开源自然语言处理工具综述
2023-11-27廖春林张宏军廖湘琳李大硕
廖春林,张宏军,廖湘琳,程 恺,李大硕,王 航
中国人民解放军陆军工程大学 指挥控制工程学院,南京210007
随着计算机技术的发展和应用模式的改变,需要对大量的人类语言数据进行处理和分析,以满足不同程度的研究和应用需求。自然语言处理(natural language processing,NLP)是计算机科学和人工智能领域的一个重要研究方向,主要的目标便是实现人与计算机用自然语言进行有效交互。
语言数据中文本数据占据极大的比重,故现在自然语言处理的研究对象主要针对文本数据。文本数据的处理分析一般需要分成不同的子任务来进行,例如既需要文本标准化、文本清洗等预处理操作,也包括对词法、语义等层面的具体分析,还需要像机器翻译、信息抽取等能投入生产的应用任务。
为方便对文本的处理和研究,加快相关应用的落地部署,许多研究机构和开发人员对自然语言处理领域中的子任务进行了不同程度的实现和集成,从而构建和迭代了效果良好、功能丰富的自然语言处理工具。早期的自然语言处理工具有宾夕法尼亚大学计算机与信息科学系开发的NLTK,它设计的初衷是为了方便计算语言学课程教学[1]。同一时期,斯坦福大学自然语言处理课题组也展开相关的研究,后来在2014 年左右集成发布了全面的工具CoreNLP[2]。国内也同样开展了自然语言处理工具的研究与构建,其中具有代表性的便是哈尔滨工业大学社会计算与信息检索研究中心构建的LTP[3-4],清华大学自然语言处理实验室开发的THUNLP一系列工具。一些个人开发者也对自然语言处理工具做出了贡献,例如Wang 等人开发的面向中文文本的处理工具SnowNLP。
随着自然语言处理领域研究的迅速发展,不少工具对子任务以往的实现方法进行了改进,新的方法和处理范式正在被提出和应用。每种工具对子任务具有不同程度上的支持,在应用任务和背景方面又有一定的侧重。面对日益增长的各类文本处理需求,寻找符合需求的文本处理工具比较耗费时间和精力。目前国内外已经发布多款开源的自然语言处理工具,只有少数博客对其中的几款经典工具进行简单的介绍,缺乏相关的论文对这些工具进行系统的整理。为了给从事自然语言处理相关工作的研究和开发人员提供参考,现围绕国内外23款开源自然语言处理工具主要完成以下工作:
(1)依照文本处理中的处理顺序和作用把各项子任务划分为辅助任务、基础任务、应用任务并进行介绍。
(2)根据工具所面向的处理语言对工具进行分类介绍,概括各种工具支持的编程语言、调用方式等信息,对比工具以及在各项任务上的特点。
(3)对各种工具支持子任务的实现原理进行探究,按照规则方法、统计学习方法、神经网络方法以及基于它们的组合方法四个类别进行比较。
(4)根据当前自然语言处理工具的不足之处,展望自然语言处理工具未来的发展方向。
1 自然语言处理工具任务
自然语言处理领域的一大特点是任务种类纷繁复杂,任务之间又有一定的层次关系,并且任务有多种划分方式。从处理的顺序以及作用角度,可以将任务分为对文本预处理和规范的辅助类任务,在字词、句法和语义维度上的基础类任务,以及与现实生产实际密切相关的应用类任务。
1.1 辅助类任务
辅助类任务一般在基础任务和辅助任务前发挥作用,文本形式和内容往往丰富多样,主要针对文本进行清洗和规范化,为后续任务提供部分功能计算接口,将文本转换为方便计算机处理的形式和提取一些特殊文本特征,对较少的语料进行扩展。
文本规范处理:文本数据来源广泛,需要对不同来源的文本进行统一。一些文本中的字体形式不同,需要对文本进行全半角转换。中文领域由于历史文化等差异,不同地区和不同时期的文本在字符上存在差异,例如古汉语繁体与现代白话文简体、我国港澳台地区与内陆地区用语,有时也需要对繁体和简体中文进行相互转换。
字符特征提取:汉语拼音是根据普通话读音的组成规则,将韵母、声母以及声调合并成音节。象形字起源于图画文字,是一种最为古老的造字方式,汉字由象形字演变而来,汉字的一些部首偏旁保留着对语言潜在规律的刻画。刘梦迪等人[5]表明将汉字的拼音和偏旁部首作为特征对一些子任务效果有所提升。
相似度计算:文本相似度计算主要目标是量化比较文本之间在语义上的相似程度,自然语言处理领域许多任务都需要用到相似度计算。机器翻译任务中相似度被用来衡量翻译的精确度,在智能问答领域中使用相似度来评定问题与答案之间的语义匹配,文本聚类任务中也被用来作为聚类标准。
文本嵌入:当前自然语言处理领域主流的方法是深度学习,首先需要进行文本嵌入工作。文本嵌入主要实现文本由符号形式转换为向量形式,从而方便计算机处理,同时文本嵌入也是实现单词语义推测、句子情感分析等目的的一种手段,例如根据现有词语推测出新词,如“机场-飞机+火车=火车站”。
词形还原:印欧语系的语言往往具有复杂的词性变化,一些语义上相近的单词(computer 和computing)由于组成的细微差异被认为是不同的单词,为了减少词表大小,降低计算复杂度,需要对单词进行词形还原或者词干提取等任务。
数据增强:数据增强可以理解为通过有限的数据生成更多的数据,增加样本的数量以及多样性,从而间接提升方法和模型的鲁棒性。当前热门神经网络方法需要大量的数据来提升模型方法的泛化能力,因此需要做数据增强增加数据量。
1.2 基础类任务
基础类任务聚焦于文本的词法、句法以及语义层面的分析,每个层面中又有具体的子任务,许多任务之间具有顺序性和关联性,这些任务大多是应用类任务实现的前提。
(1)字词分析
分词:词是最小的能独立使用的音义结合体,是能够独立运用并表达语义的最基本单元,因此分词标记(token)是多项自然语言处理子任务的基础。在以英语为代表的印欧语系中,词之间通常以空格、标点符号等分隔符进行区分。而在以中文为代表的东亚语系中,词与词之间并没有明显的界限,中文分词(Chinese word segmentation)任务便是将一串中文字序列切分成中文词序列。
