在线课程推荐系统综述
2023-11-27刘星雨杨佳琦陈国华贺超波
余 鹏,刘星雨,程 颢,杨佳琦,陈国华,贺超波
华南师范大学 计算机学院,广州510631
在线课程是指依据特定的教学目标,按一定的教学策略组织教学内容[1],通过移动互联网技术为学习者构建的网络课程。常见的MOOC、微课、SPOC[2]及线上开放课程等都属于在线课程。
在线课程不受时空限制,可以在有限的环境条件下完成学习,便于开展相关教学活动。根据中国互联网络信息中心(CNNIC)发布的第50 次《中国互联网络发展状况统计报告》,截至2022年6月,各大在线课程学习平台的学习者规模已达3.77 亿[3]。此外,国家大力支持教育信息化,在《教育信息化2.0 行动计划》文件中提出构建一体化的“互联网+教育”平台、整合各级各类教育资源公共服务平台和支持系统、建成国家数字教育资源公共服务体系[4]的要求。在《“十四五”国家信息化规划》文件中提出加快建设中国教育专用网络和“互联网+教育”大平台,推动优质教育资源开放共享[5]。还有在《教育部办公厅关于实施一流本科专业建设“双万计划”的通知》中指出要引领带动高校优化专业结构,促进专业建设质量提升,推动形成高水平人才培养体系[6]。上述文件的提出推动了在线课程学习平台的快速发展。目前国内有学堂在线、中国大学MOOC和网易云课堂等平台,国外则有Coursera 等平台,这些平台提供了数万门课程,为上千万国内外学习者提供在线学习服务。
在线课程平台处在高速发展中,但仍然存在一些问题需要解决,其中最突出的是“课程过载”。一方面,课程信息的爆炸式增长使得学习者被大量无关的课程信息所困扰,导致他们难以找到适合自己的课程;另一方面,平台很难为所有学习者提供个性化学习资源服务,导致学习者学习兴趣减弱以及平台用户流失。为解决上述问题,研究人员将推荐系统引入在线课程平台,提出在线课程推荐。在线课程推荐是指通过研究学习者的学习兴趣和历史选课行为以及课程属性等信息,向学习者推荐其可能感兴趣的课程,从而有效缓解“课程过载”问题,提升学习者的学习体验[7]。
在线课程推荐系统的核心部分是高效的推荐方法,因此已有研究的重点都集中于推荐方法。经典推荐算法如协同过滤[8]等在实际应用中存在着冷启动和灰群体等问题。随着近年来智能信息处理技术的快速发展,在线课程推荐方法的研究迎来了新机遇,随之提出基于智能信息处理的方法。如基于图神经网络的推荐方法[9]利用上下文信息更好地理解学习者的行为背景和偏好,从而提供更准确的推荐结果;基于知识图谱的推荐方法[10]融合了大量的领域知识,使得推荐系统能够更好地了解学习者需求并提供更精准的推荐结果;基于异质信息网络的推荐方法[11]能够整合多个不同类型的数据源,更全面地描述学习者和课程的特征和关系用于推荐。这些方法能够更好地获取学习者和课程的相关信息,进而完成推荐。
尽管目前已有在线课程推荐系统的相关综述,如文献[12-13],但它们只涉及传统理论和方法,对于最新的理论和方法并未进行深入总结分析,也没有整理和提供相关数据集。因此仍有必要对在线课程推荐系统的相关工作进行系统梳理和总结,为研究人员提供有价值的参考和指引。本文从推荐方法的角度对当前最新的在线课程推荐进行归纳总结,主要内容包括:(1)给出系统通用框架,归纳在线课程推荐系统的基本定义;(2)按不同原理对相关推荐方法进行分类;(3)介绍在线课程推荐系统的评价指标,整理相关数据集;(4)根据当前方法存在的问题,对未来在线课程推荐发展趋势进行展望和总结。
1 基本框架及相关概念
本文提出一个通用的在线课程推荐框架,如图1所示。在线课程推荐系统主要由学习者、课程和推荐方法三部分组成。学习者部分和课程部分主要包括学习者和课程的相关信息以及特征。推荐方法通过分析学习者特征与课程特征,从而向目标学习者推荐需要的课程。相关概念的详细介绍如下:

图1 在线课程推荐系统基本框架Fig.1 Basic framework of online course recommendation system
(1)学习者:即课程推荐系统的目标用户,可以进行浏览、搜索和学习课程等操作。学习者是课程推荐系统的使用者,也是重要的数据来源,为后续优化推荐方法提供反馈信息。
(2)学习者特征:是学习者的属性和相关特征信息,主要包括学习目标和需求、历史学习信息、学习风格、学习进度等。这些特征用于课程推荐,是推荐方法的重要特征来源。
(3)课程库:在线课程系统中所有网络课程以及相关资源,主要包括课程视频、电子教材、教学课件、作业等。课程库中的课程是在线课程推荐系统的推荐对象。
(4)课程特征:是课程库中课程的属性和相关描述信息,主要包括课程的内容、主题领域和开课学期等。提取的课程特征可以通过推荐方法来实现满足学习者需求的课程推荐。
(5)推荐方法:通过学习课程特征和学习者特征,对相关特征进行匹配,推荐给学习者可能感兴趣的课程。
形式上,在线课程推荐系统可以定义为:设所有学习者的集合为S,所有课程的集合为C,函数f表示学习者s对课程c的感兴趣程度,最符合学习者s偏好的推荐课程集合为C′,即f:S×C→R,其中R表示非负实数的有限序列,将使函数f取得最大值的课程推荐给学习者,如下所示:
