基于密度峰值聚类的正则化LFDA算法
2023-12-04陶新民吴永康包艺璇范芷汀
陶新民,吴永康,包艺璇,祁 霖,陈 玮,范芷汀,黄 珊
(东北林业大学 工程技术学院,黑龙江 哈尔滨 150040)
1 问题的提出
随着各行各业信息化程度的不断提升,数据挖掘技术被广泛应用于从内部数据中提取有效信息来支持企业制定经营决策、工厂维修设备和医院诊断疑难杂症等过程[1]。而数据降维作为数据挖掘必不可少的前期工作,在提高模型精确度、缩短挖掘时间和降低数据存储成本等方面具有重要作用[2]。其中,费舍尔判别分析(Fisher Discriminant Analysis,FDA)作为一种经典的降维算法,通过线性变换将高维样本数据投影到低维向量空间,使投影后同类样本之间的距离尽可能小,不同类别样本之间的距离尽可能大,从而达到利于分类和降维的目的,目前已被广泛应用到医学诊断、风险预警、系统监测等领域[3-5]。在FDA基础上,SUGIYAMA等[6]通过最大化局部类间散度和最小化局部类内散度的方式提出一种局部FDA(Local FDA,LFDA)算法,该方法解决了FDA无法有效处理存在多模态分布和噪声的数据集以及降维空间维数需小于类别数的问题。
然而,由于FDA和LFDA都是有监督降维算法,在进行特征提取时,需要大量有标签数据才能得到较好的泛化性能,但在现实应用中,受各种条件所限,要获取大量有标签样本十分困难,多数情况下只有少数有标签样本可用。当FDA或LFDA利用少数有标签样本进行学习时,容易出现过拟合现象,从而降低泛化性能。因此,如何利用少量有标签数据和大量无标签数据指导FDA的学习成为了广大学者们关注的重点。近年来,半监督学习的出现为解决该问题带来了新的启示。半监督学习是一种介于有监督学习和无监督学习的学习方法[7],相比于单一的有监督或无监督学习,半监督学习可以综合利用少量有标签样本和大量无标签样本中的信息进行学习,进而提高预测模型性能[8]。因此,将FDA算法和半监督学习有效结合可以充分利用少量有标签样本指导无标签样本的学习,得到更好的降维效果[9]。
为保持无标签数据的内在结构,半监督学习通常基于两种假设,即基于流形假设和基于聚类假设。基于流形假设的半监督FDA学习算法在实现类间间隔最大化的同时,通过保持无标签数据间内在流形结构的方式提升降维性能,但基于流形假设的半监督FDA方法在使用正则化项保持数据内在结构时,通常无法同时保证数据全局一致性和局部一致性假设,容易导致判别信息丢失,进而影响降维后的分类性能[10-11]。为避免此问题,学者们开始研究基于聚类假设的半监督FDA降维方法。该方法通常分为两步:首先通过有标签数据与无标签数据的相对几何关系获得无标签数据的伪标签,然后利用有标签数据和具有伪标签的无标签数据共同求解降维子空间[12]。基于聚类假设的半监督FDA降维方法使用聚类算法获得伪标签的方法可以产生较好的降维效果[13-14],但由于聚类算法本身受参数初始值以及噪声影响,使其在数据呈现各种不同形状和大小的聚类结构时获得的伪标签与真实标签相差甚远,进而影响其降维性能;其次,简单地将聚类伪标签作为类标签赋值给无标签样本的方法也极易引起误差传递,降低其鲁棒性,从而导致算法的性能大大降低。
本文将FDA、LFDA、半监督FDA及其改进算法的原理及局限总结如表1所示。

表1 FDA、LFDA、半监督LFDA及其改进算法
为解决上述问题,本文使用密度峰值聚类(Density Peak Clustering,DPC)算法[26]获得聚类伪标签。相比于其他聚类算法,该算法不需要预先设定聚类个数,对初始参数不敏感,且能识别出各种形状和大小的聚类,因此可以避免聚类算法参数和数据分布形态对降维性能的影响,非常适合聚类个数未知情况下的高维复杂数据聚类伪标签求解问题。