词性标注:词性作为对词的一种泛化,在句法分析、语言识别、文本生成等任务中发挥着重要作用。词性标注(part-of-speech tagging)是对句子中的每个词都分配合适的词性,如副词、动词、名词等。
命名实体识别:命名实体识别(named entity recognition)指的是在句子的词序列中定位并识别人名、地名、机构名等实体范围,命名实体对信息抽取、机器翻译等任务有着重要作用。
词典库构建:词典库是常用词语、领域词语等构成的集合,通常由人工进行整理,具有极高的可靠性,可直接用于分词等任务或作为高质量训练数据。
(2)句法分析
句法分析通过分析语言单位内成分之间的相关关系揭示其句法规律与结构,句法分析又分为成分句法分析(constituency parsing)、依存句法分析(dependency parsing)。
成分句法分析:成分是一种抽象,它将语法作用相似的一些词合并为一个短语单元,如名词短语作用与名词相似,可以在句子中作为主语或宾语成分。成分句法分析旨在解析出由词构成短语,再由短语构成句子的过程。
依存句法分析:依存句法理论认为词语之间存在着主从关系,即在句子中一个词修饰并依附于另一个词,通过依存分析能揭示句子词语中的主谓关系、动宾关系、核心关系等,从而进一步理解语义来提升更深层次的任务效果。
规则库构建:规则是依据具体任务对语言规律的总结,特定的规则对具体任务有很强的匹配性,对效果要求较高的任务通常需要规则库进行矫正。规则库在基础任务和应用任务中都有被应用。
(3)语义分析
语义角色标注:语义角色标注(semantic role labeling)是浅层次的语义分析任务,主要目标是对给定谓词标注其在句子中的短语论元,如施事、受事、时间和地点等,对智能问答、自动翻译和信息抽取等应用产生推动作用。
语义依存分析:语义依存分析(semantic dependency parsing)与依存句法分析相似,通过词语所承载的语义框架来描述该词语,从而刻画句子语义,从语义层面分析句子中语言单位之间的依存关联。语义依存跨越了句法结构的表层限制,获取的是深层的语义信息。
抽象意义表示:抽象意义表示(abstract meaning representation,AMR)是一种将句子的意义表示为以概念为节点的单源有向无环图的语言学框架。AMR正在引起学术界越来越广泛的关注,已经出现许多利用AMR进行机器翻译、关系提取等应用的工作。
1.3 应用类任务
应用类任务的研究是推动自然语言处理发展的直接因素,其他任务大多围绕应用类任务而产生,应用类任务与人们的生活息息相关,一般可以直接投入现实生产中,提高语言文字类相关工作的效率。
信息抽取:信息抽取(information extraction)是当前自然语言处理研究中的一个热门方向。信息抽取同时也是一个宽泛的概念,狭义的信息抽取指的是实体、实体之间的关系以及二者所构成的事件提取,而广义的信息抽取还包括关键词提取、新词发现以及文本摘要等从文本中抽取出任务所需的特定信息。
文本分类与聚类:文本聚类(text clustering)是无监督聚簇过程,它将文本转换成数字信息形成高维空间点,再计算空间点间距离,将距离较近的聚成一个簇,同一簇的文本具有较强的相似性。文本分类(text classification)则让计算机按照一定的分类体系或标准将文本归入预先定义类别中的一个或若干个。
指代消解:将代表同一实体的不同指称划分到等价集合的过程称为指代消解(co-reference resolution)。指代消解在机器阅读理解、信息抽取、多轮对话等任务中都起到重要作用,能够有效解决文本当中的实体具有多个指代名称的问题。
情感分析:情感分析(sentiment analysis)是指对含有主观性的情感色彩文本进行分析处理、归纳以及推理的过程。互联网中用户对人物、事件、产品等产生大量的评论文本,有丰富的舆论和商业价值,需要情感分析相关技术对这类文本挖掘出有价值的信息。
机器翻译:机器翻译(machine translation)又称为自动翻译,是利用计算机把一种自然源语言转变为另一种自然目标语言的过程,一般指自然语言之间句子和全文的翻译。
文本纠错:语音识别、OCR以及用输入法打字等诸多场景中都会出现字词错误,这不仅影响人和机器的理解,错误传播也会影响后续任务的效果,因此需要文本纠错任务(text correction)对文本中不符合语言规则的地方进行修正。
文本对抗攻击:机器学习模型的输入是数值型向量,文本对抗攻击(textual confrontation)便是利用这一点生成对抗样本,对原始的样本数据添加针对性但不会影响人类感知的微小扰动,使机器学习模型产生错误的输出,该任务可在情绪分析、售后评价等实际应用中歪曲客观事实。
文本生成:文本生成(text generation)的早期定义指的是接收非语言形式的信息作为输入,生成可读的文字表述,广义的文本生成则是将输入来源扩展为文本、图像等数据形式。
自动问答:自动问答(question answering,QA)是利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。QA不同于现有的信息检索只返回基于关键词匹配内容排序结果,而是提供更加精准的自然语言答案。
