生成式人工智能技术原理及其教育适用性考证
2023-11-28苗逢春
苗逢春
生成式人工智能技术原理及其教育适用性考证
苗逢春1,2
(1.北京师范大学 互联网教育智能技术及应用国家工程实验室,北京 1000875;2.联合国教科文组织总部 教育信息化与人工智能教育部门,法国巴黎 75007)
作为对联合国教科文组织发布的《生成式人工智能教育与研究应用指南》进行系列解读的第一篇,文章着重对生成式人工智能技术原理进行追本溯源的辨析并考证其教育适用性。生成式人工智能是可跨人类思维表征符号加工和生成新内容的人工智能技术,但其并不理解语义和真实世界的技术局限会限制其变革教育的潜力。垄断性基础模型已引发数字基础设施升级的安全忧患并存在投射西方价值观和语言文化偏见的风险,故研发自主可控的基础模型和更具适用性的教育基础模型是生成式人工智能教育应用的安全底线。生成式人工智能主要以成人应用互联网产生的数据作为训练用数据,其基于聊天的内容服务方式不适合未成年人,应设置独立聊天的年龄下限。从教育内容提供的视域考证,基于广而杂数据集训练并采取付费内容服务模式的人工智能生成内容作为主要的教育内容获取来源,存在既不符合技术设计初衷也不符合教学目的的悖论。而从教学育人过程的视域考证,生成式人工智能输出内容可用自动化的“内容预制菜”明喻其惰化学习主体通过解构内容实现知识建构和技能获得的反智风险。课程内容制作、双基学习、特殊学习需求、高阶思维和探究实践,是设计主体适应和学科适用的生成式人工智能教学应用的主要情境与脉络。
生成式人工智能;ChatGPT;人类思维符号表征;价值观及语言偏见;教育适用性;基础模型
引言
自2022年11月美国开放人工智能研究中心(OpenAI Artificial Intelligence Research Center INC,简称“OpenAI”)发布第三代聊天生成式预训练转换模型(Chat Generative Pre-trained Transformers,ChatGPT,下文简称“ChatGPT”)——ChatGPT-3以来,人工智能开发商便开始炒作关于生成式人工智能(Generative Artificial Intelligence,GenAI)教育潜力的激进观点,学术界也跟风式地持续涌现关于其教育应用模式或引发教育变革的理论假设。为确保在教育中有目的、有组织地合法、有效应用生成式人工智能,亟需矫正“技术跃迁焦虑”驱动、忽视实然新技术性能和技术局限的人为理论造魅及其对政策的误导,并回归技术与教育的应然互动关系来论证其教育价值。为此,联合国教科文组织于2023年9月发布《生成式人工智能教育与研究应用指南》(下文简称《指南》)[1]。作为生成式人工智能在教育领域的第一个全球性指导文件,《指南》力图从以下五个层面考证其教育寓意:①可能威胁教育作为公共产品属性的基本争议。作为技术起点,《指南》首先概要叙述了生成式人工智能的工作原理并辨析了其技术局限,总结和剖析了该技术可能引发的八个主要法律和伦理忧患。②确保可信教育人工智能的治理规则。《指南》以“以人为本的人工智能应用原则”为指导,基于对全球人工智能治理现状的调研和分析,提出了各国制定生成式人工智能管理办法的路线图和具体管理建议,尤其倡议各国应考虑设置未成年独立使用ChatGPT等聊天平台的年龄下限。③教育管制与应用政策。《指南》详细阐述了在教育领域合法、有效应用生成式人工智能技术的政策要件和实施策略。④教育实践应用的设计与评估。因循优先管制、确保包容、引导应用的隐含逻辑,《指南》提出“人类主导、主体适用的互动性应用”的生成式人工智能教育实践应用框架,建议从科学研究及研究性学习助理、协同课程制作、双基教学助理、可计算的技能操作诊断、特殊学习需求等生成式人工智能具有明显技术潜能的领域,审慎论证生成式人工智能的应用场景。⑤对学习过程、学习结果及其评估等的深远影响。《指南》倡议各国追踪研判并反思生成式人工智能对学习目标与评价、知识产权、学生思维、心智发展等的长远影响,据此制定中长期应对措施。
本研究是对《指南》进行解读的第一篇,重点结合生成式人工智能的工作原理,考证其教育应用的安全性、价值观投射、未成年人独立聊天的风险,并辩证分析其在支持教育内容提供、教学过程实施等方面的适用性和变革潜能,以期探索更有针对性的管理和应用策略。
一 生成式人工智能的基本性能:对人类思维符号表征系统的模式识别与内容生成
在以文本、图像和视频制作为产品输出的商业领域,已投入使用的ChatGPT对于生产力的提升效果显著。哈佛商学院对律师、咨询等行业中ChatGPT应用效果的调查结果显示,ChatGPT可提高12.2%的文本生产力,文本加工的质量提升了40%[2]。但文本、图像和视频加工产品在教育领域属于初始的内容输入,而绝非教学目的,甚至不是教学过程的重点。因此,诸多关于生成式人工智能会对教育产生根本性变革的假说,多属于既脱离技术原理又无视教育目标和过程的无端推测。深入辨析生成式人工智能的技术原理、已有的技术边界和可能的技术发展路向,并从教学育人目标和过程出发考证其适用性,是理性判断其教育价值的逻辑基点。
1 从处理人类思维符号表征系统的角度理解生成式人工智能
(1)生成式人工智能的定义
《指南》从人工智能对人类思维表征符号系统的模拟角度,对“生成式人工智能”进行了定义:生成式人工智能是根据人类借助思维符号表征系统表达的提示(Prompts)自动生成内容的人工智能技术。不同于仅能对已有网页进行搜索排序或单纯地对现有内容进行提取和重新编排的数字技术,生成式人工智能可以生产先前并不存在的新内容。生成式人工智能技术允许用文字、语音等格式呈现提示或提供图形图像、视频、软件代码等参考范例,然后以论文或报告、声音、图像、绘画、视频、软件代码等各类符号表征呈现输出的内容。生成式人工智能的核心技术是生成式预训练转换模型,这是一种利用从互联网网页、社交媒体对话和其他在线媒体中收集的数据进行训练的内容生成深度学习模型。生成式人工智能虽然可以生产新内容,但不能理解文本背后隐含的现实世界中的物体、物体之间的关系和社会关系,因而不能形成新的观点或应对现实世界复杂挑战的解决方案。此外,尽管生成式人工智能具有内容输出的流畅性、相对于提示要求的内容输出针对性等特点,但当前仍不能被信任为可生成准确、可靠内容的技术。即便是ChatGPT也在用户协议中声明:尽管诸如ChatGPT的工具可生成看似合理的答案,但不能被视为可依据的准确答案(详见https://chat.openai.com)。生成式人工智能输出中的错误很难被那些对相关查询和聊天主题缺乏牢固知识基础的用户察觉,对尚未掌握足够事实性知识的未成年人用户来说此问题尤为严重。为此,OpenAI等生成式人工智能提供商建议:在高厉害关系领域,包括面向未成年人讲授事实性知识的教育领域,应该慎用或不用ChatGPT等并非基于专业数据培训的生成式人工智能平台。