鉴于此,本文提出一种基于密度峰值聚类的正则化局部费舍尔判别分析(Density Peak Clustering-based Regularized Local Fisher Discriminant Analysis,DPC-RLFDA)算法,该方法结合半监督学习思想,可以充分利用无标签数据指导FDA的学习过程。本文主要工作如下:首先对正则化LFDA和DPC相关的算法原理进行阐述,从而引出本文的DPC-RLFDA算法;其次采用密度峰值聚类算法获得无标签和有标签样本的聚类伪标签,分别构建正则化项并整合到类内散度矩阵和类间散度矩阵,有效地增强了提取特征的判别能力,降低了误差传递并使所提算法适用于多模态和噪声存在的数据;同时结合核函数提出基于DPC的正则化KLFDA算法(Kernel Density Peak Clustering-based Regularized Local Fisher Discriminant Analysis-DPC-RLFDA,KDPC-RLFDA),使得该算法可以求解非线性非高斯数据的降维问题;最后给出本文算法优势的理论分析、降维维度分析、算法流程和计算复杂度。通过在人工数据集和UCI数据集上的大量实验,证明了本文算法降维性能较其他算法有较大提升。
2 正则化局部费舍尔判别分析及其算法原理
2.1 费舍尔判别分析算法原理
费舍尔判别分析(FDA)是一种有监督降维方法,其主要工作原理是:对于给定训练样本集,首先寻找使投影后同类样本点尽可能近,异类样本点尽可能远的最佳投影方向,然后根据未知类别样本在该方向投影后的位置确定类别。
假设有标签样本xi∈Rd及其对应标签yi∈{0,1,…,c}(i=1,2,…,n),其中:n表示样本的数量,c表示样本的类别数。
令Sw和Sb分别代表类内散度矩阵和类间散度矩阵:
(1)
(2)
其中:μl表示类l中样本的平均值,μ表示整个样本的平均值,Φl表示属于类l中的样本数,即
(3)
(4)
(5)
假设类内散度矩阵Sw满秩,则FDA的目标函数BFDA可定义为:
(6)
其中:BT为投影矩阵,tr(·)表示矩阵的迹。即FDA趋向于寻找实现类间散度最大化,同时类内散度最小化的低维投影子空间BFDA来保证低维子空间中不同类别之间最大程度的分离性。但当数据集不服从高斯分布时,FDA通常不能获得较好的算法性能;此外,FDA中类间散度矩阵的秩最多为c-1,这意味着它最多可以找到c-1个有意义的特征;而且,FDA在计算类间散度时,没有考虑同类样本的多模态分布特征和异常值存在的情况。为了解决上述问题,SUGIYAMA等[6]通过最大化类间散度可分离性和最小化局部类内散度的方式提出一种局部FDA算法。
2.2 局部FDA算法原理
令Xn={x1,x2,…,xi,…,xn}∈Rd×n表示有标签数据集,Xm={Xn,Xu}={x1,x2,…,xi,…,xm}∈Rd×m表示整体数据集,其中xi∈Rd表示第i个数据,yi∈{1,2,3,…,c}是xi的数据标签,c为类别数,d为原始空间维度,n为有标签数据的总数,m为训练样本的总数,m>n,则Xu为无标签数据集。若在r维低维子空间中通过投影矩阵H∈Rd×r变换得到xi的投影表示Ji∈Rr(1≤r≤d)为
Ji=HTxi,
(7)
则由文献[6],LFDA的优化函数可表示为:
(8)
显然,LFDA的目的是为了寻找使HTSlbH和HTSlwH的比值最大的投影矩阵HLFDA。然而,当LFDA没有充足的有标签样本用于训练时,容易产生过拟合现象。阻止过拟合的一种常用方法就是引入一个有关无标签样本的正则化项到目标函数中。
2.3 正则化LFDA算法原理
正则化后的LFDA(RLFDA)的目标函数表达如下:
Srlb=Slb+βSulb,
(9)
Srlw=Slw+βSulw,
(10)
(11)
其中:Sulb,Sulw为与无标签数据相关的两个正则化项,它们分别用于规范化类间散度矩阵和类内散度矩阵;参数β∈[0,1]控制无标签数据的重要程度。正则化后的LFDA为将先验知识结合到目标函数提供了便利。例如,若Sulb,Sulw可以通过主成分分析(Principal Components Analysis,PCA)保持无标签数据的全局结构[27],则经过PCA正则化后的类间散度和类内散度矩阵的表达如下:
SrlbPCA=Slb+βS(t),
(12)
SrlwPCA=Slw+βId。
(13)
其中:Id为d×d的单位矩阵;S(t)为总的散度矩阵。
(14)
其中W(t)是m×m的矩阵,其元素为:
(15)
由此,可以进一步得到S(t)的矩阵表达形式:
S(t)=XmL(t)XmT。
(16)
其中L(t)=D(t)-W(t)∈Rm×m,D(t)∈Rm×m为一个对角矩阵,其第i个对角元素是
(17)
因此,经过PCA正则化后,LFDA的目标函数矩阵表达形式为:
(18)
除了利用PCA保持全局结构,还可以通过引入局部保持投影(Locality Preserving Projections,LPP)正则化项实现局部空间一致性假设[28],即原始空间中具有高度一致性的样本在降维空间中也应该彼此靠近。经过LPP正则化后的类间散度和类内散度矩阵的表达如下:
