无注意力胶囊网络的面部表情识别方法
2023-11-27许学斌刘晨光路龙宾曹淑欣徐宗瑜
许学斌,刘晨光,路龙宾,曹淑欣,徐宗瑜
1.西安邮电大学 计算机学院,西安710121
2.西安邮电大学 陕西省网络数据分析与智能处理重点实验室,西安710121
人类通过表情传递大量的情感信息,随着人工智能以及计算机技术的发展[1],采用表情识别技术可以从人类的表情中分析出识别对象的情感活动,因此面部表情识别是计算机视觉领域一个很有意义的研究方向[2]。面部表情识别(facial expression recognition,FER)技术是将生理学、心理学、图像处理、机器视觉与模式识别等研究领域进行交叉与融合[3],面部表情识别在生物特征识别、医疗研究以及自动驾驶等领域都有着广阔的应用前景。
1971 年Ekman 和Friesen 定义了厌恶、愤怒、恐惧、快乐、悲伤和惊讶六种基本情绪[4]。随后,藐视也被作为基本的情绪之一[5]。
面部表情识别主要经历三个过程,如图1所示。首先是对输入的面部图像进行预处理,进行灰度化或者二值化处理,采用计算机技术将图片信息数字化,再去除图片噪声,使某些特征更加敏感;然后提取一种面部表情照片的嘴巴、鼻子以及眼睛等显著特征;最后根据已经提取好的图像特征进行人类表情的分类。

图1 图像识别过程Fig.1 Image recognition process
传统的面部表情识别主要是通过人工提取图像类特征的方法进行分类,如尺度不变特征变换(scaleinvariant feature transform,SIFT)[6]、加速鲁棒特征(speeded up robust features,SURT)[7]、方向梯度直方图(histogram of oriented gradients,HOG)[8]、局部二值模式(local binary patterns,LBP)[9]等方法,但由于其一系列繁琐的过程,无法满足实际的应用需求。恰逢此时深度学习进入快速发展阶段,而相较于传统的特征提取方法,卷积神经网络(convolutional neural network,CNN)模拟人类大脑神经元的传输信号方式显著提升了特征提取能力,因此迅速被应用到图像分类领域。卷积神经网络在面部表情识别[10]过程中也有着非常优秀的表现。许多新网络模型的出现更有利于提取特征,常见的网络模型有AlexNet[11]、VGGNet[12]、ResNet[13]等。一般的神经网络方法首先对目标图像进行特征提取,之后再采用全连接方法进行特征分类。Mollahosseini等人[14]提出了一种深层神经网络架构,通过多标准人脸数据集来解决面部表情识别问题。Chen 等人[15]提出了一个基于差分卷积神经网络的两阶段框架,来解决面部表情图片不平稳特征问题。Zhang等人[16]提出基于静态图像的双通道加权混合深度卷积神经网络(WMDCNN)和基于图像序列的双通道加权混合深度卷积长短期记忆网络(WMCNN-LSTM),分别用于静态图片以及动态序列。Chang等人[17]根据测试样本的复杂性,将每个测试样本分配给相应的分类器来解决面部表情数据不平衡问题。Krithika等人[18]基于图的特征提取和混合分类方法(GFE-HCA)来有效地识别人类的情绪。Pham等人[19]将无处不在的深度残差网络和类似Unet的架构相结合,产生了一个残差掩蔽网络,使其能够专注于相关面部表情信息以做出正确的决策。然而,上述的大多数方法对面部表情识别的关键特征关系以及空间位置联系少有关注,显现不出模型的鲁棒性。
区分表情的因素多为人脸中细微的变化,如何更有效地捕捉空间特征信息,对提高表情识别的精度具有至关重要的作用,因此提出稀疏多层感知机的空间特征感知机制,这是一种无注意力网络结构,对于空间姿态的关注度尤为明显。除此之外,常规的卷积神经网络在面对面部表情图像中复杂的空间关系和特征信息时,不能建立有效特征提取和映射模型,相比之下,胶囊网络[20]弥补了CNN 无法处理图片位置方向等缺点,更符合人类认知过程。胶囊网络以位置向量代替标量输出的网络架构,使用独特的非线性激活以及动态路由更新算法代替原本的全联接方法进行特征分类,保留各显著特征之间的位置关系,增强模型的鲁棒性。因此,本文对胶囊网络进行一定程度的优化,设计出一种sMLP-CapsNet网络模型,sMLP(spare multilayer perceptron)以及胶囊网络均对空间信息较为敏感,而且采用sMLP相较于原本的MLP只需要很少的网络参数量便能关注表情识别各个特征之间的位置映射,提升表情识别的分类精度。实验证明本文方法可以得到更好的结果。
1 胶囊神经网络
胶囊网络中的Capsule类似于人类大脑中的Capsule,对目标的位置、尺寸等信息的处理极其有效,更加适应于不同场景下的检测环境,可以得到更加高效的辨识效率。胶囊网络结构相较于一般的卷积神经网络,采用了向量的输入输出方式代替原本的标量输入输出,这样做可以更好地保留各显著特征之间的位置关系。参数的更新方式是Routing-by-Agreement 原则,而不是卷积神经网络的反向传播更新参数。因此胶囊网络能更多地“理解”图像,通过胶囊可以建立图像三维关系,输出的向量还能反映图像的状态等,相比于卷积神经网络,即使学习的数据量很少也能达到很好的效果。
CapsNet 如图2 所示,由编码器和解码器两部分组成。编码器由卷积层、主胶囊层以及数字胶囊层构成,后三层由三个全连接层构成解码器。编码器结构的卷积层是整个CapsNet结构的第一层,就是常规的卷积操作,其作用是进行图片的高层次特征提取,训练网络的过程就是改变卷积核的权值,使得卷积核可以提取分类所需要的特征信息;主胶囊层是在胶囊内进行卷积操作,提取输入的多维实体特征后进行拼接;数字胶囊层使用动态路由算法进行权值更新,映射到最终的输出空间上。解码器相当于重构图像,就是把训练出的类别重新构建出实际图像,其实现方式是将Capsule 的输出向量用作重构网络的输入,经过三个全连接层重构解码出完整的图像。