2 方法分类
随着推荐方法的不断发展,被应用于在线课程的推荐方法也趋于多样化。本文基于不同的推荐方法,将在线课程推荐方法分为基于关联规则挖掘的方法、基于矩阵分解的方法、基于概率模型的方法、基于深度学习的方法、基于智能优化的方法、基于语义计算的方法以及基于联合建模的方法。主要方法介绍如图2所示[14-70]。

图2 在线课程推荐系统主要方法Fig.2 Main methods of online course recommendation system
2.1 基于关联规则挖掘的方法
关联规则挖掘起源于购物篮分析,其中使用最普遍的方法是Apriori。Apriori 方法在课程推荐中重点关注课程和学习者之间的关联。Tang[14]考虑每个学习者的兴趣,根据其他学习者的学习情况,自动找到相似的学习者后对课程应用Apriori方法来创建课程关联规则完成推荐。对于包含选课记录和就业情况的数据,Liu 等人[15]提出将Apriori方法应用于选修课推荐,将学习者的选课记录和就业情况作为一个事务处理,利用Apriori方法给出选课与就业之间的强关联规则来处理相关数据,最终推荐对学习者就业有利的课程。Fauzan等人[16]提出将Apriori 方法与聚类方法结合,对每个学习者进行聚类操作,应用Apriori生成相关课程关联规则示例,通过该规则进行评分并推荐。为了处理海量数据,Zhang 等人[17]提出基于Apriori 方法的分布式关联规则挖掘方法,利用Hadoop和Spark等大数据处理技术将学习者的行为日志归纳为学习者的行为数据,通过Apriori关联规则在相关数据中发现学习者与课程间的关系,最终实现推荐。
总体来说,上述基于Apriori 关联规则挖掘的推荐方法不仅有效提高了课程推荐的效率,而且具有较高的可解释性。然而,现存的方法大多仅利用一种Apriori关联规则来进行课程推荐,忽略了部分数据之间的关系。因此,在未来的研究中可以结合多种关联规则算法和多样化关联规则度量指标来完成课程推荐。
2.2 基于矩阵分解的方法
矩阵分解(matrix factorization,MF)在课程推荐方面首先构建学习者-课程评分矩阵,随后将评分矩阵分解为两个低秩矩阵,最终预测学习者对相关课程的评分从而完成课程推荐。目前MF 在课程推荐方面的主流方法有SVD++、广义矩阵分解和概率矩阵分解等。
SVD++在奇异值分解方法(singular value decomposition,SVD)的基础上融入学习者对课程的隐式行为,提高推荐准确性。Malhotra 等人[18]使用SVD++得到学习者尚未选择的课程列表和已经选择课程的学习者列表,通过预测学习者在这些课程中的分数来完成推荐。为引入学习者未来工作所需的技能信息,Symeonidis等人[19]利用SVD++获取学习者信息,将学习者对课程的偏好信息、课程的内容特征与技能信息结合,设置学习者-课程矩阵、课程-技能矩阵以及学习者-技能矩阵,提高推荐性能。其中SVD++方法预测学习者对课程评分为:
其中,N(u)表示一个课程集合,yki表示学习者已经显示出对N(u)中课程i的隐式偏好,μ是所有评分的平均值,bui和bvj表示观察到的学习者u和课程v的平均值的偏差。
广义矩阵分解(generalized matrix factorization,GMF)在矩阵分解的基础上对输出结果进行规范化,将最终输出值限制在0~1 范围内。对于处理具有时间序列的数据,Guo 等人[20]将GMF 与长短时记忆模型结合,利用GMF 表示课程数据特性,采用长短时记忆模型来处理时间序列的真实学习数据,提高推荐准确性。此外概率矩阵分解(probabilistic matrix factorization,PMF)结合概率模型与矩阵分解算法,通过考虑评分的分布特性,达到更好的推荐性能。Li 等人[21]结合PMF 与云模型,PMF假设数据的潜在分布,解决过拟合问题,通过云模型计算两个学习者之间的相似度,实现课程推荐。
基于矩阵分解的方法可以学习到学习者和课程之间的隐式关系,不仅解决了数据稀疏性,同时具有较高的可解释性。但是现存的方法也存在诸如冷启动和计算复杂度高等问题。上述方法中SVD++可以结合局部信息和整体信息,但解决冷启动问题的能力有限;而GMF 对于冷启动问题的解决优于SVD++,并且具有较高的可扩展性,但因为结合了神经网络的相关方法,使得可解释性相对较弱;PMF则是通过概率建模来处理课程与学习者之间的关系,但可扩展性较差。在未来的研究中可以结合其他先进的方法对矩阵分解进行改良,使得课程推荐模型具有更高的效率和准确性,并有效缓解冷启动困境。
2.3 基于概率模型的方法
