基于BiLSTM模型的冶金领域国家标准指标识别研究
2023-12-03夏磊方思怡解凌蔡焱顾晓虹
夏磊 方思怡 解凌 蔡焱 顾晓虹
摘 要:冶金行业为集成电路、人工智能、航空航天等重要领域提供必不可少的金属原材料。冶金国家标准是重要的基础性战略资源,在冶金产业的高质量发展中发挥技术性支撑作用。国家标准文本中蕴含大量的关键技术性指标,人工逐一识别并抽取的模式在大数据时代已无法满足数字化转型的需求。本研究采用深度学习算法,对冶金领域的国家标准文本分别开展RNN、GRU和BiLSTM模型的对比实验,根据模型性能择优选取最优模型。研究结果显示BiLSTM模型在冶金领域国家标准指标识别的表现上最好,由此采用BiLSTM为该领域标准指标识别的深度学习模型。
关键词:冶金,国家标准,标准指标识别,深度学习,BiLSTM
DOI编码:10.3969/j.issn.1002-5944.2023.03.014
基金项目:本文受上海市市场监督管理局科技项目“标准指标智能抽取和比对技术在政府监管和‘企标领跑者制度实施中的研究与应用”(项目编号:2021-47)资助。
Research on the Identifi cation of National Standard Indicator in Metallurgical Field Based on BiLSTM Model
XIA Lei FANG Si-yi* XIE Ling CAI Yan GU Xiao-hong
(Shanghai Institute of Quality and Standardization)
Abstract: Metallurgy plays a fundamental role in providing indispensable metal raw materials for important industries such as integrated circuit, artificial intelligence and aerospace. Metallurgical national standards are basic strategic resources of great importance, supporting the high-quality development of metallurgy. The contents of national standards contain a large number of critical technical indicators. Manually identifying and extracting indicators fail to meet the requirement of digital transformation after the advent of the Big Data Era. The deep learning models are used to conduct 3 experiments based on RNN, GRU, and BiLSTM model on metallurgical national standards to fi nd an optimal solution. The results suggested that BiLSTM model performed best in the identification of indicators in metallurgical national standards, thus making BiLSTM the solution to the identifi cation of standard indicator in this fi eld.
Keywords: metallurgy, national standard, identifi cation of national standard indicator, deep learning, BiLSTM