图2 胶囊网络结构Fig.2 Capsule network structure
CapsNet 的训练过程分为三个步骤,图3 是胶囊网络的算法结构。

图3 动态路由算法Fig.3 Dynamic routing algorithm
参数ωij通过反向传播算法进行更新,对输入向量利用矩阵ωij相乘,得到浅层胶囊,这一步是通过矩阵ωij来映射低层特征与高层特征的相对关系,即通过这些低层次的特征可以组成一个什么样的图,后续来判断其属于哪一类;
通过对进行加权相加得到sj,耦合函数cij通过softmax()函数计算,这里是用来衡量低层胶囊的特征对高层胶囊特征的重要程度,比如说一张图像的嘴巴更能反映这张图所属的类别,那么权重cij就会大一些。这里的参数bij初始为0,然后通过利用浅层输入向量和实际输出向量νj的一致性进行更新,当两个向量同向时即代表二者相似度较高,当前的低层特征更能反映图像特征,此时乘积为正,bij权重增加,表示当前低层胶囊更被高层胶囊所接受;相反乘积为负时,表示底层胶囊更容易被高层胶囊所排斥。通过这样的权重更新方式建立起了低层特征与高层特征的关联,使模型能更好地理解图像。
最后利用squash函数非线性变化,得到深层胶囊向量νj。图片分类的概率用输出向量的模长表示,模长越大代表图片属于这个类的概率越大。
2 基于sMLP的面部表情识别方法
2.1 sMLP网络模块
Tang 等人[21]基于MLP 的视觉模型,构建了一个称为sMLPNet的无注意网络,使用稀疏连接和权重共享设计sMLP模块。如图4所示,相较于原始的MLP(a)深色令牌与其他所有令牌交互的方式,sMLP(b)中的令牌只需要与其同行同列位置的令牌交互,当sMLP执行两次时就可以实现与所有其他蓝色令牌的交互。对于一张2D 图像,sMLP 沿高度或者宽度应用1D MLP,并且参数在行或列之间共享。

