基于深度学习的招聘信息文本分类研究
2023-11-29任济洲
任济洲
(澳大利亚国立大学 计算机与控制学院,堪培拉 ACT2601)
文本分类是计算机处理自然语言的一项基本任务,广泛应用于垃圾邮件过滤、舆情分析、情感分析和新闻分类等领域[1]。在海量信息的当下,如何有效地分类和解析企业招聘信息文本,提高招聘效率和实现求职者与职位的精准匹配具有重要的现实意义。
传统文本分类方法依赖于人工提取的特征和基于统计的模型。人工提取的特征通常包含词性和词频,朴素贝叶斯和最大熵模型是常用的统计学模型。例如,徐军等[2]使用朴素贝叶斯和最大熵模型进行情感分类,但这种模型在大数据场景下效果有限。随着深度学习的发展和计算能力的提升,新的算法和模型不断出现。徐逸等[3]将分层式卷积神经网络与注意力机制相结合,解决了长文本的语义分布问题。Zhang Y等[4]通过多通道卷积神经网络和过采样技术,解决了样本不平衡问题。王勇等[5]将层次Softmax与CNN结合,显著加速了模型训练。Liu P等[6]应用RNN于多任务学习,提高了分类性能。梁志剑等[7]将BiGRU与朴素贝叶斯结合,解决了GRU的长依赖和梯度消失问题。王伟等[8]提出了融合注意力机制和BiGRU模型,高效地完成了情感分类。
词嵌入技术作为自然语言处理的核心,近些年来取得了新的突破。Bengio Y等[9]使用神经网络解决了传统语言模型数据的稀疏性和上下文忽略的局限性。Mikolo T等[10]提出Word2Vec,通过简化模型和优化算法,显著改进了词的嵌入表示。Pennington J等[11]推出GloVe模型,更全面捕获词的共现信息。Busta M等[12]利用FastText模型解决词形变化和未登录词的问题。Devlin J等[13]发布了适用于多种下游任务的BERT模型,为NLP任务提供预训练词向量。
尽管现有研究已经推出了多种文本分类模型,但这些模型多数采用单一的网络架构,且未考虑不同词嵌入技术对分类性能的影响,这限制了模型在不同场景下的泛化能力和灵活性。本文旨在研究不同的词嵌入技术和网络结构在招聘信息文本分类任务上的性能表现,包括Word2Vec-CNN,Word2Vec-LSTM,Bert-CNN和Bert-LSTM。在此基础上,构造了Bert-CBM混合模型。其融合了CNN,BiLSTM以及多层感知机(Multilayer Perceptron,MLP)的优势。实验结果表明,该混合模型在当前任务中展现出了较优性能。