概率模型(probabilistic models,PM)是利用概率理论建立的统计模型,在课程推荐方面对学习者或课程进行概率建模,利用概率值进行课程推荐。对于处理具有时间属性的信息,Lan 等人[22]通过对学习者的学习时间以及历史评论信息等属性进行概率建模,利用课程主题下新帖子引发兴趣随时间衰减的速度进行课程建模,匹配相关属性信息进行推荐。Morise 等人[23]使用贝叶斯模型,提取评价过大量课程的学习者数据和被学习者评价过的课程数据,计算已知学习者和其余学习者间的相似度来生成推荐课程序列。Alaoui 等人[24]使用主题建模和LDA(latent Dirichlet allocation)来进行课程推荐,主题建模用于分析课程数据,发现课程之间存在的交叉主题词以及这些主题词之间如何相互关联,最后使用LDA进行主题分类来提高推荐效果。
综上,基于概率建模的课程推荐方法具有良好的特征选择能力,可以自动选择对预测任务最相关的特征。与矩阵分解方法相比,概率建模的泛化能力更强。然而,相关方法对数据的分布和假设有很高的要求,直接影响着方法的性能。因此未来可以在数据处理方面进行研究并用于概率建模推荐。
2.4 基于深度学习的方法
深度学习是近年来计算机科学领域最重要的发展领域,基于深度学习的在线课程推荐方法不断被提出,主要分为基于卷积神经网络的方法、基于图神经网络的方法、基于递归神经网络的方法、基于自动编码器的方法。
2.4.1 基于卷积神经网络的方法
卷积神经网络(convolutional neural network,CNN)是由卷积层、池化层、全连接层等组成的深度学习模型。在课程推荐系统中,CNN 用于学习学习者和课程的表示向量。Ma[25]利用CNN 构建学习者偏好模型,通过分析课程之间以及学习者之间的关系分别获得相关特征,处理学习者和课程特征之间的关系完成推荐。对于处理考虑情感等因素,Chanaa[26]组合多个CNN 构建图预测器(式(3)),包括查询CNN 和关键CNN,获取课程特征之间的交互,通过学习者对课程的态度、困惑程度以及难度等因素对课程进行建模,完成学习者模型之间的交互并实现推荐。对于处理课程文本信息,Yuhana等人[27]提出结合CNN与Word2Vec的方法,利用Word2Vec将课程文本信息转换为矩阵,将结果输入CNN 产生分类输出,通过自适应学习完成推荐。Ezaldeen 等人[28]则提出了一个增强型电子学习混合推荐系统ELHRS,将基于CNN的细粒度情感分析模型视作课程推荐的一部分,并预测关于某个特定学习资源的文本评论的评分,最终提供给学习者其领域和偏好相关的最高预测评级的电子学习资源和课程。为利用隐含特征,Sheng 等人[29]将CNN 与元路径结合,通过设计一系列不同的元路径来获取学习者与课程间的隐含特征,利用CNN 来处理序列并给定元路径,提高推荐效率。
为获取更为准确的学习者或课程的特征信息,研究者结合了CNN 与注意力机制进行特征提取。Wang 等人[30]使用基于注意力的CNN,获取学习者在一门课程中的偏好和学习者在在线学习中的长期偏好,然后利用注意力机制,根据估计得分与实际得分之间的差异进行改进并用于推荐。尽管上述方法在课程推荐方面有一定效果,但仍然存在特征提取不完整的问题。基于上述问题,Zhu[31]提出了结合CNN 与双层注意力机制,第一层与CNN结合构建子网络,使CNN能够学习课程的关键属性;另一层以学习者和网络课程特征向量为输入数据,利用注意力机制为学习者的历史交互课程分配个性化权重。结合了双层注意力机制的方法在相关指标上优于只使用单层注意力机制的方法。
上述基于CNN的方法均可以自动学习数据中学习者和课程的局部特征,继而从这些抽象的局部特征中学习到更多的特征,提高模型的性能。然而现存的使用CNN的课程推荐方法在训练过程中涉及大量矩阵乘法和卷积运算,具有较高的计算复杂度;此外基于CNN的方法可解释性较差。因此将来可以结合可解释性较强的方法来进行推荐。
2.4.2 基于图神经网络的方法
图神经网络(graph neural network,GNN)是一种将相关数据建模成图结构并利用神经网络进行处理的深度学习模型。在课程推荐方面,构建学习者-课程图,表示学习者和课程的关系,通过引入卷积操作构成图卷积网络(graph convolutional network,GCN)学习节点表示。Li[32]提出适用于英语课程推荐的模型,设计包含不同数量和不同大小卷积核的多尺度GCN层,通过GCN层进行课程和学习者节点特征提取,将学习者交互内容与节点表示相结合进行推荐。Huang 等人[33]提出基于GCN 的学生选课推荐模型,首先将学习者和课程之间的交互建模为学习者-课程图,然后利用多模态知识图谱来描述课程的辅助信息,最后利用GCN 传播节点邻居的嵌入信息,聚合学生和课程的表示,输出预测推荐分值。为解决此前GCN模型中存在的过度平滑和解崩溃等问题,Zhou等人[34]提出层次细化的GCN模型,图中的X表示节点嵌入,将可学习的权重放在层嵌入上进行节点更新,按照程度敏感概率修剪一定比例的学习者-课程交互图的边,使其稀疏化,提升推荐性能。