(2)生成式人工智能对人类思维符号表征系统的模式识别与内容生成
在近期生成式人工智能的诸多突破性技术中,真正引发深思的是该技术看似逐步具备了处理人类思维所采用的全部表征符号的性能。人类常用的符号表征有口头或书面语言呈现的自然语言、图形图像(包括抽象图形、照片或视频、图像、绘画等)、音乐和软件代码等。生成式人工智能技术支持人类借助自己惯常使用的各类符号表征来呈现提示或提供参考范例,然后通过生成式预训练转换模型,以人类无法觉察其延迟的运算速度,用论文、报告、演示文稿、声音、图像、绘画、视频、数字或数值、软件代码等各类符号,表征呈现其生产的内容、答案或建议。
在接受输入提示方面,ChatGPT-3和ChatGPT-3.5仅限于文本输入,而ChatGPT-4接受用户在文本输入的基础上同时使用语音和图像呈现混合提示,在“文生文”的基础上实现了“图(含视频)生文”“文生图(含视频)”等跨符号表征的功能,并支持在提示和响应中混合使用计算机代码。2023年9月,OpenAI发布人工智能图像合成模型的测试版本DALL•E 3,其以ChatGPT为基础,支持用户通过提示工程(Prompt Engineering)逐步展开复杂的描述,再根据描述自动生成图像,展现了通过自然语言对话生成图像的能力。ChatGPT-4也获得了可为静止图像或录像自动生产字幕、对图像中的元素进行分类识别并分析图像中的文本内容、解释图像传承的艺术模因(Memes)、对同时含有文本和图像的文件进行总结提炼等技术性能。
除了ChatGPT系列产品,2023年初谷歌公司发布“诗人”(Bard,详见https://bard.google.com)大语言模型,可实现与互联网保持实时链接,并为其输出的响应提供即时更新的信息;随后,又发布了多模态大模型“双子座”(Gemini),能够理解和生成文本、计算机代码,并能够识别和生成图像,是与ChatGPT-4性能对标的基础模型。元宇宙公司(下文简称“Meta公司”)的大语言模型“羊驼”(Alpaca,详见https://crfm.stanford.edu/2023/03/13/alpaca.html),致力于解决大语言模型输出中的错误信息、社会刻板印象和有害语言问题。“Meta大语言人工智能模型”(也称Llama大模型,详见https://ai.facebook.com/blog/large-language-model-llama-meta-ai)则是基于更小的超算能力和较少的训练资源,来探索新型生成式人工智能开发模式的前沿尝试。
由于生成式人工智能在技术性能、技术集成的深度和综合性等方面已超越单纯的大语言模型,有研究者认为“大语言模型”已不再适合概括生成式人工智能技术的全部内涵,故提出用生成式人工智能“基础模型”(Foundation Models)的概念代替大语言模型[3]。生成式人工智能最近的技术进展也为人工智能上下游垂直技术研发提供了具有突破性的基础模型,并触发了人工智能芯片、超算能力、数据分析和表达、模型优化等各核心技术领域的竞争。围绕生成式人工智能基础模型新涌现的“卡脖子”关键技术集群,将是自主可控数字技术研发的必争领域。
2 生成式人工智能的技术原理
(1)生成式人工智能的基本工作原理
①文本生成式人工智能的基本工作原理。文本生成式人工智能使用人工神经网络技术中的通用文本转换器,通常又被称为“大语言模型”(Large Language Model),但大语言模型不能被用来概括图像生成式人工智能,也不能用来统称生成式人工智能的所有门类。经过训练的生成式预训练转换器可通过以下步骤,根据人类用户的提示指令生成文本或输出其支持的其他格式:第1步,提示指令被分解为文本的最小单位或基本元素字节(Token),然后输入到生成式预训练转换器中。第2步,转换器通过统计模型预测组合为连贯反应的最可能的词语或句子,具体流程是转换器先从训练用大数据模型中确认单词或短语的语言模式,之后转换器借助这些语言模式预测特定单词或短语在特定语境中出现的概率,最后基于概率预测,转换器在其反馈中预测后续最有可能的单词或短语。第3步,预测产生的单词或短语转化为可阅读的文本(或可理解的声音)。第4步,可理解的文本或声音经过“护栏技术”(Guardrails)处理,过滤掉不良输出(如明显违法或违反已知伦理法规的内容等)。第5步,重复第2步至第4步,直到完成一个完整的响应(即达到字节数的最高限度或预先设定的响应停止基准)。第6步,产生的响应采用后处理技术进一步加工,通过格式编排、添加标点及其他语言增强方法(如模拟人类可能应用的语气词“是的”“当然”“对不起”等),来提高其可阅读性或可理解性。
文本生成式人工智能模型为需要内容处理和表达的各领域提供了基础性自动化内容加工工具,并已引发了内容加工行业的生产方式变革。例如,微软的文字处理、电子表格、演示文稿制作等办公套件,已实现内嵌ChatGPT的软件升级。再如,谷歌在Chrome浏览器内嵌“文案写作人工智能”(Compose AI)模型,支持写作中的语句自动完成和文章生成;内嵌于PDF软件的“PDF聊天”(ChatPDF,详见https://www.chatpdf.com)可对PDF格式文件内的文本、图表等进行识别和加工,并自动总结文件的要点,开展基于文本的问答对话。
生成式人工智能借助概率对文本上下文进行模式识别,根据句法规则生成文本内容,但它并不理解语言的语义(Semantics),与人类理解自然语言并基于对语言的理解借助各类符号表征进行沟通和问题解决的能力相去甚远。同时,生成式人工智能不能借助句法理解文本和图像等背后真实世界中的物体和复杂的社会关系,尽管它可以为人类的知识发现提供文献综述和数据计算的支持,但其自身不能发现新知识。囿于现有技术局限,生成式人工智能技术无法为解决现实世界中的复杂挑战提供创新型解决方案,也不能做出社会价值判断或价值观引导。这一技术局限制约了生成式人工智能较为独立地引导复杂知识学习和问题解决的导学性能,进而限制了其变革教育的潜能。