近两年对自然语言处理应用任务的相关研究成绩斐然,信息抽取任务因为具有多样的抽取目标和复杂的结构,需要根据具体的任务设计特定的模型结构和标注标签,比较耗费时间和资源,百度和中国科学院联合提出的USM方法旨在通过统一的模型方法完成信息抽取任务[6]。在文本理解和生成、自动问答领域最大的突破当属OpenAI推出的ChatGPT和GPT4模型,GPT4支持图文语义化的解读以及更好的回答组织能力,而ChatGPT则带来语言的深层次理解。机器翻译字符序列很长,对计算资源的需求很大,Carrión等人[7]提出一种准字符集机器翻译的建模方法,其粒度介于字符与字词之间,从而缓解机器翻译中灾难性遗忘问题,同时与字符级建模方法相比更为高效。
自然语言处理中的各类任务不是彼此独立,各类任务存在联系,例如文本在分析前需要进行预处理操作,分词又是很多任务的基础,基于分词才能对文本进行词法、语法层面的分析。文本纠错等应用类任务同样也可以反过来为辅助类任务提供支持,在文本清洗中发挥作用,从而提供质量更高的语料。各子任务之间的关系如图1所示。
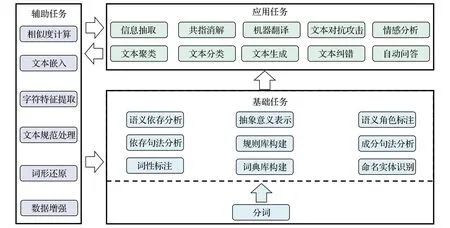
图1 子任务结构关系Fig.1 Subtask structure relationships
1.4 相关任务数据集
表1 整理了一些常用于训练和评测的自然语言处理子任务数据集,并给出数据集所支持的相关任务、链接地址、语料来源等信息以供参考。
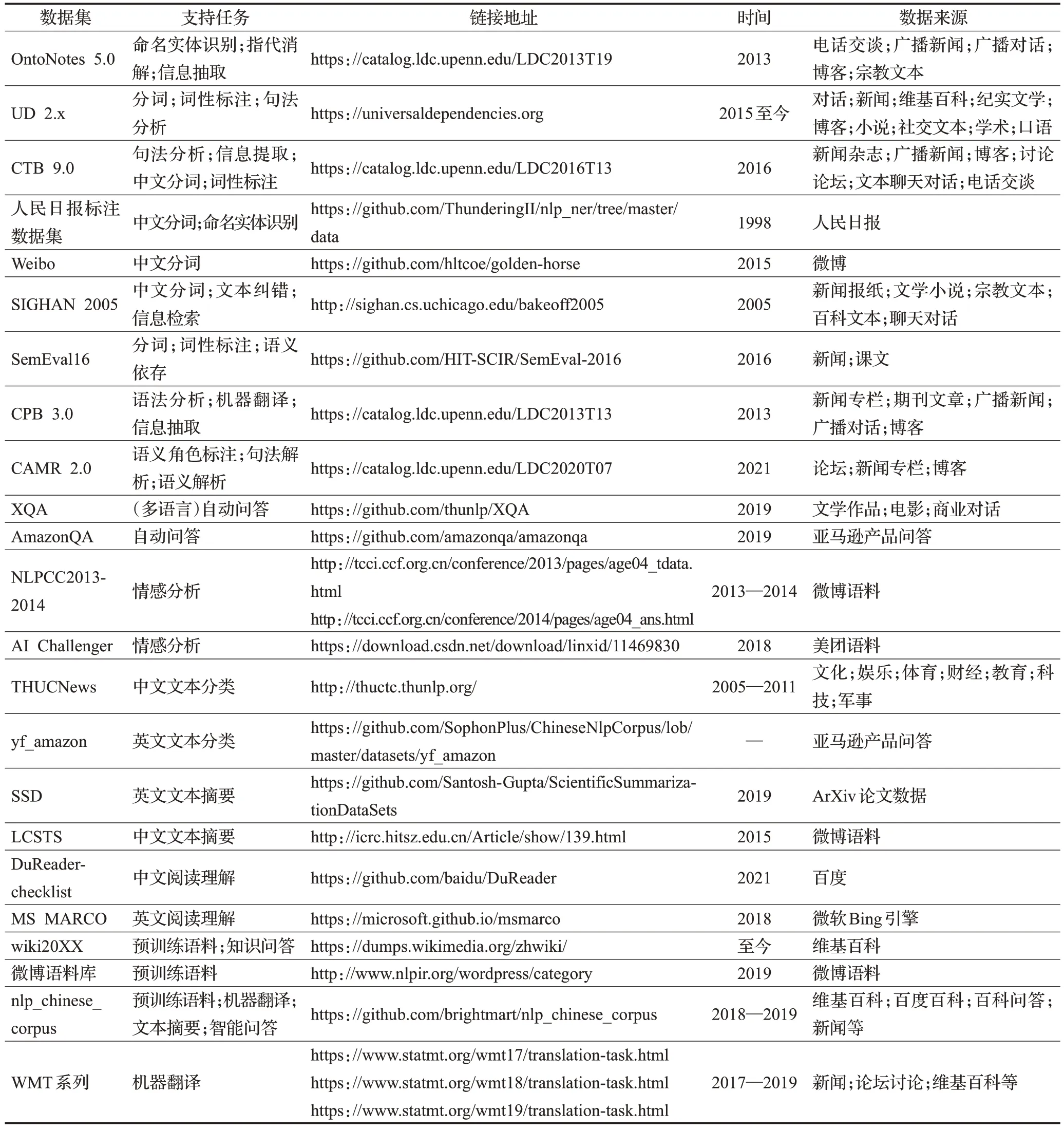
表1 相关任务数据集对比Table 1 Comparison of relevant task datasets
2 主流工具分析
当前国内外从事自然语言处理领域研究的机构和一些个人开发者发布了多款自然语言处理工具,本文选取了其中的23款工具作为调查对象。在选取工具时考虑以下几个方面:具有一定知名度与影响力(GitHub 的star数为1 000以上),如NLTK;面向具体领域的文本进行分析和处理,如JiaYan;在任务实现上采取较为新颖的方法,如Graph4NLP;支持的子任务较为全面,实现方法较为丰富,如Hanlp。
2.1 工具分类
自然语言处理工具丰富多样,现根据工具所面向的处理领域将工具划分为英文领域处理工具、中文领域处理工具以及多语言处理工具进行介绍。
(1)英文领域处理工具
英文领域的自然语言处理研究开展最早,也最先构建相关的集成工具。宾夕法尼亚大学为方便计算语言学研究和教学使用Python 构建了NLTK,提供WordNet等50 多个语料库资源下载和预处理接口,可用于文本分类、语义解析和推理等任务的文本处理库,还对同一子任务提供多种算法以供使用者针对不同的需求进行选择。
艾伦人工智能研究所基于Pytorch开发的NLP框架AllenNLP[8],它为NLP中的常见任务和模型提供高级抽象和简单易用的API,模块化的设计使得开发者可以轻松扩展自己的模型,也方便初学者能够快速实验。AllenNLP 同样致力于多模态研究,从图像和自然语言学习联合模型以实现图片问答任务。
近年来图深度学习开始兴起,一些的自然语言处理问题能够以图结构进行建模,从而得到更好的解决。吴凌飞等人构建的工具Graph4NLP 被用于在图深度学习和自然语言处理的交叉研究。它为研究人员和开发人员提供灵活的接口,也支持构建全管道支持的自定义模型。Graph4NLP除了提供实现文本分类、语义解析等功能外,还能实现知识图谱补全和求解一些由自然语言描述的简单数学问题。
(2)中文领域处理工具
哈尔滨工业大学较早对中文领域自然语言处理进行研究,LTP便是其研制的一套开放中文自然语言处理系统,先后历经四大版本,实现方法也从早期的规则和统计学习方法到最新的基于预训练模型微调。LTP 面向基础任务由下到上提供一整套的性能良好的语言处理模块,还可通过Web 端对依存图等处理结果进行可视化。
THUNLP不是具体的工具名,而是由清华大学研制推出的一系列单独NLP 工具[9-13],包括支持高效分词和词性标注分析的THULAC;实现文本对抗攻击全过程的OpenAttack;可一键运行的开源关系抽取OpenNRE;能够自动高效地实现用户自定义的文本分类语料的训练、评测、分类功能的THUCTC;支持多语言机器翻译和提供完善训练支持的THUMT等工具。
复旦大学的fastNLP[14]对文本的预处理、嵌入、训练以及模型评测等过程进行封装,并提供相应的接口体现出它的简洁易用性。支持部分数据集自动下载和相应的预处理,提供多种神经网络的复现模型和预训练模型的调用接口,还可以通过fitlog相配合,方便捕获异常和记录实验结果。将该工具应用于研究中可以快速构建更复杂的模型,提供的分布式接口也能使得模型在多卡设备上快速训练。
BaiduLAC是百度公司语言处理研究部门研发的一款联合的词法分析工具,主要面向中文实现词法分析等功能[15],具有效果好、效率高、调用便捷等特点。其中的超轻量级模型可支持移动端,大小仅有2.0×106,在普通手机上单线程性能达每秒钟200的查询量,支持多数移动端应用的需求,同等体积量级效果业内领先。
微觅科技公司参考各大工具的优缺点对相关任务技术进行集成推出工具Jiagu,使用大规模语料训练任务模型。该工具不但覆盖词法分析、文本生成、情感分析等常见自然语言处理任务,还通过关系抽取、关键词抽取为知识图谱的构建提供支撑。
中文领域大多NLP 工具由大学研究机构或公司进行集成和开发,并且一些行业爱好者同样对工具的发展做出了贡献。Wang等人开发了纯面向处理中文文本工具SnowNLP,能够进行基本的词法分析、文本摘要,对购物评价提供情感分析支持。ChineseNLP 基于C++和Python 开发,不仅处理速度相对更快,还能实现同义词词林的消歧、自动文本生成、信息检索等功能。DeepNLP基于TensorFlow深度学习平台并结合最新的一些算法,支持NLP基础模块和其他更加复杂任务的拓展,提供通用、娱乐和O2O 领域的命名实体识别模型。Sean 开发的xmnlp同样能够实现丰富的功能,提供电商场景下的情感识别,支持通用、金融和国际场景下的文本纠错和相似度计算,从汉字中提取偏旁部首也是xmnlp的特色功能。