1 相关技术
1.1 基于Word2vec的文本表示
Word2Vec是Google开发的一种分布式词向量训练工具,包含了Skip-gram和CBOW模型。本文采用Skip-gram模型训练的词向量,模型结构如图1所示。
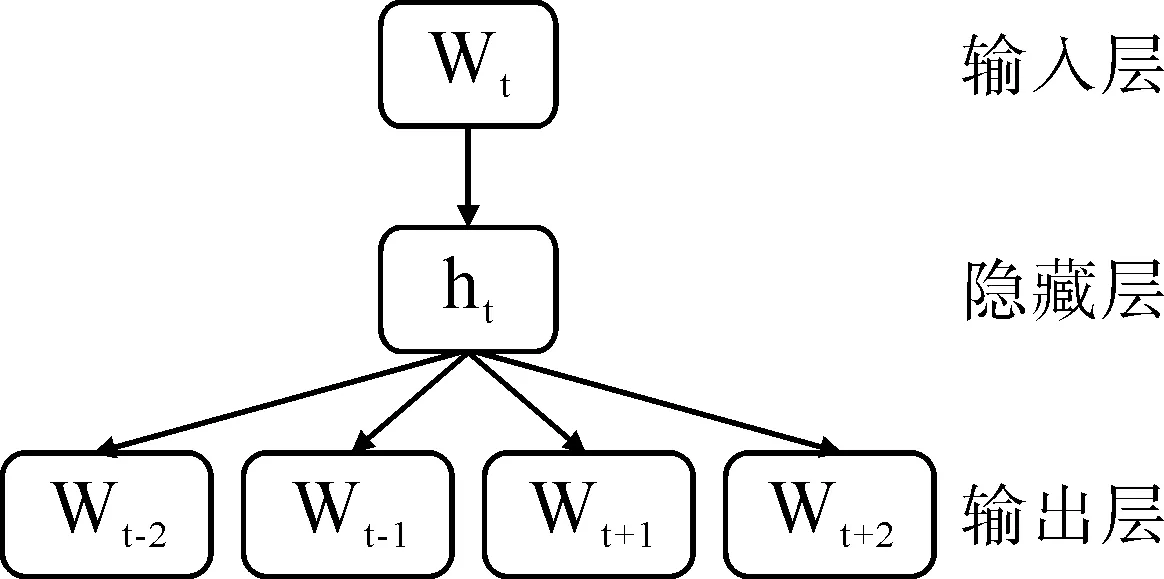
图1 Skip-gram模型结构示意
该模型由输入层、隐藏层和输出层组成,层与层之间是全连接方式。在训练时,输入字Wt,预测上下文单词。对于长度为T的文本,上下文窗口大小为m,该模型的最大似然函数M和损失函数L如式(1)和式(2):
(1)
(2)
其中,t表示第t个词,Wt和Wt+j分别表示中心词和中心词的上下文词汇;P(Wt+j|Wt) 表示给定中心词Wt时,上下文位置为t+j的词Wt+j出现的概率。
1.2 基于BERT的文本表示
BERT是一种融合Transformer中的编码器和嵌入层的双向语言模型。编码器主要由多头注意力和前馈神经网络构成,嵌入层包含位置编码。BERT模型结构如图2所示。
1.2.1 嵌入层BERT的嵌入层由词嵌入、片段嵌入和位置嵌入构成,结构如图3所示。
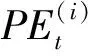
(3)
1.2.2 多头自注意力机制多头自注意力机制对原始输入通过多组自注意力进行处理,核心在于通过计算,查询向量Q、键向量K和值向量V来计算最后的输出O。自注意力计算过程参见图4。
假设原始输入为矩阵X,则自注意力的计算如式(4):
(4)
BERT使用多头注意力机制解决了自注意力机制对文本句子某一方面的过度关注问题。多头注意力机制结构如图5所示。
假设多头注意力有h个头。首先将查询、键和值向量通过线性变换分为h个部分;然后在每个头内分别计算注意力分数;最后将各头的结果拼接并输入到线性层。计算过程如式(5)和式(6):
(5)
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(6)
1.3 基于卷积神经网络的文本分类模型
CNN可以通过不同大小的卷积核来自动提取n元语法,捕捉句子的长期依赖和语义关系,还通过池化层降维,以缓解”维度灾难”问题。以CNN为基础的文本分类模型如图6所示。词嵌入层将使用Word2Vec和BERT。