②图像及音乐生成式人工智能的基本工作原理。图像及音乐生成式人工智能采用不同的人工神经网络技术——“生成对抗网络”(Generative Adversarial Networks,GANs),可与变分自动编码器合并使用。GANs由两个对抗器组成,即生成器(Generator)和判别器(Discriminator)。以图像生成对抗网络为例,生成器会根据提示对图像要素组合模式进行识别并生成一个随机图像,判别器会对比生成图像与真实图像的拟合度。随后,生成器会根据判别器的对比结果调整其使用的复杂参数,以生成更优化的图像。在预训练中,该过程会被重复千百次,以保证生成器创作出判别器难以判断与提示预期存在差异的图像。例如,如果用数千张关于某地的风景照片训练一个生成对抗器,其创作的关于该地的非真实图像将几乎无法被识别为假图片。与此类似,如果用某种风格、某个音乐家或某一歌名的不同音乐数据集训练生成对抗器,其创作的新音乐将能复制原始音乐的复杂音乐特征。
图像生成式人工智能亦多被ChatGPT的相关技术模型所垄断,如“达利•E 2”(DALL•E 2,详见https://openai.com/product/dall-e-2),这是OpenAI的图像生成人工智能工具,在此基础上还衍生出了“蜡笔”(Craiyon,详见https://www.craiyon.com)平台。此外,“途中”(Midjourney,详见https://www.midjourney.com)综合了DALL•E和稳定扩散模型(Stable Diffusion Model),而“夜间咖啡馆”(NightCafe,详见https://creator.nightcafe.studio)、“图像冲击波”(Photosonic,详见https://writesonic.com/photosonic-ai-art-generator)、“摄影师”(Fotor,详见https://www.fotor.com/features/ai-image-generator)等也都采用了DALL•E 2平台。
视频生成式人工智能基础模型除了ChatGPT-4,还有“胶质云平台”(GliaCloud,详见https://www.gliacloud.com),此平台可从新闻内容、社交媒体发帖、现场运动赛事、统计数据中生成视频。此外,“图像工厂”(Pictory,详见https://pictory.ai)和“跑道”(Runway,详见https://runwayml.com)也都可从文字中生成或编辑加工具有专业品质的视频。
音乐生成式基础模型或平台包括:“人工智能虚拟艺术家”(Aiva,详见https://www.aiva.ai),可自动创作个性化的原声音带;“爆音”(Boomy,详见https://boomy.com)、“声音玩家”(Soundraw,详见https://soundraw.io)、“变声器”(Voicemod,详见https://www.voicemod.net/text-to-song)等,都是可支持零音乐创作基础的用户用文本自动生成歌曲的平台。
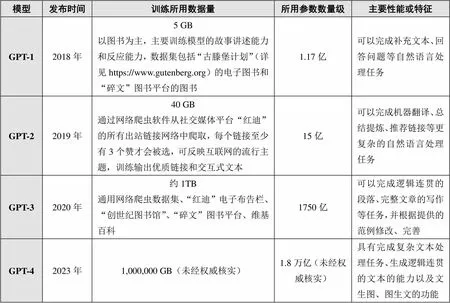
表1 OpenAI各版本GPT的训练用数据集和参数
(2)生成式人工智能的模型架构、预训练用数据量和参数的迭代升级
每一个新版本的生成式预训练转化器均在先前版本的基础上对人工智能架构、训练方法等进行综合的迭代优化,所使用的预训练数据集数量和所采用的参数也呈爆炸式增长。其中,参数是人工神经网络系统中决定该系统如何加工输入和产生输出的数值。参数通过训练中的数据界定,对模型中的知识和技能进行编码。参数决定预训练转化器的性能和应用表现,故而对预训练转换技术来说至关重要。一般而言,参数越多,能处理的数据和做出的表达越复杂。GPT使用了万亿数量级的参数,支持其处理复杂任务、生成逻辑连贯的文本的能力(具体如表1所示)。生成式人工智能架构和训练方法的迭代优化、预训练用数据集和数以亿计的参数处理,都依赖于超算能力的同步加速提升。2012年以来,用于生成式人工智能模型训练的算力的翻倍周期为3~4个月,其算力翻倍速度打破了预测计算机计算能力每两年翻一倍的“摩尔定律”[4]。
(3)现有垄断性生成式人工智能系统的训练用数据集来源和语言分布
上述处于垄断地位的生成式人工智能模型的训练用数据集主要来源于互联网网页的“爬取”信息、社交媒体对话信息、在线图书馆图书资料和互联网百科类平台的百科内容。根据OpenAI公开的资料和第三方统计,ChatGPT-3实际使用的训练用文本数据(即语料)不到1000GB,即1TB左右[5]。主要的数据来源有:互联网“通用网络爬虫数据集”(Common Crawl,详见https://commoncrawl.org),约占数据总量的61.75%;“红迪”(Reddit,详见https://www.reddit.com)电子布告栏,约占18.86%;“创世纪图书馆”(Library Genesis,详见https://librarygenesis.net)的图书,约占8.1%;“碎文”(Smashwords,详见https://www.smashwords.com/)图书平台的图书,约占7.8%;维基百科,约占3.49%。
与此同时,目前垄断性生成式人工智能模型的训练用数据集以美国及其欧洲结盟国家的语言为主。在ChatGPT公布的训练数据集语言分布中,英语语料占比高达92.64708%,其次是法语(占比1.81853%)、德语(占比1.46937%),而汉语语料占比仅为0.09905%[6]。针对这一问题,后续发布的大语言模型开发商宣称将致力于提高训练用数据集的语言代表性,但整体上仍无法改变英语及西方结盟国家语言占绝对优势的现状。例如,在自称致力于提升大语言模型语言多样性的Meta公司开发的Llama 2语料中,英语占比虽有所下降,但仍占89.7%;其他占比排前15的语言几乎没有改变;汉语语料略有提高,占0.13%[7]。
(4)现有垄断生成式人工智能平台的内容服务收费
字节通常被用作生成式人工智能收费服务的计价单位。1字节大概等于0.75个英文单词,而一个简体的中文汉字大概等于1.2~3字节或平均相当于2.7字节。以ChatGPT的定价为例,OpenAI细分出实用的产品变型并根据变型分类定价。每个产品变型通过可支持用户输入、输出的上下文长度(即提示输入的字节限制、内容生成的字节限制)进行划分,其中4K上下文最多允许4,096字节,而16K上下文最多允许16,384字节。OpenAI以GPT-3.5增强版作为起点服务平台,其服务定价如表2所示。而ChatGPT-4支持更长的上下文长度,其中型号为32K的产品的字节输入、输出长度均可达32,768字节,可支持对输入、输出性能要求较高的二级开发商和个体用户处理范围更宽泛的文件,并在对话中保持篇幅更长的上下文理解能力,但服务价格大幅提高,其服务定价如表3所示。