当前通用的中文NLP 工具多以现代汉语为核心语料,从而造成对古汉语的处理效果并不理想。Jiayan工具的目标便是辅助古汉语信息处理,帮助古汉语的相关研究人员和爱好者更好地分析和利用文言语料。工具包支持词库构建、自动分词、词性标注、文言文断句和标点五项功能,而古汉语到现代汉语的翻译等功能正在开发中。
原始文本语料因为来源广泛、内容形式丰富等不能直接分析,需要对语料进行清洗和格式规范。JioNLP便派上用场,它注重于文本预处理,支持提取HTML 文件标签中的内容;发现处理文本中的异常字符;提取E-mail、IP地址、手机电话号码等形式的内容;还支持从中解析出诸如电话号码归属地、运营商,身份证号码所含信息等;除了对文本繁简、拼音转换外,也能实现全半角等格式规范。对某些语料稀少不易获取的特殊领域,也可以进行数据增强。
(3)支持多语言处理工具
据统计,目前世界上有5 651种语言,其中形成文字的有2 769 种,地区之间又发展出特有的语系。一些工具不局限于针对一种语言进行处理和分析,而尽可能面向多语言研究,探究自然语言之间的共性。
北京理工大学发布的NLPIR 支持文字图片、文档、语音等多种形式的数据导入和分析处理,并在此基础上执行信息抽取、文本挖掘、知识关联等中间任务为情报分析、知识图谱、文档智能提供支撑[16]。NLPIR支持GBK、UTF8等多种编码标准,覆盖了中文、英文、阿拉伯语、印度乌尔都语、多哥语等“一带一路”沿线语言的自然语言处理。除能运行在Linux、Windows、IOS、安卓等操作系统上外,还对国产系统中麒麟以及龙芯、飞腾、华为鲲鹏等国产芯片提供不同程度的任务支持。
Hanlp[17]是面向NLP生产环境的工具,支持PyTorch和TensorFlow 双深度学习框架。目标是实现最前沿的NLP技术落地,主体面向中文,同时也支持英语、法语等130种语言上的10项联合任务以及多项单任务,具备精度准确、性能高效、语料时新、架构清晰、可自定义的特点。数据集有时会采用不同的标注标准,例如中文词性标注相关的数据集就拥有CTB、PKU、863 三套标准。大多工具的子任务模型一般只支持一套标注标准,Hanlp尽可能对各项子任务的各项标准提供支持,也同样对部分自然语言处理数据集提供下载和预处理接口。
OpenNLP 是Apache 基金会下面的一个用于处理英、法、意、德以及荷兰文本的工具,支持对CoNLL、OntoNotes等数据集的处理,包含词法分析等多个组件,可以构建完整的自然语言处理管道。出于工程层面以及任务效果的考虑,绝大多数子任务组件使用最大熵来实现。OpenNLP 除了能够使用编程接口外也提供命令行界面执行相关任务,也能通过这两种方式根据要求自训练组件模型。
FLAIR是德国洪堡大学牵头开发的轻量NLP框架,旨在促进最先进的序列标注、文本分类和语言模型的训练和分发,对英语、德语、丹麦语、西班牙语、法语等语言具有不同程度的任务支持[18]。文本嵌入是FLAIR 一大特色,它几乎囊括了通用的文本嵌入方式,从字符嵌入到文档级别的嵌入。该框架还实现了标准模型训练和超参数选择例程,以及一个数据获取模块,可以下载公开可用的语料数据集并将其转换为数据结构,以便快速设置实验。FLAIR对命名实体识别也极为关注,除对不同语言通用领域的命名实体识别进行研究,还对法律尤其生物医学领域提供命名实体识别模型。
UDPipe[19-20]是捷克共和国查尔斯大学数学与物理学院与应用语言学研究所发布的一款开源工具包,主要用于句子分割、词性标记、词形还原和依赖解析。UD(universal dependencies)树库项目旨在为多种语言开发跨语言一致的形态和句法树库注释。UDPipe正是基于UD 树库训练出的模型处理相关任务,到目前为止一共提供覆盖69 种语言的123 个模型。UDPipe 基于一个多任务框架,使用多种方式将文本进行嵌入,然后联合学习和预测相关的任务使得它在性能上得到一定的提升。
spaCy的定位是工业级自然语言处理库,它对66种语言提供不同程度的子任务支持。通过一个或多个按顺序调用的管道组件可自定义实现对文本的解析处理。为了更好地节省内存和提高处理速度,spaCy用Cpython对内存管理部分进行重构。引入先进的神经网络模型,用于分词标记、句法解析、文本分类等子任务,使用BERT[21]等预训练模型进行多任务学习,以及生产就绪的训练系统和简单的模型打包、部署和工作流管理。
CoreNLP 是斯坦福大学提供的一款独立且拥有一系列强大语言分析处理的工具。对任意的文章段落能够实现快速分析,并且效果相对稳定、可信赖,对文本整体化的分析保持高质量表现。能够实现词法、句法分析以及情感分析等任务,并在提供的网页和客户端上将结果进行可视化。除了分析处理英文,也为阿拉伯语、汉语、法语、匈牙利语、德语和西班牙语提供不同级别的支持。Stanza[22]可以看作CoreNLP的一个升级版本,CoreNLP中大多任务主要采用统计模型,Stanza采用深度学习的方式获取更深层次的语义信息,从而使得子任务的效果得到提升。为了促进生物和医学相关研究,Stanza还提供生物医学文献文本和临床笔记的句法分析和命名实体识别的模型。
2.2 工具任务模型结构
工具的任务模型结构是指子任务在学习和调用时的实现构型,目前主要分为单任务和多任务两大类。单任务方式是在学习时根据具体的子任务和数据选取不同的模型进行学习,而多任务则是采用同一个模型,如图2所示。