SrlbLPP=Slb+βS(m);
(19)
SrlwLPP=Slw+βS(1)。
(20)
其中S(m)和S(1)是两个正则化矩阵,其定义如下:
S(m)=XmD(m)XmT,
(21)
(22)
其中D(m)是m×m的对角矩阵,其第i个对角元素为
(23)
W(1)为m×m的矩阵,其元素为:
(24)
其中:Ai,j为xi和xj之间相似性的相似度矩阵[28],
(25)
参数σi为xi的局部化尺度参数,
σi=‖xi-xi(k)‖。
(26)
其中xi(k)为xi的第k近邻,‖·‖表示欧几里得距离,通常,k=7。
S(1)可以进一步表示成如下矩阵形式:
S(1)=XmL(1)XmT。
(27)
其中L(1)=D(1)-W(1)∈Rm×m,D(1)∈Rm×m是一个对角矩阵,它的第i个对角元素为:
(28)
因此,经LPP正则化后,LFDA的目标函数的矩阵表达形式为:
(29)
如上所述,经PCA或LPP正则化后的半监督FDA降维方法可以利用无标签样本达到保持数据全局或局部几何结构的目的。但这种方法没有考虑样本间的判别信息,从而使降维后的子空间无法有效提升分类性能。鉴于此,本文提出一种基于密度峰值聚类的正则化LFDA算法(DPC-RLFDA),该算法可有效提升降维特征的判别性能,进而有利于后续的分类任务。
3 密度峰值聚类算法
密度峰值聚类算法(DPC)是2014年发表于Science的快速聚类算法[26],该算法不需要预先设定聚类个数,对初始参数不敏感,且能识别各种形状和大小的聚类,非常适合聚类个数未知情况下的高维复杂数据聚类伪标签求解问题。
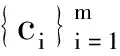
(30)
ListQ={ρq1,ρq2,…ρqm};
(31)
(32)
(33)
其中:dij表示第i个样本和第j个样本之间的欧式距离,dc为截断距离,通常设置为升序排列后距离总数前1%~2%的距离值[26],ListQ为ρi按降序排列的集合,dqiqj为第qi个样本和第qj个样本之间的欧式距离。
为了快速确定聚类中心,DPC以ρi为横坐标,以δqi为纵坐标绘制决策图[26],在实际操作中,可以用下式设置并选取参数θi数值相对较大的点来更快速准确地确定聚类中心:
θi=ρi·δqi。
(34)
有关DPC算法的详细描述,请参考文献[26]。
4 基于密度峰值聚类的正则化LFDA算法
为了提升降维特征判别性能,本文利用密度峰值聚类算法求解全体样本集合Xm伪标签,并将这些伪标签以正则化项形式合并到LFDA目标函数中,以保持数据结构的全局和局部一致性假设,具体描述如下。
4.1 DPC-RLFDA算法
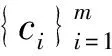
利用获得的聚类标签集合和边界点标识集合构造局部簇间散度Sulbpc和局部簇内散度Sulwpc正则化项,具体表达如下:
(35)
(36)
其中,Wulbpc,Wulwpc为两个m×m的矩阵:
(37)
(38)
其中:mci表示聚类ci中样本的数量,Ai,j表示xi和xj之间相似性的相似度矩阵,详细定义如式(25)所示。
将以上两个构造好的正则化项分别合并到LFDA算法的类间散度和类内散度矩阵中,具体表达如下:
Srlbpc=Slb+βSulbpc,
(39)
Srlwpc=Slw+βSulwpc。
(40)
其中Slb,Slw分别表示有标签样本类间散度和类内散度矩阵,如文献[6]中式(9)所示,Sulbpc,Sulwpc为全体样本簇间散度和簇内散度矩阵,如式(35)和(36)所示,β∈[0,1]为折中参数,用来控制无标签样本的重要性,则本文算法的优化目标函数如下:
(41)
4.2 算法理论分析
为方便说明经密度峰值聚类伪标签正则化后的类间散度矩阵的优势,将矩阵Srlbpc表示为成对(pair-wise)形式:
(42)
其中Wrlbpc是m×m矩阵,
(43)
与文献[6]中式(11)相比,对于同属一类的两个样本,根据其所属簇(伪标签)对其类间散度权重作了更加精确的区分,具体如下:
(44)
因为m>mci,Aijβ>0,所以
(45)
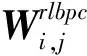
对于不同类别的两个样本,根据所属簇(伪标签)对类间散度权重也作了调整:
(46)
同样,为方便说明经聚类伪标签正则化后的类内散度矩阵的优势,本文将矩阵Srlwpc表示为pair-wise形式:
(47)
其中,Wrlwpc是m×m矩阵,
(48)
与文献[6]中式(10)相比,对于同属一类和不同属一类的两个样本,根据其所属簇(伪标签)对其类内散度权重也作了如下调整:
(49)
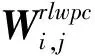
4.3 基于核的KDPC-RLFDA
为实现非高斯数据的半监督降维,通过核函数给出本文算法的核版本。为方便表达,首先给出Sulbpc的矩阵表示:
Sulbpc=XmLulbpcXmT。
(50)
其中Lulbpc=Dulbpc-Wulbpc∈Rm×m,Dulbpc∈Rm×m是一个对角矩阵,其第i个对角元素为:
(51)
同理,Sulwpc的矩阵表示为:
Sulwpc=XmLulwpcXmT。
(52)
其中,Lulwpc=Dulwpc-Wulwpc∈Rm×m,Dulwpc∈Rm×m是一个对角矩阵,它的第i个对角元素为:
(53)
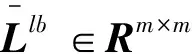
(54)
(55)
将式(54),式(55)代入式(41),本文算法的目标函数可进一步表示为如下矩阵形式:
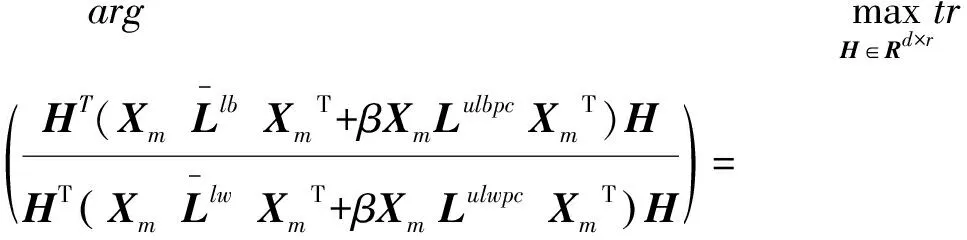
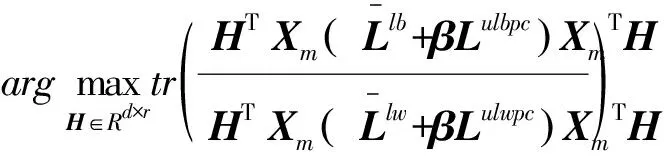
(56)
相应地,广义特征值问题可表示为:
(57)

φ(x),φ(z)〉=κ(x,z)。
(58)
其中κ(x,z)表示半正定核函数,高斯核函数作为经典的核函数表达如下:
(59)
式中σ为高斯核宽度。有关其他核函数的定义请参见文献[18]。
进一步,令K表示核矩阵,其元素为:
Kij=〈φ(xi),φ(xj)〉=φ(xi)T×φ(xj)=κ(xi,xj)。
(60)
根据核理论,假设在F空间进行本文算法降维,则公式(57)可进一步表达为:
(61)
式中φ由{φ(x1),φ(x2),…,φ(xm)}扩展得到:
(62)
式中:ai代表φ(xi)对应的系数,a=(a1,a2,…am)T表示系数矩阵。将式(62)带入式(61)中,同时公式两边左乘φ(Xm)T得到:
(63)
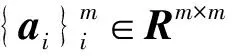
HKRLFDAPC=(φ1,φ2,…,φr)=
φ(Xm)(a1,a2,…,ar)。
(64)
结合式(1)和式(64),可以获得未知样本x∈Rd×1在降维子空间的特征表达J∈Rr×1,如下所示:
φ(Xm)Tφ(x)=(a1,a2,…,ar)TK(:,x)。
(65)
其中K(:,x)=[κ(x1,x),κ(x2,x),…,κ(xm,x)]T。
4.4 本文方法的降维维度分析
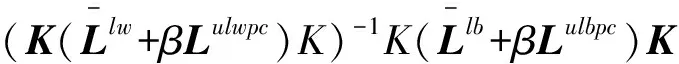
(66)
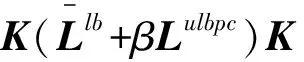
4.5 本文算法的算法流程
算法1基于密度峰值聚类的正则化LFDA算法。
输入:整体样本集Xm∈Rd×m,有标签样本集Xn∈Rd×n及其相应的标签集yi∈{1,2,…,c},低维子空间的维度r,DPC的截断距离dc,高斯核宽σ,其中c为类别数,d是原始空间维度,n是有标签样本的数量,m表示训练样本的数量,m>n,d≥r≥1;
输出:投影矩阵HKRLFDAPC。
4.构造高斯核矩阵K,求解式(57)的广义特征值问题;
5.选择r个最大特征值对应的特征向量构造HKRLFDAPC∈Rm×r。
4.6 本文算法的计算复杂度
由以上分析可知,本文算法的计算复杂度主要由生成全体样本聚类伪标签的DPC聚类算法的复杂度O(m2),计算有标签样本的局部类间散度和类内散度矩阵的复杂度O(n2)以及计算全体样本的局部类间散度和局部类内散度矩阵的复杂度O(m2)组成,其中m为全体样本的数量,n为有标签样本的数量。因为m>n,所以本文算法总的计算复杂度为O(m2),这和其他现有LFDA算法及其变体的计算复杂度相同。
5 实验与分析
为了证明DPC-RLFDA算法处理数据降维问题时的有效性,本文采用人工数据集、部分UCI数据集以及实际轴承故障诊断数据作为实验数据,分别对提出的算法与FDA及其改进算法进行性能测试和对比。
5.1 判决超平面的确定