由于注意力机制可以将模型注意力集中在输入数据的特定部分,更好地捕捉关键信息,研究人员将注意力机制与GNN结合用于课程推荐。Wang等人[35]将GNN与Top-N个性化推荐结合,应用注意力机制来生成嵌入表示,通过GNN获取学习者特征,将学习者特征和课程特征进行处理,利用Top-N方法得到得分较高的前N个课程进行推荐。为得到更多的学习者和课程特征用于推荐,Wang等人[36]提出基于超图的推荐方法HGNN,将学习者表征的学习任务转化为超边的嵌入,通过改进的注意力机制学习课程的表示(式(4)),利用GNN对课程信息进行传播和聚合,最终实现推荐。为处理学习者和课程之间的隐藏关系,Wang等人[9]设计多个包含语义关系的元路径来引导学习者偏好在GNN 中的传播,使用注意力机制强化影响学习者偏好的因素。通过设计元路径,寻找学习者与课程之间的隐含关系并进行处理,利用矩阵分解预测评分来完成课程推荐。考虑到学习者的课程学习之间存在先修关系,Chen等人[37]提出基于GCN的推荐方法GADN,利用GCN抽取学习者-课程的交互与课程序列信息,考虑学习者或课程及其邻居节点作为抽取建模的重点。运用注意力机制模拟学习者的学习过程,计算课程间相似度来完成推荐任务。
其中,attention(·)是用来计算节点之间相关性的映射;表示课程的嵌入;wio表示权重。
GNN在课程推荐方面的优势在于能够在学习过程中融合全局和局部的图结构信息,从而学习到更为准确的特征。并且该方法的泛化能力和可扩展性强,有利于处理新任务。但该方法也存在一定的缺陷,如当图结构发生变化时,GNN需要重新学习模型参数,无法直接应用于新的图结构。
2.4.3 基于递归神经网络的方法
递归神经网络(recurrent neural network,RNN)是将当前输入与上一时刻的隐藏状态合并作为输入,不断传递隐藏状态进行计算,处理序列数据,在课程推荐中RNN用于处理具有时间属性的数据[38]。Zhang等人[39]使用RNN进行推荐,考虑课程之间存在先修关系,首先利用RNN学习计划中的课程序列(式(5)),然后基于内容的推荐方法从历史注册信息中挖掘课程之间的关系并生成课程建议。
其中,W表示参数矩阵,b表示参数向量,g(·)是激活函数,x<t>代表学生在时间t注册的课程,a表示课程向量。
为对时间信息进行更多操作,研究人员在RNN 基础上提出门控循环单元(gated recurrent unit,GRU)和长短期记忆(long short-term memory,LSTM)模型,在课程推荐中用于学习者建模或学习者与课程之间的关系建模。Li等人[40]提出结合CNN和GRU的课程推荐模型,CNN用于学习风格的检测,GRU用于对学习风格的预测。模型首先通过一系列问题来确定每个学习者学习风格特点,然后根据学习者的特点找到满足学习者学习需求的课程并进行推荐。Saito等人[41]提出基于LSTM的学习路径推荐,首先由包括学习者的试错过程的历史记录构成学习路径,其次通过比较目标学习者的学习路径,找出与目标学习者相似的学习者,最后将LSTM 网络用于前一个过程中得到的学习路径,预测并推荐下一个学习路径,通过输出的概率值来进行推荐。
课程推荐中使用RNN主要是为了处理具有时序关系的数据和变长序列数据,并逐步生成具有结构和连续性的序列数据用于推荐。然而RNN的每个时间步都需要依次进行计算,无法并行化处理,存在计算效率低下等问题。
2.4.4 基于自动编码器的方法
自动编码器(autoencoder,AE)是一种无监督学习的神经网络模型,目的是将输入数据编码为低维度表示,同时尽可能地保留输入数据的信息。在课程推荐中AE 用于提取和降维学习者和课程特征,提高推荐准确性和效率。Zhao 等人[42]提出基于AE 的推荐方法,首先利用AE 的降维优势获取所需的学习者和课程特征向量,然后获取学习者与课程之间的深层信息并得到对应的特征向量矩阵,最终基于学习者对课程的兴趣程度预测分数并进行推荐。Gomede等人[43]提出基于协同过滤和深度AE 的推荐方法,根据每个学习者历史交互信息提供偏好信息,利用深度AE 来预测课程评分稀疏矩阵的缺失值,提高推荐效果。对于含有技能信息的学习者数据,Wang等人[44]提出基于主题建模的变分AE推荐方法,从学习者的技能概要中提取学习者能力的潜在表示,从需求识别机制了解学习者对职业发展的需求,通过变分AE获得具有可解释性的推荐。对于处理含有学习者风格的数据,Mawane等人[45-46]提出基于AE与Kohone网络的推荐模型,利用Kohonen网络映射识别学习风格的相似性,挖掘学习者特征和课程内容属性特征,通过AE对同一组中学习效果最好的学习者的课程列表进行相关预测并推荐。
为了处理具有时序信息的课程数据,文献[47-48]将AE 与LSTM 相结合来提高推荐效率。不同之处在于,文献[47]重点关注通过考虑课程相关性来学习学生的兴趣偏好,文献[48]则利用LSTM 代替了AE 中的前馈神经网络来提取课程数据的时间特性并通过AE处理课程评分数据。从各项评价指标来看,文献[48]提出的方法优于文献[47]的方法。
在课程推荐方面,AE 的优点是可以从高维输入中提取出最相关和有用的特征,从而获取学习者和课程数据的低维特征表示。但存在如学习低维表示时,可能会有信息丢失的问题。
2.5 基于智能优化的方法