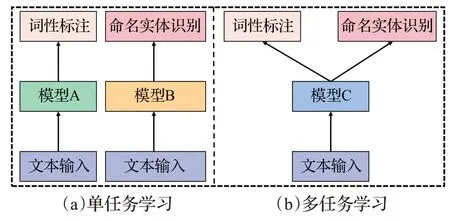
图2 任务模型结构Fig.2 Task model structure
当前许多NLP工具采取对单任务学习的方式,因为其效果相比多任务更好,但对多个单任务采用单模型往往会增加内存开销,导致处理速度不如多任务学习。同时单任务学习忽略了各任务之间的知识共享,子任务之间存在很强的相关性,比如分词能力更强的模型在词性标注、命名实体识别等任务上表现会更好,可以通过多任务学习在多个语料库上共享知识从而提升子任务性能[14]。LTP、fastNLP 等一些工具便采用多任务框架,子任务通过共享编码器实现原输入到向量的转换,不同子任务采用不同的任务解码器。
2.3 工具对比
通过对各种工具的调研,本文对各工具支持的语言、调用接口等信息进行汇总以供参考。但由于不同的自然语言处理工具在适用领域、覆盖的语言范围以及对子任务的标注标准上存在差异,同时一些工具并未公布子任务模型的训练语料来源,要准确量化比较工具的性能差异非常困难。为对工具子任务的性能进行大致的比较,依据机器之心(https://sota.jiqizhixin.com)收录的SOTA评估指标和效果设定简单的评估标准以供参考,在表2中进行具体的评估说明。
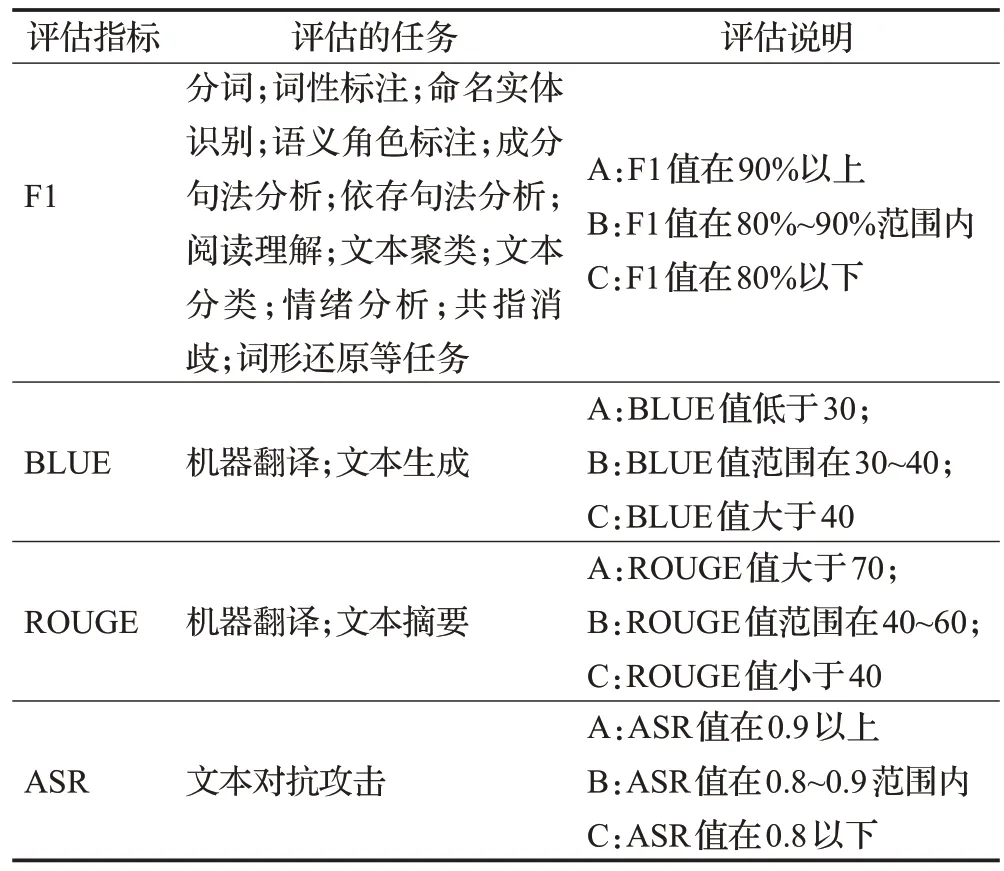
表2 工具任务评估说明Table 2 Tool task evaluation description
各工具的对比信息由表3给出。
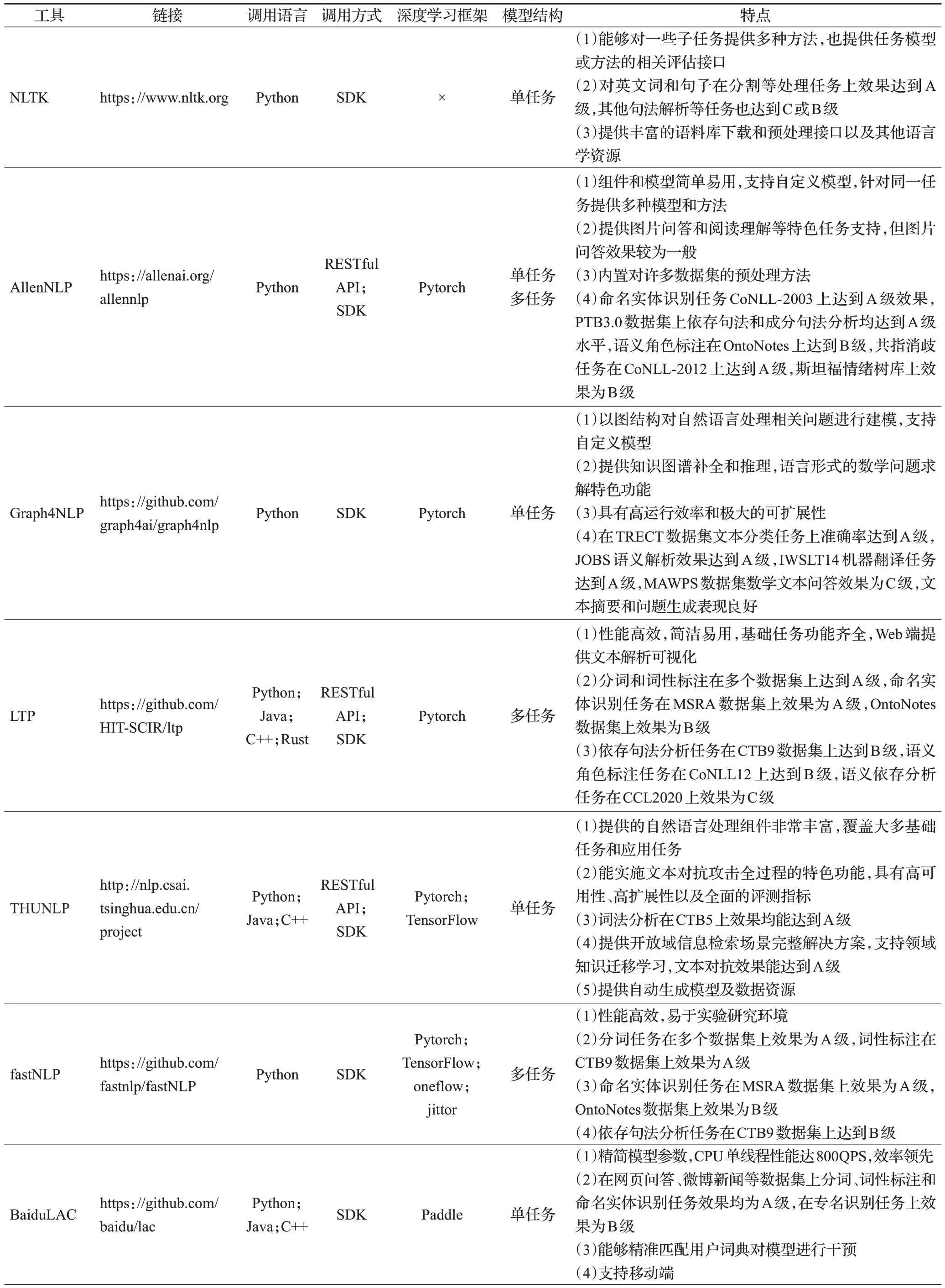
表3 工具基本信息Table 3 Basic information of tools
由于Python的简洁性和强大的功能库,近年来逐渐成为科学研究的热门工具,从表3中可以看出Python是各NLP工具支持最多的语言,其他支持的语言也集中在Java和C++,主要的原因可能是方便部署以及能够进行快速处理。各NLP 工具的调用方式也以SDK 为主,极少数支持客户端。一些工具也提供RESTful API,这是一种流行的调用方式,即用URL定位资源,用HTTP行为描述操作,通过简洁的代码获取服务器资源。NLP工具中采用这种方式能够减少本地模型部署,同时一些暂不开源的功能也能通过这种方式供用户调用。不少工具以深度学习框架为基础进行构建,支持最多的深度学习框架为Pytorch,其次为TensorFlow。
3 任务实现模型和方法
不同工具对上述的子任务各有不同程度的支持,通过对各种开源工具的调研发现,方法和模型的发展影响和促进着工具的迭代。斯坦福大学开发的工具CoreNLP在早期版本使用基于规则和统计方法来实现自然语言处理中的子任务,而在它最近新开发的工具Stanza中多应用深度学习方法,达到更好的效果。大多数工具会根据子任务的特性采取不同的原理方法,同一子任务也具有多种实现方式,Hanlp在分词任务上提供CNN+CRF[23]、预训练语言模型微调等多种方法选择。
自然语言处理工具中各子任务的原理方法大致分为四种类型,即规则方法、统计学习、神经网络以及在这三种类型上的混合方法。
3.1 规则方法
早期的自然语言处理思路是根据人类语言学知识和相关领域知识总结相关的规则,然后应用到具体任务上,基于匹配和基于任务特点是两种基本的策略。
基于匹配的方法是最朴素的思路,如中文分词任务中,依照词典对文本序列进行匹配分割,为了提升分割的正确率,衍生出正向最大匹配、逆向最大匹配以及双向扫描等方法,一些早期的信息抽取系统也是通过归纳总结出触发词定位目标信息。
基于任务特点的策略是观察任务数据的规律,然后对规律进行抽象并总结出规则算法。基于规则的新词发现算法利用词性之间的组合关系作为规则来找到新词,例如AB为字符串,根据名词的构词规则,A为名词,B为动词、名词或形容词,则AB可能为新词。一些相似度计算方法则根据知识库中定义的规则,将词汇分解成同义、反义等词汇特征进行相似度计算。NLTK等工具在较早版本的不少子任务中采取基于任务特点的方法,JioNLP中也基于规则完成丰富的文本预处理和信息提取任务。
规则方法具有描述明确、表达清晰等优点,能够使用语言模型的组成成分和结构清楚明了地将很多语言事实都表示出来,在自然语言处理中有很好的研究和应用价值。
3.2 统计方法
基于规则的方法在实际应用场合的表现往往不如统计学习和神经网络,因为后两种方法能够根据实际数据不断地学习和调整,具有较强的泛化能力,而基于规则的方法通常由人工进行整理归纳,进行调整比较困难。统计学习与深度学习的基本思想是从一定数量的观测样本出发,选择合适的模型或方法拟合样本数据的潜在规律,再利用拟合出的规律处理和分析相似的数据。
分词、词性标注和命名实体识别等绝大多数自然语言处理任务常被转化为序列标注问题进行处理,序列标注问题的输入一般为原始文本也被称为观测序列,输出是任务对应的标记序列也被称为状态序列。问题的目标是学习一个模型,使它能够针对观测序列给出标记序列作为预测。统计学习方法在解决序列标注问题中应用较多的有最大熵(maximum entropy,MaxEnt)[24]、隐马尔可夫模型(hidden Markov model,HMM)[25]、条件随机场(conditional random field,CRF)[26]以及基于它们的改进或衍生方法。常见的统计学习模型结构如图3所示。
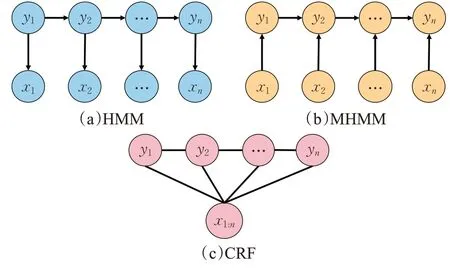
图3 常用统计学习模型结构Fig.3 Structure of common statistical learning models