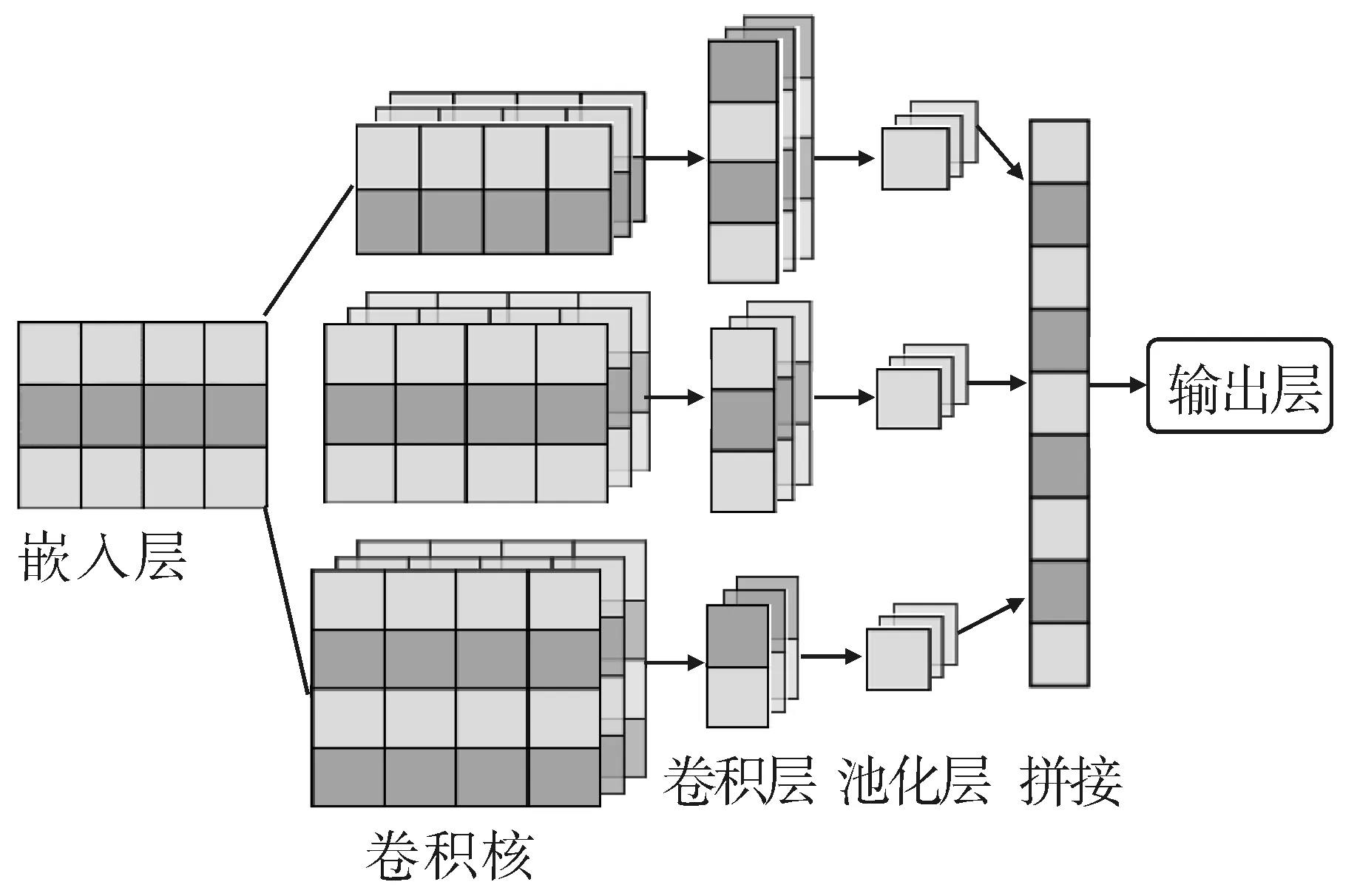
图6 TextCNN模型架构示意
在TextCNN中,使用大小不同的矩形卷积核处理模型输入。卷积核宽与词嵌入矩阵宽度相同,高度是超参数。卷积核仅在垂直方向滑动,以确保每次移动都能覆盖完整的词。假设词嵌入矩阵为X∈(n,d), 其中n是词汇量,d是词嵌入维度;卷积核为W∈(k,d),其中k表示卷积核高度。则卷积后的特征图Y可由式(7)计算。
Y[i]=f(W·X[i:i+k,:]+b)
(7)
其中f表示激活函数,Y[i]表示输出矩阵的第i个元素,b是偏置项。
下一步将特征图输入到池化层中进行降维,得到特征向量P;最后把P输入到输出层。输出层由全连接和Softmax函数组成。具体计算如式(8-10):
P(Y[i])=maxjYj[i]
(8)
L=WL·P+bL
(9)
(10)
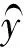
1.4 基于长短期记忆单元的文本分类模型
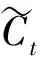
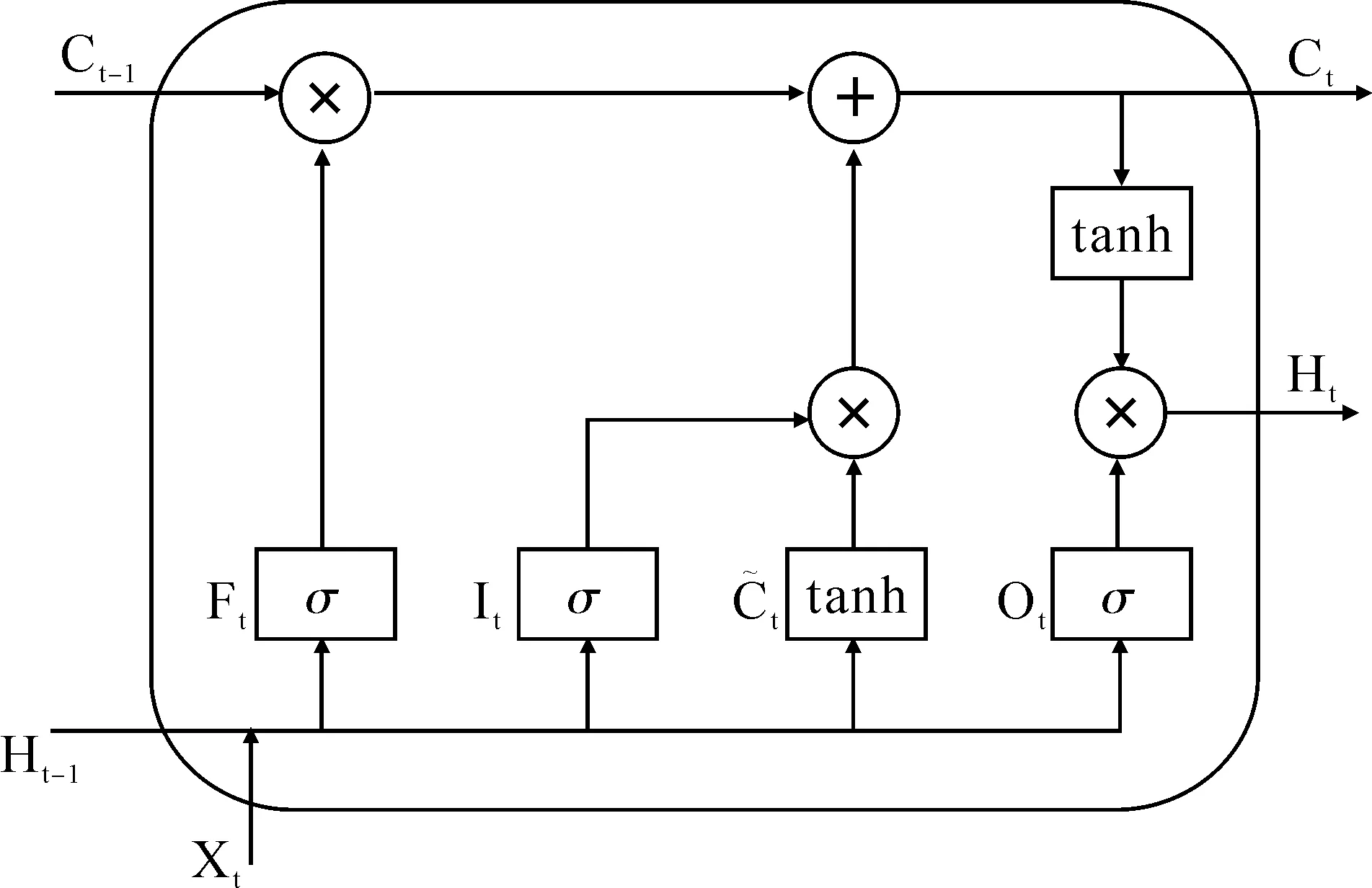
图7 LSTM单元示意
It=σ(Wi·[Ht-1,Xt]+bi)
(11)
Ft=σ(Wf·[Ht-1,Xt]+bf)
(12)
Ot=σ(Wo·[Ht-1,Xt]+bo)
(13)
(14)
(15)
Ht=Ottanh(Ct)
(16)
式(11-16)中Xt是当前时刻输入,Ht-1是上一时刻隐藏层状态,表示逐元素乘积,σ和tanh分别表示sigmoid和tanh激活函数,W和b是可学习权重和偏置参数。
1.4.2 基于LSTM的文本分类模型为了解决LSTM只能捕获文本自前向后信息的局限性,本文通过BiLSTM构建TextLSTM模型。结构如图8所示。
1.5 基于CNN和LSTM的混合文本分类模型
基于上述模型,本文构建了一个融合CNN,BiLSTM和MLP的混合模型BERT-CBM,其架构如图9所示。该模型的卷积块由三个高度不同的卷积核和最大池化层堆叠而成,以此捕获不同长度的短语和词组的信息。BiLSTM用于提取文本的全局特征。随后,将两组特征拼接,形成一个融合的特征向量。最后,把融合特征向量输入到MLP。该MLP包含两个全连接层和ReLU激活函数,可以增加模型的非线性表达能力。