智能优化方法又称现代启发式方法,是一种具有全局优化性能且通用性强的方法。近年来属于智能优化的模拟退火算法和遗传算法受到研究人员的广泛关注,并且被应用于课程推荐。
模拟退火方法(simulated annealing,SA)是一种全局组合优化问题的概率局部搜索方法,在课程推荐方面用于参数的优化。Lefranc等人[49]提出基于SA的课程推荐方法,首先通过目标函数获取学习者的偏好,然后通过SA 在复杂搜索空间中逼近全局最优,最终获得一个推荐的课程列表以及一个计划策略。对于学习者想要高GPA 的需求,Gunawan 等人[50]提出基于SA 的课程推荐方法,首先考虑课程的先修关系以及将GPA作为学习者的一个重要属性,然后对已完成课程的成绩进行评估并构建课程序列,最终通过自适应的SA 方法来进行优化并推荐相关课程。
遗传算法(genetic algorithm,GA)是一种启发式算法,通过模拟进化过程来搜索最优解。GA 在课程推荐方面的作用是对课程信息进行处理,从而提升推荐效果,具体操作为:定义基于学习者兴趣的适应度函数;将每个个体表示为一组基因,其中每个基因表示一个课程;根据先前的学习记录生成初始种群;根据适应度函数选择最适合的个体;交叉操作将两个个体的基因组合在一起生成新的个体;变异操作将某些基因随机改变以生成新的个体;重复选择、交叉、变异操作,生成新的种群,直到达到预定的停止条件;生成的个体解码为课程推荐结果。Hssina等人[51]提出将自适应学习与GA相结合,通过上述GA 的相关操作进化出一组解决推荐方案,找到最佳推荐结果并将结果中的课程自动推荐给学习者。Al-Twijri等人[52]提出基于GA的序列模式挖掘模型,通过GA 的交叉操作和变异操作,检查学习者的邻居个体来开发当前学习者个体,最终得到推荐的课程。
综上,SA 和GA 具有以下优点:能避免局部最优解的限制,具有较强全局搜索能力;都有较强的自适应性,可以逐步调整搜索策略,优化推荐结果。此外,SA的可解释性较强,GA的鲁棒性较强,但它们存在着参数设置困难和计算复杂度高等问题。
2.6 基于语义计算的方法
近年来人工智能技术不断发展,属于人工智能技术的语义计算也被广泛应用于课程推荐,主要包括基于本体的方法、基于知识图谱的方法、基于异质信息网络的方法。
2.6.1 基于本体的方法
本体(ontology)是一种形式化的知识表示方式,用来描述特定领域中的概念、实体、属性以及它们之间的关系,在课程推荐中被用于对课程或学习者进行建模。Cheng 等人[53]提出基于本体的推荐方法,根据教学大纲构建知识本体,将相关知识信息进行链接,建立知识本体和视频本体之间的关系,最终利用学习者本体和知识本体进行推荐。为了处理具有学习风格的数据,El Aissaoui 等人[54]提出基于本体的课程推荐方法,建立学习者本体和课程本体,通过基于FSLSM 的学习风格选择模型对学习风格进行匹配并确定学习者的学习风格,最后通过计算本体间的相似度得到满足学习者需求的课程。为进一步提升推荐效果,研究人员提出将本体与语义处理方法结合来进行推荐。Diao 等人[55]提出基于课程本体和学习者认知能力的推荐方法,构建基于课程本体的语义推理规则,利用最大似然估计和联合概率对学习者的认知能力进行动态估计并完成课程推荐。
基于本体的课程推荐方法利用本体来建模领域的结构和语义信息,从而更好地理解学习者需求和课程特性,提高推荐的准确性。但本体的构建和使用缺乏统一的标准和规范,导致不同的课程推荐系统可能采用不同的本体结构和语义表示方式。
2.6.2 基于知识图谱的方法
知识图谱(knowledge graph,KG)的本质是语义网络,通常用(主语,谓语,宾语)这样的三元组来表达事物属性以及事物之间的语义关系[56],在课程推荐方面的主要作用是完成学习者实体与课程实体间的关系描述。考虑课程之间存在时序性,Zhou等人[57]提出结合时间感知转换器和KG 的方法(图3),时间感知器模块考虑课程之间的注册时间间隔,KG 表明课程之间潜在的联系并捕捉其语义关联,利用深度神经网络处理相关信息得到预测候选课程的推荐概率。Zhang 等人[10]提出将KG与异构图结合的方法KGAN,将学习者的行为和课程通过KG投射到一个统一的空间中,缓解课程推荐中交互脆弱、课程相关性获取困难等问题。KGAN通过注意力机制更新候选课程的表示,通过预测模块输出学习者选择候选课程的概率。Wu等人[58]提出KG和Node2vec结合的推荐方法,首先建立一个课程-学习者KG,并用Node2vec得出KG中包含的学习者兴趣,其次计算学习者与课程间的相似度,最后利用得出的相似度得到课程推荐列表。Yang 等人[59]和Xu 等人[60]提出将KG 作为协同过滤的辅助信息源,首先构造基于课程的KG,应用基于KG 的传播和聚合技术来捕捉课程的潜在特征并进行建模,然后计算课程之间的语义相似度,最后将该语义信息融合到协同过滤推荐方法中提高推荐性能。
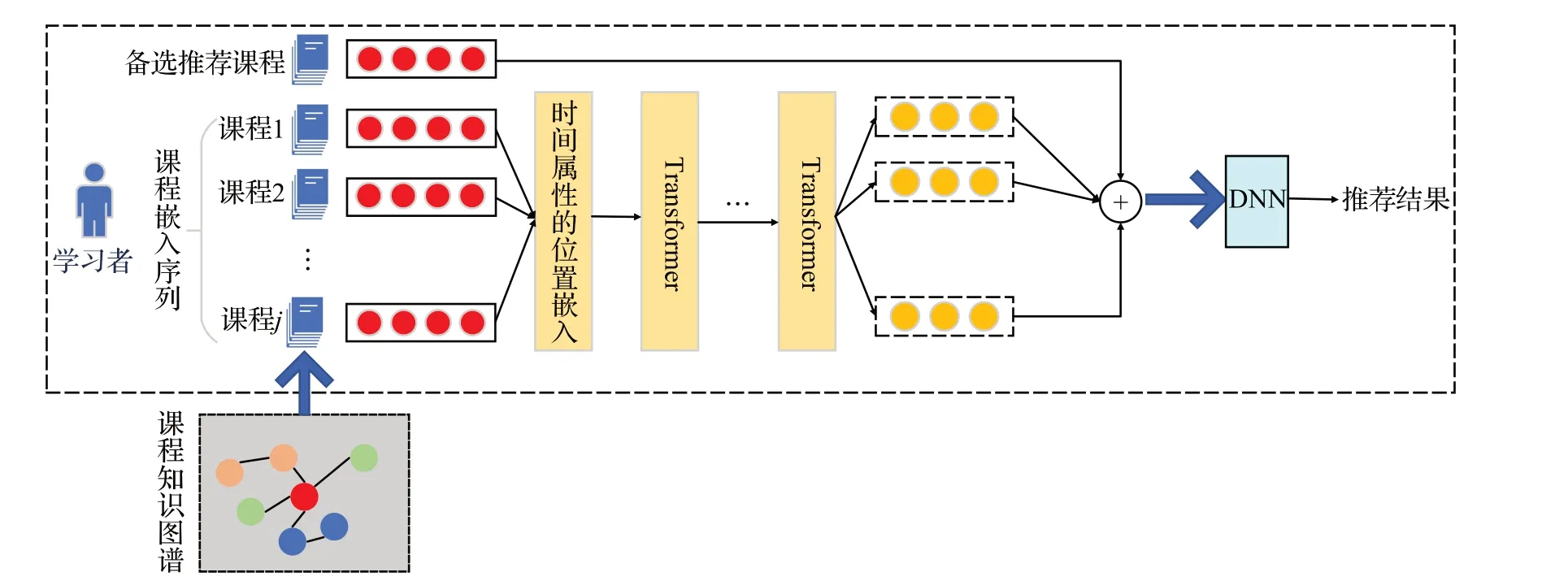