隐马尔可夫模型描述由隐藏马尔可夫链生成不可观测的状态序列,再由各个状态生成一个观测而产生观测序列的过程。SnowNLP、ChineseNLP 分别在词性标注、分词任务上采用隐马尔可夫模型来实现。然而隐马尔可夫模型假设相对比较简单,它假设任意时刻的隐藏状态只依赖于前一时刻的隐藏状态,在处理诸如实体嵌套、分词等问题时表现不佳。Fine等人[27]对模型进行改进,使用多层隐马尔可夫模型进行计算,底层模型为高层模型的参数提供支持,实现更好的泛化和扩展。张华平等人将这一方法应用到中文领域的部分处理子任务并集成到NLPIR工具中[28]。
最大熵遵循的原则是在学习时模型尽可能地满足已有的事实,而对未知的事实使用均匀分布去描述,这样使得从数据中学习到的模型更加客观,OpenNLP 大多任务便是采用最大熵的思想进行实现。
基于最大熵模型和隐马尔可夫模型融合的最大熵马尔可夫模型(maximum entropy Markov models,MEMM)[29]对隐马尔可夫模型的假设做出了改变,即认为当前时刻隐藏状态同时取决于上一时刻隐藏状态和当前时刻的观测状态,故将文本的前后信息引入到模型的学习和预测中,LTP在较早版本便应用了这一模型[4]。最大熵马尔可夫模型虽然解决了观测序列元素之间严格独立产生的问题,但是局部归一化处理,使得产生标注偏置问题。
条件随机场舍弃了隐马尔可夫模型中的两个基本假设,使之可以容纳任意的上下文信息,同时用全局归一化代替局部归一化消除最大熵马尔可夫模型中的不足之处。条件随机场相对复杂的设计使得需要训练的参数更多,也导致了训练时间长、计算复杂度更高的缺点,但优异的表现却仍然让很多工具中的子任务使用它来完成。
统计方法在自然语言处理中的应用不止上述的模型,早期工具在进行依存句法分析时也会用到概率上下文无关方法[30],文本摘要和关键词提取任务常用TextRank[31]方法,还有一些工具在任务中使用较为少见的统计方法。
3.3 神经网络方法
随着神经网络的出现,人们开始考虑将它应用在自然语言处理上。Bengio提出的NNLM 标志着采用神经网络对语言实现表示和处理的开始[32]。Chen 等人[33]提出一种将词、词性标签以及依存关系特征拼接作为输入的浅层神经网络,构建贪心依存句法解析器,并被作为CoreNLP中句法解析的一种方法。
卷积神经网络(convolutional neural network,CNN)[34]多用于计算机视觉领域,因具有良好的特征提取能力遂被引入自然语言处理领域。spaCy文本分类任务就是采用CNN 与注意力机制结合实现。Kim[35]针对句子分类提出的TextCNN 也取得良好的效果,DeepNLP 用它实现文本分类,THUNLP、lightNLP 用它进行信息抽取相关任务。CNN计算速度非常快,注重采用卷积、池化等步骤对局部信息的提取进行整合,得到整体信息,对情感分析这一类由关键短语决定的任务处理效果比较好[36]。但CNN 的模型输入输出大小相对固定,同时对语义的理解往往需要考虑较远距离上的字词,因此CNN 不善于处理具有较长距离依赖的不定长序列数据。
循环神经网络(recurrent neural network,RNN)[37]主要针对序列数据建模,能够对之前时刻的序列信息进行记忆并与当前时刻序列元素作用进行计算,计算结果作为下一时刻输入的一部分从而影响后续序列。但是RNN 由于共享同一套参数和连乘效应,导致存在梯度消失或爆炸以及信息丢失问题。针对这些问题先后设计出能够有选择性筛除不重要信息的长短时记忆网络(long short-term memory,LSTM)[38],以及对LSTM 进行改进使得收敛更快、参数较少的门控循环单元(gated recurrent unit,GRU)[39]。不过之前的RNN 结构在计算过程中只考虑前文的信息,为了利用后文的信息设计出双向结构BiLSTM、BiGRU使得模型的学习能力进一步提升[40]。lightNLP、Hanlp、DeepNLP、Stanza 等工具多使用BiLSTM,因为它在训练数据量较大时表现更好,而BiGRU由于计算速度更快,NLPIR、UDPipe将它作为实现手段。除对内部结构的改进外,针对任务的需要,对RNN 的输入输出结构进行改变,出现了用于标注任务的N-N型、针对图片生成文字的1-N型、文本分类的N-1 型,以及可用于翻译的N-M型。RNN 演化结构如图4所示。
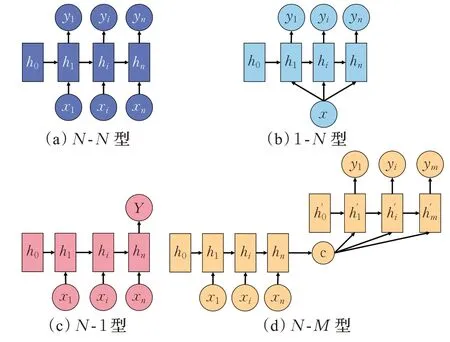
图4 RNN演化结构Fig.4 RNN evolution structure
3.4 组合方法
N-M型也被称为Seq2Seq,即编码器-解码器结构[41]。由于输入输出序列长度不受限制适合生成类任务,lightNLP 将其应用到机器翻译和文本生成任务中,ChineseNLP将其应用在文本摘要任务中。虽然RNN内部结构的改进使模型学习到信息也相对更多,但随着序列过长会使较远距离的信息被遗忘,Seq2Seq 常与注意力机制结合用于筛选任务相关的重要信息[42]。Vaswani等人[43]在Seq2Seq 与注意力机制的启发下提出著名的Transformer模型用于机器翻译,模型中的多头自注意力机制不仅能解决RNN 由于循环结构不能并行计算问题,还能捕捉相对较长序列中的信息。由于其性能较好,THUNLP、LTP、spaCy以及Hanlp等工具将其改造用于一些子任务。