图4 两种令牌交互方式Fig.4 Two tokens interaction mode
sMLP 处理相较于MLP 大大减少了模型训练参数以及计算复杂度,改善了MLP 常见的因参数量过大产生的过拟合问题。除此之外sMLP 无注意力网络对面部表情空间姿态信息表现尤为突出,提升了模型对面部表情的分类能力。
通过稀疏连接,sMLP 大大减少了模型参数以及计算复杂性,首先避免了常见的MLP过拟合的问题,其次sLMP 注意到空间信息对表情识别的帮助尤为明显。sMLP网络结构如图5所示,由三个分支组成,第一个分支对水平方向的信息进行混合,中间分支为输入的自我映射,第三个分支对垂直方向的信息进行混合,在分支末端将分支信息拼接混合,再进行卷积处理后获得最终输出。

图5 sMLP块结构Fig.5 sMLP block structure
本文使用H×W×C表示token 的输入,在水平混合路径将输入重塑为(HC)×W,多层感知器集中于对W的处理,然后被应用到HC进行信息混合;在水平混合路径将输入重塑为(WC)×H,多层感知器集中于对H的处理,然后被应用到WC进行信息混合;最后与输入的自我映射进行拼接。此过程可表示为:
2.2 sMLP-CapsNet网络结构
本文在胶囊网络的基础上提出了一种面部表情识别模型sMLP-CapsNet。该模型可以精准地获取面部图片的整体特征和局部特征,然后使用胶囊考虑对象的空间位置信息,进而实现分类预测的目标。sMLP-CapsNet模型的网络结构如图6 所示。sMLP-CapsNet 模型前半部分特征提取部分,相比于原始的胶囊网络结构多出的卷积层结构更加容易提取目标的主要特征信息,有助于面部表情识别。sMLP-CapsNet 模型后半部分,通过三个全连接层使用面部胶囊层的输出作为输入,提取的有用特征用来重构图像。

图6 sMLP-CapsNet网络结构Fig.6 sMLP-CapsNet network structure
sMLP-CapsNet 使用标准的224×224 像素图片作为网络结构的输入。首先第一部分类似于ResNet的前几层,用于提取目标特征,通过一系列的卷积池化来提取面部的轮廓等整体特征以及局部特征,包括面部的鼻子、眼睛、嘴巴等局部特征以及面部表情的细微特征,每层卷积之后使用ReLU 激活函数把激活的神经元特征保留。sMLP-CapsNet 模型的第二部分是sMLP 的主要模块,通过第二层对第一层输出的宽和高分别采用多层感知机有效地关注表情特征的空间关系。最后经过第三层的1×1 卷积进行跨通道聚合减少参数量。sMLPCapsNet 模型的第三部分属于主胶囊层和数字胶囊层,其使用卷积后的操作作为本层的输入,使用9×9卷积获得32通道维度为16的胶囊特征向量。网络的第五层属于面部表情胶囊层(FERCaps),其使用特征胶囊的输入输出7个胶囊,每个胶囊大小均为1×7,代表7种基本面部表情。
sMLP-CapsNet使用向量输入输出保留各显著特征之间的位置关系。通过输入输出之间的关联性,使用动态路由算法更新权值更新,最终输出模值的大小代表每一个分类的类别。此外,sMLP-CapsNet 模型网络使用3 个全连接层分别输出512、1 024 和150 528 个神经元,通过重构把训练出的类别重新构建出实际图像,150 528神经元等于3×224×224的重构图像。
3 实验与分析
3.1 实验环境
神经网络的训练运算最多的就是关于矩阵的运算,而GPU 本来在图形处理方面就具有优越的性能,其并行处理矩阵运算的高效性就自然而然地运用到了深度学习过程中。实验使用的机器配置为:64 位的Win10操作系统,CPU 为Intel Core i5-12400F,内存64 GB,GPU 使用11 GB 显存的NVIDIA GeForce RTX 2080 Ti训练,在python3.9中使用Pytorch模块搭建训练网络。
3.2 实验数据集
人脸表情公开的数据集已经有很多满足实验与研究的需要,本文使用CK+公开实验数据集和RAF-DB真实世界数据集,下面对这两个数据集进行介绍。
3.2.1 Extended Cohn-Kanade Dataset(CK+)
CK+面部表情数据库是由12~30岁年龄段的123个参与者的593 张图片序列组成,其中包括欧美人、非裔美国人以及其他人种,包括自发表情和摆拍的7种基本表情,图片的像素大小分别为640×480 以及640×490。实验中提取有标签的327个视频序列的后3帧共981张图片作为实验数据集,各类表情部分图片如图7 所示。本文剔除了背景对实验的影响,只保留其面部的数据,处理之后图片大小为48×48,训练集和测试集两者比例设置为8∶2。