1 引 言
作為现代材料体系的重要组成,金属是国民经济、社会生活和科技发展中必不可少的基础材料和战略物资[1]。以铅金属和稀有金属为代表的有色金属是大量尖端武器和信息技术产品构件的重要原材料。随着集成电路、人工智能等高新技术产业的快速发展,各国逐渐开始对其金属原材料开展战略储备。长久以来,标准是产业发展的重要技术支撑,标准数据是重要的基础性战略资源。冶金领域的标准文本蕴含大量的技术性指标,挖掘并比对标准指标将对冶金行业的标准化发展提供一定的依据。
在大数据时代,人工抽取标准指标的模式已日益无法满足产业数字化转型的需求。近年来,基于文本挖掘技术的方法在标准指标识别领域开始兴起。标准指标识别在本质上属于文本挖掘领域中的实体命名识别(Named entity recognition, NER)任务,国家标准指标识别为中文实体命名识别(Chinese named entity recognition, CNER)在标准领域的应用。中文文本为序列数据,已有的实证研究表明循环神经网络模型(Recurrent neural network, RNN)及其相关变式在序列数据的NER问题上有杰出表现,这些变式包括长短期记忆网络(Long- and short-term memory, LSTM)、门控循环单元网络(Gated recurrent unit,GRU)等,其中双向长短时记忆模型(Bidirectional LSTM, BiLSTM)在医疗、金融、科技文献等多种中文文本中均效果良好[2- 5]。
为了探寻冶金领域国家标准指标识别的最佳模型,本研究采用基于RNN及其重要变种的深度学习模型,通过运行RNN、GRU和BiLSTM这3组模型的训练实验,比较不同深度学习模型的性能优劣,最终确定了适用于冶金领域国家标准指标识别的深度学习模型,提出了解决冶金领域国家标准指标识别的智能化方案,为冶金领域国家标准的数字化转型和标准化战略制定提供一定的参考依据。
2 方 法
2.1 实验环境
2.1.1 硬件环境参数
本研究的实验硬件环境为Intel(R) Xeon(R) Gold 6226R CPU 2.90GHz和2.89 GHz处理器,机带RAM为128 GB,操作系统为Windows 10的64 Bit,采用的GPU型号为RTX 3090-24G。
2.1.2 软件环境参数
本研究的实验平台为Anaconda 3,Python版本为3.8.8,采用的深度学习框架为Keras 2.7.0。该深度学习框架运行于TensorFlow 2.7.0上,以基于Python的TensorFlow为后端。
2.2 数据处理
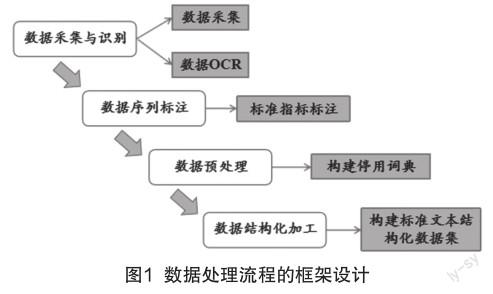
本研究的数据处理流程包含数据采集与识别、数据序列标注、数据预处理和数据结构化加工4个步骤。数据处理流程的框架图如图1所示。
2.2.1 数据采集与识别
所有标准文本数据均来自于上海市质量和标准化研究院标准文献馆有版权保护的馆藏纸质资源,经人机协作的OCR处理后将纸质文本统一转化为doc格式的电子文本65篇,约56万余字符,形成冶金领域国家标准文本数据集。
2.2.2 数据序列标注
本研究邀请具有标准化经验的冶金行业专家对冶金领域国家标准中的产品类标准开展标准指标的数据标注,在结合冶金领域国家标准指标实体特性的基础上经专家协商制定标注方案,从而完成标准文本数据的序列标注工作。
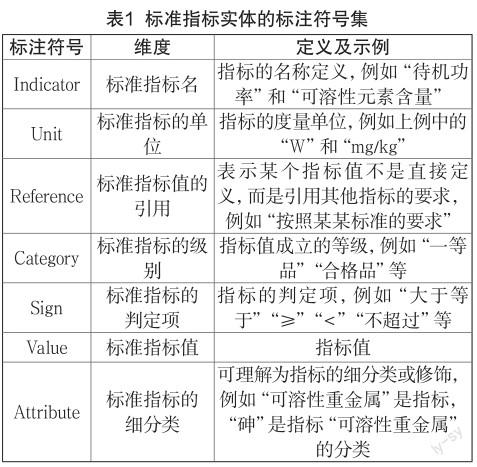
本研究的标准指标标注方案包括标准指标标注符号集和标准指标标注规则。标注符号集是指对文本数据进行标注时采用的符号或者字符集合。不同的标注任务往往对应不同的标注符号集。本研究从标准指标的内容和类型分布入手制定标准指标的标注符号集,如表1所示。
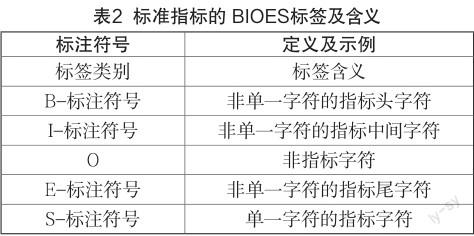