上述的深度学习方法在提取欧氏空间里的数据特征时有非常良好的表现,但是不少图结构的数据并非如一些模型假设那样彼此独立,因此这些方法有时并不适合处理非欧氏空间中的数据。为了将深度学习方法在图结构上扩展,图神经网络(graph neural network,GNN)[44]应运而生。图卷积网络(graph convolution network,GCN)[45]将卷积运算从传统的文本、图像数据推广到图数据,也是众多复杂神经网络的基础。注意力机制也被应用到图神经网络中来放大数据中重要部分的影响,其中比较有影响力的是注重于节点邻域权重的图注意力网络(graph attention network,GAT)[46]和使用自注意力机制为每个头部分计算不同权重的门控注意力网络(gated attention network,GaAN)[47]。
规则方法、统计学习方法和神经网络方法各自具有特点,有不同的适用场景,在应用研究中为了达到更好的效果,有时需要针对不同子任务的特点对方法进行改进或者选取合适的方法组合。
分词任务上便有采用词典+有向无环图+HMM 的组合方法。最开始通过Trie 树[48]依据词典得到句子中字所有可能组成词情况,并构建为有向无环图,再根据登录词词频使用动态规划查找最大概率路径的切分组合,针对未登录词采用HMM 模型进行预测处理[28]。这种组合方法不但支持自定义词典提高特定词的识别率,充分利用已知词典信息实现快速切分提高整体分词速度,还对未登录词结合统计信息进行预测,保证一定的正确性。
2015 年Huang 等人[49]提出BiLSTM+CRF 的方式进行序列标注任务,BiLSTM 对文本序列信息进行解析,然后对输出序列中每个字或词输出属于不同标签的得分。但BiLSTM缺乏对标签间关系的约束,导致得分最高的标签并不一定是正确的标签,因此需要加入CRF学习标签间的约束关系,从而做出更准确的预测。从不少工具子任务的实现原理中可以看到BiLSTM+CRF的方式掀起了很大的热度,对计算性能要求较高、运行环境特殊的BaiduLAC 和NLPIR 使用BiGRU 替换BiLSTM实现分词等任务,而在句法分析任务中,Stanza和FLAIR等采用双仿射注意力机制Biaffine[50]代替CRF提升效果。
以往模型方法需要针对具体的任务标记大量的数据训练得到效果较好的模型,而预训练语言模型在训练阶段获得了大量通用知识,在预训练模型的基础上结合其他方法进行微调便可提升许多子任务的效果。
神经网络的预训练技术可追溯至前文提到的NNLM,为了方便计算机进行处理,需要对文本中的字词进行向量化,这一过程也被称为文本嵌入。文本嵌入对任务效果影响较大,自然语言处理工具基本都提供嵌入接口,其中UDPipe和Graph4NLP提供的嵌入方式较为丰富。
较早时期的文本嵌入采用独热编码对词进行表示,但是这种方式不仅存在维度灾难和数据稀疏等问题,还完全割裂了词之间的联系。Mikolov等人[51]对NNLM进行简化获得词的低维稠密嵌入表示Word2Vec,并提出两种训练方式。其中CBOW是用一定窗口范围的上下文词预测中心词,而Skip-gram与之原理相同,只不过是用中心词预测固定窗口的上下文。但Word2Vec无法解决未登录词问题,Facebook 对此提出了fastText[52],将能组成单词的词根或词缀整理为集合,并对集合中的每个元素进行向量化表示,然后通过词根或词缀向量相加的方式表示词,此方法使得未在训练集中出现的词也能通过这种方式进行表示。这种基于上下文窗口的方法产生的词向量只学习了局部词之间的关系,缺乏对词在全局层面进行刻画,Pennington 等人[53]提出融合全局信息的词嵌入模型GloVe。GloVe统计出全局词的共现概率比,以此呈现词之间的相关性,然后学习满足共现概率比的词向量参数。
上述基于上下文窗口和基于融合全局信息的嵌入方法又被称为静态嵌入,这类方法忽略了词序信息,也只能生成一个固定的向量,无法结合上下文信息进行调整,不能解决一词多义问题。ELMo[54]模型开启了动态词嵌入的篇章,推动了语言预训练技术的发展,它能够根据词所处的上下文信息对词产生不同的映射。随后的BERT、GPT[55]、ERNIE[56]等系列模型通过对大规模语料库的预训练,得到上下文词的语法和语义等通用信息。GPT 是基于Transformer 的解码器部分演变成的自回归模型,根据上文或下文内容预测当前词进行预训练任务,因此适合文本摘要等生成类任务。BERT 则是由Transformer中的编码器改造而来的自编码模型,它将输入文本中的部分词语进行随机掩盖,并让模型去预测被掩盖的词,同时判断两个句子是否具有上下文关系,通过这两个任务使模型学习到文本的通用信息。
当下大多数预训练语言模型便是对两类模型方法进行衍生和改进。自回归模型是通过扩大模型参数量和语料库,并增加训练任务难度的方式进行优化,如GPT-2、GPT-3 等[57-58];自编码模型是调整掩码策略或句子连续预测任务,如RoBERTa[59]、ALBERT[60]。近来引发关注的Electra则是引入替换标记检测任务,用生成器预测词汇并替代标记,再用判别器检测生成器产生的词与替换前是否相同从而学习参数[61]。基于Transformer 衍生的预训练模型如图5所示。
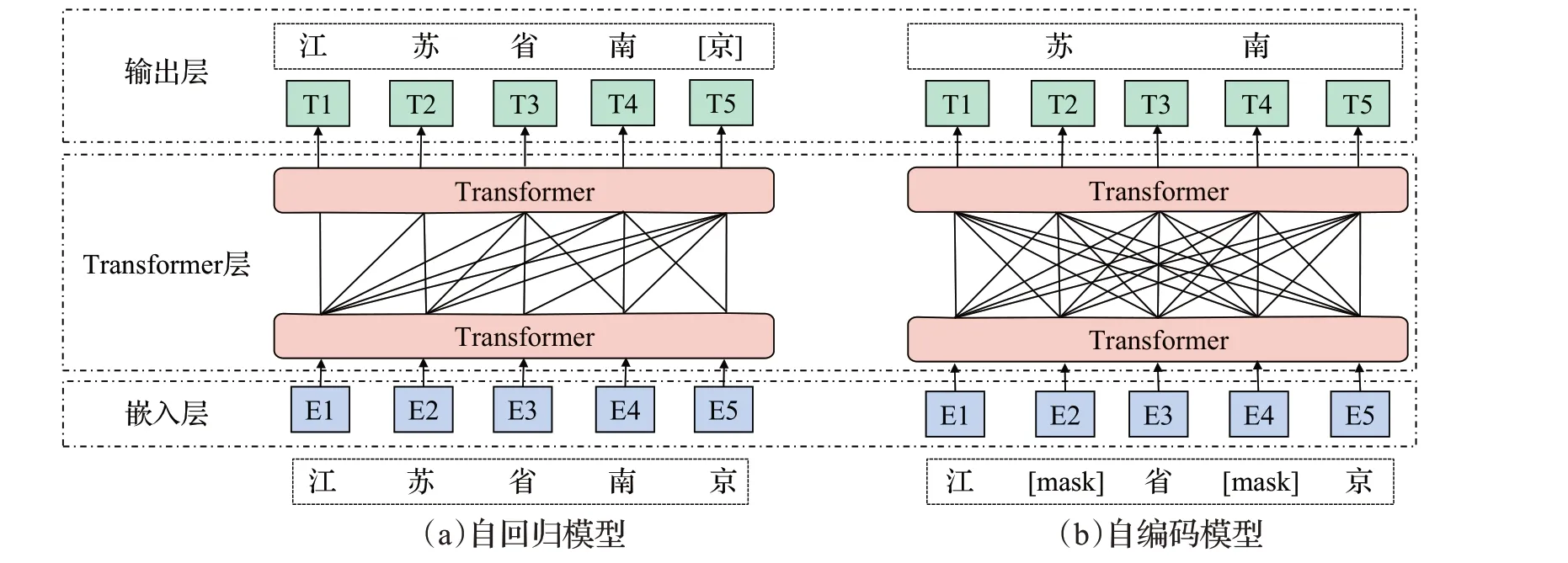
图5 基于Transformer衍生的预训练模型Fig.5 Pre-training model derived from Transformer
基于预训练模型微调的方式逐渐成为自然语言处理的新范式。LTP在最新的版本中全然采用这种方式,选取预训练模型Electra作为基础,结合线性回归进行分词和词性标记,对依存句法分析和语义依存分析使用Biaffine进行解码。fastNLP也使用类似的方式,不同的是使用基于BERT改进后的预训练模型,解码任务也大多采用CRF来完成[14]。