图7 CK+面部表情数据集部分图例Fig.7 Partial legend of CK+facial expressions dataset
3.2.2 Real-World Affective Faces Database(RAF-DB)
RAF-DB 是一个大规模的面部表情数据库,包括3万张真实世界的图片,本文使用具有7类基本情绪的图像用于实验。实验数据包括12 271 张训练图像数据以及3 068 张测试图像数据,各类表情部分图片如图8 所示。本文分别在随机旋转图片角度、图片随机竖直偏移、剪切强度、图片随机水平偏移、随机缩放、亮度调节等方面对训练数据进行扩增,即每张图片扩增为原来的6倍。

图8 RAF-DB面部表情数据集部分图例Fig.8 Partial legend of RAF-DB facial expressions dataset
3.3 实验参数与设置
本文提出的网络模型从初始化阶段到训练阶段参数如表1所示。初始阶段偏置设置为0,使用Adam进行权值更新,将其平滑参数β1和β2分别设置为0.9和0.999,ε为1.0×10-8,避免除数为0,epoch 设置为50,batch_size设置为128,即每次读入128张图片进行批处理。
3.4 实验结果与分析
为了进一步验证本文方法的有效性,将本文方法与未改进的网络进行消融实验。将ResNet34的前16层与CapsNet相级联的网络模型,以及在ResNet34与CapsNet中间加入sMLP的sMLP-CapsNet,在CK+数据集和RAFDB 数据集上分别训练50 epoch 后,在测试集上得到的消融实验结果如表2所示。