为了直观地验证数据降维后的判别性能,本文以两类分类界面作为判别超平面,具体定义如下所示:
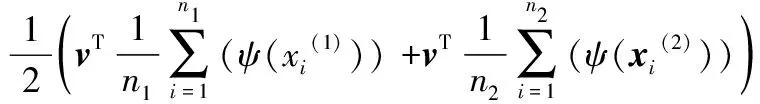
(67)
5.2 人工样本的判别性能对比分析
为了直观地描述本文提出的DPC-RLFDA算法的线性判别性能,将本文算法与LPP,PCA,FDA,LFDA,LPPLFDA,PCALFDA和SDLFDA算法的性能进行对比分析。实验数据采用改造后Twomoons数据集,其样本数为144个,有标签样本20个,无标签样本124个;对于本文算法,截断距离选取使每个数据点的平均距离个数为数据点总数2%的距离大小。实验中将规范化折中参数β统一设置为0.5,降维维度设置为r=1。不同算法在改造后Twomoons数据集上降维后的判别性能如图1所示,其中红色和蓝色数据点分别表示属于不同簇的有标签样本,绿色数据点表示无标签样本。
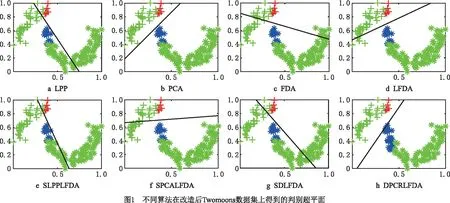
如图1所示,LPP算法和PCA算法得到的投影向量能最大程度地保留数据局部空间一致性和全部空间一致性。而FDA算法以及LFDA算法得到的投影向量能较好地实现有标签样本的判别,但却无法实现无标签样本的准确分类。这是由于这两种有监督降维算法没有利用无标签样本指导降维学习,从而导致算法得到的投影向量只适用于有标签样本区分。相比有监督降维算法,基于LPP和PCA的半监督降维算法SLPPLFDA和SPCALFDA虽利用无标签样本有效保留了数据的局部空间一致性和全部空间一致性,但得到的投影向量同样不能实现无标签样本的有效区分。基于聚类的半监督LFDA降维算法(SDLFDA)因模型受非高斯分布影响未能准确实现无标签样本的聚类伪标签求解,从而导致得到的投影向量无法实现无标签样本的有效区分。相比而言,本文算法得到的投影向量不仅能准确区分两类有标签样本,还也能实现无标签样本的有效区分。这是由于本文算法采用DPC聚类技术求解伪标签,并利用伪标签构造两个正则化项用以规范LFDA类间散度矩阵和类内散度矩阵,从而有效提升降维特征的判别性能。
为了直观地验证本文提出的KDPC-RLFDA算法的非线性判别性能,将本文算法与KLPP、KPCA、KFDA、KLFDA、KSLPPLFDA、KSPCALFDA和KSDLFDA算法的性能进行对比分析。其中数据集采用的是Twocircles数据集,其样本数为500个,其中有标签样本157个,无标签样本343个。核参数为高斯核,高斯核宽度采用5次交叉验证从σ={0.1,0.3,0.5,0.7,1,3,5,10}中择优选取。对于本文算法,所有参数设置同上。不同算法在Twocircles数据集上降维后的判别性能如图2所示,其中红色和蓝色数据点分别表示属于不同簇的有标签样本,绿色数据点表示无标签样本。
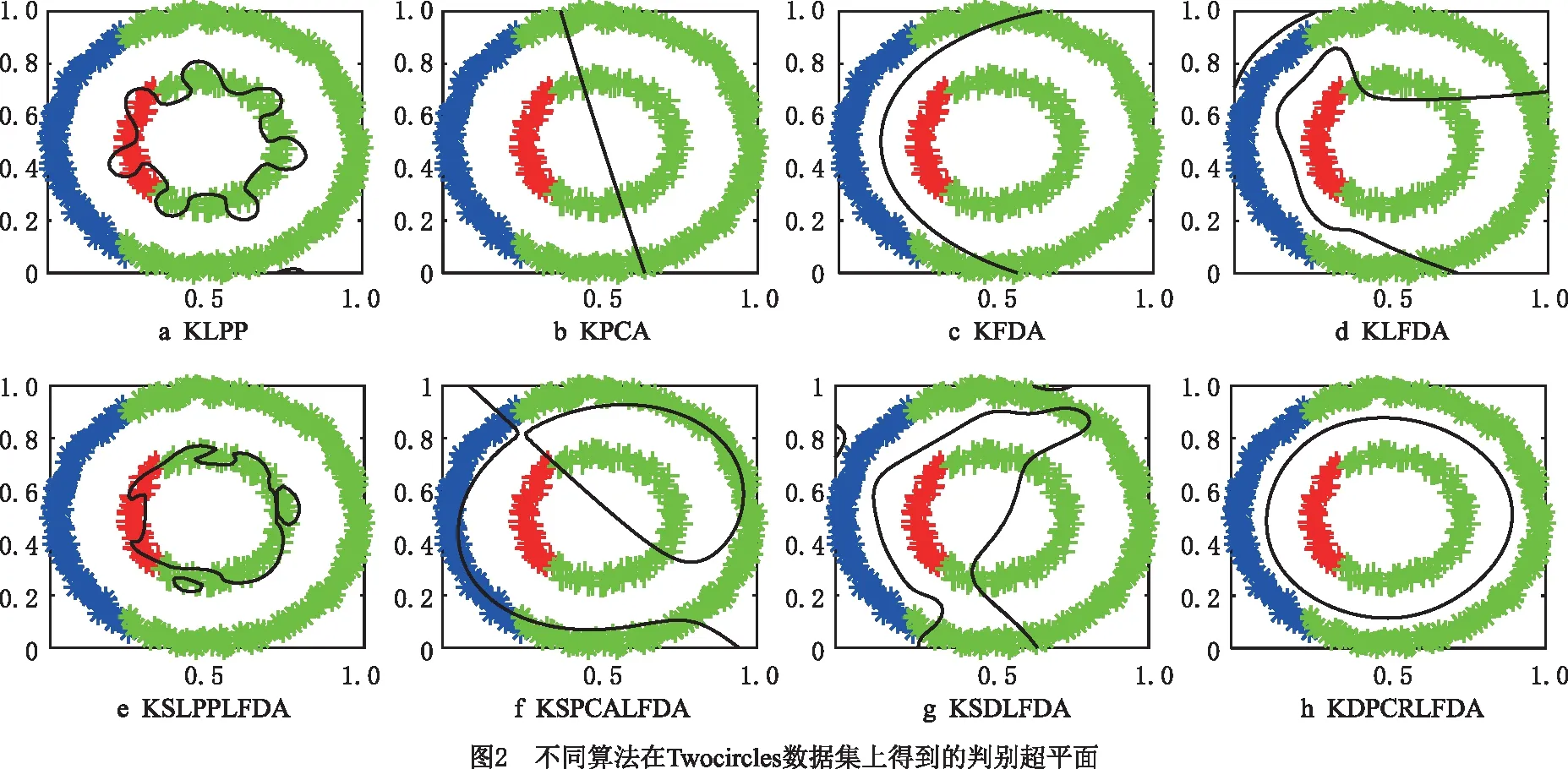
如图2所示,当数据呈现非线性可分分布特征时,与LPP和PCA相同,KLPP和KPCA同样无法实现不同类别的有效区分。相比而言,KFDA和KLFDA算法在核函数选择适当时,所产生的判别边界可以有效区分不同类别的大多数有标签样本。但是,由于KFDA和KLFDA属于有监督学习算法,不能利用无标签样本指导降维学习,因此得到的判别边界无法实现不同类别无标签样本的有效区分。与有监督降维方法相比,基于LPP和PCA半监督学习的KLPPLFDA和KPCALFDA算法虽然利用无标签样本保持局部结构和全局结构的一致性假设,但得到的判决界面仍无法实现无标签样本的有效区分。KSDLFDA算法由于受不精确伪标签的影响,得到的判别边界同样无法有效区分不同类别的无标签样本。相比其他算法,本文提出的KDPC-RLFDA算法可以有效实现有标签样本和无标签样本数据的区分。
5.3 UCI数据集的判别性能对比
为验证本文提出的算法对不同结构数据集的判别性能,进行下列实验。其中实验数据来源于国际机器学习标准数据库UCI中的8组不同的数据集,分别为WINE、BREAST CANCER、HABERMAN、IONOSPHERE、GLASS、HEART、SONAR和CAR,数据的特征信息如表2所示。
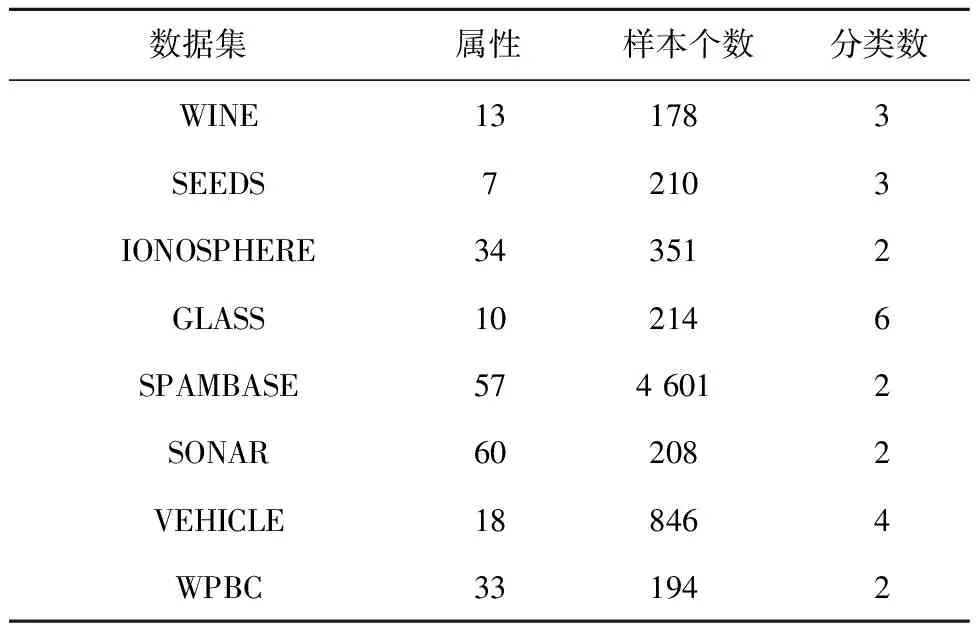
表2 实验数据集描述