不同类型的方法具有不同的特点,表4是对四大类方法的总结。
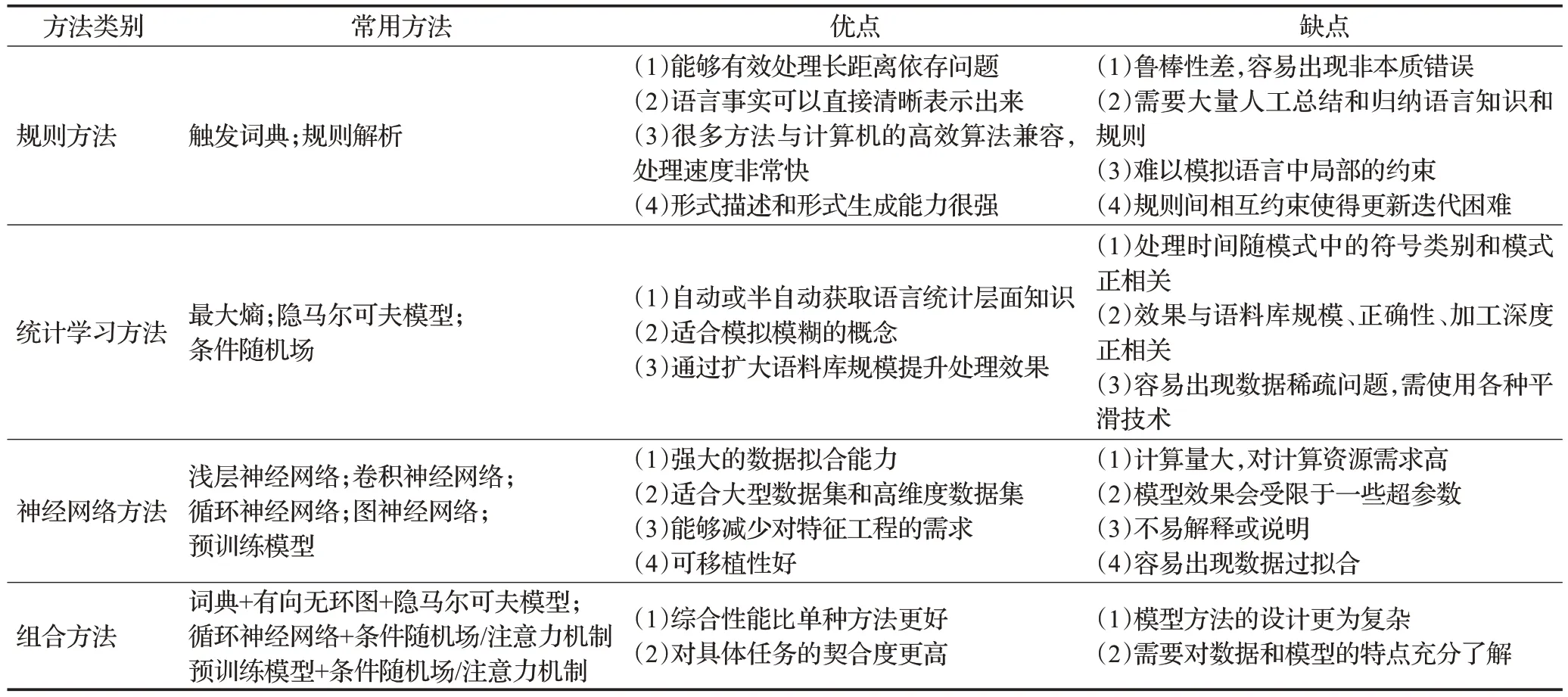
表4 方法特点比较Table 4 Comparison of method characteristics
3.5 工具子任务具体原理对比
在调研过程中,同样对每种工具子任务的具体实现原理进行记录,根据前文对子任务的分类标准整理为表5~表7。表中,×表示工具对该任务暂未实现和支持,Y*表示该工具该功能有所实现,未列出是因为这部分工具未完全开源,只提供免费调用接口。
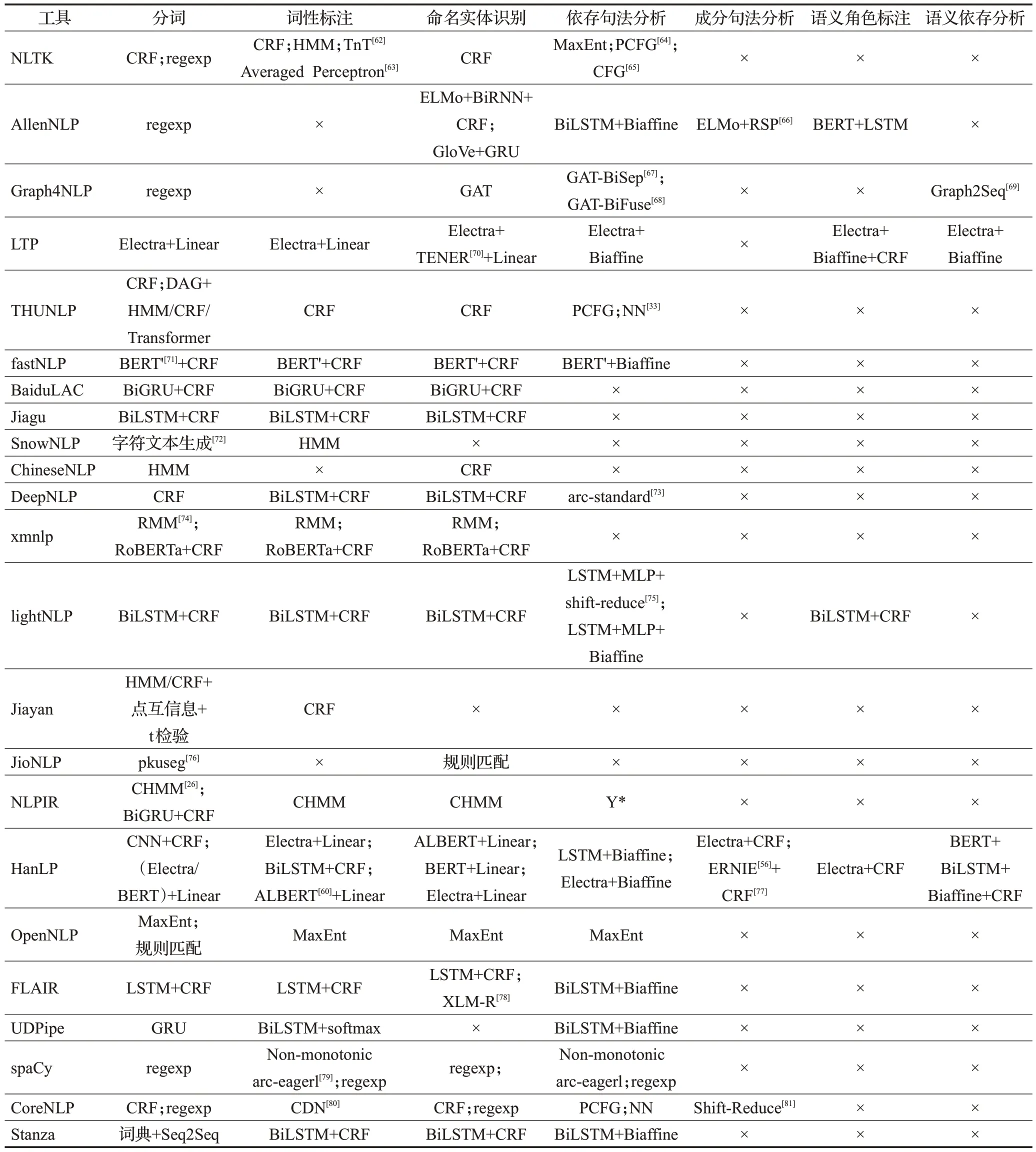
表5 基础任务原理和方法Table 5 Principles and methods of basic tasks
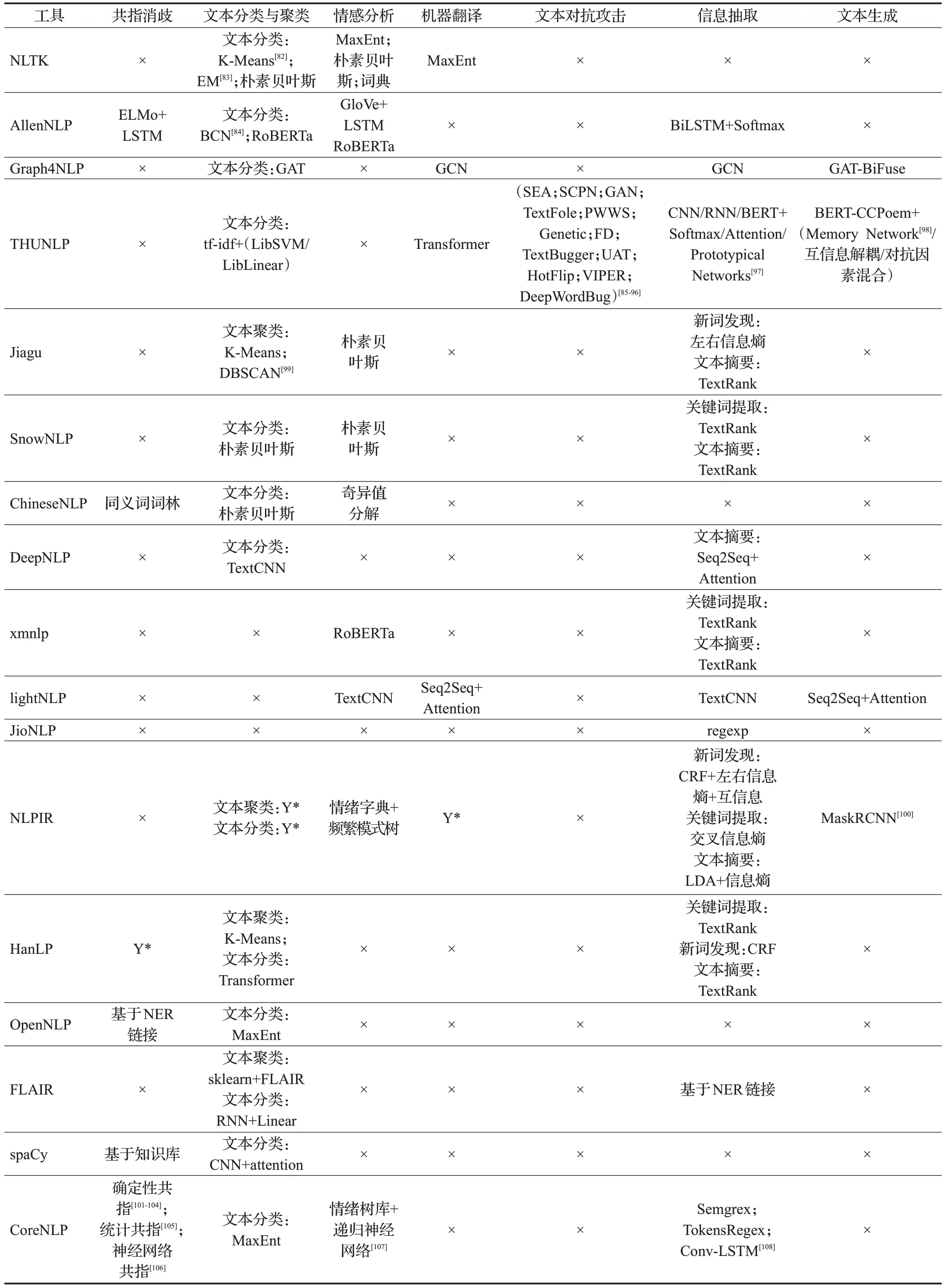
表6 应用任务原理和方法Table 6 Principles and methods of application tasks
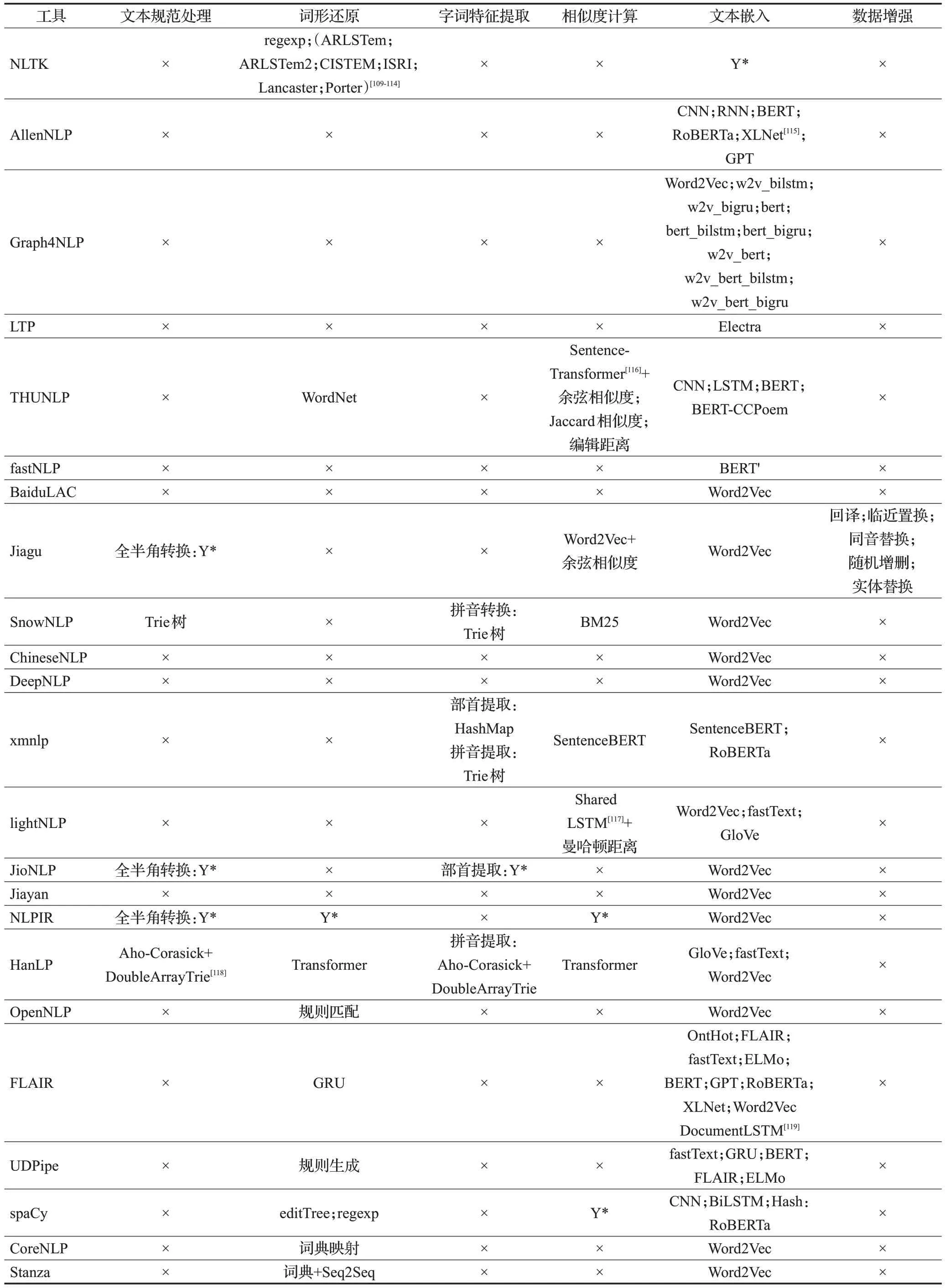
表7 辅助任务原理和方法Table 7 Principles and methods of auxiliary tasks
基础任务的实现主要集中在词法分析和依存句法分析,对语义的分析只有LTP、xmnlp、Hanlp等工具才提供支持,原因是语义层面的分析任务相对词法分析更为困难,并且相关的标注数据集较少,尤其是在中文领域。另一方面纵然有很多对语义分析相关方法的研究成果,但构建工具时并未将其纳入工具的实现范围内。
应用任务方面多在文本聚类与分类、信息抽取、情感分析等任务上有实现,对共指消歧、机器翻译与文本纠错等任务少有工具能提供。应用任务实现的方法原理多以机器学习和规则匹配为主,某些处理性能较好的工具通常将机器学习和规则相结合,也从侧面说明工具在实际应用中更应该注重配合,发挥出各自的优势。
辅助任务在研究热度上相对较低,但大多辅助任务对文本预处理和特征提取具有重要作用,从而对基础任务和应用任务具有促进作用。各工具主要在相似度计算和文本嵌入方面有较多支持。汉语辅助处理方面如繁简转换、拼音转换,更多考虑的是转换速度。
4 总结与展望
本文首先依据对文本的处理顺序和处理作用将自然语言处理中常见的子任务归为基础任务、应用任务、辅助任务三个类别,并对任务的概念进行描述,介绍一些任务相关的数据集。调研国内外23款开源自然语言处理工具,按照工具所面向的处理领域划分为英文、中文以及多语言进行介绍,对工具的支持环境、调用方式以及在子任务上的优缺点等进行汇总。最后对实现子任务常用的原理和方法进行探究,并对各种工具中子任务具体的实现原理进行分类整理对比。
目前自然语言处理工具在诸多任务上取得较好的性能表现,但仍然存在亟待解决和改进的问题。现从自然语言处理的理论研究和工程实现两大角度对自然语言处理工具未来的发展提出以下展望:
(1)多模态融合
当前自然语言处理的研究主要集中于文本数据,但文本数据对语义的表达具有局限性,因为人类是在多模态的环境下进行学习和使用语言。要使计算机对语言的理解更加充分,需要结合语音、图像等其他模态的信息,因此基于多模态的自然语言处理方法将会是一个重要的研究方向。
(2)大语言模型
现有的自然语言处理工具只能处理词句以及篇章级的任务,在人机交互、知识问答等任务中表现一般。ChatGPT和GPT4的相继问世将自然语言处理推向一个新的高度,这类大语言模型具有自主学习能力,所支持的任务效果在大规模数据驱动学习下得到极大的提升。然而大语言模型也存在对语言中的事实缺乏认知、逻辑推理能力弱等问题,如何提升大语言模型的智能水平,使其充分理解人类的情感和意图,从而为各种语言任务提供有效支撑将是今后研究的热点。
(3)领域效果融合与提升
自然语言处理所涉及到的内容相当宽泛与复杂,以中文领域为例,从时间维度包含先秦著作到现代汉语,从地理角度不同地区又存在差异。汉语一直处于发展过程中,新的词和用语习惯也在不断产生,社会分工发展出现法律、医学等不同的领域。虽然不少工具在通用领域具有一定良好的表现,但应用在一些具体领域效果却不甚理想。即便是目前火热的ChatGPT,它在特殊领域中很多任务效果十分不理想,因此应该给予具体领域更多的关注或者推动通用领域融合发展。
(4)模型压缩与高效计算
近来自然语言处理领域倾向于设计越来越复杂的网络,网络越复杂,参数越多,对数据的拟合效果也越好。然而复杂的模型对硬件设备要求较高,在移动端上部署困难,同时复杂大模型也存在计算速度慢等问题。对此常采取的思路是将大而深或者集成的网络通过知识蒸馏的方式转移到小的网络上,另外一种常见思路是通过共享参数的方式进行压缩。但目前在保证效果的前提下对模型进行压缩却比较困难。
(5)语料稀缺
自然语言处理任务的实现效果不但与任务方法和模型有关,还受到任务语料质量的影响。许多工具虽在任务语料上表现出良好的性能,但并不具备很强的泛化能力。任务语料建设又需要耗费大量的人力物力,中文相关的任务语料更为稀缺,如何利用有限的数据集提高模型的泛化能力,让计算机充分理解文本中语义信息来实现任务是未来发展的关键。
(6)标准化与简洁性
正如前文提到存在数据集标注标准多样化问题,同一子任务不同的标注标准会导致分析处理结果的差异。像Hanlp 针对不同标准训练不同的模型固然是一种解决方式,但也为工具的部署运行增加了负担。此外,某些相似的任务也可以考虑进行融合实现或者进行多任务学习,例如将中文分词、词性标注以及命名实体识别看作同一序列标注问题,从而减少任务开销。综上,实现标注标准统一和融合相似任务是语言处理工具需要考虑的一个重点。