表2 模型在CK+和RAF-DB数据集上的消融实验Table 2 Ablation experiments of models on CK+and RAF-DB datasets
从表2中可以看出,将ResNet34的前16层与CapsNet相级联的网络模型,在数据集CK+和RAF-DB上分别得到了97.41%以及84.48%的精度。通过上述消融实验可以看出,本文提出的改进方法,在CK+数据集上提升2.07 个百分点,在RAF-DB 数据集上提升1.21 个百分点,表明本文提出的方法存在一定的合理性。
本文使用模型计算力(FLOPs)和参数(Parameters)对网络模型的复杂度进行评判。FLOPs 是浮点运算次数,用来衡量模型的计算复杂度。计算FLOPs实际上是计算模型中乘法运算和加法运算的次数,即时间复杂度。Parameters 是指网络模型中需要训练的参数总数,即空间复杂度。与经典深度学习方法复杂度对比如表3所示,即使与基础的神经网络模型相比,本文方法除了DenseNet的FLOPs以及Parameters相差不大外,相比于其他方法,模型计算量以及参数量均大幅度地缩小。与深度学习方法复杂度对比如表3所示,即使与基础的神经网络模型相比,本文方法只和DenseNet 的模型计算量和参数量相差不大,与近两年的方法相比,RUL[22]使用ResNet18为基础网络,因此模型计算力相对较小,但参数量依旧大于本文方法;与EAC[23]相比模型计算量以及参数量均大幅度地缩小。总体来说本文方法的FLOPs以及Parameters均控制在极低的范围。