将本文算法与目前流行的其他判别分析算法进行对比实验,包括FDA算法、LFDA算法、LPPLFDA算法、PCALFDA算法、基于标签传播半监督线性FDA算法(Semi-Supervised Dimensionality Reduction Model,SSDRM)[23]、半监督广义判别分析算法(Semi-Supervised Generalized Discriminant Analysis,SSGDA)[14]、迭代半监督判别分析算法(Semi-Supervised Discriminant Analysis,SSDA)[24]、基于聚类的半监督LFDA降维算法(Semi-supervised Dense-clustering Local Fisher Discriminant Analysis,SDLFDA)[25]。其中分类器为1-NN分类器并采用正确分类率(CCR)作为性能评价指标,实验采用5次交叉验证,半监督算法的参数β=0.5,本文算法的截断距离设置同上,降维维度r=2。同时,为了消除随机因素的影响,本文对每个算法均独立运行31次,然后取CCR的平均值,每个数据集的统计分析结果通过盒线图进行对比分析,结果如图3所示。
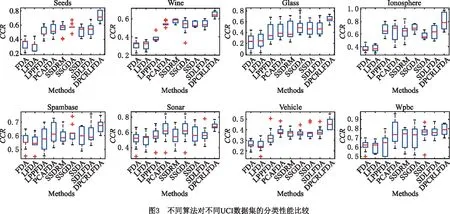
由图3中可知,FDA和LFDA的分类精度最低。这是由于FDA和LFDA属于有监督学习,只依赖有标签样本进行学习,导致其降维后的特征只适合有标签样本的判别,泛化性能较弱。相比而言,虽然LPPLFDA算法和PCALFDA算法的分类性能有所提升,但由于二者都没有充分利用无标签样本的判别信息指导降维学习,导致其性能提升并不明显。其他基于标签传递和聚类技术的半监督学习算法如SSDRM、SSGDA、SSDA和SDLFDA,虽利用了未标签样本的判别信息指导降维学习,但受伪标签生成精度的影响,其分类性能的提升并不显著。从统计结果可以看出,本文提出的算法分类性能最优。这是由于本文算法采用半监督学习方式,能够合理利用无标签样本所含判别信息指导LFDA降维学习,同时利用伪标签构造两个正则化项用以规范化LFDA类间散度矩阵和类内散度矩阵,使得降维后的特征区分性能更强,有利于后期的分类器分类,因此得到的分类性能最优。
5.4 故障诊断数据的性能对比
为了验证本文算法在处理多模态含噪声数据时的降维性能,将其应用在含多种故障类型的轴承故障检测数据中。本次试验采用的所有数据均来自于轴承故障监测试验台,试验台由驱动电机、滚动轴承、传动齿轮、模拟负载、加速度传感器和数据采集系统组成。为获取不同类型的轴承故障信号,在6206球轴承上人工引入3种结构缺陷,其中包括外圈约0.6 mm宽的裂纹、内圈约0.6 mm宽的裂纹和滚珠约1 mm直径2 mm深的凹痕。试验采用6206球轴承,内圈直径33 mm,外圈直径62 mm,球径9.5 mm,球数10个。采样率为10.24 khz,每个采样点1 024个。试验在转速为1 500 rpm的情况下进行。在1 500 rpm工况下,外圈、内圈和滚珠对应的故障特征频率分别为89.27 Hz、135.73 Hz和57.95 Hz。众所周知,当轴承发生故障时,摩擦力和冲击力的增加往往会引起时频域参数的变化,使得正常轴承和故障轴承的信号在时域和时频域上呈现出不同的分布特征。因此,在本试验中,首先选取12个与时域信号相关的统计特征,包括均值、平均绝对值、均方根、方差、标准差、峰、峰-峰,偏度、峰度、峰值因子、间隙因子和形状因子。这12个特征在时域上都能有效反映不同轴承工况下对应的时间序列分布特征。此外,为了能充分表达能量在时频域的分布,本文还采用了5层DB4小波分解系数相关的6对能量和能谱熵特征,它们分别对应5个细节层和1个近似层。同样,本文还采用经验模型分解(Empirical Mode Decomposition,EMD)的6对能量和能谱熵特征来区分不同类型的故障信号,分别对应5个本征模态函数(IMF)和1个残差分量。36维特征的详细定义请参考文献[29]。数据集包括8种不同健康状况组合:正常(NC)、内圈故障(IF)、外圈故障(OF)、滚动体故障(RF)、IF+OF、OF+RF、IF+RF和IF+OF+RF。此外,为了模拟实际应用,本文在数据集中加入白噪声,得到信噪比分别为10 dB、5 dB和2 dB的3种噪声数据。对于每个数据集,每类都有1 000个样本,每个样本有1 024个采样点,其中50%实例作为训练集,剩余的实例用于测试。采用1NN作为基分类器,考虑到FDA方法得到的降维子空间维数小于类数,本次试验将低维空间维数r统一设置为7。为避免随机性,独立执行每个算法31次,然后计算其平均CCR和偏差。对于半监督算法,每次运行时随机选择200个实例作为标签样本,其余实例作为未标签样本,其他实验参数设置同上。统计结果见表3。