表3 GPT-4的服务定价
OpenAI的图像和音乐等平台根据生成图像的分辨率或像素划分服务类型,并以图像为单元收费。DALL•E的图像生产服务收费标准如表4所示。

表4 DALL•E的图像生产服务收费标准
二 已有垄断性生成式人工智能平台教育应用的安全和价值观风险
美国OpenAI、谷歌、Meta公司的垄断性基础模型已被广泛应用,并已被内嵌为数字基础设施的有机组成部分,将对包括教育在内的各领域数字安全产生广泛而长远的影响。考证垄断性生成式人工智能平台对数字安全性、价值观等方面的深远影响,是讨论其教育应用的安全底线。
1 垄断性生成式人工智能平台的数字安全控制和价值观投射
(1)垄断性基础模型的数字安全威胁
现有垄断性基础模型引发的数字基础设施升级,从某种意义上也将是对其他国家数字安全威胁的升级。生成式人工智能已被互联网搜索引擎、浏览器等在线数据控制性基础设施采纳为内嵌模型,并已引发数字基础设施的升级。例如,谷歌公司的Chrome浏览器内嵌了多种生成式人工智能功能,主要包括:①“网络聊天GPT”(WebChatGPT,详见https://tools.zmo.ai/webchatgpt),可将ChatGPT与互联网连接以获取更准确、更及时的对话信息;②“智慧合一”(Wiseone,详见https://wiseone.io),可协助阅读过程中相关信息的实时查询;③“人工智能个人助理团队”(TeamSmart AI,详见https://www.teamsmart.ai),可综合调用ChatGPT-4、谷歌PaLM 2的Bison版本、Meta公司的Llama 2版本和其他大型基础模型。这些内嵌的生成式人工智能服务会要求用户提供电子邮件、社交账号等信息,并且会诱导用户在提示工程中开放社交账号中的文本、图像、视频等信息。由此,生成式人工智能即成为控制网络安全和个人网络隐私、主导网络流量的最底层数字基础设施的重要节点。失去基础模型的自主可控权,就意味着失去国家网络安全和公民数据保护的主动权。自2018年中美贸易冲突以来,美国随时可用维护国家安全的借口,针对其管辖范围内的核心技术对中国采取强制封锁和禁用措施。在此历史背景下,ChatGPT等美国的垄断性生成式人工智能平台在中国的应用,不具备技术可达性和数字安全的底线保障。
(2)生成式人工智能不理解价值观,但会投射价值观
当前,在垄断性生成式人工智能模型的训练用数据集的语言分布中,英语及美国主要欧洲结盟国家的语言占绝大多数。生成式人工智能并不能理解人类的价值观,但在训练转换器的过程中,如果训练用数据集的拥有者持有某种价值观,那么与该价值观相符的词汇和句法等便会被更多次地重复,从而被转换器识别为标准的文本模式而在其输出过程中得到强化并作为标准答案输出。这些被技术强化的、隐含某种价值观的语句,会被用户解读并生成与价值观关联的意义。尽管压制其他价值观和文化标准或许并非生成式人工智能的设计初衷,但对未被纳入预训练数据集的语言来说,其相关的语言范式、文化观念无法在转换器得到确认和重复。因此,主要基于美欧语料的基础模型对该领域的垄断客观上会借助文本、图像、视频等内容产品的掩盖,以难以察觉且难以抵制的方式更集中地投射“价值观和文化标准答案”,潜移默化地对处于语言文化风格和价值观成长期的青少年进行价值观渗透,并导致弱势群体数字殖民的升级[8]。
2 确保生成式人工智能教育应用的安全性
(1)强化对面向境内提供服务的跨国生成式人工智能提供商的管理
2023年7月,我国国家互联网信息办公室联合多部门公布《生成式人工智能服务管理暂行办法》(下文简称《办法》)[9],明确了辖域内服务适用的治理范畴界定,即“用生成式人工智能技术向中华人民共和国境内公众提供生成文本、图片、音频、视频等内容的服务”都应该接受本《办法》的管理;同时,明确规定提供和使用生成式人工智能服务应“坚持社会主义核心价值观”,并强调要“在算法设计、训练数据选择、模型生成和优化、提供服务等过程中,采取有效措施防止产生民族、信仰、国别……等歧视”。鉴于生成式人工智能的价值观投射具有极高的隐蔽性,目前可预见的监控方法主要有两个:一是要求向境内提供服务的生成式人工智能平台体现辖域内主要语言在训练语料中的代表性,考虑设置中文在训练语料中的占比下限;二是监管部门和用户合作,对生成式人工智能输出内容投射的价值观进行监控,“建立健全投诉、举报机制”,一旦“发现违法内容的,应当及时采取停止生成、停止传输、消除等处置措施,采取模型优化训练等措施进行整改。”
(2)优先基础模型的自主可控研发和基于开源技术的国际合作
应对目前垄断性生成式人工智能平台引发的数字安全升级,中国应鼓励和支持产权自主、安全可控的核心基础模型的技术研发,评估与预判已有垄断性基础模型引发的底层数字基础设施升级带来的安全隐患,并制定安全可控的自主数字基础设施升级方案。尽管百度的“文心一言”、阿里巴巴的“通义千问”以及其他的中国自主可控大语言模型在模型架构、训练用数据集和参数规模、模型的性能及其成熟程度等方面,均与上述垄断性基础模型存在代际差距,但基于本国数据集和本土技术团队的基础模型研发是实现产权自主、安全自控的唯一战略选择。同时,要倡导和支持基于开源技术的国际合作,通过知识共享提升技术研发能力,并探索构建优质数据和超级计算资源共享的机制,以对抗现有基础模型开发的垄断。在开源生成式人工智能领域,较为成熟和有影响力的是HuggingFace社团开发的“拥抱聊天”大语言模型(Hugging Chat,详见https://huggingface.co/chat),该社团倡导研发和训练的伦理合规性、透明性,并强调其用于模型训练的数据全部开源。另外,“开源助手”平台(Open Assistant,详见https://open-assistant.io)提供大量的开源模型、数据等,支持技术专业知识丰富的人士合作开发产权可控的大语言模型。
(3)支持基于本国课程标准的教育基础模型开发