标注规则是指在进行数据标注时所遵循的一系列一般原则或具体要求。它决定了标注数据集的构成形式,进而决定了机器学习和深度学习模型的数据输入。已有的研究指出,不同的标注规则或导致不同的模型性能[6]。因此,择取适用的标准指标的标注规则对构建有效的标准指标标注模型而言具有重要的意义。目前命名实体识别领域的常见标注规则包括BIO模式、BIOES模式以及其它自定义标注模式。与BIO模式相比,BIOES模型对于命名实体的边界信息分辨得更为清晰。本研究采用基于BIOES模式的标注规则,具体说明如表2所示。
2.2.3 数据预处理
在数据预处理阶段,主要是结合通用停用词库和冶金领域国家标准文本的文本编写情况构建适用于冶金领域国家标准的停用词库,在去除停用词和无意义符号后约45万余字符。
2.2.4 数据结构化加工
本研究以字符为数据颗粒度单位对冶金领域的国家标准文本进行文本切分,对数据进行结构化的加工,构建冶金领域的国家标准文本结构化数据集。
2.3 模型设计
本研究的标准指标识别模型框架包括输入层、中间层、输出层等若干部分。模型总体架构设计如图2所示。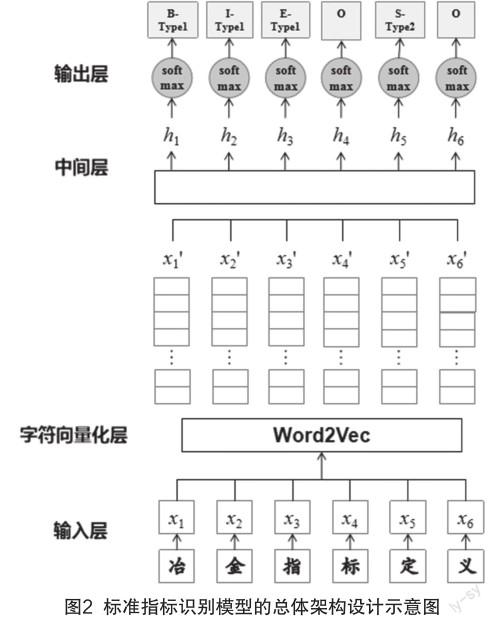
本研究的标准指标识别模型采用Word2vec对输入层的文本数据进行索引化处理。Word2vec是一种较为成熟的预训练嵌入(Embedding)模型,在各个领域得到广泛应用。与稀疏、高维、硬编码型的独热向量(One-hot encoding)相比,在较大语料库上预训练习得的嵌入模型更为低维、密集,且能表征向量间的有效联系[7],将此类预训练模型加载到数据量较大的任务中能起到数据降维的作用[8]。Word2vec有2种预训练嵌入的方法:根据目标值预测上下文的Skip-gram方法和根据上下文预测目标值的连续词袋(Continuous bag-of-words, CBOW)。已有的实证研究发现,前者适用于小型语料库和罕见语料数据,后者在大量的常用语料数据上精确性更高,训练速度也更快[9]。考虑到模型的运行效率和样本数量,本研究以字符为单位,采用基于CBOW方法的Word2vec模型原理将冶金领域的国家标准结构化数据转化为静态字符向量。该方法的示意图如图3所示。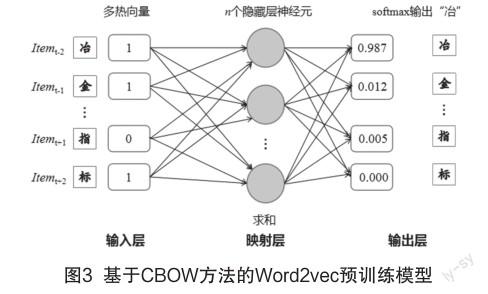
循環神经网络是序列加工问题中最为基本的深度学习模型,在语音识别、文本挖掘、股票预测等方面有了广泛的应用。截止目前已衍生出长短期记忆网络、门控循环单元网络、双向循环神经网络(Bidirectional RNN, BiRNN)、双向长短期记忆网络等多个重要变种[10],其中BiLSTM因效果较好受到大量认可。由于标准指标识别本质也是标准文本挖掘领域中的命名实体识别任务,故本研究以循环神经网络及其改进算法为核心构建适用于冶金领域国家标准指标识别的深度学习模型。
为了比较不同模型性能的优劣,也为了验证BILSTM模型是否为冶金领域国家标准指标识别的最优解,本研究根据中间层的不同设计了3种实验,分别对应下列3种模型设计:
2.3.1 实验1:基于RNN模型的标准指标识别
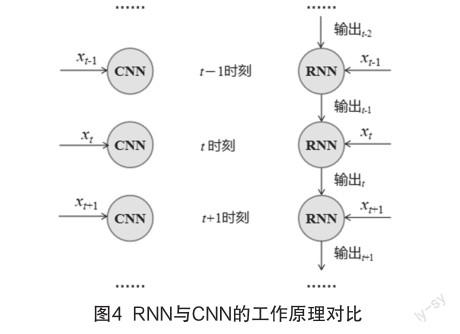
普通神经网络的计算结果仅与本周期的输入和网络权重有关。与普通神经网络相比,RNN的计算结果同时取决于指定的输入和上一周期的输出,这一功能为神经网络增加了记忆空间,能更好地预测随时间而变化的序列数据。RNN的工作原理如图4所示。
2.3.2 實验2:基于GRU模型的标准指标识别
已有的研究指出,RNN在数据的序列长度较短时预测效果较佳。为了解决RNN在长距离依赖上的问题,LSTM应运而生。它通过引入遗忘门、输入门和输出门对序列信息进行有效过滤,从而改进RNN的不足,也因此导致了网络计算复杂度过高的现象。GRU便是为了解决LSTM计算成本而诞生的LSTM优化变种。该算法包括更新门和重置门2种门控单元,用更新门结构替代了LSTM中原有的遗忘门和输入门,在确保模型运行效果的前提下简化了模型中的门结构,从而大幅提高了神经网络的训练速度[11]。