2 实验与分析
2.1 实验环境和数据集
本实验主要运行环境:CPU为12th Gen Intel(R) Core(TM) i9-12900H 2.50 GHz,GPU为NVIDIA GeForce RTX 3070Ti,内存为32GB,操作系统为Windows11,深度学习框架为Pytorch2.0,编程语言为Python3.8。
本数据来自BOSS直聘网和猎聘网,共19 649条,覆盖了10个不同的类别。具体类别和对应的样本数量如表1所示。数据集按3∶1∶1的比例划分为训练集11 789条,验证集3 930条和测试集3 930条。数据集字段包含岗位类别,岗位要求和岗位地址。岗位类别是模型训练的标签;岗位要求是模型训练的主要输入,包含岗位职责、要求和任职资格等信息;岗位地址提供了招聘信息链接。部分数据集样本如图10所示。
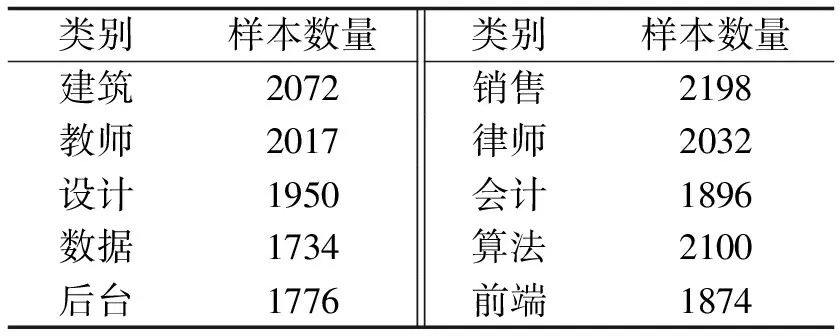
表1 数据集不同类别及其对应样本数量

图10 部分数据集样本截图
2.2 模型参数设置
本文采用的Word2Vec的词向量维度为d=300。BERT采用hugging-face预训练的BERT-base-chinese。BERT、TextCNN和TextLSTM模型参数如表2所示。BERT-CBM模型参数和训练参数如表3所示。

表2 BERT、TextCNN和TextLSTM模型参数

表3 BERT-CBM模型和训练参数
在模型训练过程中,本文选用交叉熵作为损失函数,并采用自适应矩估计法 Adam(Adaptive Moment Estimation)作为优化算法。 Adam是深度学习中最常用的优化算法之一,结合了Momentum和RMSprop的优点,可以自适应地调整参数的学习率,克服梯度下降中的局部最小值和鞍点。
交叉熵是一种用于评估模型预测值与真实值之间差异的损失函数,设为Z。对于多分类问题,交叉熵损失定义如式(17):
(17)
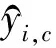
2.3 评价指标
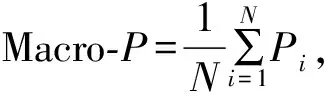
2.4 实验结果