在超前研发产权自主的核心基础模型的同时,应同步布局各关键专业领域自主可控基础模型研发的新赛道。教育基础模型或教育生成式预训练转换器(EdGPT)是基于本国审核批准的课程标准和教材内容数据、数字化教育管理和教学过程数据训练的生成式预训练转化器,可最大程度地确保生成式人工智能智能教育应用的价值观与语言文化自主。目前,已推出实测或实用版本的教育基础模型主要有“数学GPT”(MathGPT,详见https://www.mathgpt.com)和“默林大脑”(Merlyn Mind,详见https://www.merlyn.org)。从本质上来说,教育专用模型是放弃基于海量互联网数据训练出的大模型所具有的宽域内容输出这一教育低相关性技术特性,转而追求用小而专的教育数据训练更安全、更去除价值观偏见的转化器以输出更符合教学需求的精准内容和对话响应。教育专用模型能在多大程度上将生成式人工智能的最新技术进展降维应用到教育领域、教育专用模型的底层技术组合和架构设计等能在多大程度上实现学科专业知识“理解力”方面的升维突破,将是考察教育大模型性能和应用效果的重要指标。与此同时,教育基础模型的功能设计还需要界定内嵌主体适用的基本教学法与保护真实师生互动之间的边界,预防教育基础模型成为预设教学方法和流程甚至取代师生互动活动的“教学过程预制工具”。
三 生成式人工智能的年龄适用性和教学适用性
超越目前垄断性基础模型的安全性和适用性的范畴,生成式人工智能作为通用性的技术,也存在自身的技术性能有限并受人机互动边界的限制。从用户年龄、教学内容提供的需求、教学过程的特点等角度考证生成式人工智能的适用性,是发挥其教学育人潜力、规避风险的前提。
1 “聊天式”内容服务的年龄适用性
①未成年人借助生成式人工智能平台聊天的风险。未成年人借助现有的通用生成式人工智能平台聊天的年龄适用性,是考证中小学阶段生成式人工智能教育应用的法律和伦理前提。从上述预训练用数据来源的考证可以看出:现有的通用生成式人工智能模型将未经选择的成年人应用互联网过程中产生的数据作为主要的训练用语料,以支持成年人聊天式的内容服务为目的而开发。道德判断能力和社会行事能力均未达到自我保护下限的未成年人在与这些预训练模型的一对一聊天互动中,不可避免地会面临诸多风险,包括曝光于输出响应中的不适内容、借助未成年人肖像的“深伪”数字图像合成和网络传播、通过聊天互动对未成年人的行为操控等。
②未成年人独立使用生成式人工智能平台聊天的年龄下限。鉴于可预判的独立聊天风险和生成式人工智能技术在生成不准确内容等方面的不确定影响,联合国教科文组织在《指南》中建议各国政府对未成年人在无成年人监督下使用生成式人工智能平台的独立聊天设置年龄下限。参考已有的未成年人独立使用社交媒体聊天的相关法律[10][11][12],《指南》建议独立使用生成式人工智能平台聊天的年龄下限设置为13岁,并考虑16岁的更严格年龄限制。在我国,《生成式人工智能服务管理暂行办法》提出生成式人工智能“提供者应当明确并公开其服务的适用人群”,并要求“采取有效措施防范未成年人用户过度依赖或者沉迷生成式人工智能服务”[13]。相关监管部门应在此基础上,考虑进一步明确未成年人在无成人监督下与生成式人工智能聊天平台独立聊天的年龄下限。
2 生成式人工智能用于教育内容获取的悖论
(1)生成式人工智能的商业内容产品输出不具备公共教育内容输入的直接适用性
在商业领域,生成式人工智能提供商面向商业客户开发并提供文案、图像、绘画、视频和音乐等产品服务,然后按服务质量和数量收费的服务模式无可厚非。但是,内容收费服务模式与知识属于公众领域、教育提供属于公益范畴的基本共识相悖。故而,这种以输出商业内容产品为目的的技术,也不具备直接用作教育内容输入的适用性。可能的解决方案包括开发和采用更具可承受性的本土教育生成式人工智能模型、政府集体购买现有平台的使用权限并作为教育技术方案的一部分供学校和师生免费使用等方式,为教育系统提供可承受的生成式教育内容。而生成式人工智能在教育内容提供方面的适用性或适用的范围,是一个更值得深入考证的悖论。
(2)生成式教育内容获取悖论
生成式人工智能在内容生成方面取得的技术进展,引发了该技术可为教育提供教材和教师之外的第三方对话式知识获取来源的逻辑联想,也产生了可通过生成式人工智能解决贫困地区教育内容供给不足的假设,并引发了该技术会对知识的获取和生成方式乃至教学互动过程产生革命性影响的预测[14]。基于对生成式人工智能技术原理的追溯,这些假设似乎存在多重悖论。
①技术设计“目的与用途”间的悖论:生成式人工智能技术的设计初衷,是服务于专业文案创作者、视觉效果设计者、法律服务或咨询机构等。生成式人工智能平台文本输出中的少许错误或其他符号表征作品的缺陷,均可被具备高度鉴别能力的专业人员识别,并通过对话式的提示工程逐步剔除,最终输出符合预期的作品。但学生尤其是低学段学生往往缺乏巩固的事实性知识、专业领域知识、鉴别内容准确性的能力以逐步递推的提示工程所需的元认知能力,不是生成式人工智能技术设计的直接目标人群,因此直接使用生成式人工智能的输出作为学生尤其是低学段学生的主要学习内容来源也不符合其设计初衷。
②教师天然知识与“机器瓶装内容”之间的选择悖论:预训练模型采用的训练数据是人类教师知识储备的数千万倍,但人类教师的知识是由人理解、由人输出的天然知识,其与学生的互动也是由人负责、由人随时动态更正和更新的天然人际互动过程。预训练模型的内容可用预先封装的“瓶装内容”来比喻,受其技术原理的局限,这种瓶装知识广度有余但准确度和人文互动不足。尽管谷歌、OpenAI等公司已将其大模型接入搜索引擎以支持即时信息和验证,试图打开“瓶装内容”的“瓶盖”。但如果忽视教师的天然知识及其对注意力、情绪等非智力因素的把控,而过分重视不理解语义和真实世界的机器内容,那么将陷入教学内容获取主渠道的悖论。
③借助生成式人工智能面向贫困地区提供教学内容的预算悖论:针对教育内容和优质师资匮乏的贫困地区、通过生成式人工智能平台支持学生内容获取的主张,从逻辑上是一种“用更不可承受的方案解决固有资源匮乏问题”的悖论。生成式人工智能的部署和日常性可持续应用对数字设备和宽带网普及率、学生数字技能等方面的数字准备状态要求极高,缺乏经费提高生/师比的国家和地区不具备这些需要充足经费且数十年积累才能达到的数字化准备状态。同时,越是在低收入国家和地区,个体用户需承受的互联网数据流量费用在其平均收入中的占比越高。据国际电信联合会统计,非洲地区国家2022年的互联网数据流量费用占平均国民收入的5%左右,低收入国家的互联网数据流量费用占平均国民收入的9.3%[15]。在低收入地区的师生及家长已无力承担现有通用互联网数据流量费用的前提下,要求师生再承担额外费用不具有可行性。
3 “内容预制菜”应用于教学过程的反智隐忧