2.3.3 实验3:基于BiLSTM模型的标准指标识别
RNN及其变式LSTM和GRU的工作原理核心均为通过单向的数据流来处理序列信息,也即只能依赖出现在当前阶段之前的上文信息,存在下文信息依赖缺失的情况。双向循环神经网络模型通常由2组独立的循环神经网络模型构成,两者分别对应上文依赖的正序序列信息和下文依赖的逆序序列信息,通过同时训练这2组模型并进行特征合并,实现了对上下文信息的学习。在一系列的双向循环神经网络模型中,以BiLSTM的应用最为广泛。BiLSTM由前向LSTML和后向LSTMR构成[12],能有效解决LSTM的上下文信息问题[13],提供全面的文本语义信息,减少上下文语序问题所导致的判断错误[14]。
2.4 模型训练流程与参数设置
2.4.1 模型训练流程
本研究中的3种实验设计均采用8:2的比例将标准文本结构化数据集划分为训练集和测试集。模型训练流程如图5所示。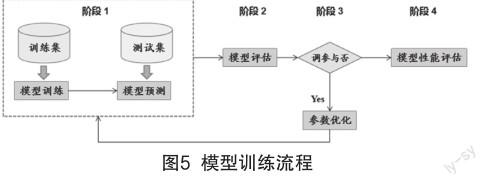
2.4.2 实验重要参数设置
本研究的重要实验参数皆经过参数调优,具体情况如表3所示。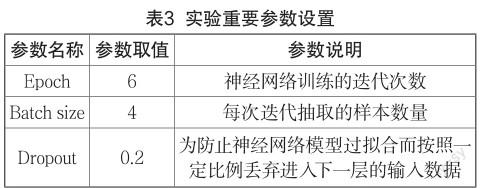
2.5 模型性能评价指标
模型的评估对建立高效模型而言至关重要。对于分类任务,标签(Label)通常为离散型数值,多采用混淆矩阵(Confusion matrix)来评估模型性能[15]。本研究采用由混淆矩阵计算而得的准确率(Accuracy, Acc)、精确率(Precision, P)、召回率(Recall, R)和F1值(F1 score, F1)。混淆矩阵的示意图如图6所示。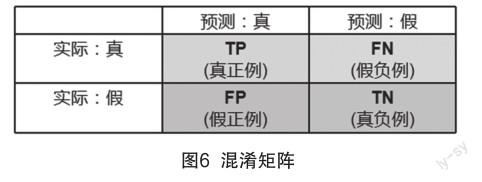
准确率、精确率和召回率由混淆矩阵中的变量直接计算而得,F1分数则是根据精确率和召回率计算而得。上述四者的具体定义和计算公式如式(1)至(4)所示。式(1)至(3)中的P表示正向的预测方向,N表示负向的预测方向,T表示预测正确,F表示预测错误。TP表示正确识别的标准指标的实体数量,TN表示正确识别的非标准指标的实体数量,FP表示将非标准指标错误识别为标准指标的实体数量,FN表示将标准指标错误识别为非标准指标的实体数量。
2.5.1 准确率
3 结果与分析
3个实验的模型性能评价指标对比结果如表4所示。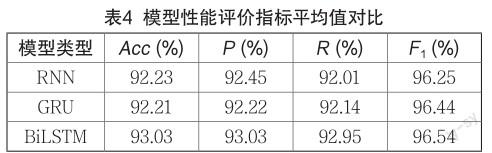
由表4可知,BiLSTM模型的准确率、精确率、召回率和F1分数均高于RNN和GRU模型,这表明与另外2种模型相比,BiLSTM模型在冶金领域国家标准的指标识别上有着更好的表现。GRU模型作为LSTM模型的效率优化变种,在召回率和F1分数上更优于传统的RNN模型。
为了进一步考察不同模型的实际训练情况,将3种模型在迭代训练过程中的综合度量指标F1分数的变化趋势绘制成折线图,如图7所示。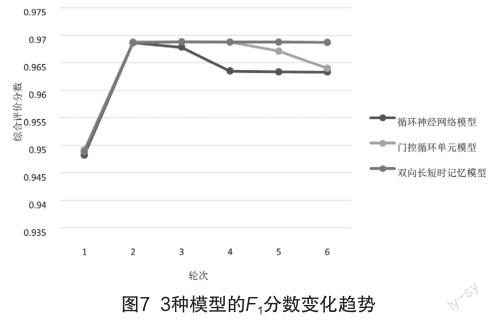
图7显示了3种模型的F1分数在迭代训练中的变化情况。在第1个Epoch至第2个Epoch阶段,3种模型的F1分数均处于上升趋势,均在第2个Epoch处趋于最优;随后BiLSTM模型的F1分数始终保持高度稳定,RNN模型的F1分数在第2个Epoch至第4个Epoch的阶段呈现下降趋势,在第4个Epoch后保持稳定;而GRU模型的F1分数则在第2个Epoch至第6个Epoch阶段处于先稳定后下降的趋势,在第4个Epoch后开始缓慢下降。由此可知,在整个训练过程中,BiLSTM模型的标准指标识别效果最为稳定,处于领先优势,其整体表现明显优于另外2种模型。
4 结 语
本研究采用深度学习模型对冶金领域国家标准开展产品类指标识别研究,通过运行3组深度学习模型的实验,全面深入地比较了RNN、GRU和BiLSTM模型的性能表现,最终发现BiLSTM模型在稳定性和准确性上有一定的优势,由此采用BILSTM作为冶金领域国家标准指标识别的深度学习模型,在一定程度上解决了冶金领域国家标准指标智能识别的问题。在未来将继续对标准指标识别模型进行进一步优化和推广,为我国其它前沿和重点领域的产业发展提供标准技术的支撑力量,为质量和标准化新型专业智库的建设提供数据基础。