图3 基于知识图谱的在线课程推荐模型Fig.3 Knowledge graph based online course recommendation model
相比基于本体的方法,KG 在课程推荐方面的优势在于其中的实体和关系可以形成多层次、包含丰富的语义信息的关联网络。KG利用这些关联进行深度的推荐分析,发现学习者和课程之间的隐藏关系和相似性,提供更精准的推荐结果。然而,KG 的构建和维护需要大量的人力和时间,并且需要不断地进行更新和校对,因此该方法的成本较高。尽管存在上述缺点,但KG仍然是目前研究的热门方向,受到众多研究人员的关注。
2.6.3 基于异质信息网络的方法
异质信息网络(heterogeneous information network,HIN)是指实体类型数大于1 或关系类型数大于1 的信息网络[61]。在课程推荐中HIN 利用学习者和课程之间的复杂关系,提高推荐的准确性和个性化程度。Wang等人[62]提出基于HIN的课程推荐方法,结合课程内容和学习者相关行为等异构信息构造HIN,用于挖掘课程和学习者之间的有效结构信息和融合相关异构信息,以学习不同类型实体的表示,进而用于课程推荐。Gong 等人[11]提出基于HIN 的增强概念推荐模型AGMKRec,将课程中的概念问题作为强化学习问题加以阐明,为学习者提供个性化、动态的概念标签列表。AGMKRec通过构建一个基于学习者、课程、概念的HIN 来得到更多相关信息,使用基于元路径的方法自动识别有用的元路径,然后学习HIN 上有效的信息表示用于推荐。Wang等人[63]提出基于课程预训练的异构子图推荐模型,首先从HIN 中提取有用信息来组成包含特定信息的异构子图,然后利用异构子图转换器捕获子图中的语义信息来建模学习者-课程交互关系,最终根据学习者的历史记录生成感兴趣课程的排序列表。Bruun 等人[64]提出将HIN 与遗传算法结合,利用学习者、课程以及两者之间的异构交互构建HIN,通过随机游走获取学习者和课程信息,利用遗传算法来防止局部最优得到最佳收敛,从而获取课程推荐列表。
由于基于深度学习的推荐方法可解释性较差,不容易解释推荐中的规律和特征。为了加强推荐方法的可解释性,研究者提出将HIN与矩阵分解结合。文献[65-66]都结合了HIN与扩展矩阵分解方法,前者通过融合节点级注意力和元路径级注意力处理学习者和课程信息,而后者则结合多层HIN 来连接相关概念和多个实体。通过比较相关指标可以发现文献[66]提出的方法取得效果更好。
对于基于HIN的推荐方法,由于HIN中不同类型节点和边之间存在着丰富的关联关系,通过分析不同类型节点之间的关联,可以发现隐藏的关联规律和相似性,从而提高推荐准确性。但该方法存在数据稀疏和计算复杂度高等问题。
2.7 基于联合建模的方法
在传统的课程推荐方法中,通常学习学习者的行为数据或课程的内容特征来进行推荐。然而,这种单一视角容易忽略两者之间的复杂关系和相互作用。因此在实际中,基于联合建模的方法被广泛应用。例如Sheng等人[67]将GMF 与HIN 相结合,通过HIN 整合显性和隐性的关系以及整合学习者和课程的嵌入,对融合嵌入使用GMF 得到相关评分推荐,最终给学习者推荐可能会选择的课程。班启敏等人[68]则提出了基于知识追踪和LSTM的课程推荐模型KPM,利用知识追踪作为辅助任务,获取学习者的知识状态,通过LSTM 建模时序交互行为,最后利用因式分解机得到预测分值进行课程推荐。Esteban 等人[69]通过将协同过滤(CF)、基于内容的过滤(CBF)以及GA结合提出混合推荐模型,利用CF和CBF分别处理学生信息和课程信息,利用GA优化推荐方法的相关参数,从而提升推荐准确度。Gong 等人[70]提出了基于HIN和强化学习的课程推荐方法,通过网络模式和元路径来表示一对实体间的语义路径,利用随机游走对给定学习者在HIN上的元路径进行采样,使用基于强化学习的方法向学习者推荐课程。
基于联合建模的方法通过学习不同信息之间的相互作用和关联关系,挖掘出更深层次的学习者兴趣和课程特征,从而形成更加综合全面的推荐结果。但联合建模方法中的参数较多,参数优化需要消耗大量计算成本,因此该方法的计算复杂度较高。
前文介绍了目前在课程推荐方面具有代表性的方法。表1列出了部分代表方法的时间复杂度,并对相关内容进行了分析总结;表2 列出了各类代表方法的特点、优点及缺点。

表1 在线课程推荐方法复杂度分析Table 1 Complexity analysis of online course recommendation methods

表2 在线课程推荐方法对比分析Table 2 Comparative analysis of online course recommendation methods
从表1中可以看出,目前大多数方法的时间复杂度为O(nlogn)和O(n2),其中n是指学习者数量。一般来说,复杂度和性能之间存在一种权衡关系。较为复杂的推荐方法可能具有更高的准确性和个性化程度,但其计算和处理的复杂度也会相应增加,如基于联合建模的方法在相关指标上优于基于PM的方法,但基于联合建模的方法时间复杂度更高。此外还需要考虑相关方法的使用场景,对于不同要求,需要研究人员选择不同的方法。