生成式人工智能根据人类用户的提示,在对各类素材进行模式识别基础上输出的文本、图像、音乐、视频等作品可称为“内容预制菜”。“内容预制菜”既可作为最终成果,也可作为半成品供进一步编辑、完善。生成式人工智能基础模型在商业领域的迅速普及,引发了“内容预制菜”商业模式在教育界的机械模仿。然而,学习主体在对确信的学习内容进行解构的基础上,开展主体能动的知识建构、技能获得和价值观养成,是实现内容的教育价值的根基。通过机器对训练用数据进行解构(即模式识别),在此基础上建构的“内容预制菜”反映的是对学生内容解构的替代逻辑。盲目强调“内容预制菜”的教育变革价值,可能会引发多层面的反智隐忧。
①内容幻象引发基础知识幻象。在内容输出过程中,生成式人工智能平台会生成关于客观事实和学科知识的“一本正经”的错误或者说是内容幻象。如果缺乏成人或教师的及时纠错,缺乏事实性知识和学习知识基础的低学段学生会基于人工智能幻象形成基础知识幻象。
②“内容预制菜”引发智力活动惰化。“内容预制菜”在商业领域可提高内容生产效率和质量。但在教育领域,内容更多地被用作教学讲解和学生理解的信息或知识输入,以培养人的智力、能力和价值观为主要目的。生成式人工智能对内容解构和建构的自动化替代,会剥夺学生尤其是低学段学生有目的地获取内容、有意识地从内容中解读意义、进行知识理解或形成技能的认知过程。处于智力和能力成长期的未成年学生如果长期无批判、去原理解读地复制“内容预制菜”并以此作为学习结果提交,会存在智力发展弱化(Intellectual Enfeeblement)的风险。
③与不理解世界的人工智能的对话可能引发导学反智。现有的垄断性生成式人工智能系统并不能理解文本或图像背后的真实世界,导致其在指导复杂知识的建构、结构不良问题的解决、通过观察的经验获取等方面均具有明显的技术劣势。如果缺乏对此技术局限的理解,忽视教师引导的作用而过分依赖生成式人工智能聊天平台对学生开展导学,将限制学生与现实世界互动中的经验获取、复杂问题解决能力的培养和价值观的养成。
总之,应明确在生成式人工智能教育应用过程中师生主体主观能动性的不可替代性,明确学生的复杂知识理解与建构、开放性问题解决、与真实世界的互动等尚属于人工智能技术不能也不应替代的人类主体性教学的边界。同时,要防止用不理解世界的生成式人工智能技术来取代教师辅助、引导学生高水平思维培养和开放式学习的理论假设或实践模式。
四 基于教学育人需求解锁技术潜能的生成式人工智能应用模式探索
在具体的教学过程中,生成式人工智能在基于模式识别的新内容生成、贯通表征符号的文图转换、参考提示标准的拟合度评判、提炼文图要点的发散性聚合等方面具有较为明显的优势。解锁生成式人工智能的技术潜能,应先锁定教学育人的现实困境和发展需求,由此确认具有教育适用性的人机协作方案或研发可“解锁”教学方式变革的创新实践“密钥”。对此,《指南》倡导构建“人类主导、主体适用的互动性应用”的生成式人工智能教学应用设计框架。在此基础上,本研究建议将课程内容制作、双基学习、特殊学习需求、高阶思维、探究实践等宏观教学需求作为教学设计的主要情境和脉络,并据此设计和实施适用于不同年龄和学习能力、不同学习领域需求的中观课程与微观教学,以超越内容过剩的人工智能教育应用现状。
1 支持包容性课程资源制作的“转换器”:手脚增强的“人头马模式”
人工智能与教育中人类主体的关系不应是简单的竞争和替代,更不应是在已有数字化基础上增加的额外数字系统负担,而应从基础性支持工具层面贯通或升级数字化工具,在课程资源开发、行政管理等场域成为与人类智能共生和全教学过程融合的减负增智工具。
生成式人工智能在教育领域与人类智能共生的应用模式之一是“人头马”模式,即借助生成式人工智能跨符号表征的内容“转换器”性能,充当人类内容加工的增强型“手脚”,而人类专注于价值观判断、高水平思维和创造性活动。该模式已涌现的实践应用场景主要是支持广域课程资源开发和数字教材拓展的人机协作:生成式人工智能支持教育数字图书馆、教材库、师生自创内容库的自动化搜索与内容生成,并支持自动添加音视频字幕、基于文本或视频生成手语解说、基于文本生产视频等跨符号表征的内容自动化加工,然后由人类审核确认并分享,实现包容性课程资源开发、拓展性数字教材支持等方面的人机互补。例如,为教师提供免费开源课程资源的英国“橡果学院”,通过生成式人工智能将课程内容转录为视频并添加手语解说,然后由课程专家审核验证,以确保人类主体的全过程决策(详见https://www.thenational.academy);再如,韩国政府已宣布将在中小学各科电子教材中内嵌生成式人工智能技术(详见https://news.kbs.co.kr/news/pc/view/view.do?ncd=7695671),该计划将于2025年秋季全面推广,其设计的功能之一,是通过生成式人工智能支持师生实现更智能化的课程资源检索和格式转换、教学流程中的实时问答、学习结果的多媒体作品制作等。
2 支持基本技能形成性评价与反馈的“判别器”:教学助理数字孪生模式
教育教学作为一种复杂的形成性社会关系实践,并非在各个环节都需要实现个别化——其中最需要个别化的环节,是学生在练习基本技能过程中的形成性正误判别和纠正。生成式人工智能可依据人类提供的标准,实现对可计算的技能表现结果的拟合度匹配和判别,并提供形成性评价与反馈。对此,可以挖掘生成式人工智能迅速而强大的“判别器”潜力,构建部分实现教学助理功能的生成式教学助理数字孪生模式。在教育领域,可计算的技能表现包括人类的语言发音与拼写、计算机代码、基础性艺术学习中的基本艺术作品等。利用生成式人工智能,可以实现教师自身无法承担的、针对学生基本技能学习表现的一对一自动判别和个别化分析性反馈。2023年,哈佛大学采用ChatGPT支持其“计算机基础”课程的编码教学[16],但该前瞻性探索不能被夸大为“哈佛大学用ChatGPT取代教师教计算机编程”:ChatGPT仅被用于帮助有坚实计算机知识技能基础的大学生理解编程语句中的重点和难点,通过对话方式判别和解释学生在学习过程中出现的代码错误,并提供改进代码编写的建议等。
但是,开展基本技能训练的教学助理数字孪生模式还远远不能支持语言领域的综合语言应用能力和跨文化理解力、计算机领域的高级编程能力和计算思维、艺术领域的艺术想象力等高阶能力的培养。另外,此模式对学生已有的知识技能基础、自我监控和调整学习进展的元认知能力和自我监控能力都有较高的要求。因此,教学助理数字孪生模式更适合高校、中高等职业教育及成人学习者。