参考文献
[1]杨洋.山西省金属学会:推动冶金行业高质量发展[J].科学之友,2022(9):30-33.
[2]LI D, YAN L, Yang J, et al. Dependency syntax guided BERTBiLSTM-GAM-CRF for Chinese NER[J].Expert Systems with Applications, 2022(196):116682.
[3]AN Y, XIA X, CHEN X. Chinese clinical named entity recognition via multi-head self-attention based BiLSTM-CRF[J]. Artificial Intelligence In Medicine, 2022(127):102282.
[4]HOU L, ZHANG J, YU T, et al. Method and dataset entity mining in scientific literature: A CNN +BiLSTM model with selfattention[J]. Knowledge-Based Systems, 2022(235):107621.
[5]陳启,刘德喜,万常选,等.增强语义表示的中文金融评价要素抽取[J].小型微型计算机系统,2022,43(2):254-262.
[6]程名,于红,冯艳红,等.融合注意力机制和BiLSTM+CRF的渔业标准命名实体识别[J].大连海洋大学学报,2020,35(2):296-301.
[7]鲁睿元,祝继华. Keras深度学习[M].北京:中国水利水电出版社,2019.
[8]吴茂贵,王红星.深入浅出Embedding:原理解析与应用实践[M]. 北京:机械工业出版社, 2021.
[9]LANE H & HOWARD C. Natural language processing in action[M]. Greenwich:Manning Publications Cp, 2019.
[10]杜康吉. 改进的循环神经网络方法及其应用研究[D].吉林市:东北电力大学,2021.
[11]朱凌建,陈剑虹,王裕鑫,等.基于GRU神经网络的脉搏波波形预测方法研究[J].电子测量与仪器学报,2022,36(5):242-248.
[12]张顺香,张镇江,朱广丽,等.基于Bi-LSTM与双路CNN的金融领域文本因果关系识别[J].数据分析与知识发现,2022,6(7):118-127.
[13]秦精俏,王彤,王玉珍.基于Word2vec_BiLSTM的用餐评论情感分析[J].枣庄学院学报,2022,39(2):37-44.
[14]胡任远,刘建华,王璇,等.引入双循环机制深度学习模型的文本情感分析[J].福建工程学院学报,2022,20(4):383-390.
[15]SAL EH H. Machine learning fundamentals[M]. Birmingham:Packet Publishing, 2018.
[16]马小蕾. 基于语义增强的生物医学文本信息抽取方法研究[D].长春:吉林大学,2022.
[17]张开放,苏华友,窦勇.一种基于混淆矩阵的多分类任务准确率评估新方法[J].计算机工程与科学,2021,43(11):1910-1919.
作者简介
夏磊,硕士研究生,工程师,研究方向为标准信息管理。
方思怡,通信作者,硕士研究生,助理工程师,研究方向为标准文献挖掘、产业标准化。
解凌,本科,高级工程师,研究方向为信息系统建设。
蔡焱,本科,工程师,研究方向为标准化和标准信息管理。
顾晓虹,本科,高级工程师,研究方向为标准文献服务。
(责任编辑:张佩玉)