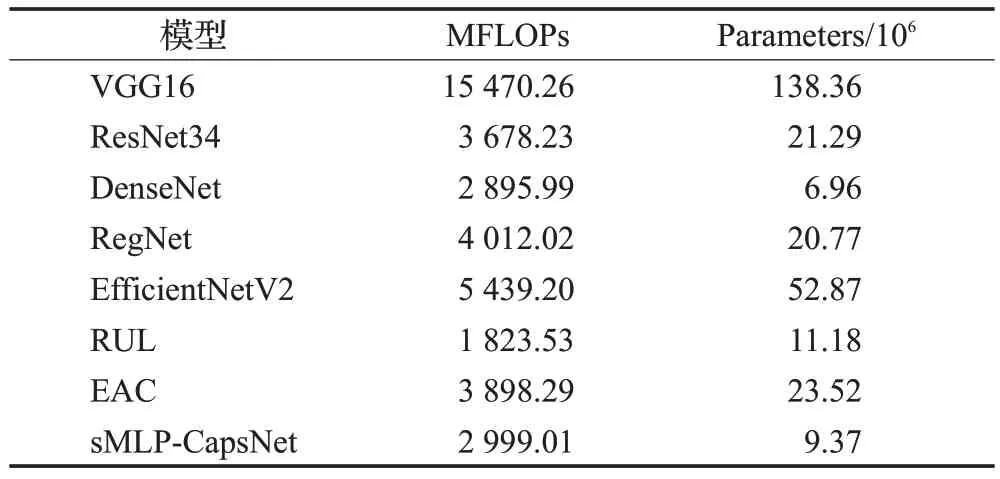
表3 支撑实验Table 3 Support experiment
算法性能精度影响因素有sMLP块的插入位置、插入数量(插入单组sMLP、连续插入两组sMLP),以及胶囊网络动态路由循环次数。表4 是插入位置以及数量的结果显示,可以看出,在循环3 次以及在Conv3_x 后面插入一个sMLP块可以达到最优的表现。
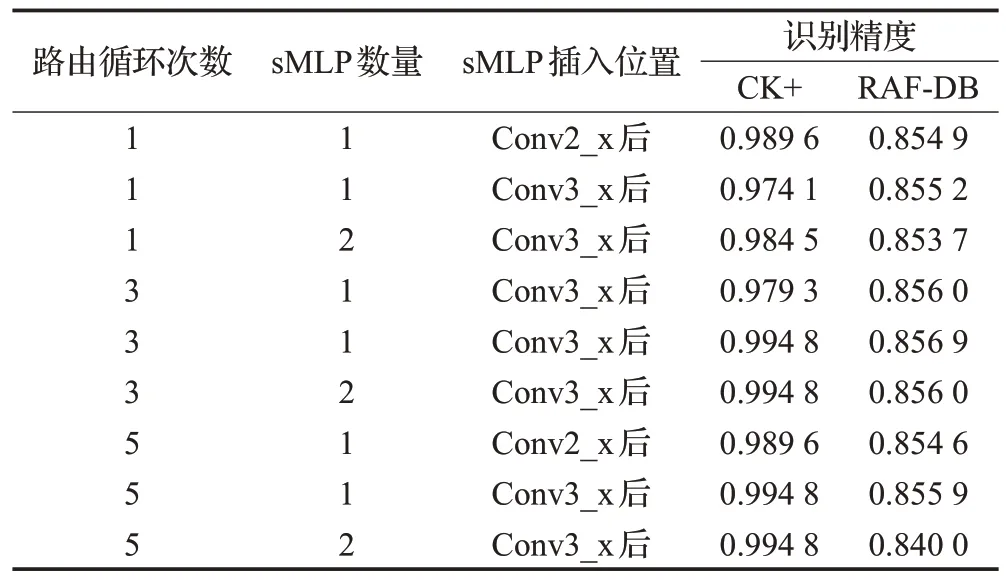
表4 影响算法因素Table 4 Factors affecting algorithms
为了对比CapsNet 与sMLP-CapsNet 对各个表情的识别情况,本文绘制了RAF-DB测试集以及CK+测试集的混淆矩阵。混淆矩阵横轴代表每一类的真实标签,纵轴代表预测标签。为了更直观地预测不同表情的准确率,对混淆矩阵进行了归一化处理。
从图9 以及图10 的RAF-DB 测试集的混淆矩阵可知,改进后的网络模型在惊讶、快乐、悲伤和中性表情上的识别精度都有显著的提高,但在其他表情类别上效果表现不佳。改进后的网络模型相较于改进前在RAF-DB数据集上精度提升了1.21个百分点,证明了本文方法的有效性。
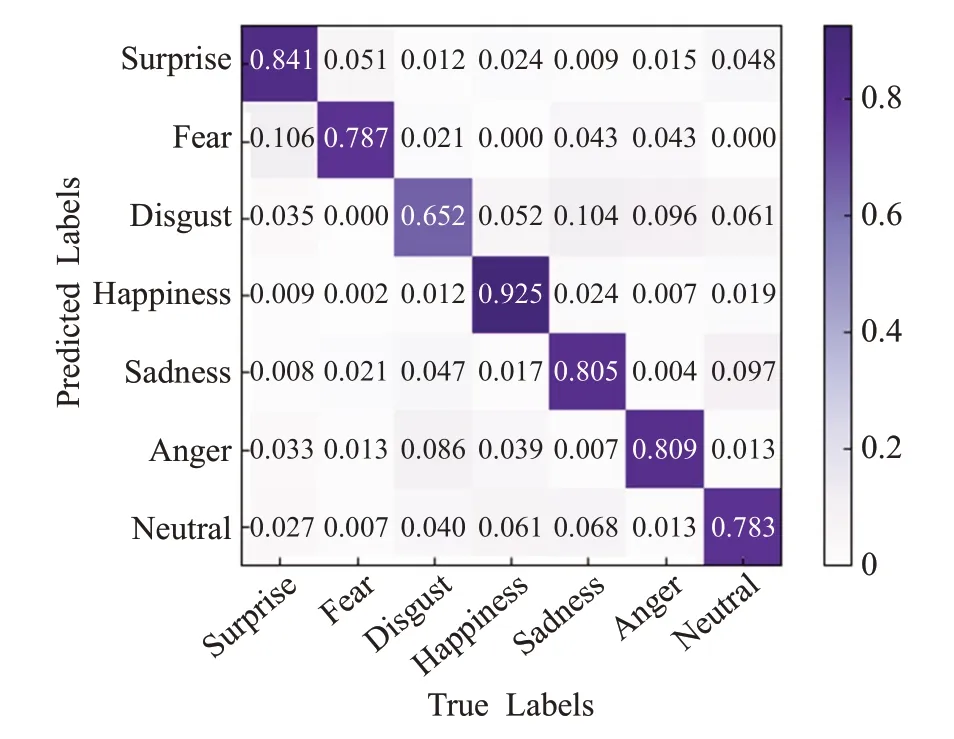
图9 RAF-DB数据集上CapsNet的混淆矩阵Fig.9 Confusion matrix of CapsNet on RAF-DB dataset