3 支持主体认知和探究的内容“增压器”:从内容富裕到探究富裕的研究助理模式
生成式人工智能支持下内容生成过程的高度自动化和生成结果的难以判别性,将倒逼课程与评价目标从“内容富裕”转为“探究富裕”。生成式人工智能合成的内容既无法被教师识别,也难以通过识别软件判别。如果教学目标局限于事实性知识的记忆且评价仅考察事实性知识的表达,学生就极易通过技术合成的内容应付作业和评价,导致生成式人工智能作弊的泛滥。
生成式人工智能在教学领域的潜在优势不是支持事实性知识的获取,而在于为探究性学习提供人类信息加工能力所无法触达的发散思维视角和文献综述广度,并通过对内容的浓缩综述和对数据的“增压”处理提升高水平思维和探究活动的效率。对此,可以挖掘基于生成式人工智能的探究性活动“增压器”潜力,探索研究助理模式或研究性学习助理模式。一个成人开发者借助生成式人工智能对话支持自我定制天气预报软件开发的实例(详见https://medium.com/@liorelgali),展示了生成式人工智能技术在创意激发、已有工具的综述和优缺点分析、专题研究、方案对比和功能取舍、自我思维局限挑战等方面的探究性“增压”价值。从科学发现的视域分析,人工智能基础模型在数据搜集、挖掘、计算等方面的突破,为人类提供了继观察、实验、推理之后的第四类科学发现范式——“基于人工智能的科学发现”(AI for Science)[17],使生成式人工智能研究助理模式在严谨的科学研究领域也有了巨大的应用空间。
需要注意的是,研究助理模式中的探究动机不可能通过技术的供给自动触发,而必须由课程与评价目标的调整和人类教师的教学设计激发引导,并最终由学生自主自导。应对生成式人工智能作弊风险的挑战,应允许学生借助技术替代一定低水平的内容处理,以从机械、重复中适度释放无意义的时间消耗。同时,通过评价目标调整和教学设计,引导学生将“剩余学习时间”更多地用于探究性学习。此外,研究助理模式中的认知过程也应由人类主导,设计师生与技术协作互动的探究活动,确保学习主体进行了具身认知与协作探究。尤其要注意发挥人类在有意义的问题界定、聚合思维、问题解决方法的顿悟等方面的优势,并与生成式人工智能的发散性内容综述和报告生成互补,实现人机智力的相互增强。
五 结语
考证生成式人工智能的教育适用性,不能局限于从已有教育体系的固有教育目标出发进行单向论证。近七八年来,人工智能已展现出通过任务单元的自动化来替代已有工作岗位、创造新岗位、打破现有工作技能培养格局的颠覆能力。生成式人工智能对工作岗位的颠覆已始于文稿创作、图像制作、音视频加工等行业[18],但其对工作岗位及其技能预期的冲击不会仅限于此。尽管生成式人工智能不应撼动教育的基本心智能力培养、价值观树立等育人目标,但其对工作技能更新与课程教学目标调适的即时冲击和长远影响已成为各国需共同面对的基础性课题。
生成式人工智能虽仍有较大的迭代创新空间,但现有的模型不理解语义和真实世界的技术局限会限制其变革教育的潜能,并模糊了教学过程中相对独立地引导复杂知识建构和问题解决的人际互动边界。从“传道、授业、解惑”的教育价值底线出发,可将生成式人工智能技术的适用性概述如下:目前该技术具有较强的一对一“解惑”能力,但应首先确保学生独立聊天的年龄限制和平台的价值观去偏;经由教育数据训练的基础模型会获得一定的个别化“授业”能力,但目前仅限于对学习结果表现具有可计算性的有限“学业”领域,这就需要警惕人工智能内容输出对学生内部认知过程的替代和惰化;在目前及可预见的未来,人工智能技术不但不具备“传道”的育人适用性,而且在数字安全、价值观误导、学习过程反智等方面已显现出反育人的威胁。对此,在讨论生成式人工智能是否可以为教学育人的种种问题提供“新答案”之前,必须先辨析和防范其造成的“新问题”。
[1][10]Miao F C, Wayne H. Guidance for generative AI in education and research[M]. Paris: UNESCO, 2023:1-38.
[2]Dell’Acqua F. Navigating the jagged technological frontier: Field experimental evidence of the effects of AI on knowledge worker productivity and quality[OL].
[3]Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation models[OL].
[4]Stanford University. Artificial intelligence index report[OL].
[5][6]Thompson A D. Contents of GPT-3 the pile v1[OL].
[7]Touvron H, Martin L, Stone K, et al. Llama 2: Open foundation and fine-tuned chat models[OL].
[8]苗逢春.数字文明变局中的教育数字化转型[J].电化教育研究,2023,(2):47-63、91.
[9][13]中国网信网.生成式人工智能服务管理暂行办法[OL].
[11]Federal Trade Commission. Children’s online privacy protection act of 1998[OL].
[12]European Union. General data protection regulation[OL].
[14]David B A, Ansah L O. Education in the era of generative AI: Understanding the potential benefits of ChatGPT in promoting teaching and learning[J]. Journal of AI, 2023,(7):52-62.
[15]United Nations. A global digital compact: An open, free and secure digital future for All[R]. New York: UN, 2023:4.
[16]Coffey L. Harvard taps AI to help teach computer science course[OL].
