展示数据分布特征。虽然DBSCAN和GHNG算法不需预先设置聚类簇数目,但DBSCAN聚类方法在处理密度不均匀数据时易出现聚类效果不佳的现象。 因此,本文改进GHNG算法在数据聚类测试中,当数据集规模发生变化时,其聚类结果能充分展现数据特征,具有较强的鲁棒性和精确性。 为进一步验证本文改进GHNG算法的有效性和可行性,以铝电解工艺过程为分析对象,对铝电解过程数据进行实时监测和控制。在铝电解过程中,铝液中不仅有铝还有铁、硅和镁等杂质,考虑铝电解工艺是以提高铝液纯度和铝的生产量为目标,影响铝液纯度和生产量因素较多,如投入料量、氟化盐、电压等。本文仅对铝电解过程中Fe和Si含量(时间序列数据)进行分析,验证该算法对数据具有及时的监测与监督能力,算法参数和原始数据(部分)分别如表2和表3所示。 表2 算法参数 表3 铝电解工艺过程时序数据 表2中:MaxN表示最大种族个数,λ表示步长,α1和α2表示调节系数,D表示误差调节系数,Tmax是最大年龄,ep表示半径,MinP表示中心的邻域内最少点的数量。 实验采用对比分析方法,采集铝电解时间序列数据(铝产量)经过生产工艺的额定量进行转换,得到实验分析数据DBSCAN聚类结果与传统GHNG、改进GHNG算法的拓扑结构和聚类展示结果对比,其拓扑结构动态图如表4所示。 表4 3种算法实时动态跟踪分析 非实时数据是以时间段进入聚类算法中,实时数据是指监测每一个数据进入聚类算法。当n=30、n=90、n=150和n=170时,由表4可知改进GHNG算法聚类结果层次清晰,准确性更高。为进一步分析本文改进算法的鲁棒性,对采集的时序数据总和(6个月)进行聚类分析,其聚类结果如图4所示。 图4a中DBSCAN算法的聚类结果层次模糊(黑色数据点围着其他簇的数据点),效果不佳;图4b中GHNG算法虽然有良好的拓扑结构,但获胜节点未能充分反映数据分布特征,未能及时适应数据的动态变化,在改进GHNG算法中获胜节点拓扑结构展示了良好的聚类效果(如图4c),同时改进GHNG算法中可以清晰的看到绿色数据点(圆圈中部分)相对较少,但是其Fe和Si的含量都较高,并且Al的相对质量也有所降低,所以当数据达到一定范围时便给监管者提供信号,让管理者改变输入参数提高Al的相对质量,对于铝电解生产工艺有明确的指导意义。因为DBSCAN算法与GHNG算法的原理不同,不存在获胜节点,无法进行获胜节点误差的分析,所以仅做传统GHNG和改进GHNG算法获胜节点误差的比较(如图5)。由图5可以看出,GHNG算法的获胜节点误差波动比较大,总体数值较高,但是改进GHNG算法的获胜节点相对稳定,且数值较低。因此,本文改进GHNG算法对数据特征分布具有较强的鲁棒性。尤其重要的是,在改进GHNG算法实时聚类结果中设定阈值可以更方便地对生产工艺过程进行精确控制(如图6)。 如图6所示,根据铝厂生产工艺要求设置Fe含量和Si含量阈值范围分别为0.15%~0.26%和0.05%~0.08%。在铝电解过程中其输出结果低于最小阈值的数据被定义为新奇数据,生产管理者设法调整输入参数尽量使输出结果向新奇数据偏移;超过最大阈值的数据被视为异常数据,在生产过程中出现异常数据便触发报警装置,以便生产管理者对铝电解参数进行实时精确控制。 由于Fe和Si的含量对铝的质量有重要影响,通过分析铝厂半年生产工艺数据,同时筛选铝质量较高和较低的时间段数据(6个样本)如表5和表6所示,方便对Fe和Si含量以及工艺参数进行控制。 表5 铝质量较高的数据 表6 铝质量较低的数据 表5中,粗体标注数据是在加入氟化盐时某些样本中输出杂质含量和对应的电压以及槽温;表6中,粗体标注数据是氟化盐的量降低后对应某些样本中杂质含量和对应电压以及槽温。由表5和表6可知,在影响铝电解质量的众多因素中,氟化盐量对杂质产生含量和铝的质量影响较大。因此,本文调整的主要参数包括投入原料、电压、氟化盐等因素,即为了控制铝产量和质量,不仅要在投料时加入适当的氟化盐,还要控制原料的投入量。由图6中的阈值范围可以检测到在最大阈值外的奇异数据点,并且对最大阈值外的奇异数据点(如表7)进行调整其原料的输入使所有数据(图5)在最大阈值内。 表7 阈值外数据 表8 调整后数据 对原料输入量进行控制后电解铝的质量输出如图7所示,与控制前图6对比可知:在阈值范围外的奇异数据点全部调控到最大阈值范围内,并朝着“新奇”数据漂移,同时原有新奇数据点依旧保持其参数输入,为生产过程中出现偏差较大的奇异数据通过调整投入量来控制输出量在正常范围内,提高生产效率,电解铝质量、杂质含量明显改善。 本文提出了生产过程奇异性相关概念,建立了一种基于改进GHNG自适应聚类模型,即在水平生长机制中建立自适应学习、拓扑结构展示和节点生成机制,实现时间序列数据奇异性的实时监测。最后,以铝电解工艺数据为分析对象,利用DBSCAN、传统GHNG和改进GHNG算法对聚类结果进行比较分析。实验结果表明,本文的改进GHNG算法聚类效果更好,能对铝电解过程奇异性数据进行实时监测并预警,同时根据奇异性数据监测结果,通过铝电解阈值机制与筛选数据方法,使铝电解产量、杂质含量明显改善。因此,该模型和算法对时间序列数据奇异性的监测能力更强,实现了对铝电解过程进行准确、有效的监测和控制,进而为决策者/管理者提供理论技术支持。下一步继续研究生产车间预测模型,为稳定生产提供科学的理论依据。2 仿真研究
3 实验研究
3.1 铝电解工艺过程与数据
3.2 实验结果


4 结束语