在推荐准确性方面,基于关联规则、矩阵分解和概率模型的方法,如文献[14,18,22]等,大多数相关方法推荐准确率都在70%~80%之间,而如文献[9,27,44]等基于深度学习的方法、文献[52]等基于智能优化的方法、文献[10,66]等基于语义计算的方法以及文献[70]等基于联合建模的方法推荐准确率大多在80%~90%之间。综上可以得出结论:通常情况下,基于深度学习、智能优化、语义计算和联合建模的方法的推荐准确率更高。
3 性能评价指标及数据集
3.1 性能评价指标
在线课程推荐系统的评价可以分为在线评价和离线评价两方面。在线评价主要是通过在线实验如问卷等方式收集结果后对系统进行评价;离线评价主要是根据需要评价的课程推荐系统在给定实验数据集上的表现,再根据相关性能评价指标来评测该系统的质量。由于在线课程评价过程成本高昂,目前大部分实验方法采用离线评价。本节主要介绍离线评价指标中的评分预测指标、集合推荐指标和排名推荐指标。
3.1.1 评分预测指标
评分预测指标衡量推荐方法预测的评分与学习者的实际评分的符合程度,其思想是课程推荐系统根据学习者对课程的评分进行推荐。评分预测指标主要包括平均值绝对误差(mean absolute error,MAE)、平均平方误差(mean squared error,MSE)、均方根误差(root mean squared error,RMSE)和标准平均绝对误差(normalized mean absolute error,NMAE)[71],公式如下:
其中,rsc表示学习者s对课程c的真实评分,表示学习者s对课程c的预测评分,EP表示测试集,rmax和rmin分别表示学习者评分区间的最大值和最小值。上述四个指标越接近0,表示推荐课程性能越好。
3.1.2 集合推荐指标
集合推荐指标是指推荐方法能否正确预测学习者选择或未选择课程的能力,主要思想是推荐系统最后得到的是推荐课程的集合(例如Top-N推荐任务)。目前最常用的集合推荐指标有准确率(Precision)、召回率(Recall)、F1指标、AUC和命中率(hit ratio,HR)。
如表3 所示,一个没有被学习者选择的课程,可能的结果有四种:系统推荐给学习者且学习者接受,系统推荐给学习者但学习者不接受,学习者接受但系统未推荐,系统未推荐且学习者不接受。

表3 课程推荐的混淆矩阵Table 3 Confusion matrix of course recommendation
Precision(式(10))是指在所有课程中,推荐系统预测正确的课程数占总课程数的比例,取值范围为[0,1],越接近1代表推荐准确率越高。
Recal(l式(11))表示一个学习者接受的课程被推荐的概率,即推荐列表中学习者接受的推荐课程与系统中学习者接受的所有课程的比率,取值范围为[0,1],越接近1代表推荐性能率越好。
F1 值(式(12))是精确率和召回率的调和平均值,F1值认为精确率和召回率一样重要,取值范围是[0,1],越靠近1代表推荐效果越好。
AUC 表示ROC(receiver operator curve)曲线下的面积,它衡量的是一个课程推荐系统能够在多大程度上将学习者接受的课程与不接受的课程进行区分。
HR@K(式(13))用于衡量模型召回的列表中前K个课程在目标列表中的命中率,该指标思想和召回率并无区别,但更能够体现模型对于Top-K热门课程的推荐性能。
3.1.3 排名推荐指标
基于在线课程推荐最终会得到一个推荐列表,人们认为该列表中排名靠前的课程重要性远大于排名靠后的课程,因此出现了排名推荐指标来对推荐效果进行加权评估。常见的排名推荐指标有半衰期效用指标(half life utility index,HLU)、折现累积收益(discounted cumulative gain,DCG)、排序偏差准确率(rank-biased precision,RBP)等。
HLU(式(14))认为学习者与接受某课程的概率与其在推荐列表中的位置呈指数递减相关,学习者选择的课程在推荐列表中越靠前该值越大。
其中,rsc表示学习者s对课程c的实际打分,lsc表示课程c在学习者s的推荐列表中的排名,d表示默认评分,h为系统的半衰期。
DCG(式(15))的主要思想是推荐列表中排名越靠前的课程越应该被学习者选择,它将排序结果中每个课程的相关性与其排名关系结合起来,以此来衡量推荐质量。一般来说该指标的值越高,说明推荐系统的性能越好。
其中,rel(i)表示在第i个位置上的相关性得分。
RBP(式(16))基于偏好模型,将推荐列表中每个课程的相关性与其排名结合来衡量推荐结果的质量。该评价指标的值越大,说明推荐系统的性能越好。
其中,p是一个偏好参数,ri表示推荐列表中第i位的课程是否是学习者选择的。
3.2 课程推荐数据集