[17]Wang H, Fu T, Du Y. et al. Scientific discovery in the age of artificial intelligence[J]. Nature, 2023,620:47-60.
[18]Frey C B, Osborne M. Generative AI and the future of work: A reappraisal[J]. Brown Journal of World Affairs, 2023:1-12.
Examination of the Technique Principle of Generative AI and Its Educational Applicability
MIAO Feng-chun1,2
The paper is the first edition of a series of interpretative articles on the Guidance for Generative Artificial Intelligence(GenAI) in education and research released by UNESCO, focusing on the tracking of the technique principle behind GenAI and the examination of its educational applicability. GenAI is a category of AI technology that can produce new content across symbolic representations used by human thinking, but its technological limitation of not being able to understand semantics of text will reduce its potential in transforming education. As foundation models, GenAI has triggered the upgrading of monopolized digital infrastructure and generated threats on digital security and it risks to project the linguistic and cultural bias held by western people whose data were used to train GPT models. The development of self-automatic GenAI models, especially EdGPT, is threshold for the secure and trustable use of GenAI in education. Based on the datasets generated by adults’ application of the Internet used to train GPT models, the chatbots-based service is not appropriate for independent use by children, and national regulatory agencies should set up the age restriction for children’s independent conversations with GenAI chatbots. From the perspective of provision of education content, the use of the service of generative content priced by tokens as main sources of education content is a paradox that is not supported by the original design of GenAI and the main aims of education. From the processes of learning and values fostering, an allegory of “automatic prefabricated content dishes” helps reveal that the unconscious use of outputs of GenAI risks of enfeeblement through reducing human agency in deconstructing content in order to construct knowledge and develop skills. The co-creation of inclusive curricular content, foundational learning, learners with special needs, and higher-order thinking as well as inquiry practices are the main contextual criteria to design human-agent and pedagogy-proper interactive use of GenAI in teaching and learning.
GenAI; ChatGPT; symbolic representations of human thinking; biases in values and linguistic biases; educational applicability; foundation model

G40-057
A
1009—8097(2023)11—0005—14
10.3969/j.issn.1009-8097.2023.11.001
苗逢春,北京师范大学研究员,联合国教科文组织总部部门主任,研究方向为人工智能与教育、数字学习政策、未来数字学校,邮箱为f.miao@unesco.org。
2023年8月28日
编辑:小米