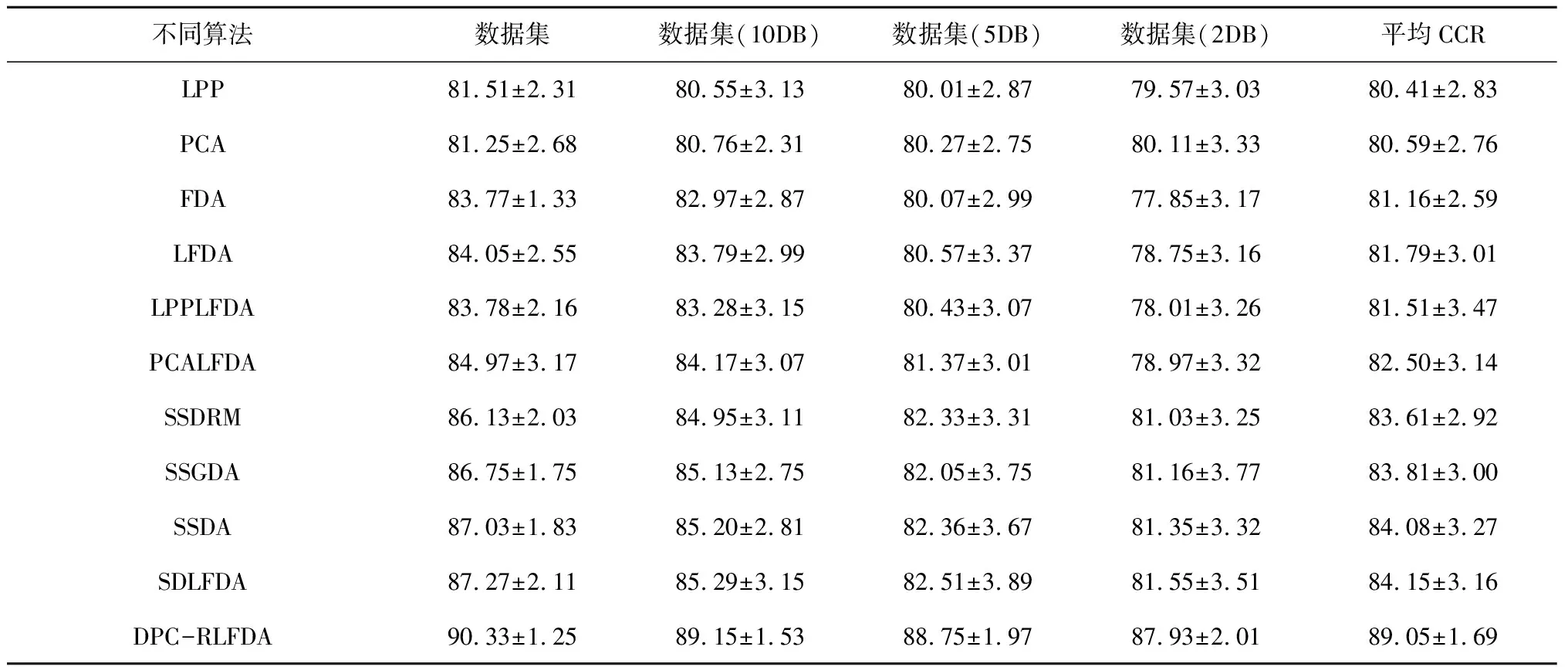
表3 不同降维方法对4种多模态含噪轴承故障数据集的分类性能
如表3所示,与其他同类算法相比,本文提出的DPC-RLFDA降维算法在所有多模态和含噪声的轴承故障数据集上表现最优。此外,随着信噪比降低,各种算法的分类精度也随之变差。这意味着噪声的存在对这些降维算法的性能产生了负面影响。因此,降低噪声对降维算法性能的影响显得尤为重要。所幸本文提出的DPC-RLFDA降维算法通过引入基于DPC的伪标签生成技术正则化项,能有效识别噪声或异常值的未标签样本以及弱化有标签噪声的权重,从而有效避免了噪声对算法性能的影响。由实验结果可以看出,虽然随着信噪比的降低,DPC-RLFDA算法的分类精度略有下降,但与其他同类降维算法相比,其在不同信噪比下仍能取得令人满意的分类结果。综上所述,将基于DPC的伪标签生成技术正则化项引入LFDA,不仅可以提高低维特征的识别能力,还可以有效避免噪声对降维性能的影响。
5.5 不同降维维度及有标签样本个数下性能对比分析
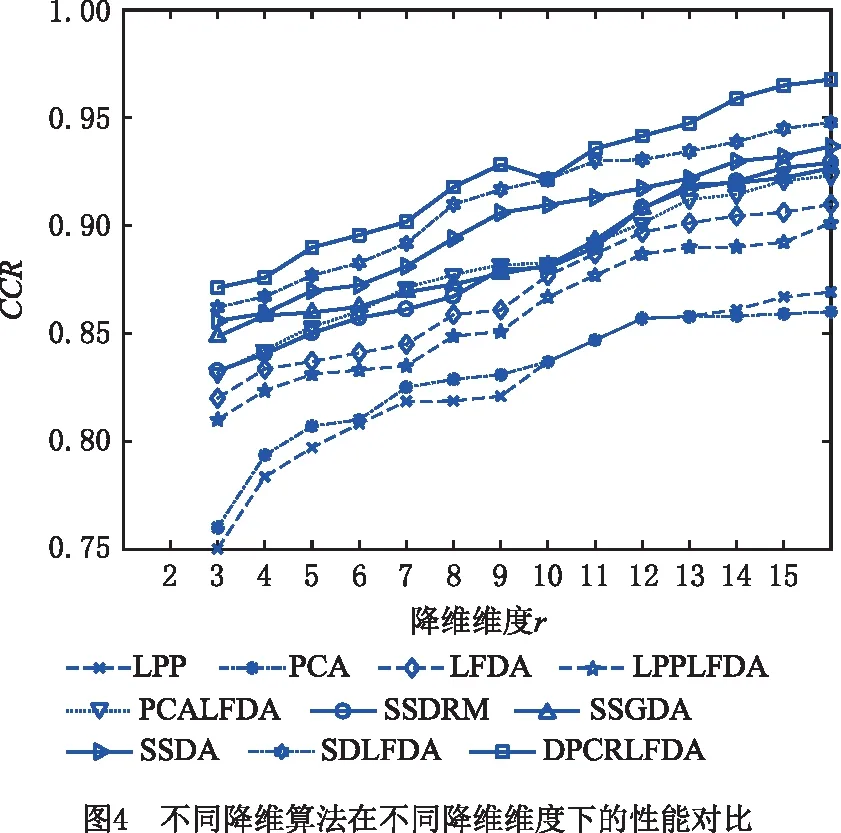
为了比较本文提出的DPC-RLFDA降维算法在不同降维维度下的分类性能,分析了不同降维维度r在2~25范围内的分类结果,其中数据集仍采用上述的多模态轴承故障诊断数据,每类含1 000个样本,其中500个为训练样本,剩余500个为测试样本。本实验同样采用最近邻分类器作为基分类器,评价指标为正确分类率(CCR),其他参数设置同上。
由于FDA算法降维维度需小于类别个数,本实验只选取LPP,PCA,LFDA,LPPLFDA,PCALFDA,SSDRM,SSGDA,SSDA,SDLFDA算法与本文算法进行对比。为消除随机影响,每个算法独立运行31次,实验参数设置同上,对于半监督算法,选取200个有标签样本,300个作为无标签样本,取平均分类正确率作为性能评价指标,其他实验结果如图4所示。实验结果表明,在不同降维维度下,本文提出的DPC-RLFDA降维算法的平均分类正确率明显优于其他算法。
同理,为研究本文DPC-RLFDA算法同其他半监督降维算法在不同数目有标签样本训练下的分类性能,实验通过从50到450等间隔改变有标签样本数目的方式进行训练学习,利用最近邻分类器实现分类,并以正确分类率(CCR)作为性能评价指标。考虑到FDA算法降维维度的限制,本次实验将降维维度r设置为7,其他参数设置同上。选取SSDRM,SSGDA,SSDA和SDLFDA4个半监督伪标签降维算法进行性能对比。得到的实验结果如图5所示。
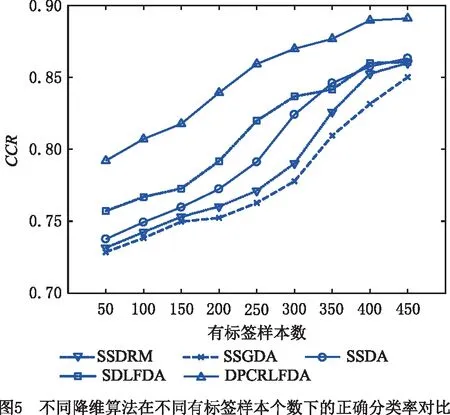
实验结果表明,同其他降维算法相比,本文算法在不同数目有标签训练样本下的分类性能都优于其他算法。此外,如图5所示,随着有标签样本数目的增加,所有半监督降维算法的分类性能都呈上升趋势,这主要是由于随着有标签样本数的增加,半监督降维算法中FDA部分的学习更加充分,得到的降维子空间泛化性能更强。此外,随着有标签样本数的增加,本文算法同半监督降维算法间分类性能的差异也随着无标签样本作用的降低而逐渐缩小。
5.6 不同参数对本文算法性能的影响
由于本文采用了密度峰值聚类算法构造伪标签,截断距离dc又是DPC的关键参数,本实验部分研究了截断距离dc参数对DPC-RLFDA算法性能的影响。根据DPC算法经验,dc通常被设置成使得每个数据点的平均近邻个数为数据点总数的1%~2%,因此假设这个比例为t,本文通过改变t从0.5%~10%的方式考察该参数对DPC-RLFDA算法降维性能的影响。实验数据同上,选取8个类别的样本数据,其中每个类别中500个样本作为训练样本,剩余500个样本作为测试样本。为了避免随机影响,每次实验随机选择200个样本作为有标签样本,余下的300个作为无标签样本,重复运行31次并计算平均分类正确率,其他参数设置如上。其中降维维度设置为r=7,分类器采用最近邻分类器进行分类,实验结果如图6所示。
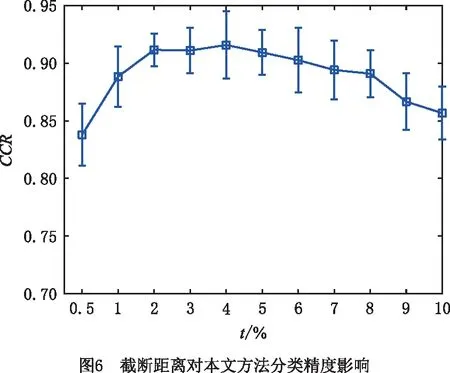