图10 RAF-DB数据集上sMLP-CapsNet的混淆矩阵Fig.10 Confusion matrix of sMLP-CapsNet on RAF-DB dataset
从图11 以及图12 的CK+测试集的混淆矩阵可知,改进后的网络模型在愤怒、藐视、悲伤等表情上的识别精度也有所提高,证明了本文方法也拥有一定的泛化性能。

图11 CK+数据集上CapsNet的混淆矩阵Fig.11 Confusion matrix of CapsNet on CK+dataset
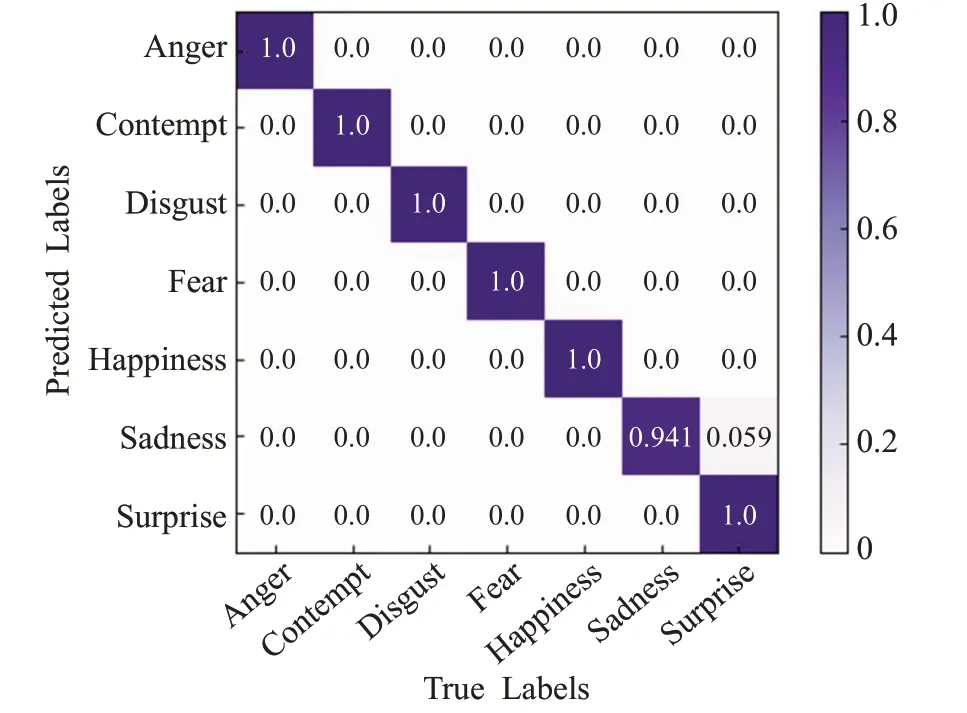
图12 CK+数据集上sMLP-CapsNet的混淆矩阵Fig.12 Confusion matrix of sMLP-CapsNet on CK+dataset
通过实验结果可以明确本文模型在面部表情识别任务中能够获得最优的识别效果。为了验证模型训练结果的有效性,在模型进行训练的过程中保存训练日志,训练结束后对日志数据进行可视化,训练情况如图13所示。

图13 模型的损失函数以及精确率Fig.13 Loss function and accuracy of model
将本文方法与几种典型的表情识别算法在CK+和RAF-DB 数据集上的识别率进行比较,得到的结果如表5 所示。与典型的表情识别算法相比,本文提出的sMLP-CapsNet 网络模型识别精度为99.48%和85.69%,均得到了较好的结果。从实验分类结果以及对比其他经典方法可以看出,本文方法可以通过更好的方法保留图像特征的位置信息来提升图像分类准确率,使得最终的准确率提升明显。

表5 本文模型与其他方法在CK+和RAF-DB数据集上识别率对比Table 5 Comparison of recognition rates of this paper model and other methods on CK+and RAF-DB datasets
4 结束语
本文在胶囊神经网络基础上进行改进和优化,提出了基于优化胶囊网络的面部识别模型sMLP-CapsNet。通过优化胶囊神经网络关注面部表情的空间信息,从轮廓到细节来提取面部表情图片特征,在CK+数据集和RAF-DB数据集上实验结果的精度提升效果明显,展现了本文方法的先进性。未来通过使用视觉形式以及非视觉形式融合的方式,如关注语义特征等更深层次的特征来提升模型的泛化能力,是值得关注的问题。除此之外,如今很多模型在光照、遮挡、背景信息以及面部姿态等复杂环境下的表情识别效果不尽如人意,复杂场景下表情识别也是未来的研究重点。