为了对比上述模型基于该数据集的表现,进一步引入了RNN和GRU。同时,添加了传统机器学习算法以验证深度学习模型在该任务上是否具有优势。机器学习模型包括朴素贝叶斯NB(Naive Bayes)、k-近邻算法KNN(k-Nearest Neighbors)和决策树DT(Decision Tree)。实验结果如表4所示。

表4 文本分类模型宏平均指标对比
以下对结果进行分析与总结。
1)在传统机器学习模型中,朴素贝叶斯在该任务上性能较好,但与深度学习模型相比性能较弱。这主要是因为机器学习模型采用TF-IDF特征,而TF-IDF假设词语之间是相互独立的,忽略了词语的上下文关系。
2)在深度学习模型中,BERT-CBM的性能有提升,其准确率、召回率和F1值均超过92%。这主要得益于该模型混合了多层次的特征提取机制。模型中的卷积块有效地识别了句子的局部特征,LSTM层捕捉了句子长距离的语义依赖关系。最后,通过MLP层进行非线性映射,进一步地提炼特征。
3)在所述模型中,基于BERT的模型在所有指标上都明显优于基于Word2Vec和传统机器学习的模型。首先,是因为BERT在预训练时使用了Masked Language Model和Next Sentence Prediction,能够生成丰富的上下文相关词嵌入;其次,基于Transformer的架构使BERT更擅长理解复杂句子结构和长距离的语义依赖。
3 结束语
本文旨在研究招聘信息的自动化分类,通过对比Word2Vec与BERT两种词嵌入技术并探讨它们与不同深度学习模型(如TextCNN,TextLSTM)结合使用的效果,以分析它们的性能差异。实验结果显示,在数据集较大的情况下,深度学习模型展示出更出色的分类性能,特别是BERT-CBM模型在该分类任务表现较优。因此,深度学习模型在招聘信息文本分类任务上能够实现自动化和高精度分类。
不过,在广泛运用模型之前,需要解决若干潜在的局限性。首先,模型的性能和泛化能力高度依赖于数据集的规模,增大样本容量有助于提高模型的可靠性。其次,训练混合模型需要大量的计算资源,未来研究可专注于模型优化。最后,针对模型内部工作机制的不透明性,未来研究应考虑引入深度学习的可解释性技术。在解决上述问题后,BERT-CBM模型有望更好地应用于个性化职业推荐和人力资源管理。其高精度的分类能力可以用于职位匹配和自动筛选简历,从而提高招聘效率。