由图6可知,DPC-RLFDA算法的分类性能初期随着t值的增加呈上升趋势,而后趋于平稳,后期出现下降趋势。这是由于当t值设置过小时,每个样本在计算局部密度时参考的近邻样本点较少,容易出现大量局部最优解,极端情况,每个样本点都是一个聚类中心,丧失了聚类的意义,如t=0.5%,每个样本的参考近邻点个数平均为500×0.5%=2.5。相反,当t值设置过大时,每个样本在计算局部密度时参考的近邻样本点较多,极端情况,所有样本点都成为了每个样本点的参考近邻点,甚至出现只有一个聚类的情况。另外t的增大也会导致计算量增加。因此,通常需要将t设置为适中值,本文建议t=2%即可。
5.7 同其他分类算法结合后的性能分析
最后,为了验证提出的DPC-RLFDA算法与不同分类器相结合后的分类性能,将本文和其他算法同不同分类器结合后的性能进行对比分析,所使用的分类器有多层感知机(Multi-Layer Perceptron,MLP)神经网,径向基函数(Radial Basis Function,RBF)神经网,支持向量机(Support Vector Machine,SVM)和极限学习机(Extreme Learning Machines,ELM)等。支持向量机算法参数采用高斯核,惩罚因子和核宽度经5次交叉验证利用网格搜索方法从σ={0.1,0.5,0.7,1,1.2,1.5,2,2.5,3}和C={2-2,2-1,1,21,22,23,26,28,210}中选取C=4和σ=1.2,RBF神经网,多层感知机神经网和极限学习机的降维维度为7,隐层单元的个数为30,其他参数设置同上,每个算法独立运行31次,计算分类正确率平均值,实验结果如表4所示。结果表明,与其他降维方法的组合相比,DPC-RLFDA组合的分类器性能最优。这说明DPC-RLFDA算法能够有效利用未标记样本来保持原始数据集中的局部聚类信息,从而使降维后的特征在不同类别间更具有区分性,进而有利于提高后续分类器的分类性能,特别是在多模态数据集上。为测试本文DPC-RLFDA算法的抗噪性能,本文还对3个有噪声的多模态轴承故障数据集进行了对比实验。表5~表7结果表明,本文DPC-RLFDA算法通过引入基于DPC伪标签生成技术的正则化项,可以有效地缓解噪声的影响,进而具有较好的鲁棒性。
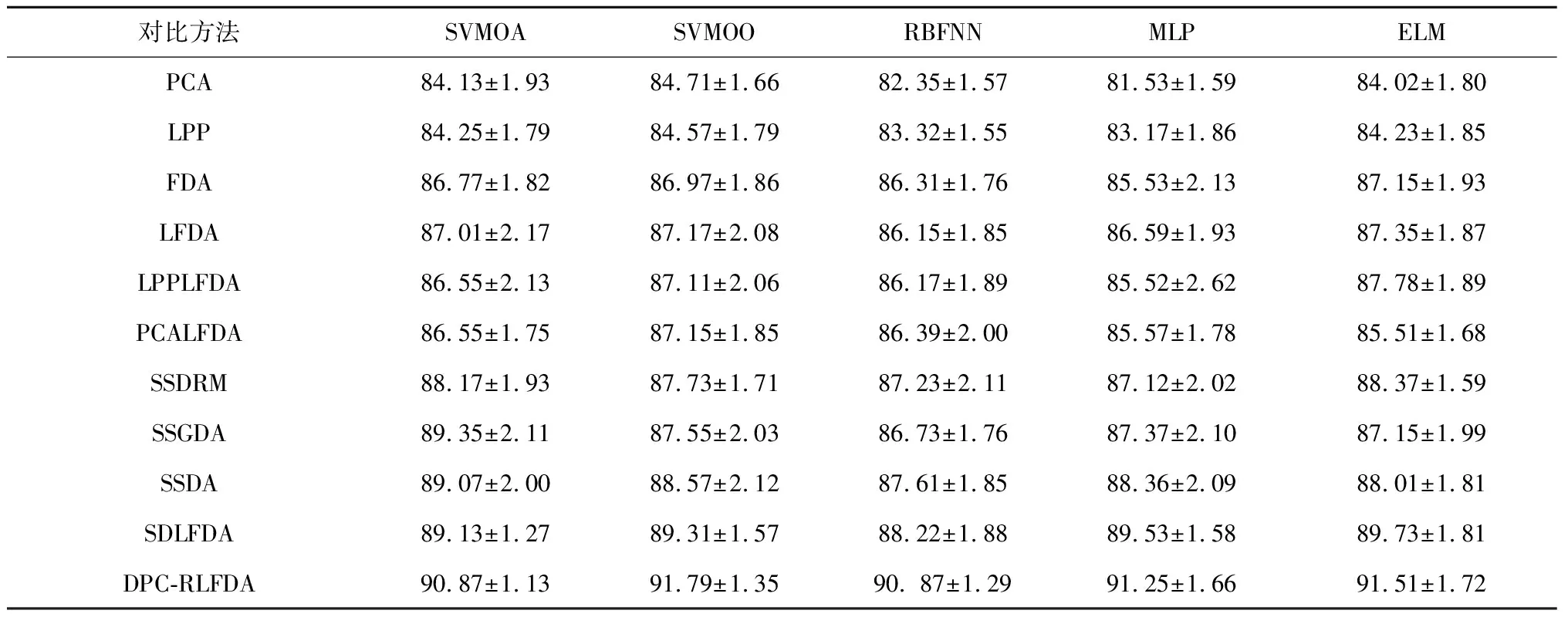
表4 不同分类和降维方法组合对多模态轴承故障数据集的分类正确率平均值
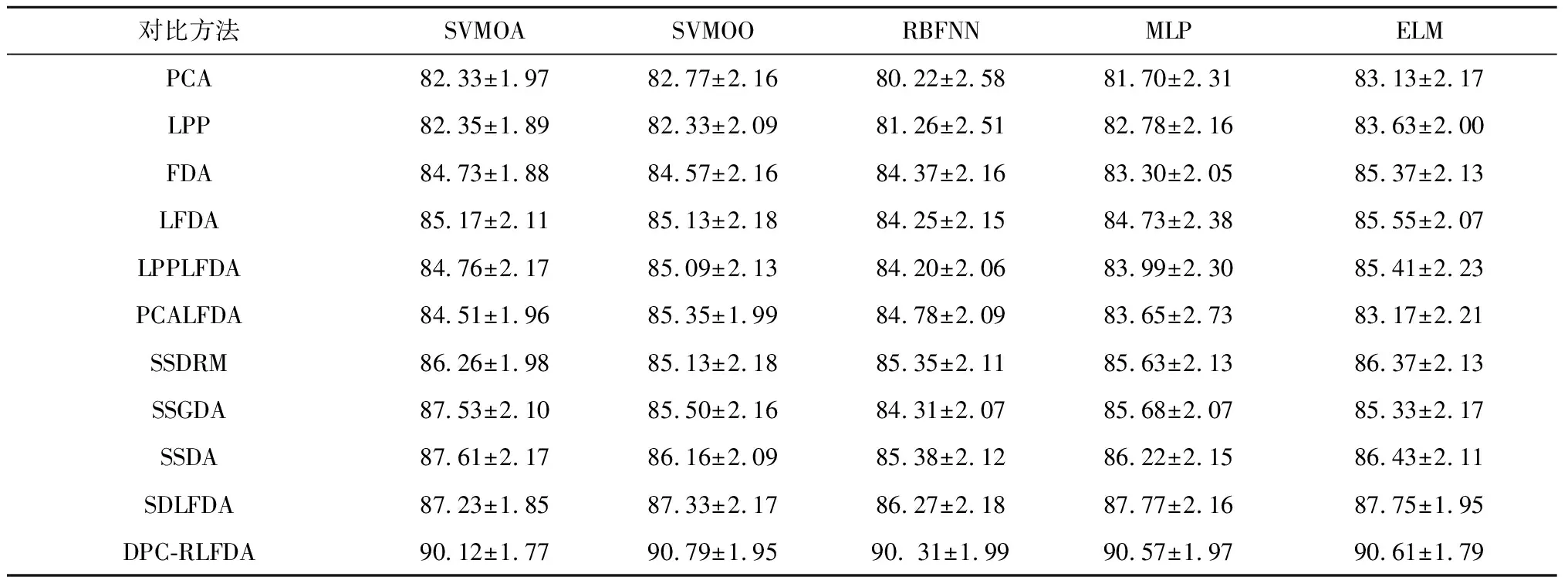
表5 不同分类和降维方法组合对多模态含噪声轴承故障数据集(DB0)的分类正确率平均值
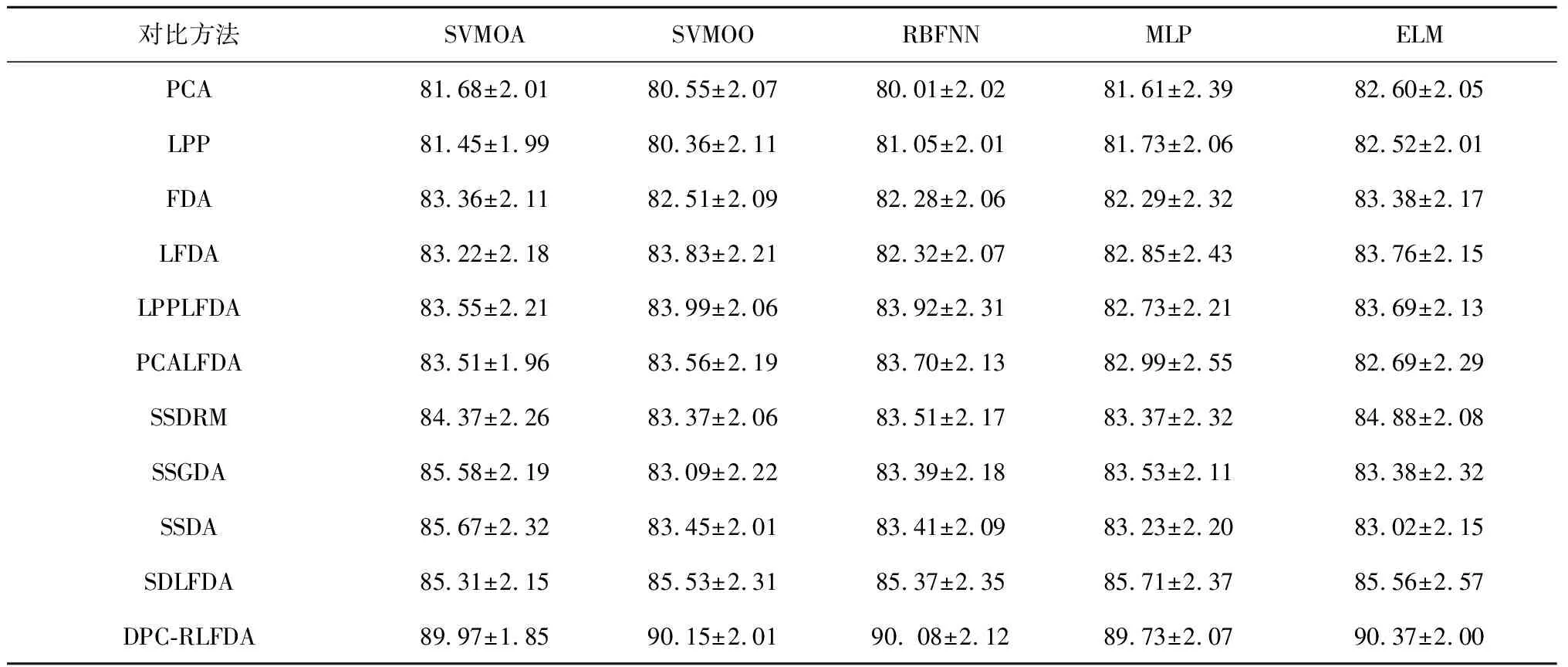
表6 不同分类和降维方法组合对多模态含噪声轴承故障数据集(DB5)的分类正确率平均值
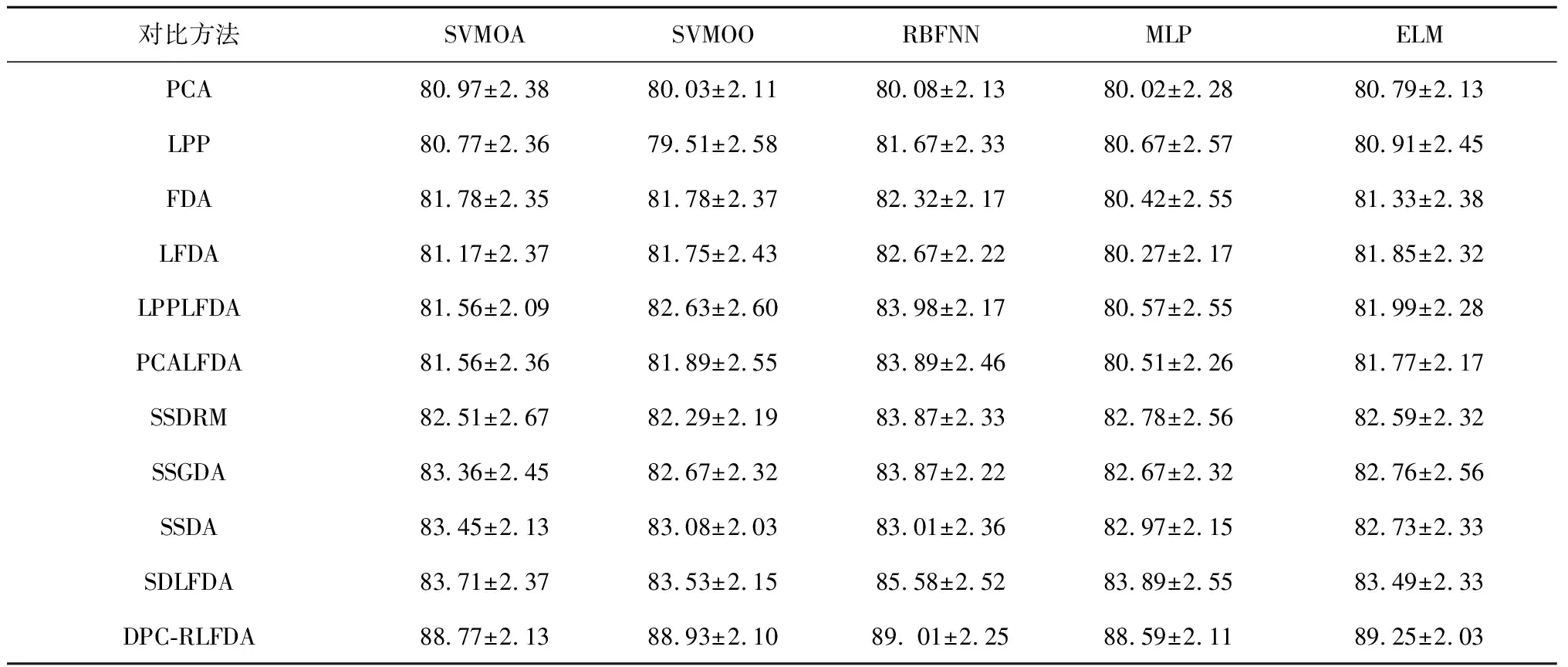
表7 不同分类和降维方法组合对多模态含噪声轴承故障数据集(DB2)的分类正确率平均值
6 结束语
本文提出一种基于密度峰值聚类的正则化LFDA算法,结合实验得到以下结论:
(1)本文采用半监督学习方式,在考虑结构一致性假设的前提下,通过密度峰值聚类算法合理利用无标签样本信息指导有监督FDA算法的学习,使得到的投影向量更加具有鉴别能力。此外,本文算法的核版本也适合处理非线性数据集降维。人工数据集以及UCI数据集的实验结果表明,本文算法得到的判决界面更符合数据的真实分布情况,进而提升了降维特征的判别性能。
(2)利用聚类伪标签构造两个正则化项用以规范局部Fisher判别分析的类间散度矩阵和类内散度矩阵;该正则化项不仅能有效提升降维特征的判别性能还能适用于处理多模态及含噪声的数据集。多模态含噪声的轴承故障诊断数据实验结果表明,与其他降维算法相比,本文算法因通过引入两个正则化项指导LFDA算法降维学习,使得降维后的特征区分性能更强,更有利于处理多模态及噪声数据集。
(3)本文算法与其他算法在不同降维维度,参数以及与不同分类器相结合后的性能对比实验结果表明,相比于其他算法,本文算法均获得了较高的判别性能及鲁棒性。
需要说明的是,本文提出的算法仍是基于聚类伪标签构造的正则化项实现半监督降维,其性能无法避免受聚类结果的影响,未来能否通过构造满足全局和局部分布特征的相似度矩阵直接规范类间和类内散度矩阵是课题组下一步研究的重点。