目前公开可用的课程推荐数据集信息见表4,其中每个数据集都含有课程和学习者的基本信息,少部分数据集如MOOCCube数据集含有视频信息,MOOPer数据集包含学习者论坛讨论数据。大部分数据集都含有时间属性,有利于理解和分析学习者的动态行为模式与提高推荐的准确性。数据集中含有的其他信息如学习者的年龄、课程的授课教师等其他属性也有利于提取更为完整准确的学习者或课程特征,用于课程推荐并提升推荐效果。

表4 课程推荐数据集统计信息Table 4 Statistics of course recommendation datasets
4 未来展望
随着在线教育平台的蓬勃发展,在线课程推荐的相关研究取得了重大进展,相关数据不断丰富,高新技术不断涌现。为了顺应科技发展潮流,做到与时俱进,在线课程推荐领域中仍有诸多的研究方向值得关注,其中包括:
(1)强可解释性的推荐
课程推荐的目的是推荐学习者可接受的课程,因此学习者需要了解推荐课程的原理,使他能够接受推荐结果[77]。现有的课程推荐方法大多只提供了推荐课程预测的准确率,特别是基于深度学习的方法,通常使用“黑盒子”理论,鲜少解释如何实现课程推荐等问题,不利于学习者理解和信任课程推荐结果。因此如何提高可解释性是目前在线课程推荐方法需要解决的重大课题之一。
(2)融合多模态数据的推荐
多模态数据是指融合了不同模态(如文本、图像、音频、视频等)的数据。相关方法主要分为两个模块,第一个模块将多模态数据表示为低维向量,第二个模块通过计算不同模态之间的相似度来融合不同模态的表示,使得融合表示能够更加适用于推荐任务。在课程推荐中,利用多模态数据可以更全面地反映学习者偏好以及课程特征,提高推荐的准确率和个性化程度。然而,目前基于多模态数据的课程推荐研究尚未成熟,仍然面临以下困境:首先是如何准确表示多模态数据;其次是如何有效融合多模态数据,以及如何计算不同模块之间的相似度等。因此融合多模态数据的课程推荐是今后的重要发展方向之一。
(3)基于因果推理的推荐
因果推理[78]旨在观察并推断出事物之间的因果关系,广泛应用于机器学习和数据挖掘领域,帮助解决因果关系的预测和干预问题。目前因果推理的常用框架有潜在结果框架和结构因果框架,应用于课程推荐,推断学习者和课程之间的因果关系,分析学习者的历史行为特征,推断出学习者的偏好以及课程的内容和特点,从而生成更符合学习者需求的推荐课程。目前Wang等人[79]在根据用户特征生成互动的过程中引入因果推理,并进行因果建模,从而达到更好的推荐效果。因此如何更好地将因果推理融入课程推荐是今后的一个重要研究方向。
(4)基于联邦学习的推荐
联邦学习[80]是一种基于机器学习的分布式计算方法,它允许多个参与方在不共享数据的前提下,通过局部训练和参数交换,共同建立一个全局机器学习模型,在保护数据隐私的同时,获得更好的数据安全性和更高的效率。而在线课程推荐所收集的数据涉及大量敏感的隐私信息,对数据保护提出了严格的要求,联邦学习可以在保证数据安全性的前提下,允许多个参与方(例如学校、教育机构和学习者)进行联合建模,提高课程推荐方法的多样性、覆盖率以及通用性。Jie等人[81]提出基于历史参数聚类的联邦学习推荐方法。首先,客户端通过使用时间衰减因子将历史学习参数与服务器发送的全局参数进行加权平均。然后,服务器对收到的参数进行参数聚合和聚类。最终,系统根据用户的历史学习参数进行迭代训练来实现推荐。未来,能够看到更多的结合联邦学习和课程推荐的研究工作。
(5)基于新型机器学习范式的推荐
对于大部分基于机器学习的在线课程推荐研究,如何与时俱进地应用新型机器学习方法是研究人员面临的巨大挑战。新型机器学习方法主要包括以下几种:首先是强化学习[82],其目标是通过与环境的交互来学习如何做出最佳决策。将强化学习应用于课程推荐,通过不断试错和优化来找到最适合学习者的课程。如Zhang等人[83]提出了一种分层强化学习的课程推荐方法,能够在没有明确注释的情况下去除噪音课程,提高课程推荐的准确率。其次是生成学习[84],通过对已有数据进行分析,并从分析出来的知识中生成新的数据用于后续任务。生成学习在课程推荐中可以根据学习者历史行为等信息来建模学习者的兴趣分布,从而生成符合学习者兴趣的课程,完成个性化推荐。最后是对比学习[85],其核心思想是通过比较不同样本之间的差异性来学习特征表示。在课程推荐中对比学习旨在比较学习者的历史行为或课程的特征,获取学习者之间以及课程之间的相似性和差异性,从而为每个学习者进行个性化推荐。
5 总结
作为在线教育领域的重点研究方向,在线课程推荐系统通过帮助学习者寻找到感兴趣的课程,极大地提升了学习者的学习兴趣和学习积极性,有助于教育行业的积极发展。近年来,该领域中出现了大量在线课程推荐系统的相关工作,可见在线课程推荐受到广大研究人员关注。本文详细讨论了在线课程推荐系统的研究内容与特点,对目前的在线课程推荐方法进行了归类和总结,并介绍了在线课程推荐的评价指标、相关数据集资源以及未来的可能研究方向。本文综述有助于相关研究人员理解在线课程推荐的研究内容、研究难点与研究思路,从而激发研究人员对未来在线课程推荐相关研究的思考,启发研究人员提出新的高效方法,并推动相关在线课程推荐技术的创新应用。
